• Random celebrity gossip • Natural disasters • Discussions never expire • We can’t keep those millions of articles from 2008 in the cache • You don’t know in advance (generally) where the traffic will be • Especially with dynamic paging, realtime, sorting, personal prefs, etc. 5
memory and measure I/O • High I/O generally means slow queries due to missing indexes or indexes not in buffer cache • Log Slow Queries • syslog-ng + pgFouine + cron to automate slow query logging 12
doesn’t do this for you • We use pgbouncer • Limits the maximum number of connections your database needs to handle • Save on costly opening and tearing down of new database connections 13
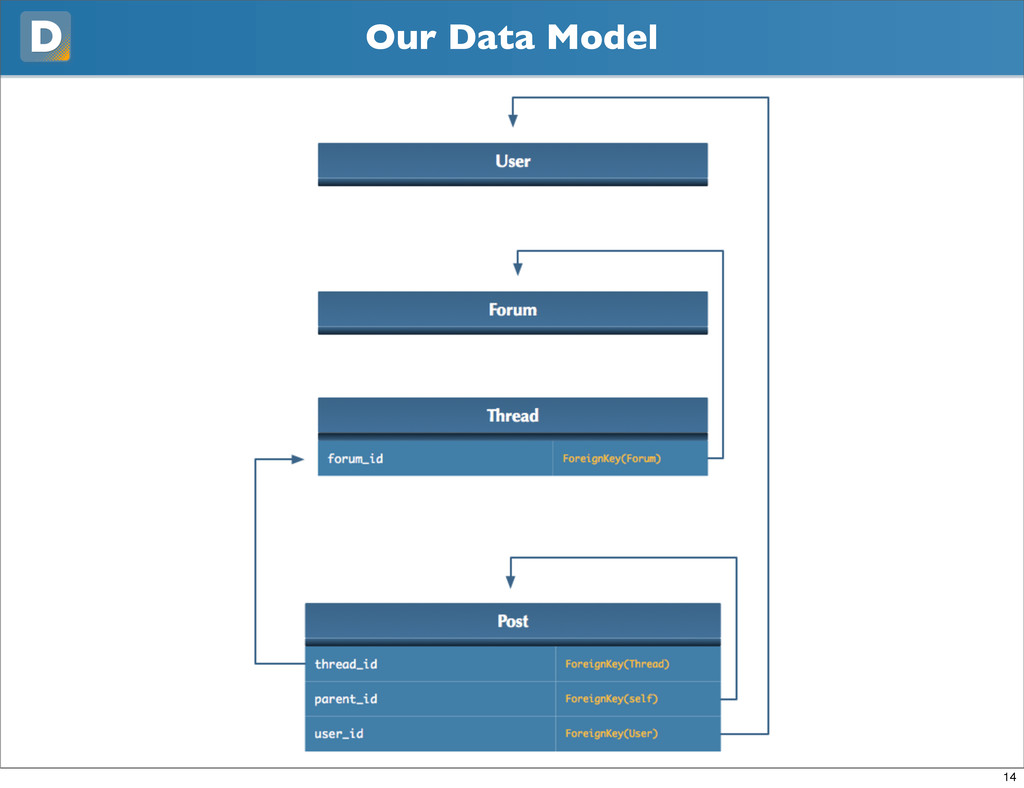
dictionary based on primary key users = dict( (u.pk, u) for u in \ User.objects.filter(pk__in=set(p.user_id for p in posts)) ) # map users to their posts for p in posts: p._user_cache = users.get(p.user_id) Allows us to separate datasets 17
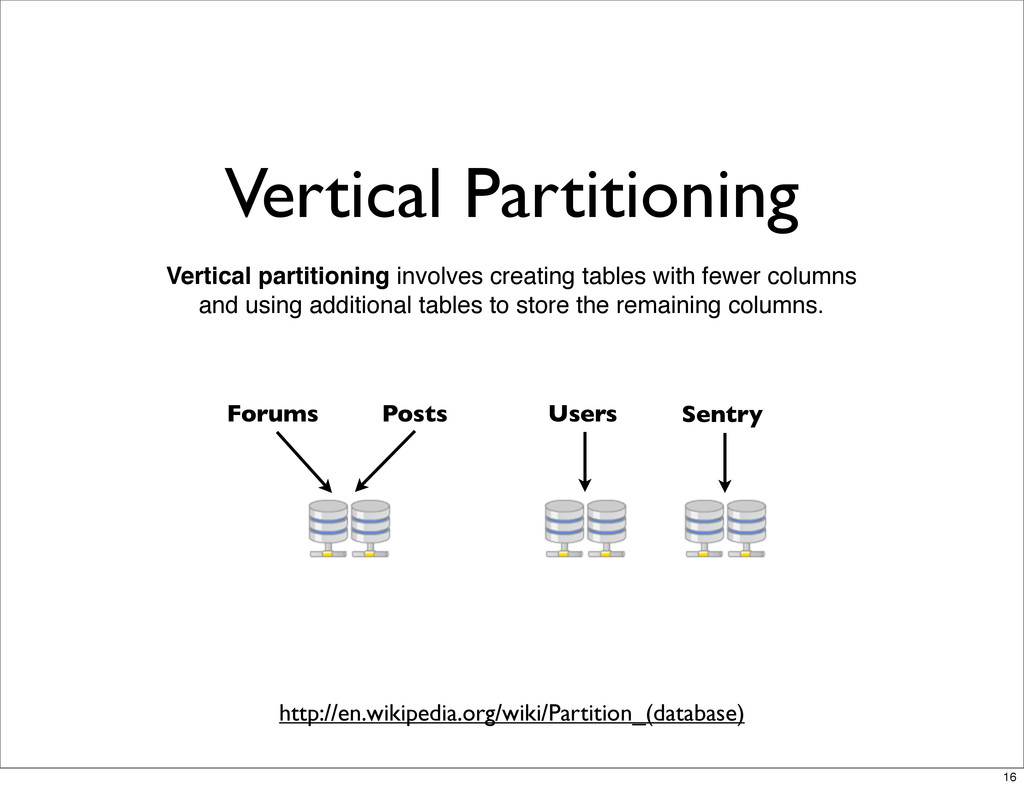
But not enough that you should care • Trading performance for scale • Allows us to separate data • Easy vertical partitioning • More efficient caching • get_many, object-per-row cache 18
your primary application master • Masters exist under specific conditions: • application use case • partitioned data • Database routers make this (fairly) easy 19
= hints.get('instance') if not instance: return None forum_id = getattr(instance, 'forum_id', None) if not forum_id: return None return get_forum_alias(forum_id) # Now, making sure hints are available forum.post_set.all() # What we used to do Post.objects.filter(forum=forum) 23
