Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
もう一度理解するTransformer(後編)
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
winnie279
September 06, 2022
Science
92
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
もう一度理解するTransformer(後編)
もう一度理解するTransformer(後編), 中村勇士, 2022
winnie279
September 06, 2022
More Decks by winnie279
See All by winnie279
NowWay:訪⽇外国⼈旅⾏者向けの災害⽀援サービス
yjn279
0
23
「みえるーむ」(都知事杯Open Data Hackathon 2024 Final Stage)
yjn279
0
80
「みえるーむ」(都知事杯オープンデータ・ハッカソン 2024)
yjn279
0
84
5分で学ぶOpenAI APIハンズオン
yjn279
0
240
『確率思考の戦略論』
yjn279
0
160
Amazonまでのレコメンド入門
yjn279
1
190
金研究室 勉強会 『もう一度理解する Transformer(前編)』
yjn279
0
130
金研究室 勉強会 『U-Netとそのバリエーションについて』
yjn279
0
1k
金研究室 勉強会 『Seismic Data Augmentation Based on Conditional Generative Adversarial Networks』
yjn279
0
120
Other Decks in Science
See All in Science
医療 LLM ベンチマークの現在地:多面的評価 と日本ローカライズ
analokmaus
1
490
データベース06: SQL (3/3) 副問い合わせ
trycycle
PRO
1
970
AI bij literatuuronderzoek in de wetenschap
voginip
0
170
生成AIの現状と展望
tagtag
PRO
0
130
コミュニティサイエンスの実践@日本認知科学会2025
hayataka88
0
170
先端因果推論特別研究チームの研究構想と 人間とAIが協働する自律因果探索の展望
sshimizu2006
3
930
俺たちは本当に分かり合えるのか? ~ PdMとスクラムチームの “ずれ” を科学する
bonotake
2
2.4k
力学系から見た現代的な機械学習
hanbao
4
4.2k
「遂行理論の未来」(松島斉教授最終講義記念セッションの発表資料)
shunyanoda
0
910
アクシズを探せ! 各勢力の位置関係についての考察
miu_crescent
PRO
1
340
