Neural Grammatical Error Correction Systems with Unsupervised Pre-training on Synthetic Data
長岡技術科学大学
自然言語処理研究室
文献紹介(2019-08-05)
Neural Grammatical Error Correction Systems with Unsupervised Pre-training on Synthetic Data
https://www.aclweb.org/anthology/W19-4427
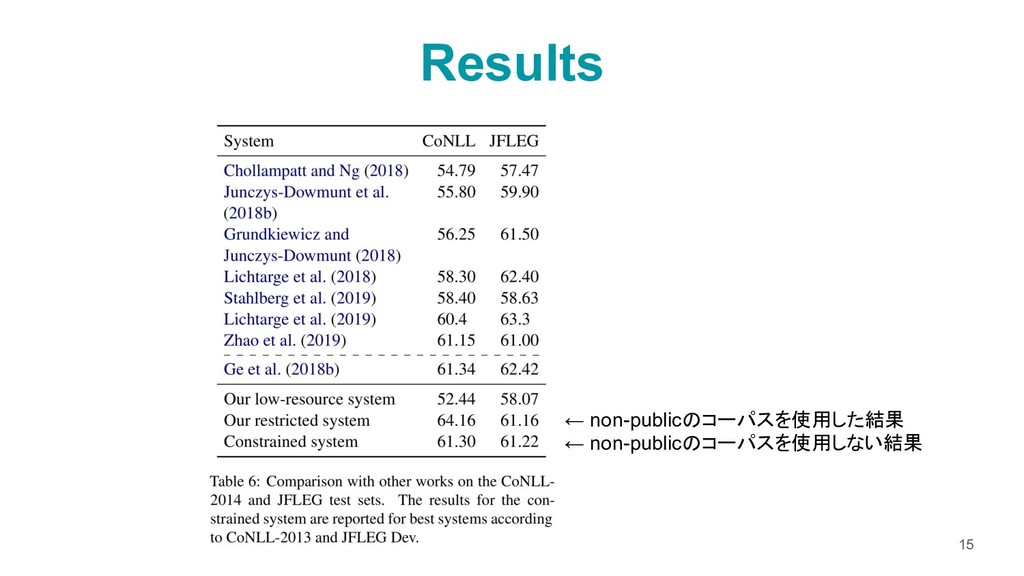
Data Roman Grundkiewicz and Marcin Junczys-Dowmunt and Kenneth Heafield Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 252–263, 2019 長岡技術科学大学 自然言語処理研究室 小川耀一朗 文献紹介(2019-08-05) 1
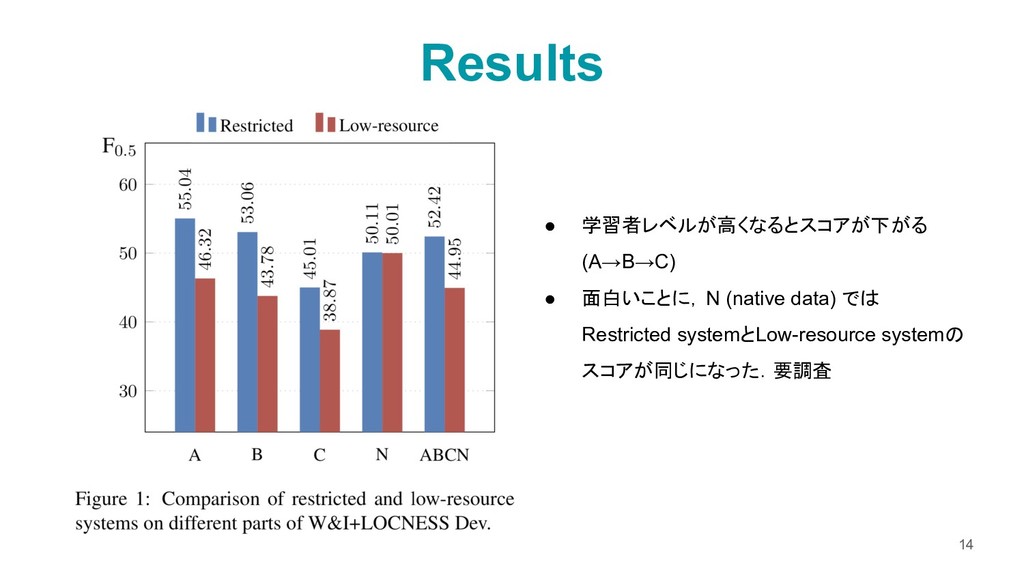
WikiEd を使用 • Wikipediaの編集履歴をまとめたコーパス • ノイズが多いため,以下の2つのスコアの平均で ソートして上位2Mペアを使用した ◦ word 5-gram LM ◦ 操作タグの5-gram LM - “I think that the public transport will always be in the future .” - “I think that public transport will always exist in the future .” “<del> the <sub> be <to> exist”
{kind=link}
![Introduction 2 [1] Approaching Neural Grammatical Error Correction as a](https://files.speakerdeck.com/presentations/4306e2c6970a4fc0beb70e7852b06ed5/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}