Data contains the output of much of the data analysis work used in Google Patents (patents.google.com), including machine translations of titles and abstracts from Google Translate, embedding vectors, extracted top terms, similar documents, and forward references.”
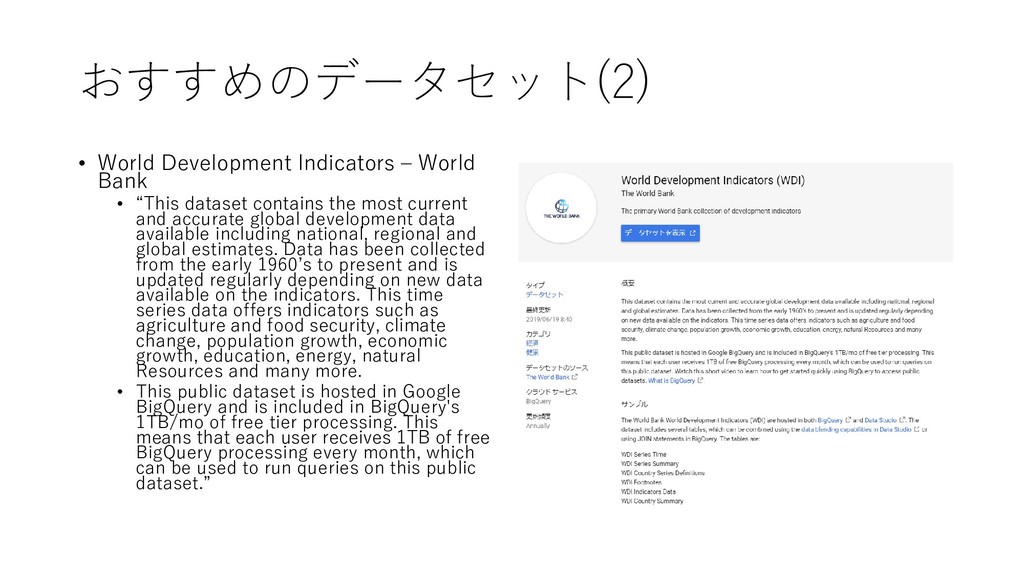
dataset contains the most current and accurate global development data available including national, regional and global estimates. Data has been collected from the early 1960’s to present and is updated regularly depending on new data available on the indicators. This time series data offers indicators such as agriculture and food security, climate change, population growth, economic