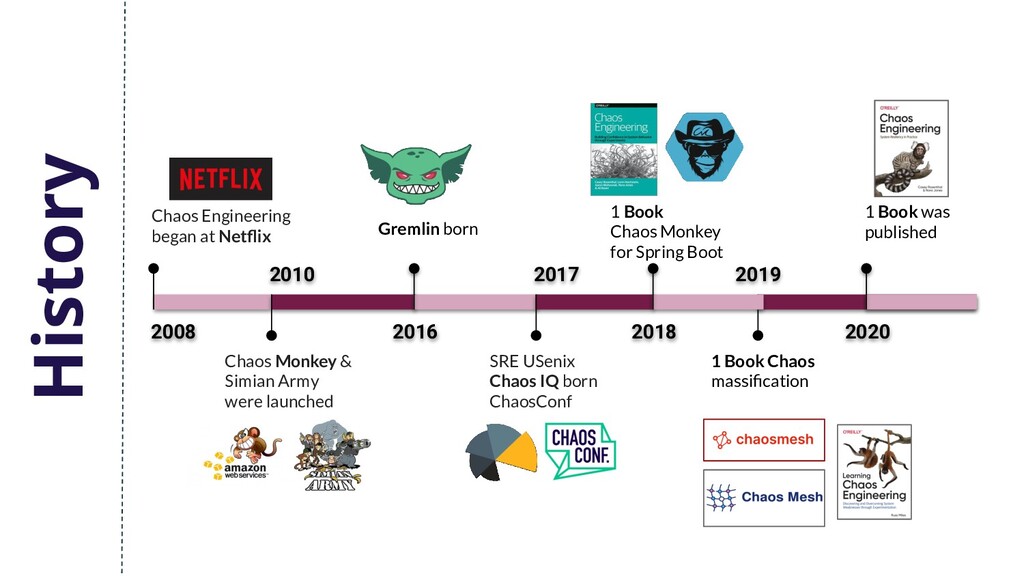
& Simian Army were launched 2016 Gremlin born 2019 1 Book Chaos massification 2017 SRE USenix Chaos IQ born ChaosConf 2018 1 Book Chaos Monkey for Spring Boot 2020 1 Book was published
I do What software engineers think I do What I really do Who is a Chaos Engineer? Help service owners to increase their resilience through education, tools and encouragement.
we test the fault tolerance of that new code! In January of 2018, they started a rigorous process of identifying failures that are likely to happen and that we must be able to tolerate, and then purposely causing them to happen in production. This isn’t Chaos Engineering as practiced and evangelized by Netflix. It’s the first step; we call it Disasterpiece Theater. Taken from Chaos Engineering Book - 2020
that will be caused to fail. 2. Survey the server or service in dev and prod. 3. Identify alerts, dashboards, logs, and metrics. 4. Identify redundancies and automated remediations. 5. Invite all the relevant people to the event! Taken from Chaos Engineering Book - 2020
failure in DEV! 2. Announce the exercise and incite the failure in PROD! 3. Receive alerts and inspect dashboards 4. Give automated remediations time to be triggered. 5. Follow runbooks to restore service in prod. 6. Debrief & distribute the recording! Taken from Chaos Engineering Book - 2020
