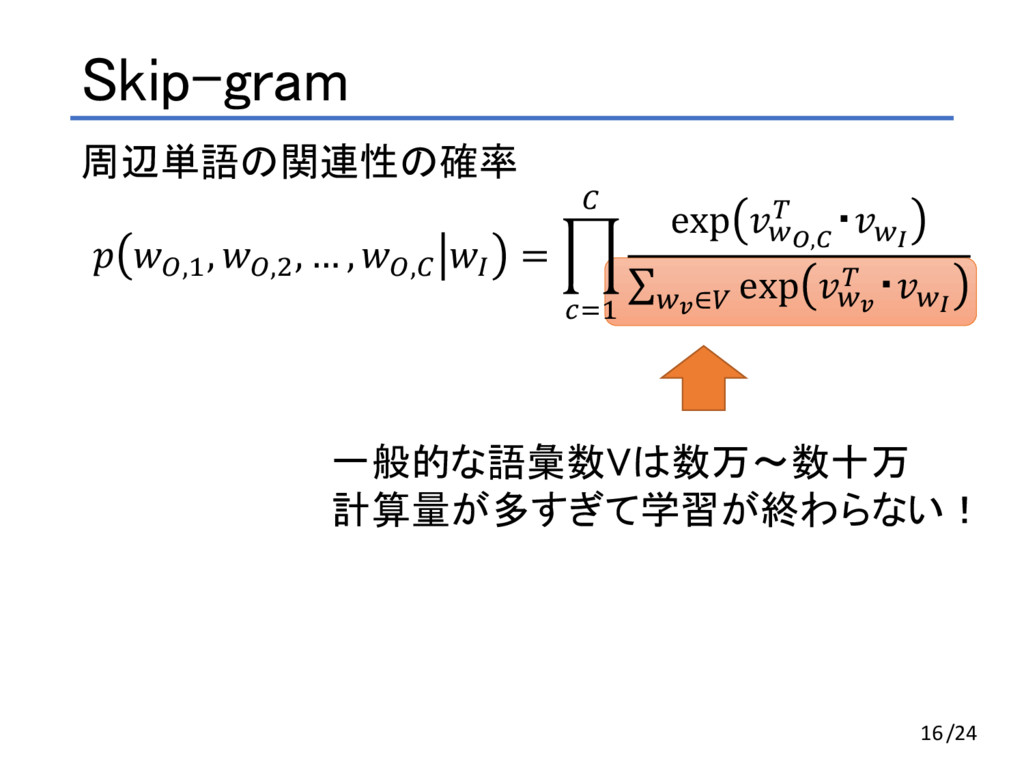
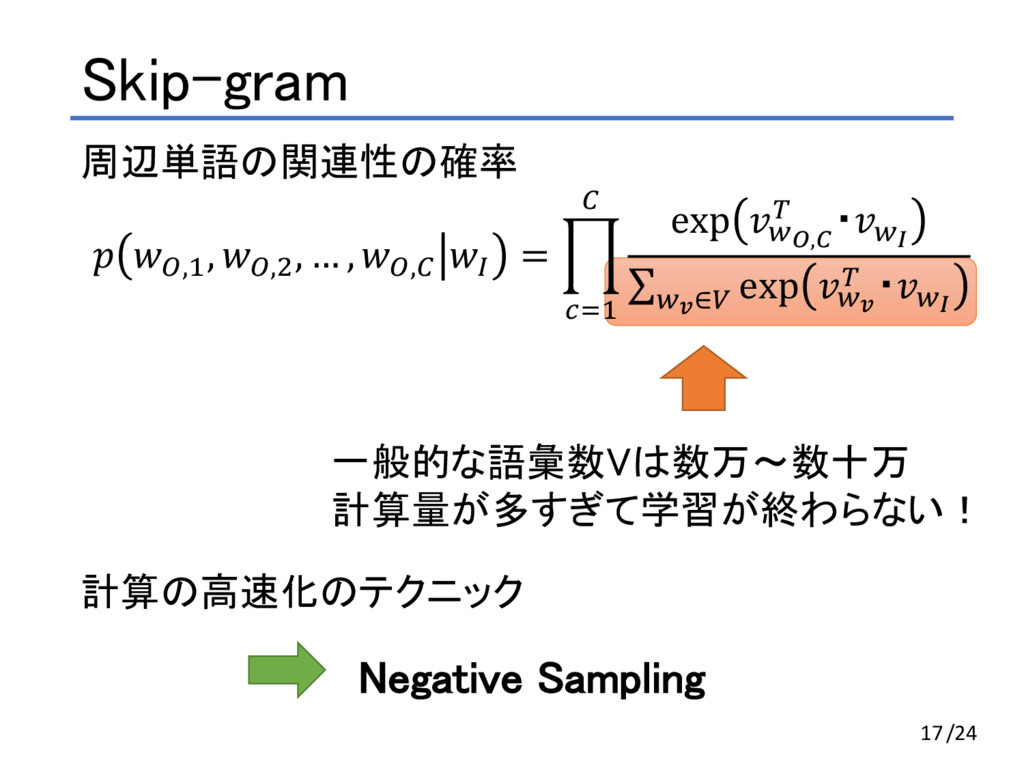
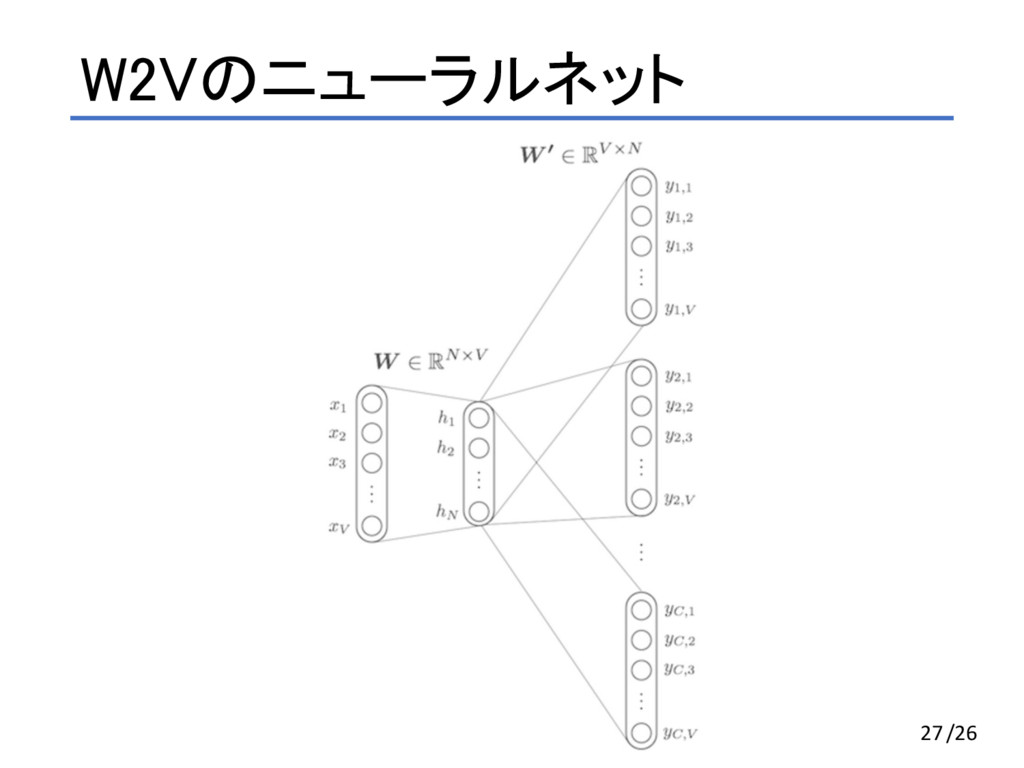
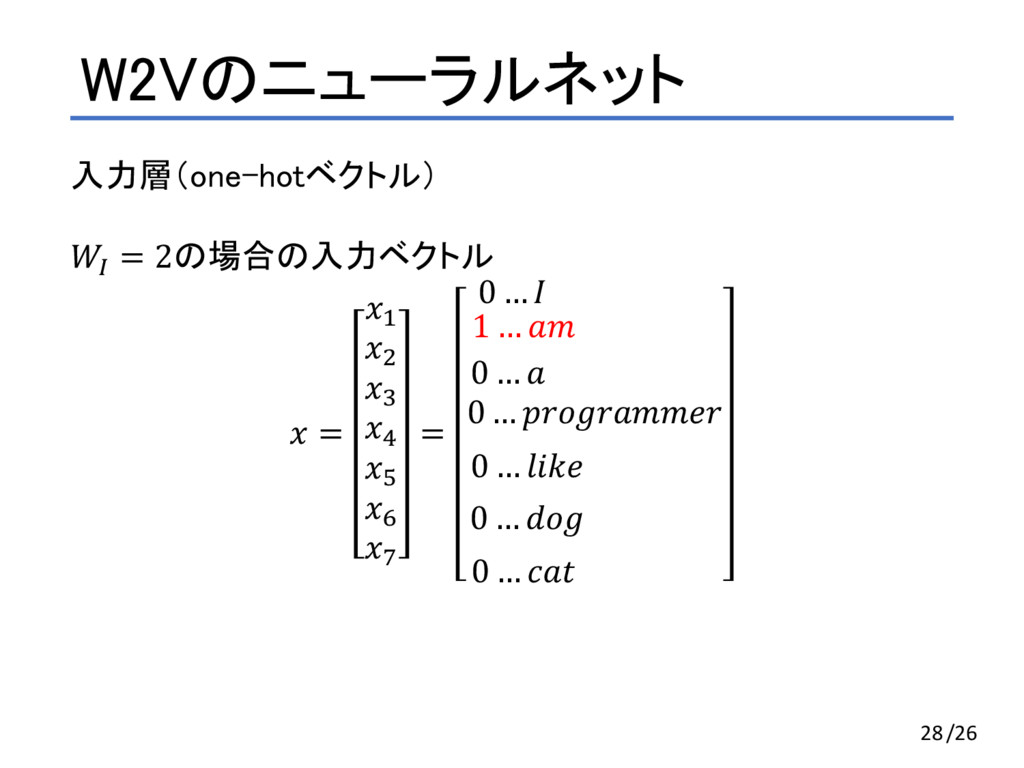
