Use NLTK to do a little bit of NLP with Python. Lots of code examples. Presented by Andrew Montalenti, CTO of Parse.ly. See http://parse.ly
Slides were created using reST and S5. You can read the slides in reST format (which is quite pleasant and lets you easily copy/paste code into IPython) here: https://raw.github.com/Parsely/python-nlp-slides/master/index.rst
You can also read the slides in your browser here:
http://bit.ly/nlp-slides
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
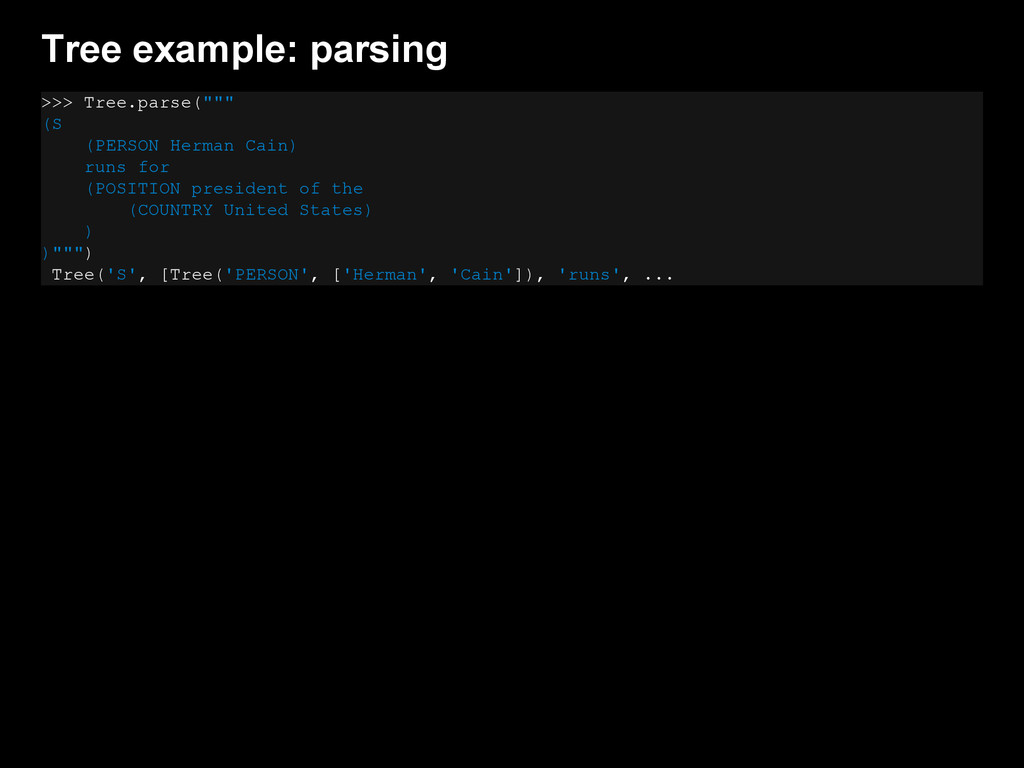{kind=link}
![Tree example: printing >>> print tree.pprint(margin=40, nodesep=" ->", parens=["", ""])](https://files