OF TECHNOLOGY • 2000 • Exchange Student in Malaysia • 2002-2009 • CLARAONLINE, INC. • ICT Hosting Company, nowadays called Cloud system supplier • 2009-2015 • Institute of Innovation Research, HITOTSUBASHI UNIVERSITY • 2015-2017 • Science for RE-Designing Science, Technology and Innovation Policy Center, National Graduate Institute for Policy Studies (GRIPS) / NISTEP / Hitotsubashi UNIVERSITY/MANAGEMENT INNOVATION CENTER • 2018-2019 • EHESS Paris – CEAFJP/Michelin Research Fellow • OECD Expert Advisory Group: Digital Science and Innovation Policy and Governance (DSIP) and STI Policy Monitoring and Analysis (REITER) project • 2019- • TDB Center for Advanced Empirical Research on Enterprise and Economy, Faculty of Economics, Hitotsubashi University
Economi c Factors Non-Knowledge Factors of Production Output: Productivity Firm’s Value Patent Patenting Propensity Inputs to Innovation R&D, designing, marketing research etc… Knowhow and First Mover Advantag Paper 3/8/2015 6
Other Economi c Factors Non-Knowledge Factors of Production Output: Productivity Firm’s Value Paten t Patenting Propensity Inputs to Innovation R&D, designing, marketing research etc… Knowhow and First Mover Advantag Paper In- tangible knowledg e 3/8/2015 7
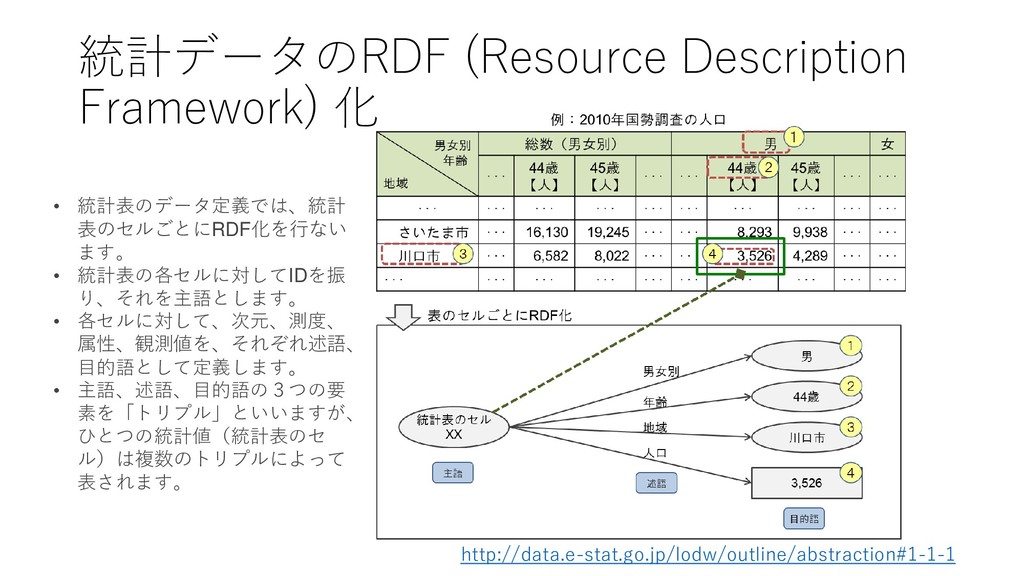
