セッションの投影資料です。
<開催日>
開催日:2023/06/28(水) 14:00-15:00@WebEX
<セッション概要>
シリーズ「IBMのObservability/APM製品(Instana)を使い倒す #1」の第一回目の開催となります。
今回は、初回セッションということで、Observability・APMの概念、なぜそれらが必要なのか、どのように活用するのか等をお伝えします。
また、IBMのObservability・APM製品である「Instana」のデモを交えながら、実用的な活用方法も学んで頂きます。
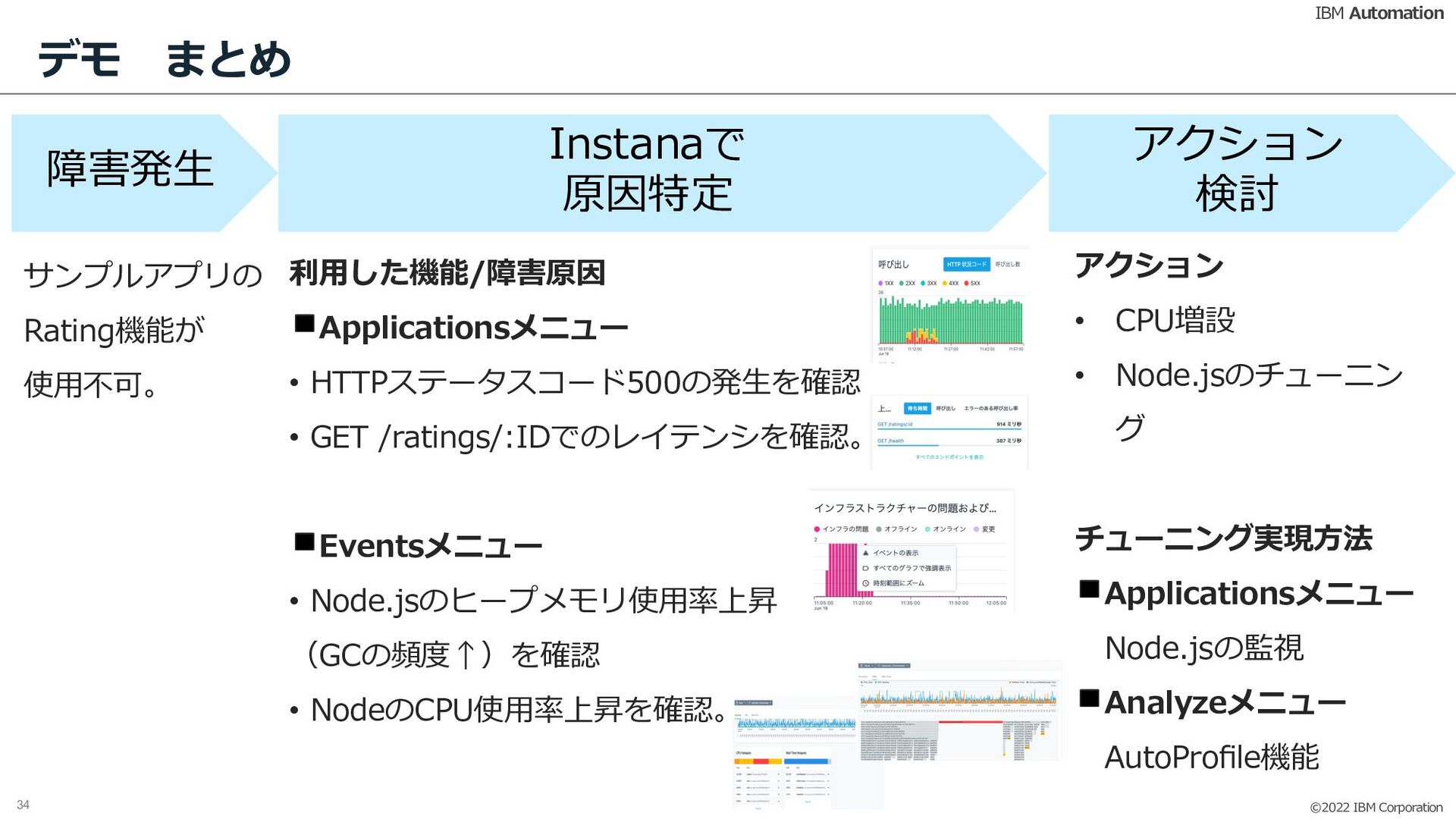
Instanaユーザ会(ユーザコミュニティ)も発足し、ますます盛り上がりを見せるInstana。