your QuerySet • This adds additional memory overhead • Many times you only need to view a result set once • So we built SkinnyQuerySet # 1 query qs = Model.objects.all()[0:100] # 0 queries (we don’t need this behavior) qs = qs[0:10] # 1 query qs = qs.filter(foo=bar) 25
is not None: # __len__ must have been run return iter(self._result_cache) has_run = getattr(self, 'has_run', False) if has_run: raise QuerySetDoubleIteration("...") self.has_run = True # We wanted .iterator() as the default return self.iterator() Optimizing memory usage by removing the cache http://gist.github.com/550438 26
Post.objects.filter(pk=post.pk)\ .update(approved=True) So we need atomic updates Request 1 post = Post(pk=1) # the author adjusts their message Post.objects.filter(pk=post.pk)\ .update(message=‘Hello!’) Request 2 29
attributes on the current instance. """ assert obj, "Instance has not yet been created." obj.__class__._base_manager.using(using)\ .filter(pk=obj) .update(**kwargs) for k, v in kwargs.iteritems(): if isinstance(v, ExpressionNode): # NotImplemented continue setattr(obj, k, v) A better way to approach updates http://github.com/andymccurdy/django-tips-and-tricks/blob/master/model_update.py 30
created, **kwargs): print data[‘id’] delayed_save.connect(my_func, sender=Post) We send a specific serialized version of the model for delayed signals This is all handled through our Queue 32
• Memcached “single point of failure” • Distributed system, but we must take precautions. • Connection timeout to memcached can stall requests. • Use `_auto_eject_hosts` and `_retry_timeout` behaviors to prevent reconnecting to dead caches. 34
