Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介:What In-Context Learning “Learns” In-Conte...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
yuri
August 21, 2023
Research
650
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
論文紹介:What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task Learning
yuri
August 21, 2023
More Decks by yuri
See All by yuri
データ指向モデリング「テキストマイニングの基礎」
yuri00
0
34
論文紹介:∞-former: Infinite Memory Transformer
yuri00
0
430
論文紹介:Learning Dependency-Based Compositional Semantics
yuri00
0
170
論文紹介:What Context Features Can Transformer Language Models Use?
yuri00
0
470
Other Decks in Research
See All in Research
「AIとWhyを深堀る」をAIと深堀る
iflection
0
520
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
670
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.4k
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
160
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
120
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
110
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
310
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
Featured
See All Featured
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Test your architecture with Archunit
thirion
1
2.3k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Making the Leap to Tech Lead
cromwellryan
135
10k
Thoughts on Productivity
jonyablonski
76
5.2k
The Language of Interfaces
destraynor
162
27k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Tell your own story through comics
letsgokoyo
1
1k
Transcript
What In-Context Learning “Learns” In-Context: Disentangling Task Recognition and Task
Learning Jane Pan, Tianyu Gao, Howard Chen, Danqi Chen ACL2023 Findings 村山 友理 東大和泉研 2023/08/27 第15回最先端NLP勉強会
事前学習したものを思い出してい るだけ? In-context learning は何をしているのか? 2 デモ(正しい入出力ペア)から学習 している?
• 事前学習時にダウンストリームで必要なタスクを暗黙的に学習していて、in-context のデモはどのタスクを解くべきかモデルに認識させるための情報を与えるだけ (Xie+ 22) • ICL性能は正解ラベルの使用に対してinsensitive (Min+ 22) 事前学習したものを思い出しているだけ?
3
