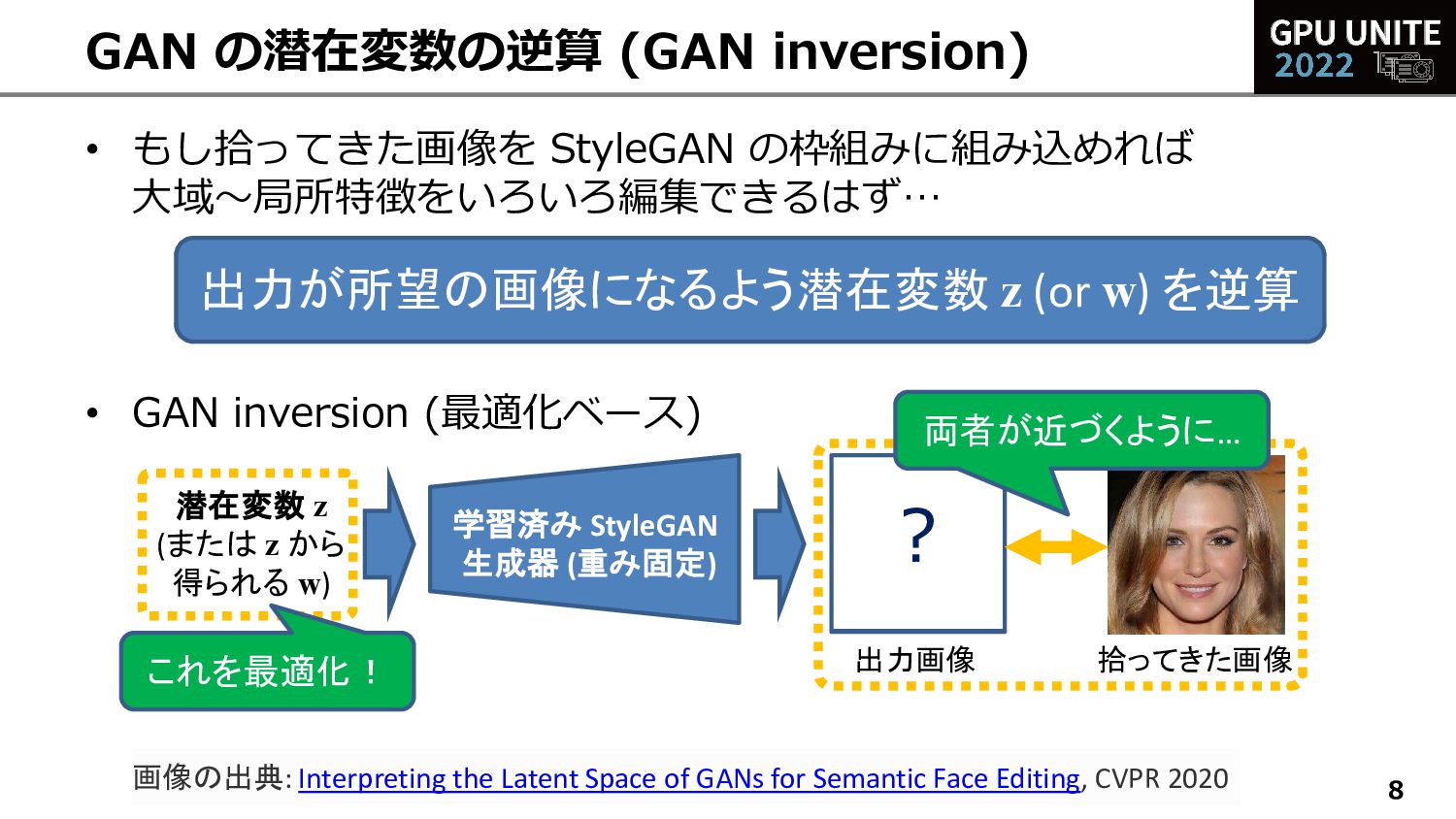
GAN の潜在変数の逆算 (GAN inversion) 出力が所望の画像になるよう潜在変数 z (or w) を逆算 学習済み StyleGAN 生成器 (重み固定) ? 出力画像 潜在変数 z (または z から 得られる w) 拾ってきた画像 これを最適化! 両者が近づくように… 画像の出典: Interpreting the Latent Space of GANs for Semantic Face Editing, CVPR 2020
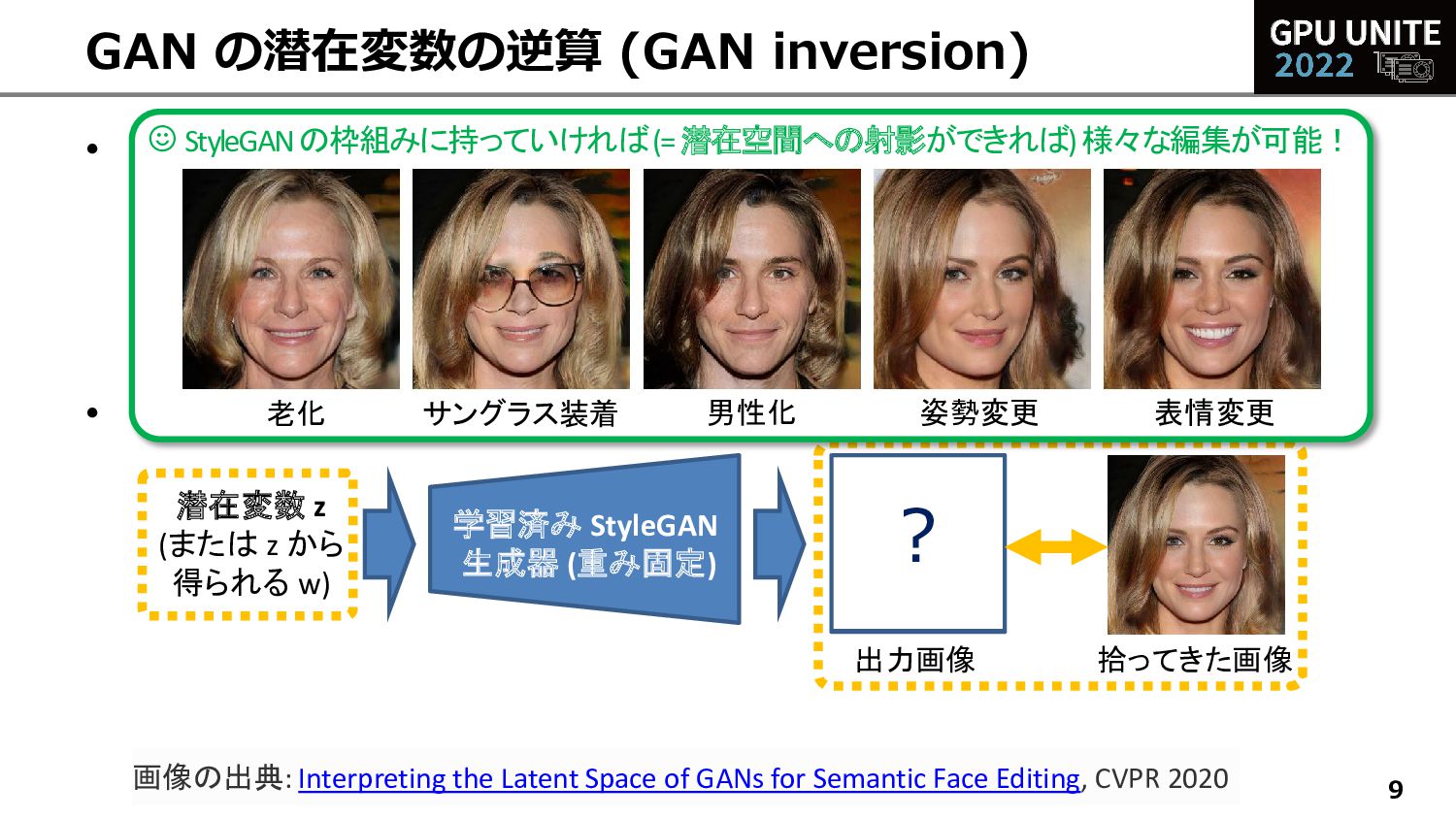
