Object Detection in the Wild," WACV2014. [Chang+, 2015] "ShapeNet: An information-rich 3D model repository," arXiv, 2015. [Xie+, 2019] "Pix2Vox: Context-aware 3D Reconstruction from Single and Multi-view Images," ICCV2019. [Tatarchenko+, 2017] "Octree Generating Networks: Efficient Convolutional Architectures for High-resolution 3D Outputs," ICCV2017. [Fan+, 2017] "A Point Set Generation Network for 3D Object Reconstruction from a Single Image," CVPR2017. [Chen+, 2019] "Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer," NeurIPS2019. [Richter and Roth, 2018] "Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers," CVPR2018. [Mescheder+, 2019] "Occupancy networks: Learning 3d reconstruction in function space," CVPR2019. [Kato+, 2017] "Neural 3D Mesh Renderer," CVPR2018 [Wang+, 2019] "Differentiable Surface Splatting for Point-based Geometry Processing," SIGGRAPH Asia 2019. [Nimier-David+, 2019] "Mitsuba 2: A Retargetable Forward and Inverse Renderer," SIGGRAPH Asia 2019 [Loubet+, 2019] "Reparameterizing Discontinuous Integrands for Diff erentiable Rendering," SIGGRAPH Asia 2019 [Murthy+, 2019] "Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research," arXiv, 2019. [Liu+, 2019] "PlaneRCNN: 3D Plane Detection and Reconstruction from a Single Image," CVPR2019. [Godard+, 2019] "Digging into Self-Supervised Monocular Depth Prediction," ICCV2019. 52
![ディープラーニングの 最新 CG/CV 応用 筑波大学 システム情報系 金森 由博 ([email protected]) 1](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
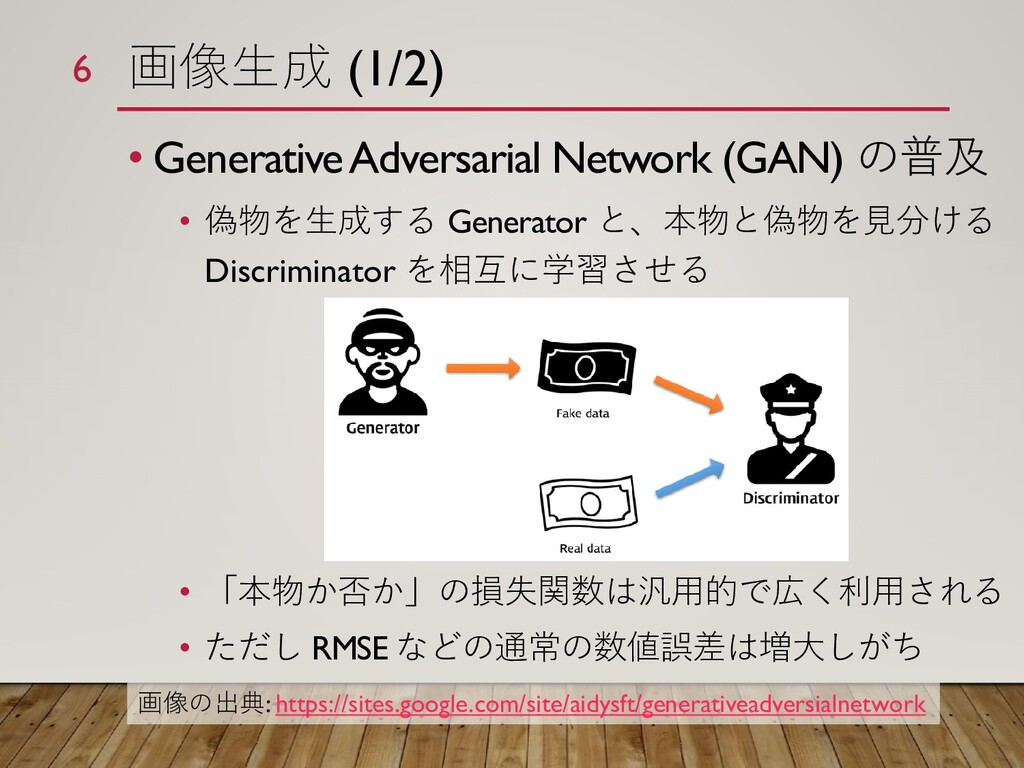{kind=link}
{kind=link}
![最新手法: StyleGAN2 [Karras+, 2019b] • 「人間の顔」の潜在空間での補間 8 動画の出典: https://www.youtube.com/watch?v=6E1_dgYlifc](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_7.jpg){kind=link}
![Image-to-Image Translation (pix2pix) (1/3) • 画像ドメイン間の「翻訳」[Isora+, 2017] • 例: 意味ラベル→実写風、実写→地図、白黒→カラー、](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_8.jpg){kind=link}