.speakerdeck.com/presentations/508c3ae036b3f8000204427f/slide_23.jpg){kind=link}
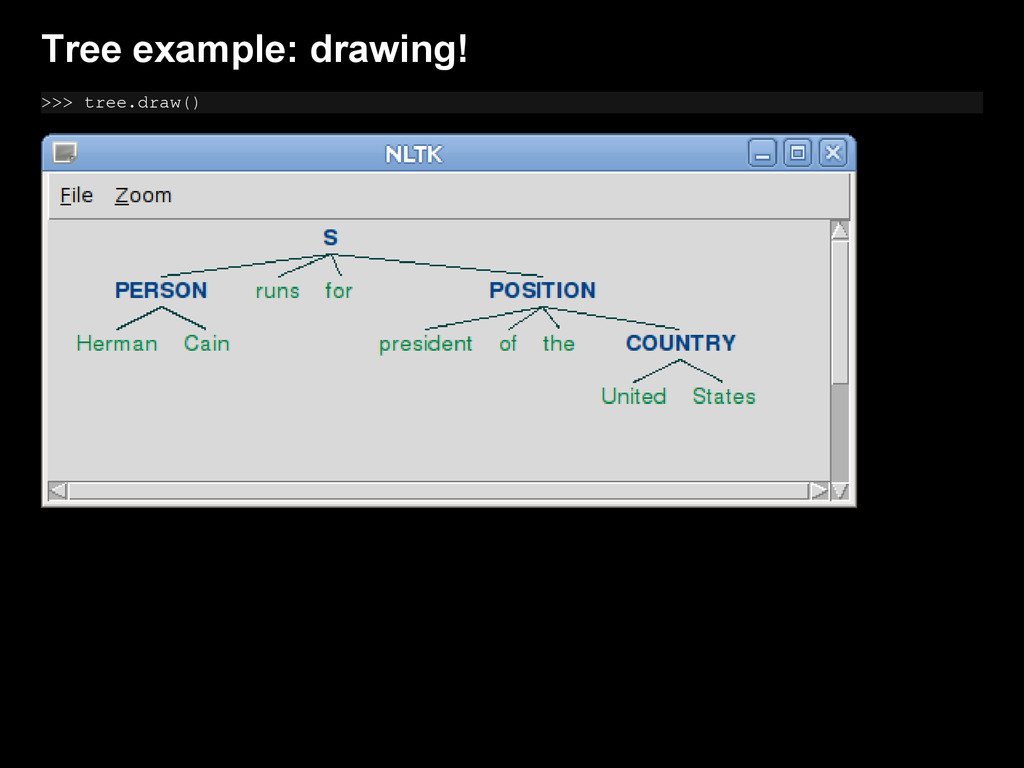{kind=link}
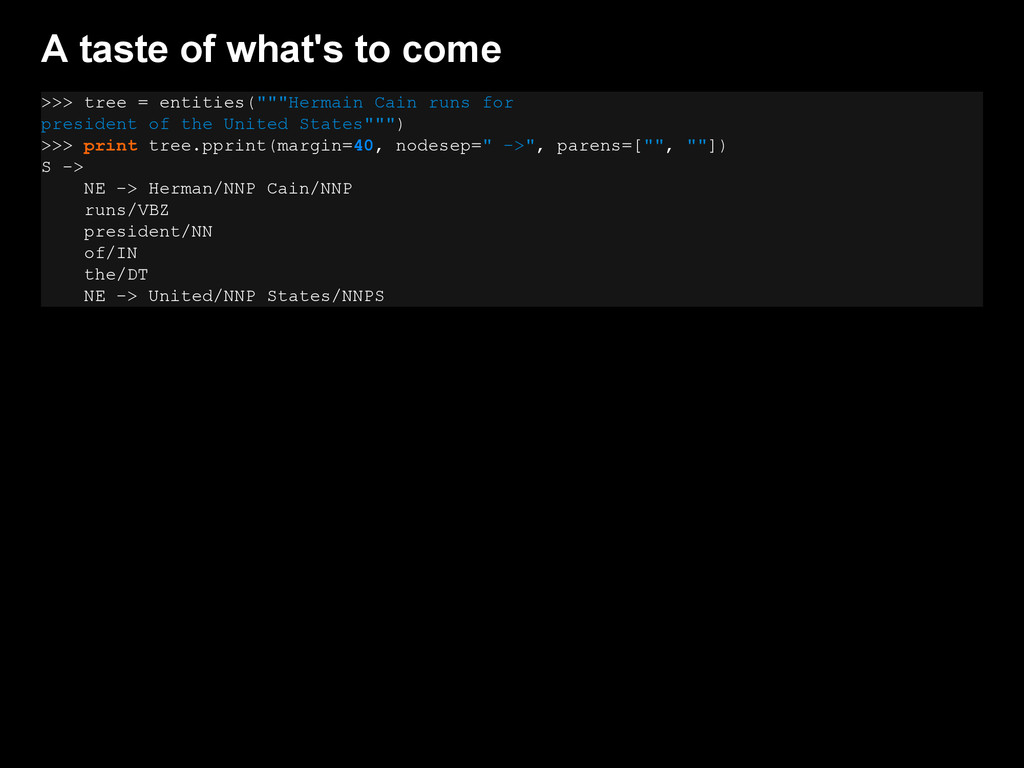{kind=link}
{kind=link}
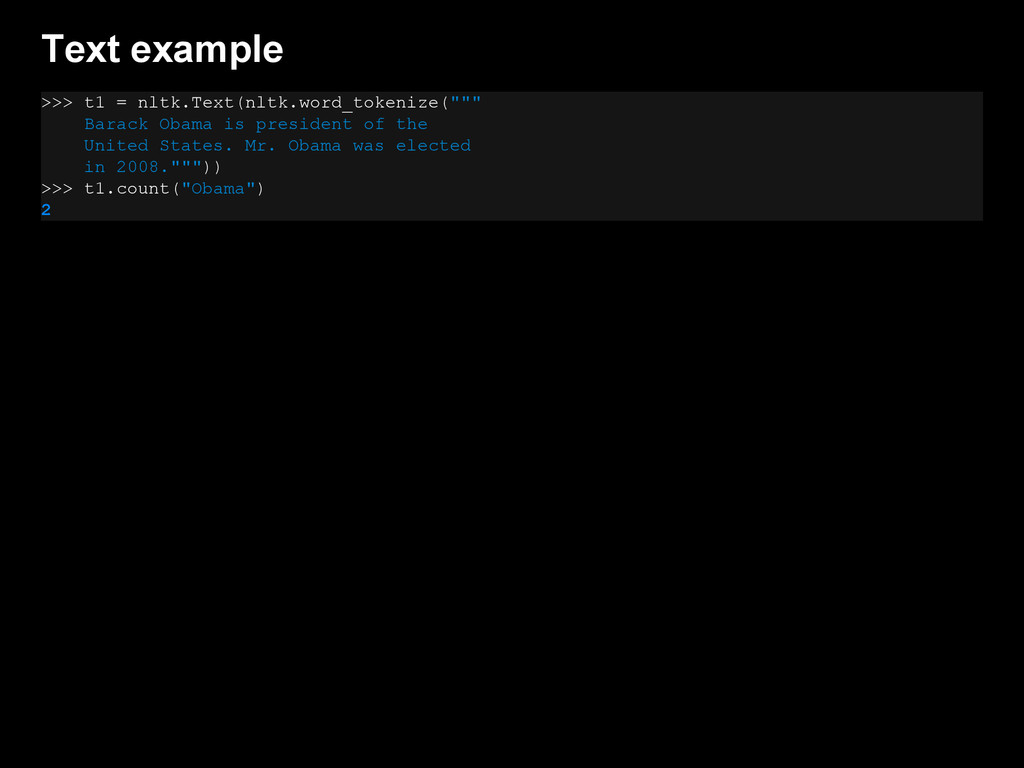{kind=link}
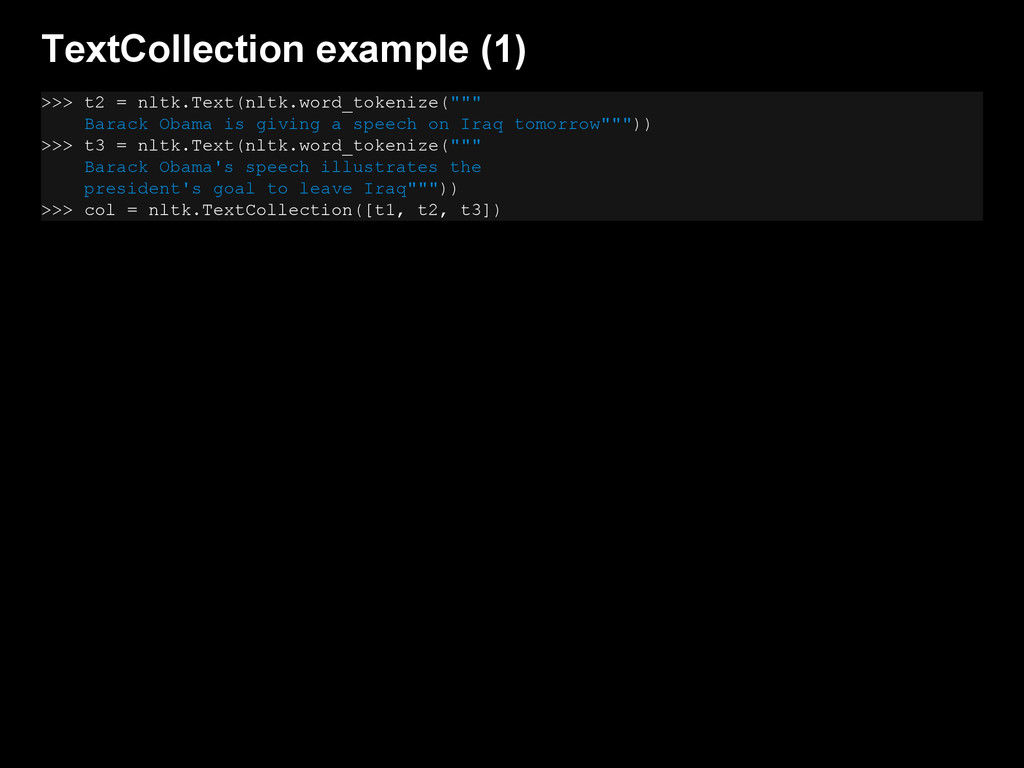{kind=link}