• Transformer-based モデルは「内部モデル」を更新するために暗黙的に勾配降下 法を行っている可能性 (Akyürek+ 23), (vonOswald+ 22) • 実データセットの指標を用いると、ICLとファインチューニングには類似点がある
(Dai+ 23) デモから学習している? 4
ICLの能力を「タスク認識」と「タスク学習」に分解 5 事前学習したものを思い出してい るだけ? タスク認識 デモ(正しい入出力ペア)から学習 している? タスク学習 • それぞれの能力を評価するために、プロンプトのラベルを操作
• いろいろなモデルサイズとデモ数で実験
Random (= タスク認識) • ラベルは一様にランダムにサンプリングされる ラベル操作 1. Random 6
Abstract (=タスク学習) • プロンプトからタスク指示文を取り除き、ラベルを抽象的な記号に置換 ◦ 数字 (0, 1, 2,...) /
文字 (A, B, C,...) / 記号 (@, #, $, %, *, ∧,...) • 抽象的なラベルであっても事前学習のバイアスがある可能性 ◦ 例えば、“0”は負例っぽい ◦ バイアスを避けるために、プロンプト毎にラベルから抽象記号にランダムに写像 ラベル操作 2. Abstract 7
Gold (= タスク認識 + タスク学習) • 正解の入力・ラベルペアが与えられる従来のプロンプト ラベル操作 3. Gold
8
• データセット ◦ 4タイプのタスクに関する16の分類データセットを使用: ▪ 感情分析 ▪ 毒性検出 ▪ 自然言語推論
/ 言い換え検出 ▪ トピック / スタンス分類 • モデル ◦ GPT-3 (Brown+ 20) ▪ ada (350M), babbage (1.3B), curie (6.7B), davinci (175B) (OpenAI API) ◦ LLaMA (Touvron+ 23) ▪ 7B, 13B, 33B, 65B ◦ OPT (Zhang+ 22) ▪ 350M, 2.7B, 6.7B, 13B, 30B, 66B (Transformers library) 実験設定 9
• タスク設定 ◦ テスト用に訓練セットからデモをサンプリング ▪ GPT-3: 150 対(予算の都合により) ▪ OPT,
LLaMA: 1,350 対 ◦ 分類タスクのタイプ毎に3種類のプロンプト雛形を用意 ◦ データセットとプロンプト全体の平均を報告 実験設定 10
• Gold (= タスク認識 + タスク学習) ◦ 全体的に一番良い • Random
(= タスク認識) ◦ 性能はスケールに依らずほぼ 横ばい • Abstract (= タスク学習) ◦ モデルサイズとデモ数に応じて 増加 ◦ 小さなモデル、少ないデモ数で はRandomより低いが、パラ メータ数・デモ数が増えると逆転 ◦ LLaMA-65B以外のOPT-66Bと davinciはGOLDに匹敵 結果 11 ※ Abstractについては数字ラベルの結果
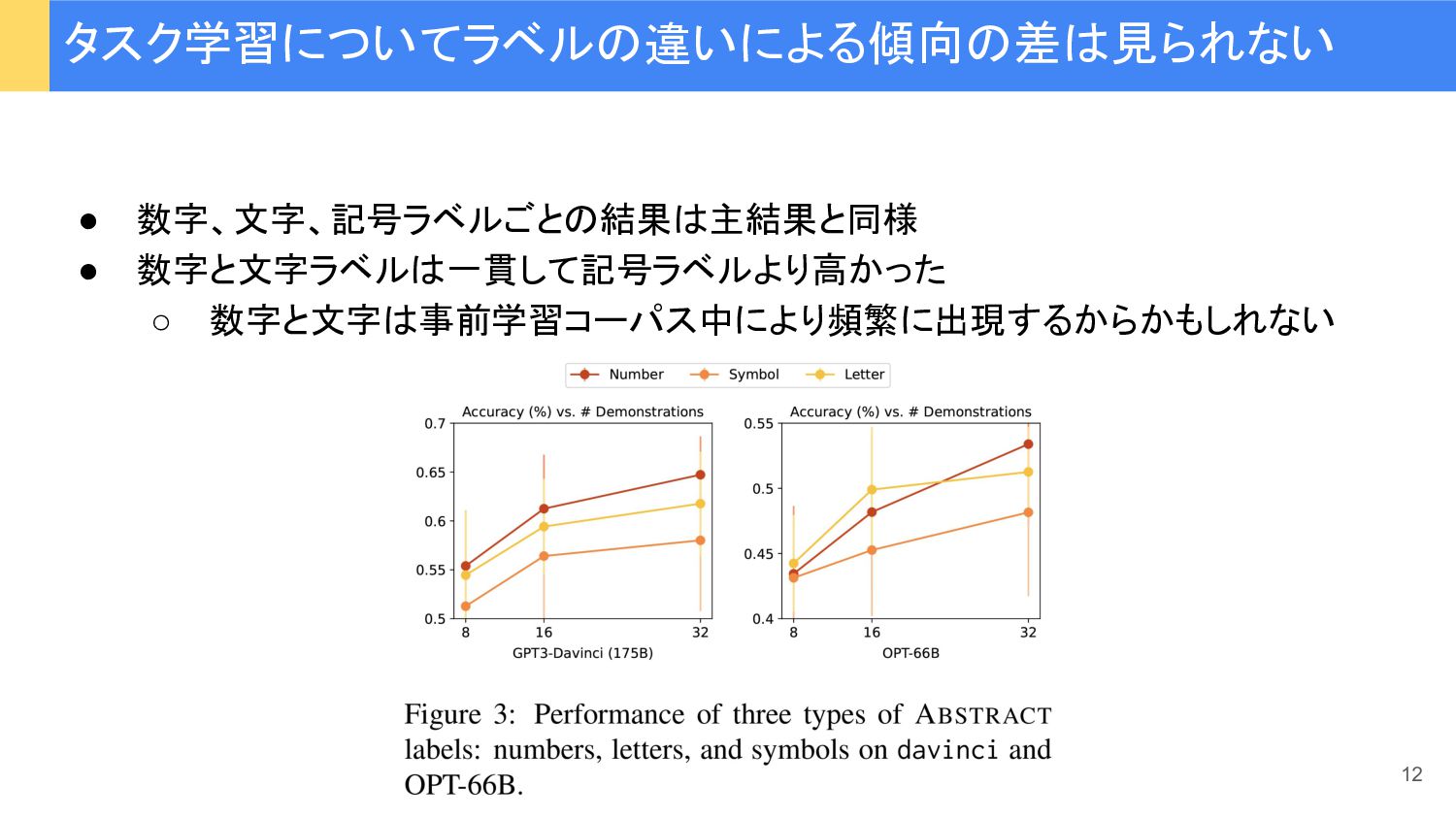
• 数字、文字、記号ラベルごとの結果は主結果と同様 • 数字と文字ラベルは一貫して記号ラベルより高かった ◦ 数字と文字は事前学習コーパス中により頻繁に出現するからかもしれない タスク学習についてラベルの違いによる傾向の差は見られない 12
• 感情分析とNLIを比較 • NLIのAbstract曲線がより平らなので、プロンプトと事前学習の質が重要 タスク学習ではタスクが単純な方がサイズとデモ数にスケールする 13
タスクのタイプ別の結果 14 感情分析 トピック / スタンス分類 毒性検出 NLI / 言い換え検出
GPT-3 LLaMA OPT
• ICLを2つの能力「タスク認識」と「タスク学習」に分解し、それぞれ異なる条件下で 発現することを示した • 小さなモデルでもタスク認識の能力はあるが、スケールしない • タスク学習の能力は大きなモデルで現れる ◦ 小さなモデルではデモを増やしても性能が上がらない ◦
大きなモデルはデモが増えると性能も向上 • Limitations ◦ 「タスク認識」と「タスク学習」に分けたが、タスク学習がデモで示されたパター ンを事前学習で学習した概念に代替しているとすれば、タスク認識の進化形と 捉えることもできるかもしれない まとめ 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}