Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
#経済学のための実践的データ分析 4.10 テキスト分析(後半)
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
yasushihara
December 18, 2019
Education
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
#経済学のための実践的データ分析 4.10 テキスト分析(後半)
#経済学のための実践的データ分析
4.10 テキスト分析(後半; 補講)
一橋大学大学院経済学研究科
原泰史
[email protected]
yasushihara
December 18, 2019
More Decks by yasushihara
See All by yasushihara
一橋大学 #経済学のための実践的データ分析 2020冬: 6/12
yasushihara
0
350
一橋大学 #経済学のための 実践的データ分析 2020冬: 4/12
yasushihara
0
310
一橋大学 #経済学のための実践的データ分析 2020冬: 3/12
yasushihara
0
450
一橋大学 #経済学のための実践的データ分析 2020冬: 2/12
yasushihara
0
340
一橋大学「経済学のための実践的データ分析」2020冬 1/12
yasushihara
0
580
一橋大学 2020秋 #経済学のための実践的データ分析 12/12
yasushihara
0
220
一橋大学 #経済学のための実践的データ分析 2020秋: 10/12
yasushihara
1
350
一橋大学 #経済学のための実践的データ分析 2020秋: 9/12
yasushihara
0
460
一橋大学 #経済学のための実践的データ分析 2020秋: 8/12
yasushihara
0
490
Other Decks in Education
See All in Education
Visionary Initiative: Materials-Positive Society — Evolving “Things,” empowering a positive society | Science Tokyo
sciencetokyo
PRO
0
110
Course Review - Lecture 13 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
2.3k
「答えを出す」より「わかる」をつくる
kzkmaeda
1
200
2026年度春学期 統計学 講義の進め方と成績評価について (2026. 4. 9)
akiraasano
PRO
0
220
Modern Data Fetching Techniques in Angular
debug_mode
0
220
「機械学習と因果推論」入門 ③ 漸近効率な推定量と二重機械学習
masakat0
0
720
!コスパよくインターンに受かる方法!
ruribou
1
290
教育現場から見た Ruby on Rails
yasslab
PRO
0
190
解決策を教えても次期リーダーは育たない ─ 器の発達に伴走するために / Partnering with leaders in their vertical development
matsu0228
1
490
Visionary Initiative: Materials-Positive Society 「モノの進化をポジティブな社会の原動力に」|Science Tokyo(東京科学大学)
sciencetokyo
PRO
0
560
AI-Based Speaking Assessment of a Short-Term Study Abroad Program
uranoken
0
360
[2026前期火5] 論理学(京都大学文学部 前期 第10回)「論理学の哲学——意味とは何か(Tonkと推論主義)」
yatabe
0
170
Featured
See All Featured
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.5k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.1k
Git: the NoSQL Database
bkeepers
PRO
432
67k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
860
Context Engineering - Making Every Token Count
addyosmani
9
1k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.2k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
1.9k
Being A Developer After 40
akosma
91
590k
We Are The Robots
honzajavorek
0
260
Transcript
経済学のための 実践的データ分析 4.10. テキスト分析 (後半)[補講] 38教室 一橋大学大学院 経済学研究科 原泰史
[email protected]
確認事項 • 電源タップは足りているでしょうか?
今年残りの予定 • 12/9; 企業データベース+RESAS • 12/12; Linked Open Data •
12/16; テキスト分析(その1) • 12/18(水曜); テキスト分析(その2; 補講) 38番教室 • 12/19; データの可視化 • ゲストあり〼 • 12/21; 一橋大学講座 • 12/22-29; イスラエル出張
