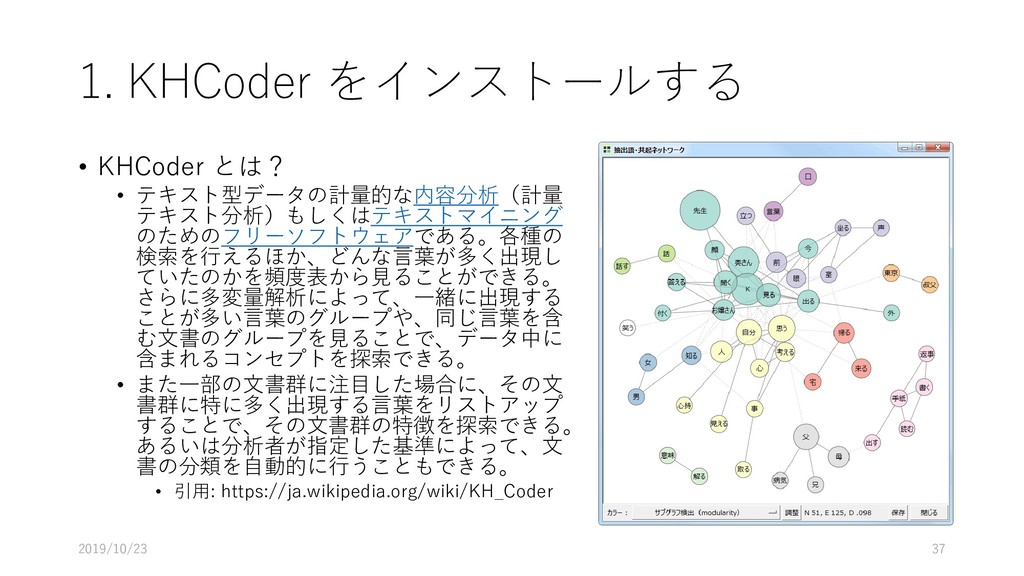
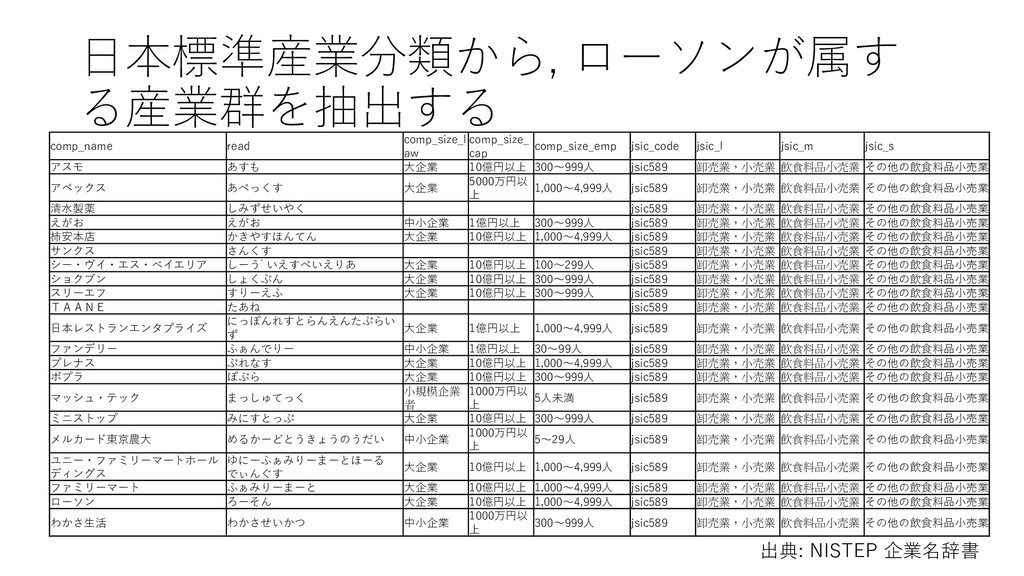
• D. 建設業 • E. 製造業 • F. 電気・ガス・熱供給・水道業 • G. 情報通信業 • H. 運輸業,郵便業 • I. 卸売業,小売業 • J. 金融業,保険業 • K. 不動産業,物品賃貸業 • L. 学術研究,専門・技術サービス業 • M. 宿泊業,飲食サービス業 • N. 生活関連サービス業,娯楽業 • O. 教育,学習支援業 • P. 医療,福祉 • Q. 複合サービス事業 • R. サービス業(他に分類されないもの) • S. 公務(他に分類されるものを除く) • T. 分類不能の産業 http://www.soumu.go.jp/toukei_toukatsu/index/seido/ sangyo/02toukatsu01_03000022.html
Research Data contains the output of much of the data analysis work used in Google Patents (patents.google.com), including machine translations of titles and abstracts from Google Translate, embedding vectors, extracted top terms, similar documents, and forward references.”
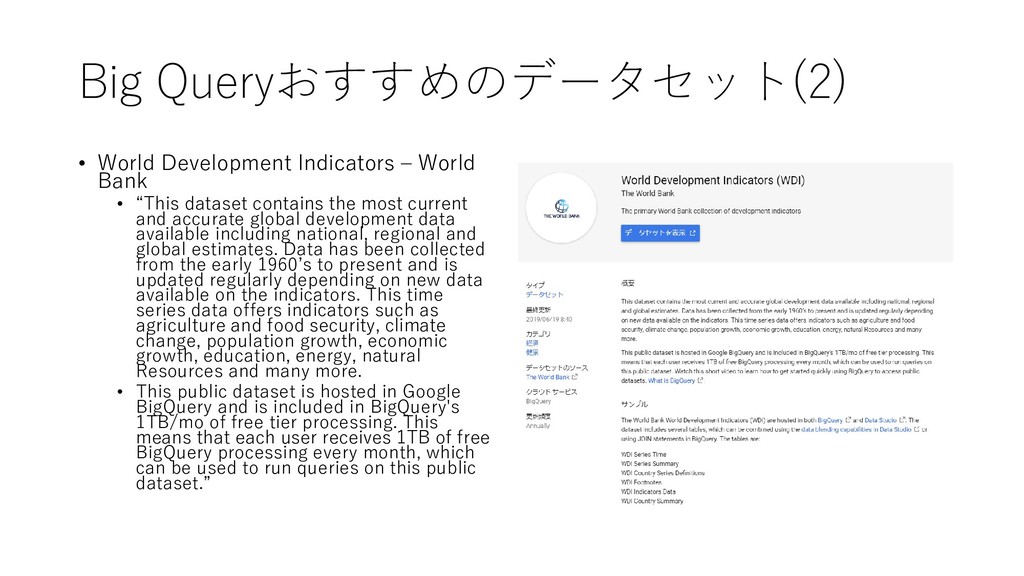
“This dataset contains the most current and accurate global development data available including national, regional and global estimates. Data has been collected from the early 1960’s to present and is updated regularly depending on new data available on the indicators. This time series data offers indicators such as agriculture and food security, climate change, population growth, economic growth, education, energy, natural Resources and many more. • This public dataset is hosted in Google BigQuery and is included in BigQuery's 1TB/mo of free tier processing. This means that each user receives 1TB of free BigQuery processing every month, which can be used to run queries on this public dataset.”
