Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Noising and Denoising Natural Language: Diverse...
Search
youichiro
August 23, 2018
Technology
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Noising and Denoising Natural Language: Diverse Backtranslation for Grammar Correction
長岡技術科学大学
自然言語処理研究室
文献紹介 (2018-08-23)
youichiro
August 23, 2018
More Decks by youichiro
See All by youichiro
日本語文法誤り訂正における誤り傾向を考慮した擬似誤り生成
youichiro
0
1.6k
分類モデルを用いた日本語学習者の格助詞誤り訂正
youichiro
0
140
Multi-Agent Dual Learning
youichiro
1
200
Automated Essay Scoring with Discourse-Aware Neural Models
youichiro
0
150
Context is Key- Grammatical Error Detection with Contextual Word Representations
youichiro
1
170
勉強勉強会
youichiro
0
110
Confusionset-guided Pointer Networks for Chinese Spelling Check
youichiro
0
220
A Neural Grammatical Error Correction System Built On Better Pre-training and Sequential Transfer Learning
youichiro
0
200
An Empirical Study of Incorporating Pseudo Data into Grammatical Error Correction
youichiro
0
230
Other Decks in Technology
See All in Technology
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
1
170
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
400
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
AI x 開発生産性を取り巻く予算戦略と投資対効果
i35_267
7
2.9k
kaonavi Tech Night#1
kaonavi
0
160
AI Native なプロダクト組織の立ち上げ方 : 生産性 100 倍への挑戦
mikesorae
0
1.3k
キャリアLT会#3
beli68
2
240
41歳でAWSが好きすぎてITエンジニアになったおっさんの話
yama3133
1
740
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
200
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
130
Featured
See All Featured
GitHub's CSS Performance
jonrohan
1033
470k
From π to Pie charts
rasagy
0
240
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Everyday Curiosity
