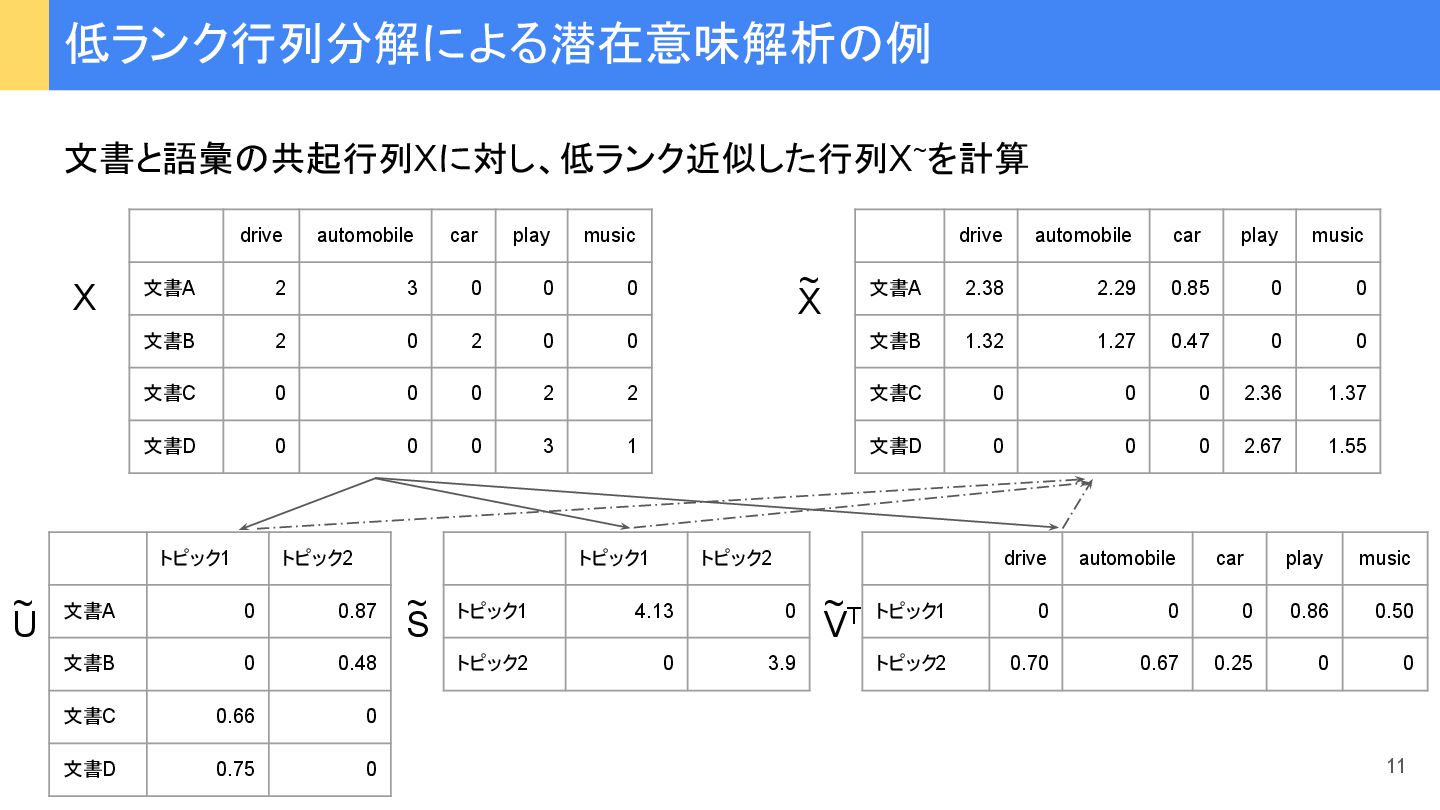
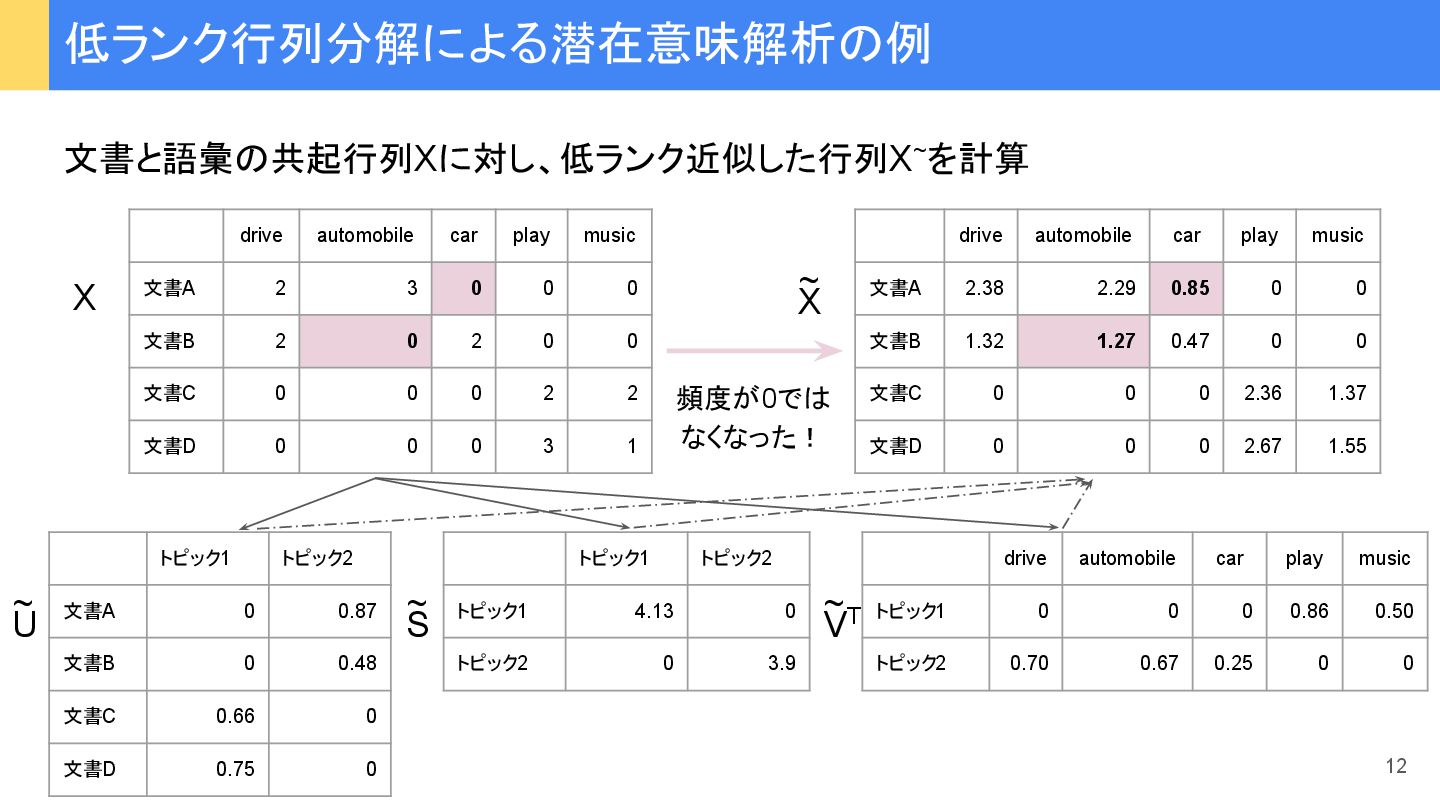
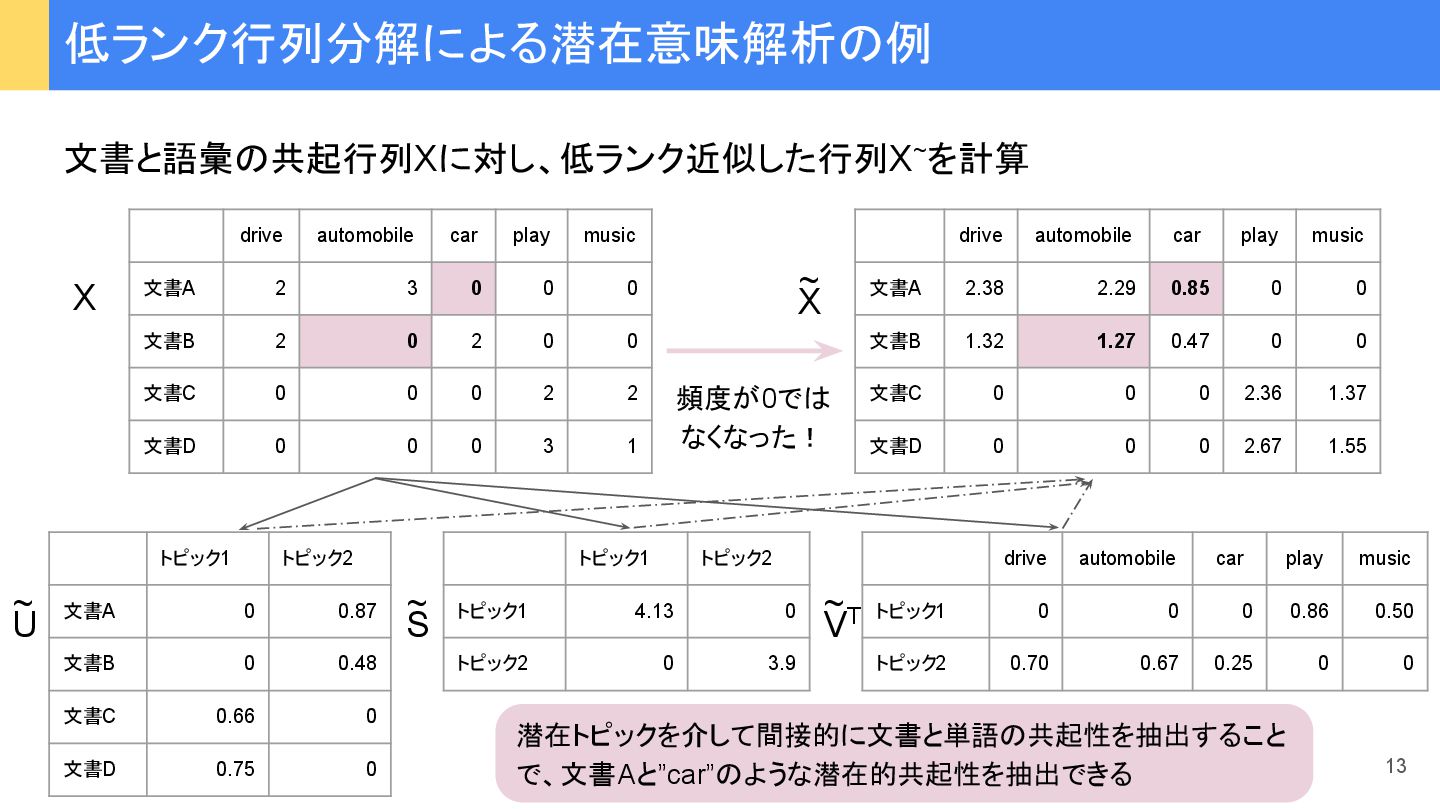