Rashomon at the Sound: Reconstructing all possible paleoearthquake histories in the Puget Lowland through topological search
cossatot
0
980
生成AI・プレプリント時代における 研究成果公開の再設計 ― トップカンファレンス文化はどこへ向かうのか / Redesigning the Dissemination of Research Outputs in the Age of Generative AI and Preprints — Where Is the Top-Conference Culture Heading?
ykiyota
0
15k
Featured
See All Featured
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
420
Code Reviewing Like a Champion
maltzj
528
40k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
The Pragmatic Product Professional
lauravandoore
37
7.3k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
320
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
150
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
600
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
270
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
360
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Transcript
もう一度理解する Transformer(後編) 金研 機械学習勉強会 2022/09/06 中村勇士
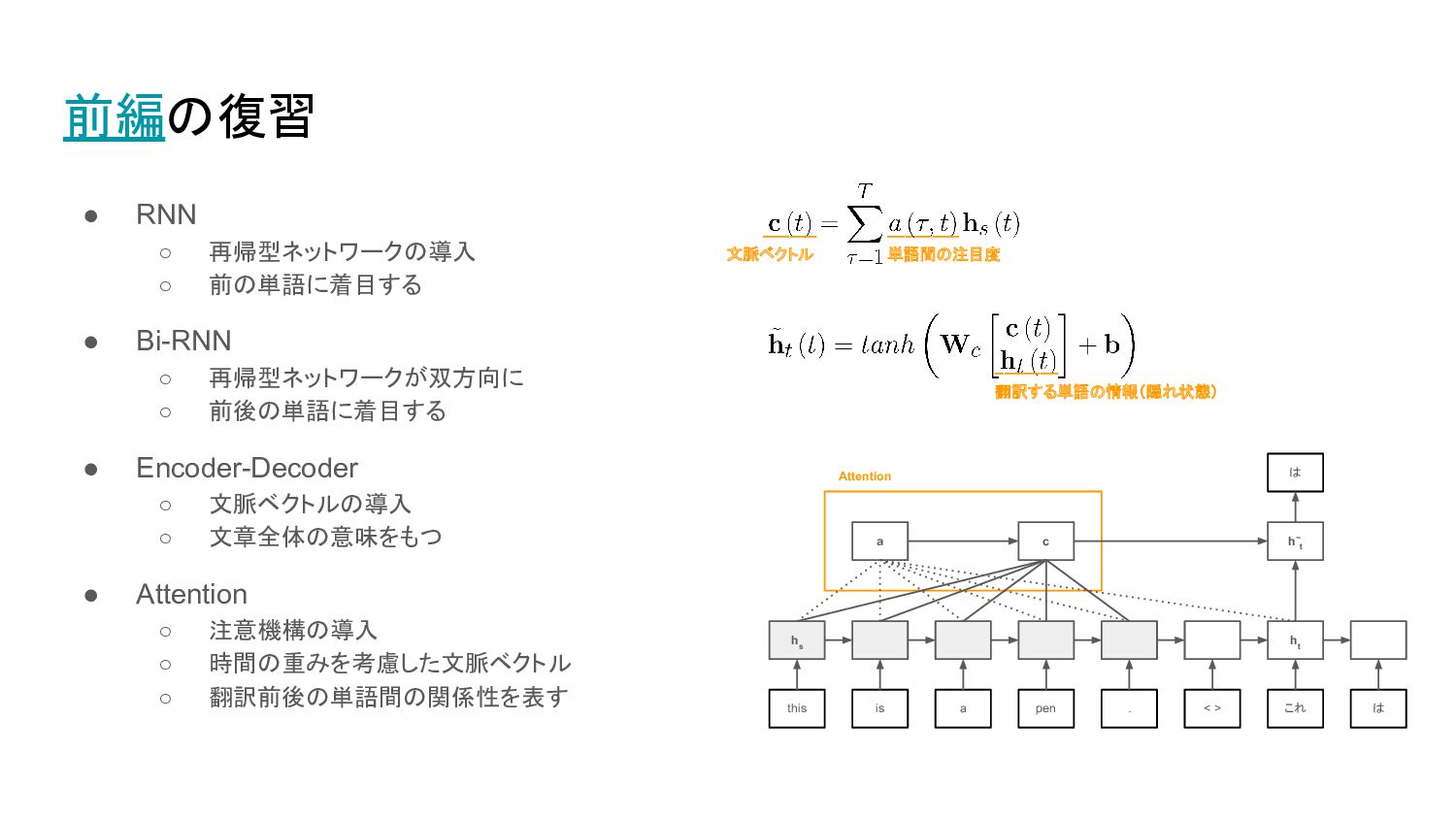
–––––––– 単語間の注目度 前編の復習 • RNN ◦ 再帰型ネットワークの導入 ◦ 前の単語に着目する •
Bi-RNN ◦ 再帰型ネットワークが双方向に ◦ 前後の単語に着目する • Encoder-Decoder ◦ 文脈ベクトルの導入 ◦ 文章全体の意味をもつ • Attention ◦ 注意機構の導入 ◦ 時間の重みを考慮した文脈ベクトル ◦ 翻訳前後の単語間の関係性を表す this h s h t h~ t c a is . a pen < > これ は は Attention –––––– 文脈ベクトル ––––––– 翻訳する単語の情報(隠れ状態)
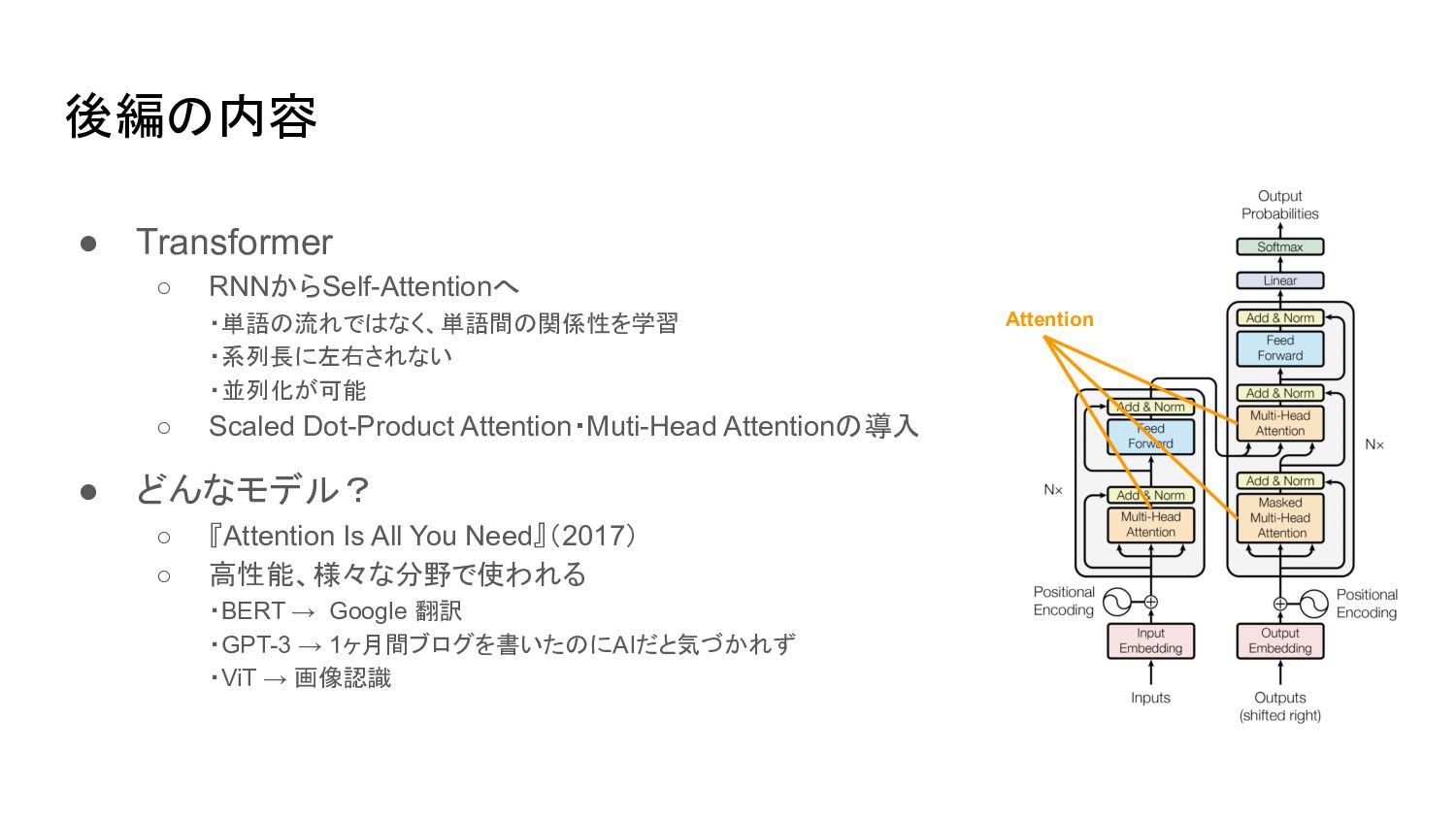
