Geometry Worked in Trading IT Graduate of Galvanize Data Science Bootcamp in San Francisco Community manager and consultant at RaRe Technologies. NLP consulting and open-source development of Natural Language Processing packages in Python.
Allocation See paper for details: “Latent Dirichlet Allocation” David Blei, Andrew Ng, Michael Jordan 2003 http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf
a although although although ambiguity and are arent at bad be be be beats beautiful better better better better better better better better break cases complex complex complicated counts dense do do dutch easy enough errors explain explain explicit explicitly face first flat good great guess hard honking idea idea idea if if implementation implementation implicit in is is is is is is is is is is it it its lets may may more namespaces nested never never never not now now obvious obvious of of often one one one only pass practicality preferably purity readability refuse right rules should should silenced silently simple sparse special special temptation than than than than than than than than that the the the the the there those to to to to to ugly unless unless way way youre' Example from Timothy Hopper: Understanding Probabilistic Topic Models By Simulation https://www.youtube.com/watch?v=_R66X_udxZQ Do you recognise this text?
is better than implicit simple is better than complex complex is better than complicated flat is better than nested sparse is better than dense readability counts special cases arent special enough to break the rules although practicality beats purity errors should never pass silently unless explicitly silenced in the face of ambiguity refuse the temptation to guess there should be one and preferably only one obvious way to do it although that way may not be obvious at first unless youre dutch now is better than never although never is often better than right now if the implementation is hard to explain its a bad idea if the implementation is easy to explain it may be a good idea namespaces are one honking great idea lets do more of those' ' '.join(sorted(text.split(' '))) It is “The Zen of Python” with word order removed
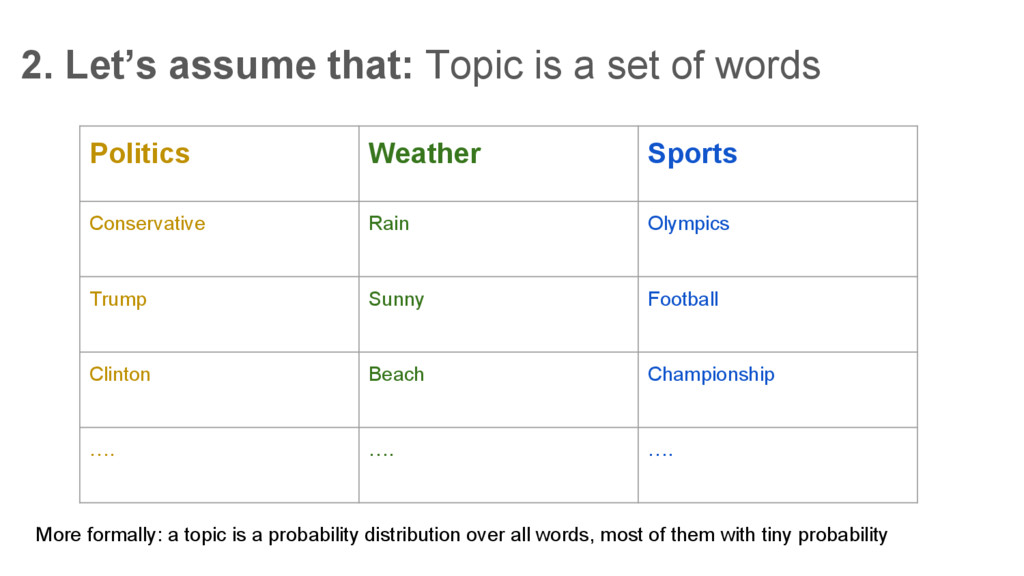
Politics Weather Sports Conservative Rain Olympics Trump Sunny Football Clinton Beach Championship …. …. …. More formally: a topic is a probability distribution over all words, most of them with tiny probability
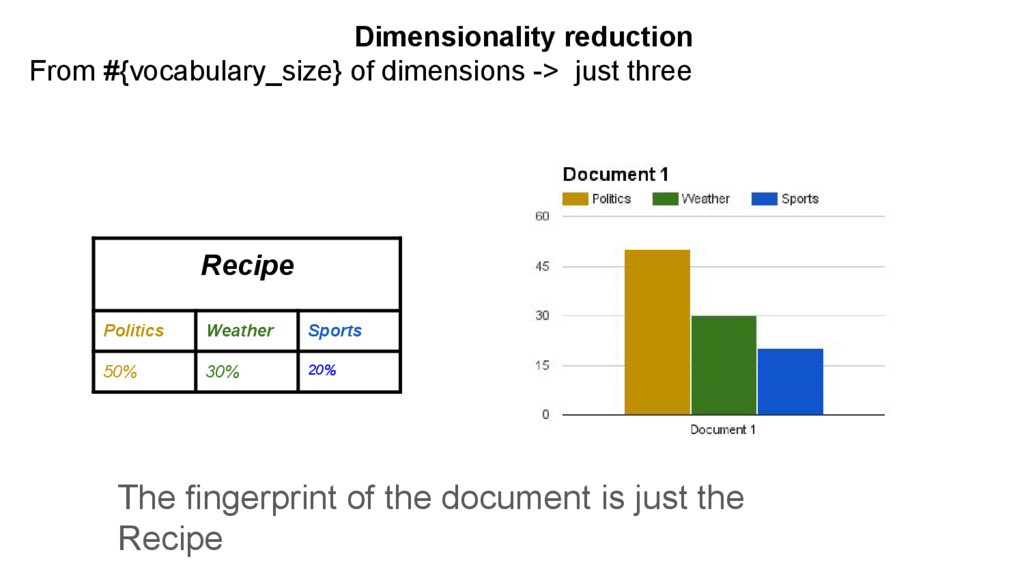
Let’s assume that: Documents are written by following recipes Recipe Politics Weather Sports 50% 30% 20% DOCUMENT Conservative Liberal Rain President Sun Snow Minister Olympics Football Politics Weather Sports Conservati ve Rain Olympics Trump Sunny Football Clinton Beach Champions hip …. …. ….
