Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
金研究室 勉強会 『もう一度理解する Transformer(前編)』
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
winnie279
July 12, 2022
Science
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
金研究室 勉強会 『もう一度理解する Transformer(前編)』
もう一度理解するTransformer(前編), 中村勇士, 2022
winnie279
July 12, 2022
More Decks by winnie279
See All by winnie279
NowWay:訪⽇外国⼈旅⾏者向けの災害⽀援サービス
yjn279
0
23
「みえるーむ」(都知事杯Open Data Hackathon 2024 Final Stage)
yjn279
0
80
「みえるーむ」(都知事杯オープンデータ・ハッカソン 2024)
yjn279
0
84
5分で学ぶOpenAI APIハンズオン
yjn279
0
240
『確率思考の戦略論』
yjn279
0
160
Amazonまでのレコメンド入門
yjn279
1
190
もう一度理解するTransformer(後編)
yjn279
0
92
金研究室 勉強会 『U-Netとそのバリエーションについて』
yjn279
0
1k
金研究室 勉強会 『Seismic Data Augmentation Based on Conditional Generative Adversarial Networks』
yjn279
0
120
Other Decks in Science
See All in Science
あなたに水耕栽培を愛していないとは言わせない
mutsumix
1
340
AkarengaLT vol.40
hashimoto_kei
0
110
AkarengaLT vol.41
hashimoto_kei
1
140
Bリーグのショットデータを活用した得点期待値モデルの構築 / Construction of expected points model using shot data of B.LEAGUE
konakalab
0
140
ダメな自分の育て方―性格タイプの「劣等機能」から理解するニガテ克服術
ppillc
0
150
データベース03: 関係データモデル
trycycle
PRO
1
540
Bear-safety-running
akirun_run
0
150
人生を変えた一冊「独学大全」のはなし / Self-study ENCYCLOPEDIA: The Book Which Change My Life #独学大全 #EM推し本
expajp
0
160
データベース06: SQL (3/3) 副問い合わせ
trycycle
PRO
1
970
Conversation is the New Dashboard: 属人性を排除する第4世代BIツールの勢力図
shomaekawa
1
590
機械学習 - K-means & 階層的クラスタリング
trycycle
PRO
0
1.6k
白金鉱業Meetup_Vol.20 効果検証ことはじめ / Introduction to Impact Evaluation