みんなで楽しく、Instanaを学んでいきましょう!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![©2022 IBM Corporation IBM Automation Instanaをどのように活⽤するか︖ [平常時] 処理数、エラー率、応答性能などを即座に把握。 業務ごとの処理量を 容易に把握。](https://files.speakerdeck.com/presentations/198b28f8d2df4b449b06561ad6da4aaf/slide_20.jpg){kind=link}
![©2022 IBM Corporation IBM Automation Instanaをどのように活⽤するか︖ [障害時] 処理量や応答性能の急激な変化 を検知・通知。 解析画⾯から応答性能で要求をソート。](https://files.speakerdeck.com/presentations/198b28f8d2df4b449b06561ad6da4aaf/slide_21.jpg){kind=link}
{kind=link}
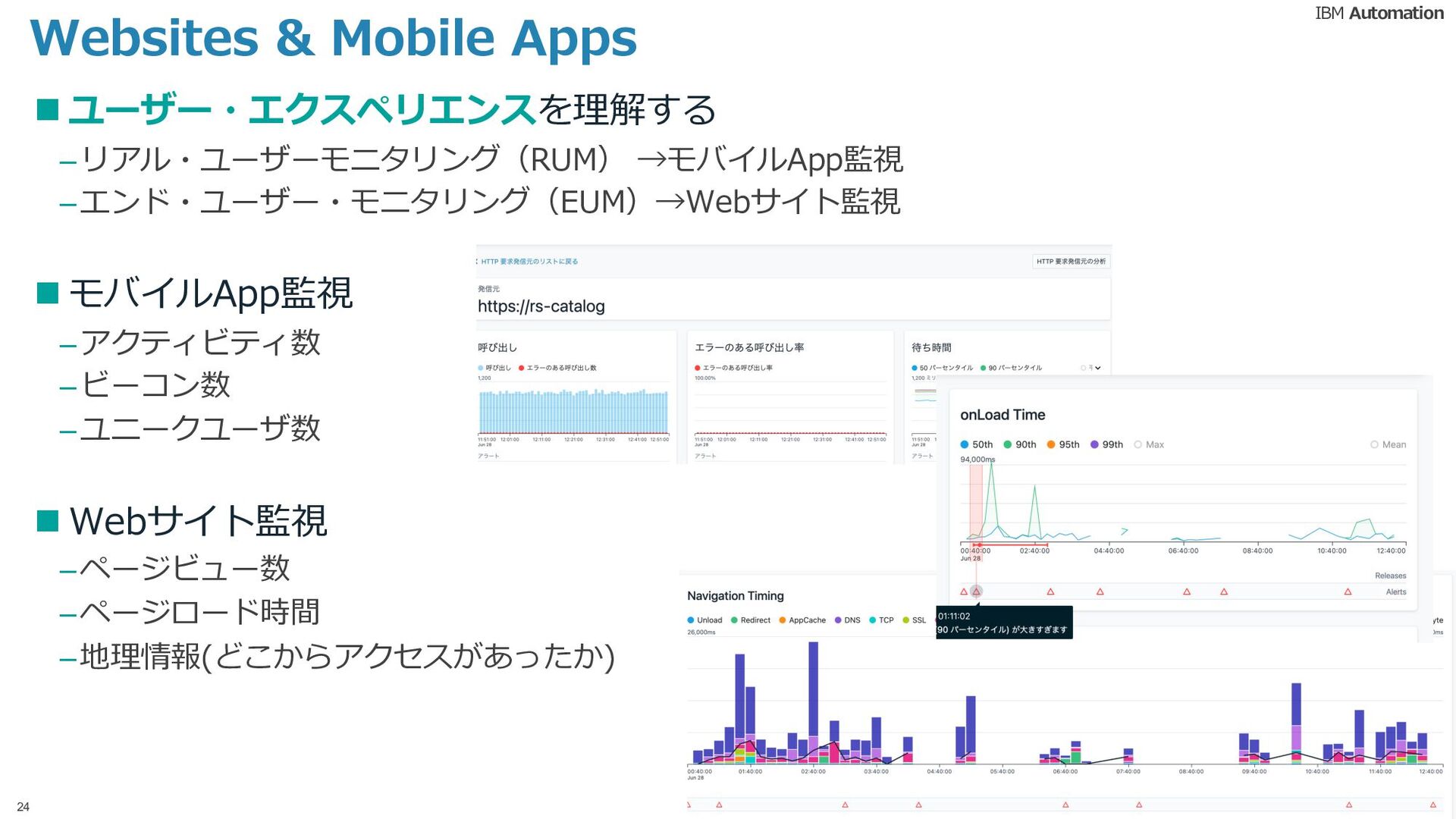{kind=link}
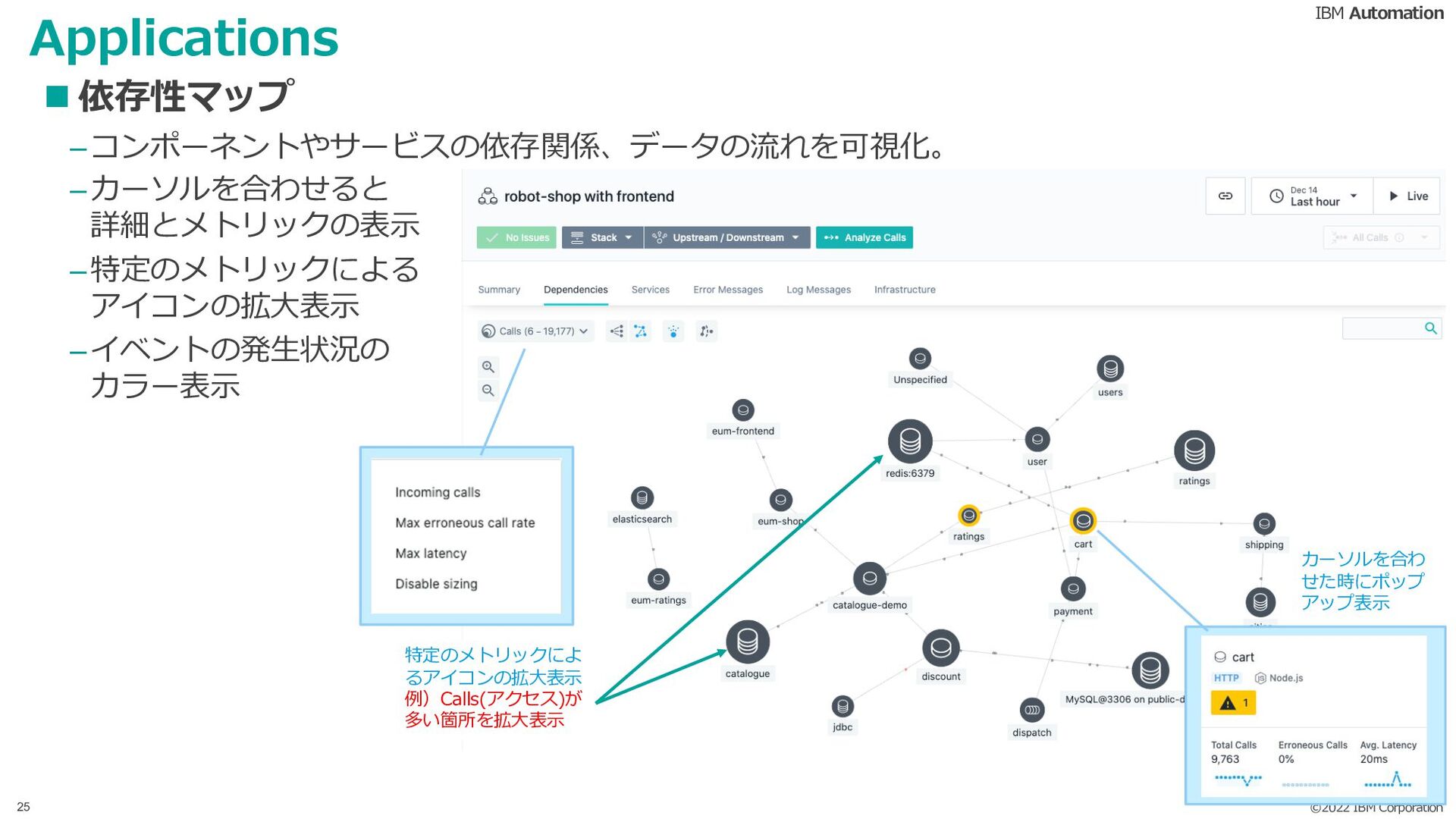{kind=link}
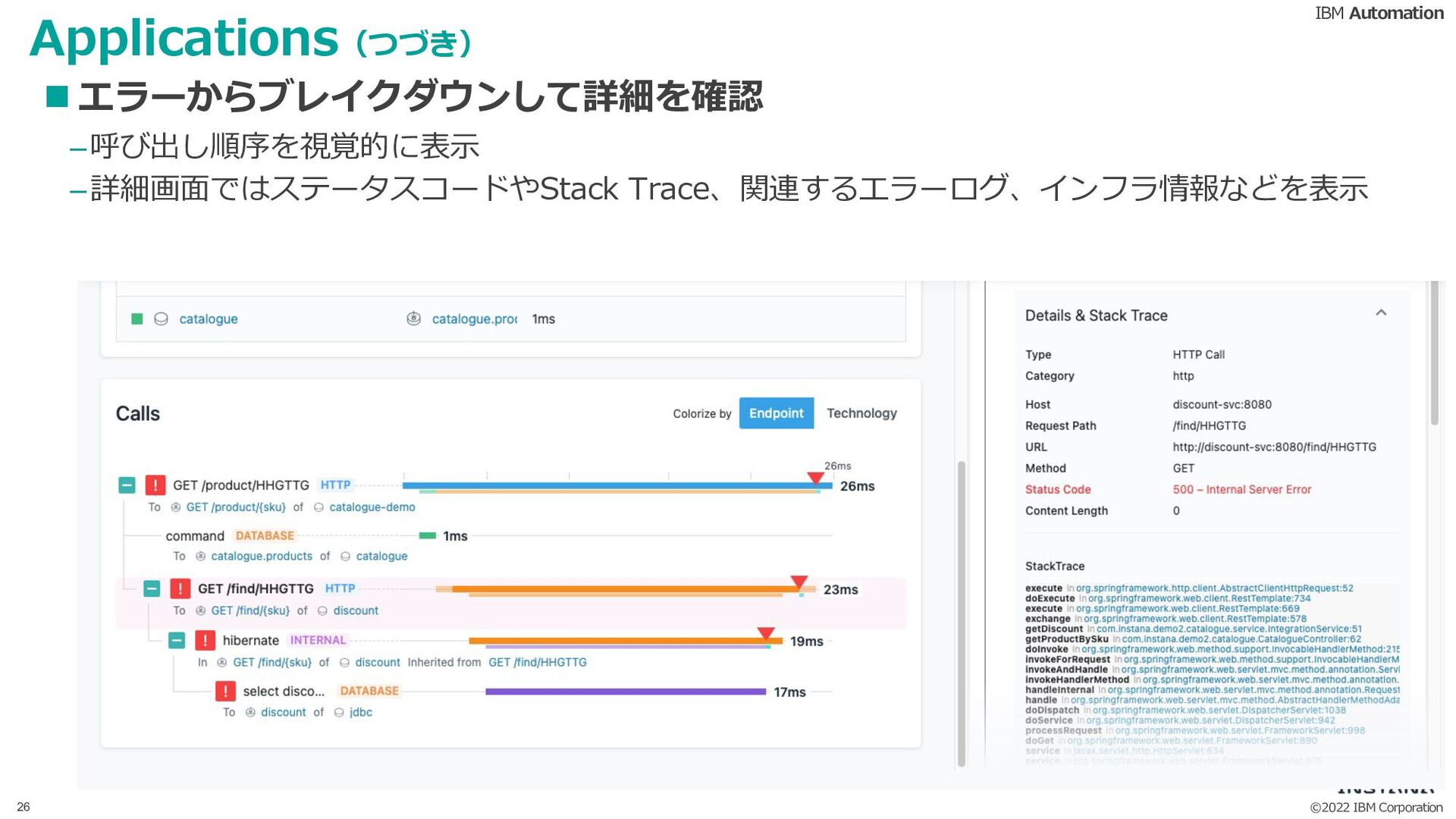{kind=link}