backwards with Bayesian Inference! Find the model that describes the documents best! - “Put words that appear together into the same topic.” Politics Weather Sports Conservati ve Rain Olympics Trump Sunny Football Clinton Beach Champions hip …. …. …. DOCUMENT 1 Conservative Liberal Rain President Sun Snow Minister Olympics Football DOCUMENT 2 Trum Clinton Storm Swimming Hockey DOCUMENT 1000 UEFA Arsenal Football
parameters: - Number of topics - Are docs about a few topics or many? (low or high alpha) - Do topics have a few words or many? (low or high beta) - Advanced: pre-seed topics, # of iterations, asymmetric priors, multicore etc See paper for details: “Latent Dirichlet Allocation” David Blei, Andrew Ng, Michael Jordan 2003 http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf
color_words(good_lda_model, bow_water) bank river water tree color_words(bad_lda_model, bow_water) bank river water tree ? river bank or financial bank ?
topic words appear ‘together’ in the corpus. The trick is: many ways to define ‘together’... Just use ‘c_v coherence’ - it is the best one. Paper: “Exploring the Space of Topic Coherence Measures” by M. Roder et al http://svn.aksw.org/papers/2015/WSDM_Topic_Evaluation/public.pdf
sport”, “the game is played with a ball”, “the game demands great physical efforts” ] Topic to evaluate = {game, sport, ball, team} Many-many coherence measures can be tried. Here are two simple ones.
a set of words to find out how coherent the set is. goodcm = CoherenceModel(model=goodLdaModel, texts=texts, dictionary=dictionary, coherence='c_v') print goodcm.get_coherence() 0.552164532134 badcm = CoherenceModel(model=badLdaModel, texts=texts, dictionary=dictionary, coherence='c_v') print badcm.get_coherence() 0.5269189184
teams of 5-15 developers, engineers, analysts and data scientists •2-day intensives include Python Best Practices and Practical Machine Learning, and 1-day intensive Topic Modelling RNDr. Radim Řehůřek, Ph.D. Gordon Mohr, BA in CS & Econ industry-leading instructors for more information email [email protected] m
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Colouring words in Gensim bow_water = ['bank', 'water', 'river', 'tree']](https://files.speakerdeck.com/presentations/eb7e1850123b4368b338119392dc3972/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Lev Konstantinovskiy @teagermylk [email protected] See you at our PyCon UK](https://files.speakerdeck.com/presentations/eb7e1850123b4368b338119392dc3972/slide_32.jpg){kind=link}