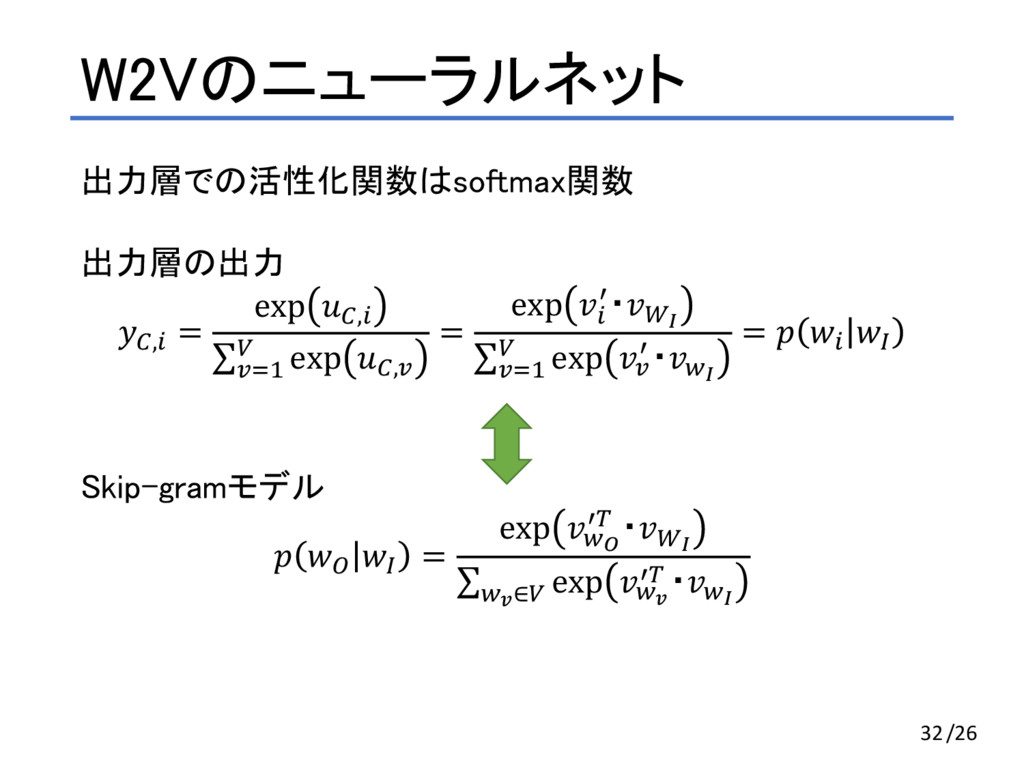
, #,D $ = E exp *+,F , ・*. ∑ exp *0 , ・*. *0∈3 D GHA 「I am a programmer 」という文章で前後1単語ずつ考える(C=1) • $ が I の時、Cは{ am } • $ が am