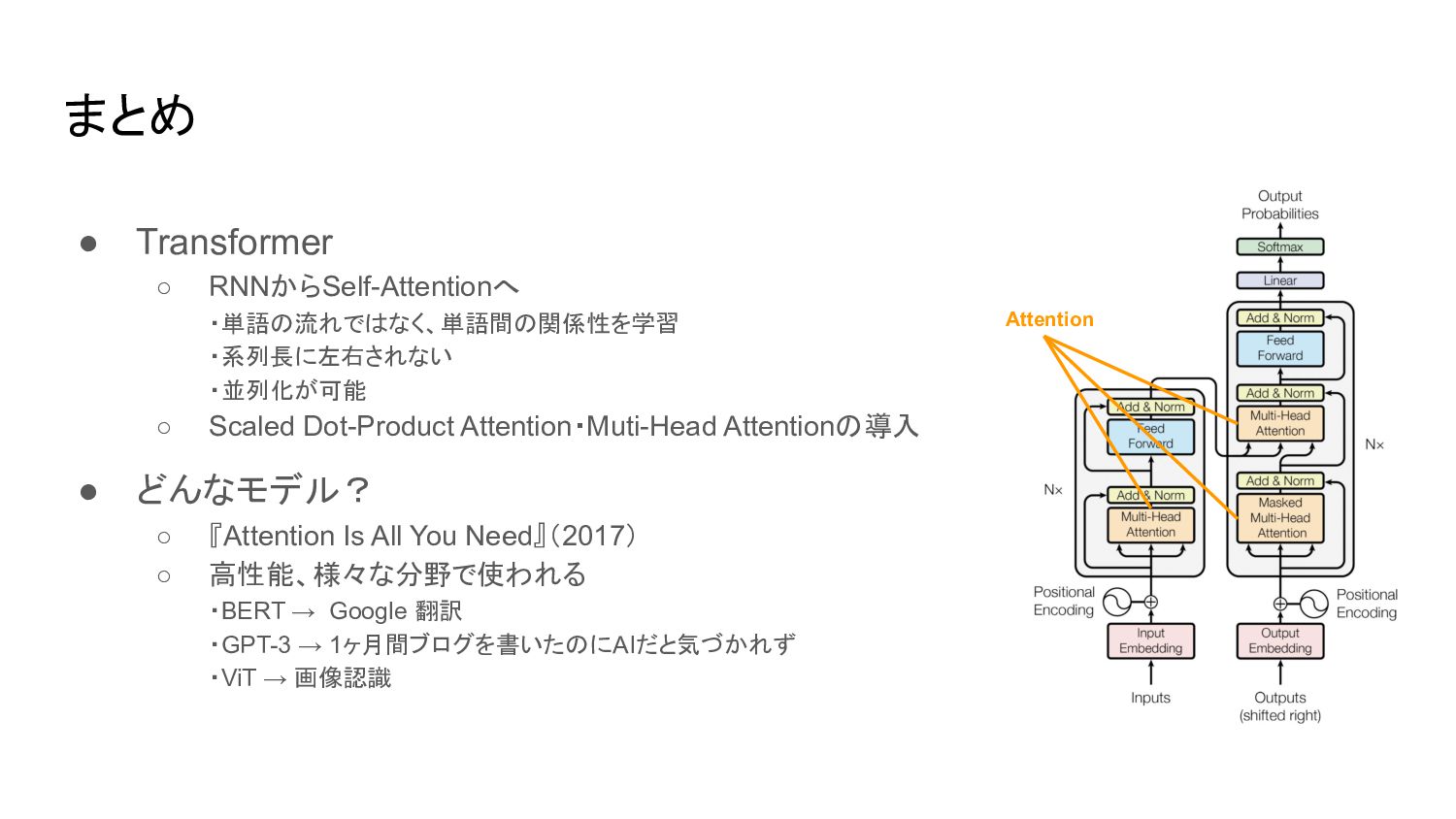
• Transformer ◦ RNNからSelf-Attentionへ ・単語の流れではなく、単語間の関係性を学習 ・系列長に左右されない ・並列化が可能 ◦ Scaled Dot-Product
Attention・Muti-Head Attentionの導入 • どんなモデル? ◦ 『Attention Is All You Need』(2017) ◦ 高性能、様々な分野で使われる ・BERT → Google 翻訳 ・GPT-3 → 1ヶ月間ブログを書いたのにAIだと気づかれず ・ViT → 画像認識 後編の内容 Attention
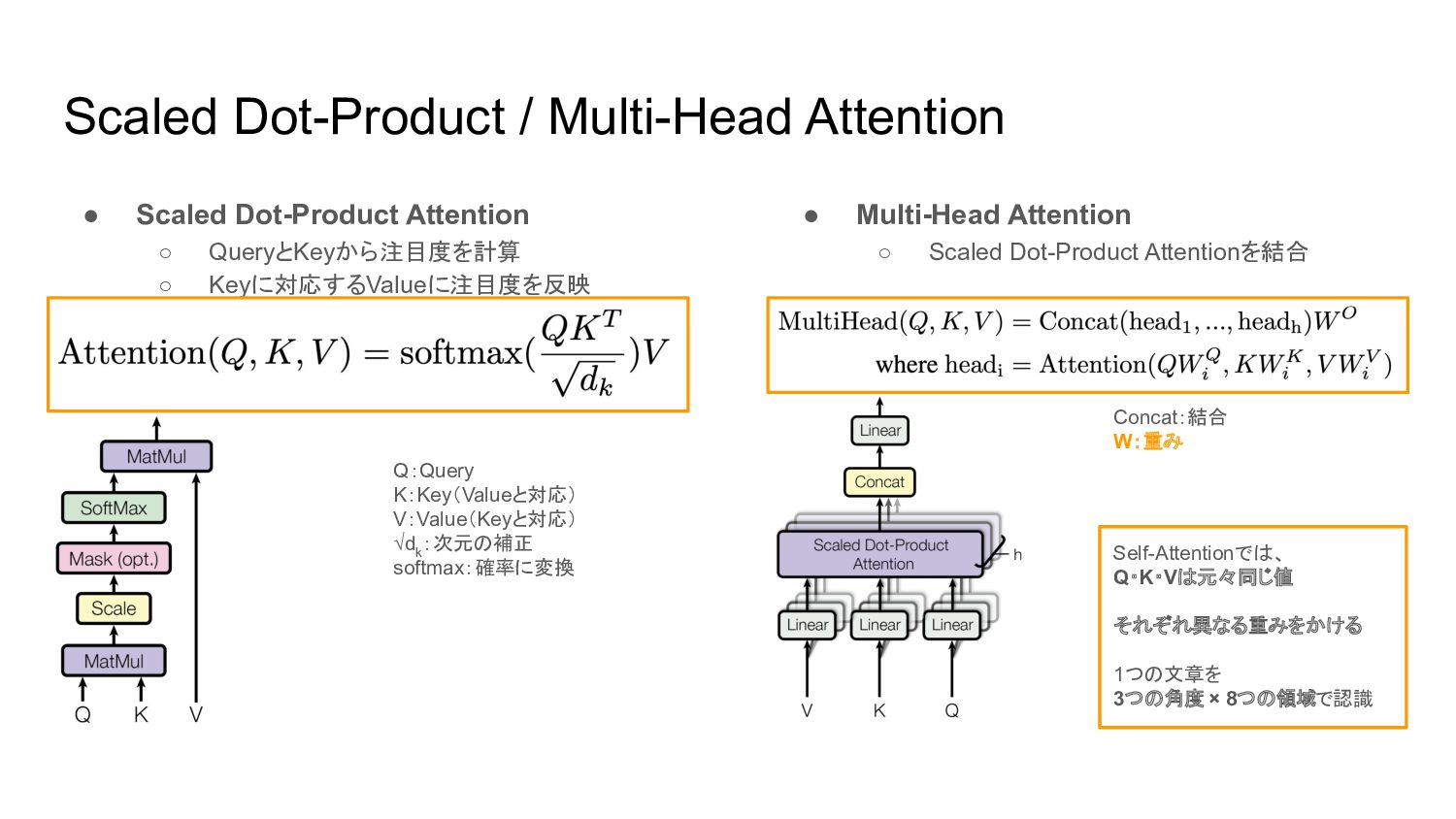
• Multi-Head Attention ◦ Scaled Dot-Product Attentionを結合 Scaled Dot-Product /
Multi-Head Attention • Scaled Dot-Product Attention ◦ QueryとKeyから注目度を計算 ◦ Keyに対応するValueに注目度を反映 Q:Query K:Key(Valueと対応) V:Value(Keyと対応) √d k :次元の補正 softmax:確率に変換 –––––––––––––––––––––––––––– 注目度 Concat:結合 W:重み