GAN の潜在変数の逆算 (GAN inversion) 出力が所望の画像になるよう潜在変数 z (or w) を逆算 学習済み StyleGAN 生成器 (重み固定) ? 出力画像 潜在変数 z (または z から 得られる w) 拾ってきた画像 ☺ StyleGANの枠組みに持っていければ(= 潜在空間への射影ができれば) 様々な編集が可能! 老化 サングラス装着 男性化 姿勢変更 表情変更 画像の出典: Interpreting the Latent Space of GANs for Semantic Face Editing, CVPR 2020
and Animation of 3D Avatars, SIGGRAPH 2022 A tall and skinny female soldier that is arguing. A skinny ninja that is raising both arms. An overweight sumo wrestler that is sitting.
![2022年版・深層学習による写実的画像合成の 最新動向 筑波大学 システム情報系 金森 由博 ([email protected])](https://files.speakerdeck.com/presentations/8e7f4ed6feae4c5e96f138e87b29420b/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
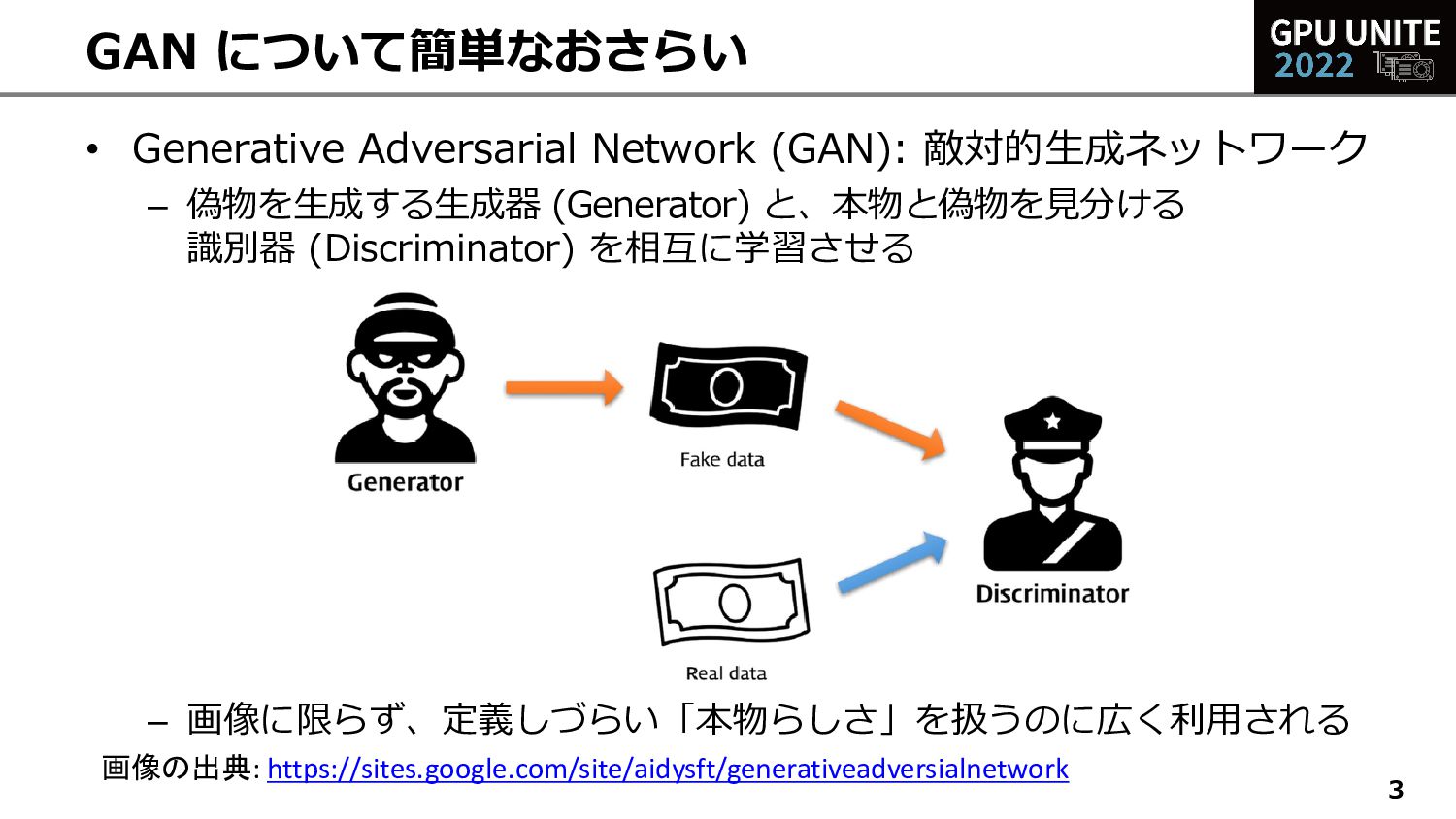
![• 大域的特徴 (顔の姿勢や概形など) から局所的特徴 (色) まで制御可能 5 代表的アーキテクチャ: StyleGAN [Karras+2018]](https://files.speakerdeck.com/presentations/8e7f4ed6feae4c5e96f138e87b29420b/slide_5.jpg){kind=link}
{kind=link}
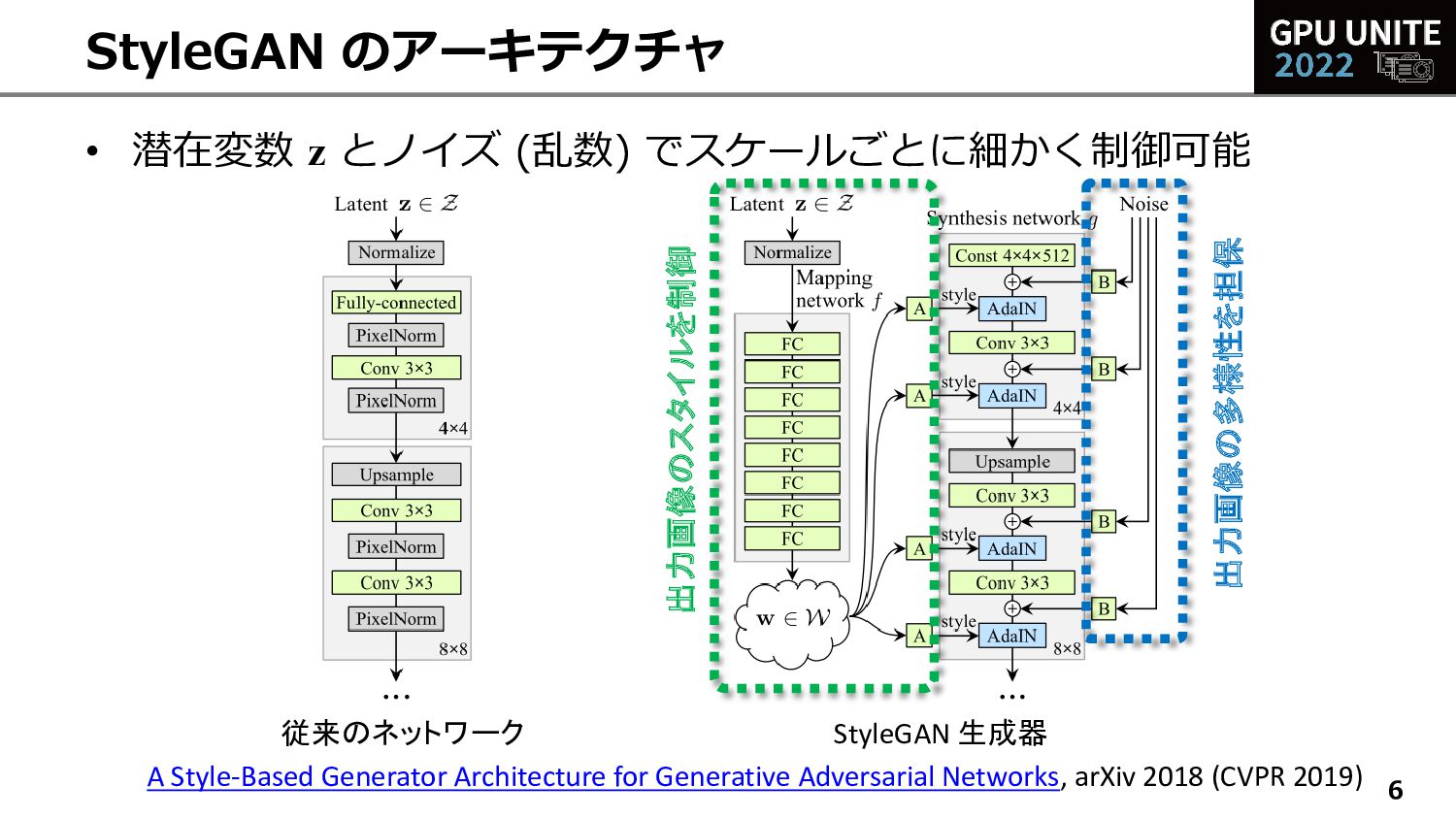