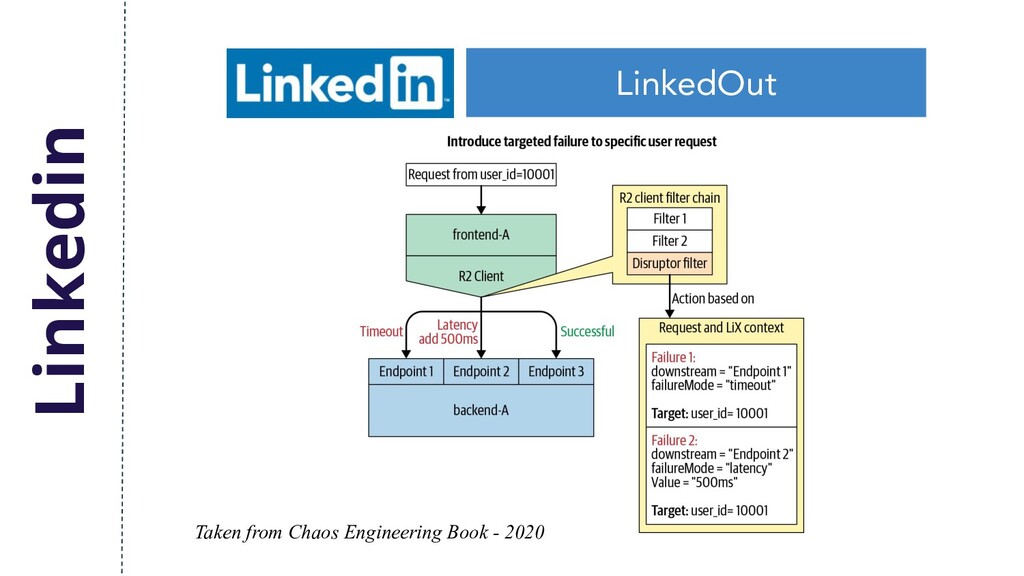
to help draw conclusions about how we should plan their chaos experiments. When you’re running failure experiments for the first time, it’s important to start small. Even shutting down one server can be hard to recover from. 3 failure modes into the disruptor: Error, Delay and Timeout. Taken from Chaos Engineering Book - 2020
capabilities powered by blockchain, AI, machine learning, and business intelligence. They are building cloud native apps and adopting practices like CI/CD pipelines, templated frameworks, secret management and Chaos Engineering. They started with a list of around 25 experiments. Taken from Chaos Engineering Book - 2020
behavior. 2. Potential/possible failures. 3. Impact to in-flight transactions. 4. Monitoring of the infrastructure and application. 5. Risk score for each experiment. Taken from Chaos Engineering Book - 2020
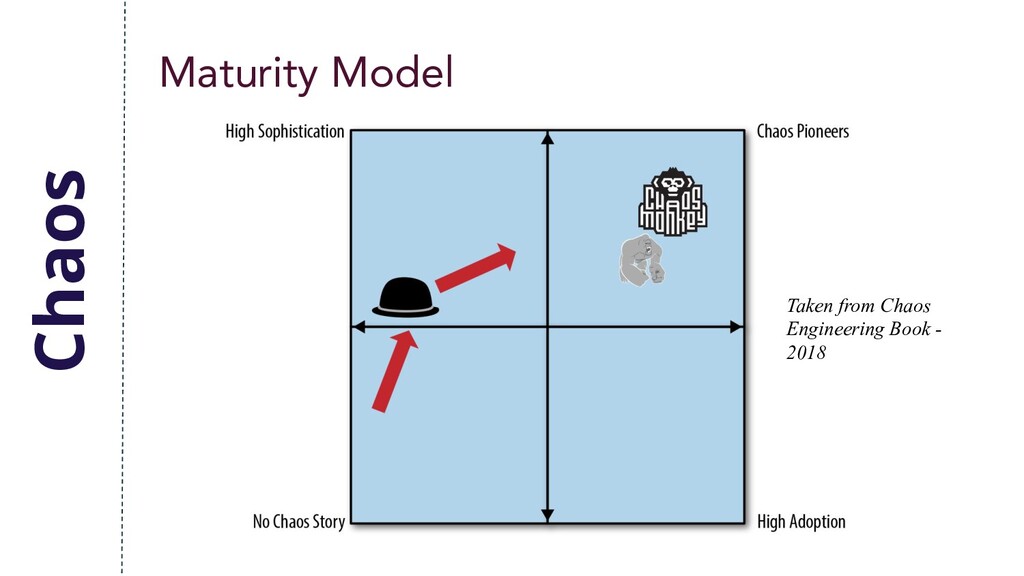
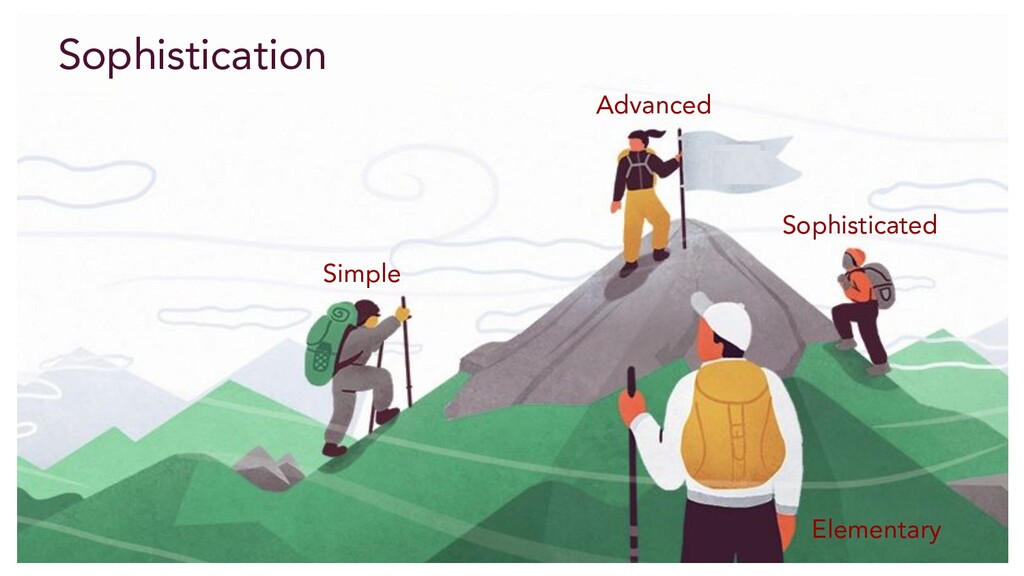
process is administered manually. • Results do not reflect business metrics. • Simple events are applied like turn it off. Taken from Chaos Engineering Book - 2018