4.10. テキスト分析(2) • この回では、これまで用いてきたデータセットについて、異な るアプローチから解析することを目指します。 • 具体的にはすでに定量化されているデータではなく、特許にお ける特許名、論文における論文名、企業データベースにおける 企業の概要などのテキストデータを解析する手法について学び ます。
• 講義ではPython, R および, KHCoder (http://khcoder.net/) を用い、解析を行います。学生は分析した結果についてレポー トにまとめ、提出する必要があります。
ケーススタディ2: 小室さんと華原さんのトークを分析してみよ う • TK MUSIC CRAMP • 1995年から1998年まで放送してた音楽番組 •
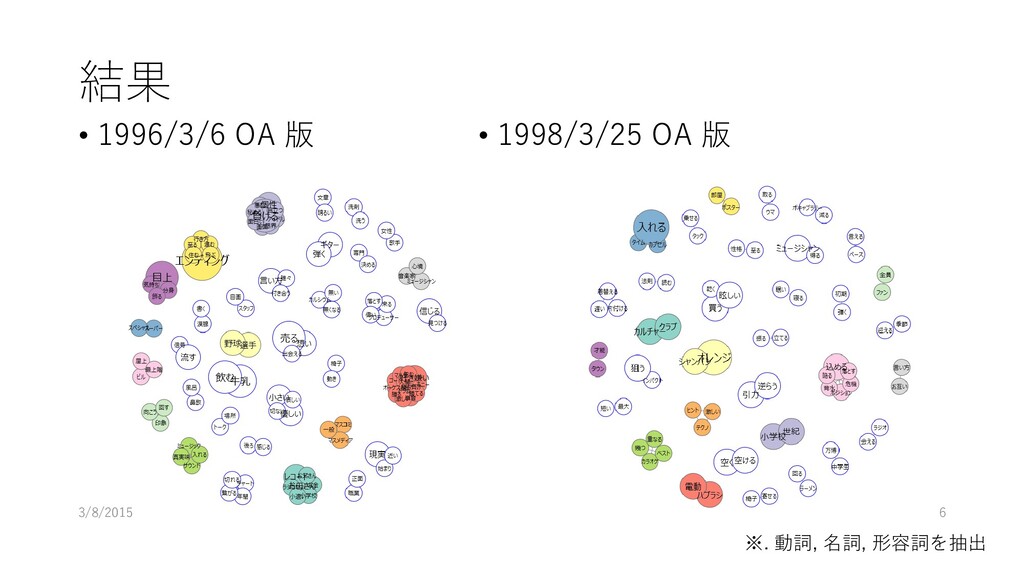
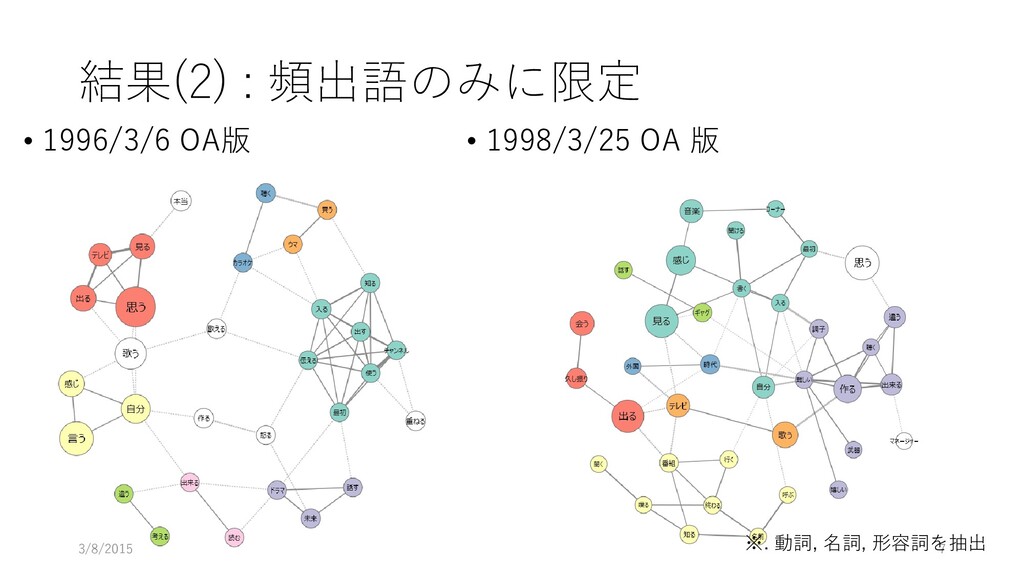
1995年度は小室哲哉さんが • 1996年度はSMAPの中居正広さんが • 1997年度は華原朋美さんが司会を担当 • 二人の会話を共起グラフ分析して、二人がどのくらいラブラブ だったのか、どのくらい冷めちゃったのか可視化できるかやっ てみよう • 分析対象 • 1996/3/6 オンエアのトーク • 1998/3/25 オンエアのトーク 3/8/2015 5
結果 • 1996/3/6 OA 版 • 1998/3/25 OA 版 3/8/2015
6 ※. 動詞, 名詞, 形容詞を抽出
結果(2) : 頻出語のみに限定 • 1996/3/6 OA版 • 1998/3/25 OA 版
3/8/2015 7 ※. 動詞, 名詞, 形容詞を抽出
今日のコン テンツ SNSの口コミ分析 KHCoder の使い方 (for Windows ユーザ) 感情分析 レポートの説明
最終レポートの説明
1. (Twitterを使った) 口コミ分析
利用する Notebook • Jupyter Notebook • https://www.dropbox.com/s/xw8sltq0kp4 ey2g/Twitter%20API%20%E3%81%8B%E3 %82%89%E5%A4%A7%E5%AD%A6%E3%8 1%AB%E9%96%A2%E4%BF%82%E3%81%
99%E3%82%8B%E3%81%A4%E3%81%B6 %E3%82%84%E3%81%8D%E3%82%92%E 5%8F%96%E5%BE%97%E3%81%97%E3% 81%A6%2C%20WordCloud%20%E3%82%9 2%E4%BD%9C%E3%82%8B.ipynb?dl=0
Twitter のAPI を申請する • https://developer.twitter.com にアクセスする
Twitter の API を申請する • Apply for a developer account
をクリックする
Twitter の API を申請する • 利用目的を選択する
Twitter の API を申請する 必要事項を入力し, Next をクリックする
Twitter の API を申請する • なぜ API を利用したいのか記入する
Twitter の API を申請する • 内容を確認し, Looks Good! をクリックする
Twitter の API を申請する • Submit Application をクリックする
Twitter の API を申請する • E-mail でメッセージが届くので Confirmation をする
Twitter の API を申請する • E-mail での Confirm を終えると, Developer
ページに遷移する
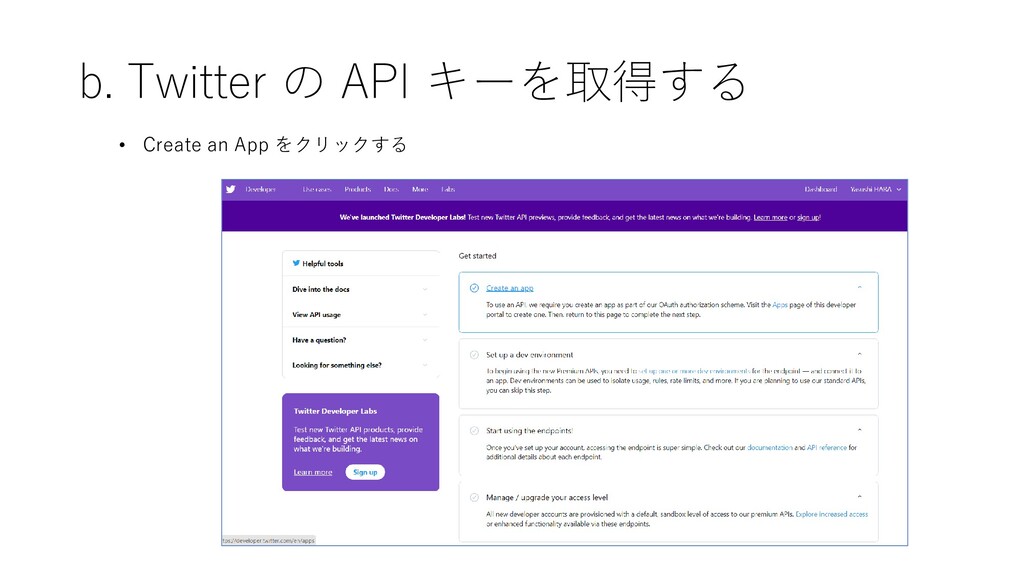
b. Twitter の API キーを取得する • Create an App をクリックする
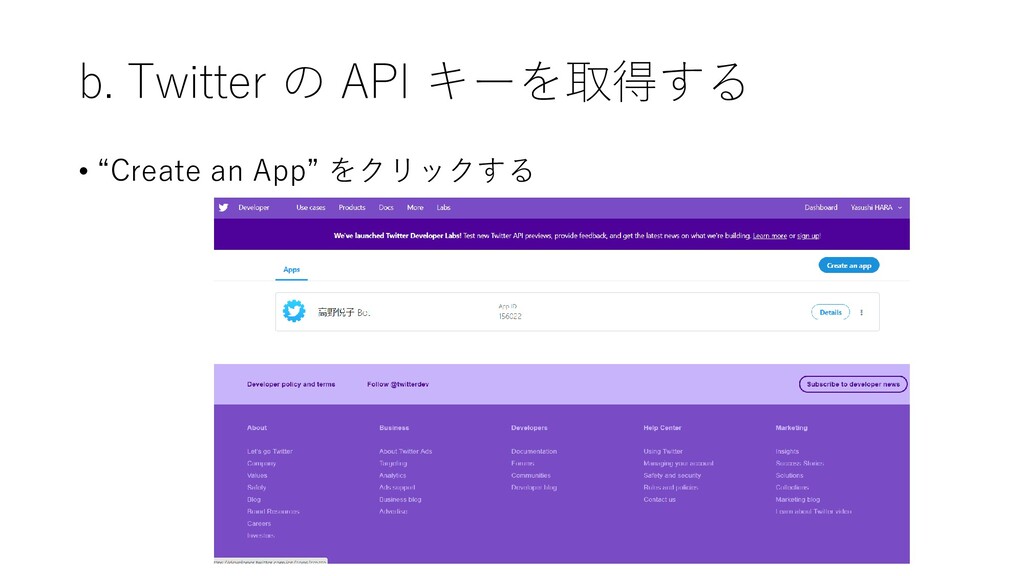
b. Twitter の API キーを取得する • “Create an App” をクリックする
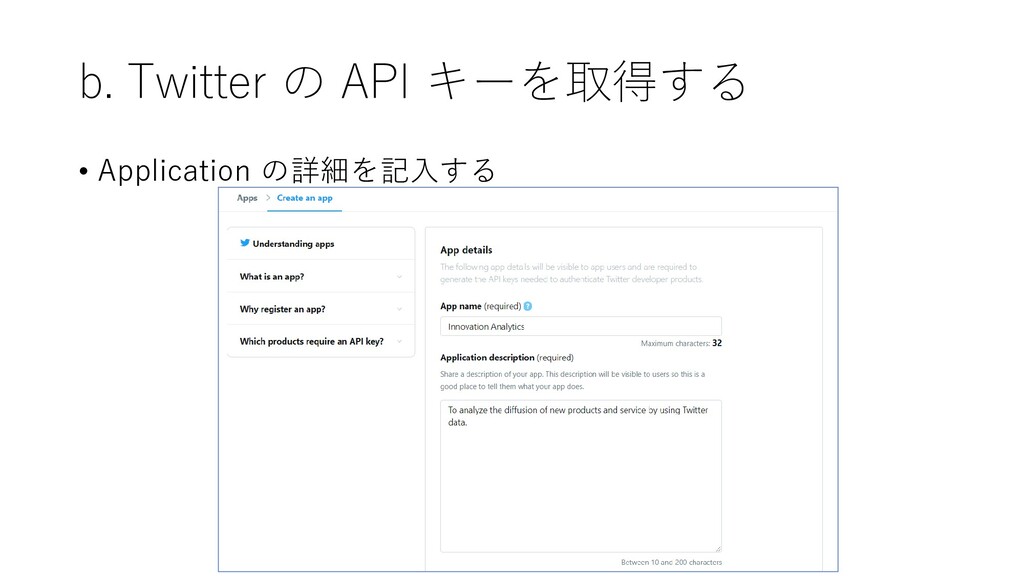
b. Twitter の API キーを取得する • Application の詳細を記入する
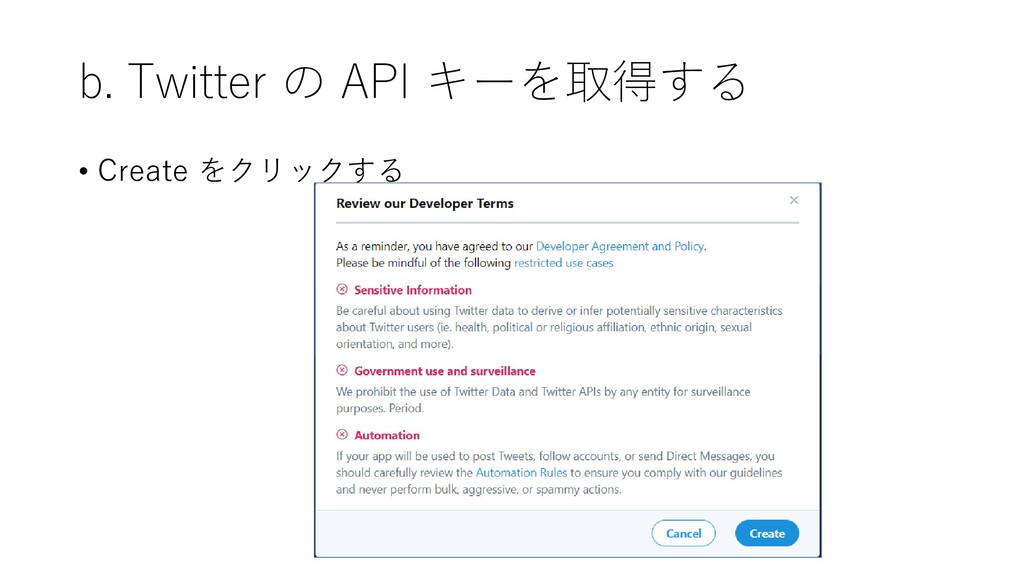
b. Twitter の API キーを取得する • Create をクリックする
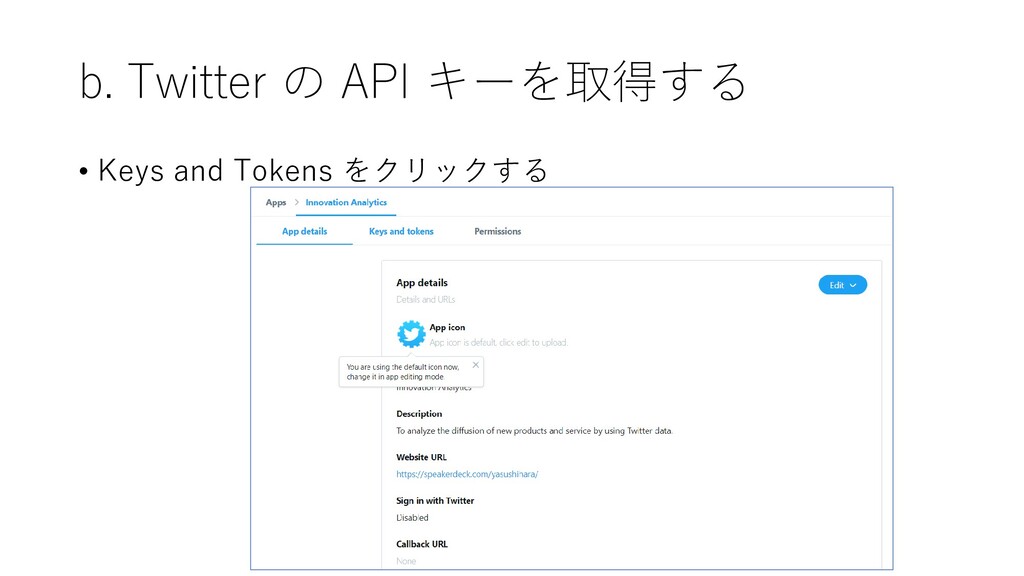
b. Twitter の API キーを取得する • Keys and Tokens をクリックする
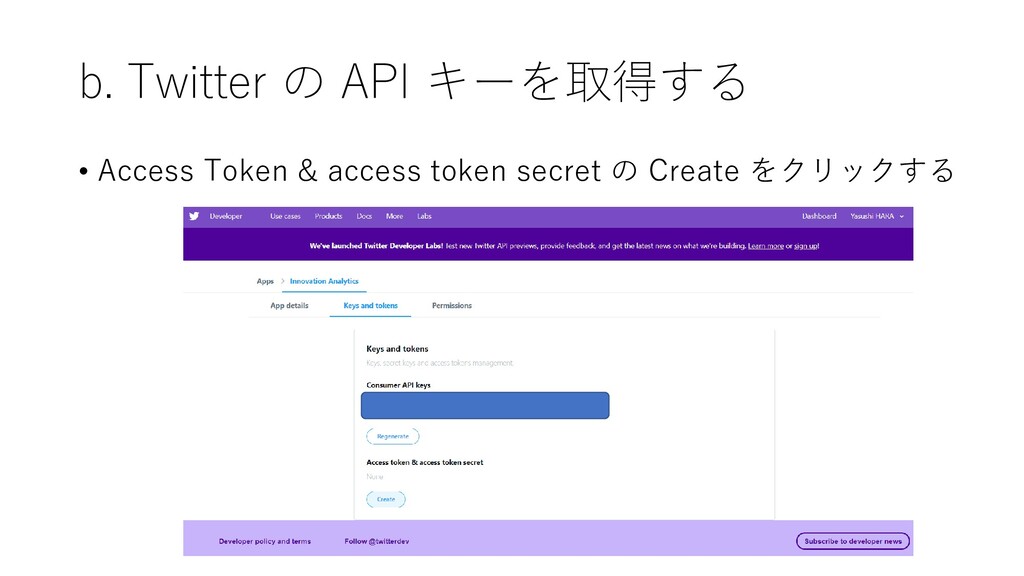
b. Twitter の API キーを取得する • Access Token & access
token secret の Create をクリックする
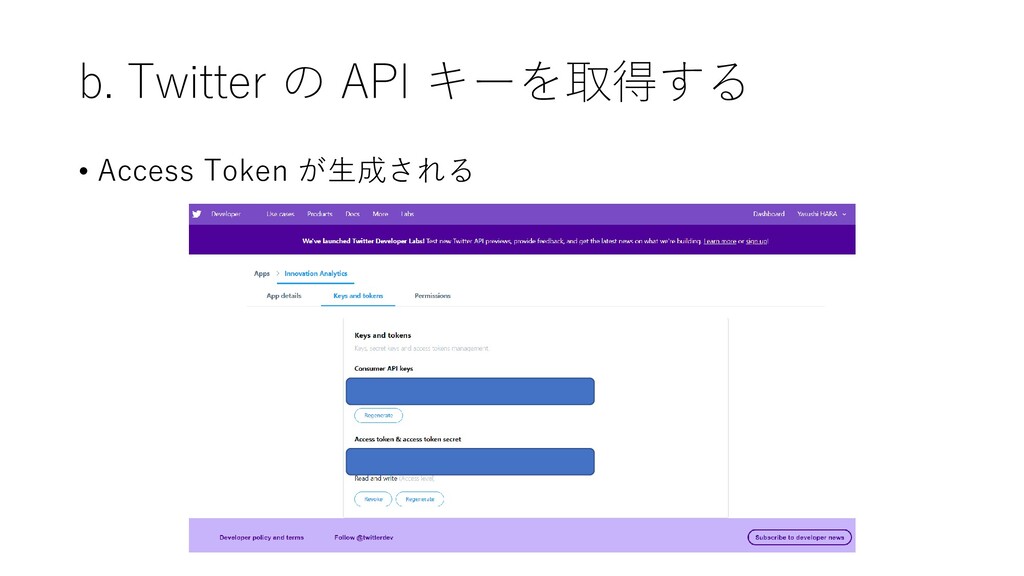
b. Twitter の API キーを取得する • Access Token が生成される
c. 自分のタイムライン情報を取得する • Twitter パッケージをインストールする
c. 自分のタイムライン情報を取得する • 先程取得したAPI キー情報を指定する • Twitter に Oauth 経由でアクセスする
• 自分のタイムライン情報を取得する
c. 自分のタイムライン情報を取得する • 自分がフォローしているユーザーのツイートが取得される
d. ハッシュタグに基づきデータを取得す る • 利用するパッケージ (tweepyと datetime) をインポートする • b.