![TextCollection example (2) >>> col.vocab().items()[0:4] [('Obama', 4), ('Barack', 3), ("'s",](https://files.speakerdeck.com/presentations/508c3ae036b3f8000204427f/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
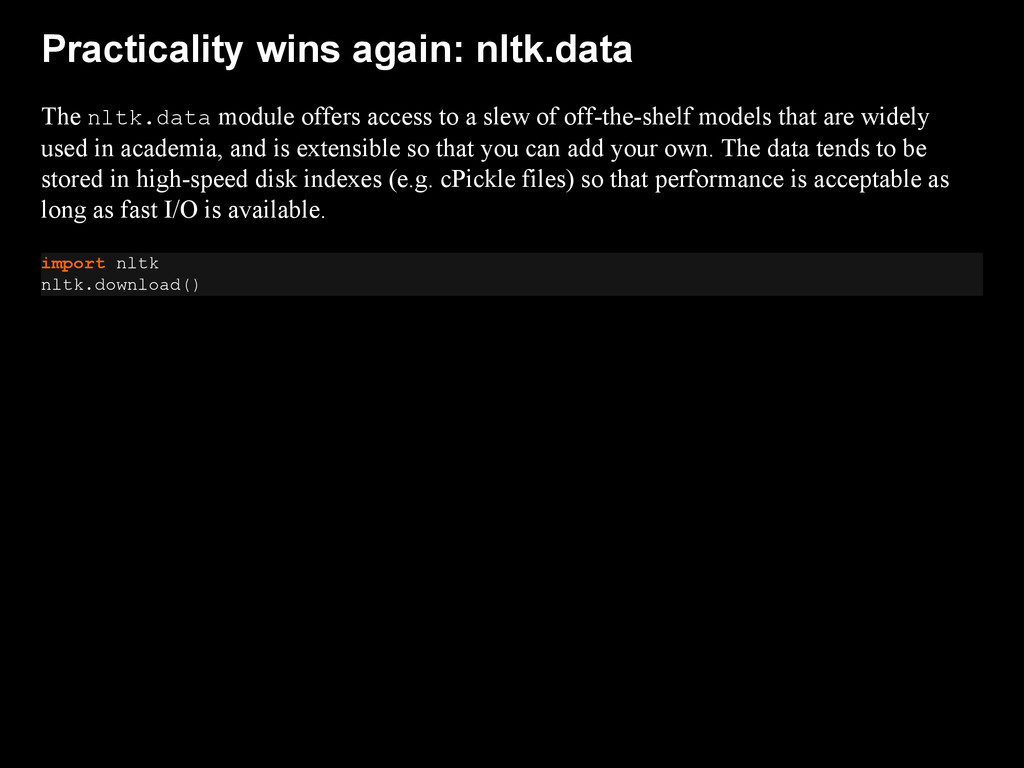{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
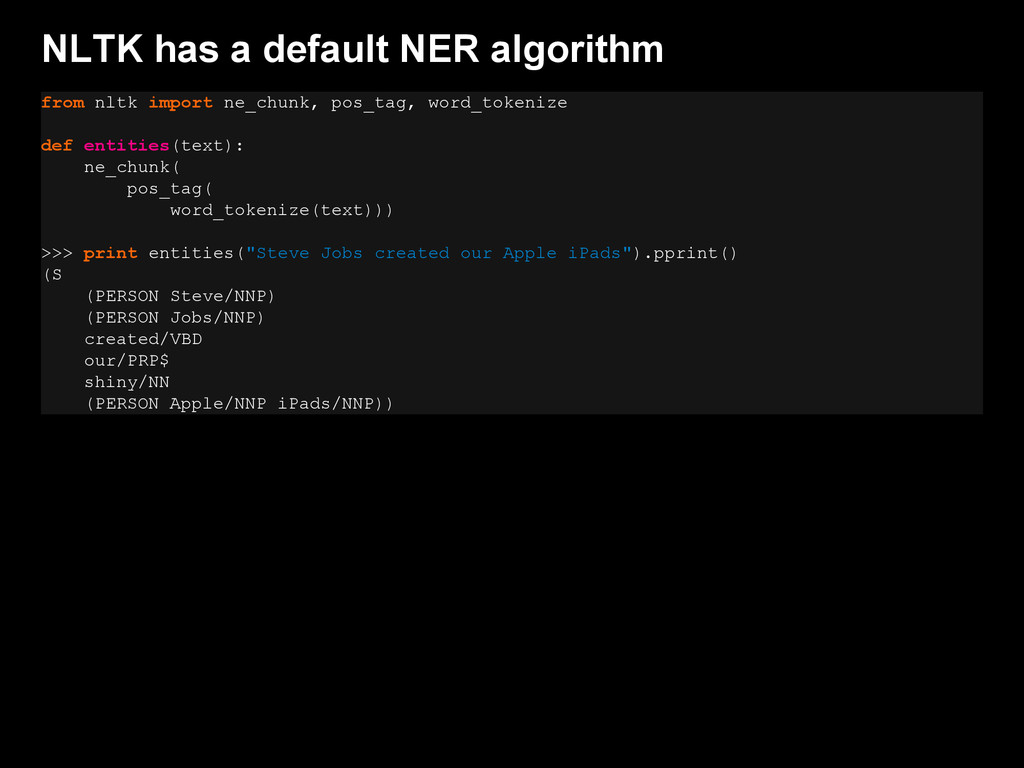{kind=link}
