Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LangChain Open Deep Researchとは?
Search
ttnyt8701
May 15, 2025
Programming
490
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LangChain Open Deep Researchとは?
https://blueish.connpass.com/event/354793/
ttnyt8701
May 15, 2025
More Decks by ttnyt8701
See All by ttnyt8701
Gemini CLI のはじめ方
ttnyt8701
1
310
ObsidianをMCP連携させてみる
ttnyt8701
3
7.2k
Claude Codeの使い方
ttnyt8701
2
460
FastMCPでMCPサーバー/クライアントを構築してみる
ttnyt8701
3
750
Vertex AI Agent Builderとは?
ttnyt8701
4
450
A2A(Agent2Agent )とは?
ttnyt8701
2
520
Amazon Bedrock LLM as a Judgeを試す
ttnyt8701
2
220
Amazon Sagemaker Jump Startを用いて爆速でモデルを作成してみる
ttnyt8701
3
130
Amazon SageMaker Lakehouseでデータのサイロ化による課題を解決する
ttnyt8701
2
88
Other Decks in Programming
See All in Programming
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
650
IBM Bobを活用したレガシーアプリの最新化
oniak3ibm
PRO
1
240
LLM本来の能力を解き放つサンドボックス技術とAI民主化への適用
yukukotani
3
4.9k
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
180
エンジニアと一緒にテストコードの設計と実装を改善した話
mototakatsu
0
250
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
180
どこまでゆるくて許されるのか
tk3fftk
0
430
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
480
そのテスト、説明できますか?~LWテスト戦略FW~のご紹介
nakahara
0
200
TSKaigi Night Talks 2026_TypeScriptでサプライチェーンの整合性を型に閉じ込める
geekplus_tech
0
430
AI 輔助遺留系統現代化的經驗分享
jame2408
1
1.2k
関数型プログラミングのメリットって何だろう?
wanko_it