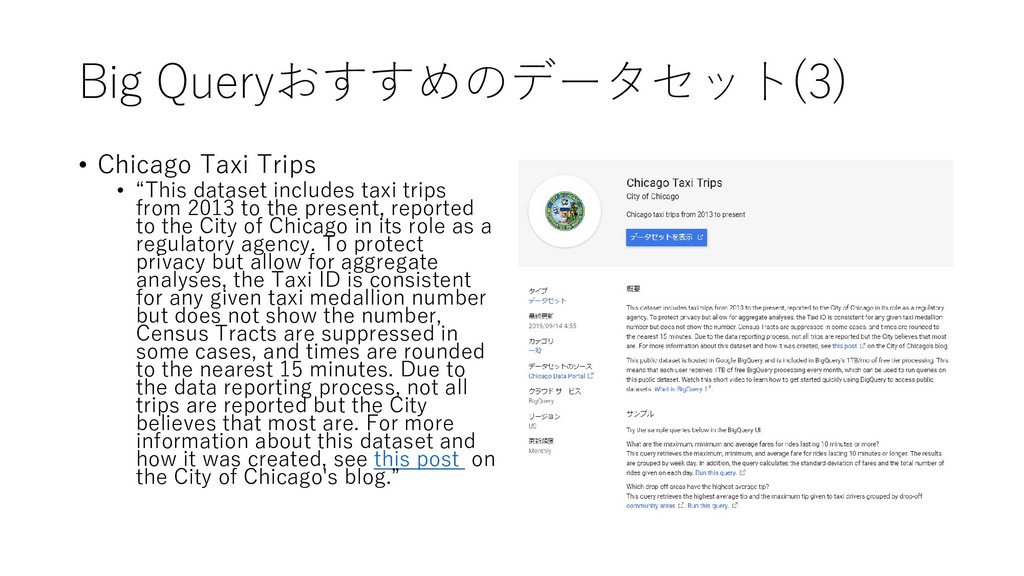
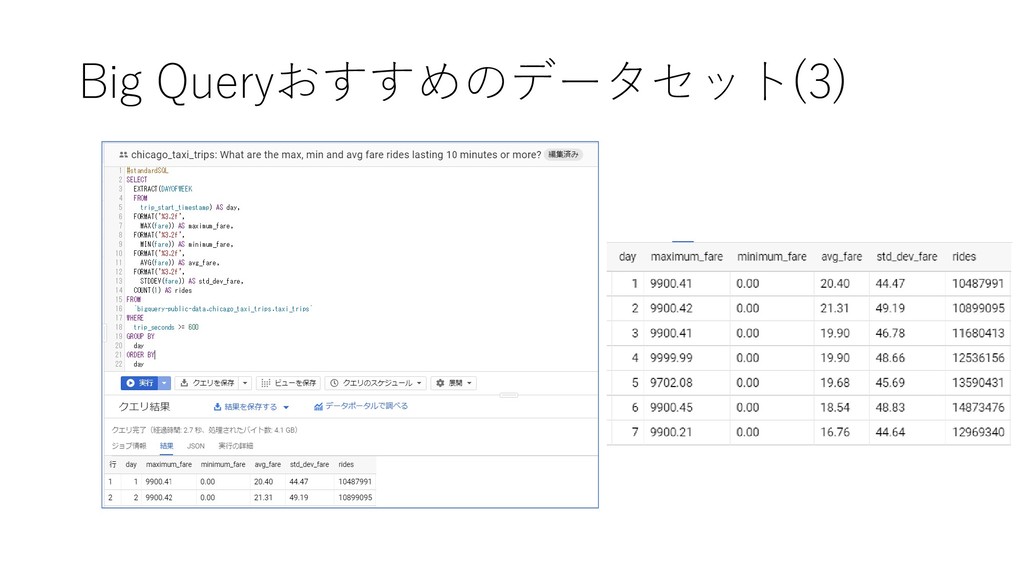
taxi trips from 2013 to the present, reported to the City of Chicago in its role as a regulatory agency. To protect privacy but allow for aggregate analyses, the Taxi ID is consistent for any given taxi medallion number but does not show the number, Census Tracts are suppressed in some cases, and times are rounded to the nearest 15 minutes. Due to the data reporting process, not all trips are reported but the City believes that most are. For more information about this dataset and how it was created, see this post on the City of Chicago's blog.”