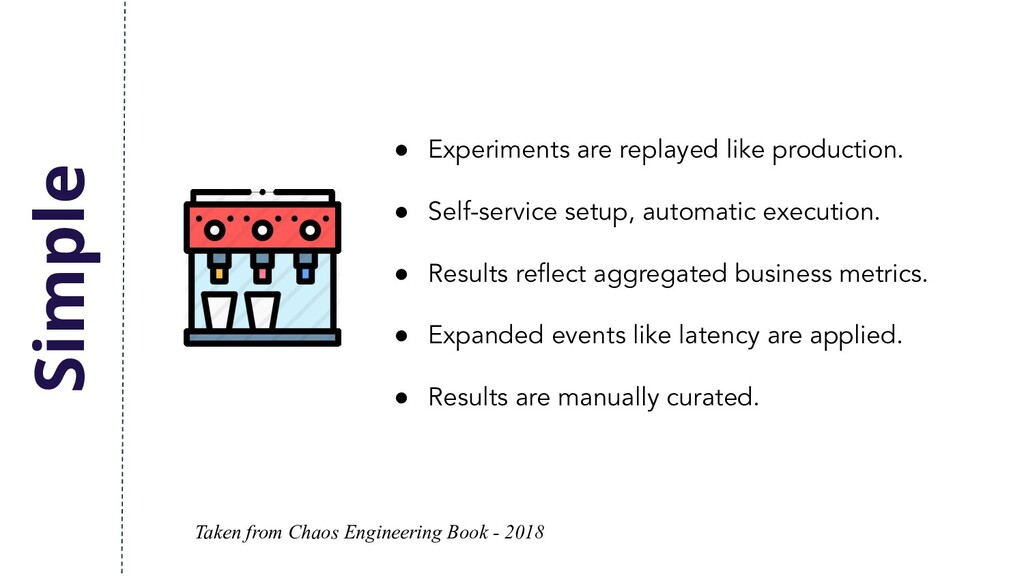
automatic execution. • Results reflect aggregated business metrics. • Expanded events like latency are applied. • Results are manually curated. Taken from Chaos Engineering Book - 2018
are automated. • Experimentation is integrated with CD. • Business metrics are compared. • Combination of failures. • Results are tracked over time. Sophisticated Taken from Chaos Engineering Book - 2018
and execution are fully automated. • Events include state mutation. • Experiments have dynamic scope. • Revenue loss can be projected from results. • Capacity forecasting can be performed. Advanced Taken from Chaos Engineering Book - 2018
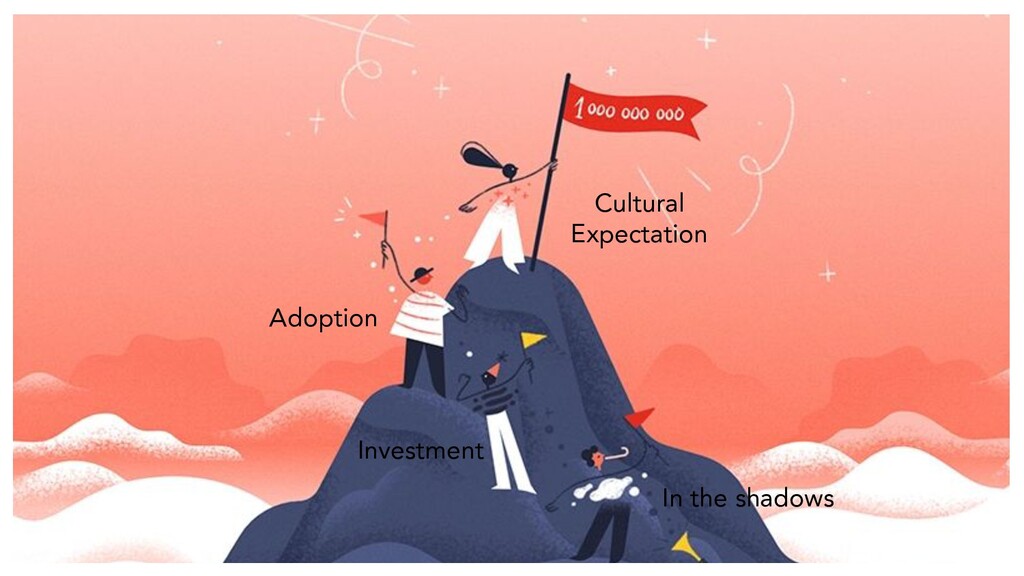
There is low or no organizational awareness. • Early adopters infrequently perform chaos experimentation. In shadows Taken from Chaos Engineering Book - 2018
allow to create regression experiments. • Critical services practice regular Chaos. • Occasional Gamedays are performed. Adoption Taken from Chaos Engineering Book - 2018
services use chaos. • Chaos experimentation is part of onboarding. • Participation is the default behavior. Expectation Taken from Chaos Engineering Book - 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}