0
150
Featured
See All Featured
BBQ
matthewcrist
89
10k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
270
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Amusing Abliteration
ianozsvald
1
220
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Six Lessons from altMBA
skipperchong
29
4.3k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
310
The SEO identity crisis: Don't let AI make you average
varn
0
510
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
180
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Transcript
LangChain Open Deep Researchとは? 2025.05.15 ©BLUEISH 2025. All rights reserved.
立野 祐太 Yuta Tateno 普段はOCRやRAGを用いたアプリケーション開発に従事しています エンジニア 自己紹介 ©BLUEISH 2024. All
rights reserved.
目次 1. Open Deep Researchとは? 2. Open Deep Researchの利点 3.
ワークフロー 4. マルチエージェント 5. ワークフロー vs マルチエージェント 6. サポート(LLMモデル / 検索API) 7. ハンズオン 8. 振り返り
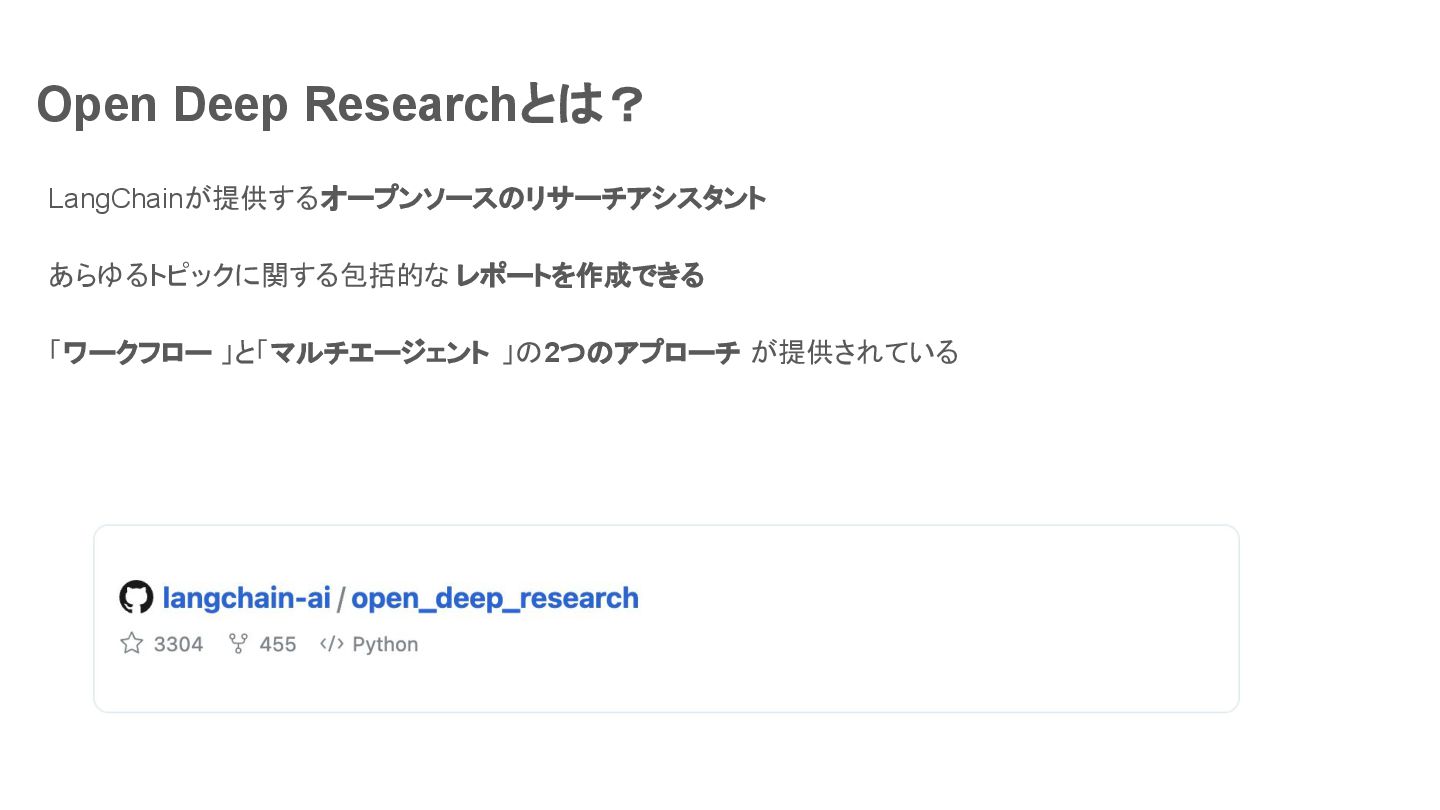
Open Deep Researchとは? LangChainが提供するオープンソースのリサーチアシスタント あらゆるトピックに関する包括的な レポートを作成できる 「ワークフロー 」と「マルチエージェント 」の2つのアプローチ が提供されている
Open Deep Researchの利点 類似サービス • Gemini Deep Research • OpenAI
Deep Research 利点 • 設定柔軟性 • コスト効率 • 新しいモデルやツールを柔軟に組み込める 設定柔軟性 : • レポート構造を細かく指定可能 • 使用するLLMモデルを自由に選択・変更可能 • 検索回数や反復回数を設定可能 • 使用する検索APIを自由に選択・変更可能
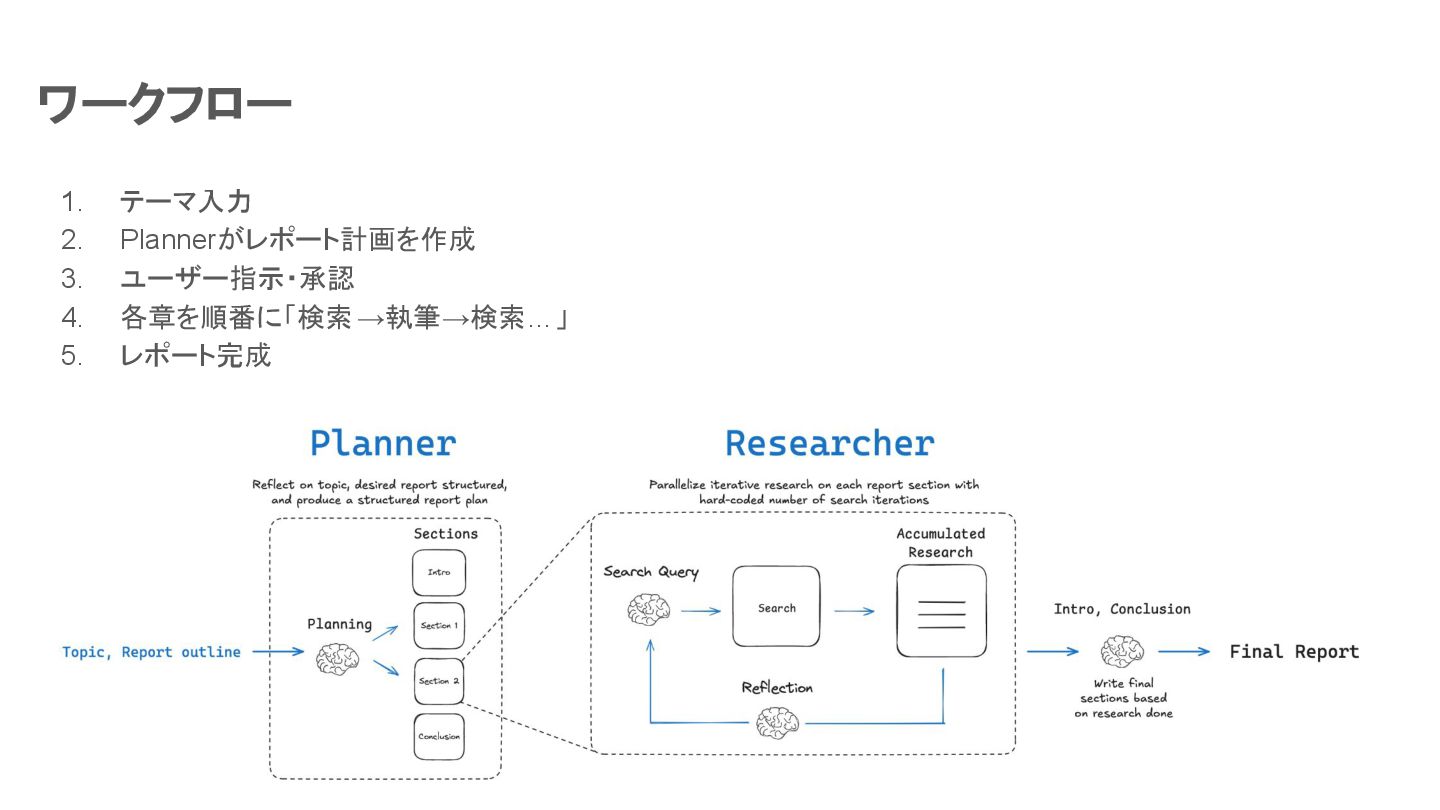
ワークフロー 計画と実行をワークフローで行い、人間のフィードバックを取り入れてレポートを作成 人間のフィードバックによりレポートを細かく制御できる。レポートの品質と正確性が重要な状況に最適