{kind=link}
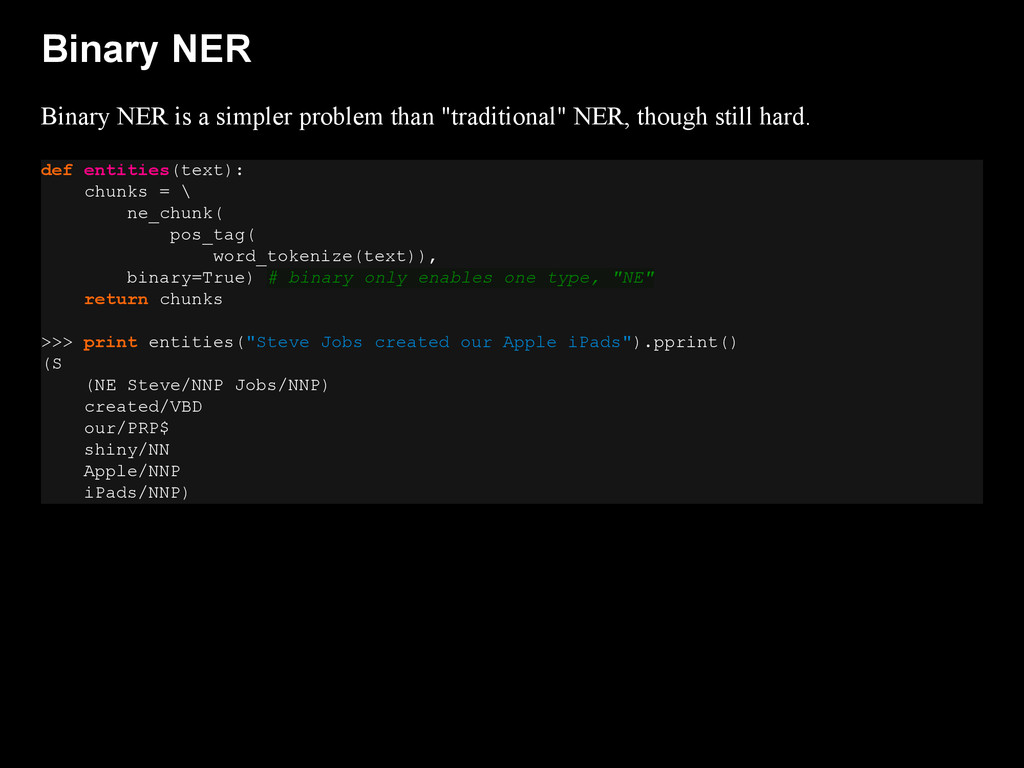{kind=link}
{kind=link}
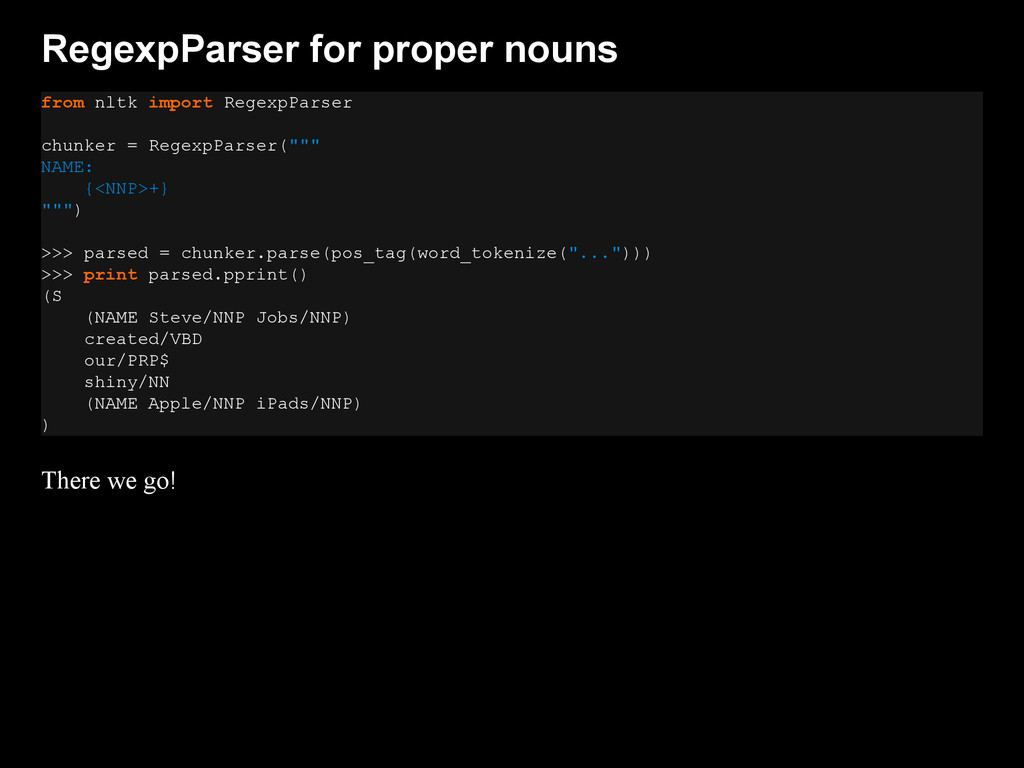{kind=link}
{kind=link}
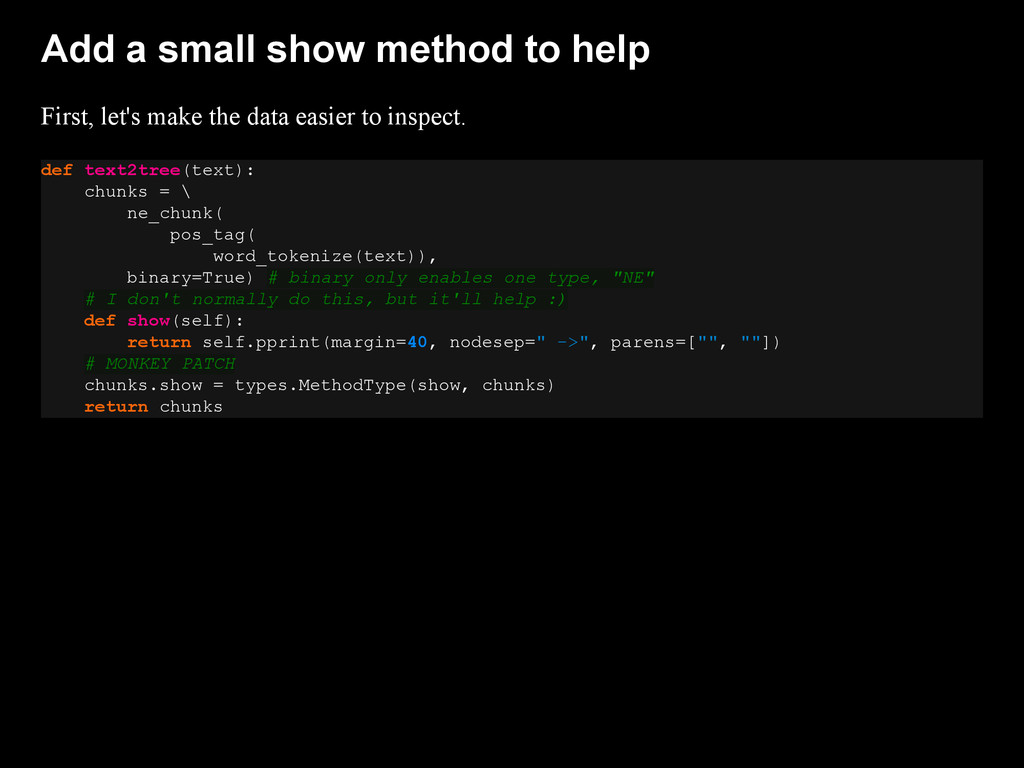{kind=link}
![Trees become entities def chunk2entity(chunk): return ' '.join(leaf[0] for