cassininazir
0
260
A Tale of Four Properties
chriscoyier
163
24k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Design in an AI World
tapps
1
270
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Transcript
Noising and Denoising Natural Language: Diverse Backtranslation for Grammar Correction
Ziang Xie, Guillaume Genthial, Stanley Xie, Andrew Y. Ng, Dan Jurafsky Proceedings of NAACL-HLT 2018, pages 619–628, 2018 ⽂献紹介(2018-08-23) ⻑岡技術科学⼤学 ⾃然⾔語処理研究室 ⼩川 耀⼀朗 1
Introduction l 機械翻訳ベースの⽂法誤り訂正(GEC)アプローチでは、学習者の誤り⽂ と正しい⽂の⼤規模なパラレルコーパスが必要になることがボトルネッ クとなっている Ø 正しい⽂にノイズを加えて誤り⽂を⽣成し、学習者作⽂データの不⾜を 補う⼿法を提案 l 単純な⽅法はトークンの削除や置換を⾏うことだが、⾮現実的なノイズ
を⽣成してしまう Ø 提案⼿法では、encoder-decoderとbeam searchを組み合わせて多様 な誤り⽂を⽣成する 2
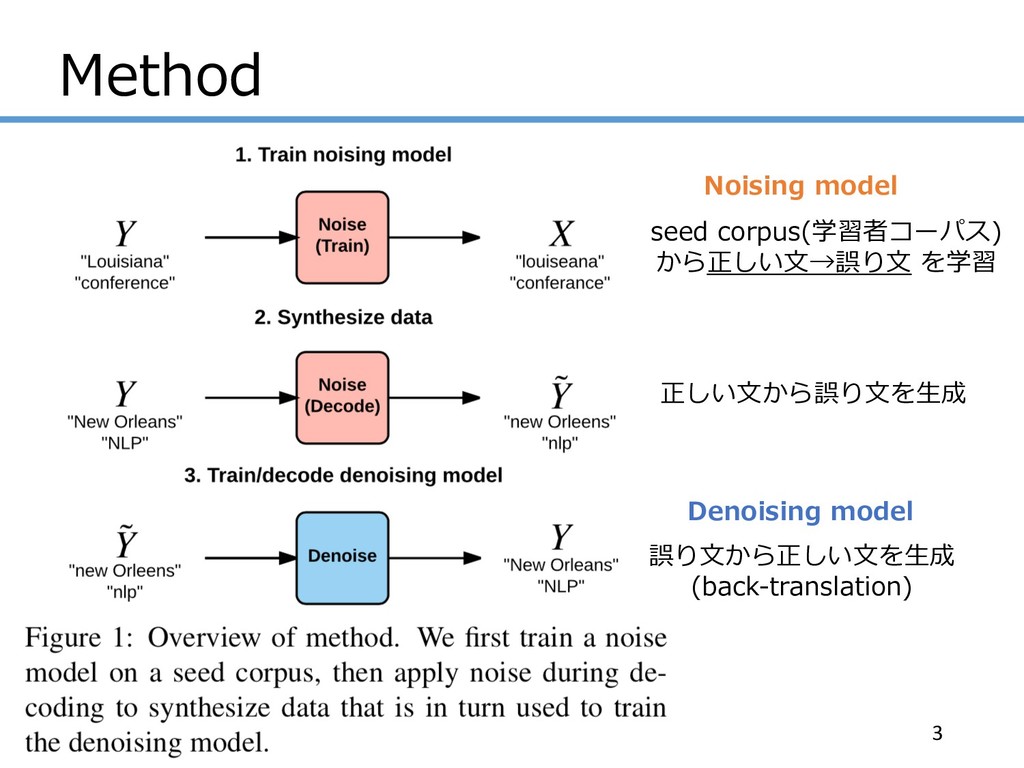
Method 3 正しい⽂から誤り⽂を⽣成 Noising model seed corpus(学習者コーパス) から正しい⽂→誤り⽂ を学習 Denoising
model 誤り⽂から正しい⽂を⽣成 (back-translation)
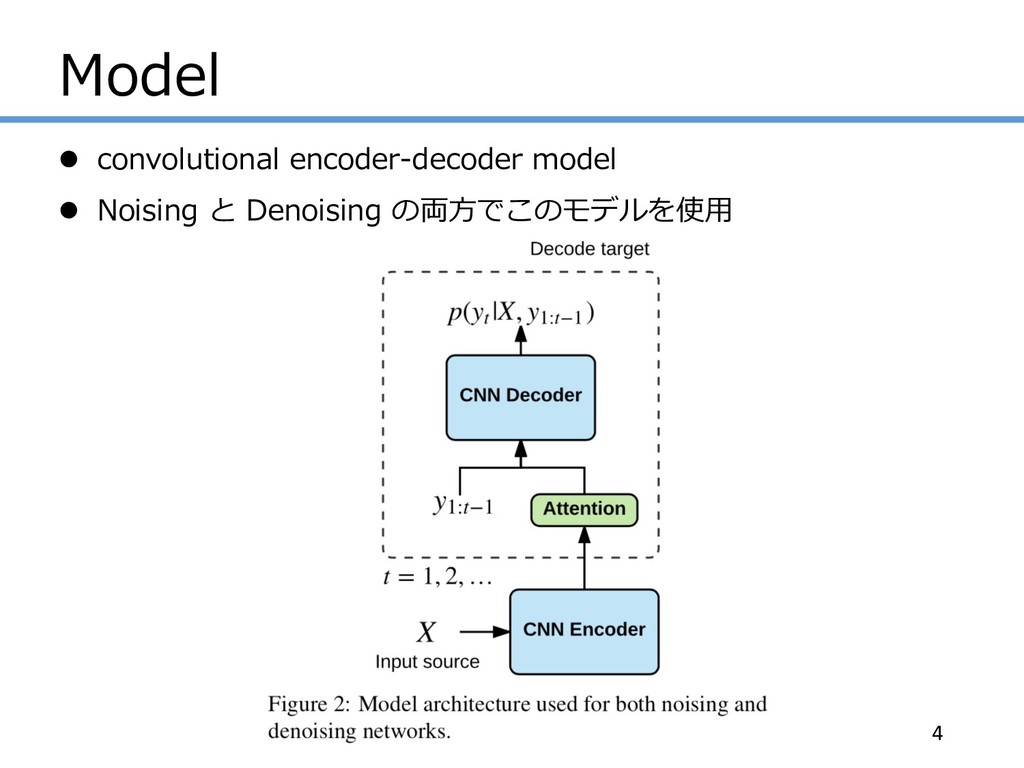
Model 4 l convolutional encoder-decoder model l Noising と Denoising
の両⽅でこのモデルを使⽤
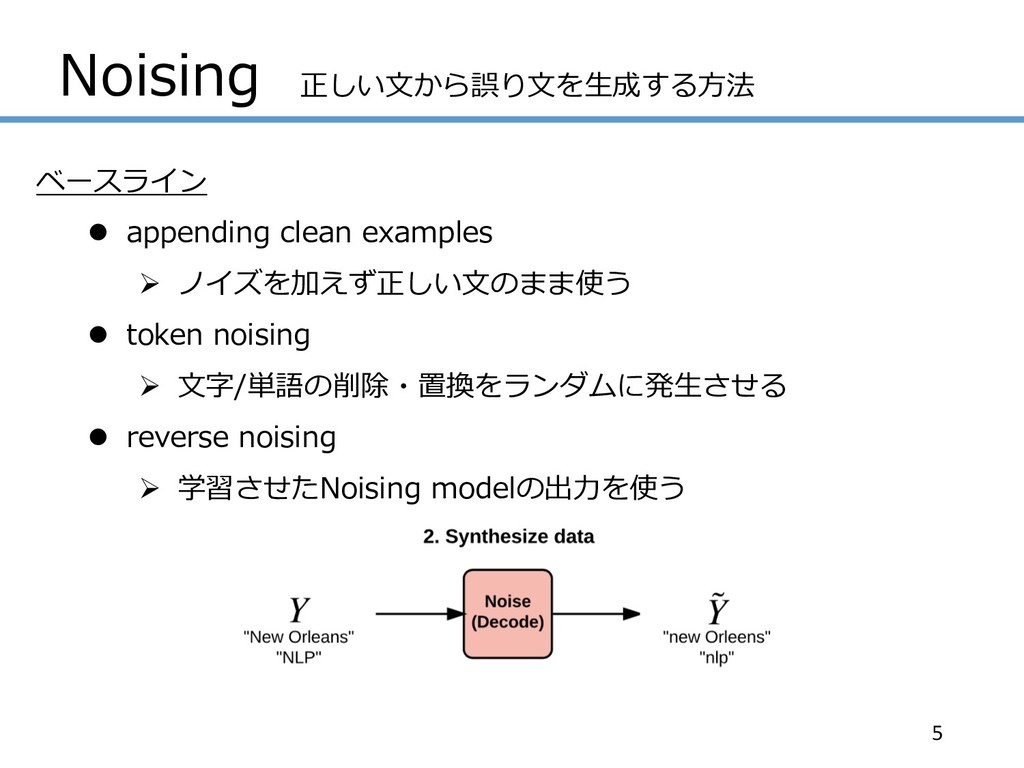
Noising 正しい⽂から誤り⽂を⽣成する⽅法 ベースライン l appending clean examples Ø ノイズを加えず正しい⽂のまま使う l
token noising Ø ⽂字/単語の削除・置換をランダムに発⽣させる l reverse noising Ø 学習させたNoising modelの出⼒を使う 5