1. テーマ入力 2. Plannerがレポート計画を作成 3. ユーザー指示・承認 4. 各章を順番に「検索→執筆→検索…」 5. レポート完成
ワークフロー
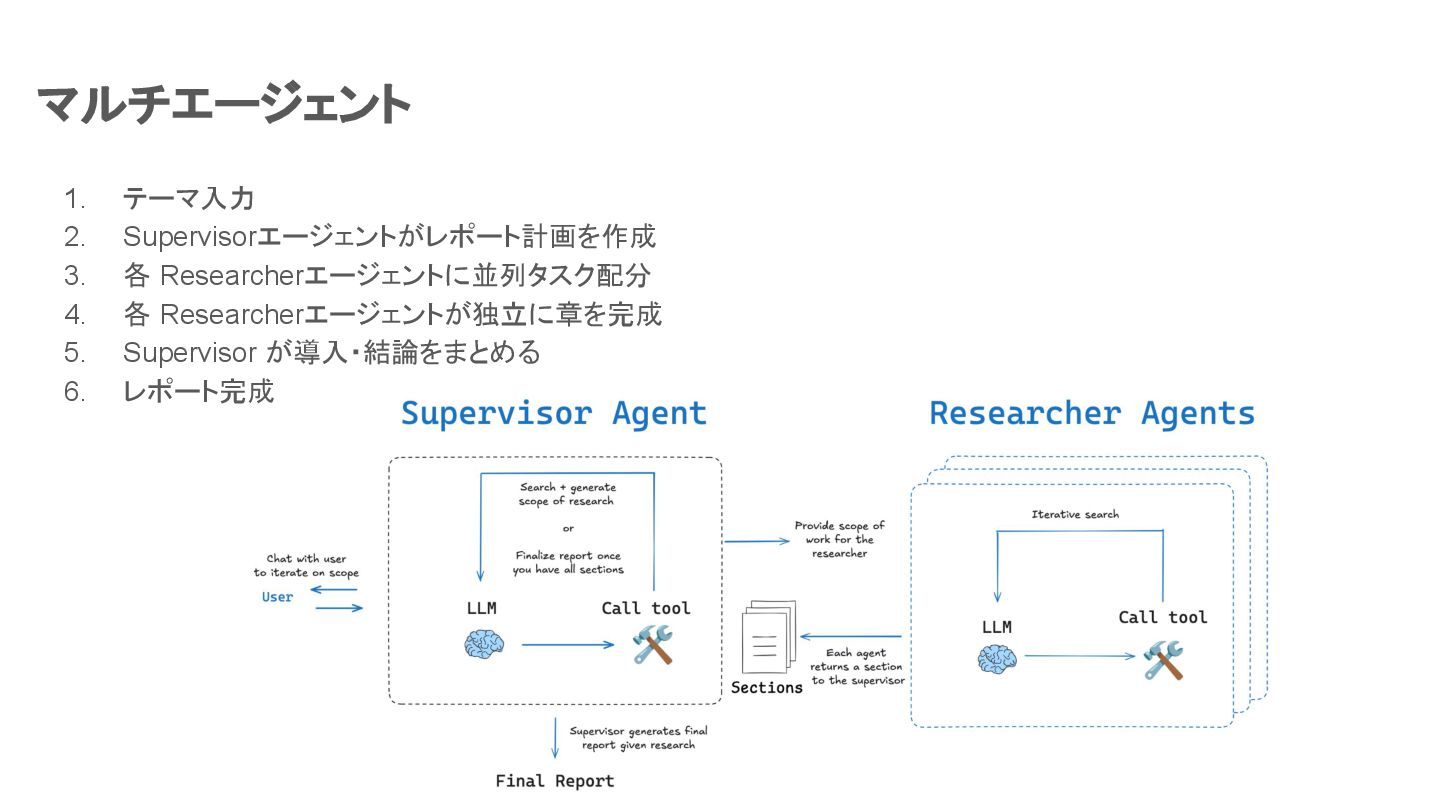
マルチエージェント テーマを入力するのみで、スーパーバイザーエージェントとリサーチャーエージェントが並列処理でレポートを作成 効率性と並列化に重点を置いており、ユーザーの関与を減らしてレポートを高速に生成するのに最適
1. テーマ入力 2. Supervisorエージェントがレポート計画を作成 3. 各 Researcherエージェントに並列タスク配分 4. 各 Researcherエージェントが独立に章を完成
5. Supervisor が導入・結論をまとめる 6. レポート完成 マルチエージェント
ワークフロー vsマルチエージェント レポート生成時間 ワークフロー: 1章ずつ順番に処理。次の章に進む前に前章の完成・反映を待つため、全体の所要時間は合計になる。 マルチエージェント: すべての章を同時に処理。章数が多いほど並列メリットが大きく、全体の所要時間は最長の1章分だけに近づく。 ユーザーの介入ポイント ワークフロー: プランニングフェーズで人のフィードバックを挟める。必要なら計画を練り直してから本文生成
マルチエージェント: 計画後は自動並列処理。途中で人が介入する仕組みは標準ではなし