![経済学のための 実践的データ分析 3.10. テキスト分析 (後半) 38教室 一橋大学 経済学研究科 原泰史 [email protected]](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
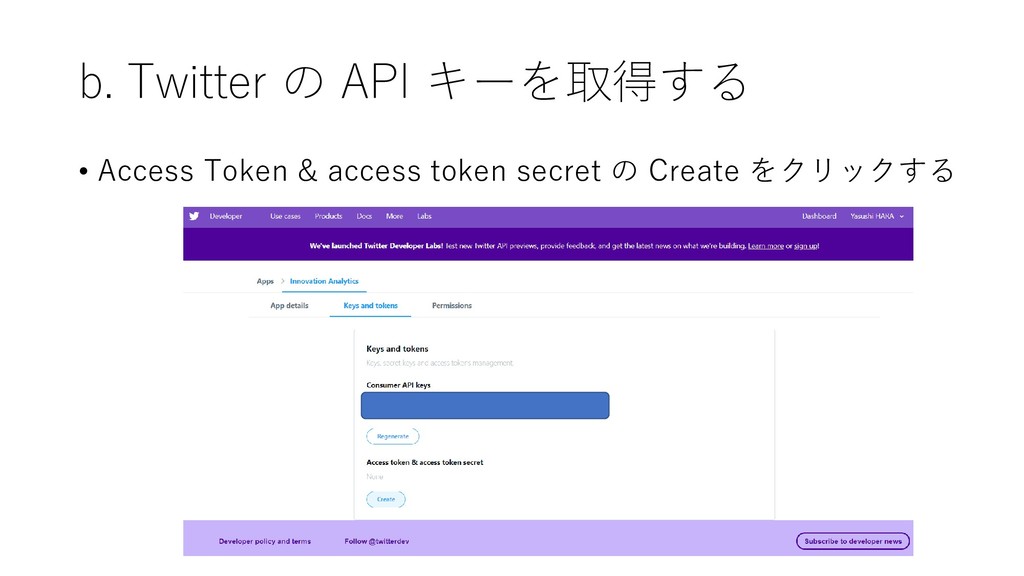{kind=link}
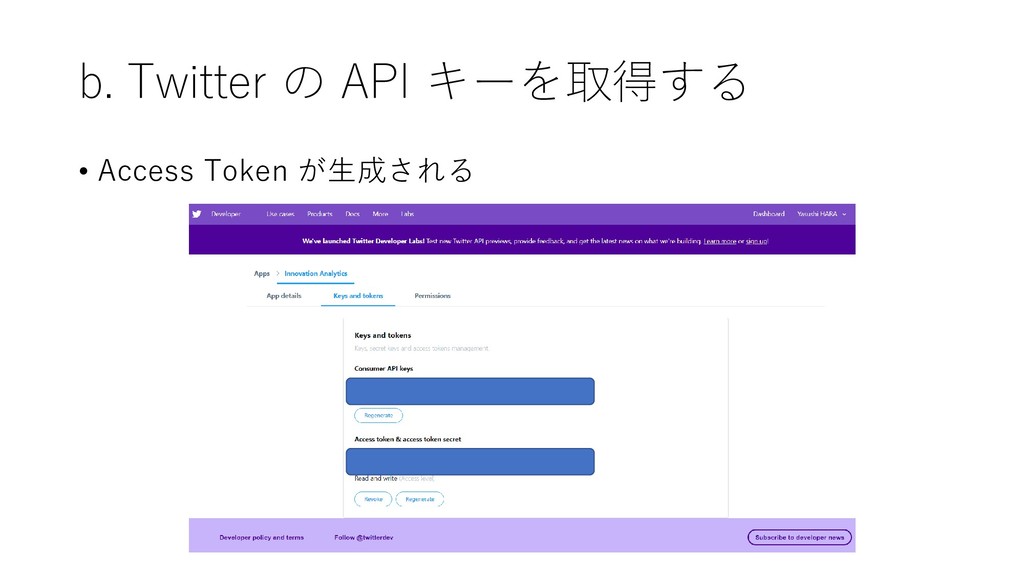{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
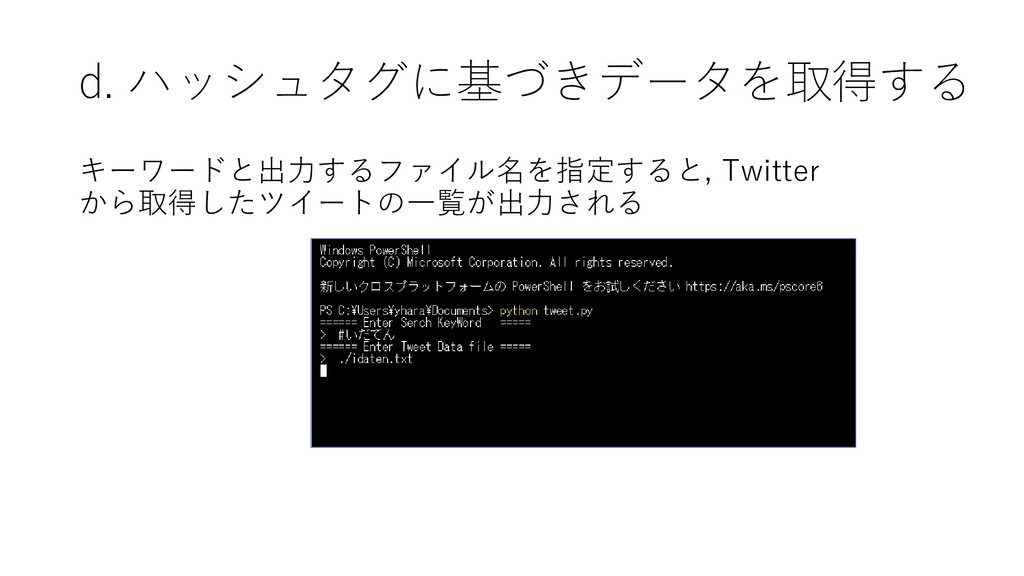{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3. KHCoder に定点調査の自由記述データ を読み込む • KHCoder を開く • [プロジェクト] –[新規]](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_48.jpg){kind=link}
![3. KHCoder にデータを読み込む • [参照]をクリックして, 分析対 象ファイルを選ぶ • 分析対象とする列について[詳 細]](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_49.jpg){kind=link}