の作業で取得した Consumer_key, Consumer_secret, Access_token, Access_secret を 指定する • 検索キーワードを変数として格 納する • ツイートを取得する 参考; https://qiita.com/kngsym2018/items/3719f8da1f129793257c
d. ハッシュタグに基づきデータを取得する • ファイル名を指定する • ファイルをテキストファイル として出力する
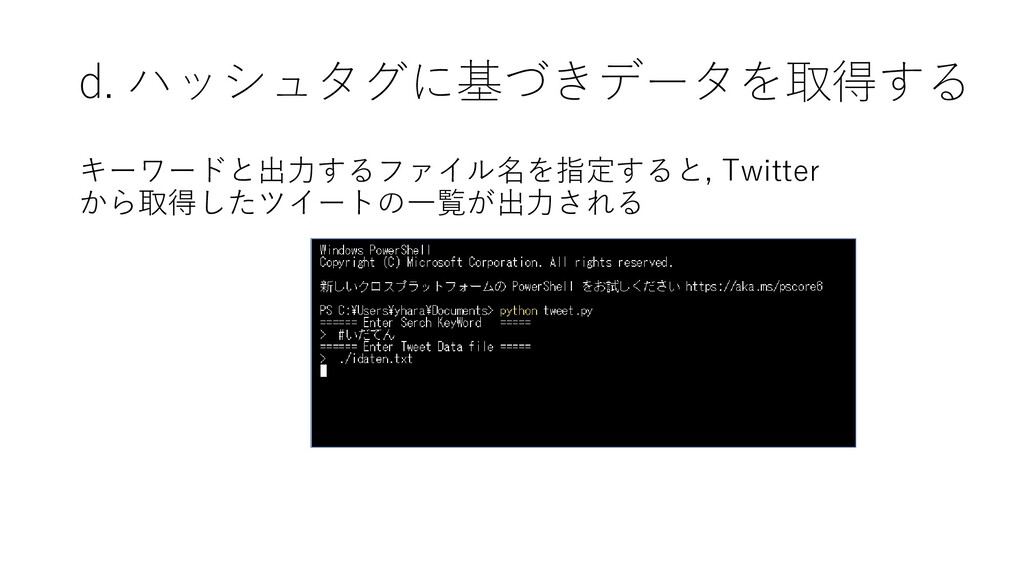
d. ハッシュタグに基づきデータを取得する キーワードと出力するファイル名を指定すると, Twitter から取得したツイートの一覧が出力される
e. 取得したデータを解析する (wordcloud) • 早稲田大学 • 慶應大学
e. 取得したデータを解析する (wordcloud; cont.) • 甲南大学 一橋大学
SNS データは何に使える? • 消費者行動 (マーケティングっぽい) • 口コミ分析 • 研究{者}の社会的なインパクトの測定 ->
特定の研究者の名前 を含むツイートの回数, リツイートの回数, Fav 数 etc…
Tips; データが使える/使えないSNS • Mixi • Mixi graph api; http://developer.mixi.co.jp/conn ect/mixi_graph_api/
• Twitter • API でデータを取得可能, 過去デー タに関しては要課金 • Instagram • API 提供, 審査あり; • https://developers.facebook.com /docs/instagram-api • Facebook • Graph API; https://developers.facebook.com /docs/graph-api?locale=ja_JP • スクレイピングは全面的に禁止; https://www.octoparse.jp/blog/5 -things-you-need-to-know- before-scraping-data-from- facebook/ • Tiktok • Unofficial API は発見; https://github.com/szdc/tiktok- api
2. khcoder で解析しよう
やりたいこと • Dbpedia.org の東証一部/東証二部/マザーズの 会社概要データを持ってきて, 1. どのようなことばがよく出てくるのかを知りたい 2. どのようなことばと、どのようなことばがつながっ ているのかを知りたい
2019/12/17 38
やること 1. KHCoder をインストールする 2. Dbpedia.org から SPARQL Endpoint 経由でデータセットを取得する
• 前回の内容 3. Manaba からデータセットをダウンロードする 4. KHCoder に定点調査の自由記述データを読み込む 5. データ分析前の処理をする 6. 頻出語の取り出しを行う 7. 共起ネットワークを書く 8. 属性情報ごとの特徴を抽出する 9. 対応分析を行う 2019/12/17 39
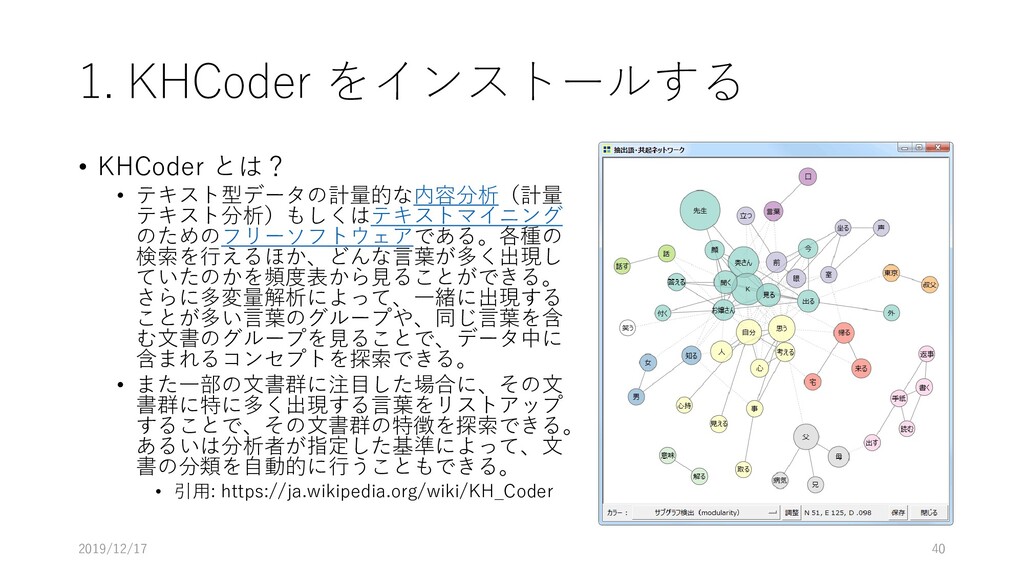
1. KHCoder をインストールする • KHCoder とは? • テキスト型データの計量的な内容分析(計量 テキスト分析)もしくはテキストマイニング のためのフリーソフトウェアである。各種の
検索を行えるほか、どんな言葉が多く出現し ていたのかを頻度表から見ることができる。 さらに多変量解析によって、一緒に出現する ことが多い言葉のグループや、同じ言葉を含 む文書のグループを見ることで、データ中に 含まれるコンセプトを探索できる。 • また一部の文書群に注目した場合に、その文 書群に特に多く出現する言葉をリストアップ することで、その文書群の特徴を探索できる。 あるいは分析者が指定した基準によって、文 書の分類を自動的に行うこともできる。 • 引用: https://ja.wikipedia.org/wiki/KH_Coder 2019/12/17 40
1. KHCoder をインストールする • https://khcoder.net/dl3. htmlにアクセスする • Download をクリックす る
2019/12/17 41
1. KHCoder をインストールする • ダウンロードしたファイル (khcoder-3a16.exe) を選択 し, クリックする •
Unzip を選択し, ファイルを 展開する 2019/12/17 42
1. Khcoder をインストールする • スタートメニューなどに登録して, 起動する 2019/12/17 43
1. KHCoder をインストールする • アプリケーションが表示される 2019/12/17 44
1. Khcoder をインストールする • Tips: Mac な場合 • かなりめんどくさい •
Perl やR の個別パッケージの導 入が必要 • 有償版のインストールパッケー ジが提供されている. • https://khcoder.stores.jp/#!/it ems/536a53268a56108414000 1dd 2019/12/17 45
2. Dbpedia.org から SPARQL Endpoint 経 由でデータセットを取得する • 前回の講義で説明した Dbpedia.org
の SPARQL Endpoint から, 東証一部, 東証二部, およびマザーズの企業名とその企業概要を 取得する • 日経NEEDS などに採録されたオフィシャルなデータではなくて、 Wikipedia で執筆された企業の「紹介文」 2019/12/17 46
2. Dbpedia.org から SPARQL Endpoint 経 由でデータセットを取得する • Jupyter Notebook
で以下のように記述する (詳しくは前回配布 した notebook を参照のこと)
2. Dbpedia.org から SPARQL Endpoint 経 由でデータセットを取得する • 以下の通り, 企業名と概要がアウトプットされる