![• ☺ 高解像度の高品質画像を生成可能 – 改良版 StyleGAN2 [Karras+2019], StyleGAN3 [Karras+2021] も有名](https://files.speakerdeck.com/presentations/8e7f4ed6feae4c5e96f138e87b29420b/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![• 最適化は遅い、局所解に陥りやすい → 入力画像をよく近似する潜在変数をすぐ出力できるようなネットワーク (エンコーダ) を学習 … pSp [Richardson+2021], e4e](https://files.speakerdeck.com/presentations/8e7f4ed6feae4c5e96f138e87b29420b/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
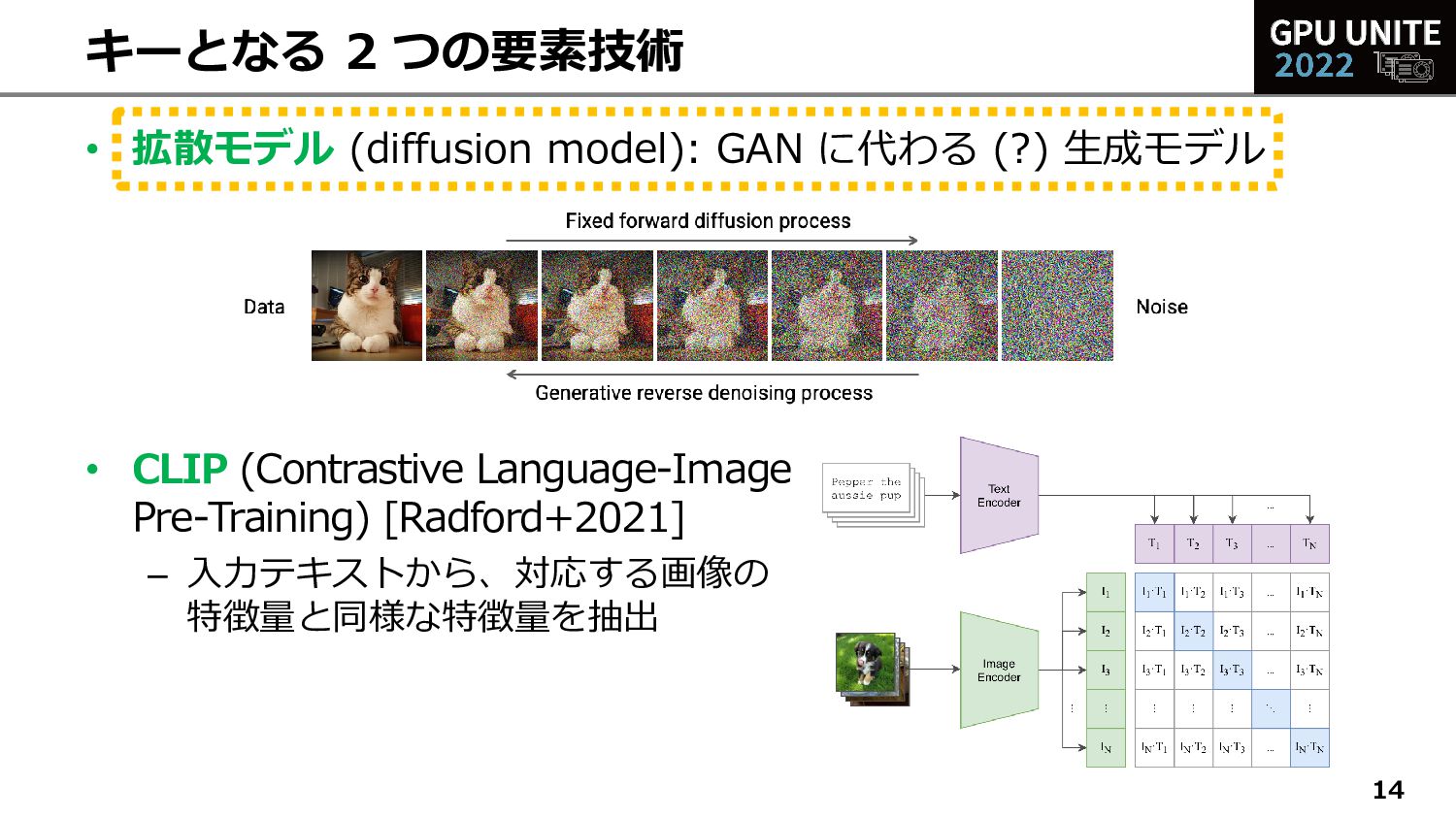{kind=link}
{kind=link}
{kind=link}
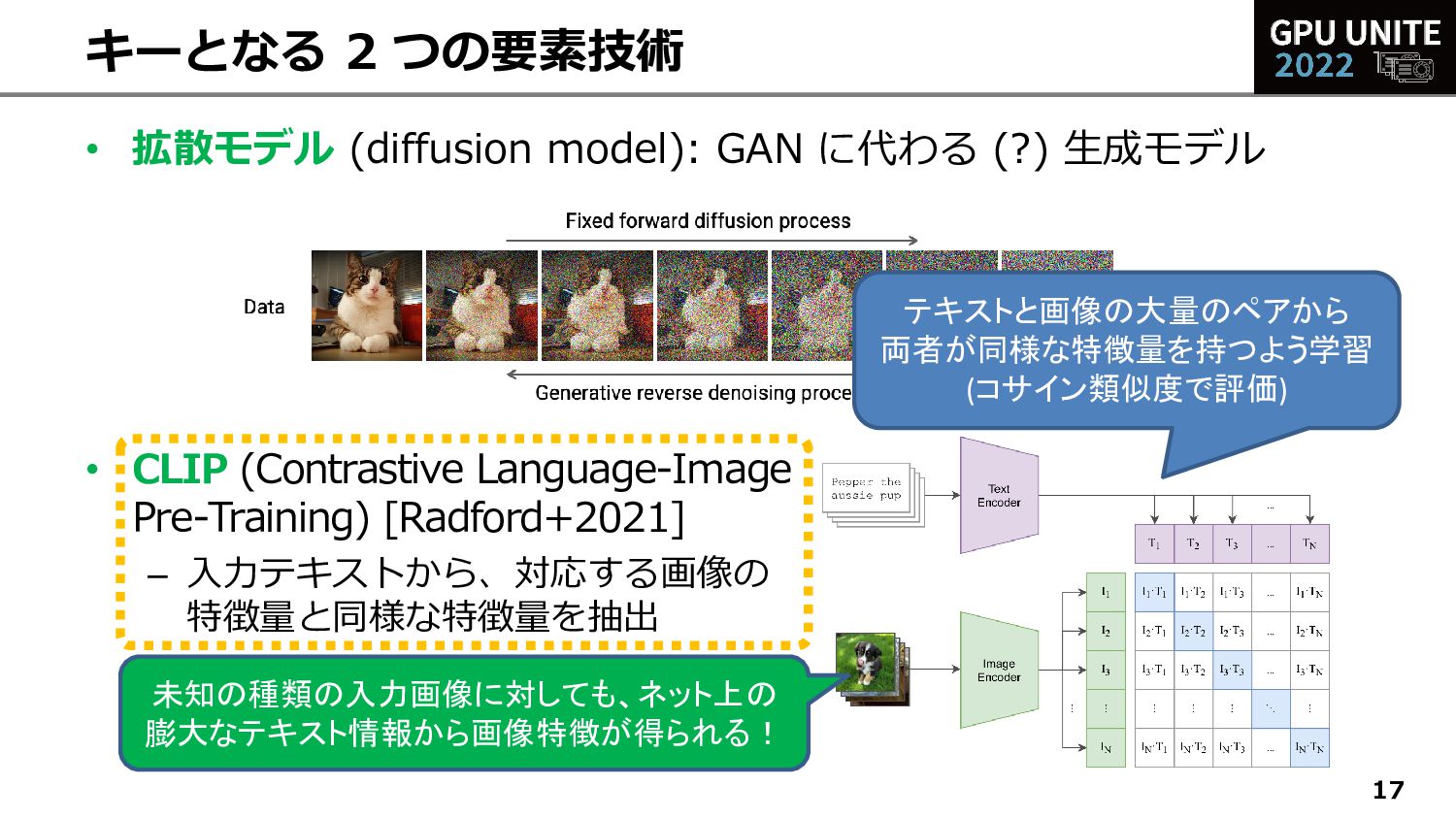{kind=link}
{kind=link}
{kind=link}