![4. データ分析前の処理をする • [前処理] – [テキストのチェッ ク]をクリックする • OKをクリックする 2019/10/23](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_50.jpg){kind=link}
![4. データ分析前の処理をする • 修正が必要である旨メッセージが表示される • [画面に表示] をクリックして, 問題点をチェックする • “テキストの自動修正”](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_51.jpg){kind=link}
![4. データ分析前の処理をする • 問題点が修正される. • [閉じる]をクリックする. 2019/10/23 53](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_52.jpg){kind=link}
![4. データ分析前の処理をする • [前処理] – [前処理の実行] を選択する • OKをクリックする 2019/10/23](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_53.jpg){kind=link}
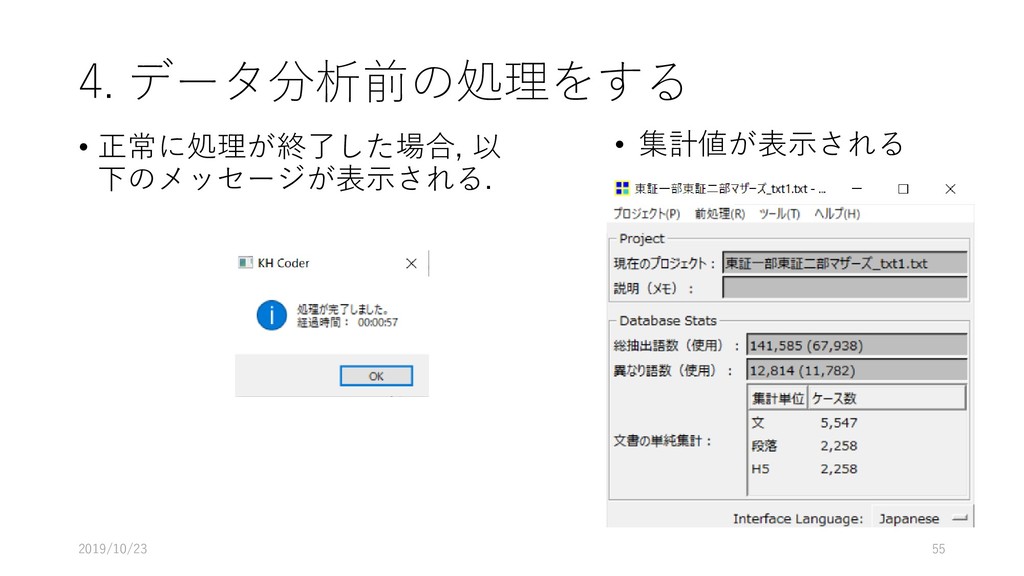{kind=link}