…, x n ), y=(y 1 , y 2 , …, y i , …, y n ) ピアソン 積率相関係数 (Pearson product-moment correlation coefficient)(また ピアソン相関係数、 あるい 単に相関係数) つぎ ように定義: x, y 変数x, y 平均 r xy -1から1まで 実数値をとり、 • r xy が1に近いほどx, y間に 強い正 相関がある • r xy が-1に近いほどx, y間に 強い負 相関がある • r xy が0に近いときx, y 無相関 類似度 指標① ピアソン 積率相関係数 28 ‾ ‾
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
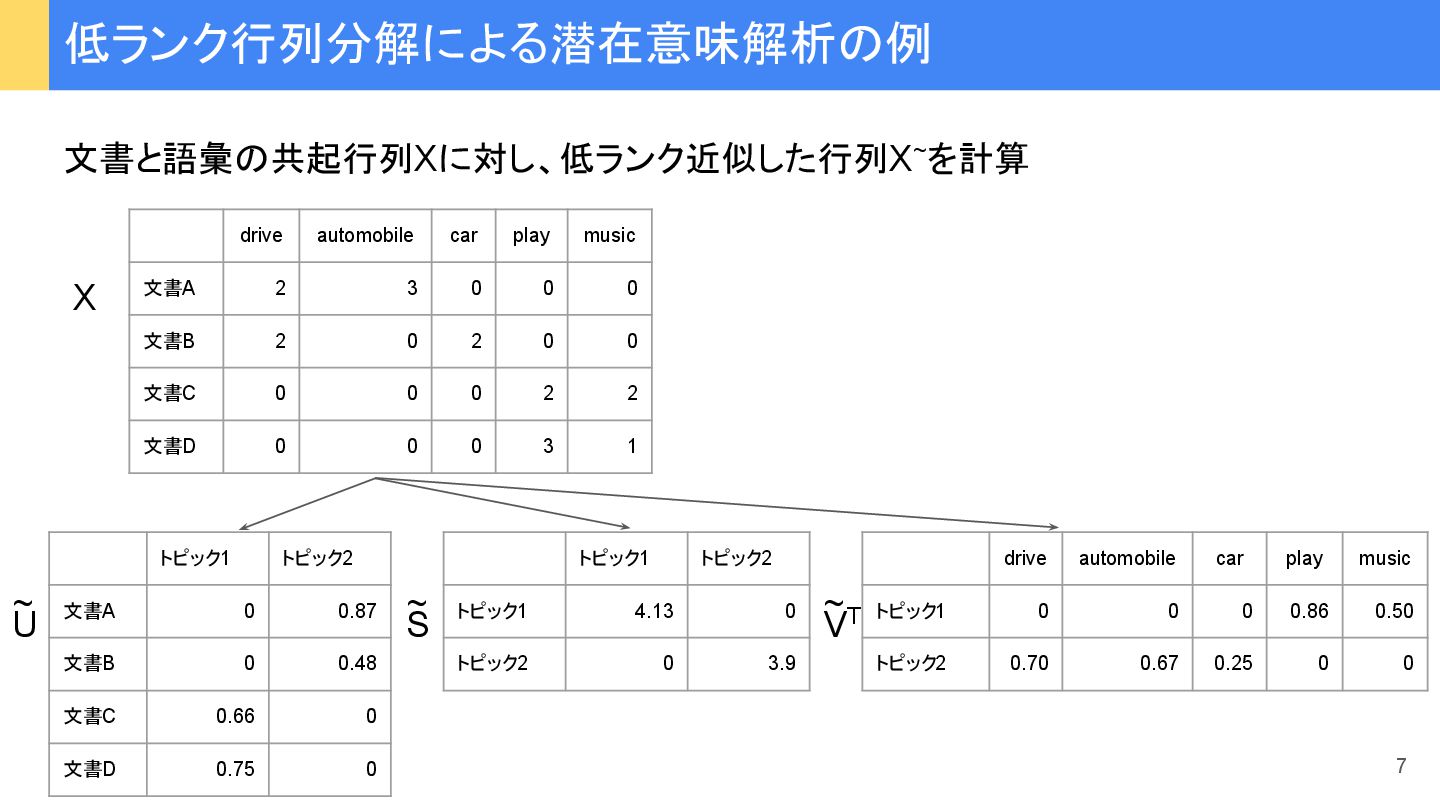{kind=link}