2. Dbpedia.org から SPARQL Endpoint 経 由でデータセットを取得する • 同様の作業を, 東証一部と東証二部で繰り返す
#東証マザーズ上場企業の情報を取得する sparql2 = SPARQLWrapper(endpoint='http://ja.dbpedia.org/sparql', returnFormat='json') sparql2.setQuery(""" PREFIX dbpedia-owl: <http://dbpedia.org/ontology/> select distinct ?name ?abstract where { ?company <http://dbpedia.org/ontology/wikiPageWikiLink> <http://ja.dbpedia.org/resource/Category:東証マザーズ上場企業> . ?company rdfs:label ?name . ?company <http://dbpedia.org/ontology/abstract> ?abstract . } """) results2 = sparql2.query().convert()
2. Dbpedia.org から SPARQL Endpoint 経 由でデータセットを取得する • Excel or
panda で適宜整形する
3. KHCoder にデータを読み込む • データ • 東証一部/東証二部/マザーズ: • https://www.dropbox.com/s/9jtwyxw4ae3nntz/%E6%9D%B1%E8%A8%BC%E4%B 8%80%E9%83%A8%E6%9D%B1%E8%A8%BC%E4%BA%8C%E9%83%A8%E3%83%9
E%E3%82%B6%E3%83%BC%E3%82%BA.xlsx?dl=0 • 経済学者/経営学者/社会学者: • https://www.dropbox.com/s/jmvz8fv25aqecsj/%E6%97%A5%E6%9C%AC%E3%81 %AE%E7%B5%8C%E6%B8%88%E7%B5%8C%E5%96%B6%E7%A4%BE%E4%BC%9 A%E6%B3%95%E5%AD%A6%E8%80%85%E4%B8%80%E8%A6%A7.xlsx?dl=0 • ヒップホップ/ロック/フォークグループ: • https://www.dropbox.com/s/5iye8puor1eg52r/%E6%97%A5%E6%9C%AC%E3%81 %AE%E3%83%92%E3%83%83%E3%83%97%E3%83%9B%E3%83%83%E3%83%97% E3%83%AD%E3%83%83%E3%82%AF%E3%83%95%E3%82%A9%E3%83%BC%E3% 82%AF%E3%82%B0%E3%83%AB%E3%83%BC%E3%83%97.xlsx?dl=0 2019/12/17 51
3. KHCoder に定点調査の自由記述データ を読み込む • KHCoder を開く • [プロジェクト] –[新規]
を選択する 2019/12/17 52
3. KHCoder にデータを読み込む • [参照]をクリックして, 分析対 象ファイルを選ぶ • 分析対象とする列について[詳 細]
をクリックする • OK をクリックする • ファイルが読み込まれる 2019/12/17 53
4. データ分析前の処理をする • [前処理] – [テキストのチェッ ク]をクリックする • OKをクリックする 2019/12/17
54
4. データ分析前の処理をする • 修正が必要である旨メッセージが表示される • [画面に表示] をクリックして, 問題点をチェックする • “テキストの自動修正”
より[実行]をクリックする 2019/12/17 55
4. データ分析前の処理をする • 問題点が修正される. • [閉じる]をクリックする. 2019/12/17 56
4. データ分析前の処理をする • [前処理] – [前処理の実行] を選択する • OKをクリックする 2019/12/17
57
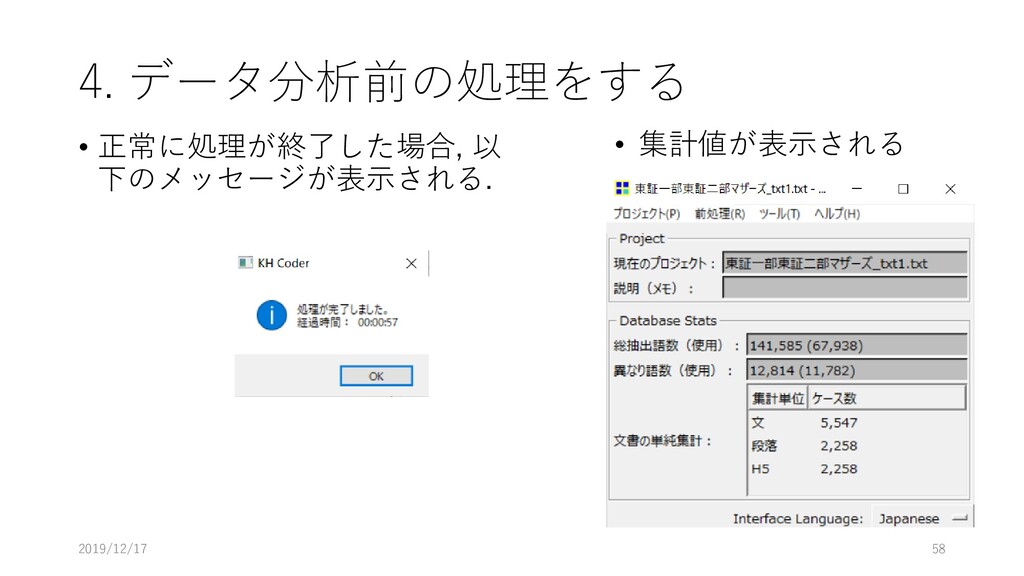
4. データ分析前の処理をする • 正常に処理が終了した場合, 以 下のメッセージが表示される. • 集計値が表示される 2019/12/17 58
4. データ分析前の処理をする • 複合語の検出を行う • [前処理]-[複合語の検出]-[茶筌 を利用]をクリックする
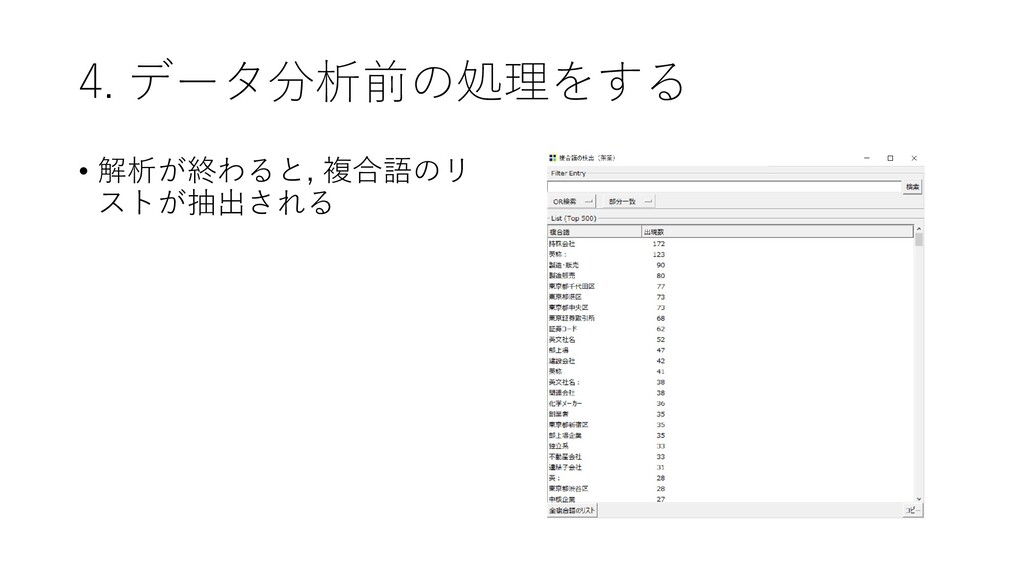
4. データ分析前の処理をする • 解析が終わると, 複合語のリ ストが抽出される
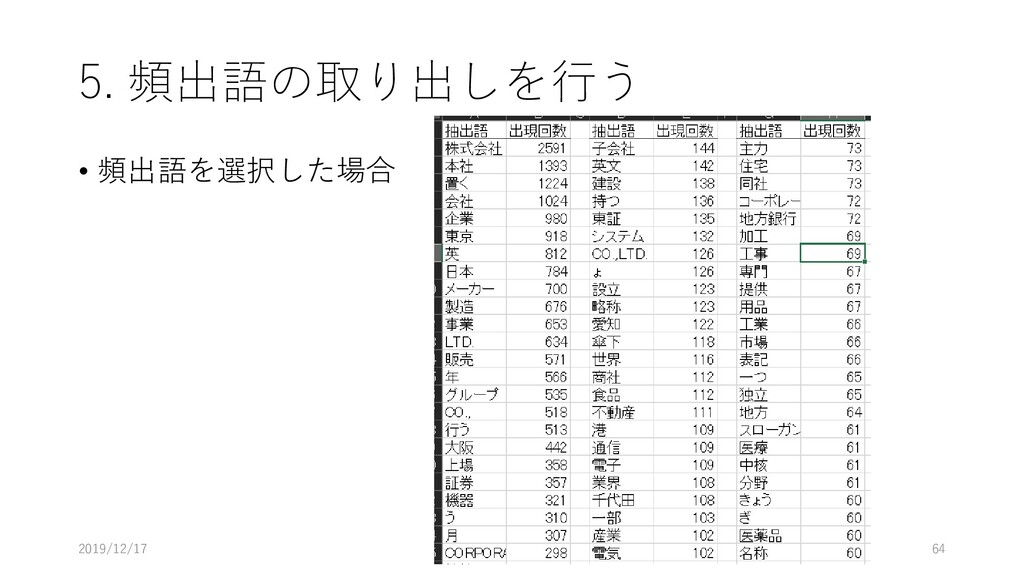
5. 頻出語の取り出しを行う • [ツール]-[抽出語]-[抽出語 リスト(Excel)]を選択する 2019/12/17 61
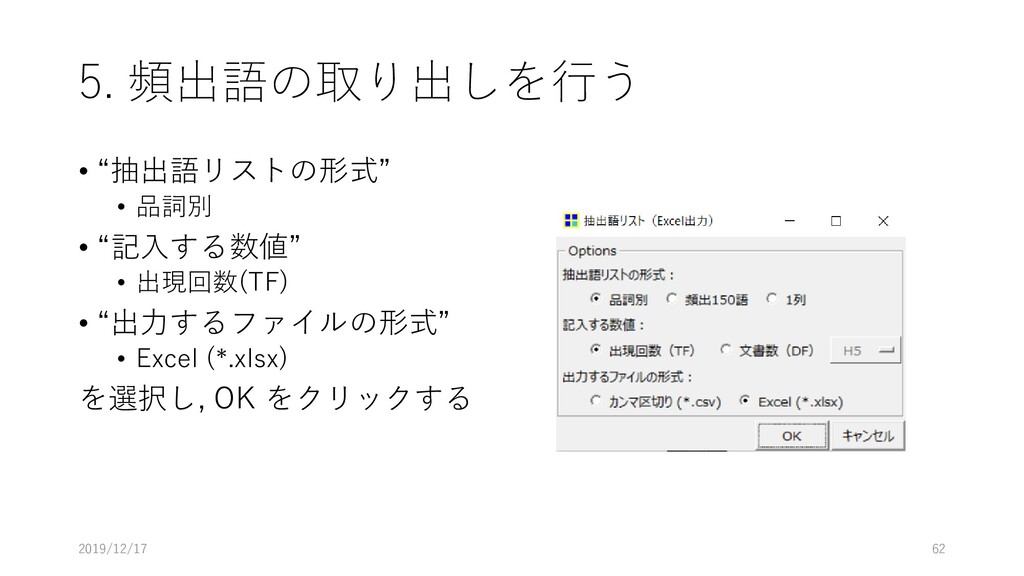
5. 頻出語の取り出しを行う • “抽出語リストの形式” • 品詞別 • “記入する数値” • 出現回数(TF)
• “出力するファイルの形式” • Excel (*.xlsx) を選択し, OK をクリックする 2019/12/17 62
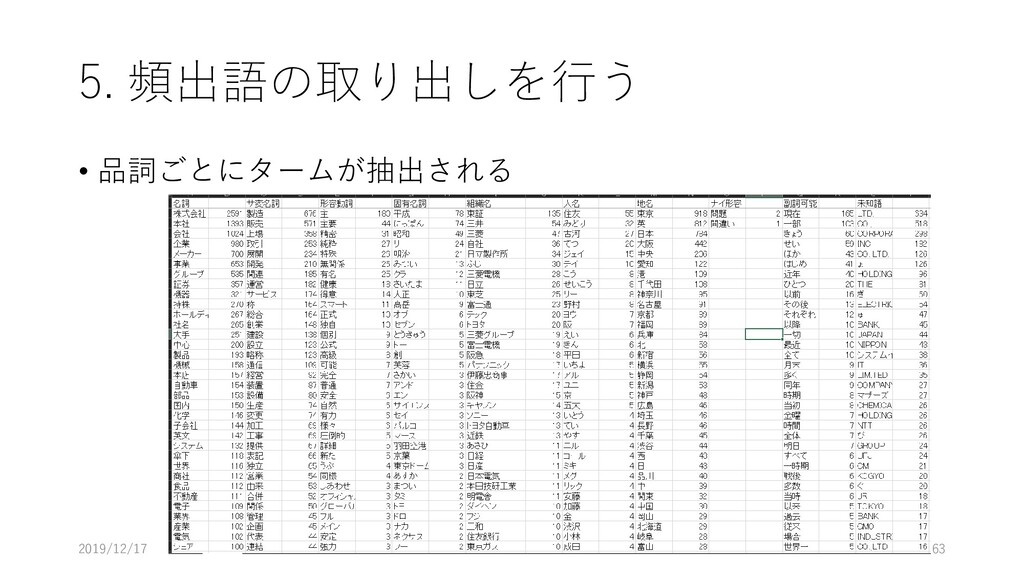
5. 頻出語の取り出しを行う • 品詞ごとにタームが抽出される 2019/12/17 63
5. 頻出語の取り出しを行う • 頻出語を選択した場合 2019/12/17 64
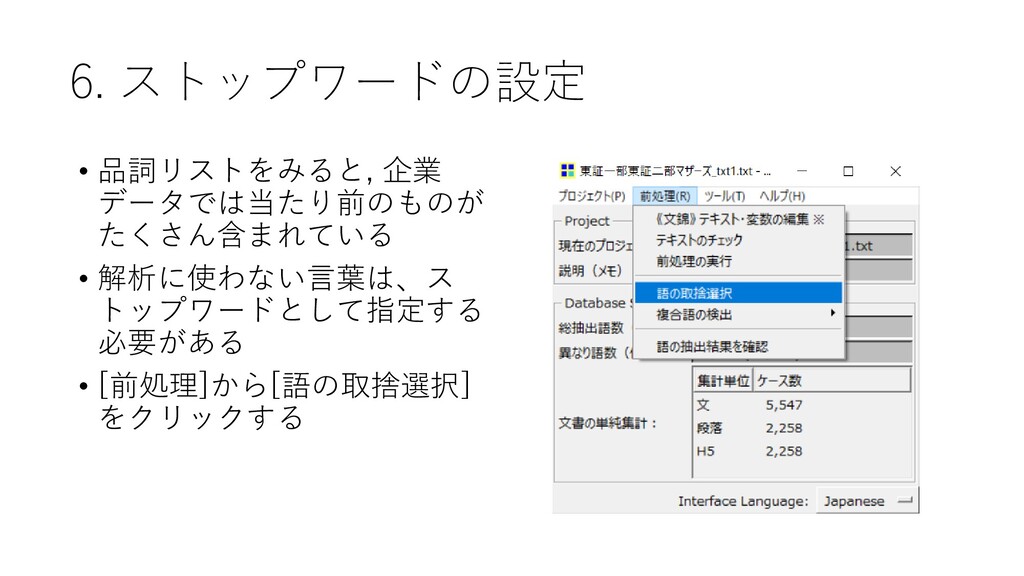
6. ストップワードの設定 • 品詞リストをみると, 企業 データでは当たり前のものが たくさん含まれている • 解析に使わない言葉は、ス トップワードとして指定する
必要がある • [前処理]から[語の取捨選択] をクリックする
6. ストップワードの設定 • Force ignore “使用しない語の指定” にス トップワードを指定する • 株式会社
• 本社 • 会社 • 企業 • LTD. • CO., • CORPORATION • INC. • ょ • CO.,LTD. • HOLDINGS • THE • ELECTRIC • コーポレート など….
