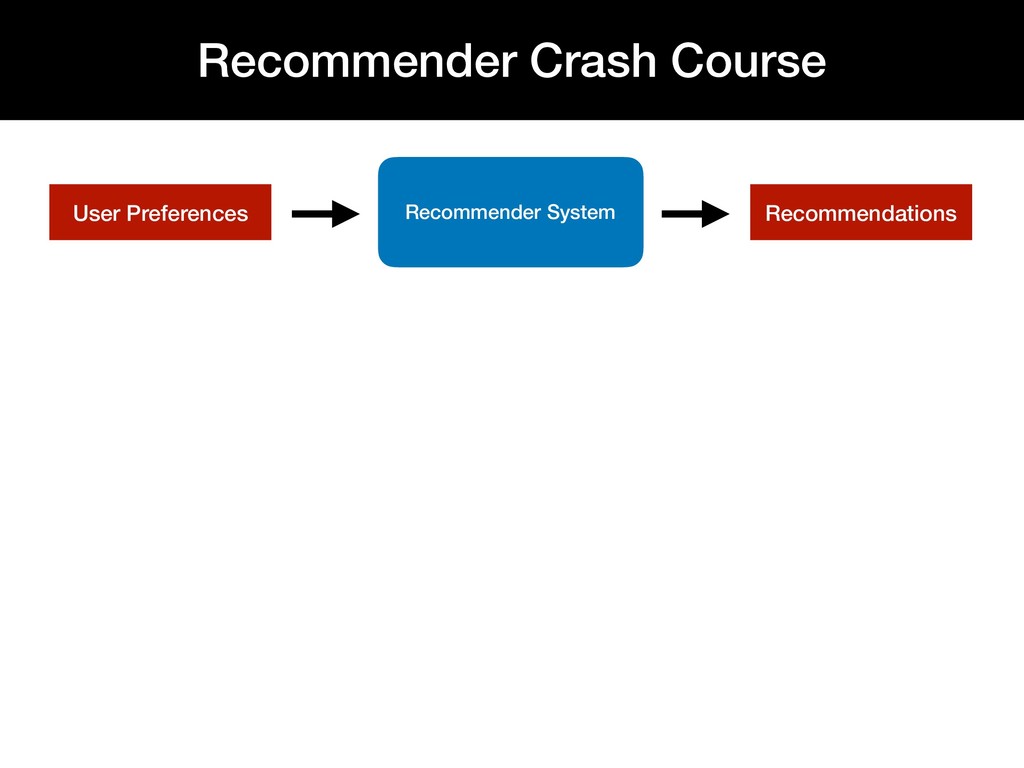
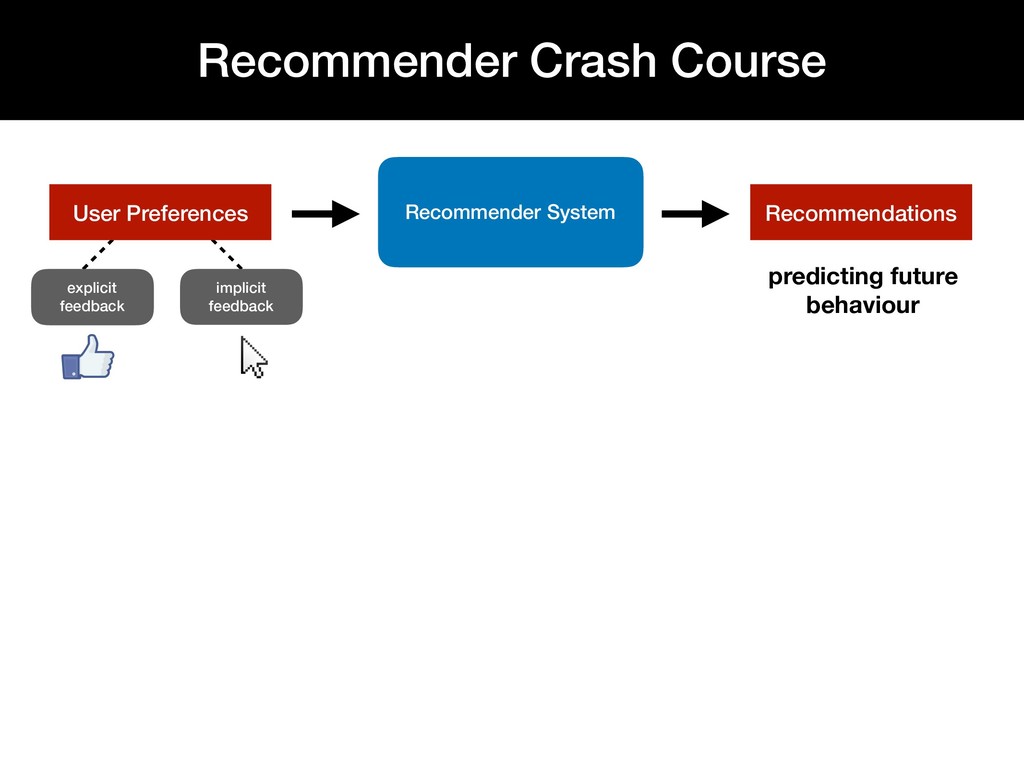
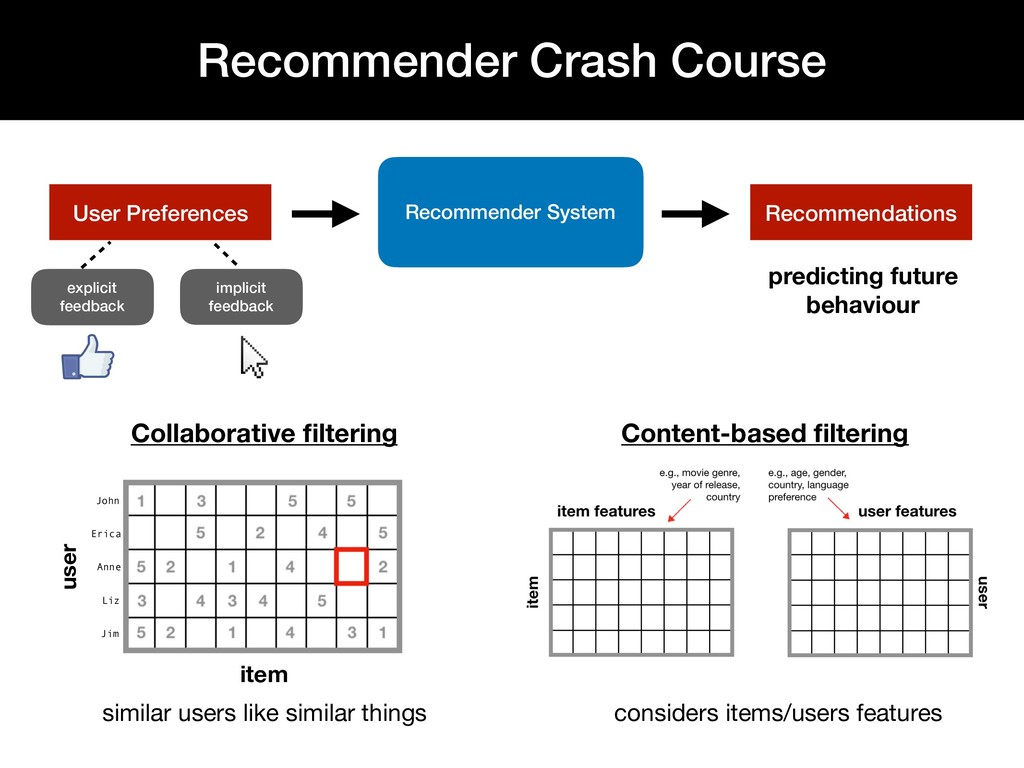
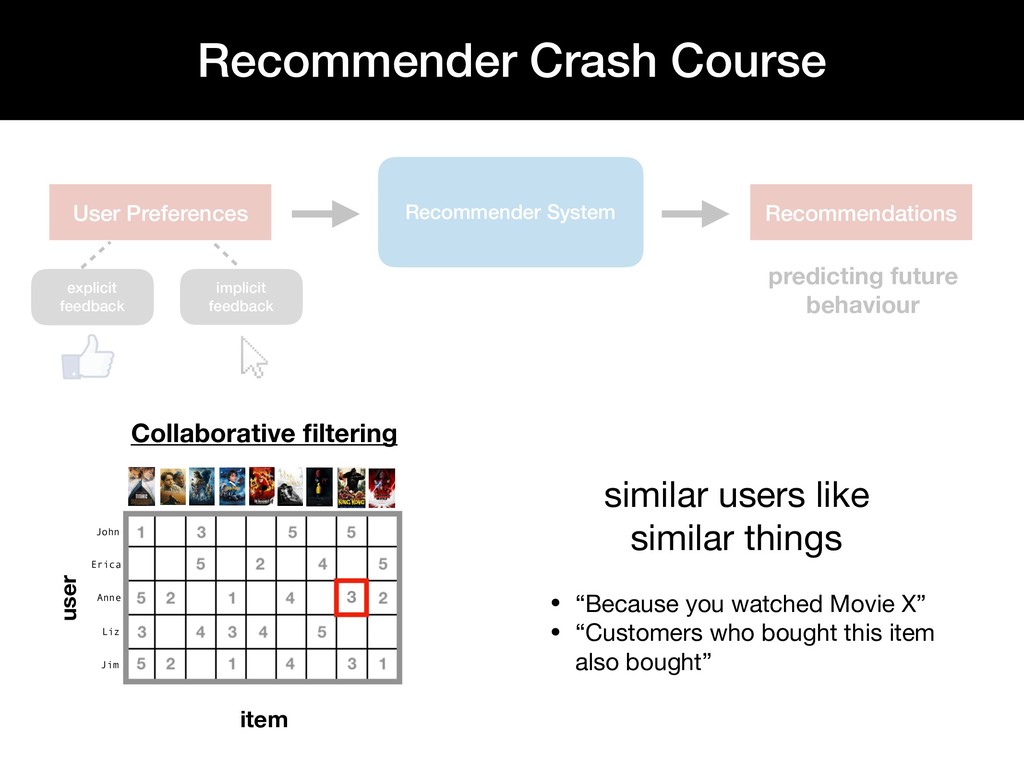