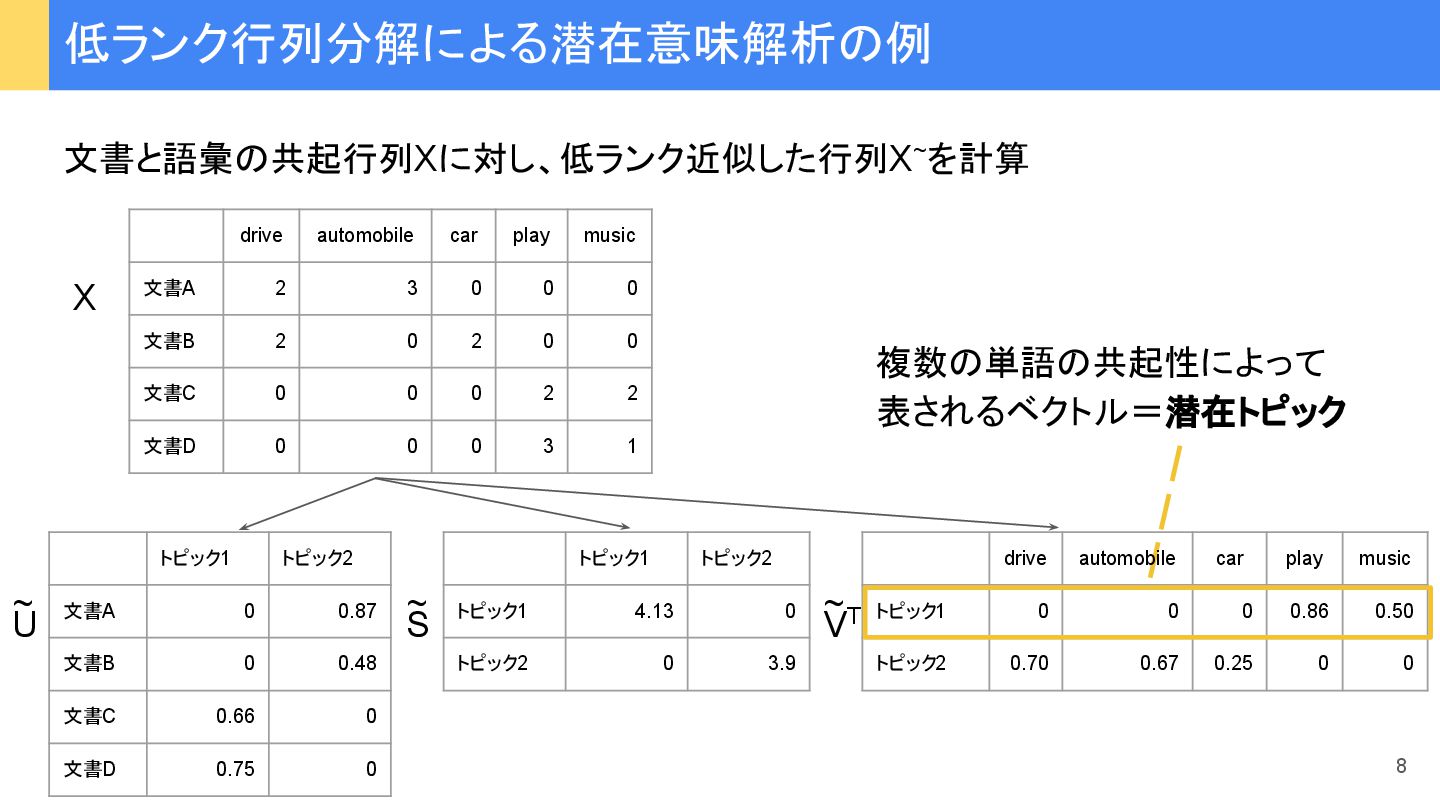{kind=link}
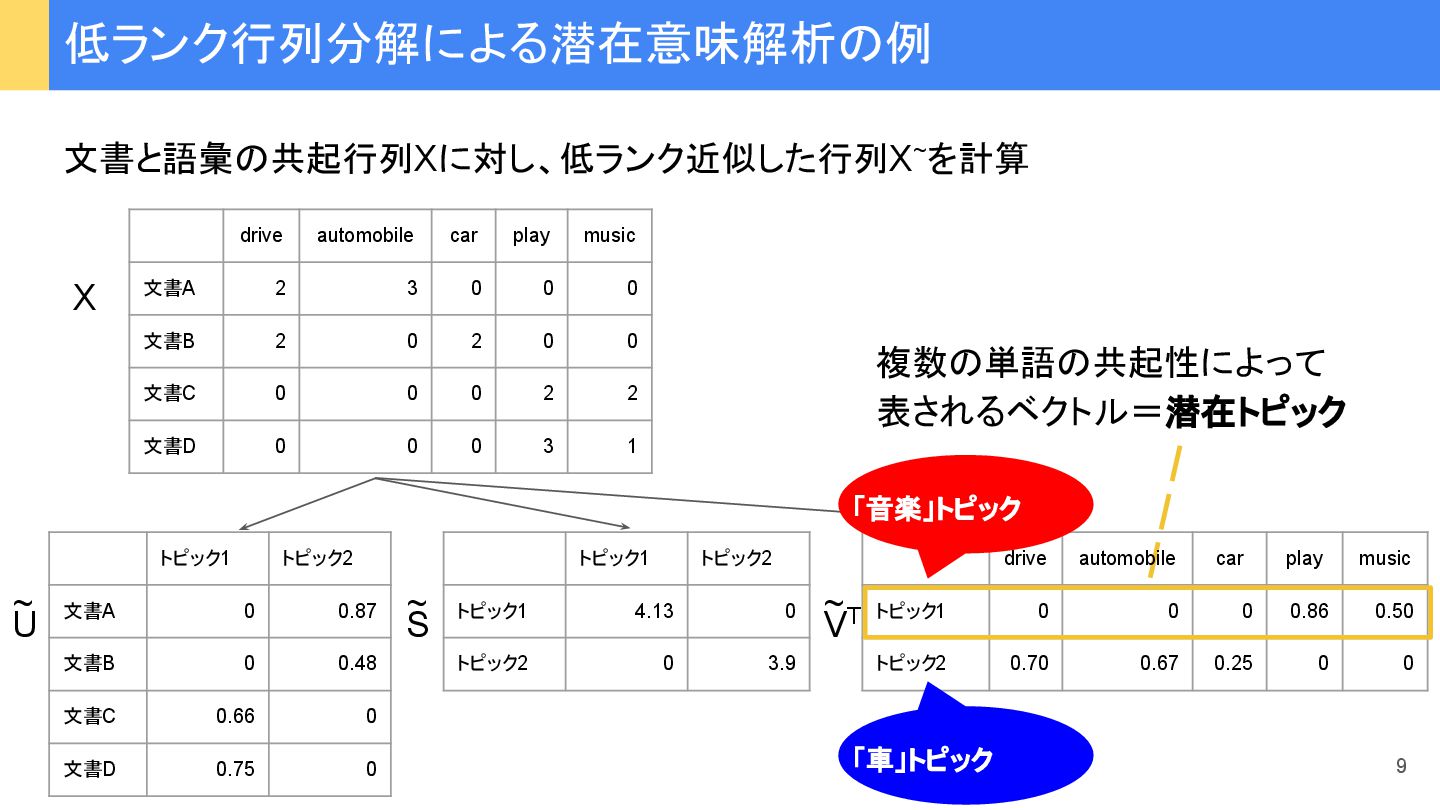{kind=link}