format) but with an open licence, to be Open Data ★★ Available as machine-readable structured data (e.g. excel instead of image scan of a table) ★★★ as (2) plus non-proprietary format (e.g. CSV instead of excel) ★★★★ All the above plus, Use open standards from W3C (RDF and SPARQL) to identify things, so that people can point at your stuff ★★★★★ All the above, plus: Link your data to other people’s data to provide context https://www.w3.org/DesignIssues/LinkedData.html https://5stardata.info/ja/
Data is such a dataset that is openly available for anyone to use for non-commercial research. The data was produced as a joint effort by the Institute for Geoinformatics, University of Muenster, Germany and the National Institute for Space Research (INPE) in Brazil. • The data can be accessed in a Linked Data fashion via a SPARQL-endpoint, and via dereferenciable URIs. The data consists of 8250 cells—each of size of 25 km * 25 km—capturing the observations of deforestation in the Brazilian Amazon Rainforest and a number of related and relevant variables. This spatiotemporal deforestation data was created using a number of aggregation methods from different sources. The data covers the whole Brazilian Amazon Rainforest. http://linkedscience.org/data/linked-brazilian-amazon-rainforest/
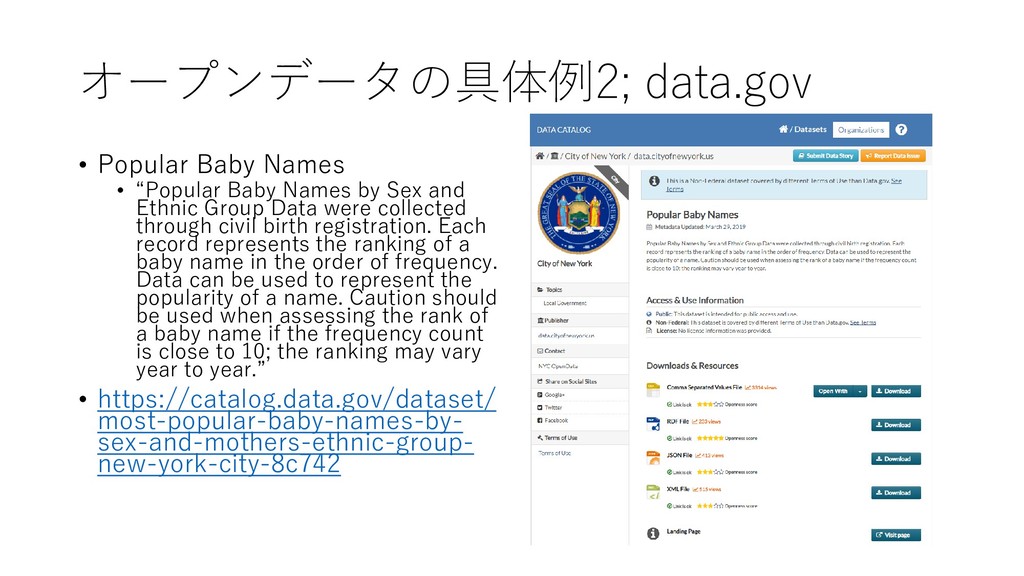
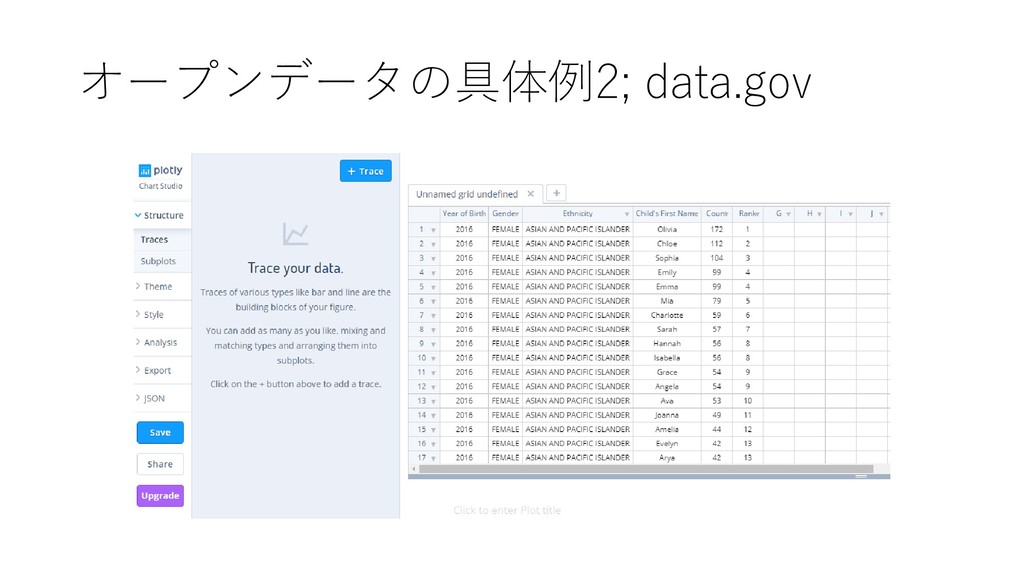