![4. データ分析前の処理をする • 複合語の検出を行う • [前処理]-[複合語の検出]-[茶筌 を利用]をクリックする](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_55.jpg){kind=link}
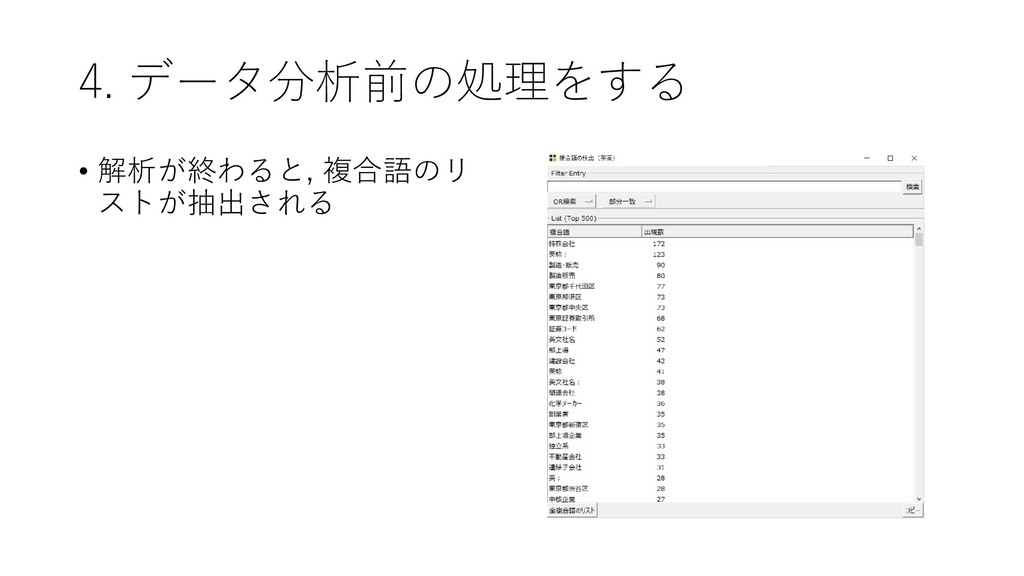{kind=link}
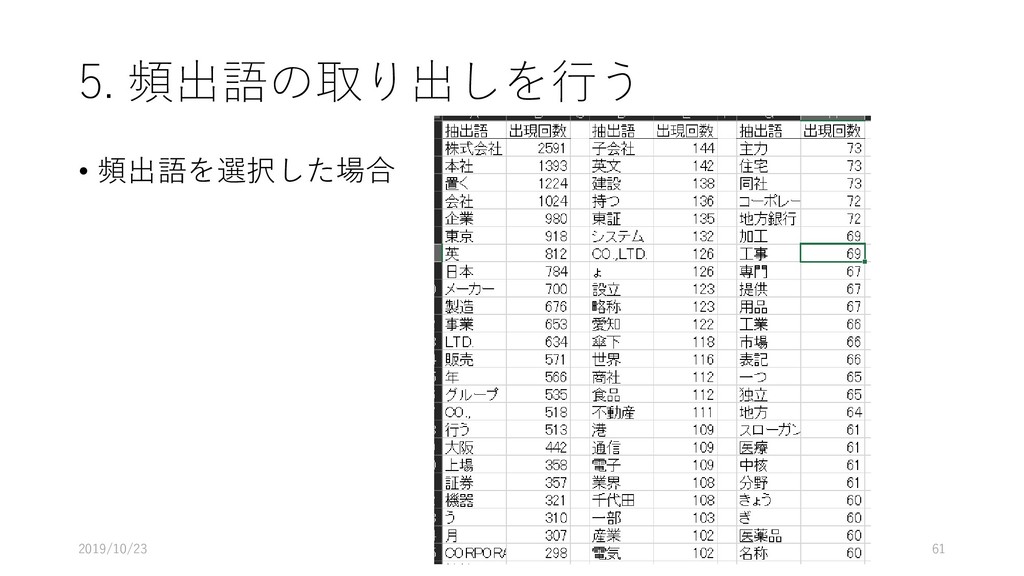
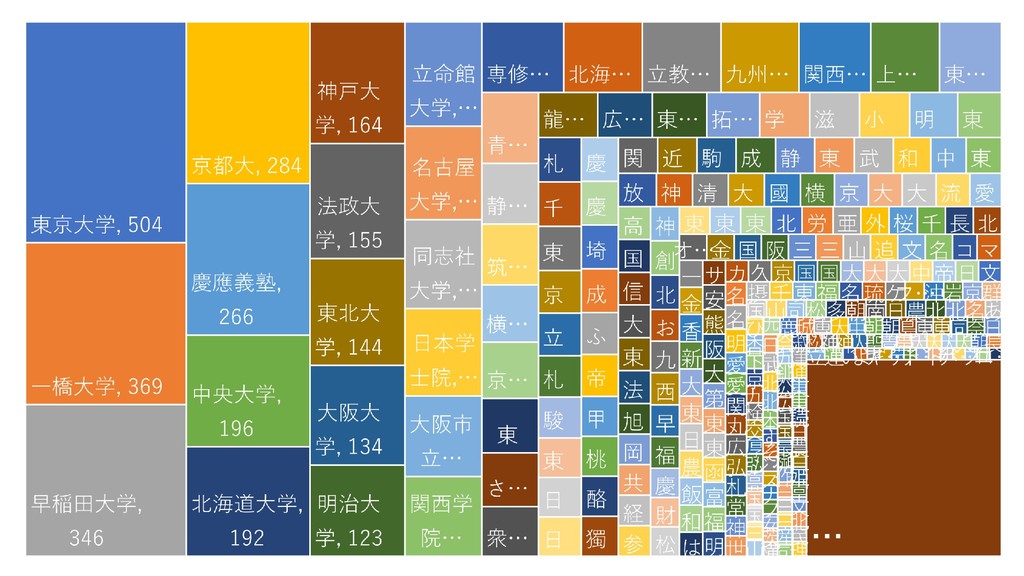
![5. 頻出語の取り出しを行う • [ツール]-[抽出語]-[抽出語 リスト(Excel)]を選択する 2019/10/23 58](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_57.jpg){kind=link}
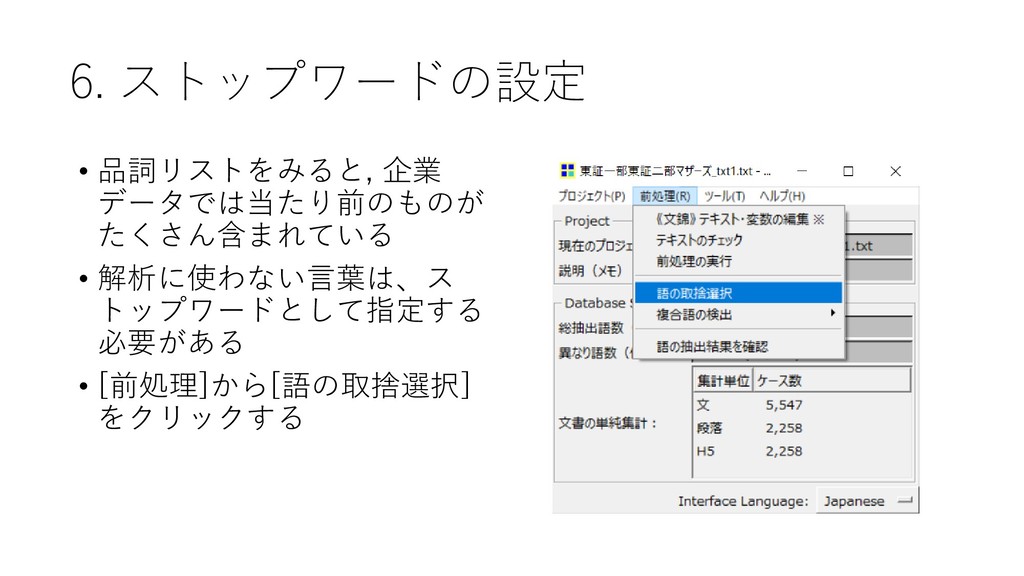
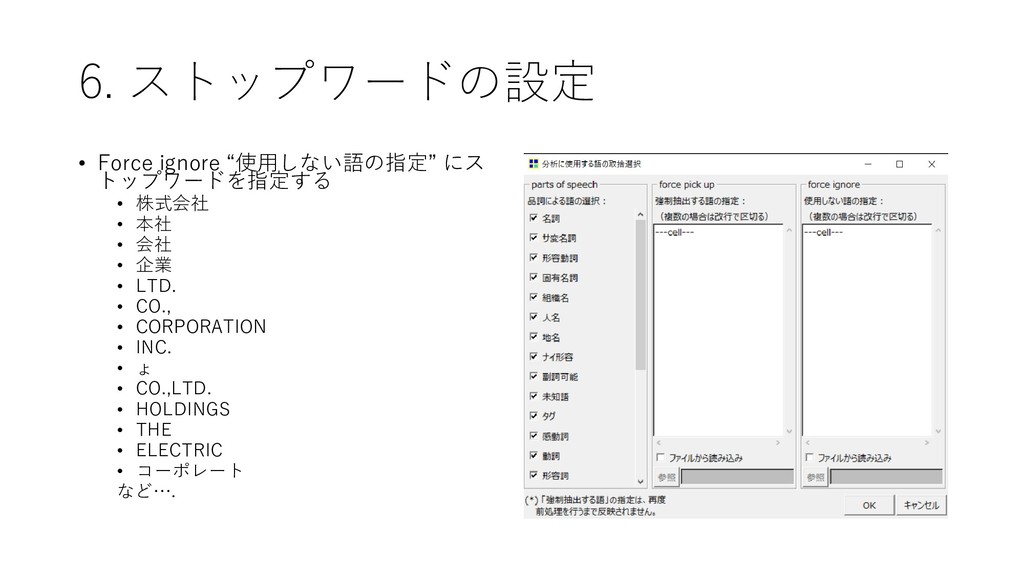
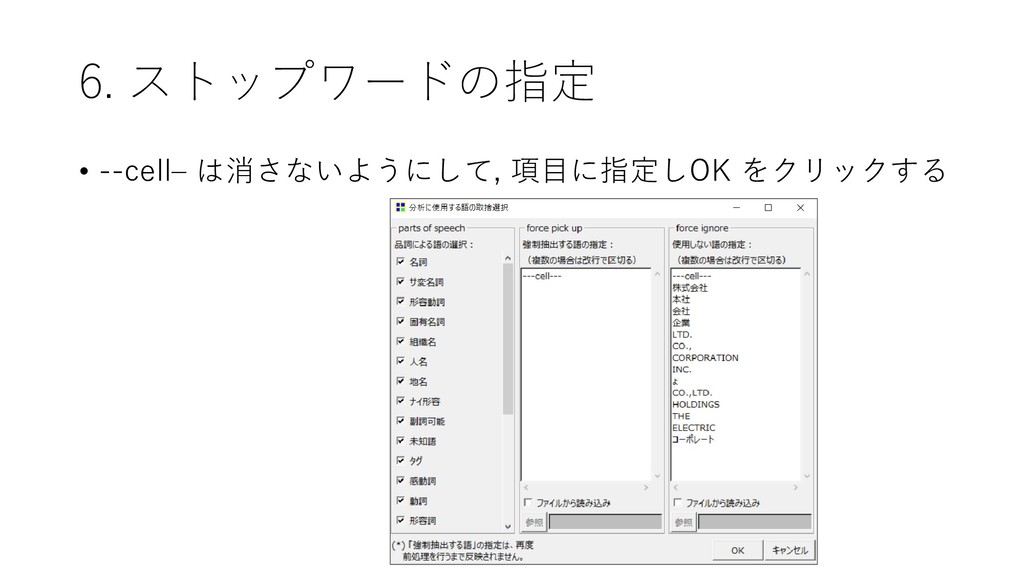
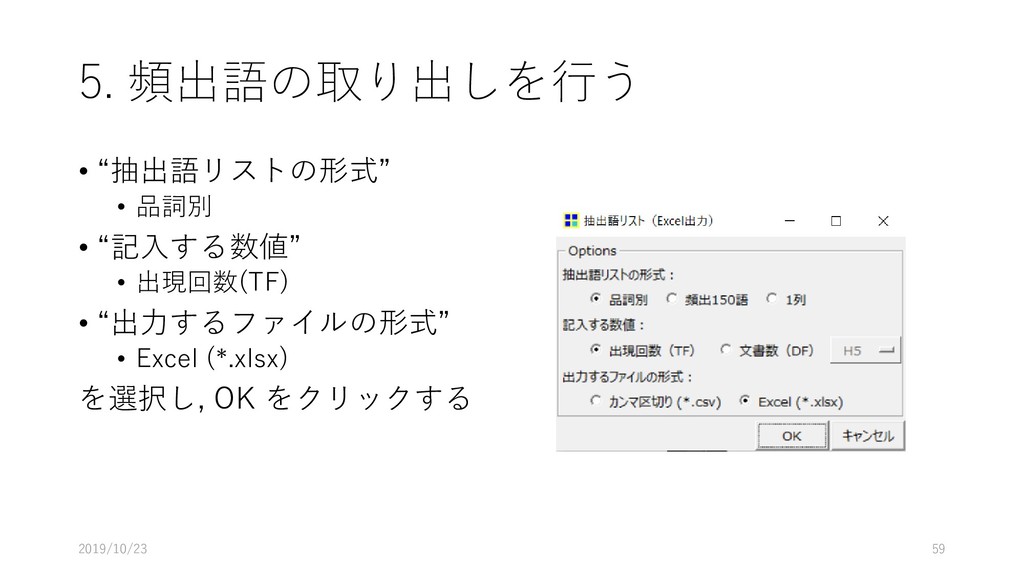{kind=link}
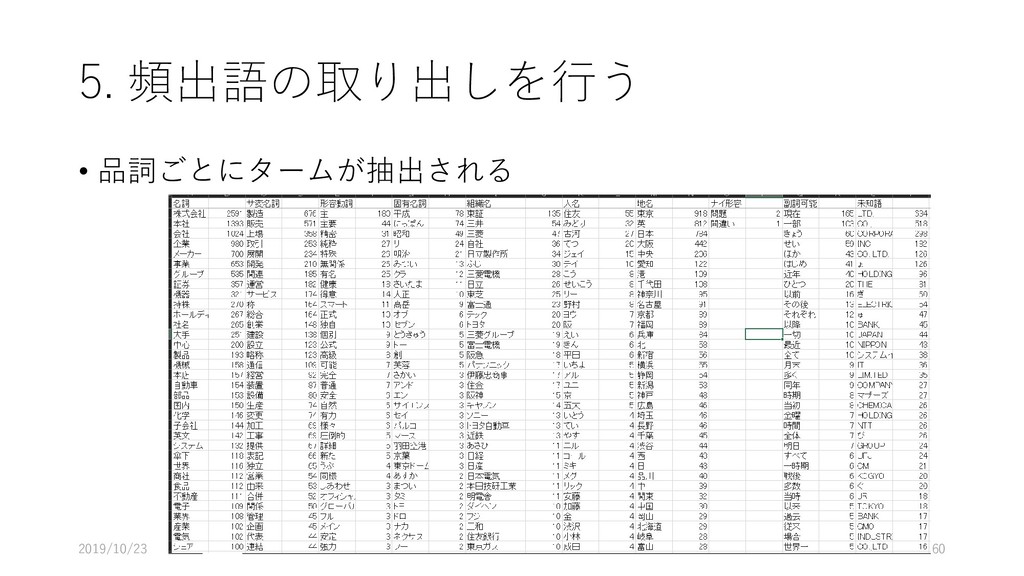{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
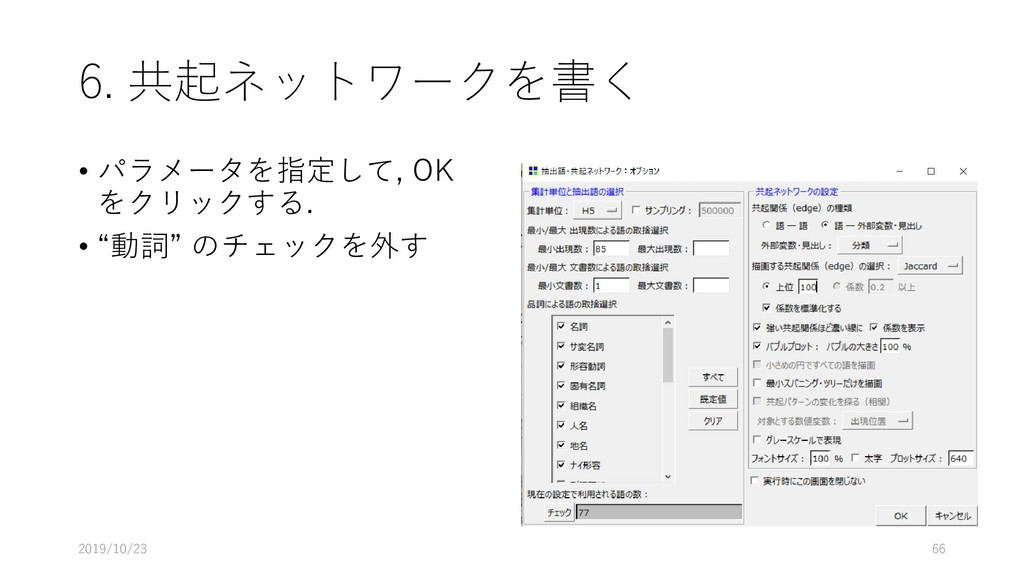