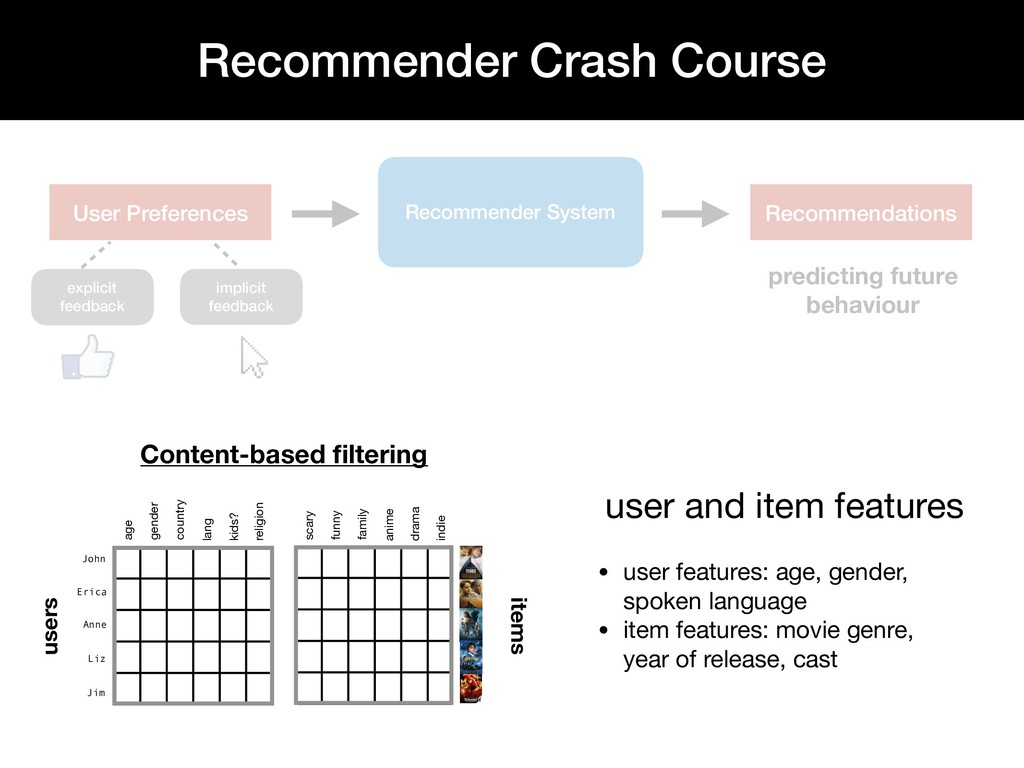
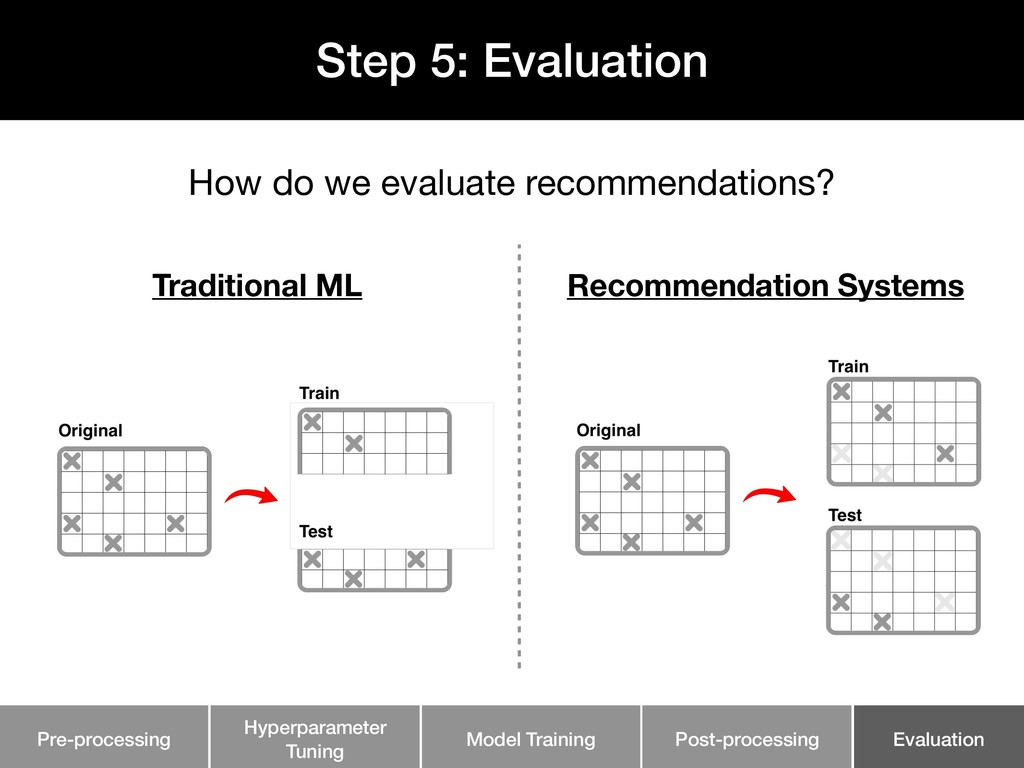
Personalized recommendation systems play an integral role in e-commerce platforms, with