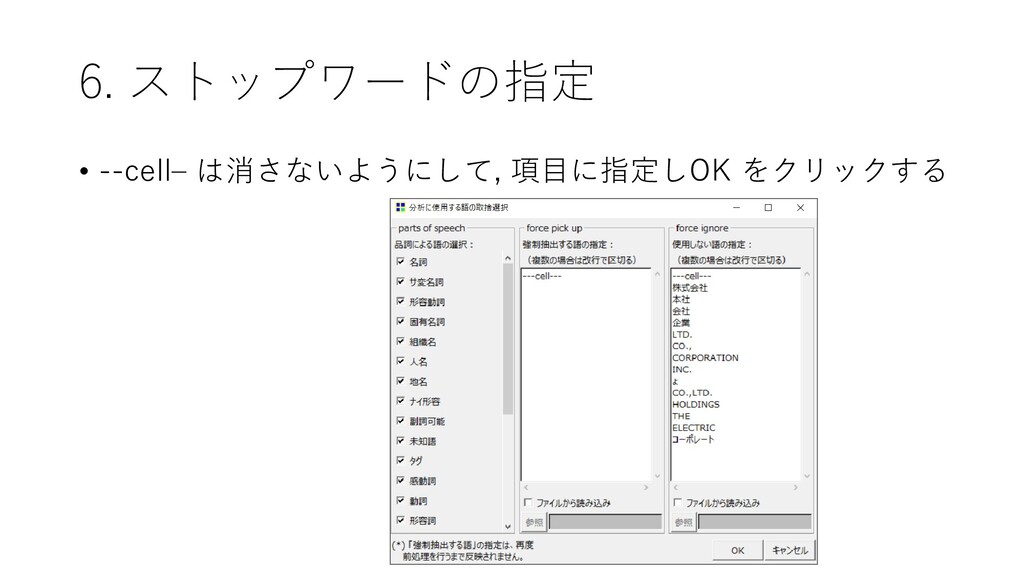
6. ストップワードの指定 • --cell– は消さないようにして, 項目に指定しOK をクリックする
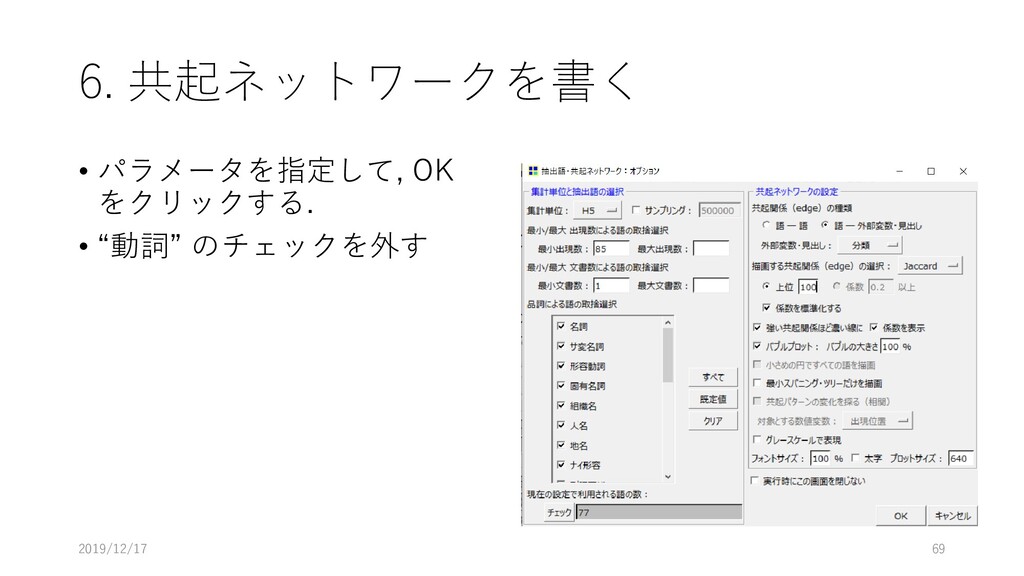
6. 共起ネットワークを書く • [ツール]-[抽出語]-[共起 ネットワーク]を選択する 2019/12/17 68
6. 共起ネットワークを書く • パラメータを指定して, OK をクリックする. • “動詞” のチェックを外す 2019/12/17
69
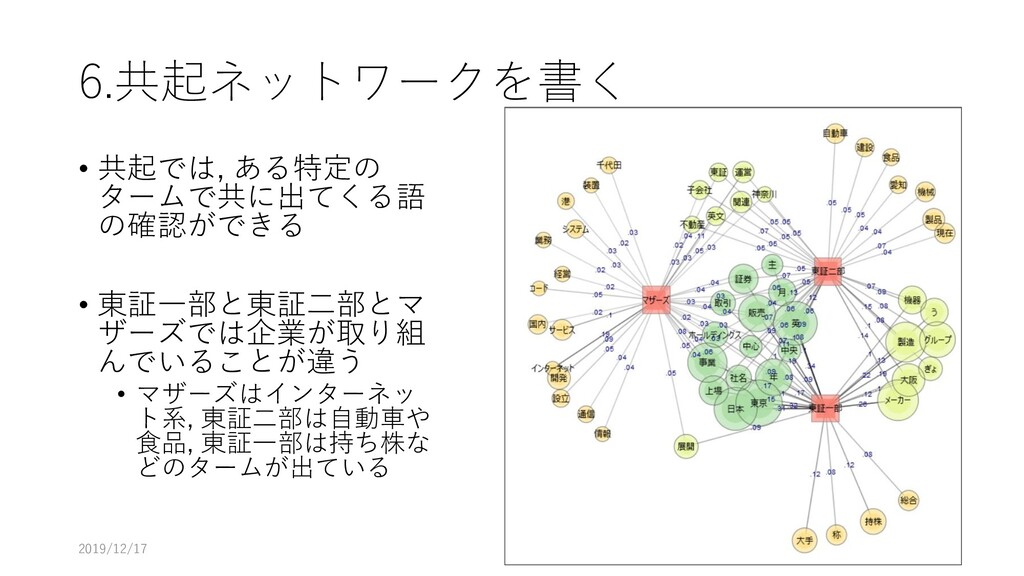
6.共起ネットワークを書く • 共起では, ある特定の タームで共に出てくる語 の確認ができる • 東証一部と東証二部とマ ザーズでは企業が取り組 んでいることが違う
• マザーズはインターネッ ト系, 東証二部は自動車や 食品, 東証一部は持ち株な どのタームが出ている 2019/12/17 70
7. 対応分析を行う • 抽出語を用いた対応分析を行 い、その結果を二次元の散布 図に示す • 出現パターンの似通った語に はどのようなものがあったの か探ることができる
• [ツール]-[抽出語]-[対応分析] を選択する 2019/12/17 71
7. 対応分析を行う • “対応分析のオプション” – “分析に仕様するデータ表の 種類”から, [抽出語 x 外部変
数] から分類を選択し, OK を クリックする 2019/12/17 72
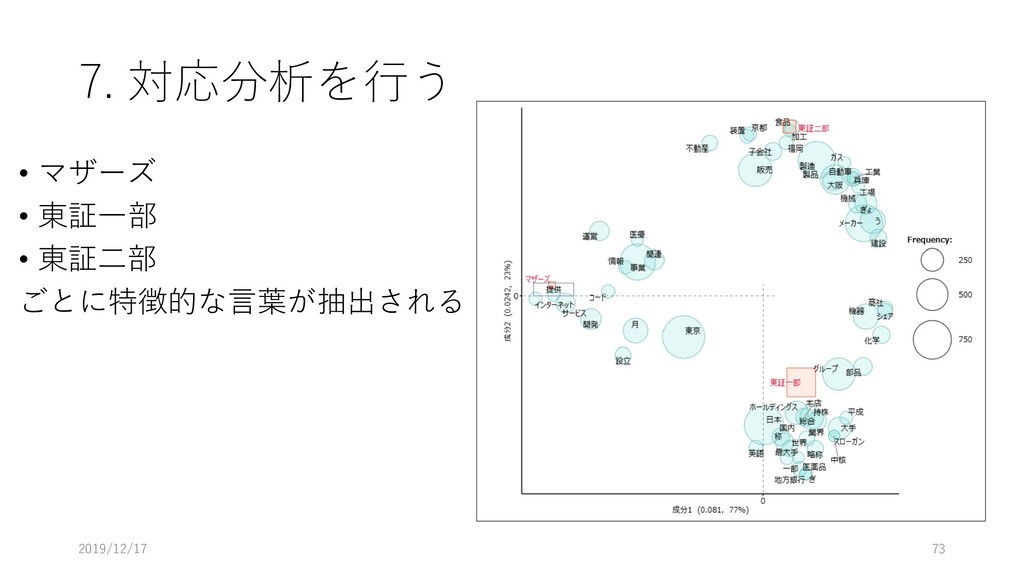
7. 対応分析を行う • マザーズ • 東証一部 • 東証二部 ごとに特徴的な言葉が抽出される 2019/12/17
73
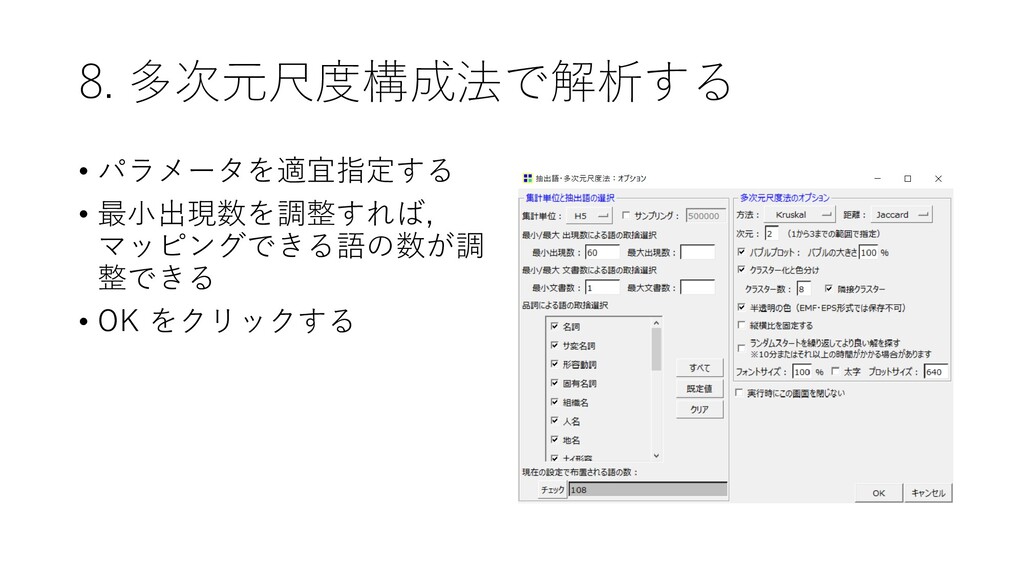
8. 多次元尺度構成法で解析する • 近接している語のパターンを 解析できる • [ツール]-[抽出語]-[多次元尺 度構成法]を選択する
8. 多次元尺度構成法で解析する • パラメータを適宜指定する • 最小出現数を調整すれば, マッピングできる語の数が調 整できる • OK
をクリックする
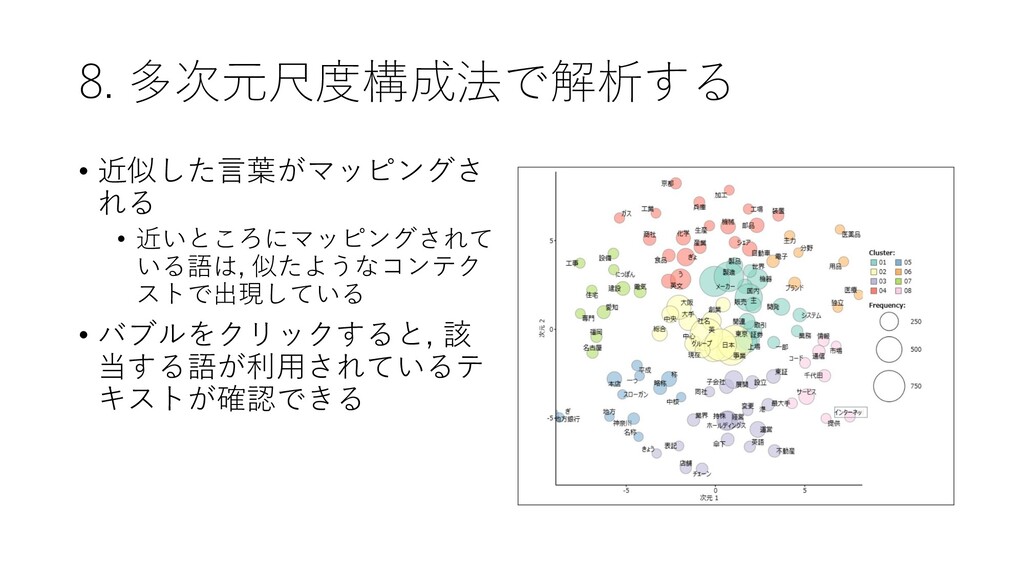
8. 多次元尺度構成法で解析する • 近似した言葉がマッピングさ れる • 近いところにマッピングされて いる語は, 似たようなコンテク ストで出現している
• バブルをクリックすると, 該 当する語が利用されているテ キストが確認できる
9. マッチングルールを作成する • 特定の語のグループを作成し, それらでグルーピングするこ とで特徴を抽出する • 今回の場合, 自動車産業, 電気
産業, 銀行, ICT など産業分類 ごとにグルーピングする • 記述方法 *グループ名1 みかん or いちご or りんご *グループ名2 ごりら or らっこ or こんどる *グループ名3 るびー or びーどる
9. マッチングルールを作成する • 例.