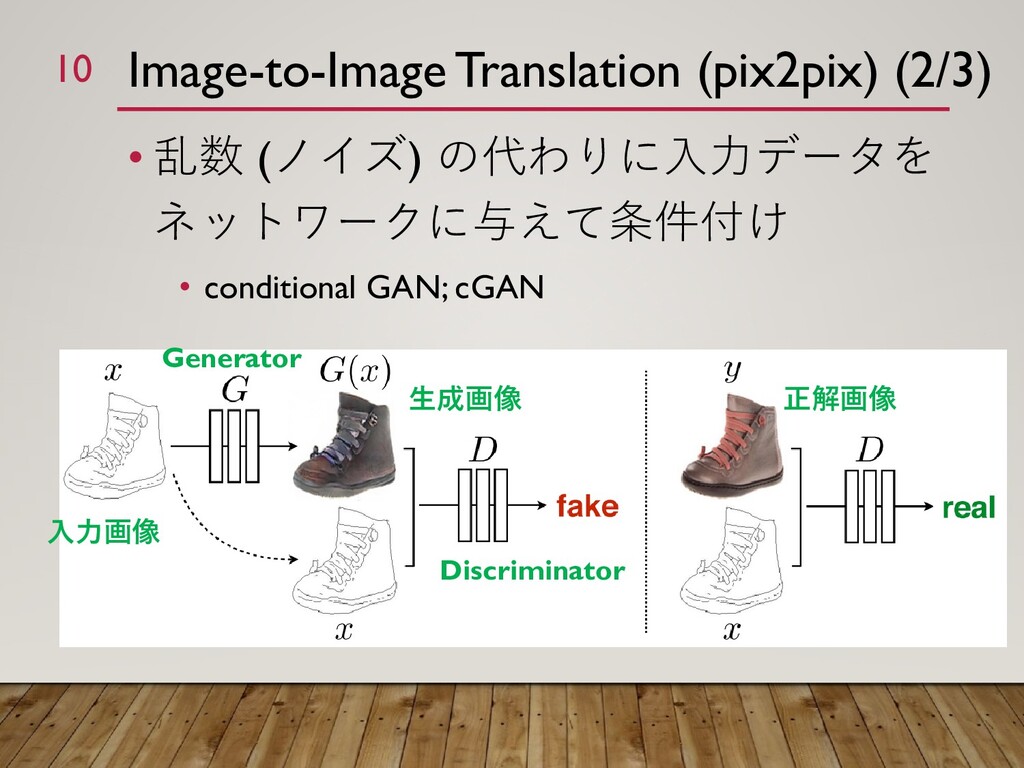{kind=link}
{kind=link}
![CycleGAN [Zhu+, 2017] (1/2) • 入力・正解画像ペアに画素単位の対応が 取れていなくても変換を学習できるように 12](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_11.jpg){kind=link}
![CycleGAN [Zhu+, 2017] (2/2) • pix2pix (左) では画素の対応の取れたペアが 必要だったが、CycleGAN (右)](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_12.jpg){kind=link}
![pix2pix の高解像度化 (pix2pixHD) [Wang+, 2018] • 特に意味ラベルからの画像合成の例で 高解像度 (例: 2048×1024)](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_13.jpg){kind=link}
![pix2pix の高解像度化 (pix2pixHD) [Wang+, 2018] • 低解像度 (中央) と高解像度 (両端)](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_14.jpg){kind=link}
![意味的画像合成の改良 [Park+, 2019] • 意味ラベルからの画像合成を安定に、 より軽量なネットワークで実現 • 意味ラベルを捉える正規化層 (SPADE) を導入](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_15.jpg){kind=link}
