homepages found via metadata • Full-text search: – Billions of resources – Dedicated faceted search service • Analytical access: – Combine faceted full-text search with: • Trend analysis • Visualisation tools – Working with modern historians to drive development
– Geo-index – Format profiles – Link graphs • Facilitate independent research • Can be made available under CC0 • Hosted at http://data.webarchive.org.uk/opendata/
search • Analytics & visualisation (at full scale) • Secondary datasets • Remote analysis of datasets (an API, e.g. SPARQL) • Full computational access service (internal only right now) • Not just the web archive?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
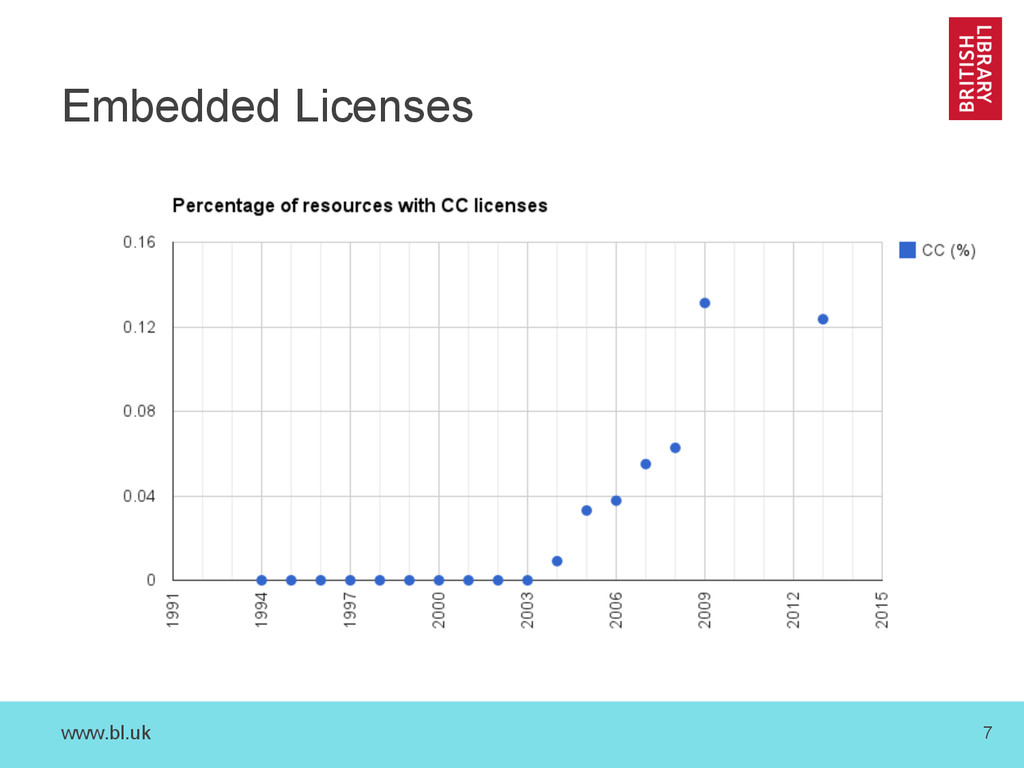{kind=link}
{kind=link}
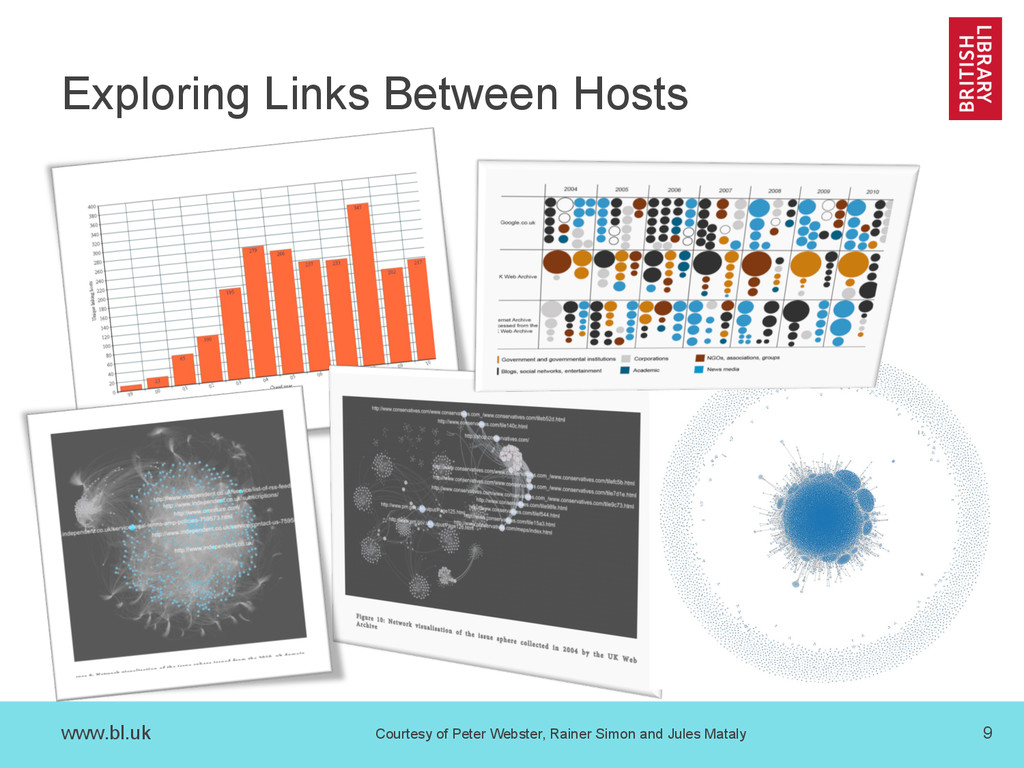{kind=link}
{kind=link}
![www.bl.uk 11 Top-Level Links Over Time [here]](https://files.speakerdeck.com/presentations/f5a23ee0750301329b0956ffc786e5d1/slide_10.jpg){kind=link}
{kind=link}
![www.bl.uk 13 Thank you! Email: [email protected] Twitter: @anjacks0n UK Web](https://files.speakerdeck.com/presentations/f5a23ee0750301329b0956ffc786e5d1/slide_12.jpg){kind=link}