growth, education, energy, natural Resources and many more. • This public dataset is hosted in Google BigQuery and is included in BigQuery's 1TB/mo of free tier processing. This means that each user receives 1TB of free BigQuery processing every month, which can be used to run queries on this public dataset.”
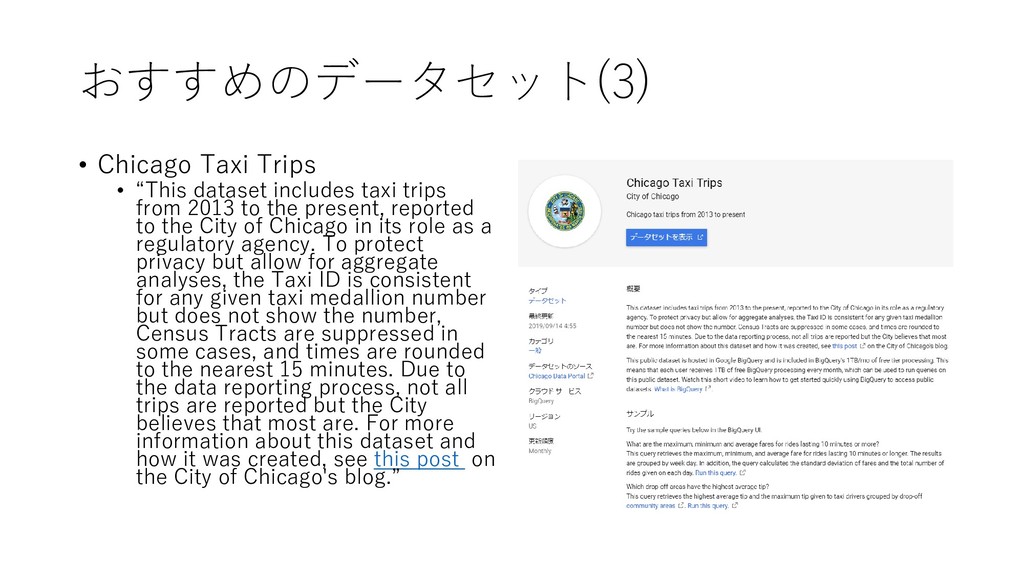
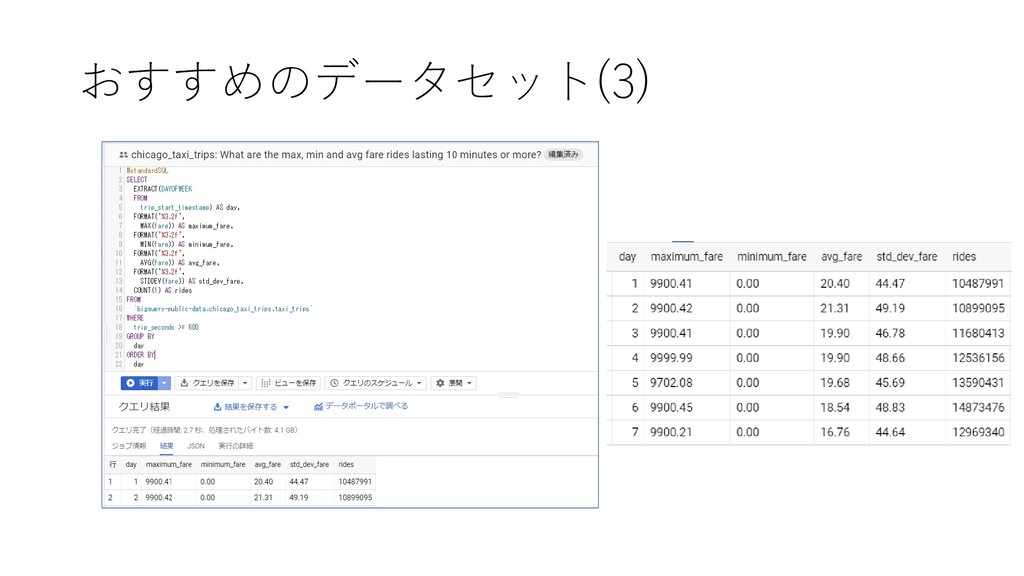
trips from 2013 to the present, reported to the City of Chicago in its role as a regulatory agency. To protect privacy but allow for aggregate analyses, the Taxi ID is consistent for any given taxi medallion number but does not show the number, Census Tracts are suppressed in some cases, and times are rounded