by Sex and Ethnic Group Data were collected through civil birth registration. Each record represents the ranking of a baby name in the order of frequency. Data can be used to represent the popularity of a name. Caution should be used when assessing the rank of a baby name if the frequency count is close to 10; the ranking may vary year to year.” • https://catalog.data.gov/dataset/ most-popular-baby-names-by- sex-and-mothers-ethnic-group- new-york-city-8c742
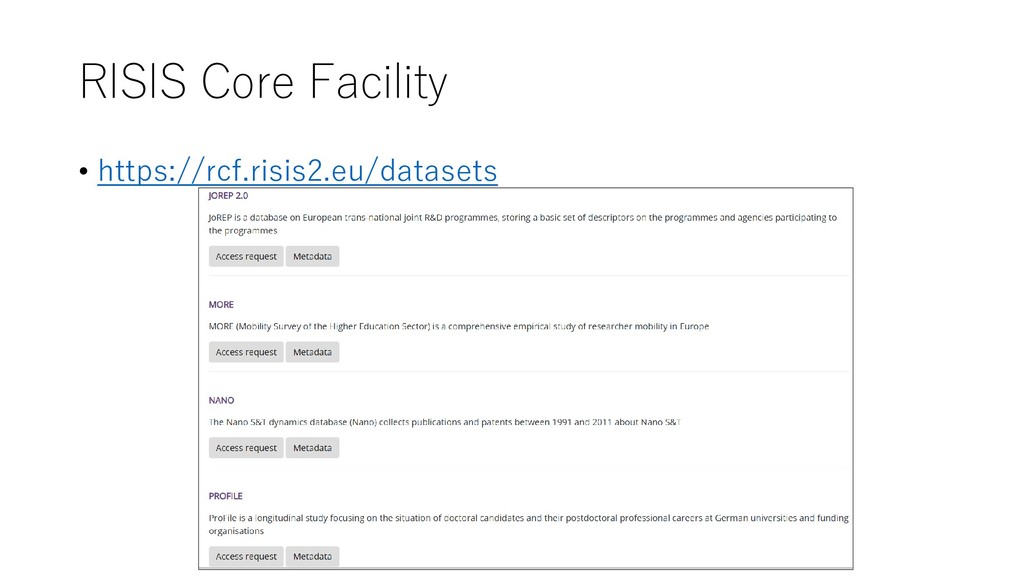
RISIS CORE FACILITY (RCF), is organised around 3 major dimensions and activities: • 1. A front end, focusing on users, the ways they access RISIS, work within RISIS and build RISIS user communities. At the core is the RISIS Core facility (WP4). The core facility supports virtual transnational access (WP8) and is accompanied by all the efforts we do to raise awareness, train researchers and interact with them (WP2) and to help them build active user communities (mobilising D4Science VRE, WP7). • 2. A service layer that helps users organise problem based integration of RISIS datasets (with possibilities to complement with their own datasets) – this entails the data integration and analysis services (WP5) and methodological support for advanced quantitative methods (WP6). • 3. A data layer that gathers the core RISIS datasets that we maintain (WP5) and enlarge (WP9), the datasets of interest for which we insure reliability and harmonisation