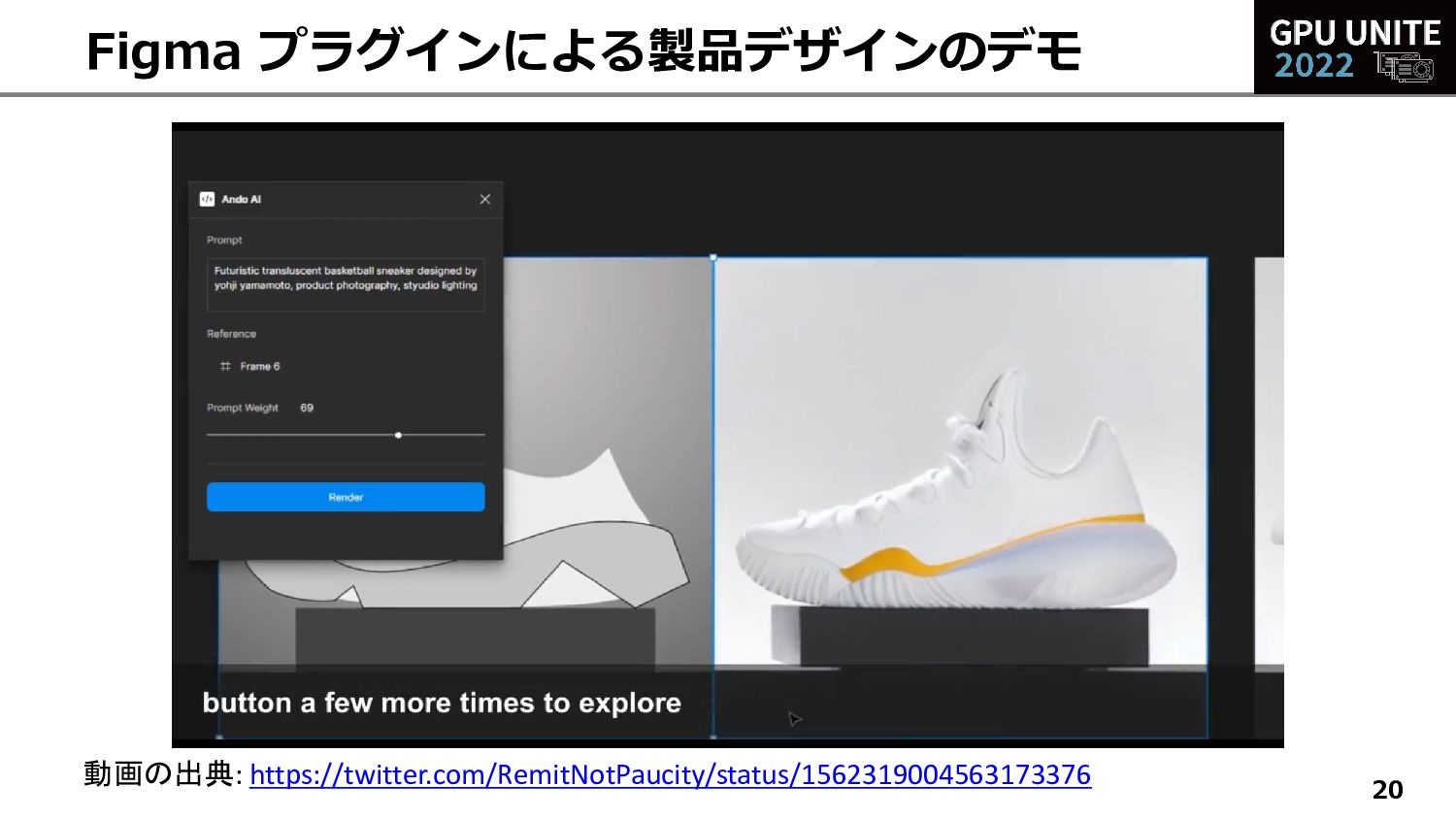{kind=link}
{kind=link}
{kind=link}
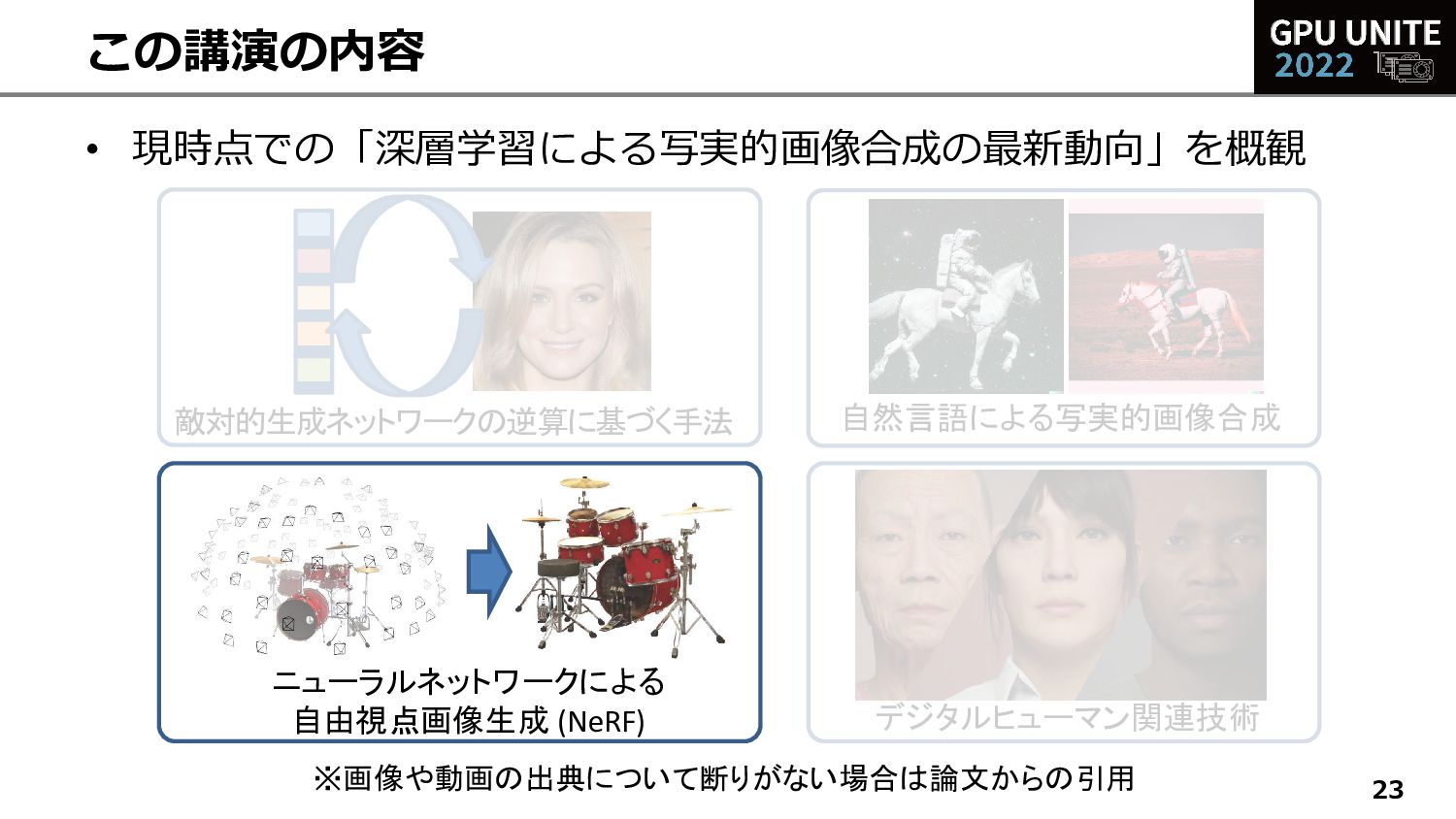{kind=link}
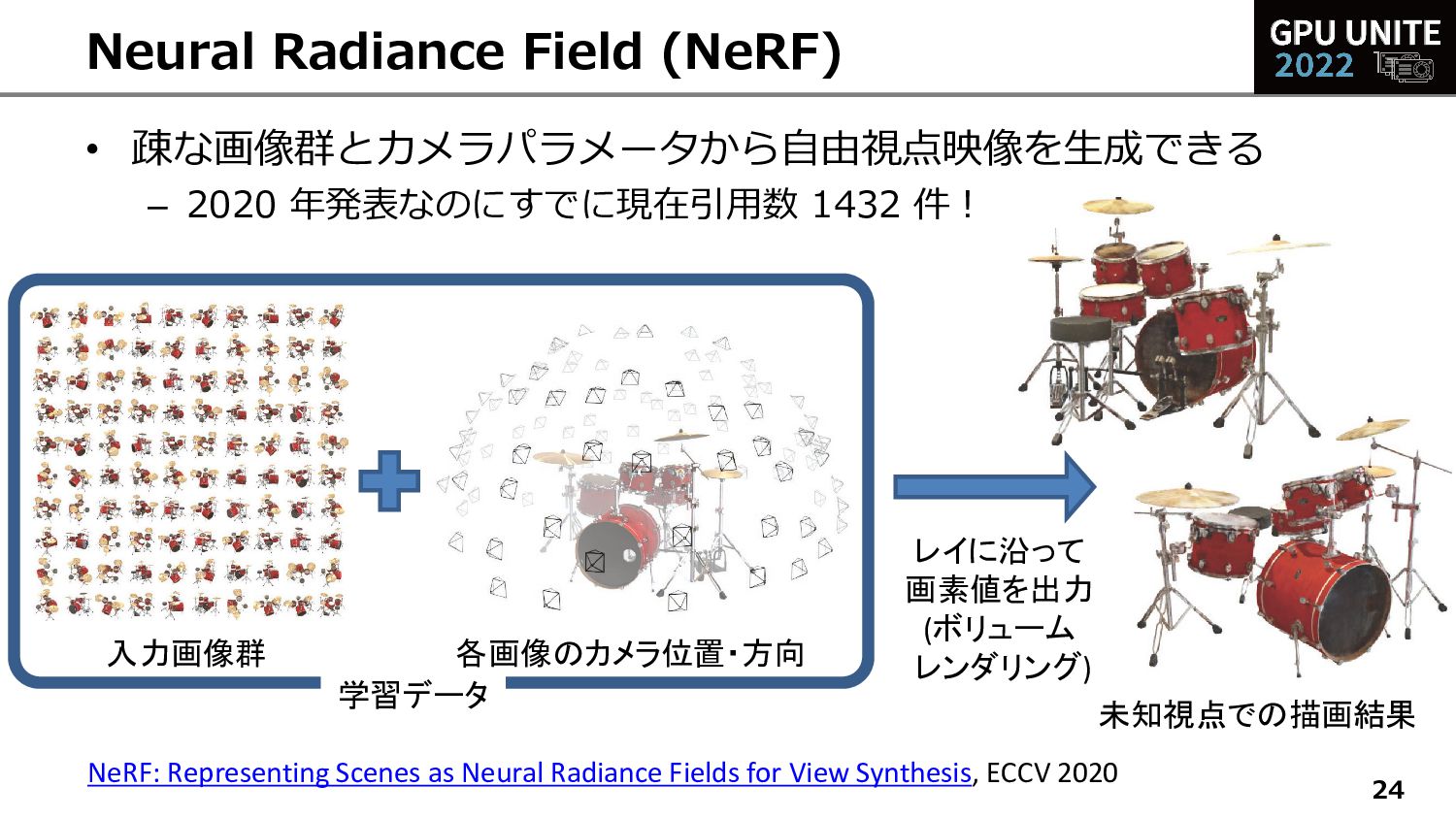{kind=link}
{kind=link}
{kind=link}
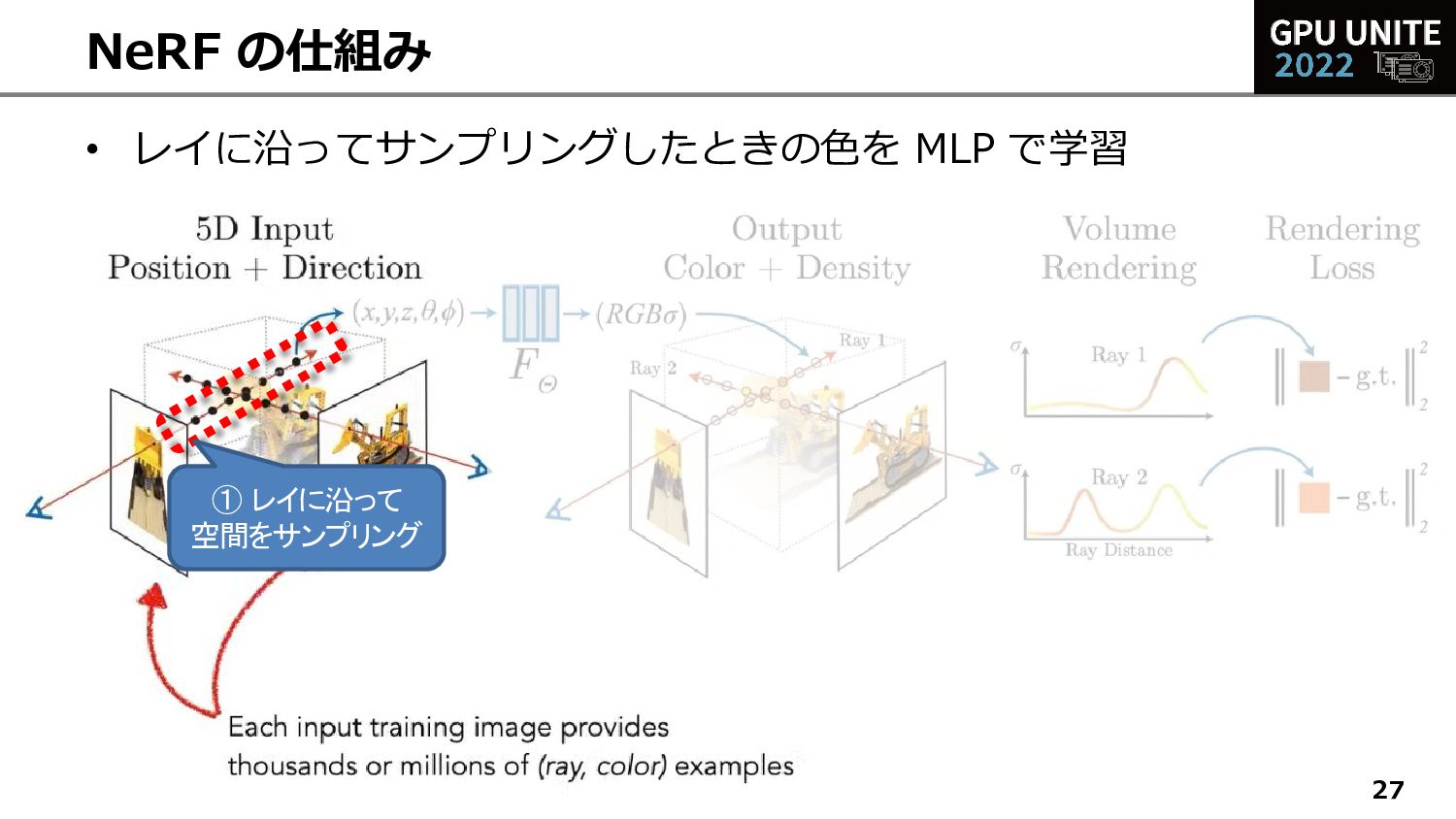{kind=link}
{kind=link}
{kind=link}
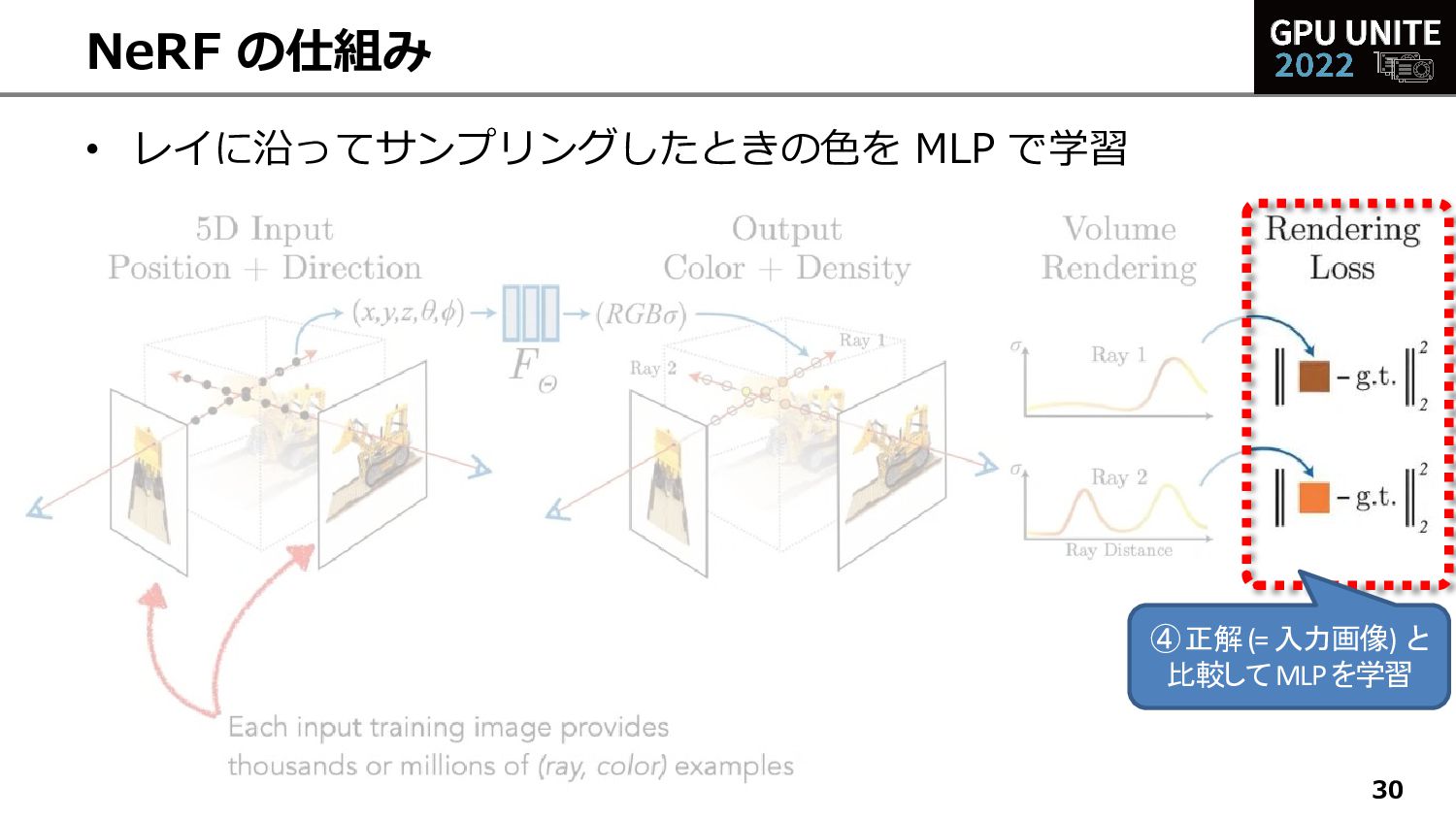{kind=link}