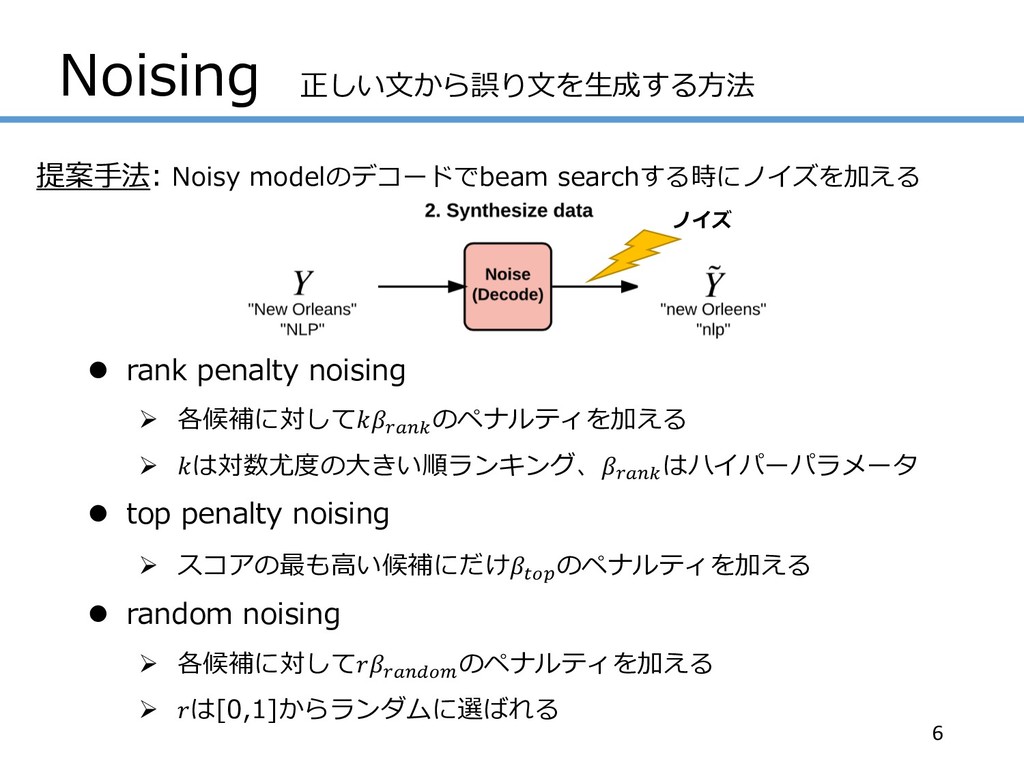
Noising 正しい⽂から誤り⽂を⽣成する⽅法 提案⼿法: Noisy modelのデコードでbeam searchする時にノイズを加える l rank penalty noising
Ø 各候補に対して#$%& のペナルティを加える Ø は対数尤度の⼤きい順ランキング、#$%& はハイパーパラメータ l top penalty noising Ø スコアの最も⾼い候補にだけ'() のペナルティを加える l random noising Ø 各候補に対して#$%+(, のペナルティを加える Ø は[0,1]からランダムに選ばれる 6 ノイズ
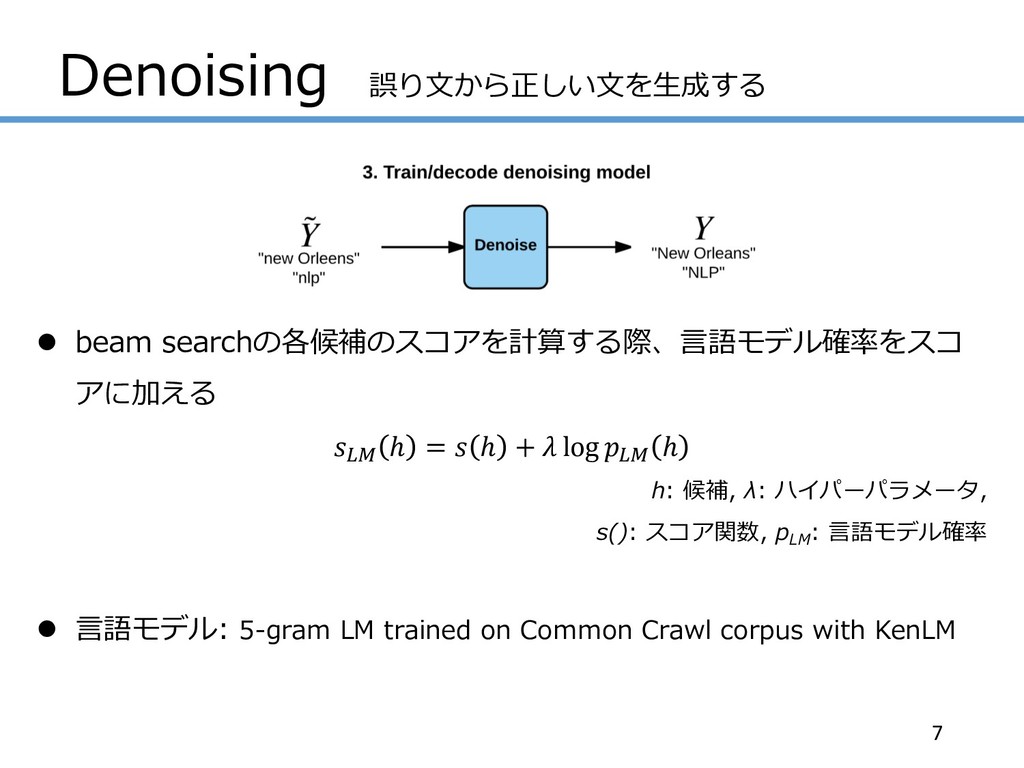
Denoising 誤り⽂から正しい⽂を⽣成する l beam searchの各候補のスコアを計算する際、⾔語モデル確率をスコ アに加える ./ ℎ = ℎ
+ log ./ ℎ h: 候補, λ: ハイパーパラメータ, s(): スコア関数, pLM : ⾔語モデル確率 l ⾔語モデル: 5-gram LM trained on Common Crawl corpus with KenLM 7