ワークフロー vsマルチエージェント 制御と可視化のしやすさ ワークフロー: 各フェーズごとに状態が明確(計画案/フィードバック/各章の進捗) マルチエージェント: 背後で同時に処理が走るため、状態が追いにくい 検索ツールの対応範囲 ワークフロー: Tavily、Perplexity、Exa、ArXiv、PubMed、Linkup…複数の
API が選択可能 マルチエージェント: Tavily のみ対応(将来的に拡張可能)
向いているシナリオ ワークフロー: 「品質重視」 人によるフィードバック、多様なソースからの検索が必要なケース マルチエージェント: 「スピード重視」 章ごとに独立した調査が可能で、交差検証が不要なケース ワークフロー vsマルチエージェント
ワークフロー: • Tavily API • Perplexity API • DuckDuckGo API
• Linkup API • Exa API • Google Search API/Scrapper • ArXiv (物理学、数学、コンピュータサイエンスなどの学術論文 ) • PubMed (MEDLINE、生命科学ジャーナル、オンライン書籍からの生物医学文献 ) マルチエージェント: • Tavily API(将来的に他のツールもサポート予定) 検索APIのサポート
LangChain: init_chat_model()でサポートされているモデルを使用できる LLMモデルのサポート プロバイダー • openai • anthropic • azure_openai