for integration (WP4), and the new datasets that we develop and will progressively open (WP10). https://www.risis2.eu/project-description/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Framework of Innovation Indicators [modified.] (Pakes and Griliches 1984) Other](https://files.speakerdeck.com/presentations/5769c6758cee41d8b75356cded2a863c/slide_5.jpg){kind=link}
![Framework of Innovation Indicators [modified. 2] (Pakes and Griliches 1984)](https://files.speakerdeck.com/presentations/5769c6758cee41d8b75356cded2a863c/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Jupyter Notebook のインストール(1) • 2. [Download] をクリックする](https://files.speakerdeck.com/presentations/5769c6758cee41d8b75356cded2a863c/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3-2. 新しいnotebook を作成する • [ファイル]-[python3 の新しいノートブック] を選択する](https://files.speakerdeck.com/presentations/5769c6758cee41d8b75356cded2a863c/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
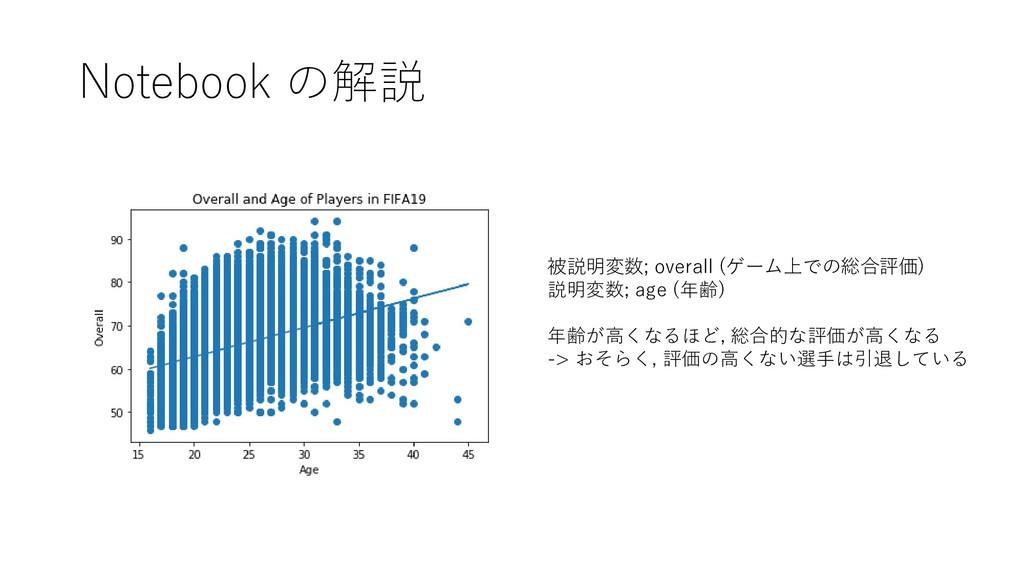
![Notebook の解説 やっていること ・説明変数と被説明変数をそれぞれの列か ら取り出す (.iloc [行, 列]で, 行を指定せず 列のみを指定する)](https://files.speakerdeck.com/presentations/5769c6758cee41d8b75356cded2a863c/slide_76.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
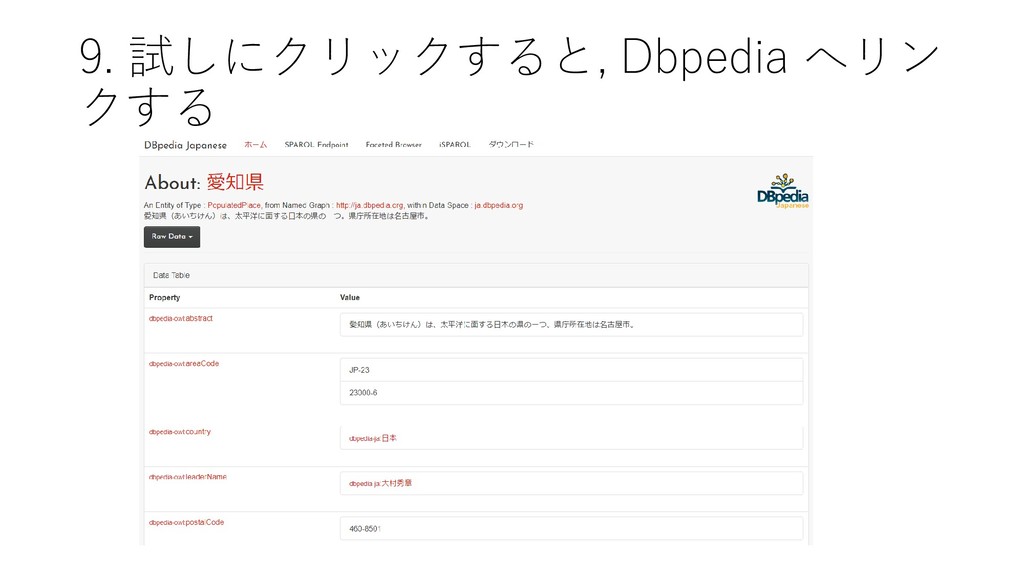{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/5769c6758cee41d8b75356cded2a863c/slide_154.jpg){kind=link}