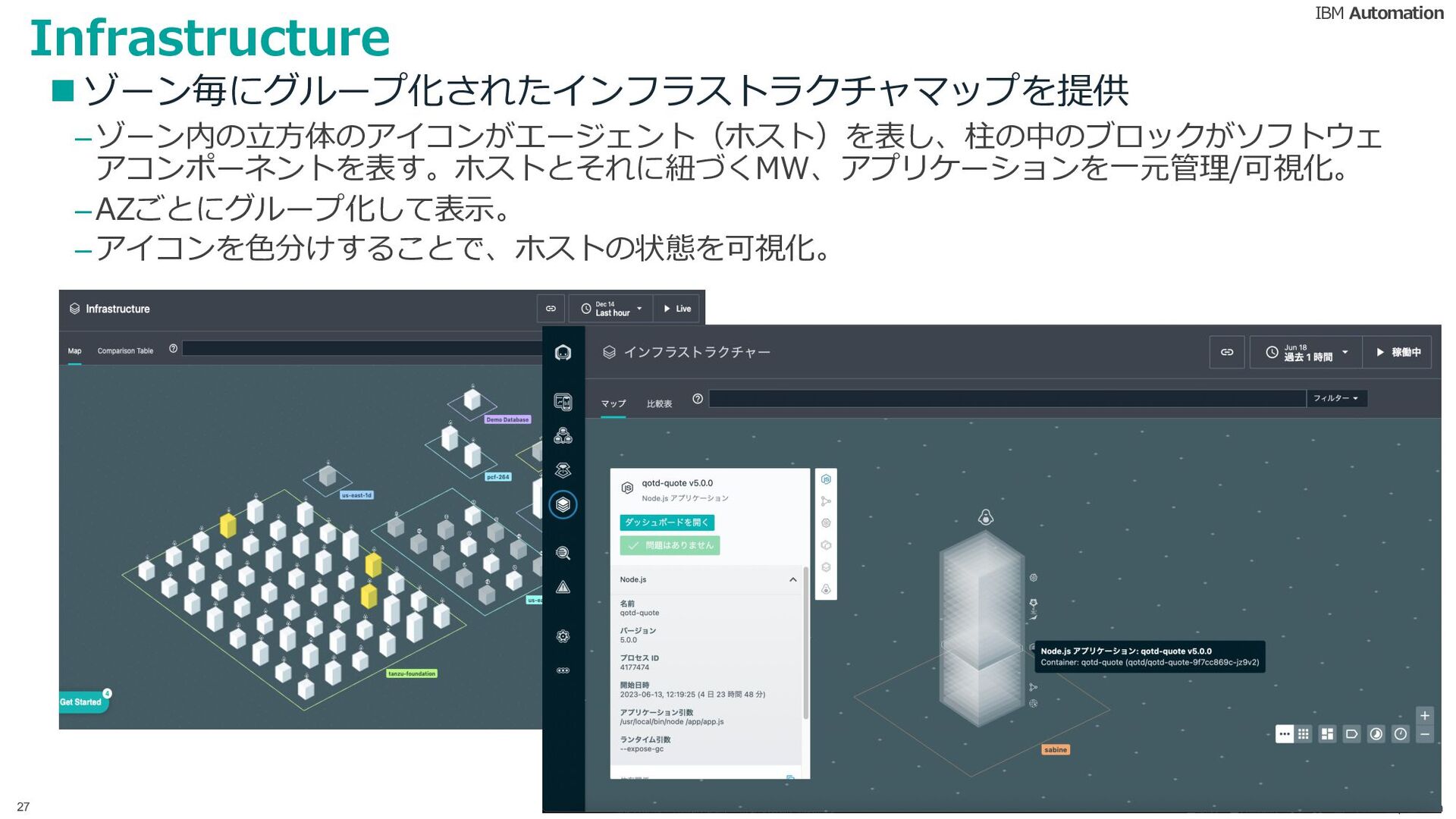{kind=link}
{kind=link}
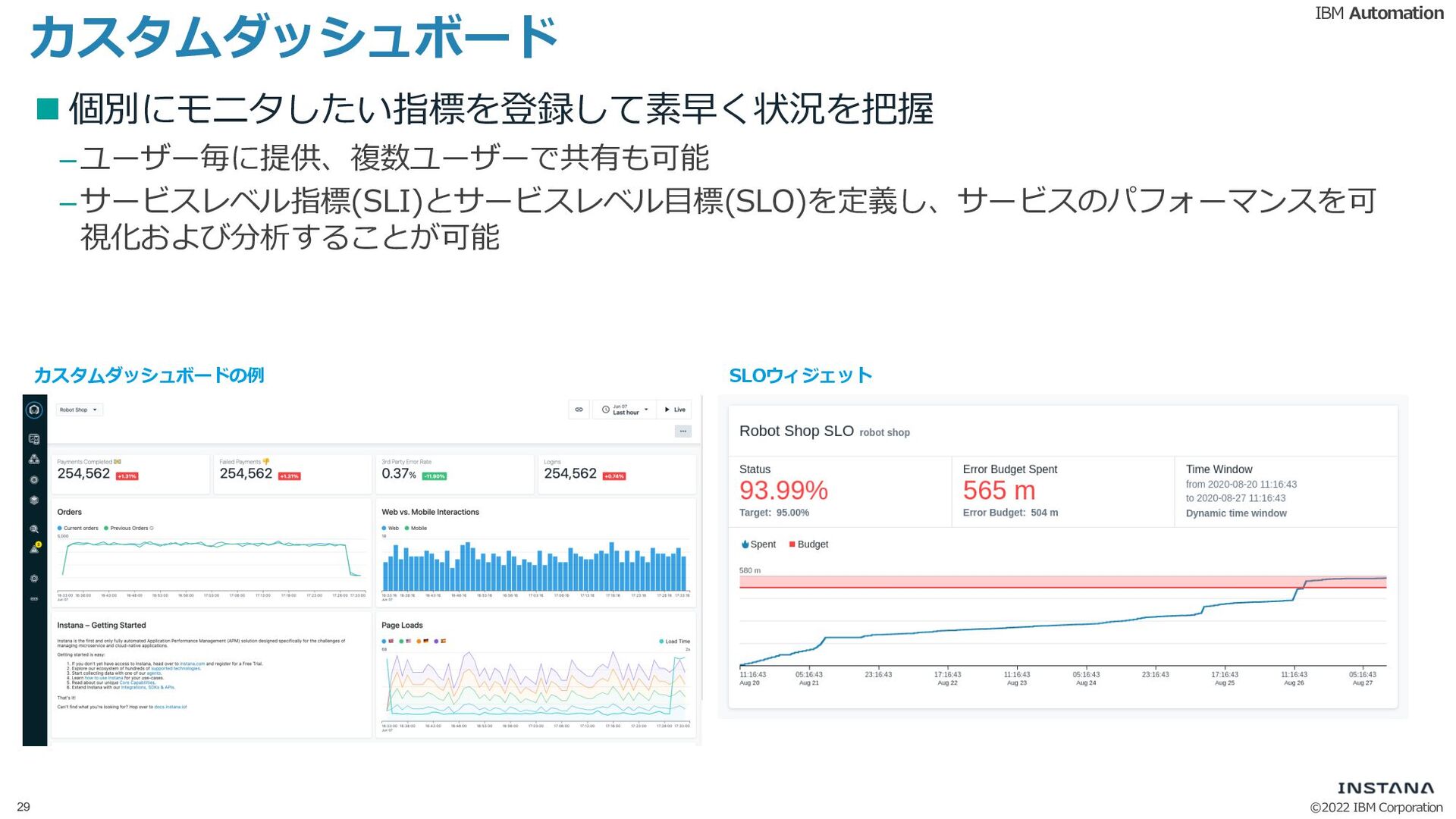{kind=link}
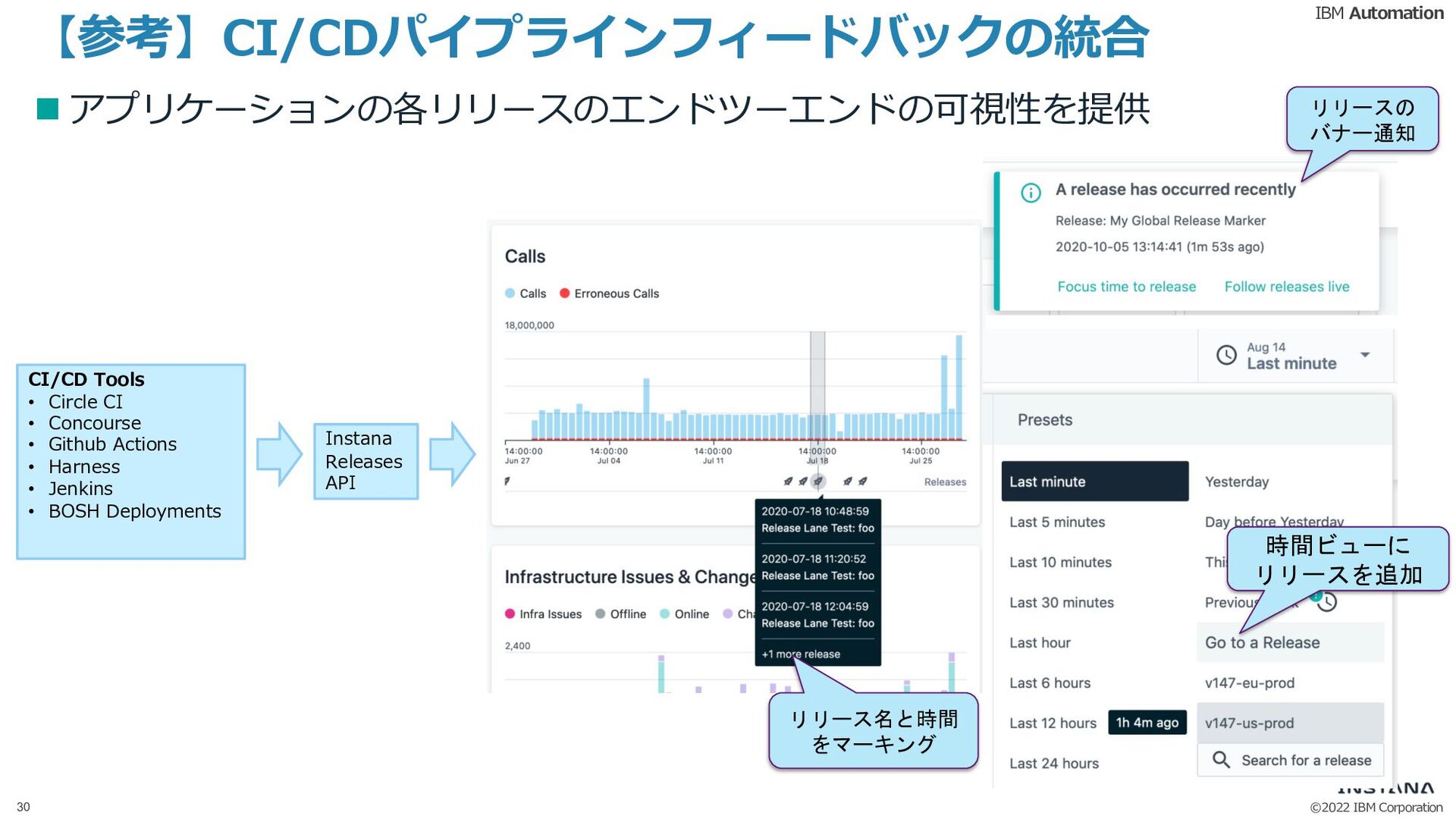{kind=link}