![意味的画像合成の改良 [Park+, 2019] • 意味ラベルを考慮した正則化層 SPADE を 多重解像度で追加することで安定化 • 2](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_16.jpg){kind=link}
![画像生成についての参考文献 [Karras+, 2017] "Progressive Growing of GANs for Improved Quality,](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_17.jpg){kind=link}
{kind=link}
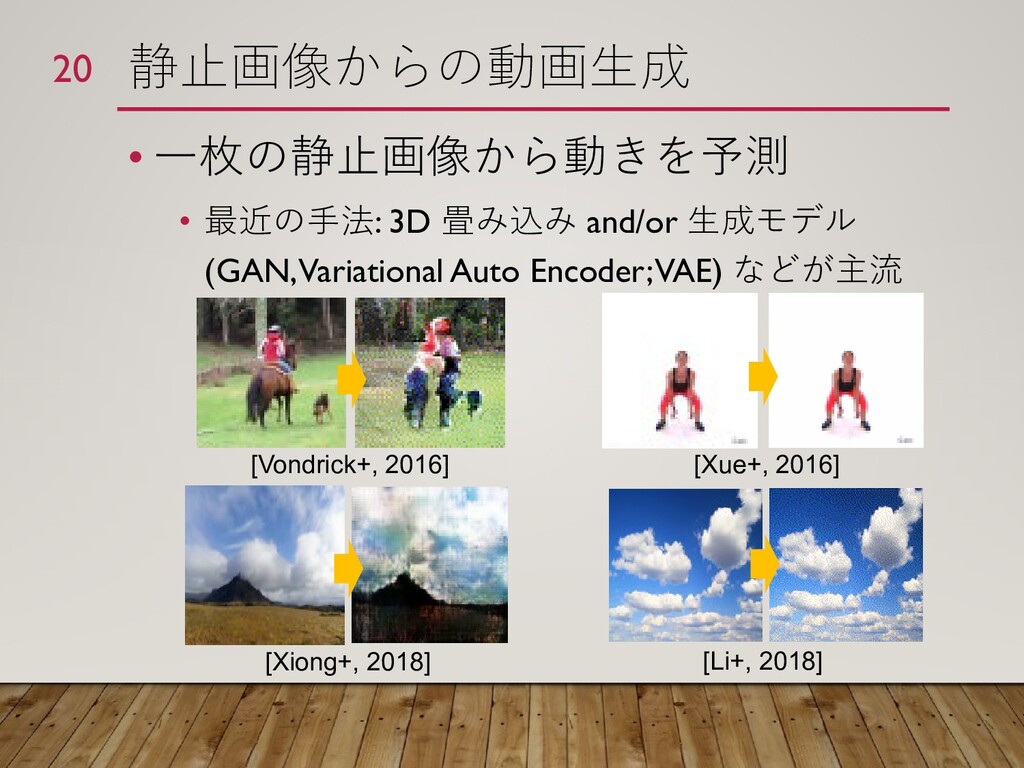{kind=link}
{kind=link}
{kind=link}
![景観画像のアニメーション生成 • 高解像度&予測フレーム数の制限なし& 動きと色の変化を制御可能 [Endo+, 2019] 23 入力画像 動きのみ予測 動きと色変化を予測](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_22.jpg){kind=link}
![[Endo+, 2019] の長所とその理由 • 高解像度 (1024×576 など) • 流れ場を予測し、それを利用して入力画像の画素 から予測フレームを再構成](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_23.jpg){kind=link}
![既存手法との比較 (1/2) 25 入力画像 流れ場 (予測) 流れ場 (予測) [Endo+, 2019]](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![SinGAN [Shaham+, 2019] • 一枚の画像から定常的なアニメーションを 自動生成、ICCV 2019 のベストペーパー 29 動画の出典:](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_28.jpg){kind=link}