to the nearest 15 minutes. Due to the data reporting process, not all trips are reported but the City believes that most are. For more information about this dataset and how it was created, see this post on the City of Chicago's blog.”
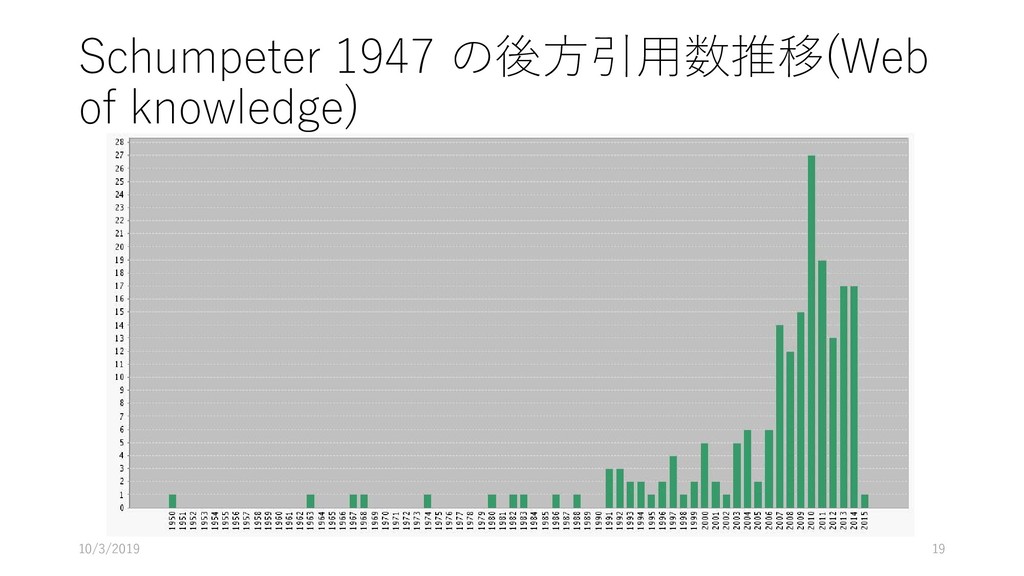
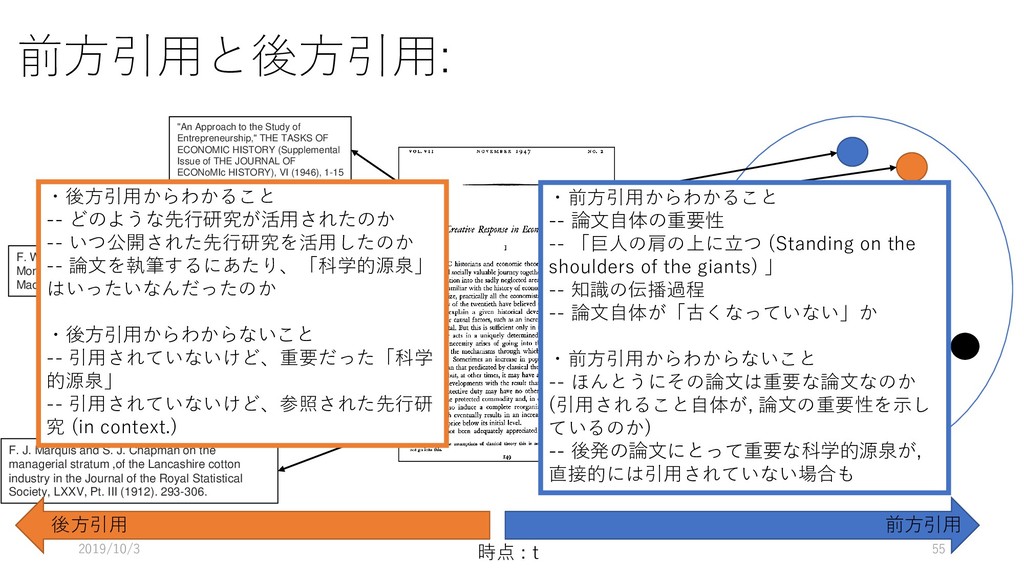
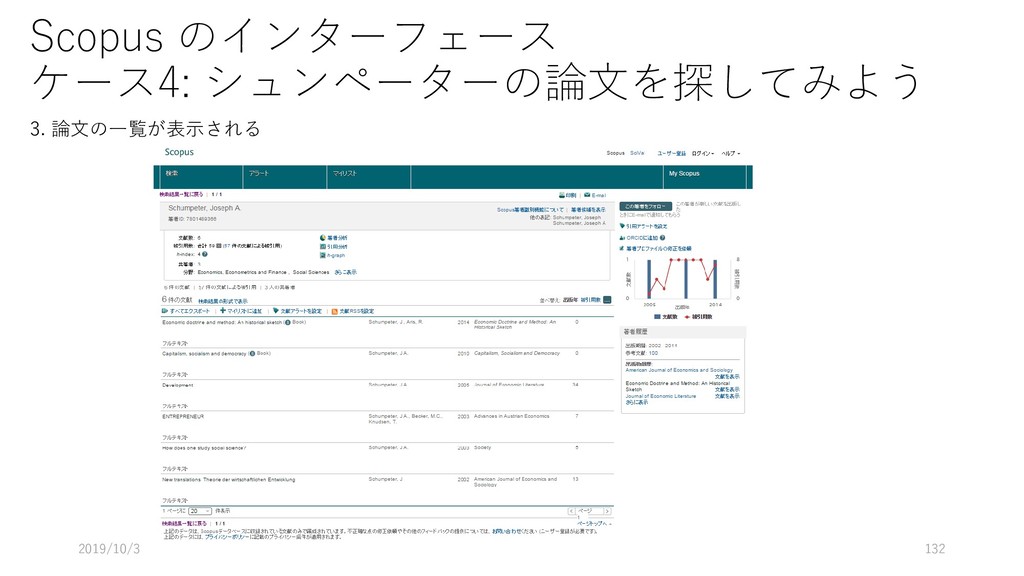
Entrepreneurship," THE TASKS OF ECONOMIC HISTORY (Supplemental Issue of THE JOURNAL OF ECONoMIc HISTORY), VI (1946), 1-15 Oscar Lange, "A Note on Innovations," Review of Economic Statistics, XXV (1943), 19-25 F. W. Taussig, Inventors and Money-Makers (New York: The Macmillan Company, 1915). Fritz Redlich, The Molding of American