cache key cache for index to server list. • Removal of a server causes majority of cache keys to be remapped to new servers. CACHE_SERVERS = [‘10.0.0.1’, ‘10.0.0.2’] key = ‘my_cache_key’ cache_server = CACHE_SERVERS[hash(key) % len(CACHE_SERVERS)] 35
uses libketama (http://tinyurl.com/lastfm-libketama) • Addition / removal of a cache server remaps (K/n) cache keys (where K=number of keys and n=number of servers) Image Source: http://sourceforge.net/apps/mediawiki/kai/index.php?title=Introduction 36
heavily accessed cache key causes many clients to refill cache. • But everyone refetching to fill the cache from the data store or reprocessing data can cause things to get even slower. • Most times, it’s ideal to return the previously invalidated cache value and let a single client refill the cache. • django-newcache or MintCache (http:// djangosnippets.org/snippets/793/) will do this for you. • Prefer filling cache on invalidation instead of deleting from cache also helps to prevent the thundering herd problem. 37
became a burden • For postgresql_psycopg2, there’s a database option, OPTIONS[‘autocommit’] • Each query is in its own transaction. This means each request won’t start in a transaction. • But sometimes we want transactions (e.g., saving multiple objects and rolling back on error) 38
databases. • Isolate slow functions (e.g., external calls, template rendering) from transactions. • Selective autocommit • Most read-only views don’t need to be in transactions. • Start in autocommit and switch to a transaction on write. 39