![動画生成についての参考文献 [Vondrick+, 2016] "Generating Videos with Scene Dynamics," NIPS2016. [Xie+,](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_29.jpg){kind=link}
{kind=link}
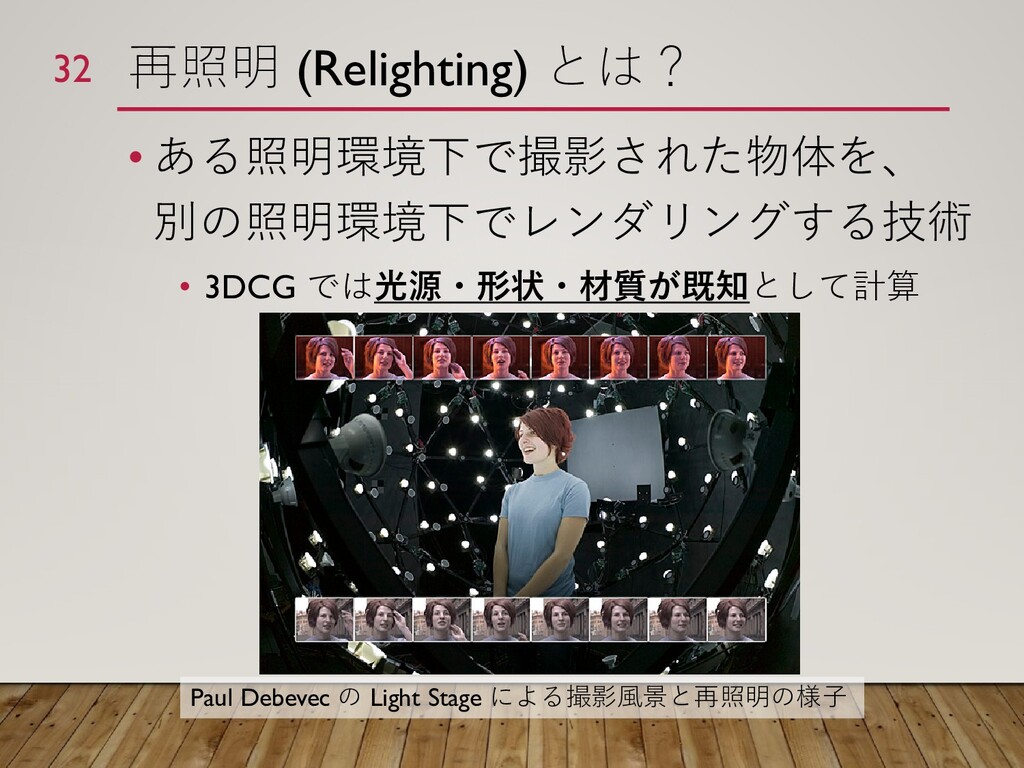{kind=link}
{kind=link}
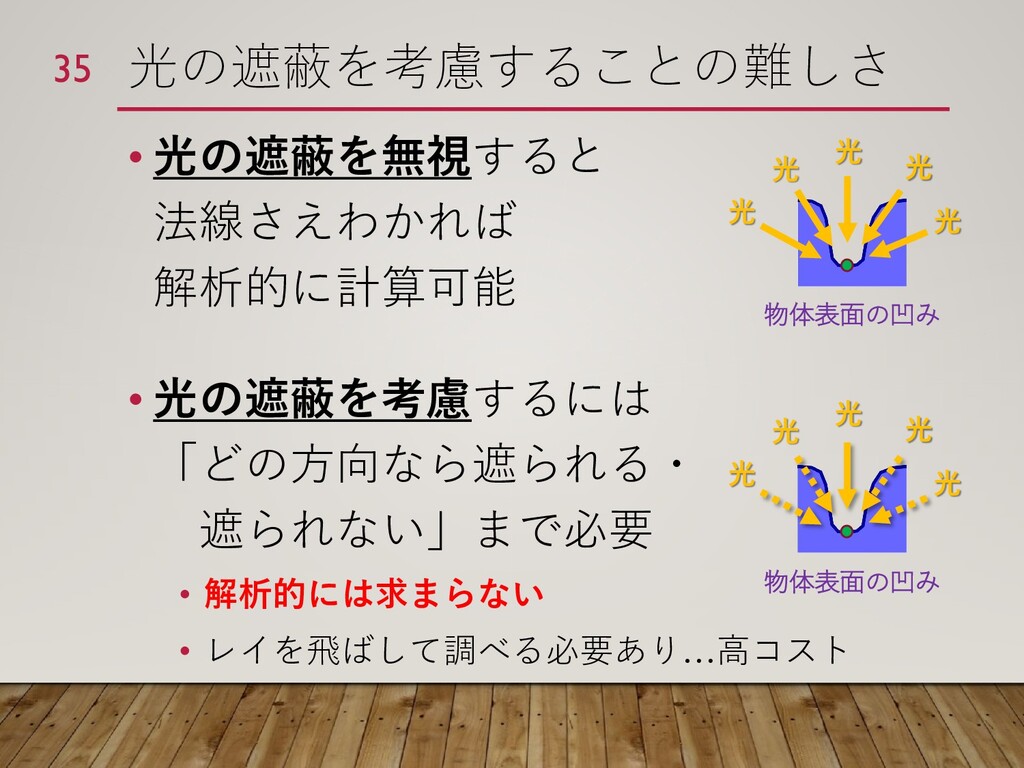
![光の遮蔽を考慮するか否かの影響 • 非凸形状の場合、見た目に大きく影響 • リアルタイム CG の分野で研究済み [Sloan+, 2002] 34](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_33.jpg){kind=link}
{kind=link}
![光の遮蔽を考慮した再照明 • 光の遮蔽を明示的に考慮 [Kanamori+, 2018] • 事前に計算した遮蔽情報を用いて教師あり学習 • 畳み込みニューラルネット (CNN)](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
![後続の研究 • Light Stage を使って撮影された高品質 データを用いて教師あり学習 [Sun+, 2019] • 光の遮蔽を含めた照明計算は暗黙的に考慮される](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_38.jpg){kind=link}
![再照明についての参考文献 [Barron and Malik, 2015] "Shape, Illumination, and Refl ectance](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
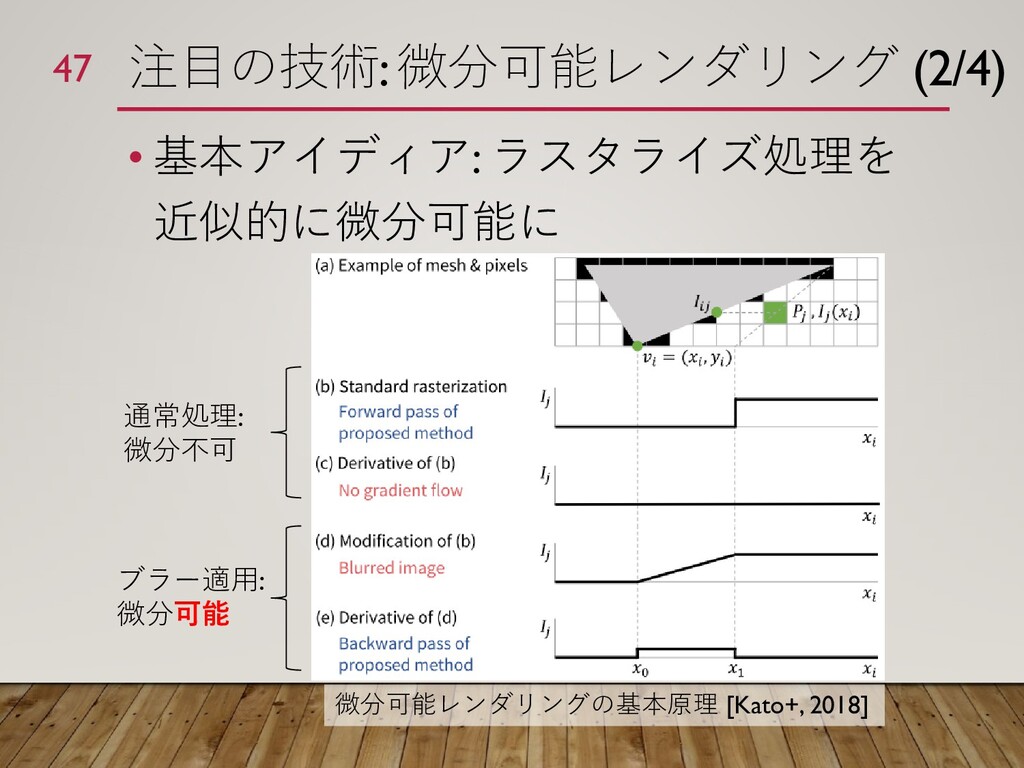
{kind=link}