Banking—Men and Ideas (New York: Hafner Publishing Company, 1947). Robert A. Gordon, Business Leadership in the Large Corporation (Washington, D.C.: The Brookings Institution, 1945). F. J. Marquis and S. J. Chapman on the managerial stratum ,of the Lancashire cotton industry in the Journal of the Royal Statistical Society, LXXV, Pt. III (1912). 293-306. 前方引用 後方引用 ・後方引用からわかること -- どのような先行研究が活用されたのか -- いつ公開された先行研究を活用したのか -- 論文を執筆するにあたり、「科学的源泉」 はいったいなんだったのか ・後方引用からわからないこと -- 引用されていないけど、重要だった「科学 的源泉」 -- 引用されていないけど、参照された先行研 究 (in context.) ・前方引用からわかること -- 論文自体の重要性 -- 「巨人の肩の上に立つ (Standing on the shoulders of the giants) 」 -- 知識の伝播過程 -- 論文自体が「古くなっていない」か ・前方引用からわからないこと -- ほんとうにその論文は重要な論文なのか (引用されること自体が, 論文の重要性を示し ているのか) -- 後発の論文にとって重要な科学的源泉が, 直接的には引用されていない場合も 2019/10/3 55
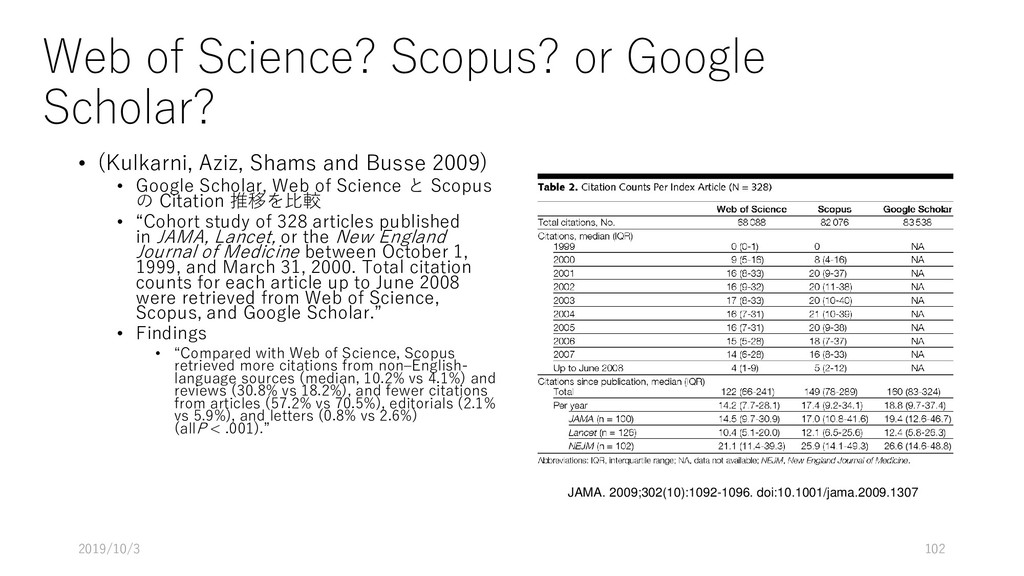
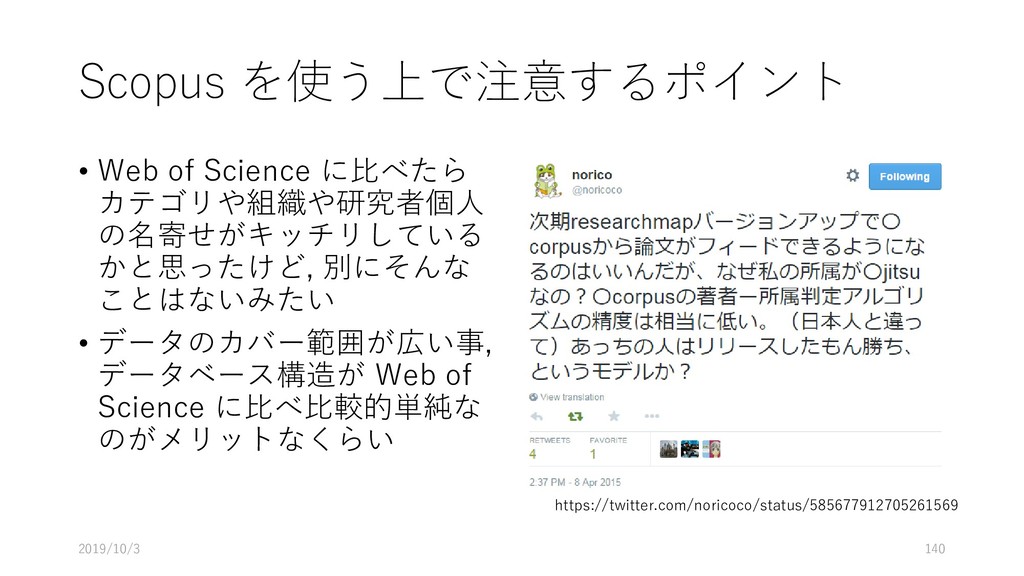
Shams and Busse 2009) • Google Scholar, Web of Science と Scopus の Citation 推移を比較 • “Cohort study of 328 articles published in JAMA, Lancet, or the New England Journal of Medicine between October 1, 1999, and March 31, 2000. Total citation counts for each article up to June 2008 were retrieved from Web of Science, Scopus, and Google Scholar.” • Findings • “Compared with Web of Science, Scopus retrieved more citations from non–English- language sources (median, 10.2% vs 4.1%) and reviews (30.8% vs 18.2%), and fewer citations from articles (57.2% vs 70.5%), editorials (2.1% vs 5.9%), and letters (0.8% vs 2.6%) (allP < .001).” 