• azure_ai • google_vertexai • google_genai • bedrock • bedrock_converse • cohere • fireworks • together • mistralai • huggingface • groq • ollama • google_anthropic_vertex • deepseek • ibm • nvidia • xai • perplexity
⚠注意 ワークフロー 構造化された出力をサポートする必要がある マルチエージェント エージェントモデルはツール呼び出しをサポートする必要がある LLMモデルのサポート
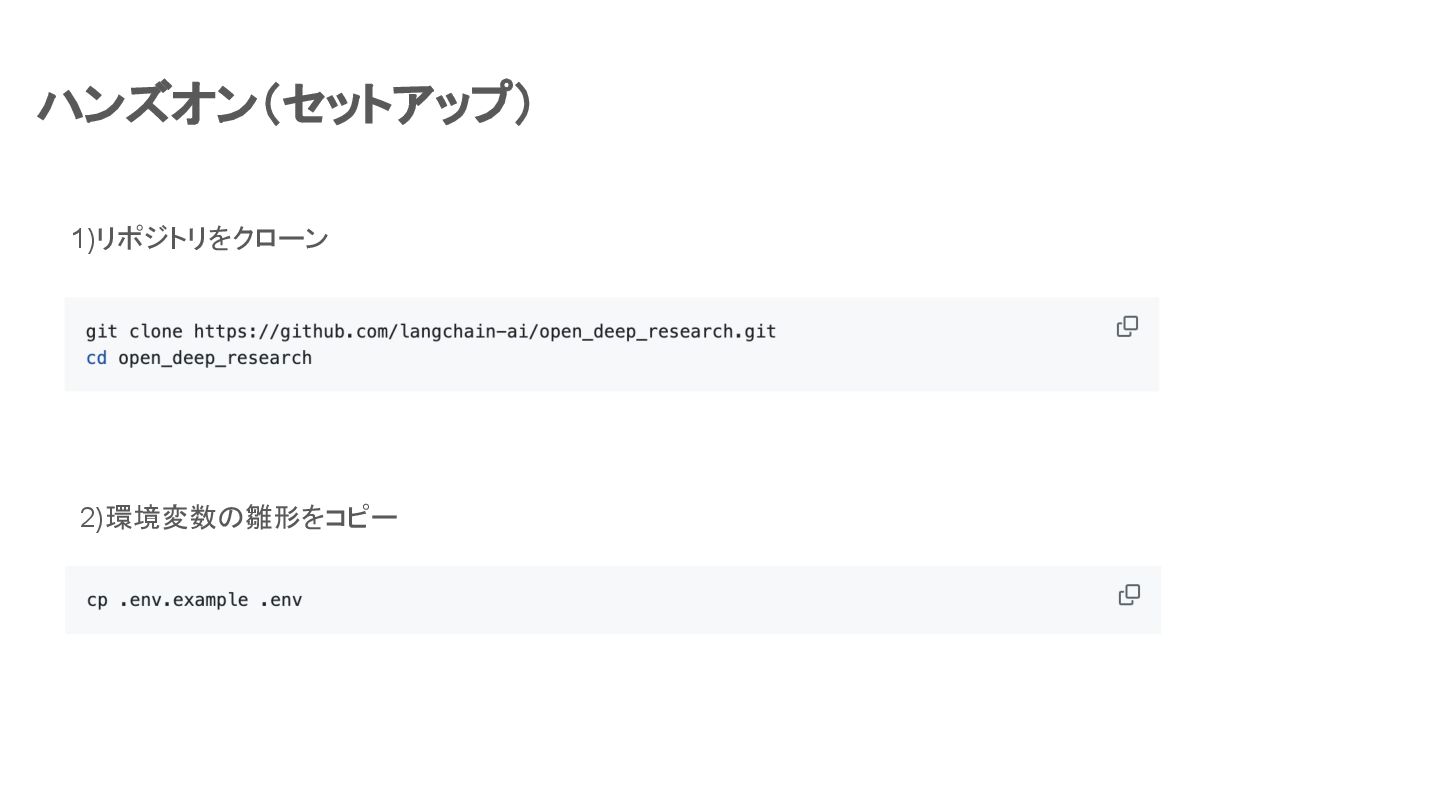
ハンズオン(セットアップ) 1)リポジトリをクローン 2)環境変数の雛形をコピー
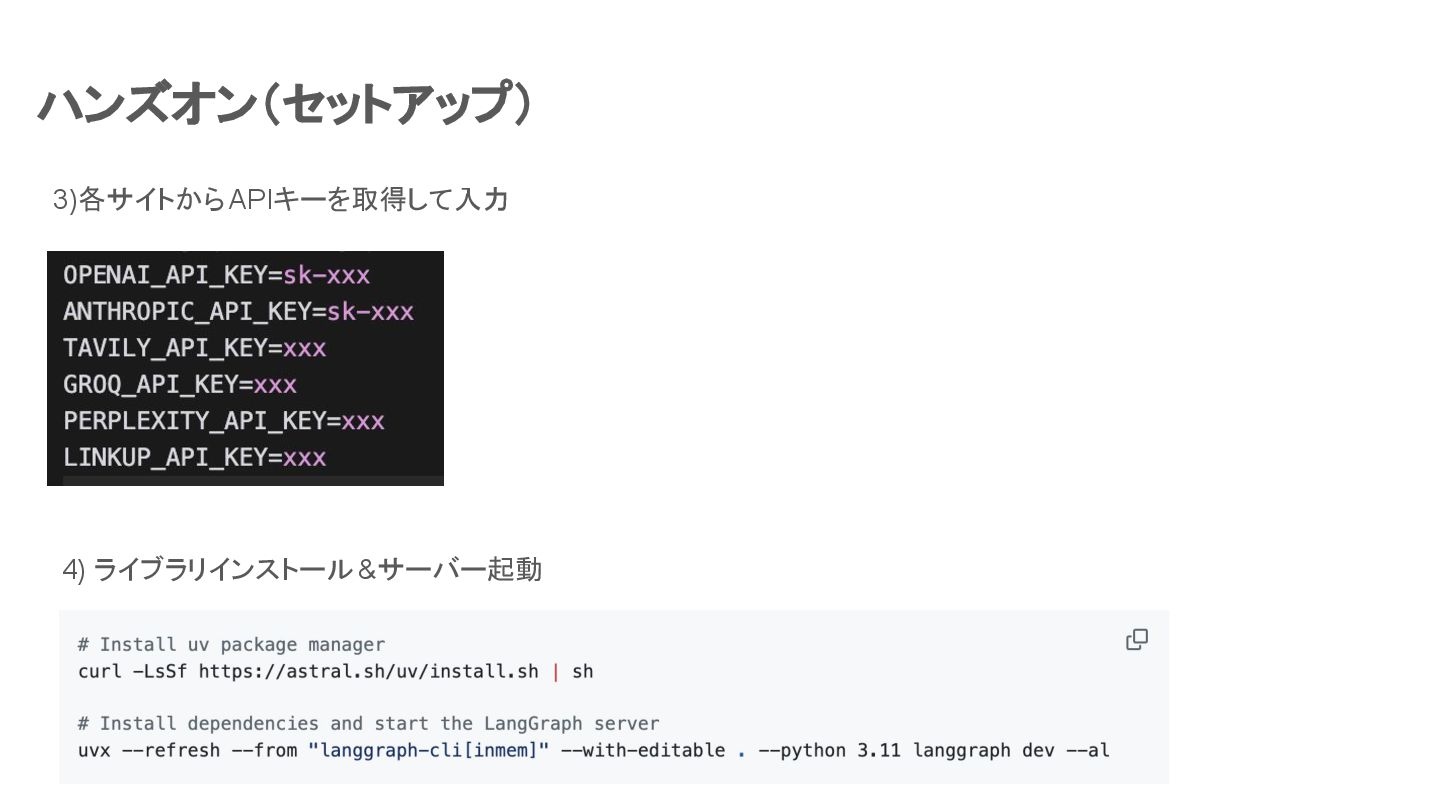
ハンズオン(セットアップ) 3)各サイトからAPIキーを取得して入力 4) ライブラリインストール &サーバー起動
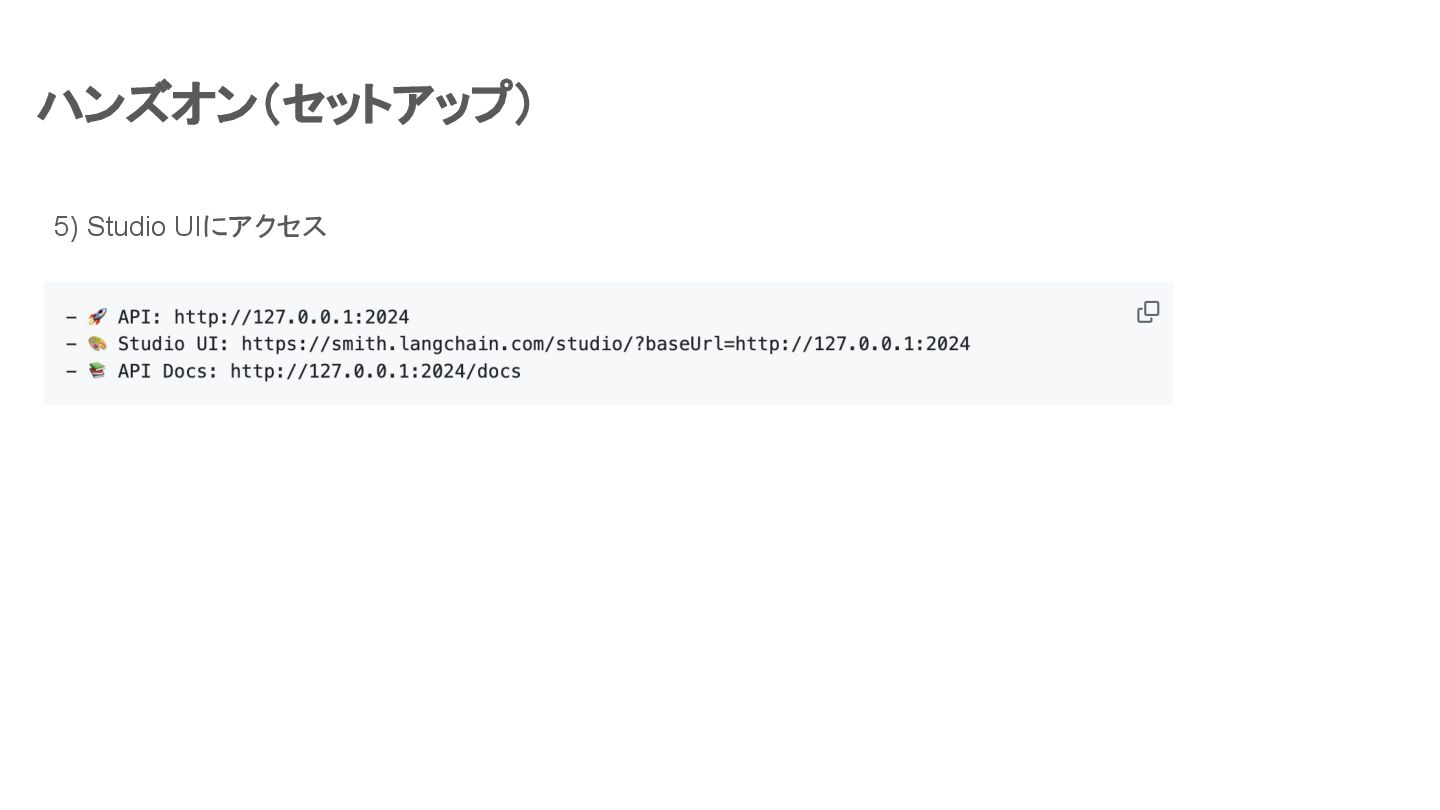
ハンズオン(セットアップ) 5) Studio UIにアクセス
ハンズオン(ワークフロー) open_deep_researchを選択 入力 1) open_deep_researchを選択 2) トピックを入力&送信
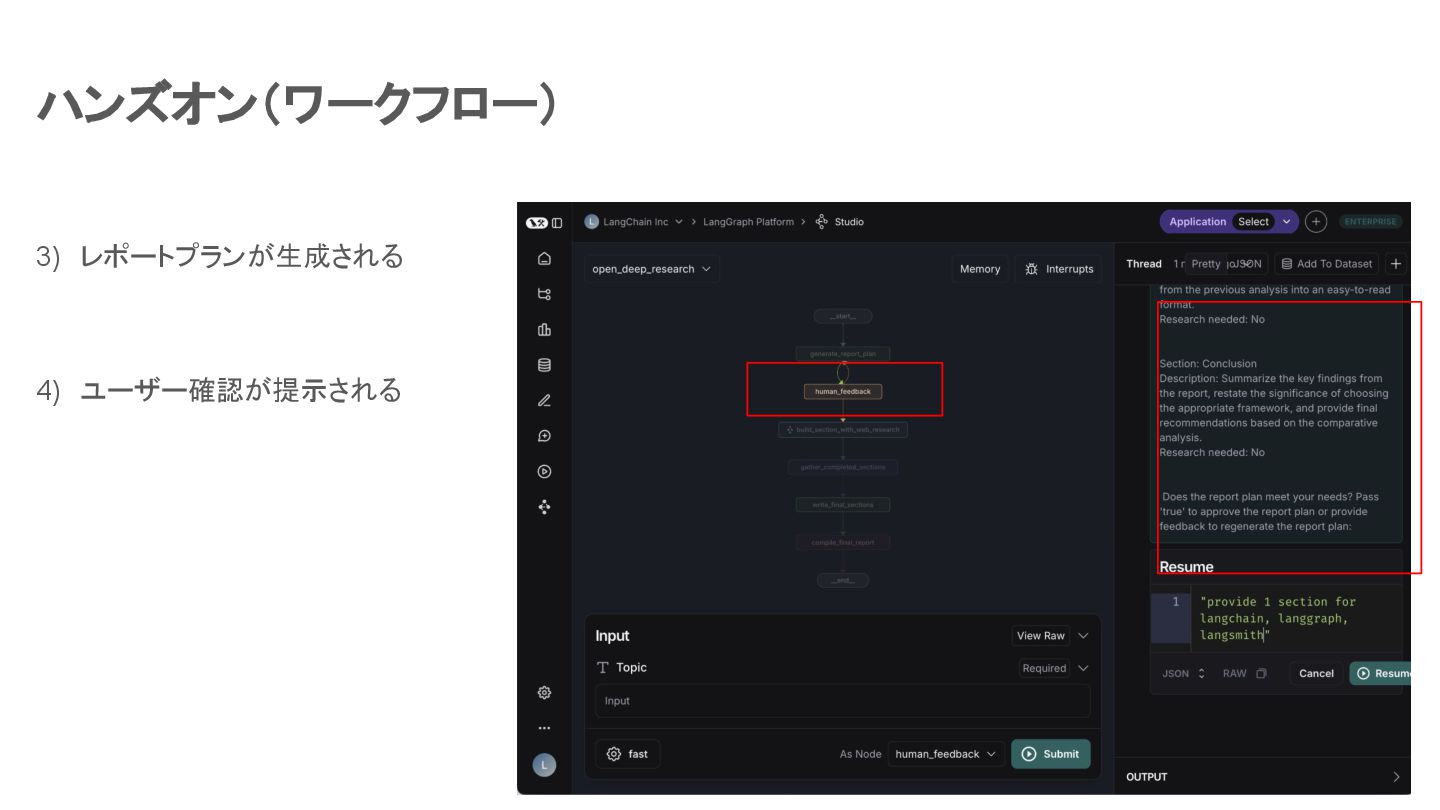
ハンズオン(ワークフロー) 3) レポートプランが生成される 4) ユーザー確認が提示される