the goal of driving user engagement. While there is extensive literature on the theory behind recommendation systems, there is limited material that describes the underlying infrastructure of a recommendation system pipeline.
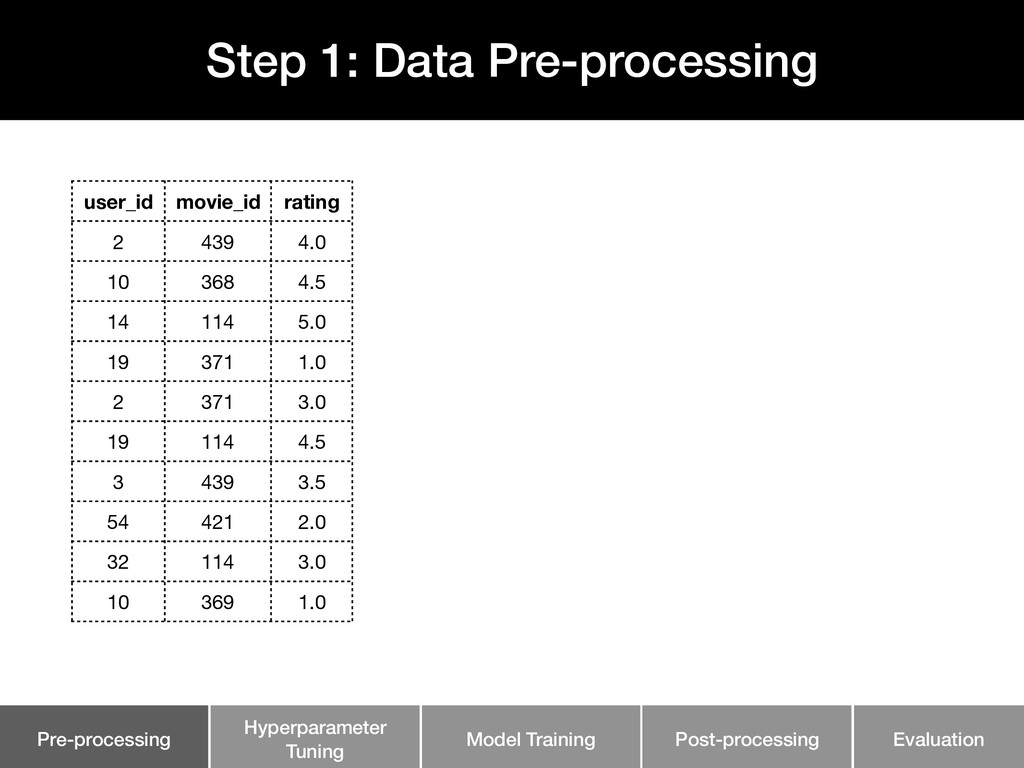
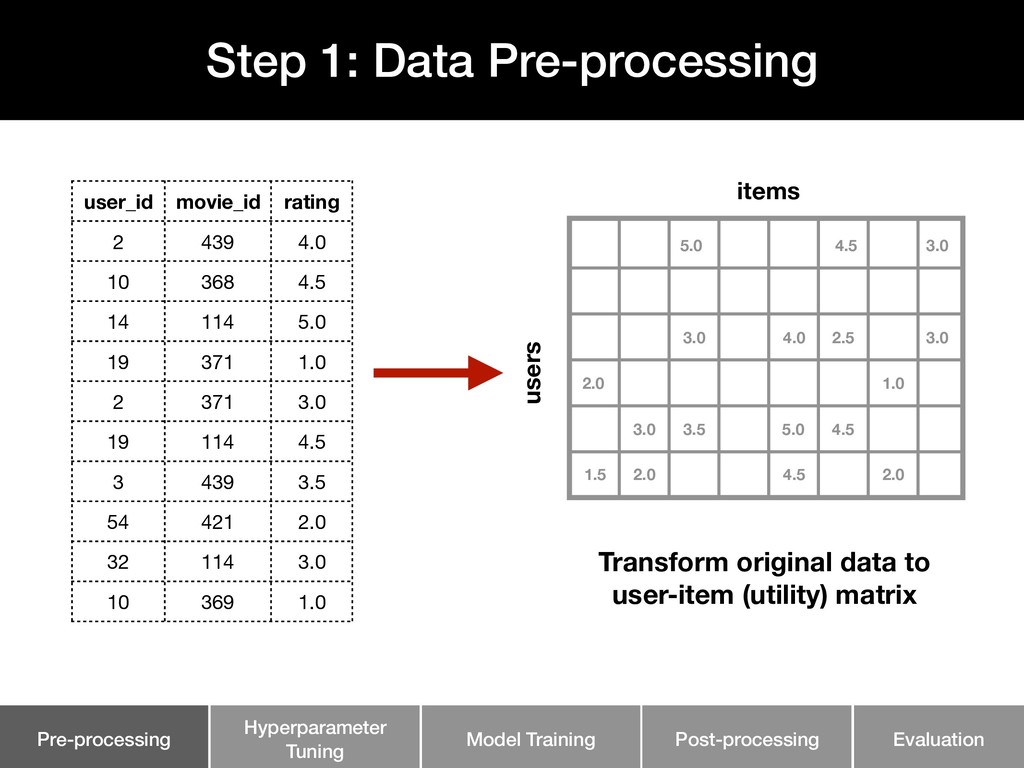
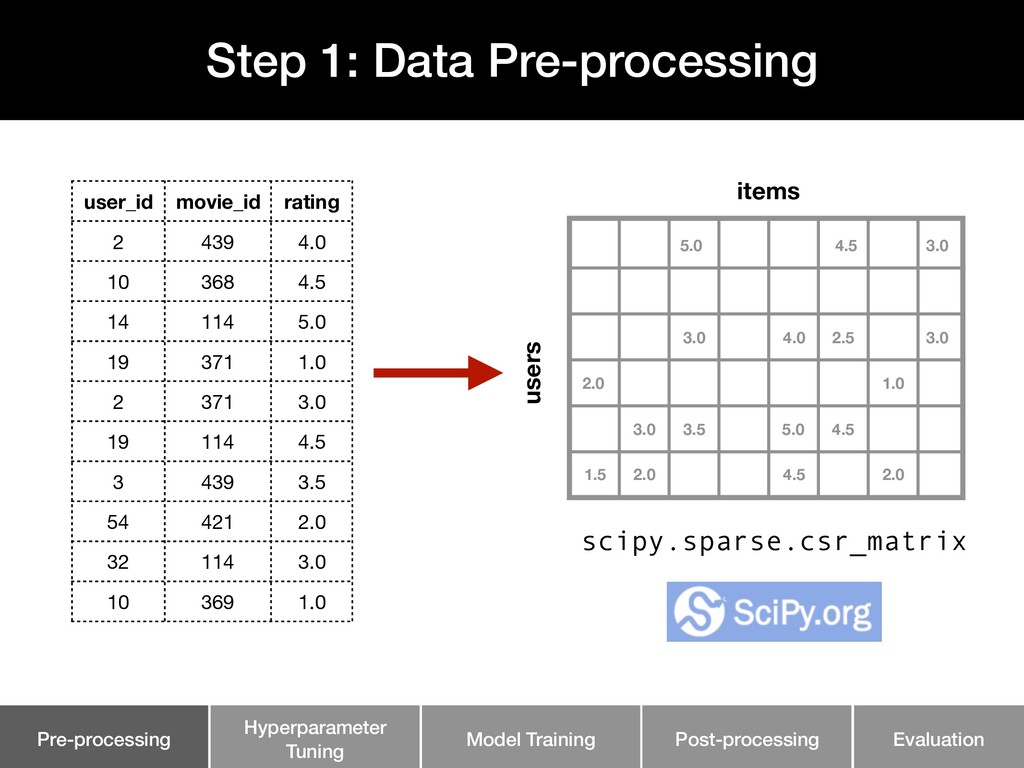