brainpadpr
2
1.9k
Featured
See All Featured
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
200
Accessibility Awareness
sabderemane
1
130
Amusing Abliteration
ianozsvald
1
200
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
300
Context Engineering - Making Every Token Count
addyosmani
9
950
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.4k
Become a Pro
speakerdeck
PRO
31
6k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
230
The Cost Of JavaScript in 2023
addyosmani
55
10k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
430
Transcript
もう一度理解する Transformer(前編) 金研 機械学習勉強会 2022/07/12 中村勇士
もう一度とは? • 『Attention is all you need』読みました ◦ 見返してみたら、約1年前でした(見たい方は こちら)
◦ 難しくてなかなか理解できず → リベンジします • Transformerとは? ◦ 2017年の自然言語処理モデル ◦ 高性能、様々な分野で使われる ・BERT → Google 翻訳 ・GPT-3 → 1ヶ月間ブログを書いたのに AIだと気づかれず ・ViT → 画像認識
Transformerまでの道のり • なぜ難しかったのか? ◦ 基本的にAttentionを知らなかった ◦ ほかの文章生成モデルを知らなかった • どうすれば良いか? ◦
まずは基本的なAttentionを理解する! ◦ ほかの文章生成モデルを知る! • RNN • Bi-RNN • Encoder-Decoder • Attention • Transformer • BERT or GPT-3 or ViT 機械学習勉強会で 出てきた 前半 RNNを不使用 後半以降 RNNを不使用
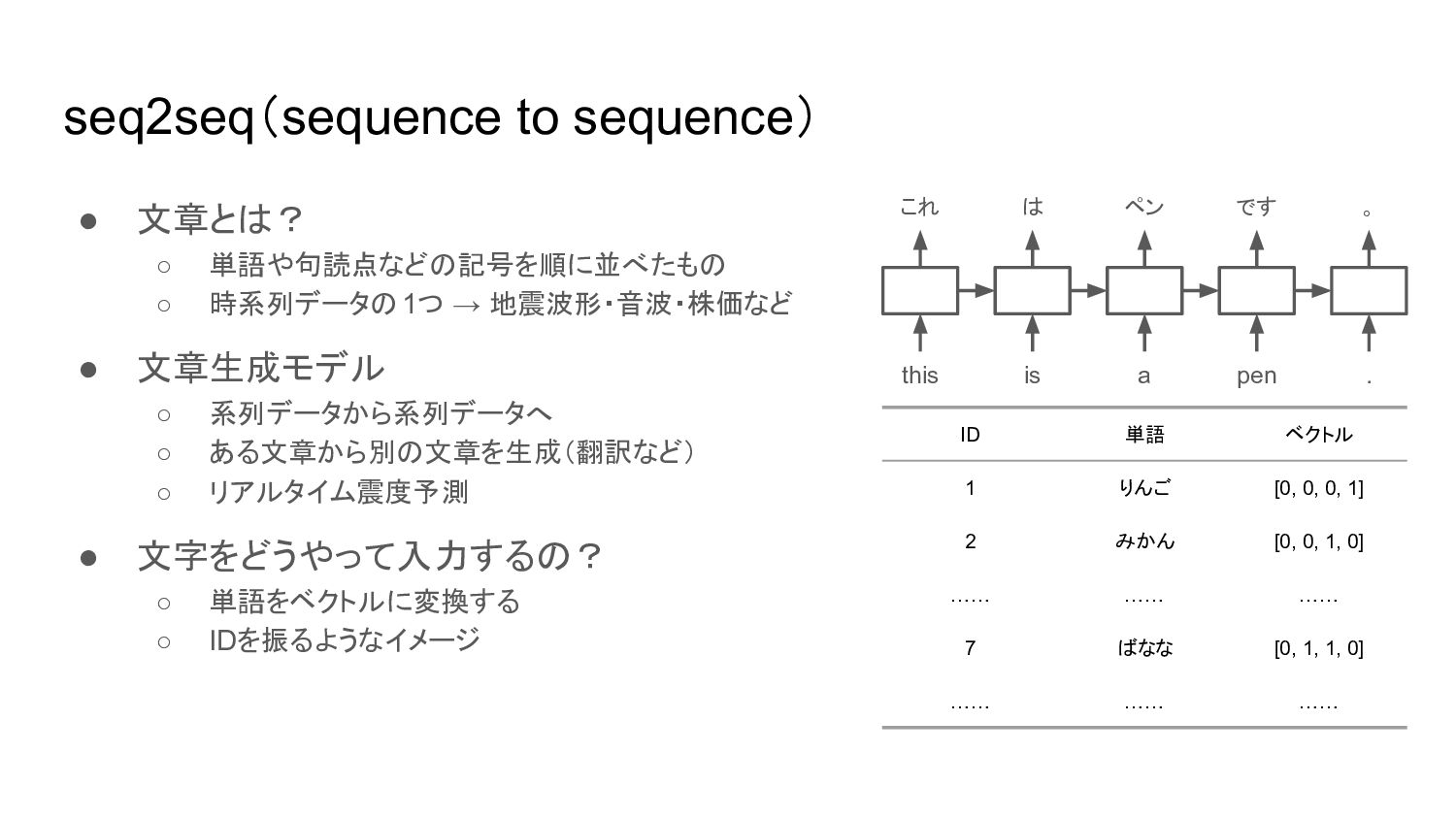
seq2seq(sequence to sequence) • 文章とは? ◦ 単語や句読点などの記号を順に並べたもの ◦ 時系列データの1つ →
地震波形・音波・株価など • 文章生成モデル ◦ 系列データから系列データへ ◦ ある文章から別の文章を生成(翻訳など) ◦ リアルタイム震度予測 • 文字をどうやって入力するの? ◦ 単語をベクトルに変換する ◦ IDを振るようなイメージ this is . a pen これ は ペン です 。 ID 単語 ベクトル 1 りんご [0, 0, 0, 1] 2 みかん [0, 0, 1, 0] …… …… …… 7 ばなな [0, 1, 1, 0] …… …… ……
• 前後の情報を持てる • 文字の説明 ◦ x:入力データ ◦ h:隠れ状態 ◦ W,