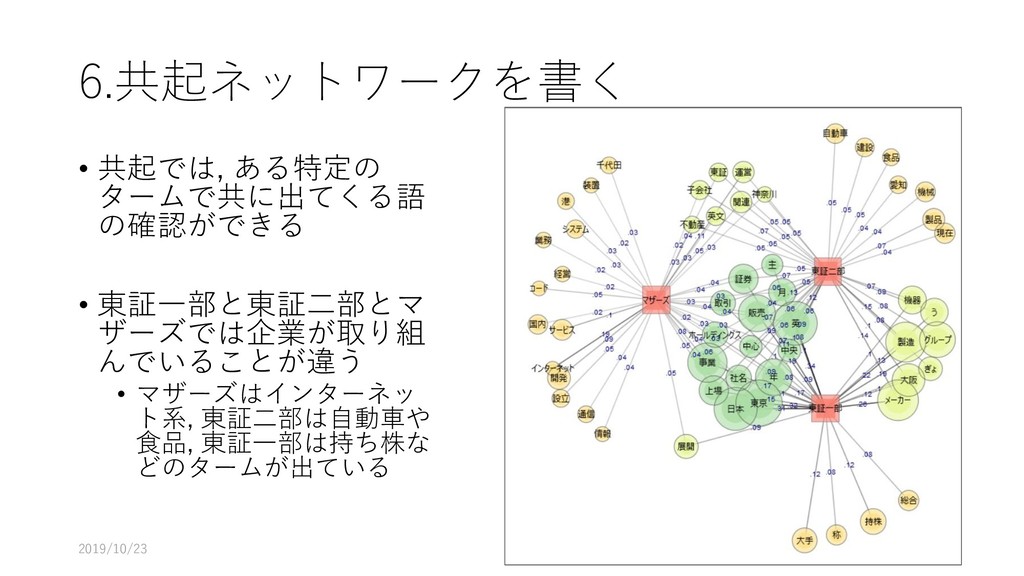
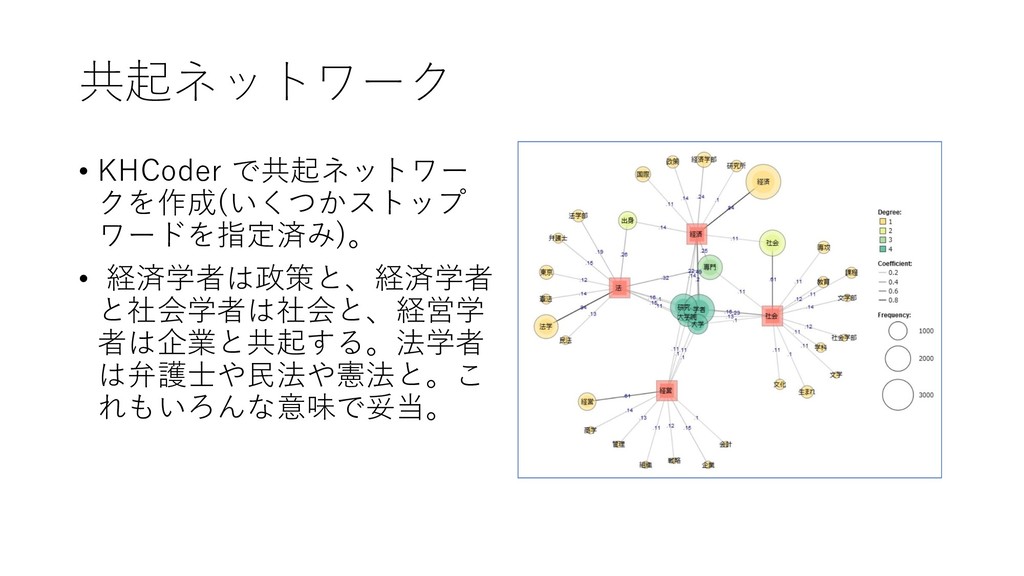
![6. 共起ネットワークを書く • [ツール]-[抽出語]-[共起 ネットワーク]を選択する 2019/10/23 65](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_64.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
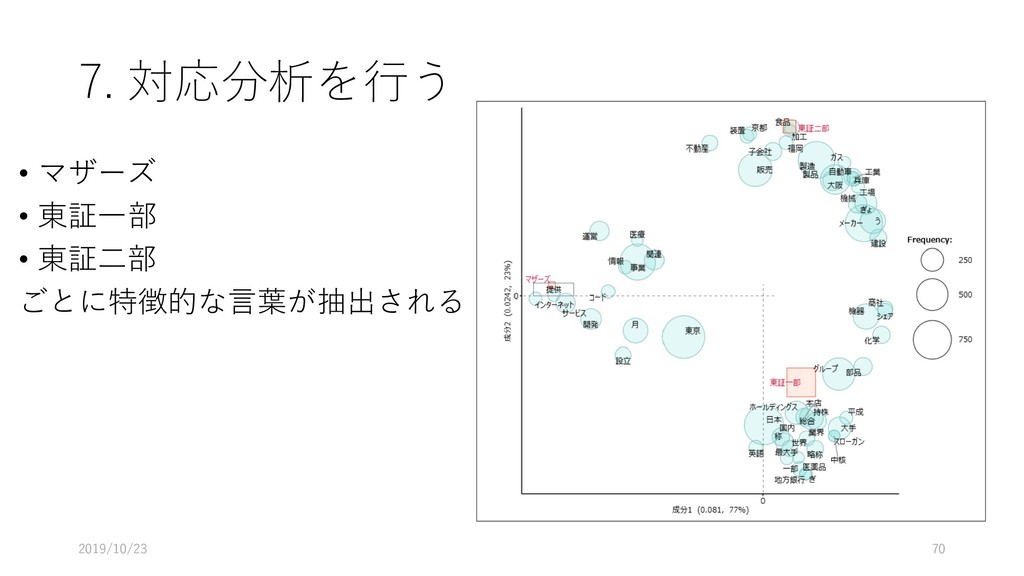{kind=link}
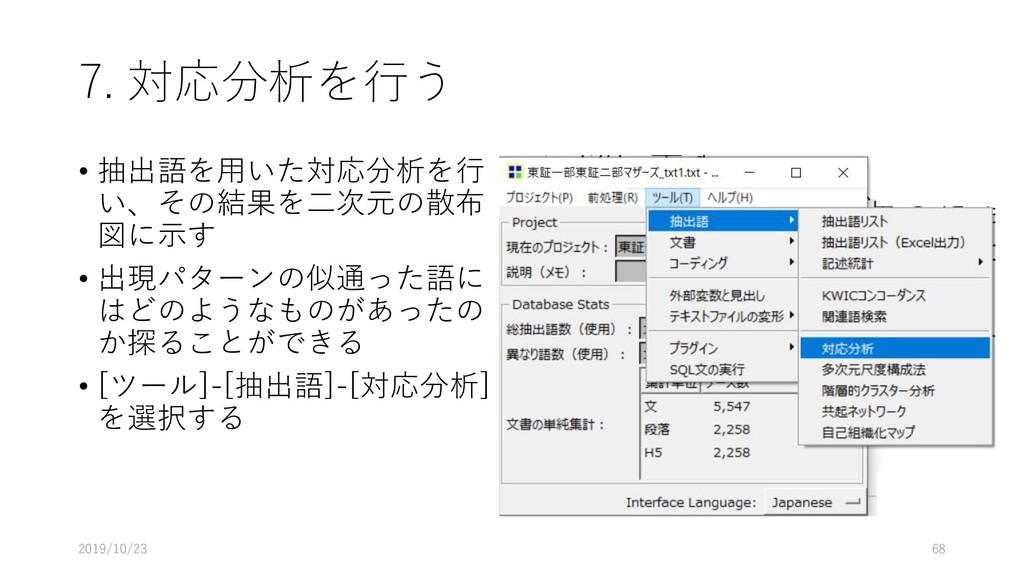
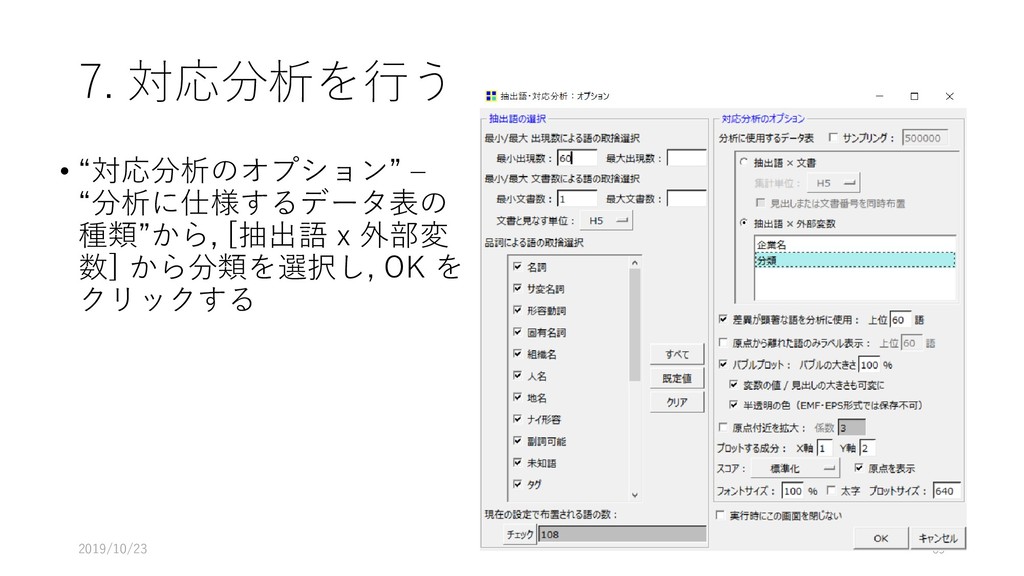
![8. 多次元尺度構成法で解析する • 近接している語のパターンを 解析できる • [ツール]-[抽出語]-[多次元尺 度構成法]を選択する](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_70.jpg){kind=link}
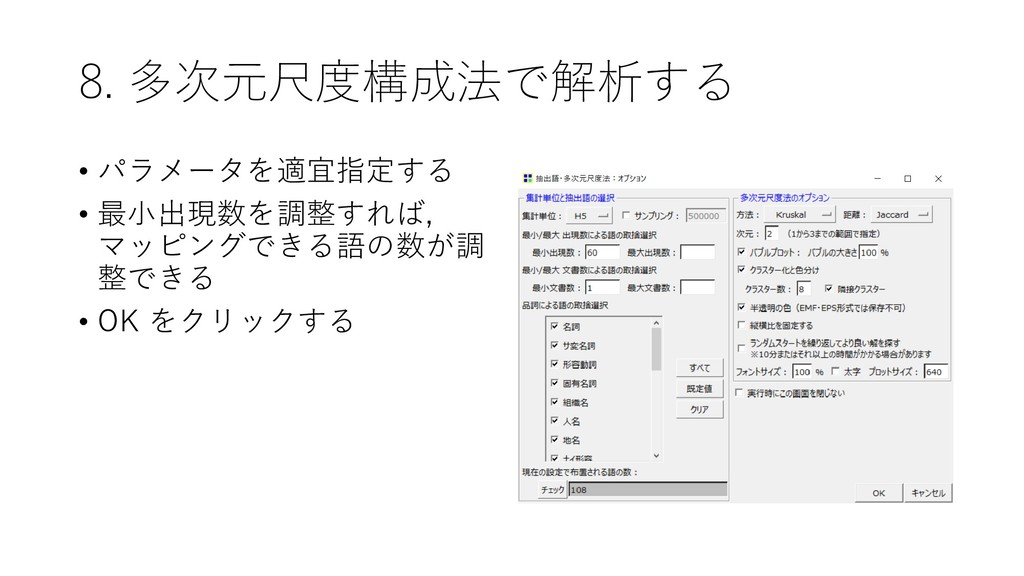{kind=link}
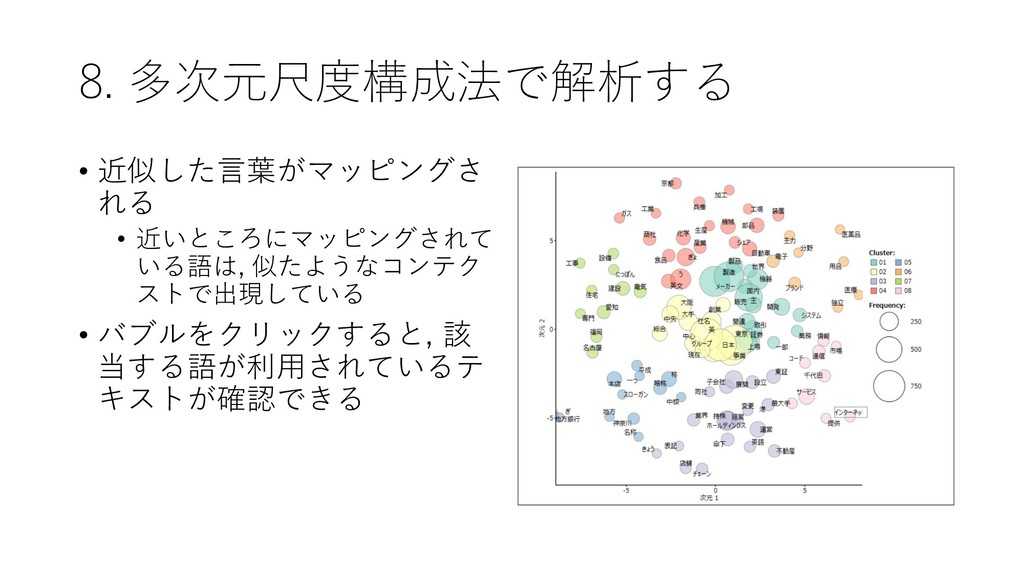{kind=link}