2019/10/3 102 JAMA. 2009;302(10):1092-1096. doi:10.1001/jama.2009.1307
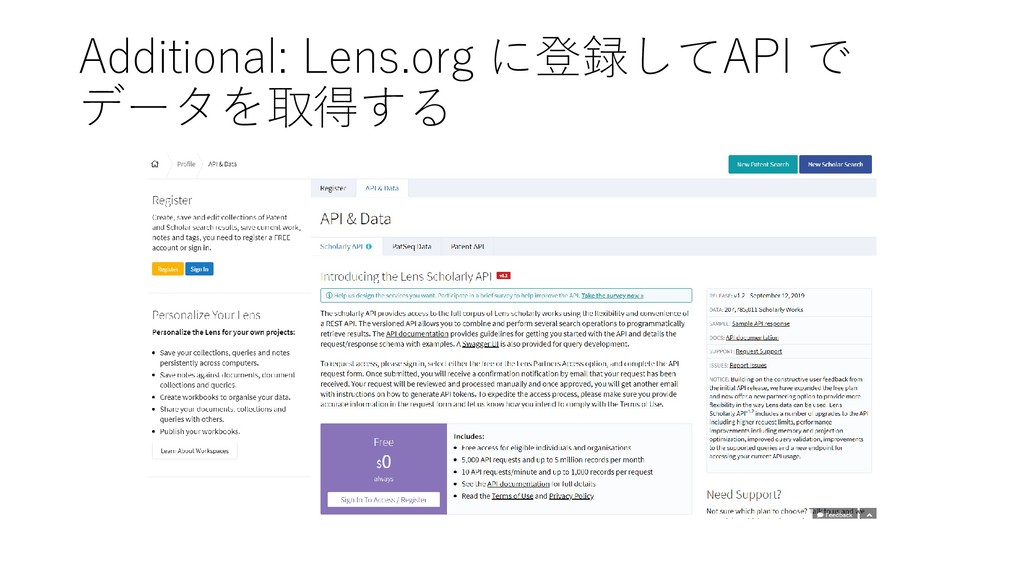
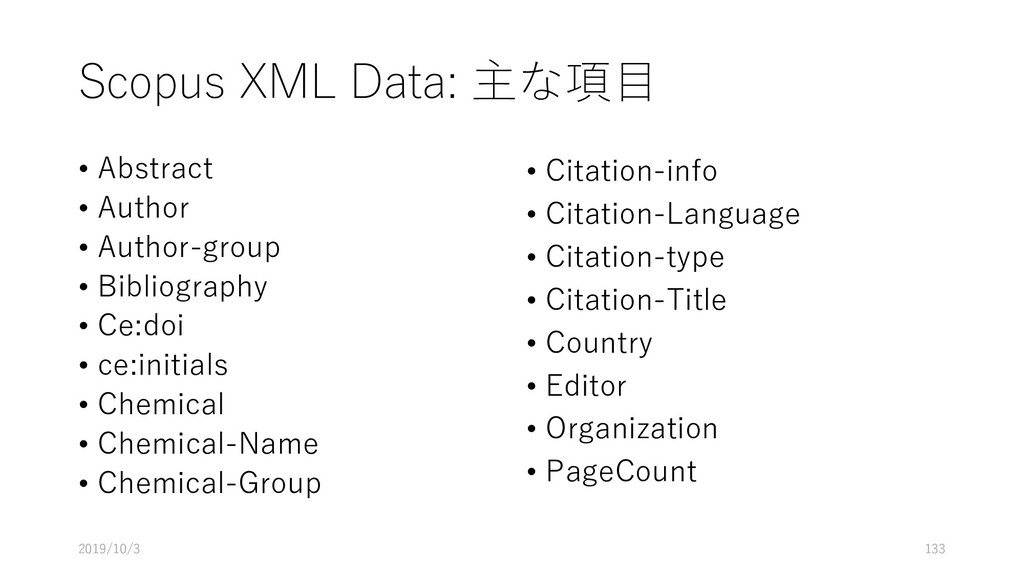
bibliographic data from 1907 - present: 81+ Million documents from nearly 100 jurisdictions. • USPTO Applications from 2001 – present with full text and images. • USPTO Grants from 1976 – present with full text and images. • USPTO Assignments (14+ Million). • European Patent Office (EP) Grants from 1980 – present with full text and images. • WIPO PCT Applications from 1978 – present with full text and images. • Australian Patent Full Text from IP Australia • Paper • PubMed • Crossref • Microsoft Academic • CORE • PubMed Central https://about.lens.org/