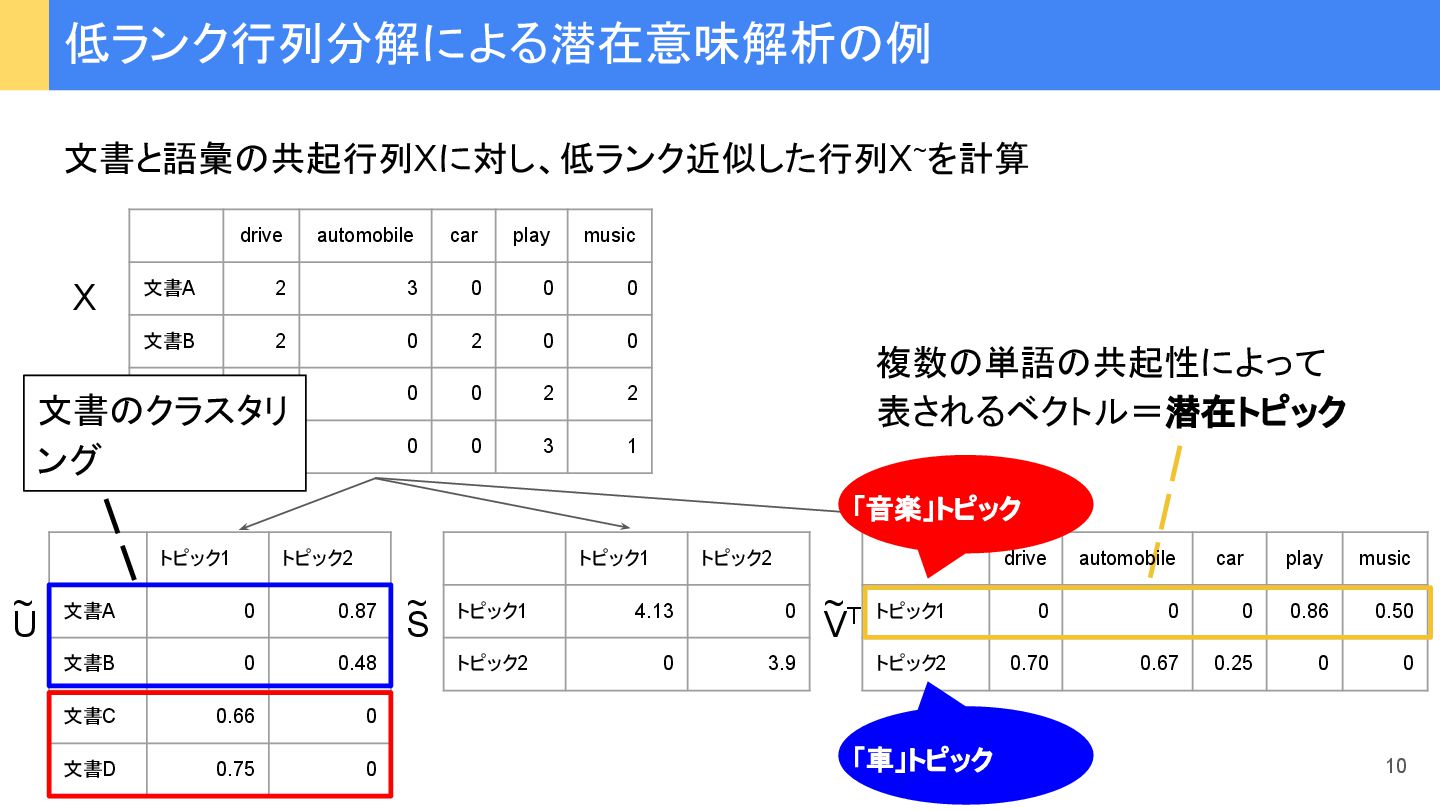{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
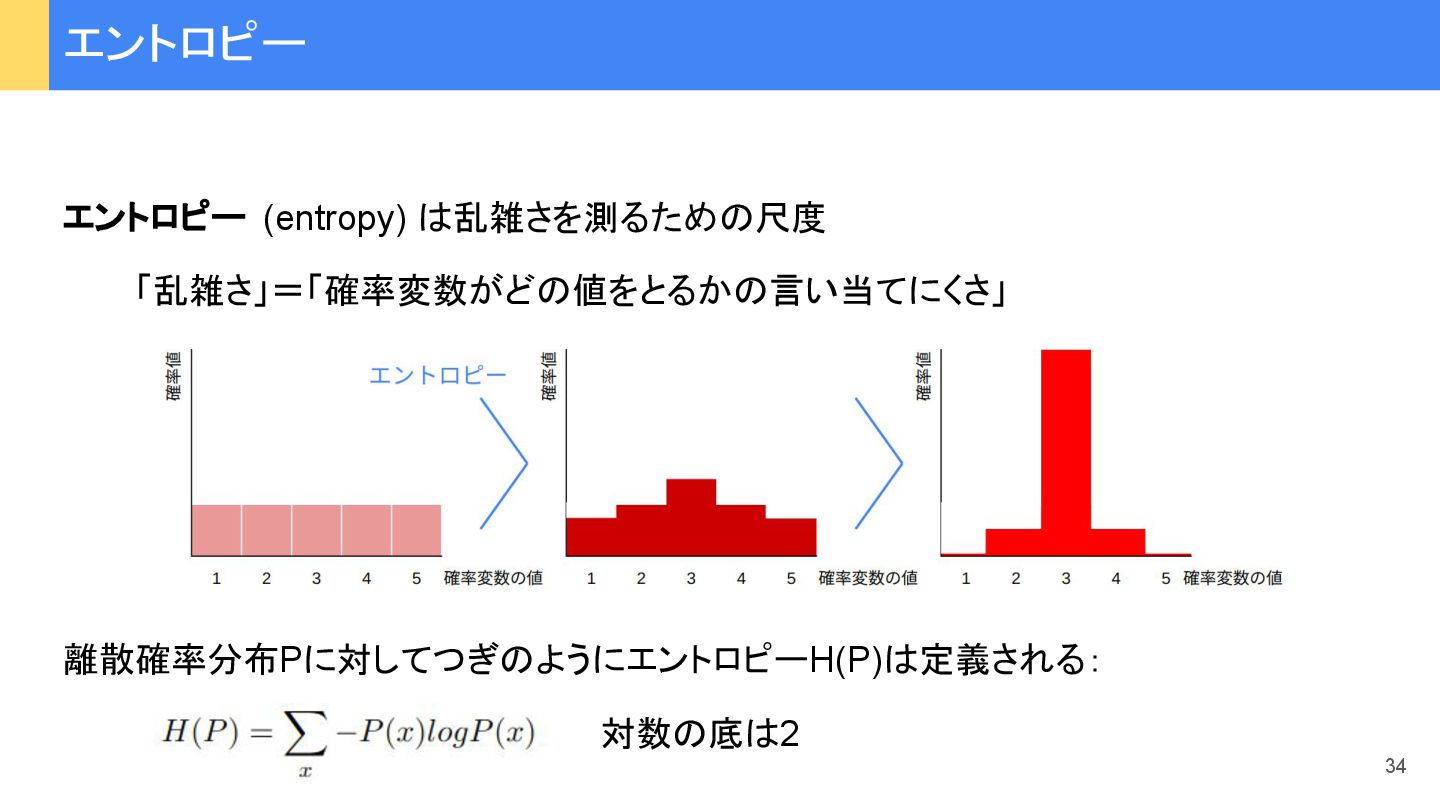{