• Multi-Head Attentionの使い方の話 ◦ 今まで: 翻訳前後の単語間の関係性に注目 ◦ Self-Attention: 文章内の単語間の関係性に注目 ◦
RNNからSelf-Attentionへ Self-Attention V K Q V K Q Self-Attention Attention
Concat:結合 W:重み • Multi-Head Attention ◦ Scaled Dot-Product Attentionを結合 Scaled
Dot-Product / Multi-Head Attention • Scaled Dot-Product Attention ◦ QueryとKeyから注目度を計算 ◦ Keyに対応するValueに注目度を反映 Q:Query K:Key(Valueと対応) V:Value(Keyと対応) √d k :次元の補正 softmax:確率に変換 Self-Attentionでは、 Q・K・Vは元々同じ値 それぞれ異なる重みをかける 1つの文章を 3つの角度 × 8つの領域で認識
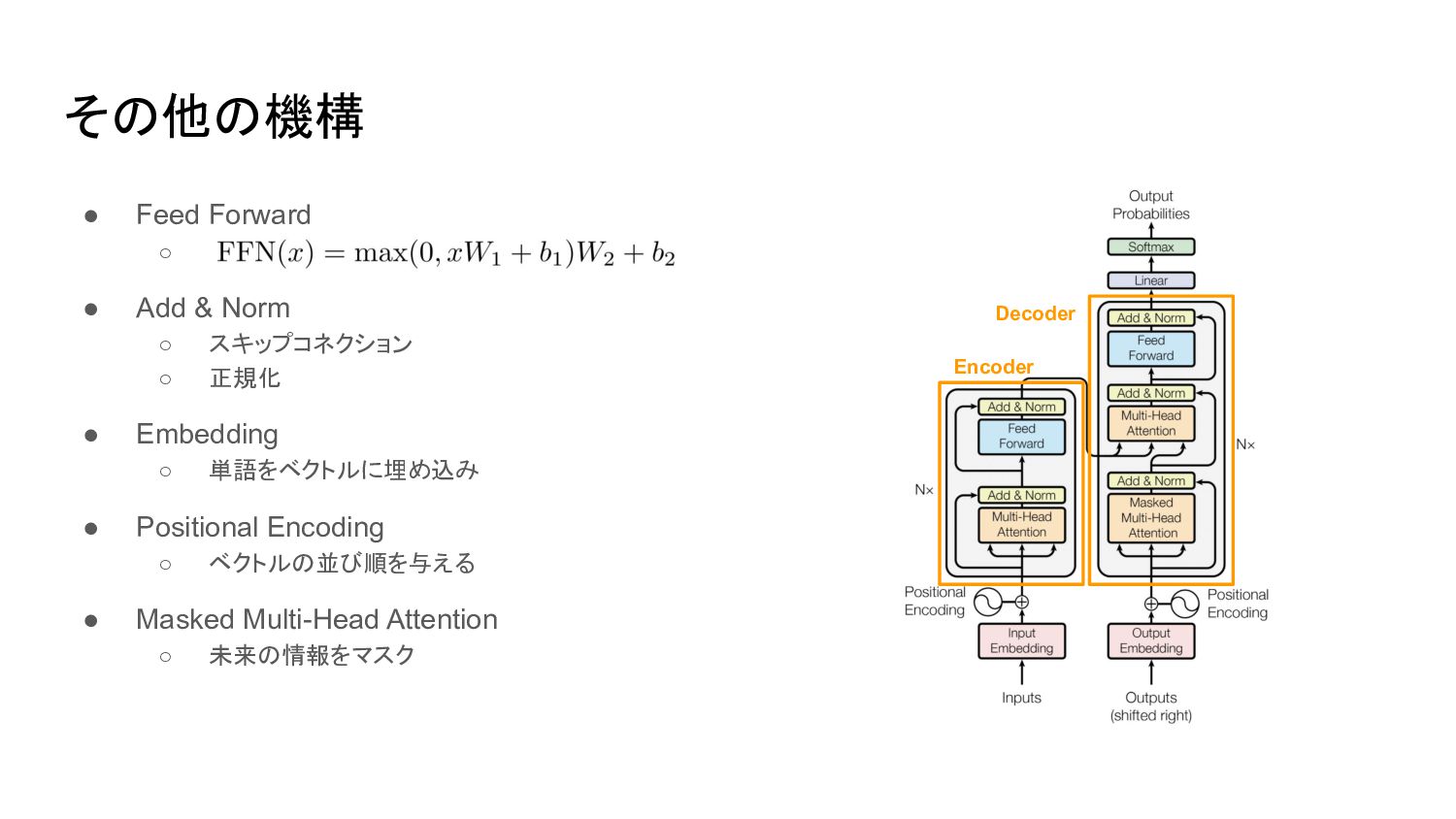
• Feed Forward ◦ • Add & Norm ◦ スキップコネクション
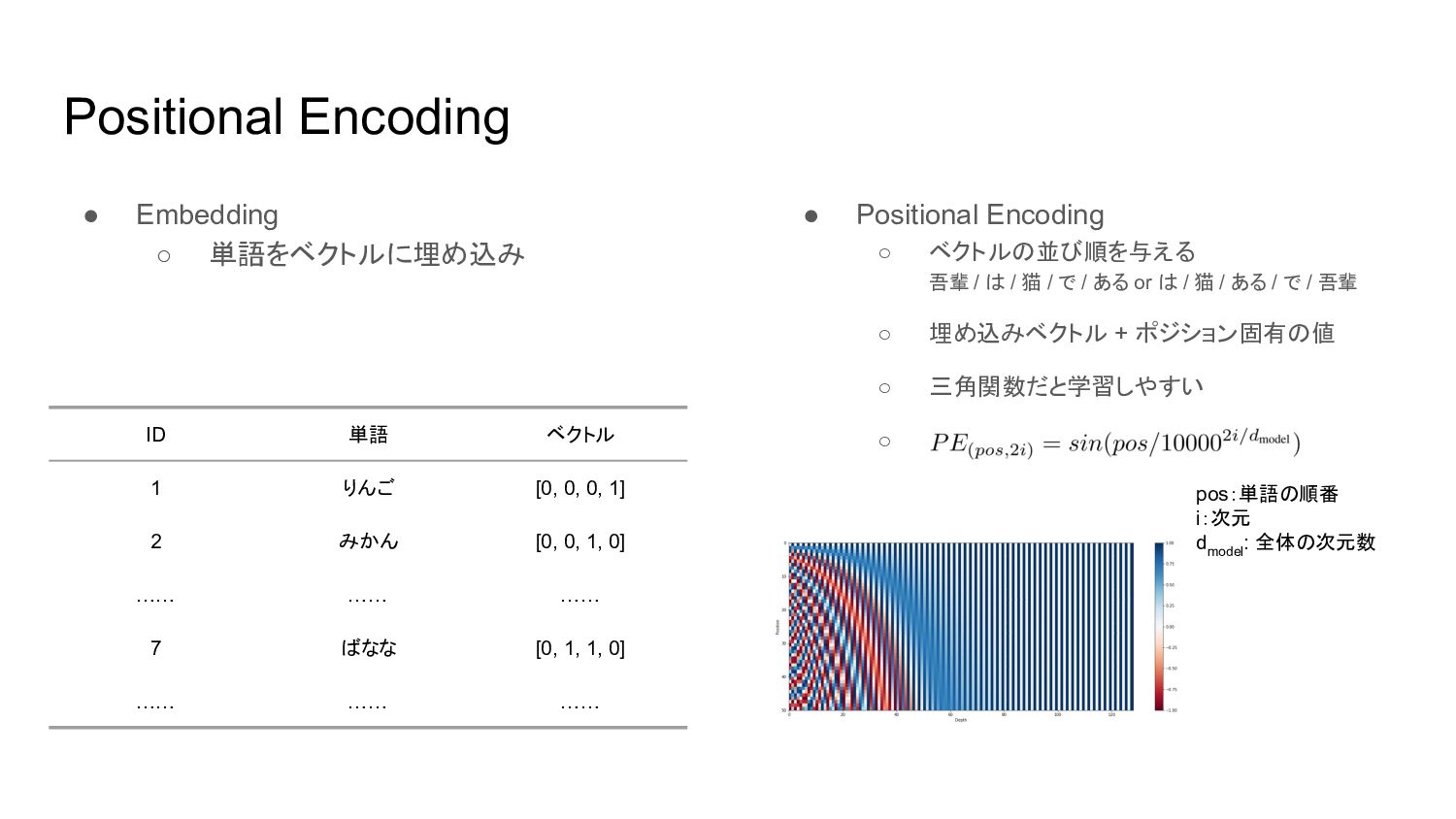
◦ 正規化 • Embedding ◦ 単語をベクトルに埋め込み • Positional Encoding ◦ ベクトルの並び順を与える • Masked Multi-Head Attention ◦ 未来の情報をマスク その他の機構 Encoder Decoder
• Positional Encoding ◦ ベクトルの並び順を与える 吾輩 / は / 猫
/ で / ある or は / 猫 / ある / で / 吾輩 ◦ 埋め込みベクトル + ポジション固有の値 ◦ 三角関数だと学習しやすい ◦ Positional Encoding • Embedding ◦ 単語をベクトルに埋め込み ID 単語 ベクトル 1 りんご [0, 0, 0, 1] 2 みかん [0, 0, 1, 0] …… …… …… 7 ばなな [0, 1, 1, 0] …… …… …… pos:単語の順番 i:次元 d model : 全体の次元数
• Transformer ◦ RNNからSelf-Attentionへ ・単語の流れではなく、単語間の関係性を学習 ・系列長に左右されない ・並列化が可能 ◦ Scaled Dot-Product
Attention・Muti-Head Attentionの導入 • どんなモデル? ◦ 『Attention Is All You Need』(2017) ◦ 高性能、様々な分野で使われる ・BERT → Google 翻訳 ・GPT-3 → 1ヶ月間ブログを書いたのにAIだと気づかれず ・ViT → 画像認識 まとめ Attention
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}