![経済学のための実践的 データ分析 3.6. 特許+論文データ を用いた分析 38教室 経済学研究科 原泰史 [email protected]](https://files.speakerdeck.com/presentations/f8a03397d11442baa9bdf9864bc12f78/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
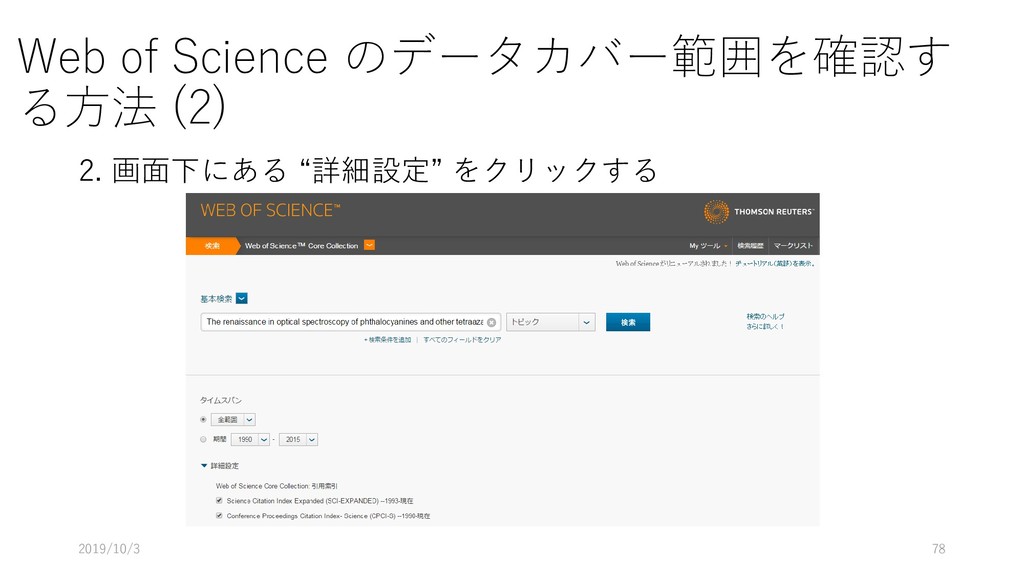
{kind=link}
{kind=link}
{kind=link}
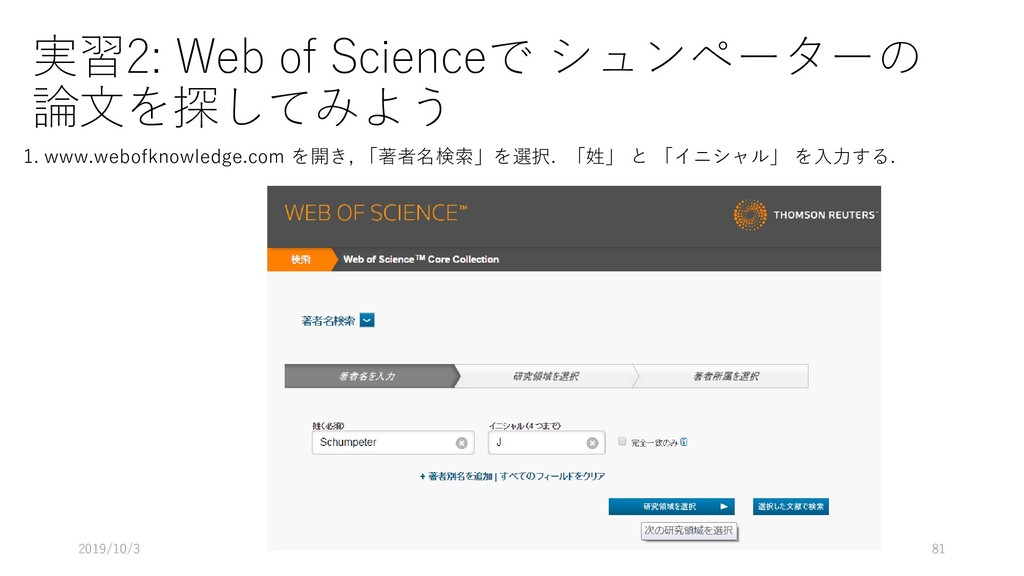
{kind=link}
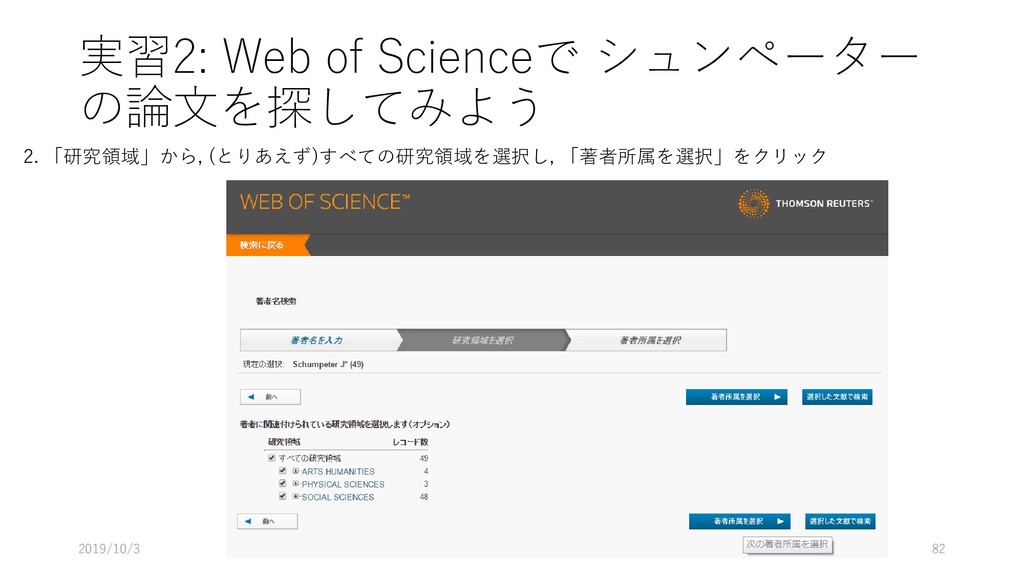
{kind=link}
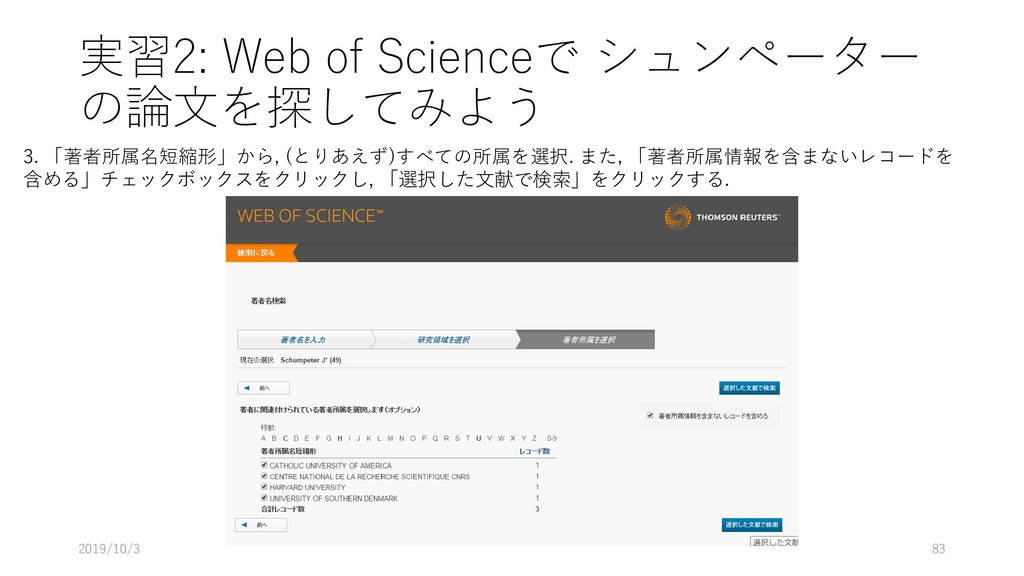
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
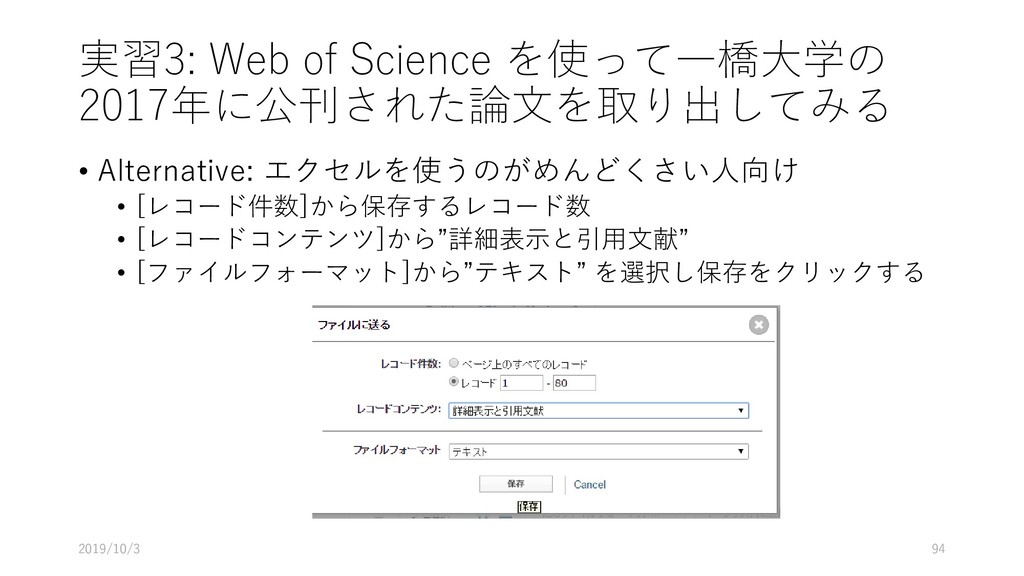
![実習3: Web of Science を使って一橋大学の 2017年に公刊された論文を取り出してみる • [レコード件数]から保存するレコード数 • [レコードコンテンツ]から”詳細表示と引用文献”](https://files.speakerdeck.com/presentations/f8a03397d11442baa9bdf9864bc12f78/slide_91.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![7.データベースを用いた分析(3) 企業データ ベース/データベース間の接合[座学、実習] • 帝国データバンク企業・経済高度実証研究センター (http://www7.econ.hit-u.ac.jp/tdb-caree/about-caree/) が提供 する企業のデータベースについて説明を行います。本データベース には、企業の取引、出資、銀行取引データや、決算書データなどが 含まれています。こうしたデータセットに基づき、前二回同様、問](https://files.speakerdeck.com/presentations/f8a03397d11442baa9bdf9864bc12f78/slide_124.jpg){kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/f8a03397d11442baa9bdf9864bc12f78/slide_127.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/f8a03397d11442baa9bdf9864bc12f78/slide_144.jpg){kind=link}