![注目の技術: 微分可能レンダリング (4/4) • レイトレーシングに基づく微分可能 レンダラ “Mitsuba 2” [Nimier-David+, 2019]](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
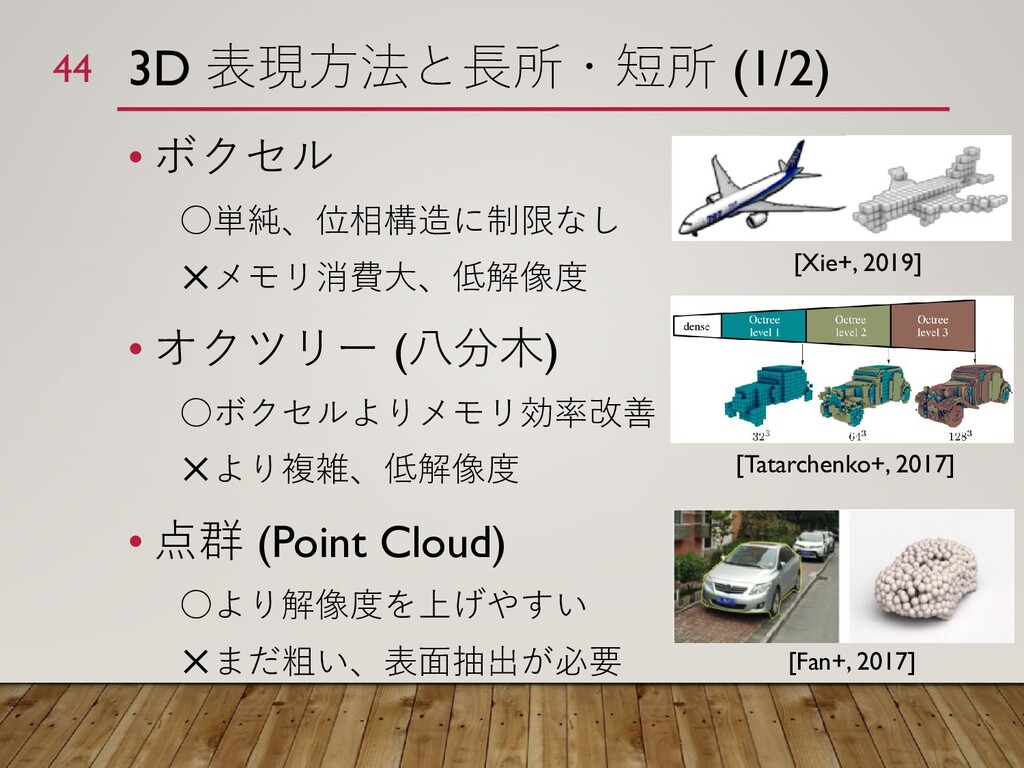
![3D 復元についての参考文献 [Xiang+, 2014] "Beyond PASCAL: A Benchmark for 3D](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_50.jpg){kind=link}
{kind=link}
![人物を対象とした深層学習手法 • 様々な技術の混成、実用化への期待大 54 ランドマーク推定 [Cao+, 2018] ポーズ&体型推定 [Kolotouros+, 2019]](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_52.jpg){kind=link}
{kind=link}
![注目の技術: Deep Fake (2/4) • 騙す (合成) 技術の例 [Kim+, 2018]](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_54.jpg){kind=link}
![注目の技術: Deep Fake (3/4) • 見抜く (検出) 技術の例 [Rossler+, 2019]](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![人物関係についての参考文献 [Cao+, 2018] "OpenPose: realtime multi-person 2D pose estimation using](https://files.speakerdeck.com/presentations/b3cf92d4928a48a78165641b36f882d3/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}