{kind=link}
{kind=link}
![10. コーディングルールに基づき単純推 計する • [ツール]-[コーディング]-[単 純推計] をクリックする](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_75.jpg){kind=link}
{kind=link}
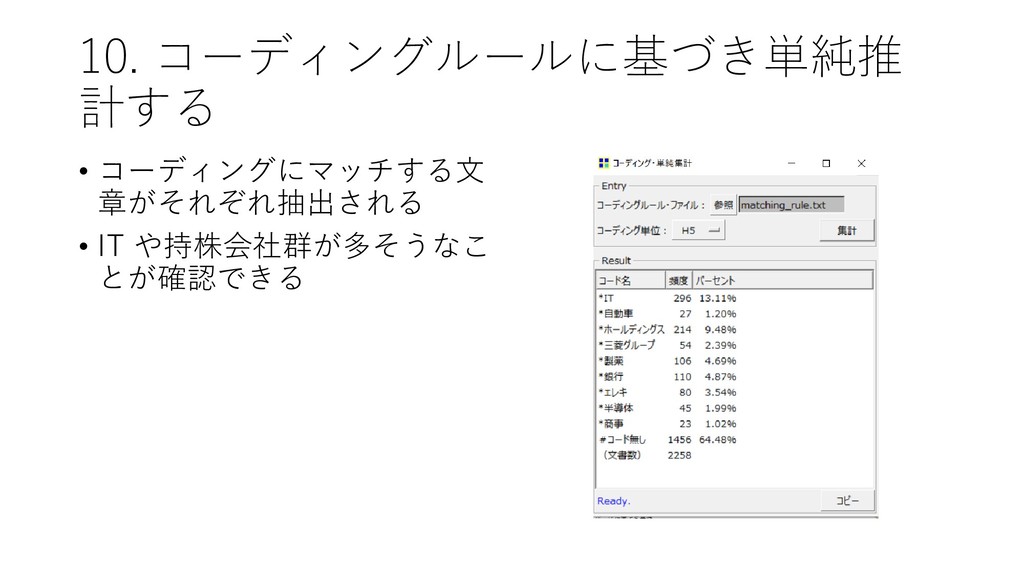{kind=link}
![11. コーディングルールに基づきクロス 集計する • [ツール]-[コーディング]-[ク ロス集計] をクリックする](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_78.jpg){kind=link}
![11. コーディングルールに基づきクロス 集計する • クロス集計[分類]を選択した上で, [集計] をクリックする • マザーズはITの割合が高いことが確認できる](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_79.jpg){kind=link}
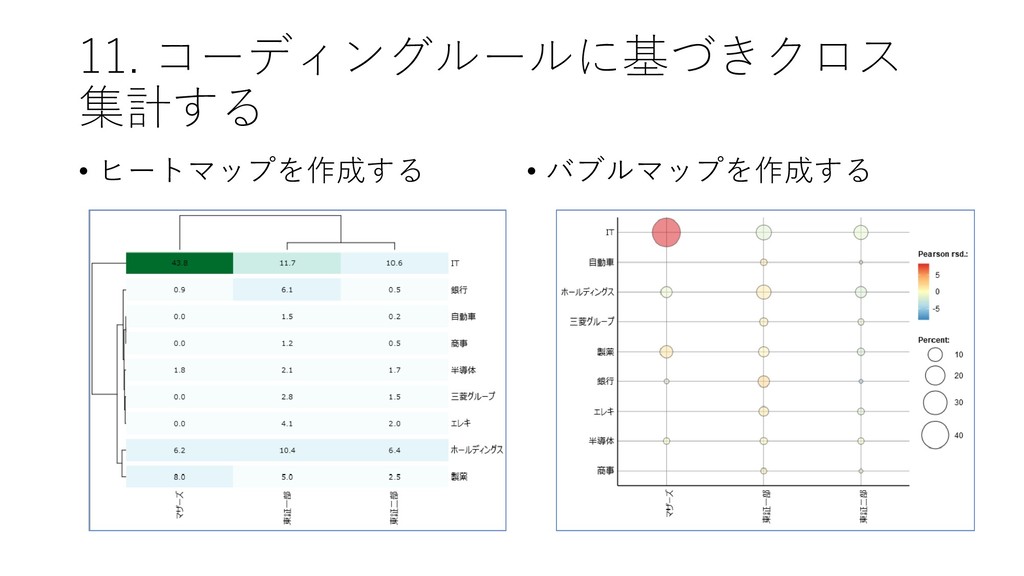{kind=link}
![12. Jacaard 係数に基づき類似度行列を導 出する • [ツール]-[コーディング]-[類 似度行列]をクリックする](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_81.jpg){kind=link}