の時、Cは{ I, a } • $ が a の時、Cは{ am, programmer } • $ が programmer の時、Cは{ a } 12/24
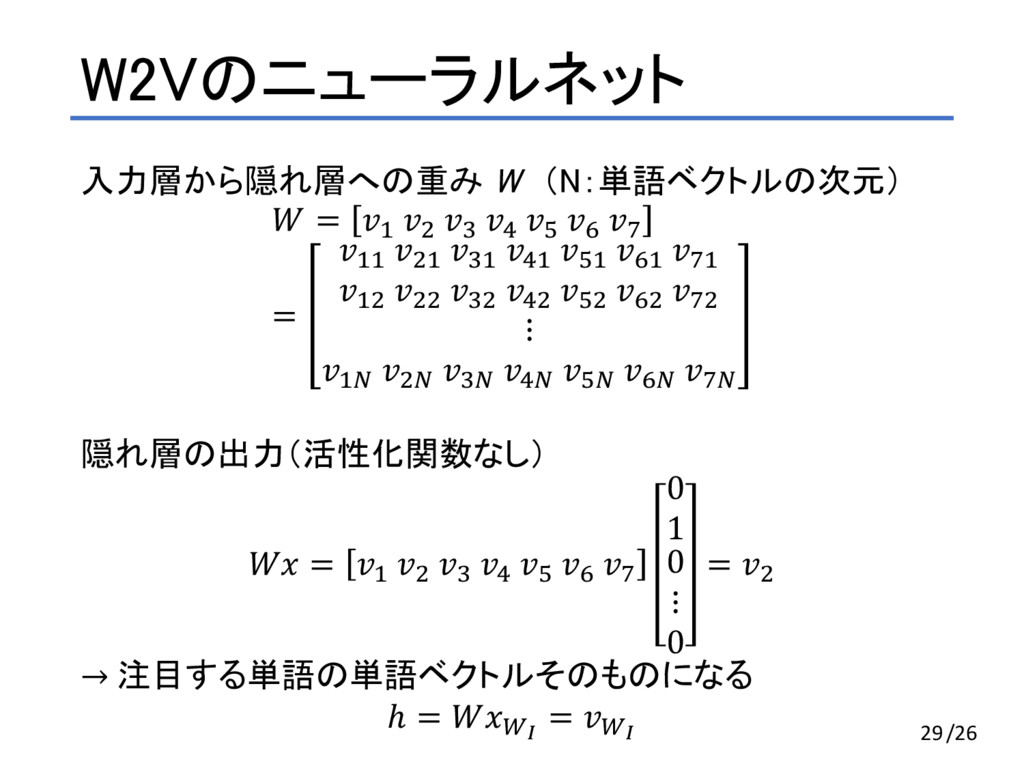
c d = AA BA `A aA bA cA dA AB BB `B aB bB cB dB ⋮ Aj Bj `j aj bj cj dj 隠れ層の出力(活性化関数なし) = A B ` a b c d 0 1 0 ⋮ 0 = B → 注目する単語の単語ベクトルそのものになる ℎ = -. = -. 29/26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}