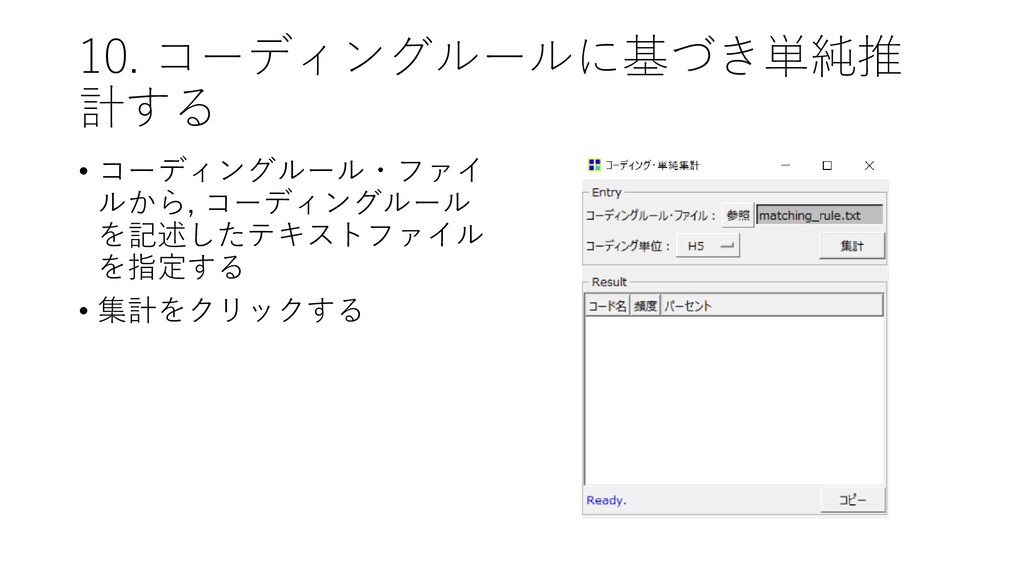
10. コーディングルールに基づき単純推 計する • [ツール]-[コーディング]-[単 純推計] をクリックする
10. コーディングルールに基づき単純推 計する • コーディングルール・ファイ ルから, コーディングルール を記述したテキストファイル を指定する •
集計をクリックする
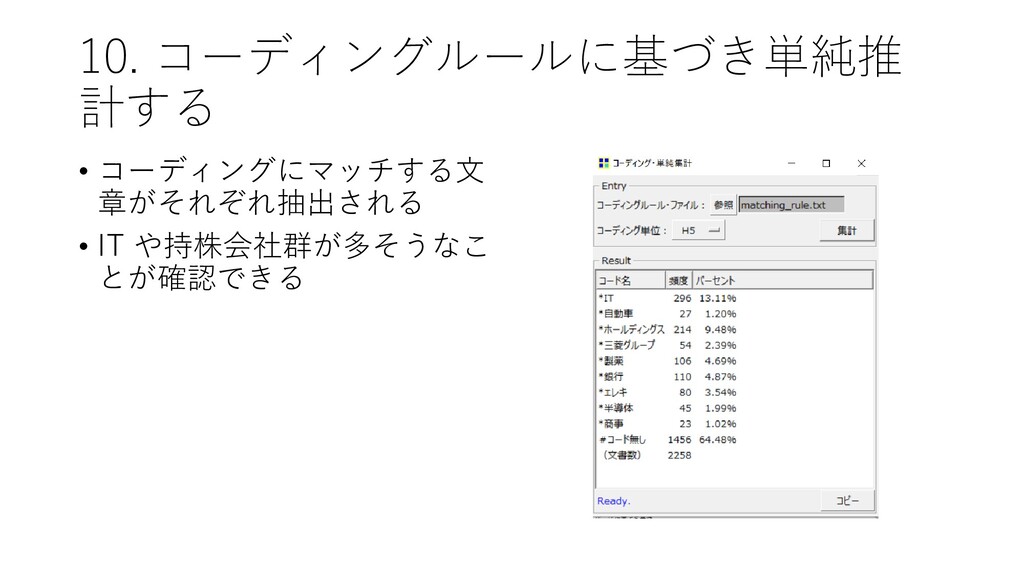
10. コーディングルールに基づき単純推 計する • コーディングにマッチする文 章がそれぞれ抽出される • IT や持株会社群が多そうなこ とが確認できる
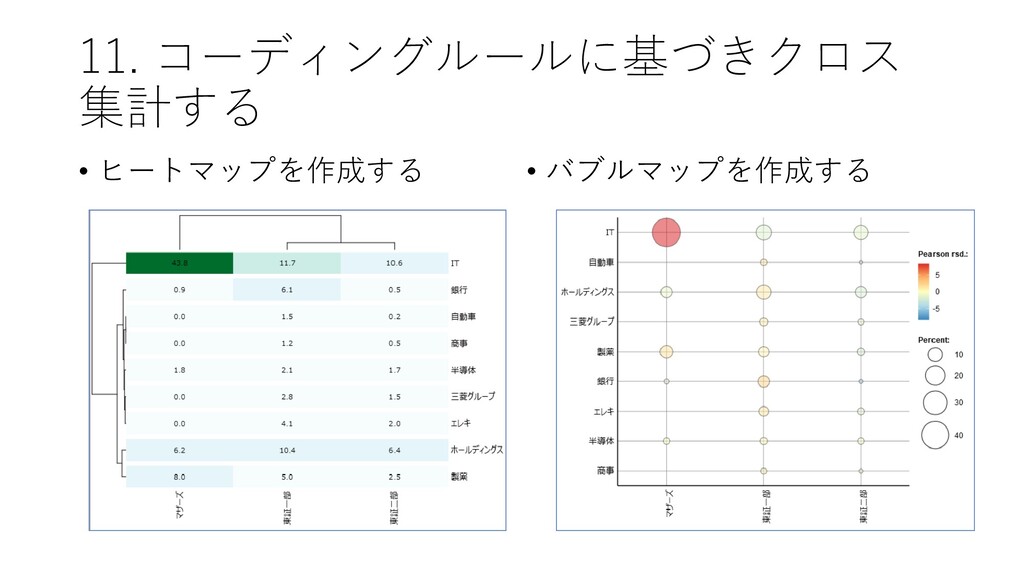
11. コーディングルールに基づきクロス 集計する • [ツール]-[コーディング]-[ク ロス集計] をクリックする
11. コーディングルールに基づきクロス 集計する • クロス集計[分類]を選択した上で, [集計] をクリックする • マザーズはITの割合が高いことが確認できる
11. コーディングルールに基づきクロス 集計する • ヒートマップを作成する • バブルマップを作成する
12. Jacaard 係数に基づき類似度行列を導 出する • [ツール]-[コーディング]-[類 似度行列]をクリックする
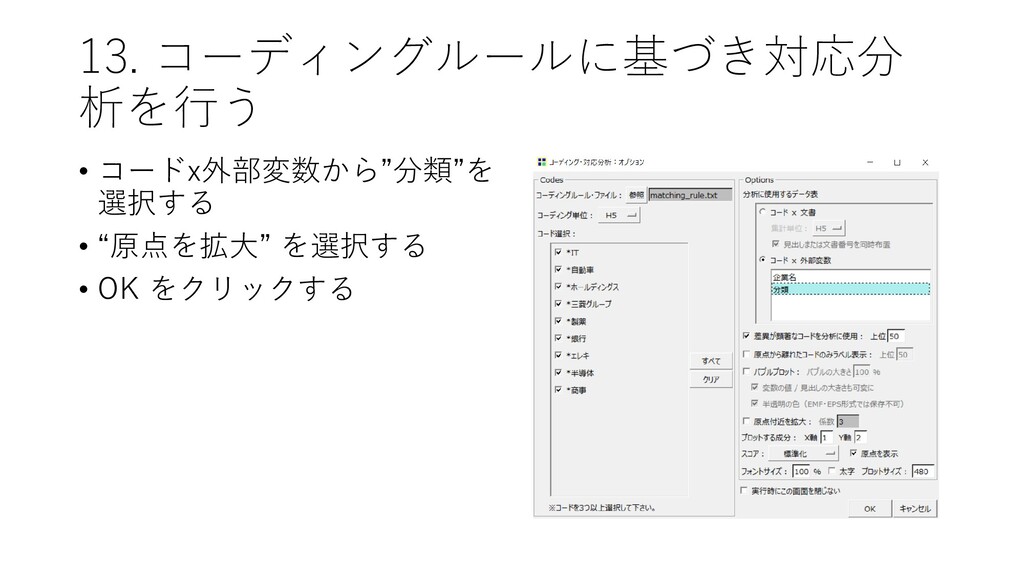
13. コーディングルールに基づき対応分 析を行う • [ツール]-[コーディング]-[対 応分析]をクリックする
13. コーディングルールに基づき対応分 析を行う • コードx外部変数から”分類”を 選択する • “原点を拡大” を選択する •
OK をクリックする
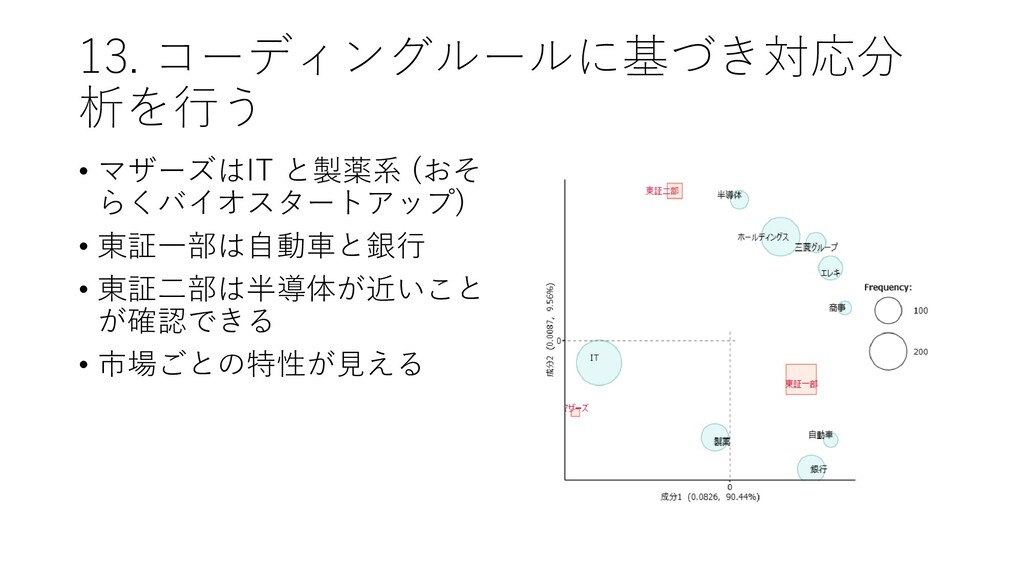
13. コーディングルールに基づき対応分 析を行う • マザーズはIT と製薬系 (おそ らくバイオスタートアップ) • 東証一部は自動車と銀行
• 東証二部は半導体が近いこと が確認できる • 市場ごとの特性が見える
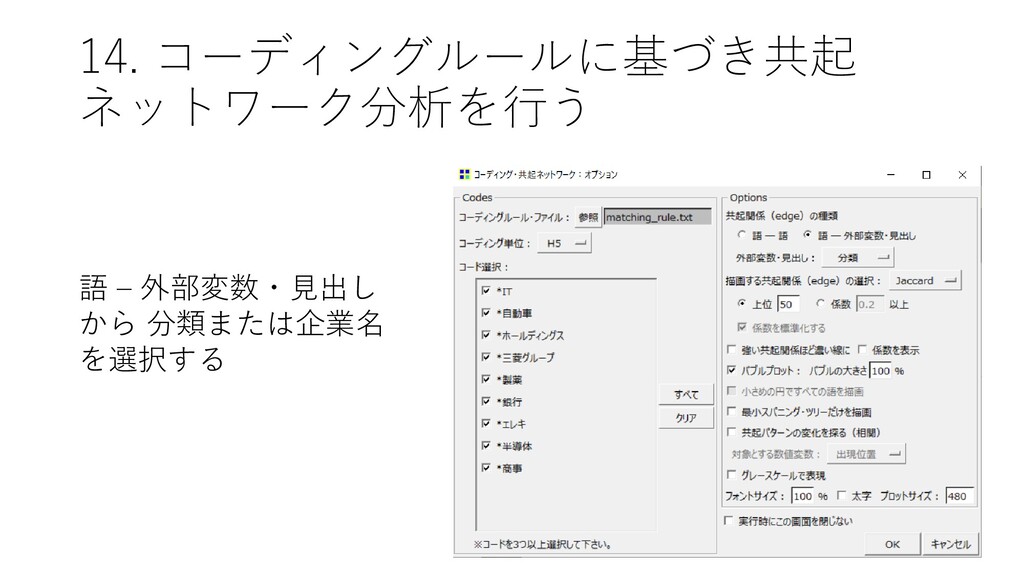
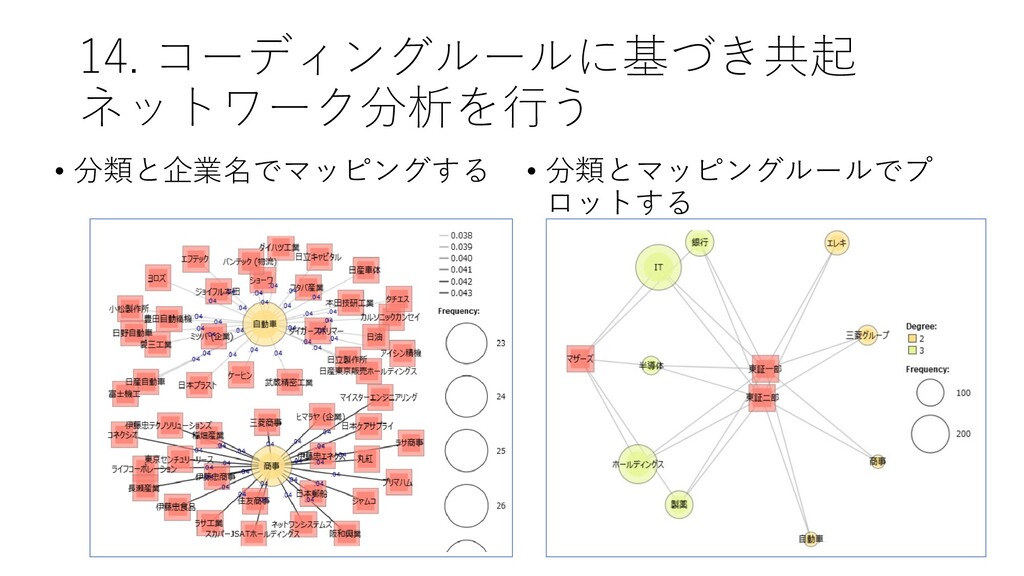