leaf](https://files.speakerdeck.com/presentations/508c3ae036b3f8000204427f/slide_48.jpg){kind=link}
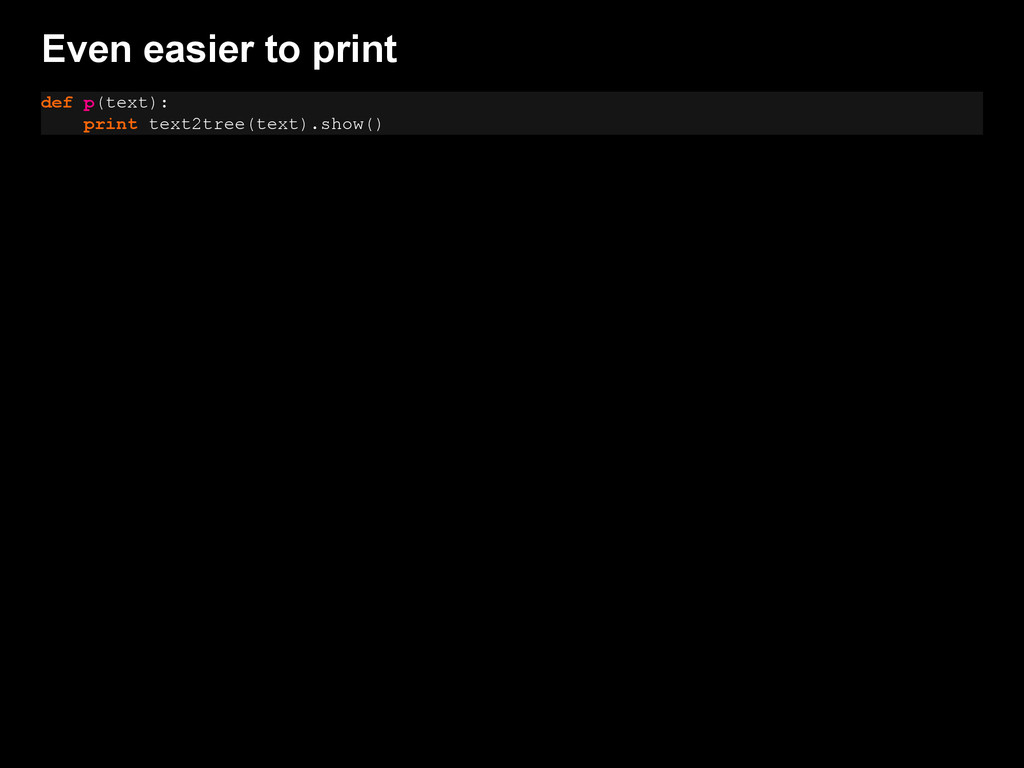{kind=link}
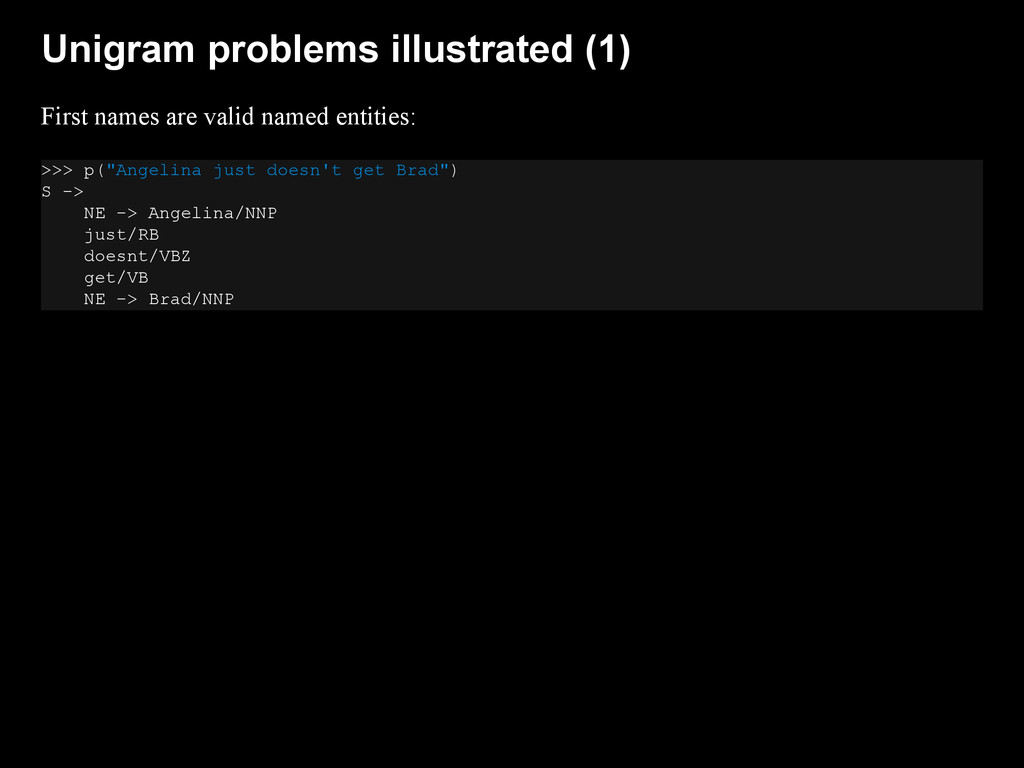{kind=link}
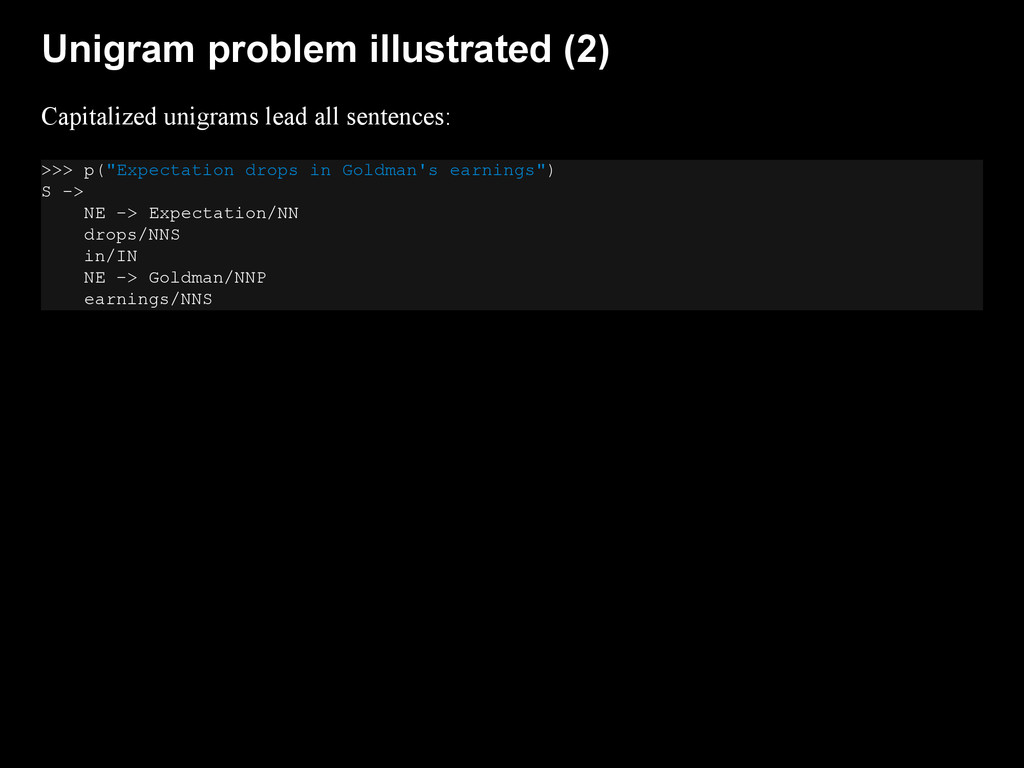{kind=link}
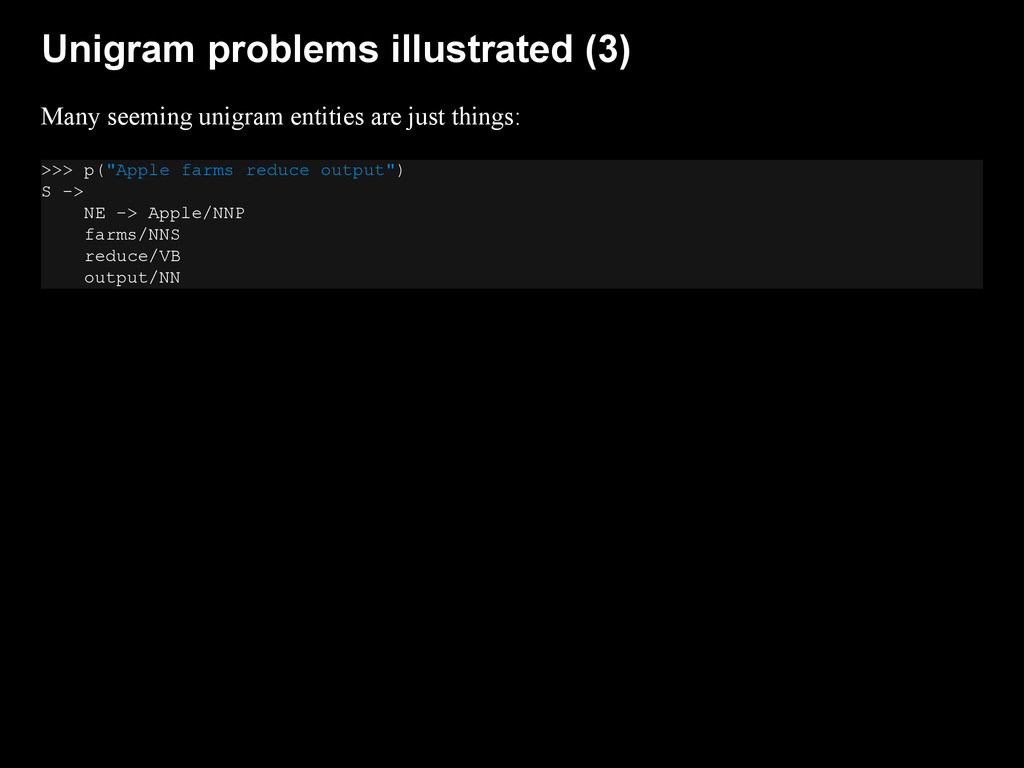{kind=link}
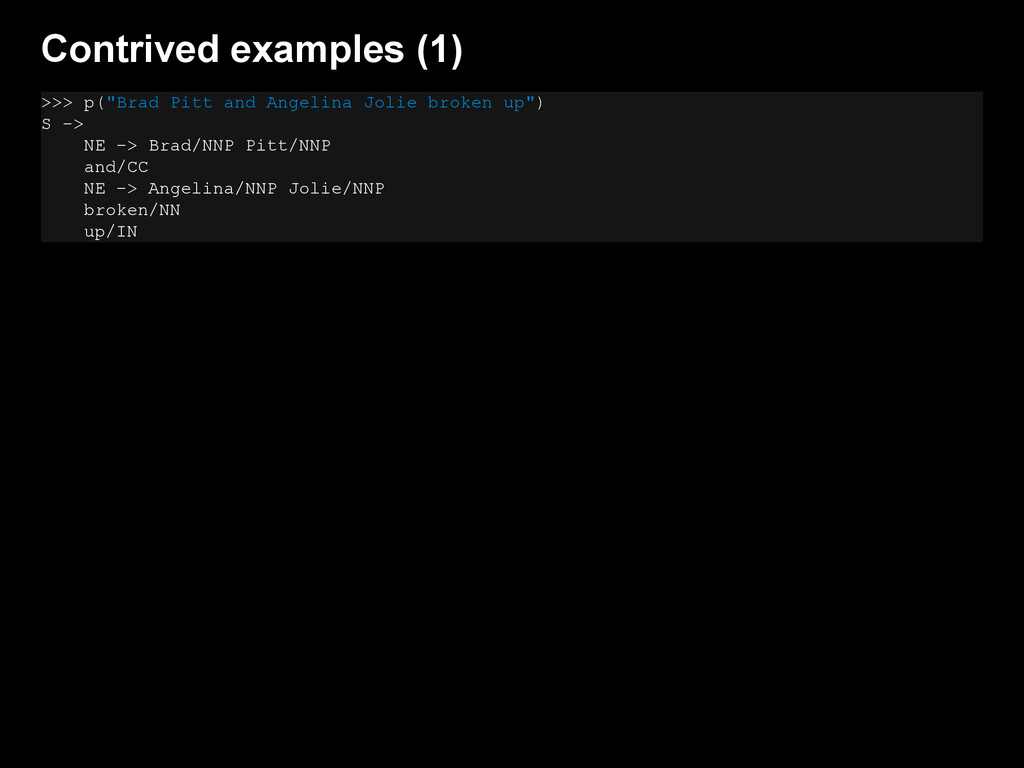{kind=link}