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
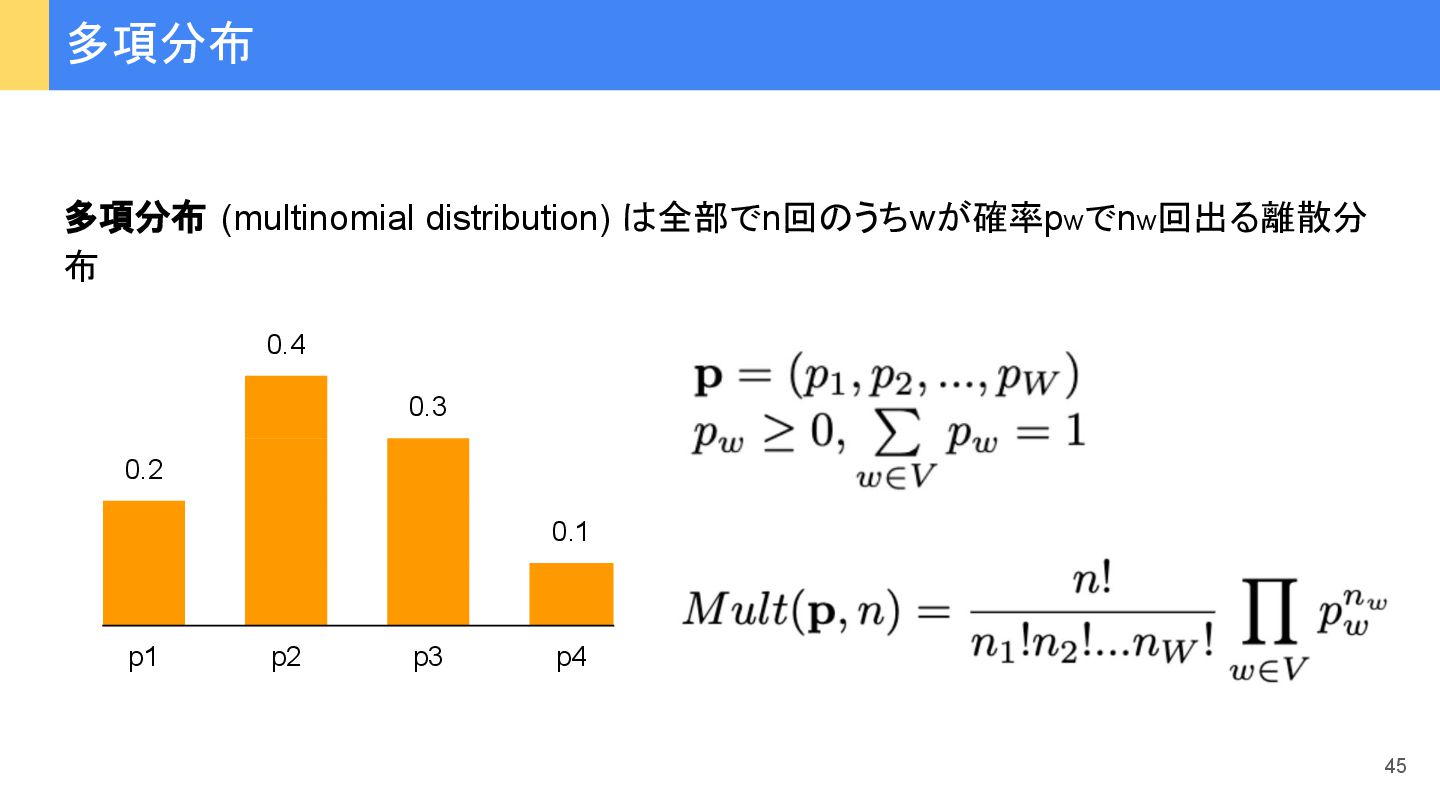{kind=link}
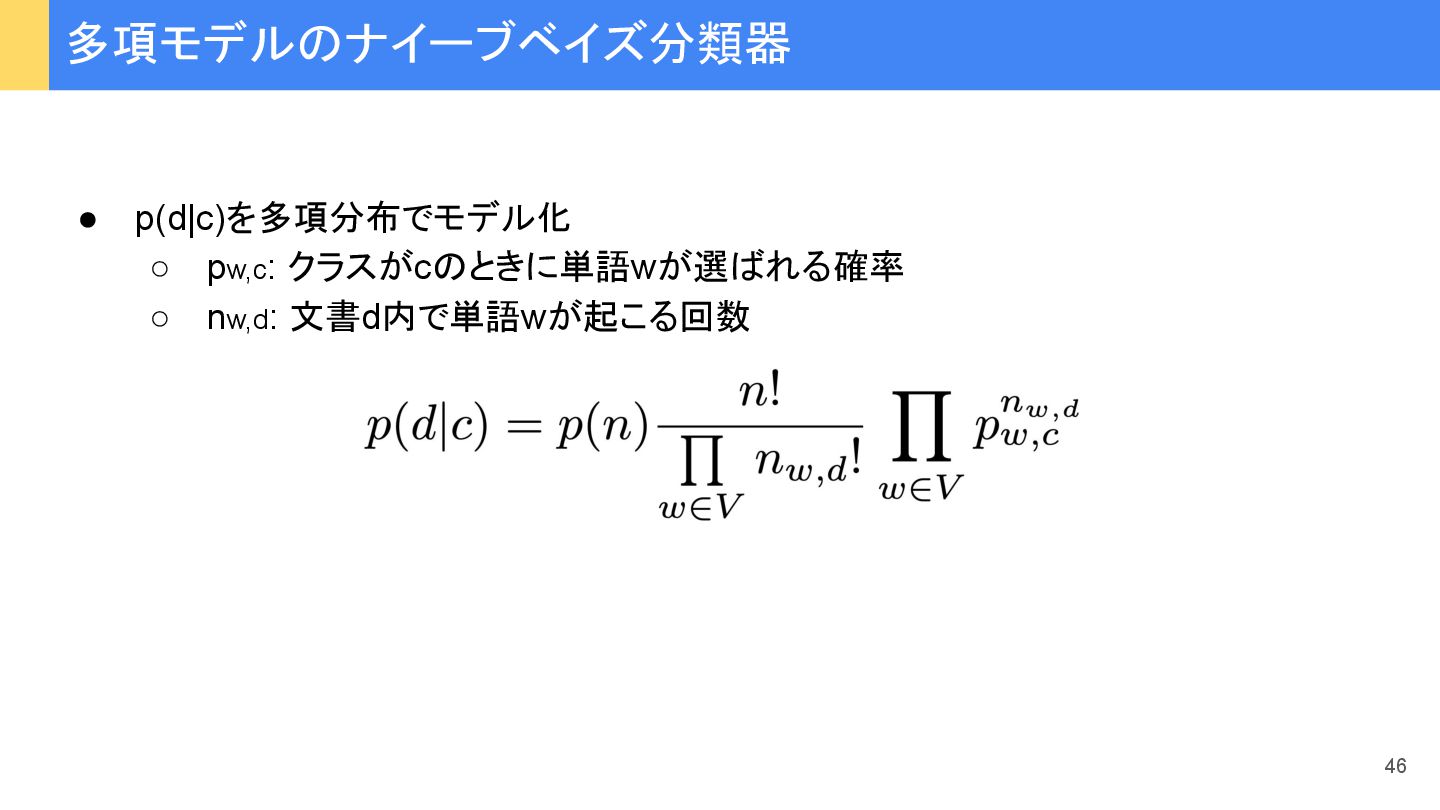