![• カメラパラメータが必要 → カメラパラメータも一緒に推定 … CAMPARI [Niemeyer & Geigar 2021]](https://files.speakerdeck.com/presentations/8e7f4ed6feae4c5e96f138e87b29420b/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
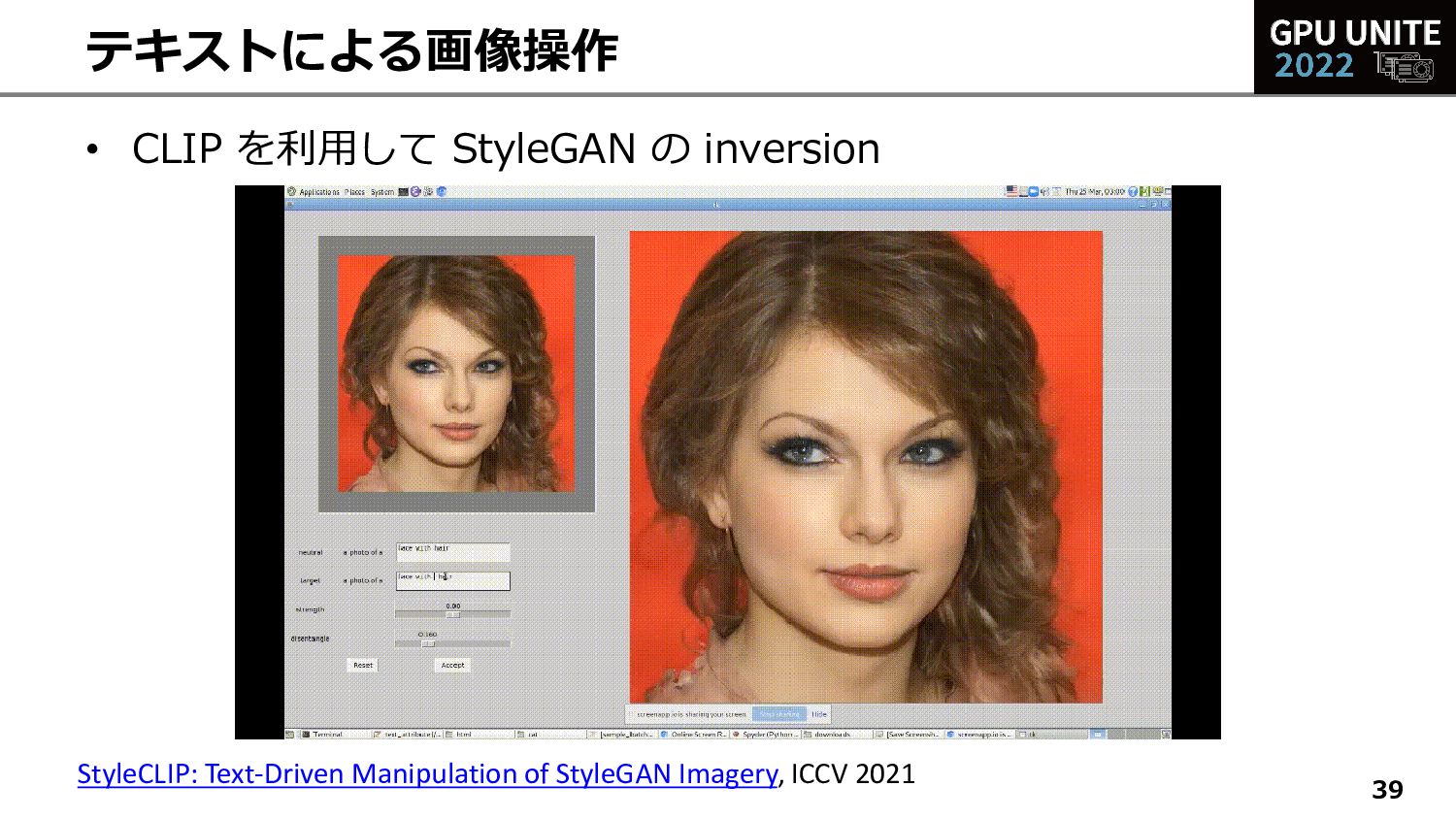{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}