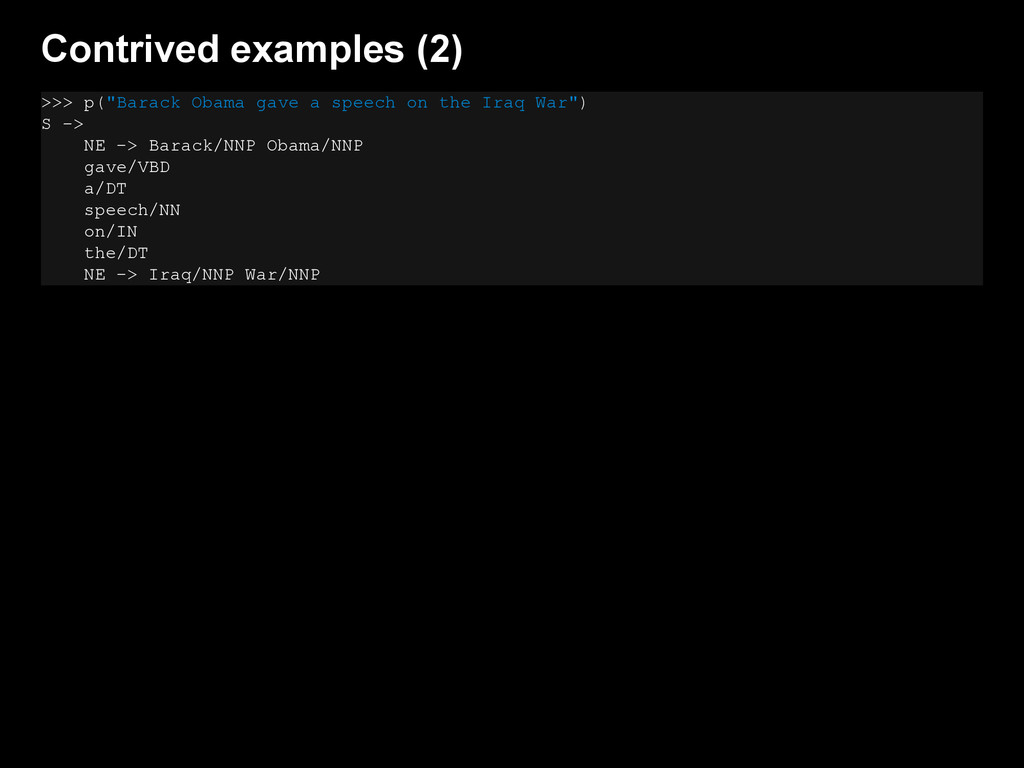{kind=link}
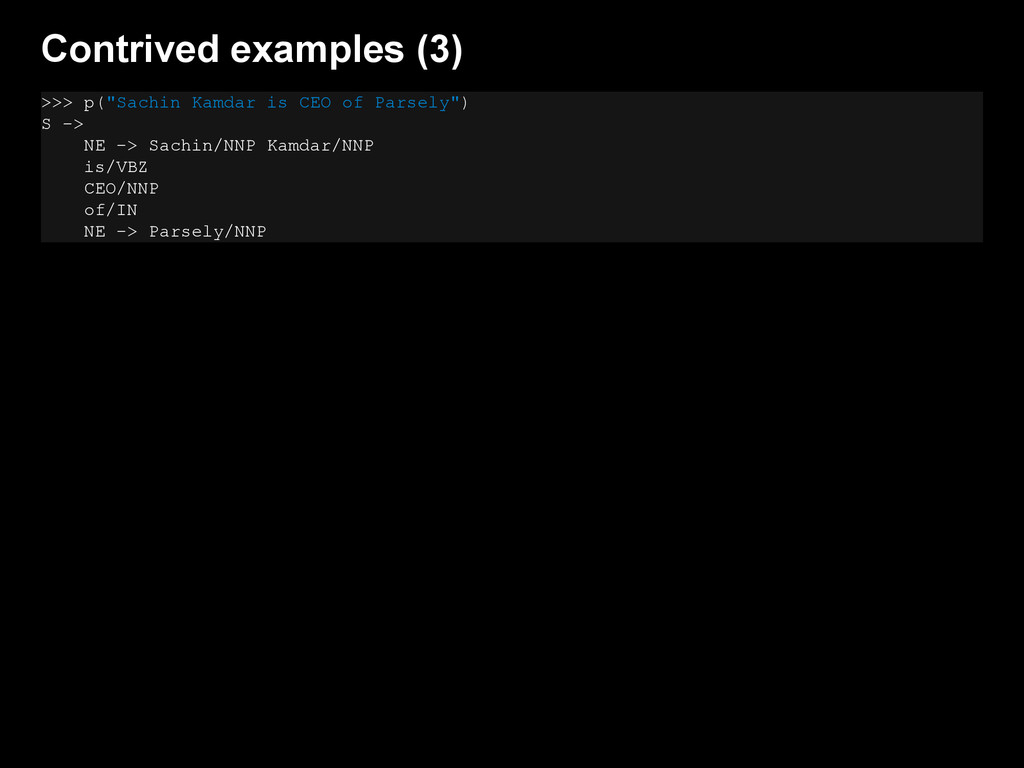{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
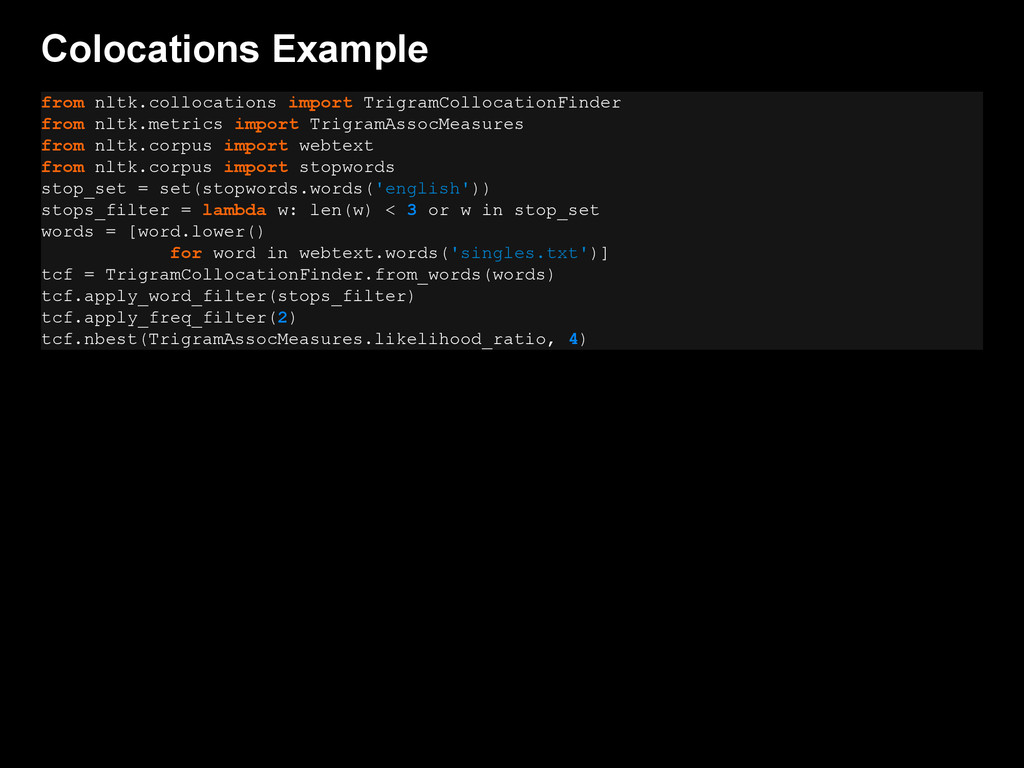{kind=link}
{kind=link}
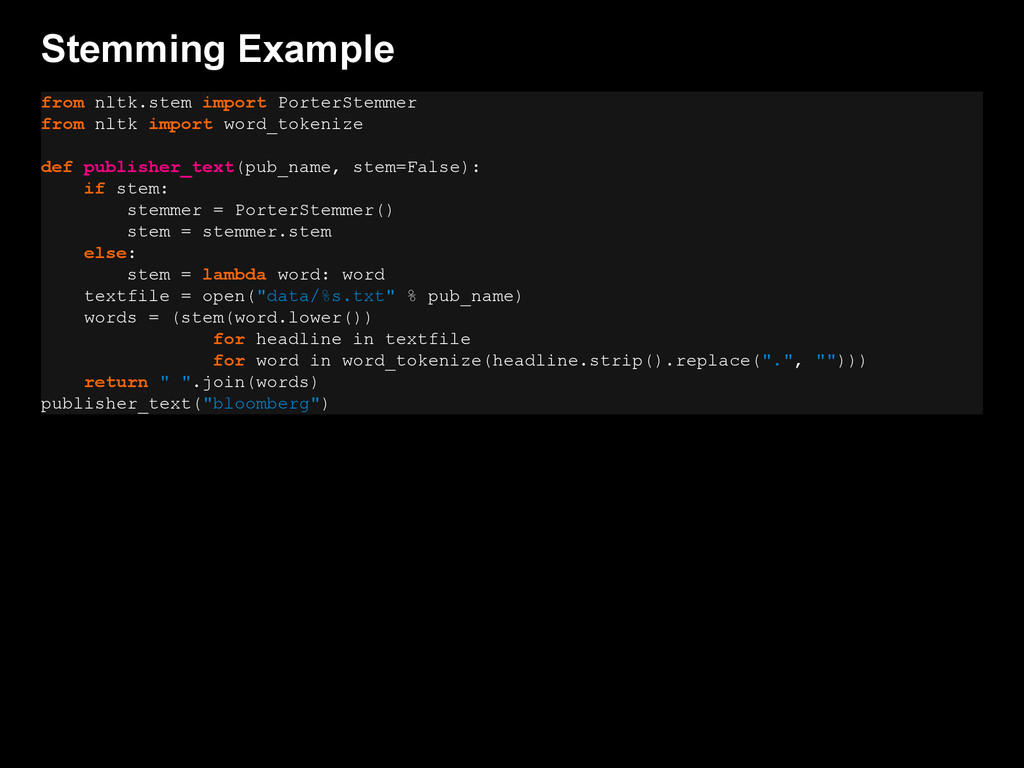{kind=link}
{kind=link}
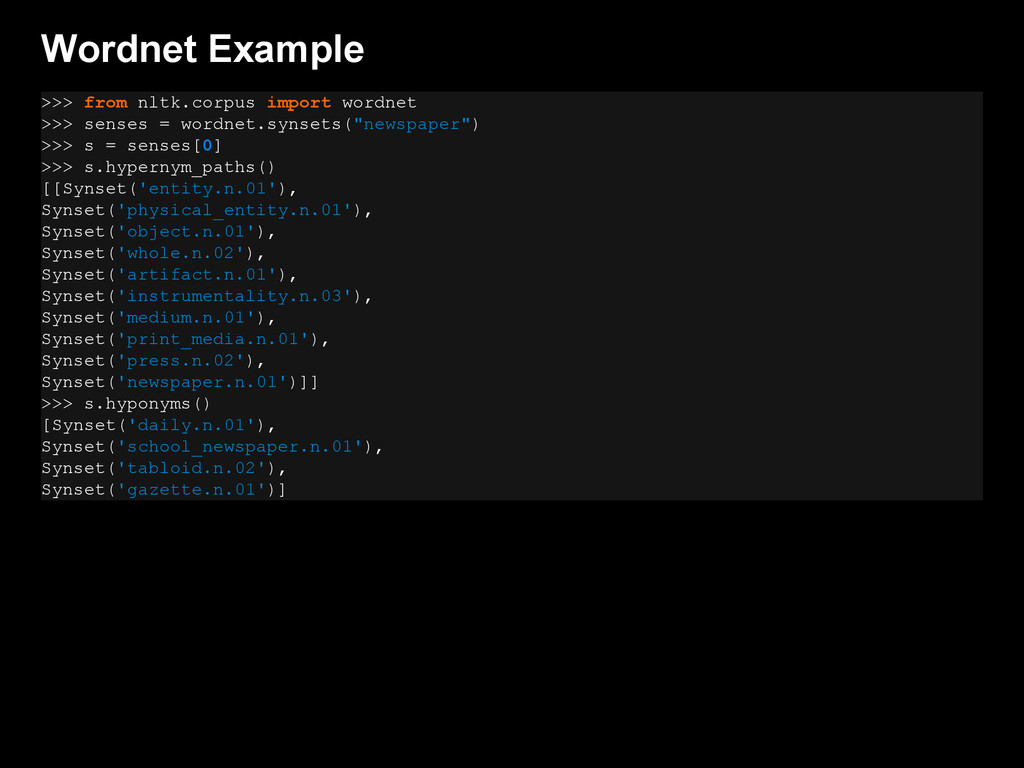{kind=link}