This talk walks through the steps involved in building a recommendation pipeline, from data cleaning, hyperparameter tuning, model training, and evaluation.
{kind=link}
{kind=link}
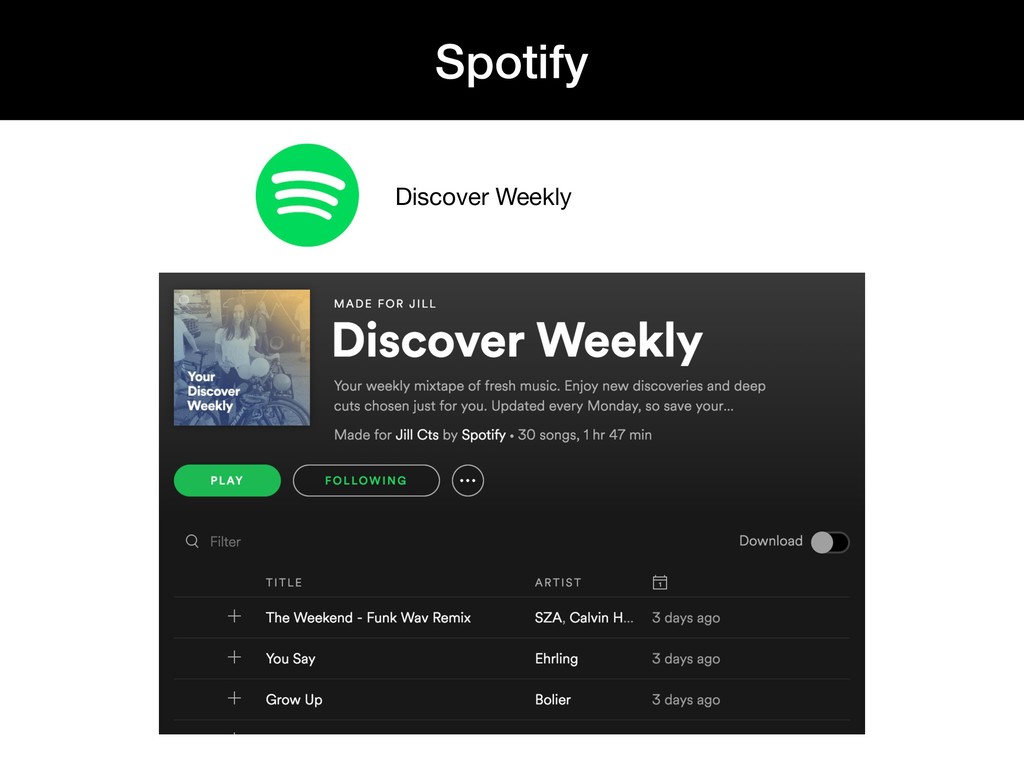{kind=link}
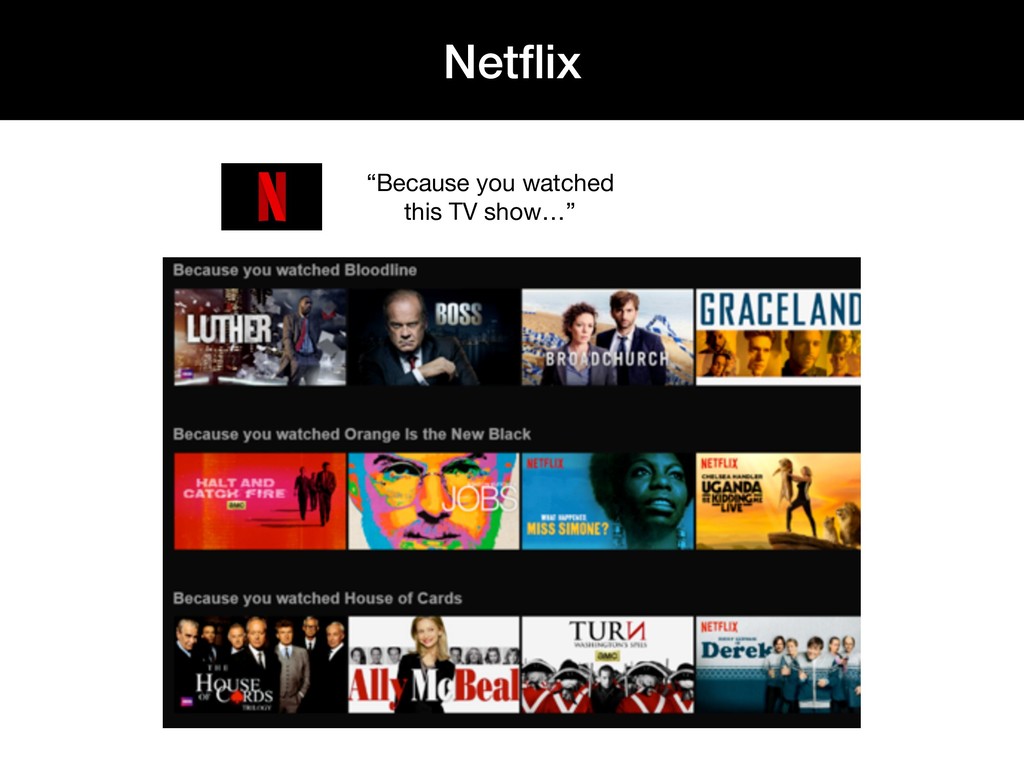{kind=link}
{kind=link}