U:重み ◦ b:バイアス Bi-RNN(Bidirectional RNN) this h s is . a pen これ は ペン です 。 結合 以降の情報
• 文脈ベクトル(context vector)をもつ • 入力と出力を異なる長さにできる • 文字の説明 ◦ h:隠れ状態 ◦
y:出力 ◦ c:文脈ベクトル Encoder-Decoder this h t is . a pen <bos> これ は は これ 文脈ベクトル 1つ前の出力 隠れ状態
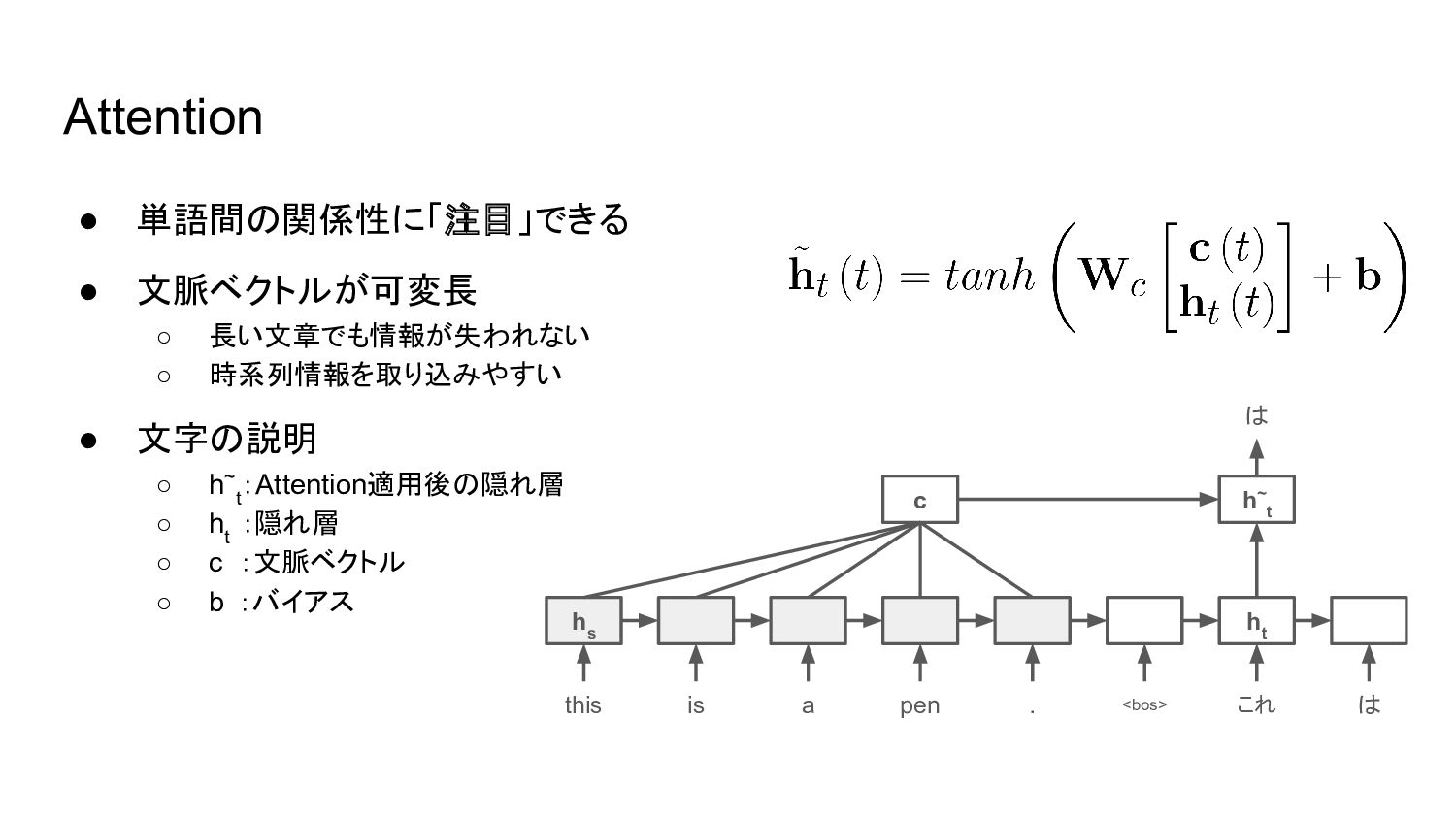
• 単語間の関係性に「注目」できる • 文脈ベクトルが可変長 ◦ 長い文章でも情報が失われない ◦ 時系列情報を取り込みやすい • 文字の説明
◦ h~ t :Attention適用後の隠れ層 ◦ h t :隠れ層 ◦ c :文脈ベクトル ◦ b :バイアス Attention this h s h t h~ t c is . a pen <bos> これ は は
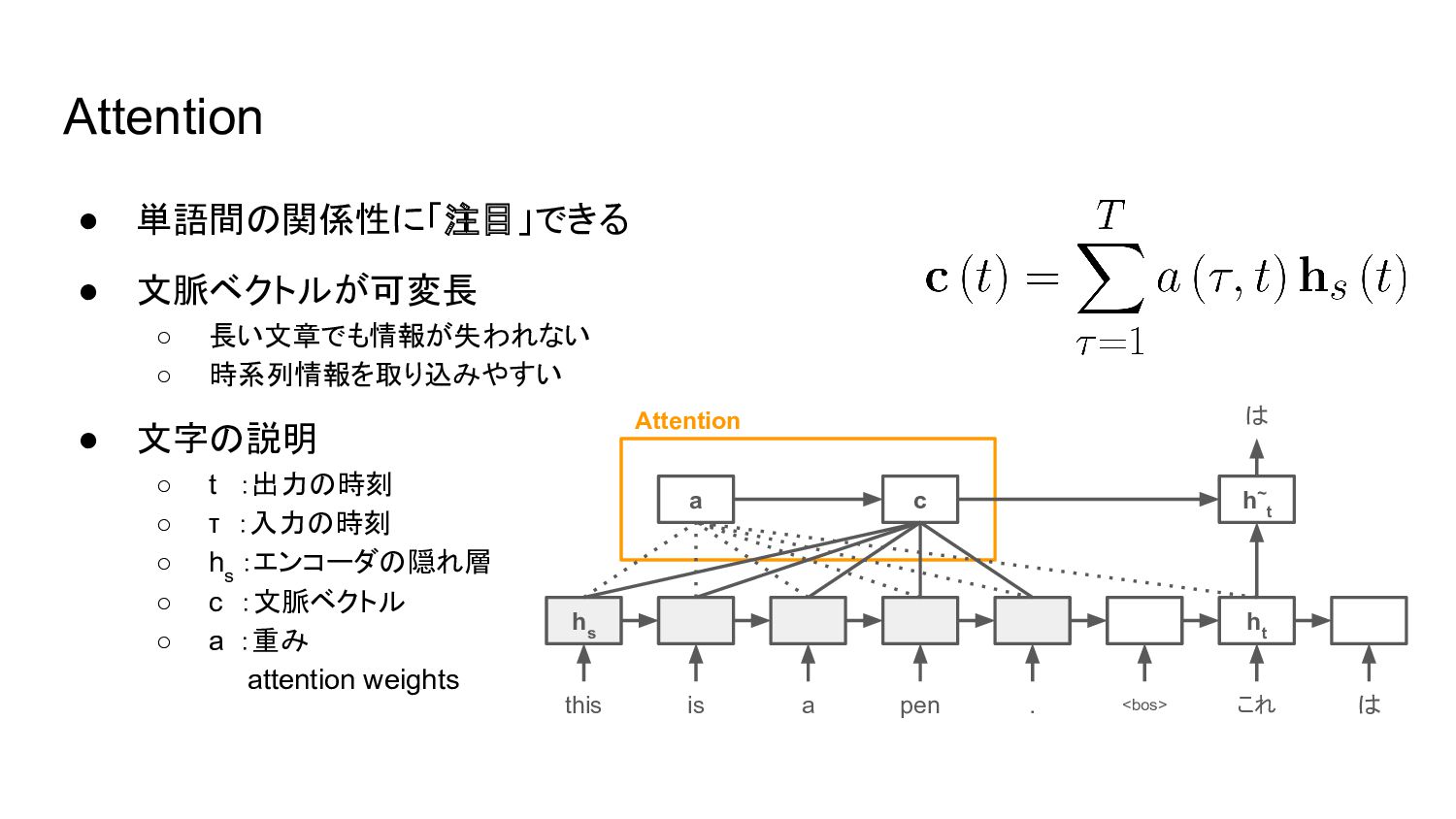
• 単語間の関係性に「注目」できる • 文脈ベクトルが可変長 ◦ 長い文章でも情報が失われない ◦ 時系列情報を取り込みやすい • 文字の説明
◦ t :出力の時刻 ◦ τ :入力の時刻 ◦ h s :エンコーダの隠れ層 ◦ c :文脈ベクトル ◦ a :重み attention weights Attention this h s h t h~ t c a is . a pen <bos> これ は は Attention
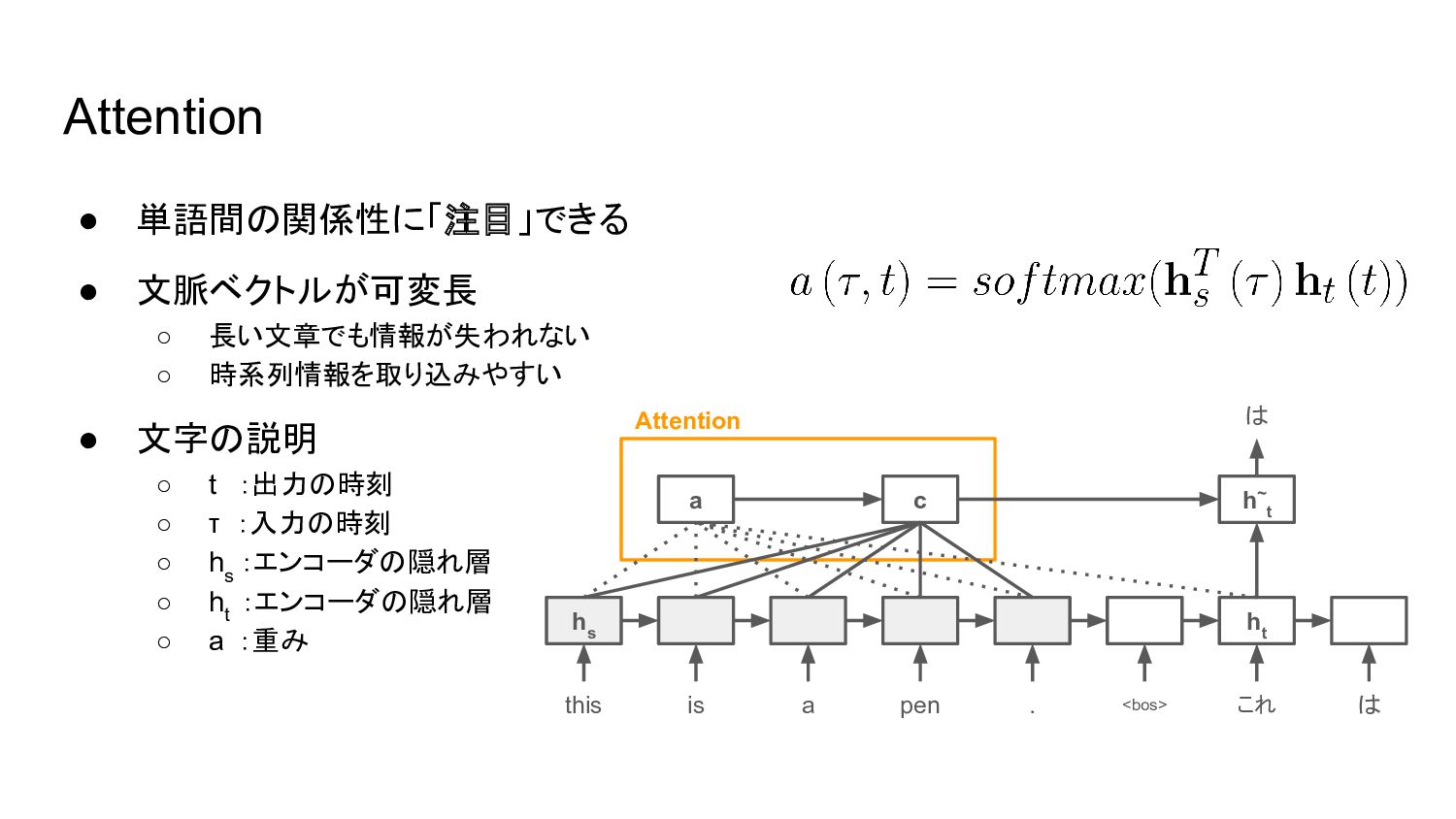