14. コーディングルールに基づき共起 ネットワーク分析を行う • [ツール]-[コーディング]-[共 起ネットワーク] をクリック する
14. コーディングルールに基づき共起 ネットワーク分析を行う 語 – 外部変数・見出し から 分類または企業名 を選択する
14. コーディングルールに基づき共起 ネットワーク分析を行う • 分類と企業名でマッピングする • 分類とマッピングルールでプ ロットする
今日の実習; その1 (windows ユーザ向け) • アップロードされている • (1) 東証一部/二部/マザーズの 企業概要データ
• (2)日本の経済/経営/社会/法学 者の概要データ • (3)日本のロック/ヒップホップ /フォークグループの概要デー タ を用いて, テキスト分析を行う • 語句の抽出 • 共起ネットワーク • 対応分析 • 多次元尺度構成法 • コーディングルールの設定 などを行い解析すること
None
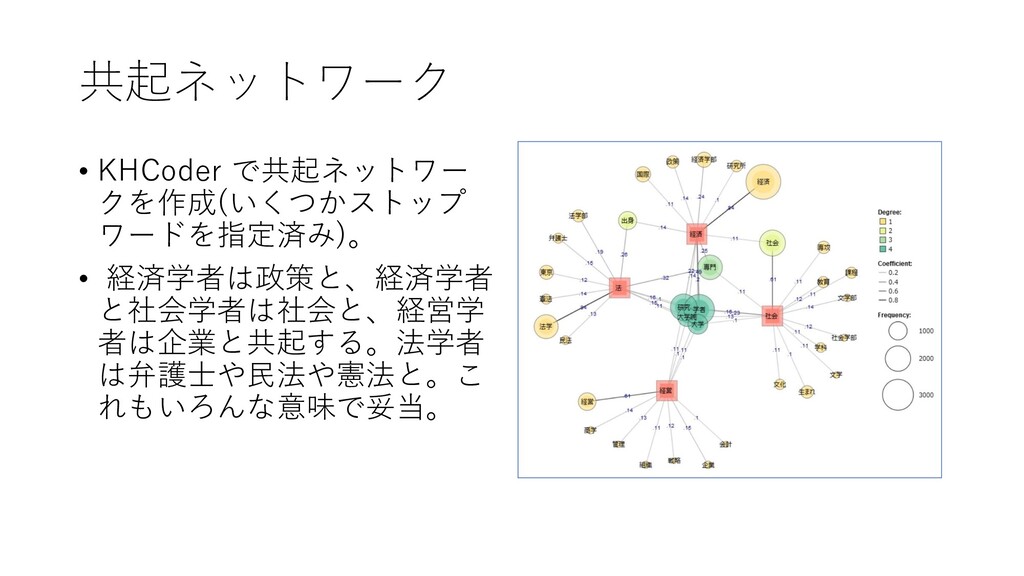
共起ネットワーク • KHCoder で共起ネットワー クを作成(いくつかストップ ワードを指定済み)。 • 経済学者は政策と、経済学者 と社会学者は社会と、経営学 者は企業と共起する。法学者
は弁護士や民法や憲法と。こ れもいろんな意味で妥当。
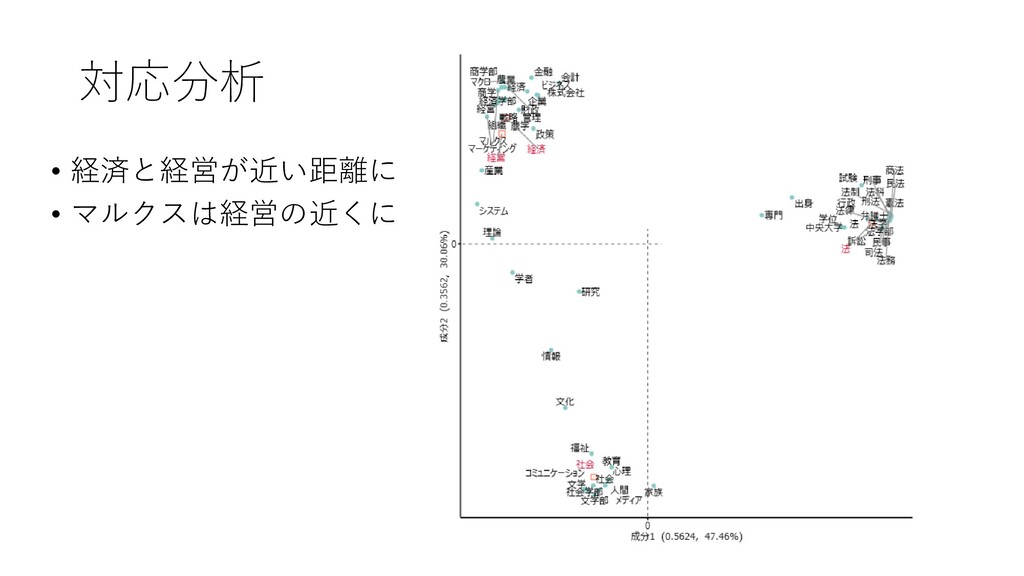
対応分析 • 経済と経営が近い距離に • マルクスは経営の近くに
3. 感情分析
5. 感情分析 • Ekman and Friesen (1971) • 表情の研究を通じ, 感情表現には普遍的
な6つの感情 (怒り, 嫌悪, 恐怖, 喜び, 悲 しみ, 驚き) があることを示す. • ただし, 西洋文化圏と東洋文化圏では表 情の表出に違いがある. • 参照 • 日本人の基本6感情の表情は「エクマン理 論」に従うか? – 人工知能を用いて検証 • https://academist- cf.com/journal/?p=10185 • https://ocw.mit.edu/courses/brain-and- cognitive-sciences/9-00sc-introduction- to-psychology-fall-2011/emotion- motivation/discussion-emotion/ © Paul Ekman. All rights reserved.