{kind=link}
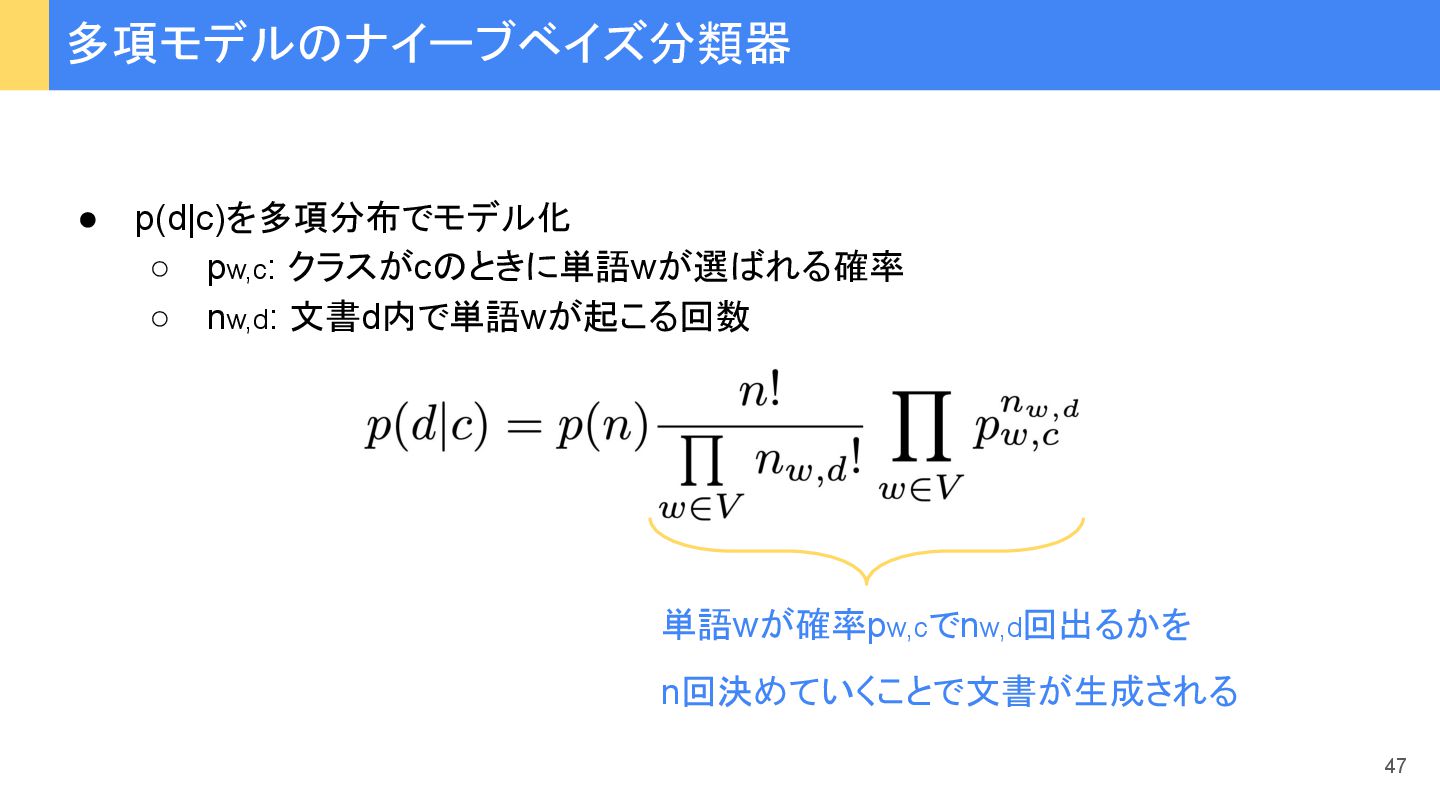{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}