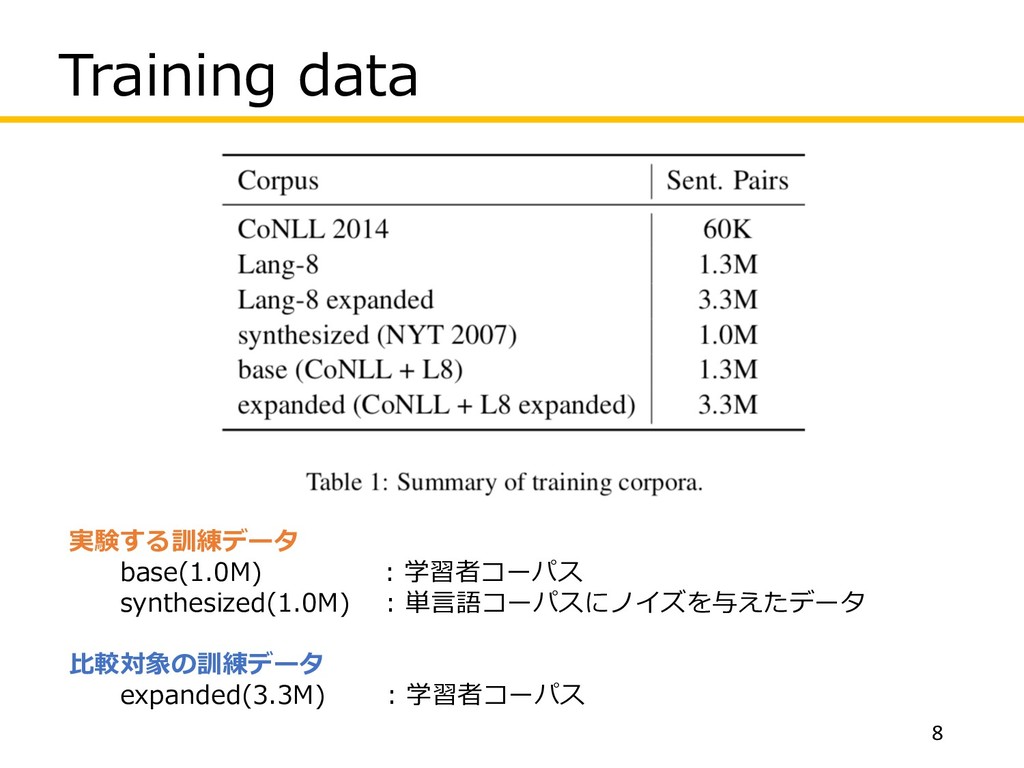
Training data 8 実験する訓練データ base(1.0M) : 学習者コーパス synthesized(1.0M) : 単⾔語コーパスにノイズを与えたデータ
⽐較対象の訓練データ expanded(3.3M) : 学習者コーパス
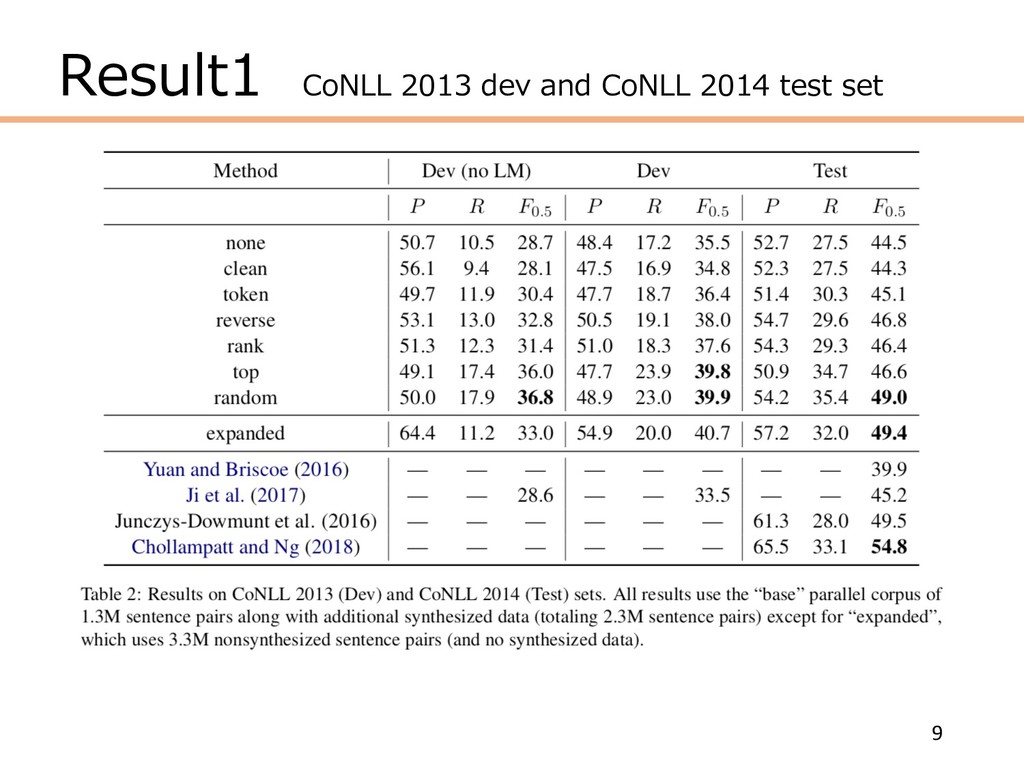
Result1 CoNLL 2013 dev and CoNLL 2014 test set 9
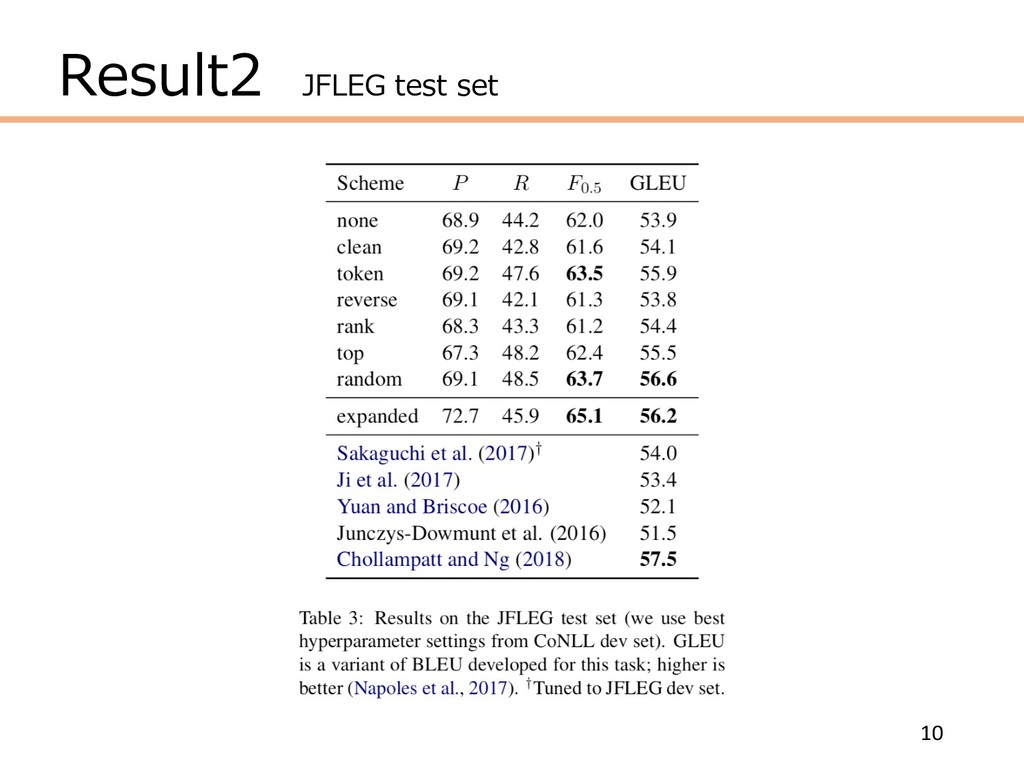
Result2 JFLEG test set 10
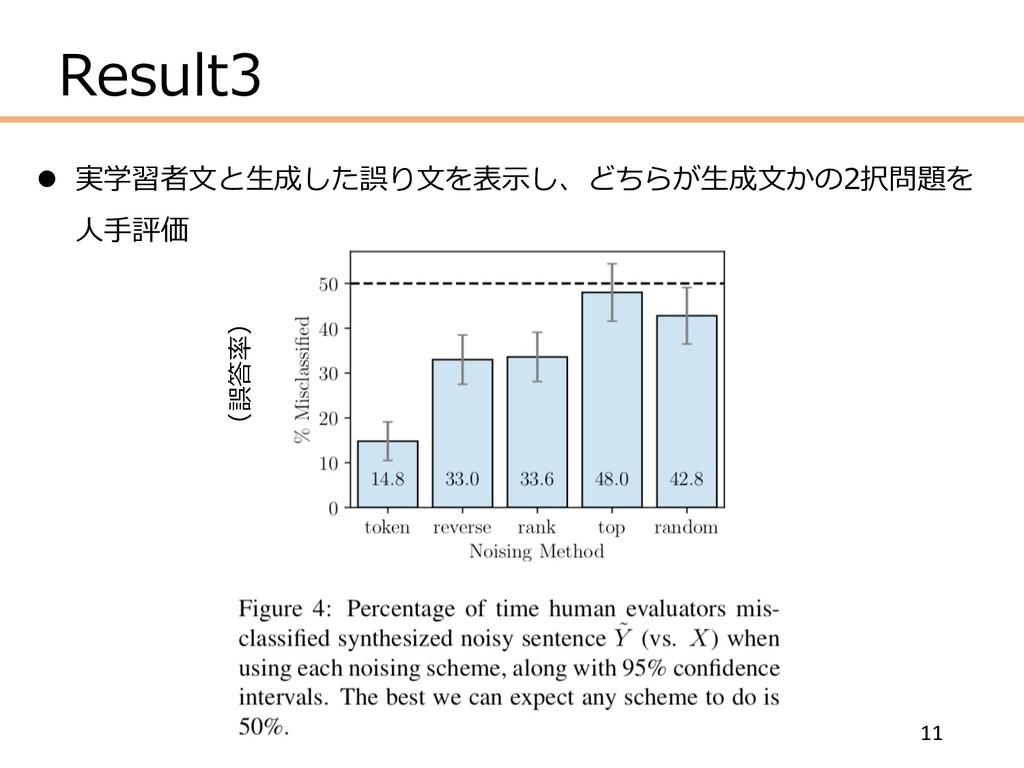
Result3 11 l 実学習者⽂と⽣成した誤り⽂を表⽰し、どちらが⽣成⽂かの2択問題を ⼈⼿評価 (誤答率)
Conclusion l GECタスクでは⼤量の学習者コーパスが必要となるが、本論⽂では Noising model、Denoising modelを⽤いて正しい⽂から誤り⽂を⽣成 する⼿法を提案し、学習者コーパスの不⾜を補った l ⽣成された誤り⽂と学習者⽂を⽐較し、⼈が⾒⽐べても区別が難しいこ とがわかった