利用する Notebook • Google Colaboratory • https://colab.research.google.com/driv e/1EZ3NMw3I9FrjTFEPBQQRiD4TtUD zJ4YF
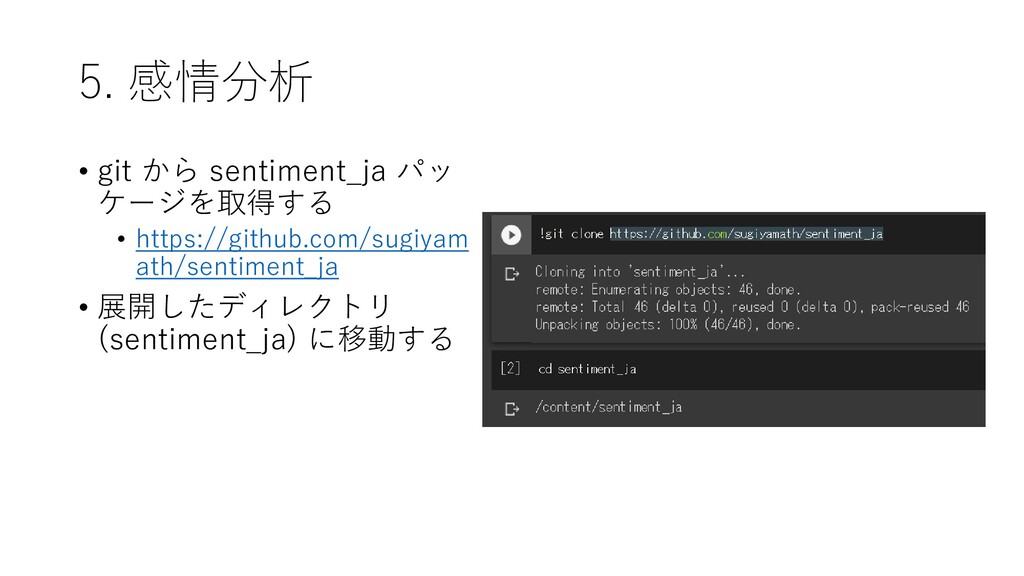
5. 感情分析 • git から sentiment_ja パッ ケージを取得する • https://github.com/sugiyam
ath/sentiment_ja • 展開したディレクトリ (sentiment_ja) に移動する
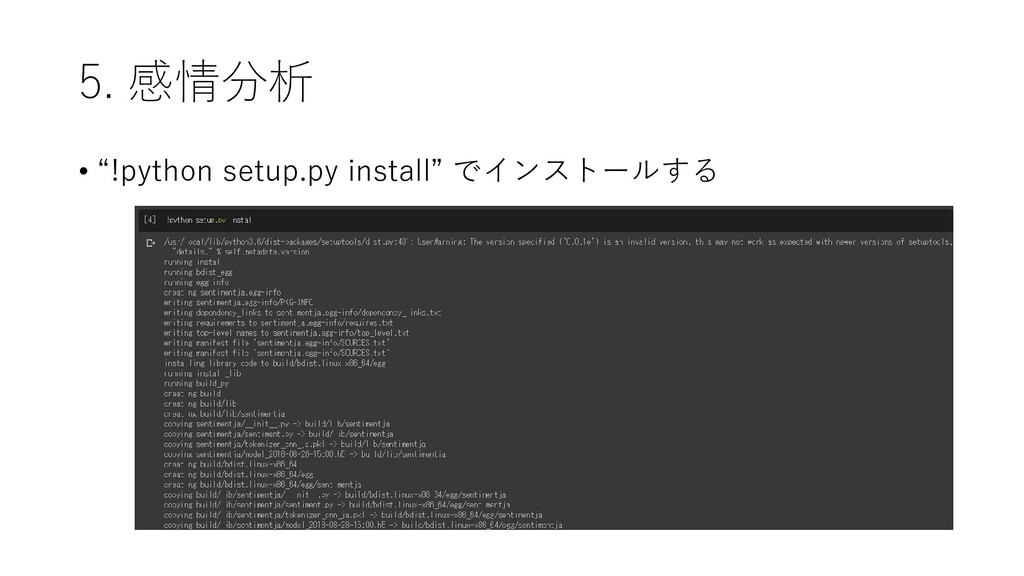
5. 感情分析 • “!python setup.py install” でインストールする
5. 感情分析 • Analyzer パッケージをインポートして, 文字列を取り込む • 「三田でラーメン二郎の本店でヤサイカラメアブラマシマシの二郎を 食べるのは素晴らしい」 •
「行列は切ない」
5. 感情分析 • 出力結果 • [{'sentence': '三田でラーメン二郎の本店でヤサイカラメアブラマシマ シの二郎を食べるのは素晴らしい', 'emotions': {'happy':
'7.0', 'sad': '1.0', 'disgust': '1.0', 'angry': '1.0', 'fear': '1.0', 'surprise': '12.0'}}, {'sentence': '行列は切ない', 'emotions': {'happy': '1.0', 'sad': '8.0', 'disgust': '5.0', 'angry': '3.0', 'fear': '1.0', 'surprise': '1.0’}}] • Happy, sad, disgust, angry, fear, surprise で分類される
参考文献 • pythonでgensimを使ってトピックモデル(LDA)を行う • https://paper.hatenadiary.jp/entry/2016/11/06/212149 • 「OK word2vec ! "マジ卍"の意味を教えて」
Pythonで word2vec実践してみた • https://www.randpy.tokyo/entry/python_word2vec • models.word2vec – Word2vec embeddings • https://radimrehurek.com/gensim/models/word2vec.html • 15分でできる日本語Word2Vec • https://qiita.com/makaishi2/items/63b7986f6da93dc55edd
参考文献(2) • Pythonで文字列を分割(区切り文字、改行、正規表現、文字 数) • https://note.nkmk.me/python-split-rsplit-splitlines-re/ • WindowsでNEologd辞書を比較的簡単に入れる方法 • https://qiita.com/zincjp/items/c61c441426b9482b5a48
• Windows 10 64bit で python + Mecab • https://qiita.com/kuro_hane/items/64e39d5deeb3f876b421 • Windows10(64bit)/Python3.6でmecab-python環境構築 • http://blog.livedoor.jp/oyajieng_memo/archives/1777479.html
参考文献(3) • MeCab: Yet Another Part-of-Speech and Morphological Analyzer •
https://taku910.github.io/mecab • mecab-ipadic-NEologd : Neologism dictionary for MeCab • https://github.com/neologd/mecab-ipadic-neologd • Word2Vecを用いた類義語の抽出が上手く行ったので、分析を まとめてみた • https://qiita.com/To_Murakami/items/cc225e7c9cd9c0ab641e • 自然言語処理による文書分類の基礎の基礎、トピックモデルを 学ぶ • https://qiita.com/icoxfog417/items/7c944cb29dd7cdf5e2b1
参考文献(4) • 日本語ツイートをEkmanの基本6感情で評価 • https://qiita.com/sugiyamath/items/7cabef39390c4a07e4d8 • ツイートから学習した感情分析モデル • https://qiita.com/sugiyamath/items/dc342d53b4e4e4ef9308
5. 成績評価の方法
成績評価(1) • 平常レポート (40パーセント; 必須) • 講義計画に示したように、複数の回で学生にはレポートを課します。 レポートは Word/PowerPoint形式のメールあるいは, github
経由で の提出が求められます(どの方法を採用するかは、初回の講義で決定し ます)。 • レポートには、(A.) 利用したデータセットとその内容, (B.) 分析の問 い, (C.) 分析手法, (D.) 分析結果 を明記する必要があります。ページ 数や文字数は問いませんが, これらの内容が含まれており, 講義中にア ナウンスする評価手法を満たす場合, 高い得点を得ることが出来ます。 • 平常点 (10パーセント) • 本講義は実習が多く含まれており, また取り扱うデータセットや内容も 多彩です。そのため、受講者同士が協力する必要があります。こうし た受講者の態度を評価するために、平常点を設けます。
成績評価(2) • 最終レポート (40パーセント; 必須) • 講義の最終回では最終レポートの報告会を行います。受講者は3名から4名か ら構成されるグループで、最終レポートの報告を行う必要があります(人数は 受講者の人数により変更される可能性があります)。最終レポートでは、プレ ゼンテーションの方法を学生は自由に選ぶことが出来ます。PowerPoint
以 外にも、Prezi などのアクティブプレゼンテーションツールや、他のプレゼ ンテーション手法を用いることが出来ます(プレゼンテーションツールについ ては、必要であれば講義内で説明する機会を設けます)。最終レポートでは、 以下の点について評価を行います。 (A.) グループ内の役割分担 (B.) データセットのユニークさおよび、それが適切に処理されているか (C.) 分析手法のユニークさおよび、それが適切に解析されているか (D.) プレゼンテーションのユニークさ (E.) 質疑応答にうまくリプライすることが出来ているか • 最終レポートの360°グループ評価 (10パーセント) • 3. の最終レポートについて、グループの自己評価および他のグループからの 評価を行います。3. で挙げた評価ポイントに基づき、グループメンバーおよ び他のグループは評価を行います。
Withdraw について • レポートを一回も提出していない場合 • Withdraw として扱います • レポートを1回提出している場合 •
Withdraw ではなく、単位取得の意思があるとみなします • レポート1回目提出後単位取得に進まない場合には, 12/27 10:45 (JST) までにSlack DM にてその旨おしらせください
次回以降の予告
11. データのビジュアライゼーションと ネットワーク分析 • これまでの回で取り上げてきたデータをわかりやすく研究で活 用する手法を学ぶことを目指します。 • Python やR などを用いたデータの可視化手法の確認や、
Tableau (https://www.tableau.com/ja-jp) などのデータ可 視化ソフトウェアの紹介および実習を行います。
11. Tableau のインストール • https://www.tableau.com/tft/activation からダウンロードしておいてください。 • メールアドレスを聞かれるので, 一橋の学生メールアドレス (hit-u.ac.jp
が入ったもの) を入力 • プロダクトキーには, (Slack でアナウンスしたコード) を指定してください
12. 機械学習 • R を用いて、木構造を用いて分類および回帰を行う決定木の手 法について、具体例の紹介および実習を行います。また、最終 レポートについての説明を行います。 • これまでに学んだ手法を用いデータ解析を行うことで、グルー プでのレポートをまとめます。このグループの決定を行います。
13. まとめと最終報告レポート • テーマ • 「◦◦のための実践的データ分析」 • 卒論や修論や博論の作成の入り口になるような、データの調達とその データの解析を, 講義で取り上げたデータセットおよび分析手法で実施
する • 分析単位はマクロ (国レベル) でもメソ (企業/産業レベル) でもミクロ (個人レベル) でも問いません • 利用できるデータセット • 特に制限なし • 利用できるツール • Tableau, Excel, SQL, Jupyternotebook (Python), R など, 特に制限なし
13. まとめと最終報告レポート • 評価方法 • グループ内での自己評価 • グループ外からの評価 アンケートシステムをManaba or
Google Docs で用意します。 • 評価基準 • (A.) グループ内の役割分担 (B.) データセットのユニークさおよび、それが適切に処理されているか (C.) 分析手法のユニークさおよび、それが適切に解析されているか (D.) プレゼンテーションのユニークさ (E.) 質疑応答にうまくリプライすることが出来ているか • 納品物 • プレゼンテーションに利用したSlack グループにアップロードすること
グループ分け(1) • グループα • 2116157u • 2116205a • 2117044k •
2117102m • グループβ • 2115096s • 2117156k • 2118025h • 2118091b • 2117003u • グループγ • 2113015y • 2116260h • 2117124s • 2117222s • 2117223k • グループμ • 1118077h • 1117199m • 1117044b • 1118051z • 1118256h • グループδ • 2117119z • 2117198z • 2118059x • 2118149u • 2118084y • グループε • 2116015m • 2115018k • 2116221c • 2117092k • 2117232h
THANKS
[email protected]
![経済学のための 実践的データ分析 4.10. テキスト分析 (後半)[補講] 38教室 一橋大学大学院 経済学研究科 原泰史 [email protected]](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![3. KHCoder に定点調査の自由記述データ を読み込む • KHCoder を開く • [プロジェクト] –[新規]](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_51.jpg){kind=link}
![3. KHCoder にデータを読み込む • [参照]をクリックして, 分析対 象ファイルを選ぶ • 分析対象とする列について[詳 細]](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_52.jpg){kind=link}
![4. データ分析前の処理をする • [前処理] – [テキストのチェッ ク]をクリックする • OKをクリックする 2019/12/17](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_53.jpg){kind=link}
![4. データ分析前の処理をする • 修正が必要である旨メッセージが表示される • [画面に表示] をクリックして, 問題点をチェックする • “テキストの自動修正”](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_54.jpg){kind=link}
![4. データ分析前の処理をする • 問題点が修正される. • [閉じる]をクリックする. 2019/12/17 56](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_55.jpg){kind=link}
![4. データ分析前の処理をする • [前処理] – [前処理の実行] を選択する • OKをクリックする 2019/12/17](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_56.jpg){kind=link}
{kind=link}
![4. データ分析前の処理をする • 複合語の検出を行う • [前処理]-[複合語の検出]-[茶筌 を利用]をクリックする](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_58.jpg){kind=link}
{kind=link}
![5. 頻出語の取り出しを行う • [ツール]-[抽出語]-[抽出語 リスト(Excel)]を選択する 2019/12/17 61](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![6. 共起ネットワークを書く • [ツール]-[抽出語]-[共起 ネットワーク]を選択する 2019/12/17 68](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![8. 多次元尺度構成法で解析する • 近接している語のパターンを 解析できる • [ツール]-[抽出語]-[多次元尺 度構成法]を選択する](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_73.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10. コーディングルールに基づき単純推 計する • [ツール]-[コーディング]-[単 純推計] をクリックする](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_78.jpg){kind=link}
{kind=link}
{kind=link}
![11. コーディングルールに基づきクロス 集計する • [ツール]-[コーディング]-[ク ロス集計] をクリックする](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_81.jpg){kind=link}
![11. コーディングルールに基づきクロス 集計する • クロス集計[分類]を選択した上で, [集計] をクリックする • マザーズはITの割合が高いことが確認できる](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_82.jpg){kind=link}
{kind=link}
![12. Jacaard 係数に基づき類似度行列を導 出する • [ツール]-[コーディング]-[類 似度行列]をクリックする](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_84.jpg){kind=link}
![13. コーディングルールに基づき対応分 析を行う • [ツール]-[コーディング]-[対 応分析]をクリックする](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_85.jpg){kind=link}
{kind=link}
{kind=link}
![14. コーディングルールに基づき共起 ネットワーク分析を行う • [ツール]-[コーディング]-[共 起ネットワーク] をクリック する](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_88.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS [email protected]](https://files.speakerdeck.com/presentations/ebe340c7f9d442bb9a03527f88b1f0db/slide_117.jpg){kind=link}