{kind=link}
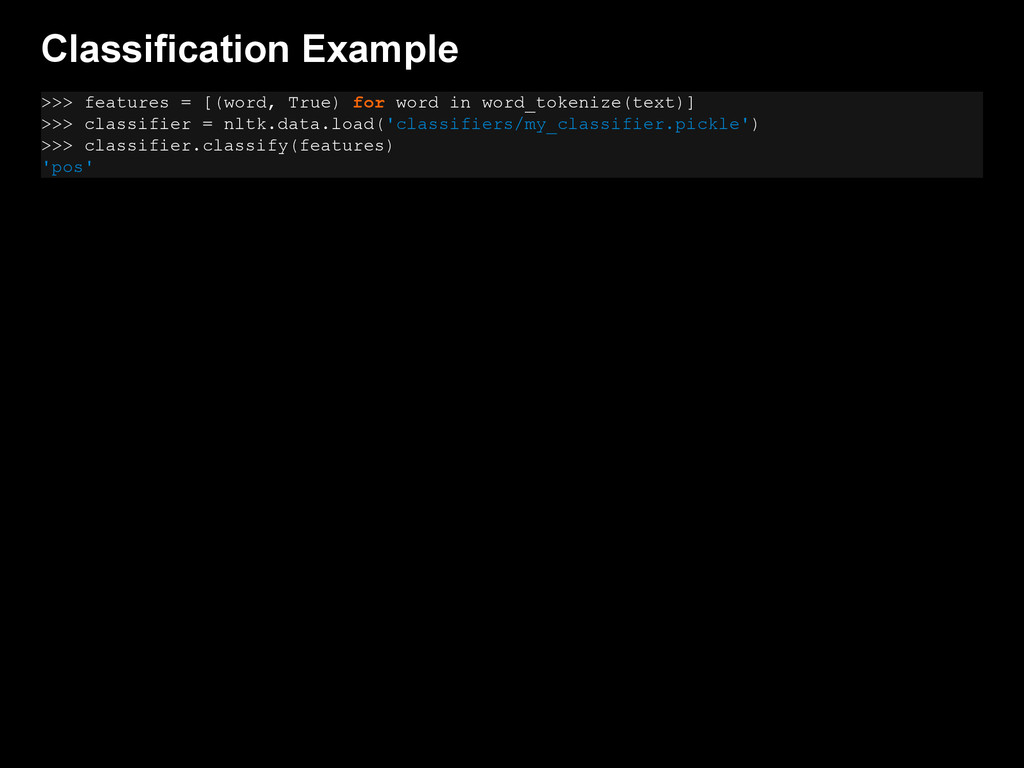{kind=link}
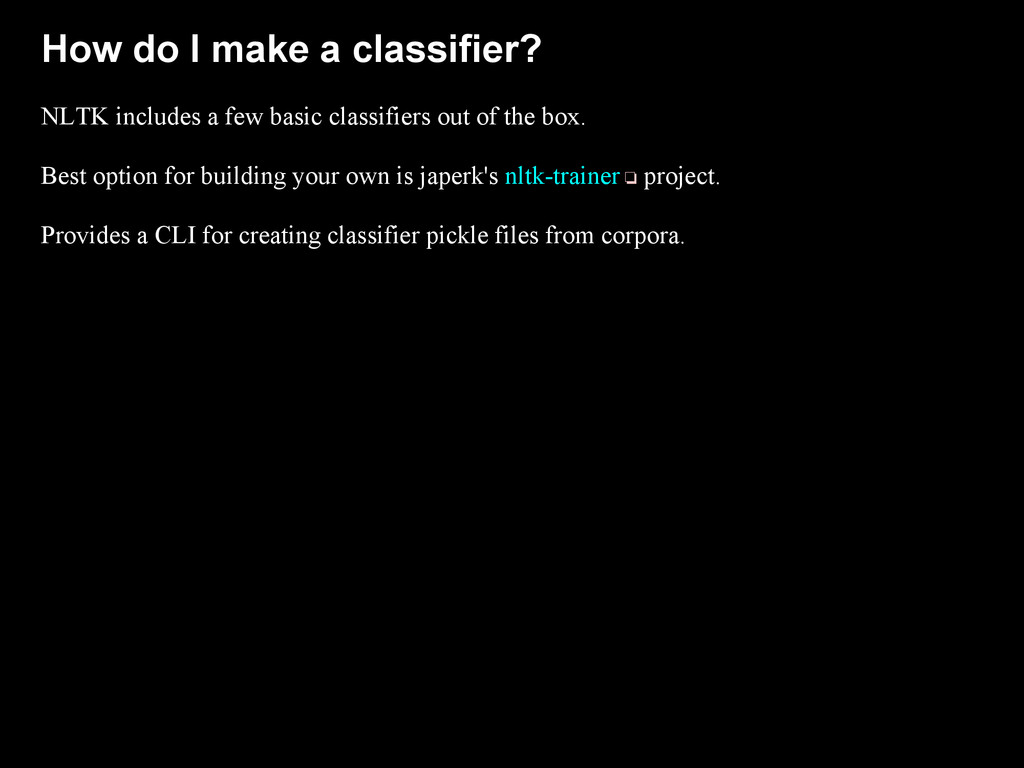{kind=link}
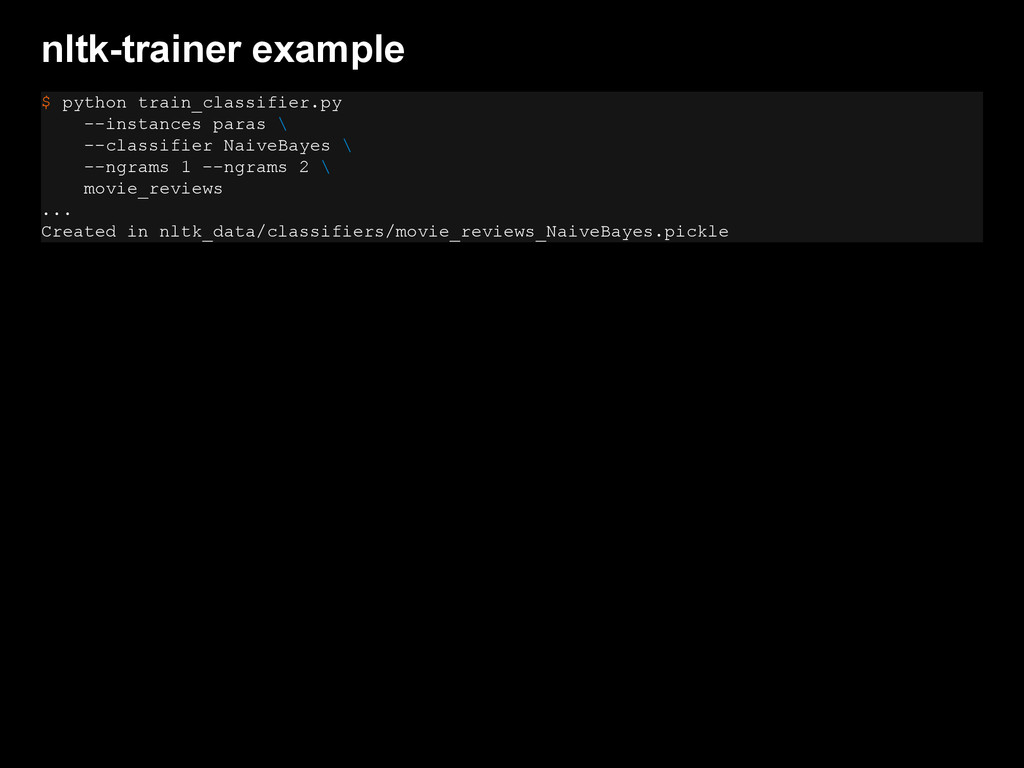{kind=link}
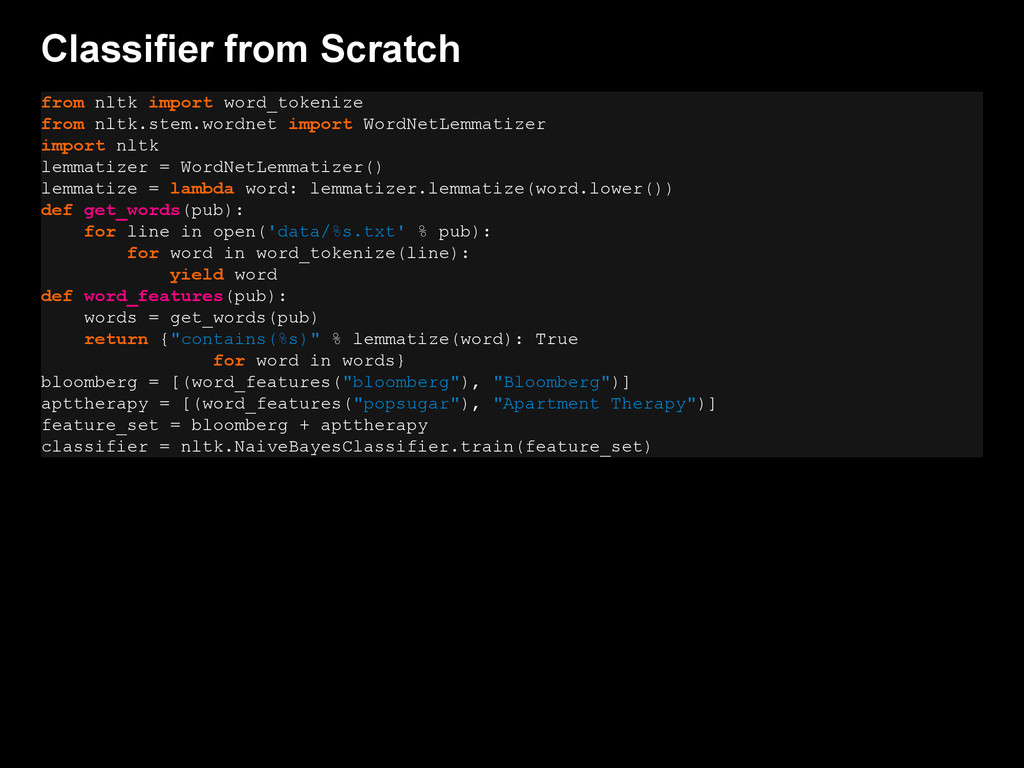{kind=link}
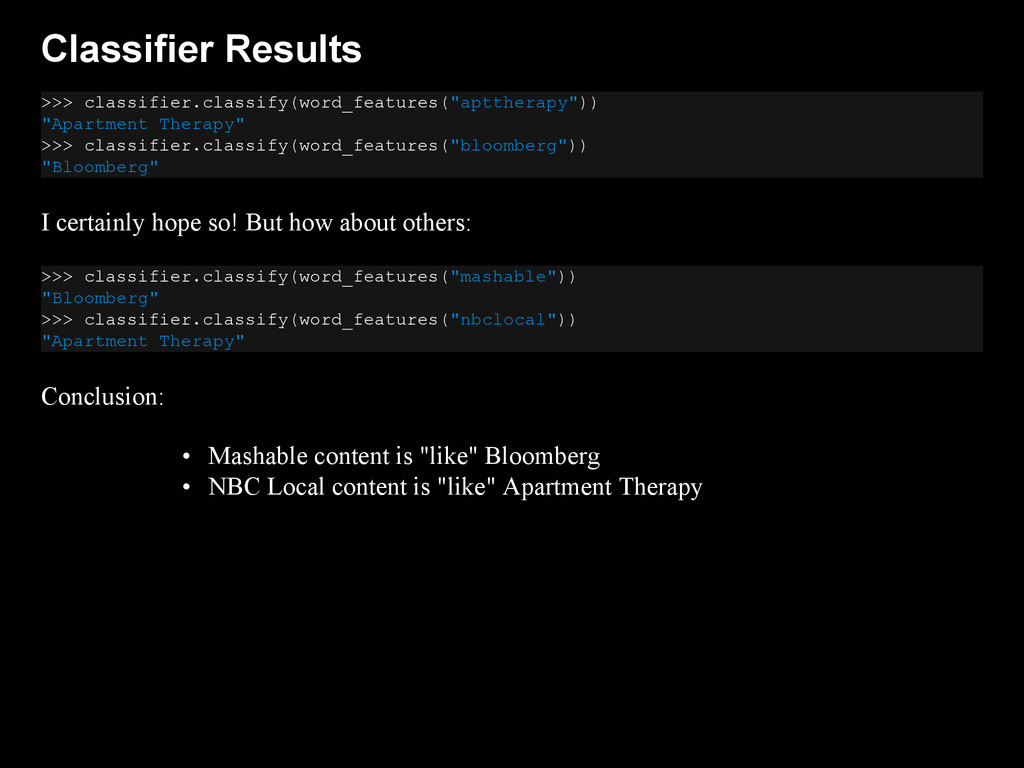{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}