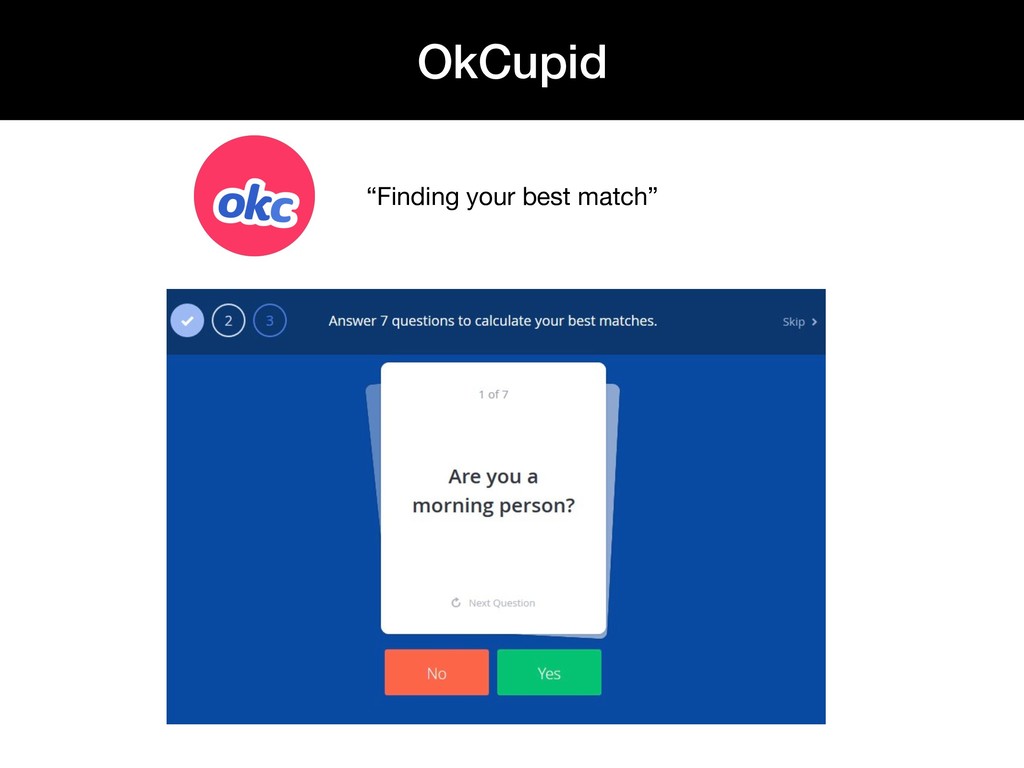{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
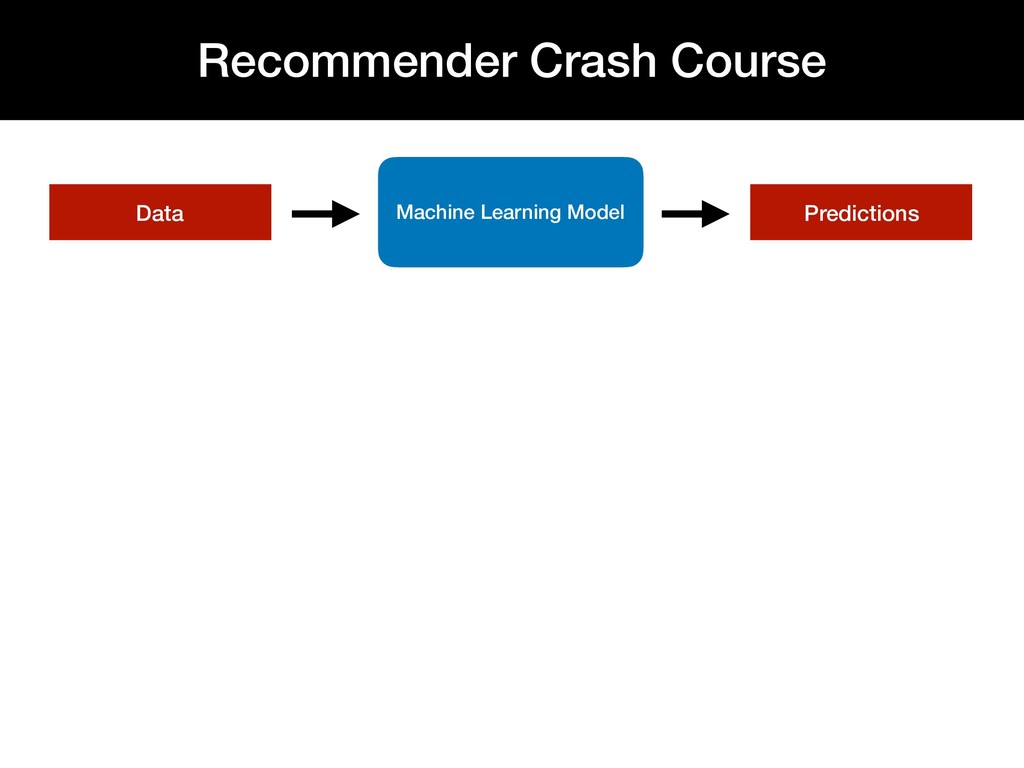{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Jill Cates twitter: @jillacates github: @topspinj [email protected]](https://files.speakerdeck.com/presentations/80fb80962418488faeea07b1bdb13eb8/slide_41.jpg){kind=link}