an hour on some days • Hudson keeps our builds going • combined with Selenium • Post-commit hooks for quick testing • like Pyflakes • Reverting to a previous version is a matter of seconds 44
new guy • Our testing process is fairly heavy • 70k (Python) LOC, 73% coverage, 20 min suite • Custom Test Runner (unittest) • We needed XML, Selenium, Query Counts • Database proxies (for read-slave testing) • Integration with our Queue 46
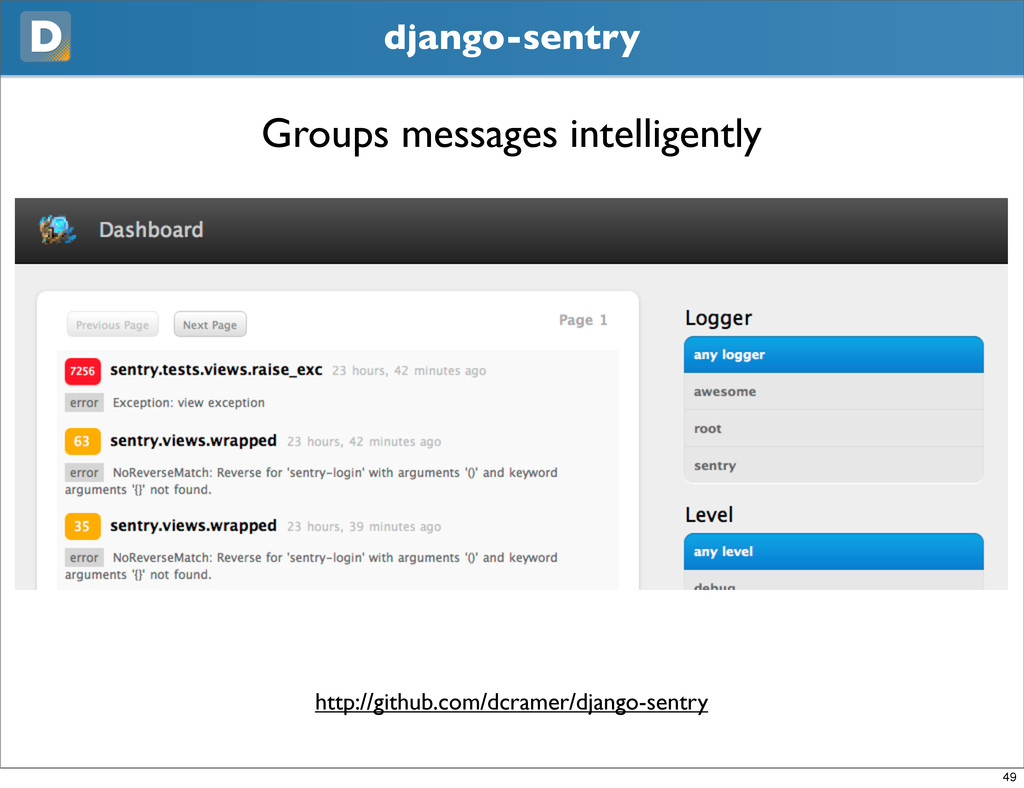
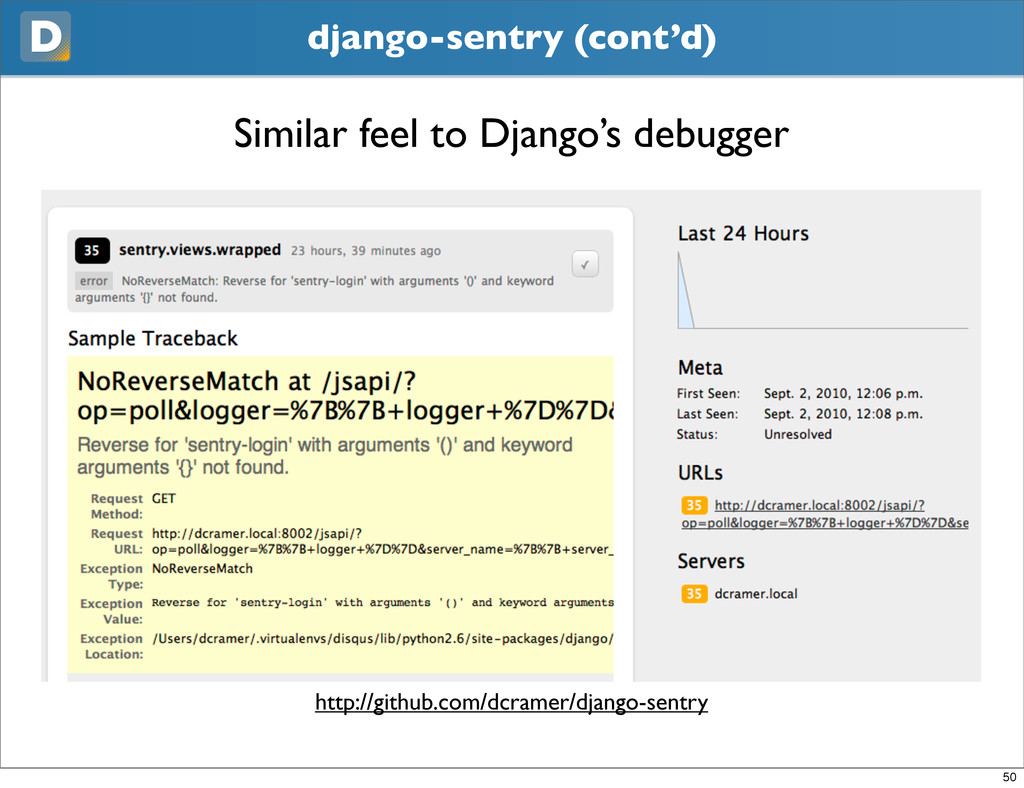
wanted Subtasks • Emailing exceptions is a bad idea • Even if its localhost • Previously using django-db-log to aggregate errors to a single point • We’ve overhauled db log and are releasing Sentry 48
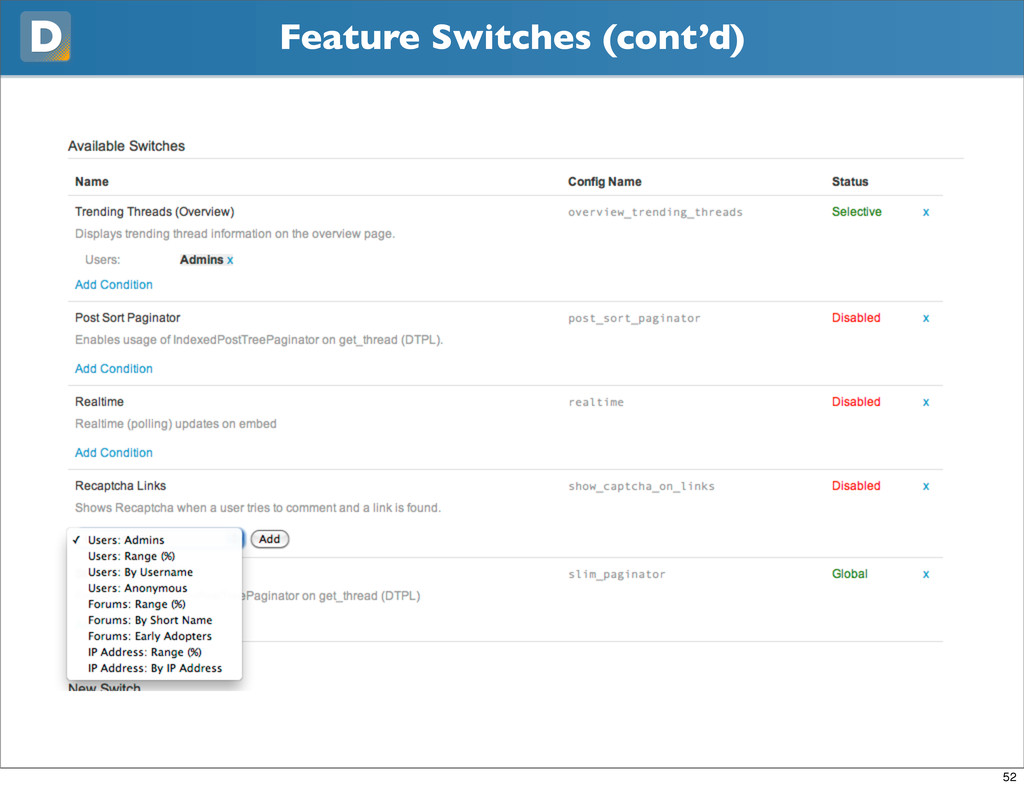
feature wasn’t performing well at peak • it had to respond without delay, globally, and without writing to disk • Allows us to work out of trunk (mostly) • Easy to release new features to a portion of your audience • Also nice for “Labs” type projects 51
We like Django • But we maintain local patches • Some tickets don’t have enough of a following • Patches, like #17, completely change Django.. • ..arguably in a good way • Others don’t have champions Ticket #17 describes making the ORM an identify mapper 53
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pythonic Joins posts = Post.objects.all()[0:25] # store users in a](https://files.speakerdeck.com/presentations/4e80d5fe5cc0ec0063000376/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}