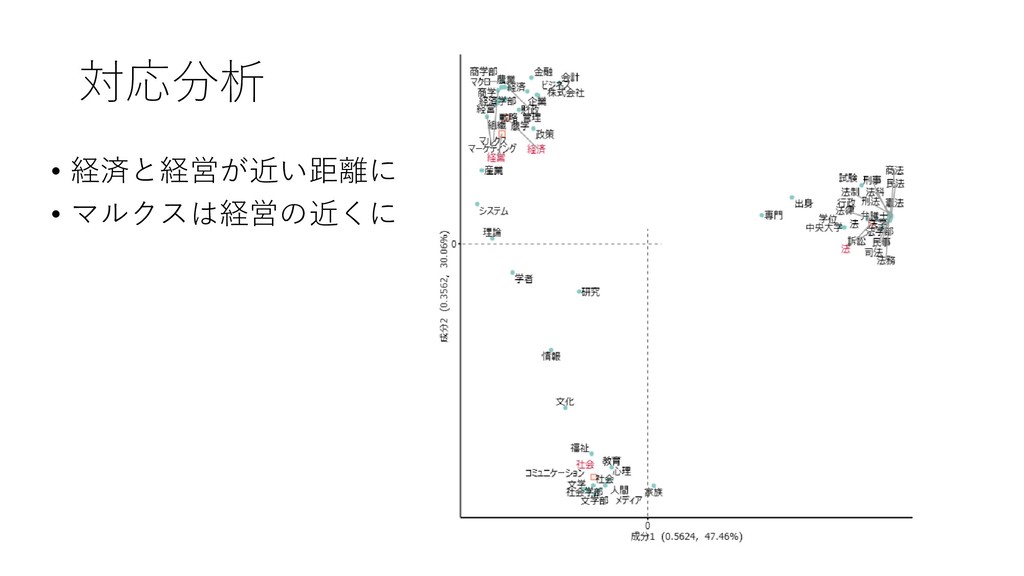
![13. コーディングルールに基づき対応分 析を行う • [ツール]-[コーディング]-[対 応分析]をクリックする](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_82.jpg){kind=link}
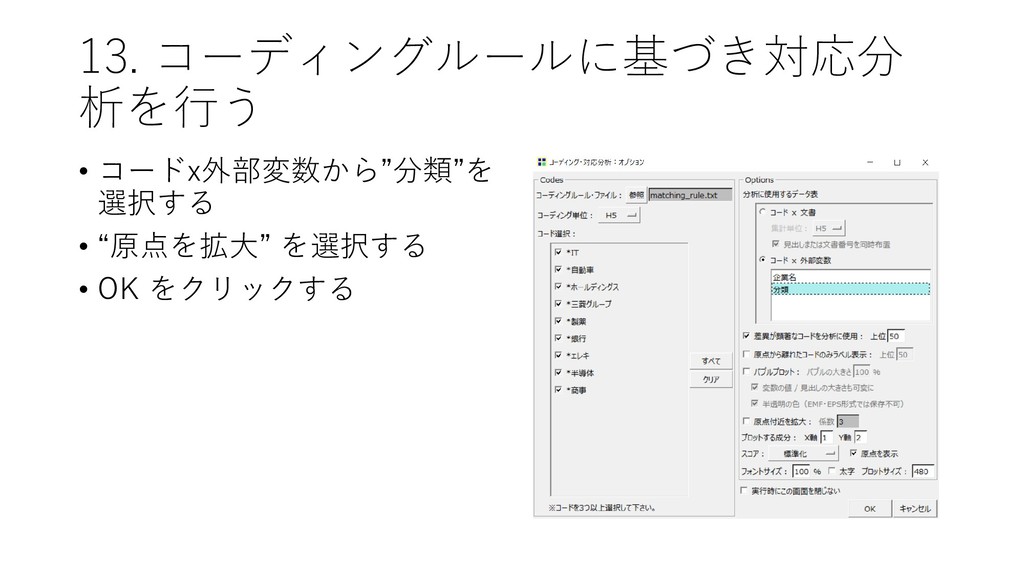{kind=link}
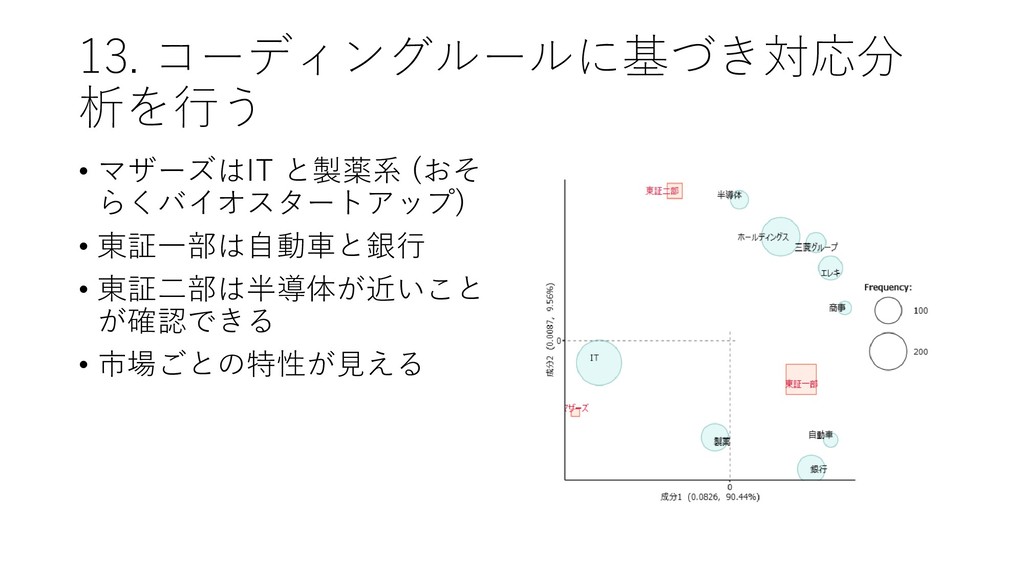{kind=link}
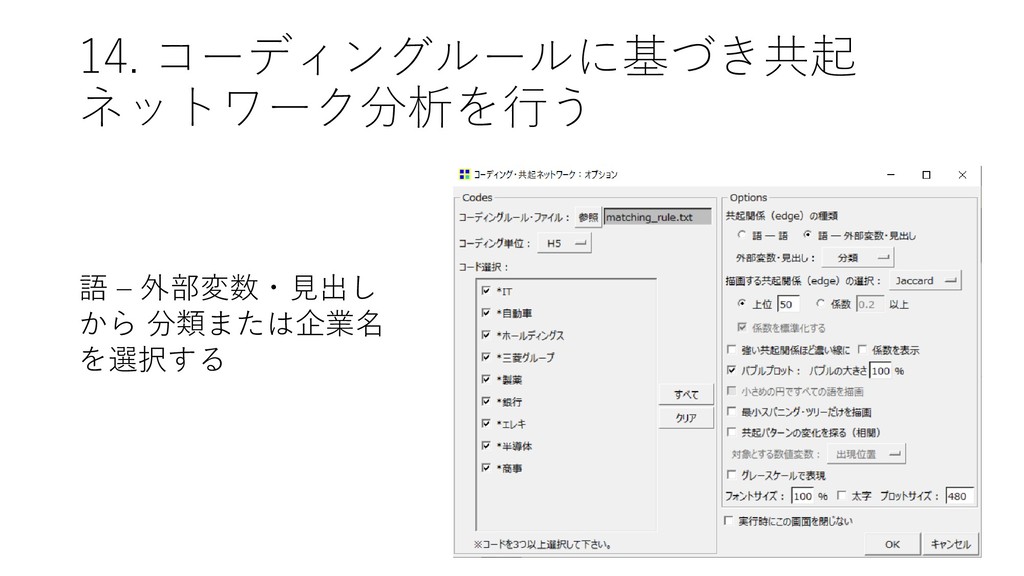
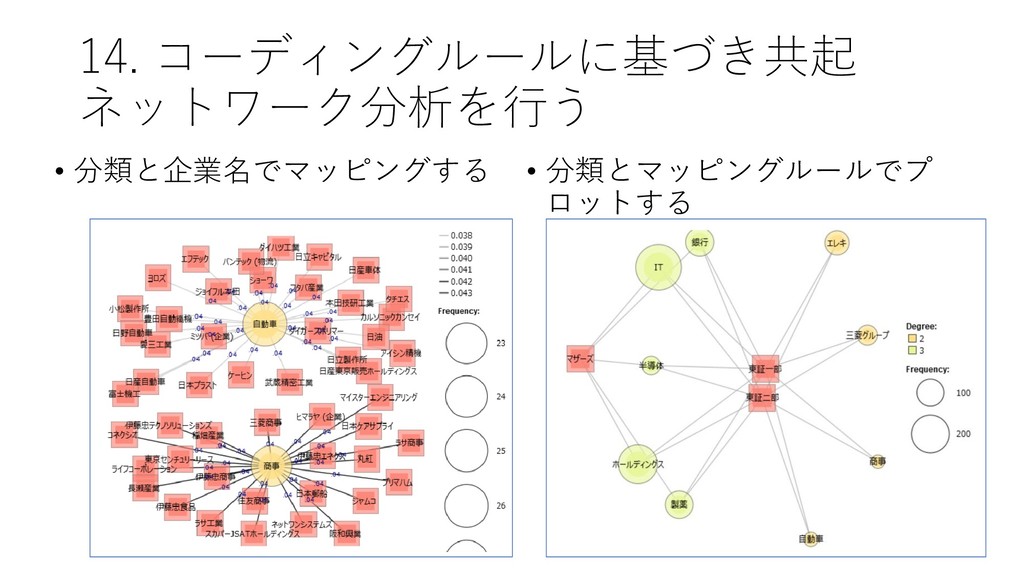
![14. コーディングルールに基づき共起 ネットワーク分析を行う • [ツール]-[コーディング]-[共 起ネットワーク] をクリック する](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_85.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/fdb66fa8d1564d73b00da7e78022e6eb/slide_138.jpg){kind=link}