• 単語間の関係性に「注目」できる • 文脈ベクトルが可変長 ◦ 長い文章でも情報が失われない ◦ 時系列情報を取り込みやすい • 文字の説明
◦ t :出力の時刻 ◦ τ :入力の時刻 ◦ h s :エンコーダの隠れ層 ◦ h t :エンコーダの隠れ層 ◦ a :重み Attention this h s h t h~ t c a is . a pen <bos> これ は は Attention
• 単語間の関係性に「注目」できる • 文脈ベクトルが可変長 ◦ 長い文章でも情報が失われない ◦ 時系列情報を取り込みやすい • まとめ
◦ AttentionはEncoder-Decoderに c(t)を加えたもの ◦ cは単語と単語の関係性から 文脈ベクトルを合成する Attention this h s h t h~ t c a is . a pen <bos> これ は は Attention
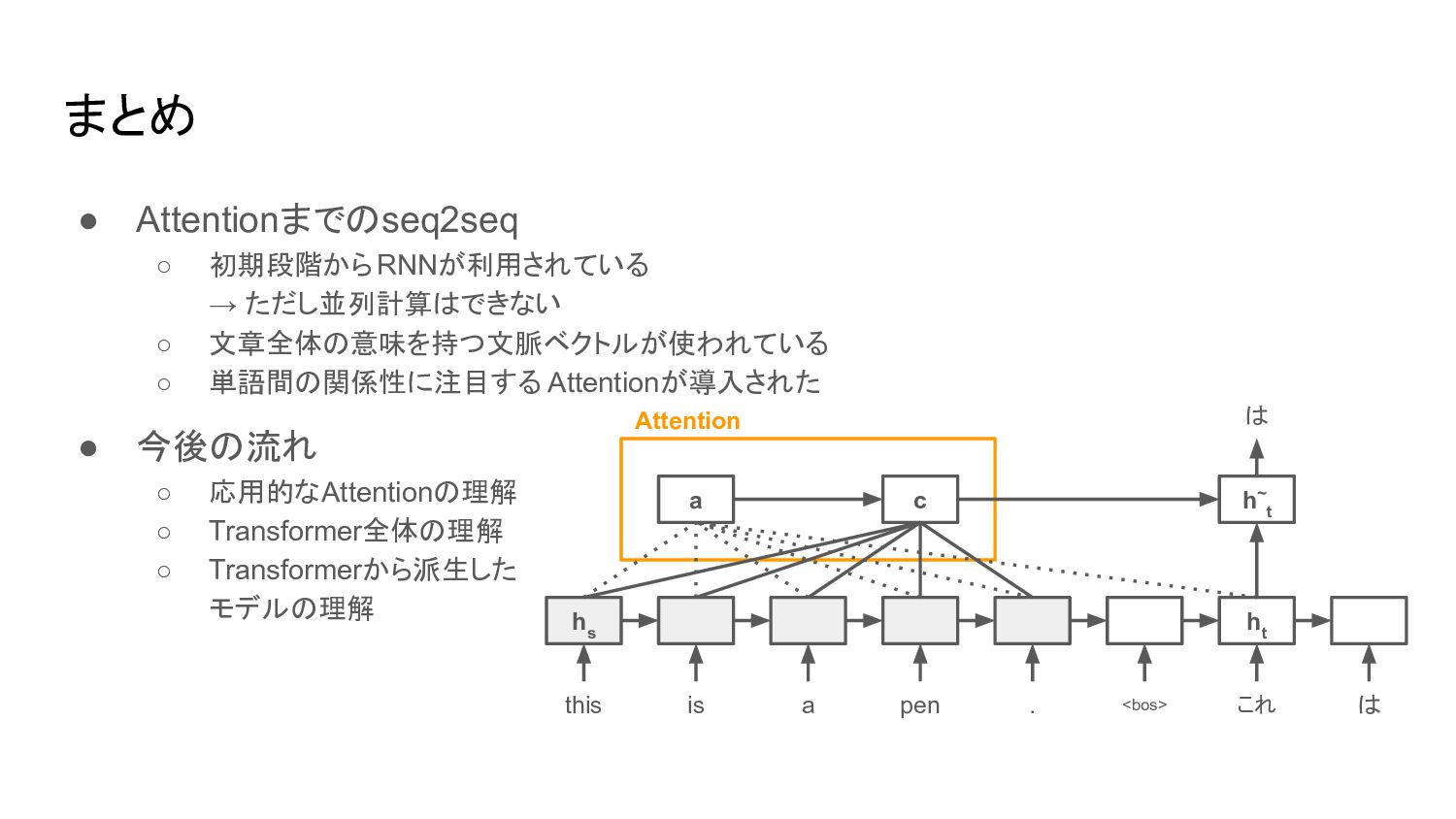
まとめ • Attentionまでのseq2seq ◦ 初期段階からRNNが利用されている → ただし並列計算はできない ◦ 文章全体の意味を持つ文脈ベクトルが使われている ◦
単語間の関係性に注目する Attentionが導入された • 今後の流れ ◦ 応用的なAttentionの理解 ◦ Transformer全体の理解 ◦ Transformerから派生した モデルの理解 this h s h t h~ t c a is . a pen <bos> これ は は Attention
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}