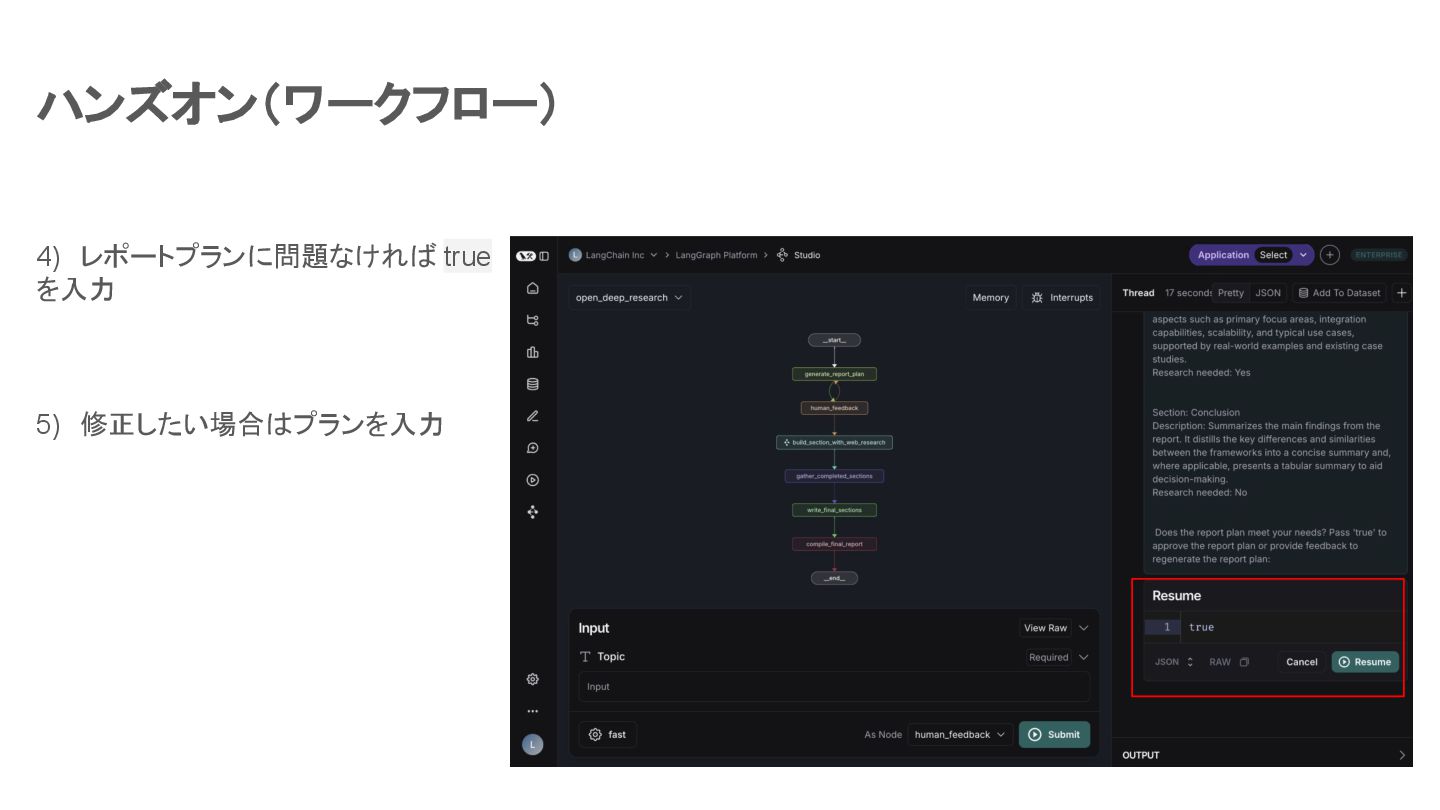
ハンズオン(ワークフロー) 4) レポートプランに問題なければ true を入力 5) 修正したい場合はプランを入力
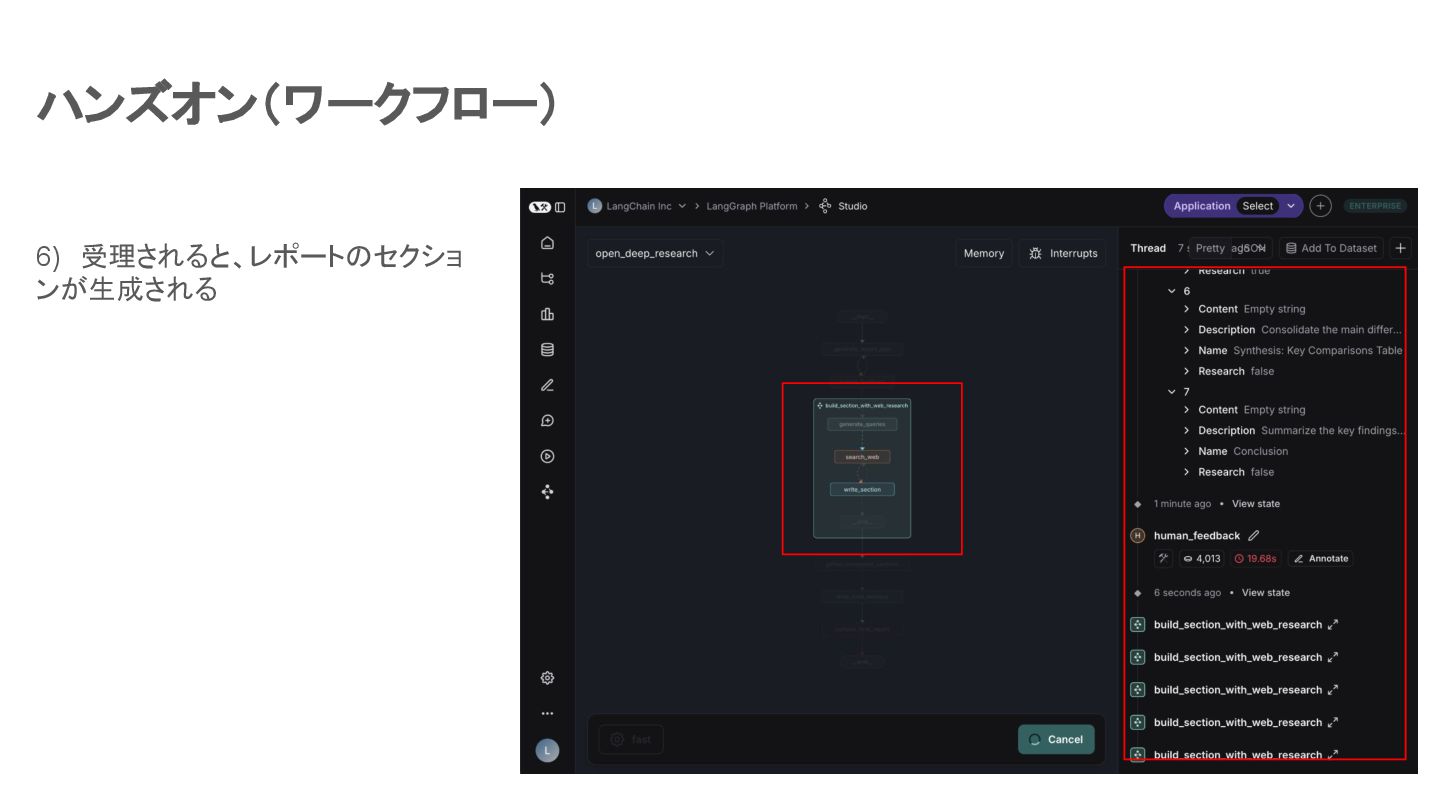
ハンズオン(ワークフロー) 6) 受理されると、レポートのセクショ ンが生成される
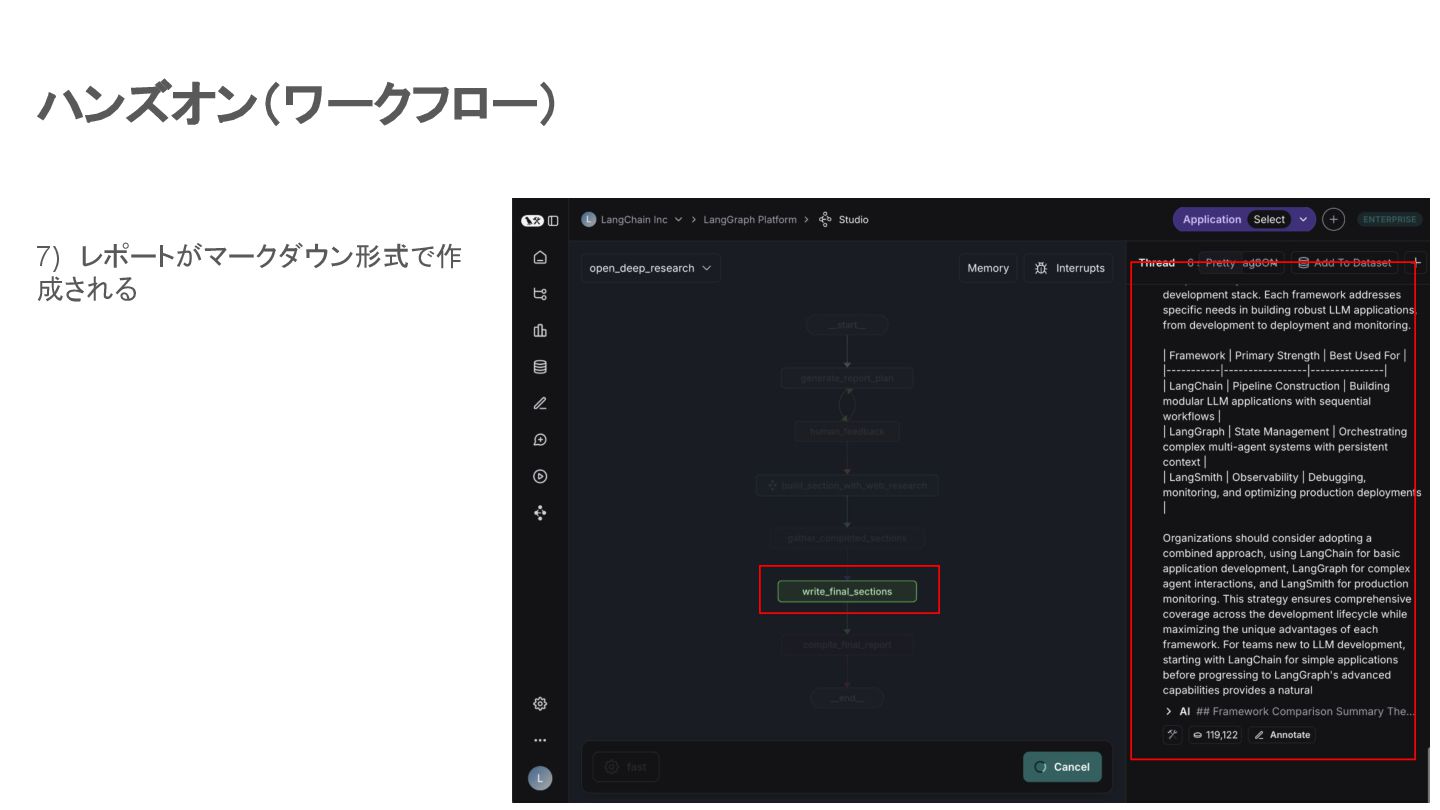
ハンズオン(ワークフロー) 7) レポートがマークダウン形式で作 成される
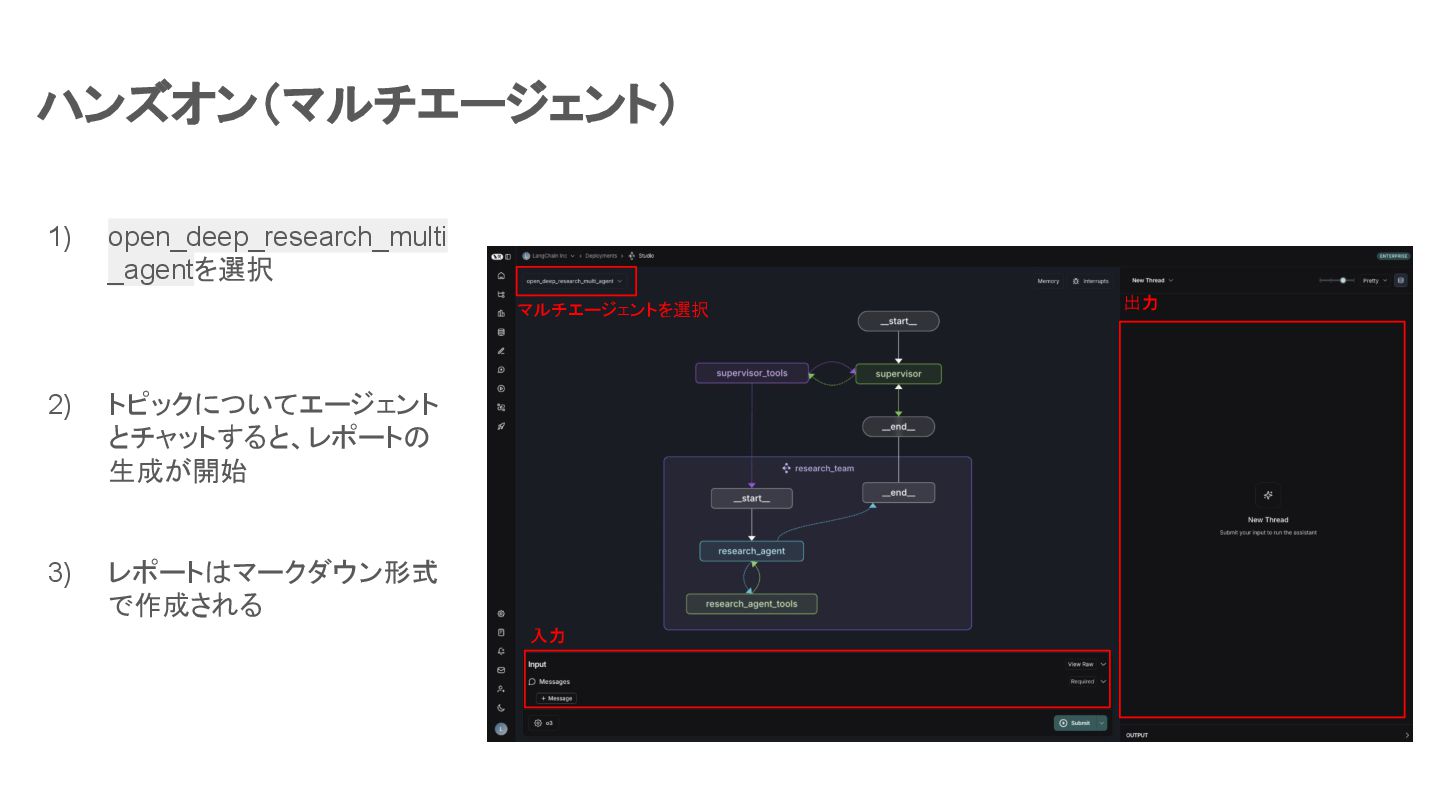
ハンズオン(マルチエージェント) マルチエージェントを選択 入力 出力 1) open_deep_research_multi _agentを選択 2) トピックについてエージェント とチャットすると、レポートの
生成が開始 3) レポートはマークダウン形式 で作成される
振り返り • オープンソースのリサーチアシスタント • 低コストでカスタマイズ性に優れる • 「ワークフロー」では高品質なレポートを生成するのに最適 • 「マルチエージェント」ではレポートを高速に生成するのに最適
参考文献・引用 https://github.com/langchain-ai/open_deep_research?tab=readme-ov-file
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}