l 実験では、⽣成したデータを加えて訓練した結果が、⼤規模な実学習者 コーパスで訓練した結果と同程度の性能を⽰した 12
13
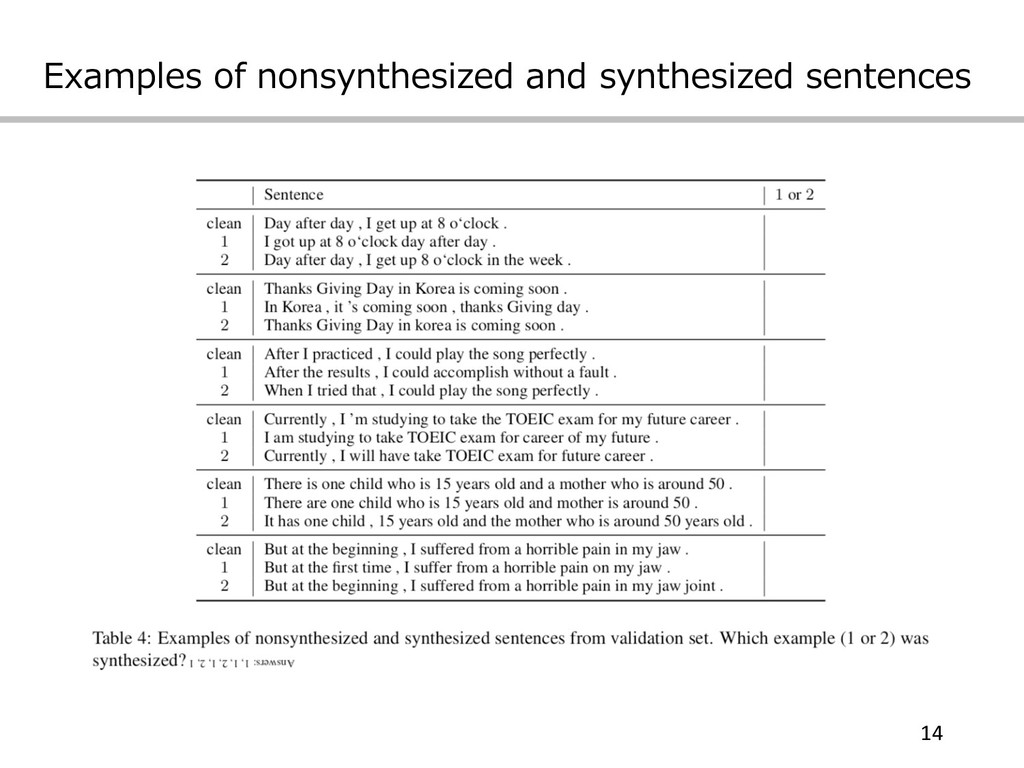
Examples of nonsynthesized and synthesized sentences 14
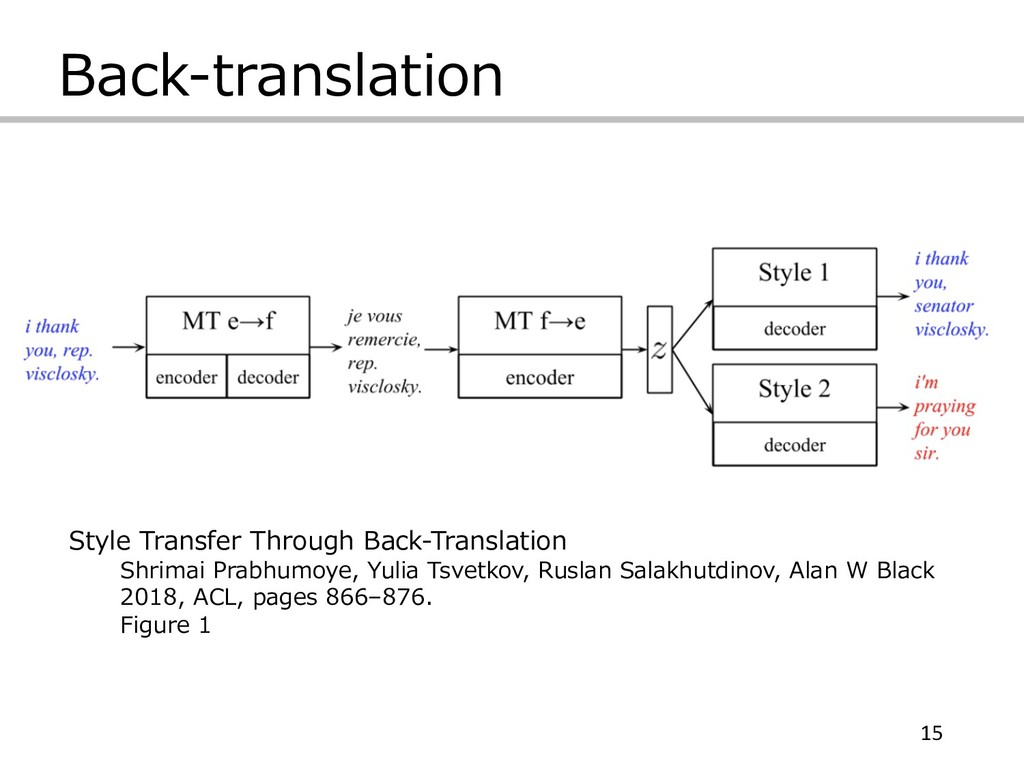
Back-translation 15 Style Transfer Through Back-Translation Shrimai Prabhumoye, Yulia Tsvetkov,
Ruslan Salakhutdinov, Alan W Black 2018, ACL, pages 866–876. Figure 1
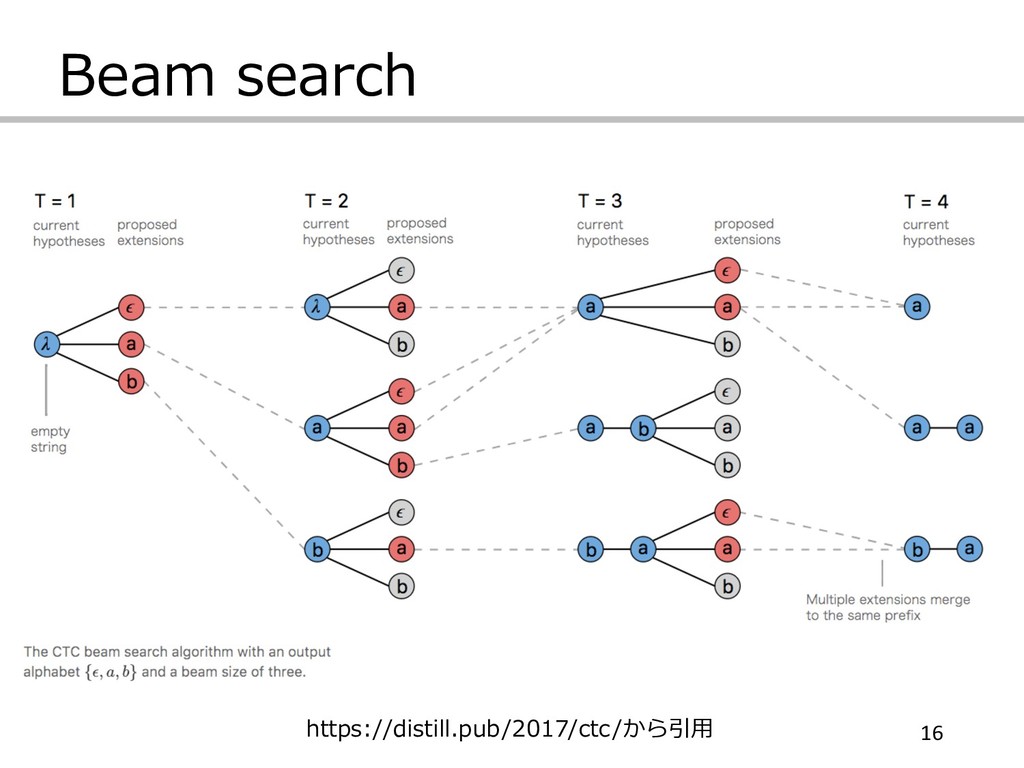
Beam search 16 https://distill.pub/2017/ctc/から引⽤
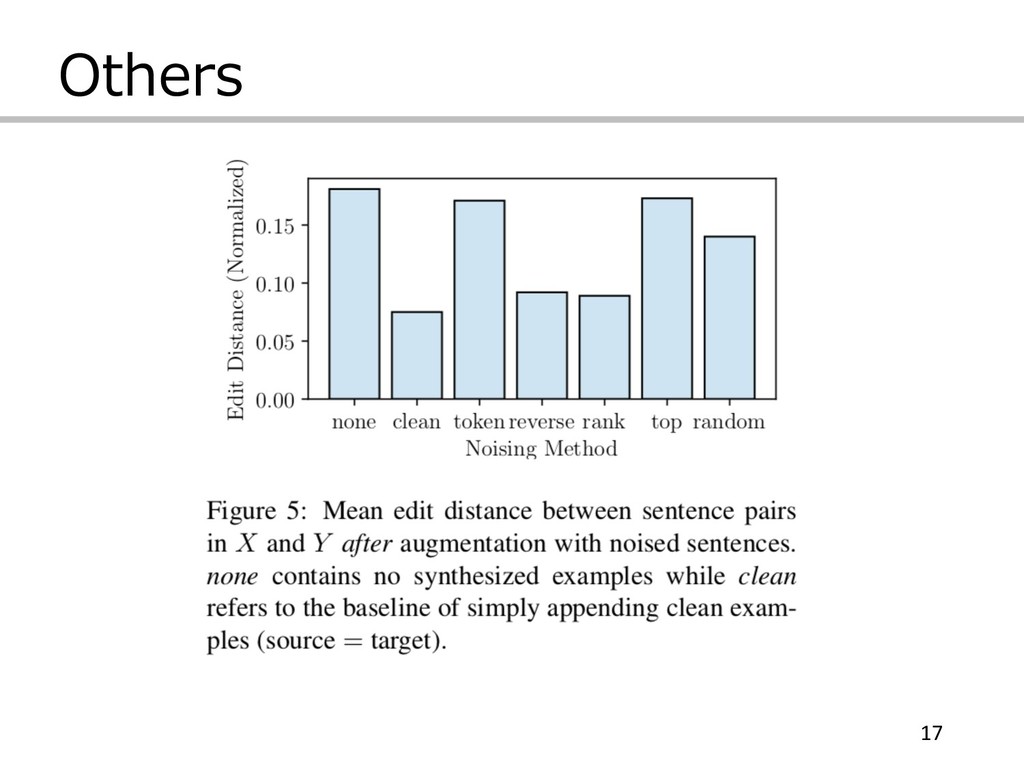
Others 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}