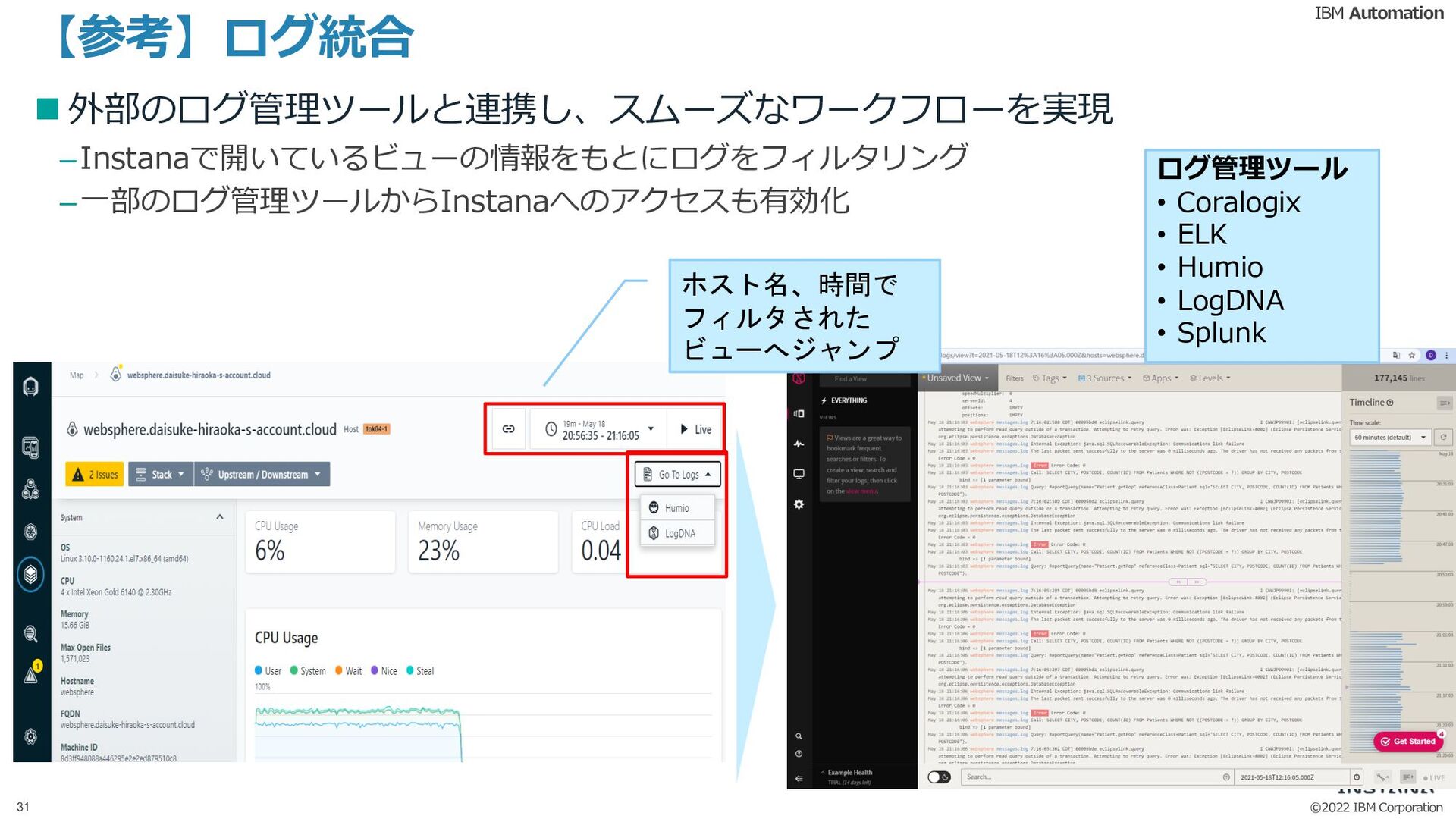{kind=link}
{kind=link}
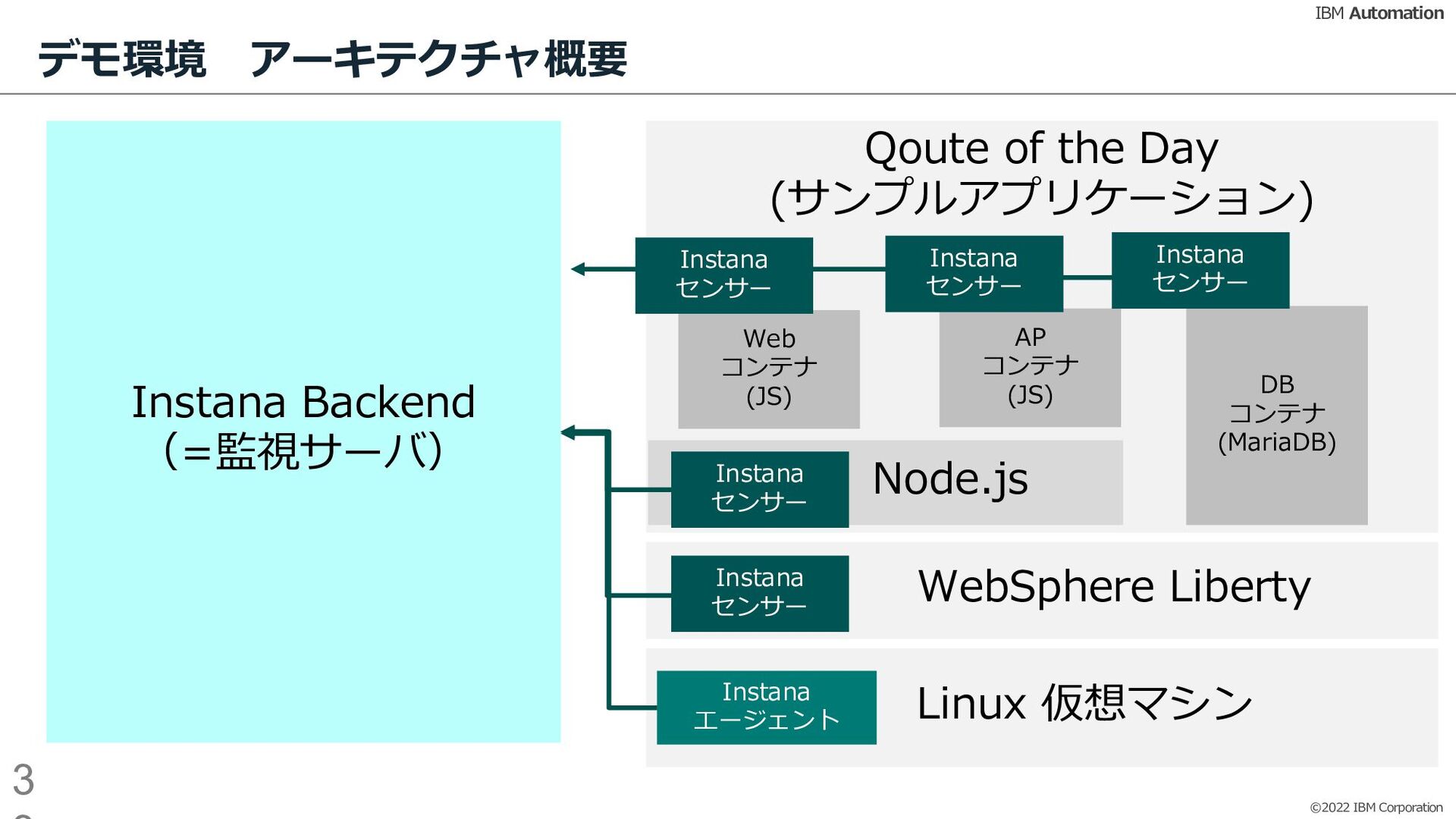{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}