– Legal Deposit since 2013 – Historical 1996-2013 from IA • Iterative Development: – Work directly with researchers – Today’s historical research tools provide tomorrow’s reading rooms • Using Solr to support: – Discovery – Preservation – Analytics
of poor quality content, e.g. from crawler traps. – Spam, e.g. link spam from link farms. – Utility of PageRank over time is unclear • Faceted search – Invest in developing facets to allow filtering rather than PageRank or boosts to rank results. – e.g. basic facets from embedded metadata: • Last-Modified, Author, etc.
hated it • Natural language detection – e.g. gov.uk + fr • Postcode-based geoindex • Sentiment analysis • Similarity hashing via ssdeep – To detect similar texts
Web?” • From Crawl To Web – Crawl schedule, parameters, logs. – "Files over 10MB are not archived” – De-duplication handling critical – Can't forget HTTP 30x, 40x, 50x • Compensate via normalisation strategies – c.f. Google Books Ngram
or Hadoop – Makes development much easier • Hadoop indexer has two modes: – SolrCloud: • Performance acceptable as long as shards map to cores and there's good I/O (1 billion, 1 server, 1 week) • Memory issues relating to query complexity – Direct to HDFS: • Really fast for moderate data volumes • Slows down as shards grow
– Begun developing an analytics UI • Keen to collaborate – This community faces a common problem: • But not a core SolrCloud/ElasticSearch use case – Danish SolrCloud on SSD discovered via Solr mailing list • http://sbdevel.wordpress.com/2013/12/06/danish- webscale/
{kind=link}
{kind=link}
{kind=link}
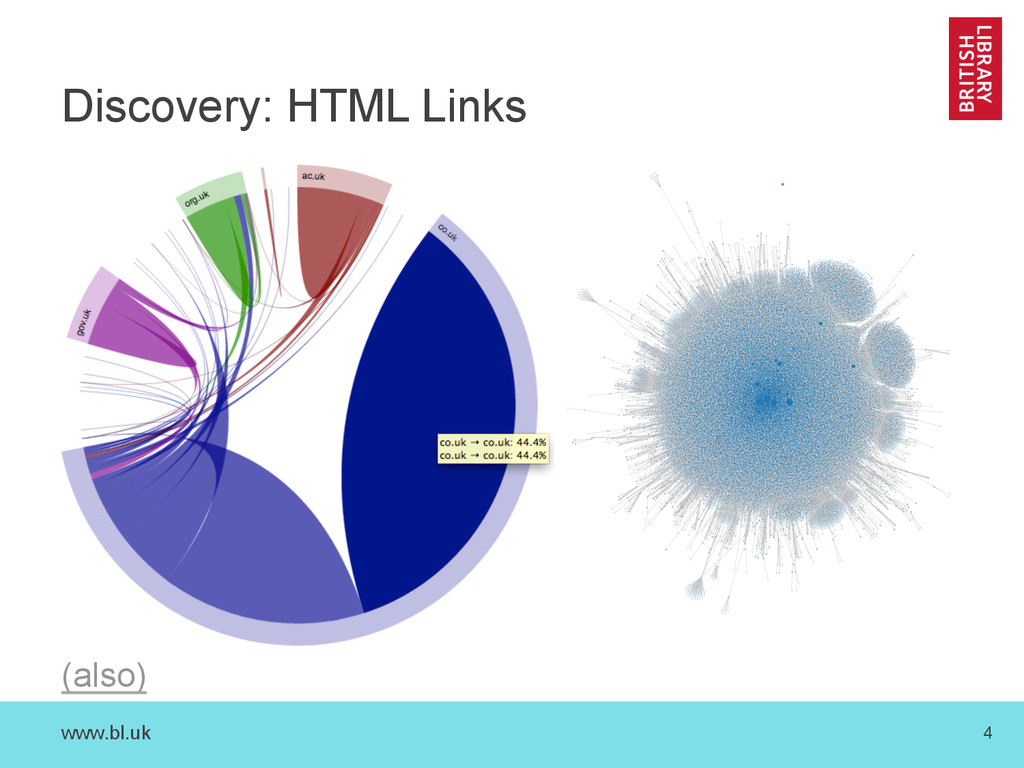{kind=link}
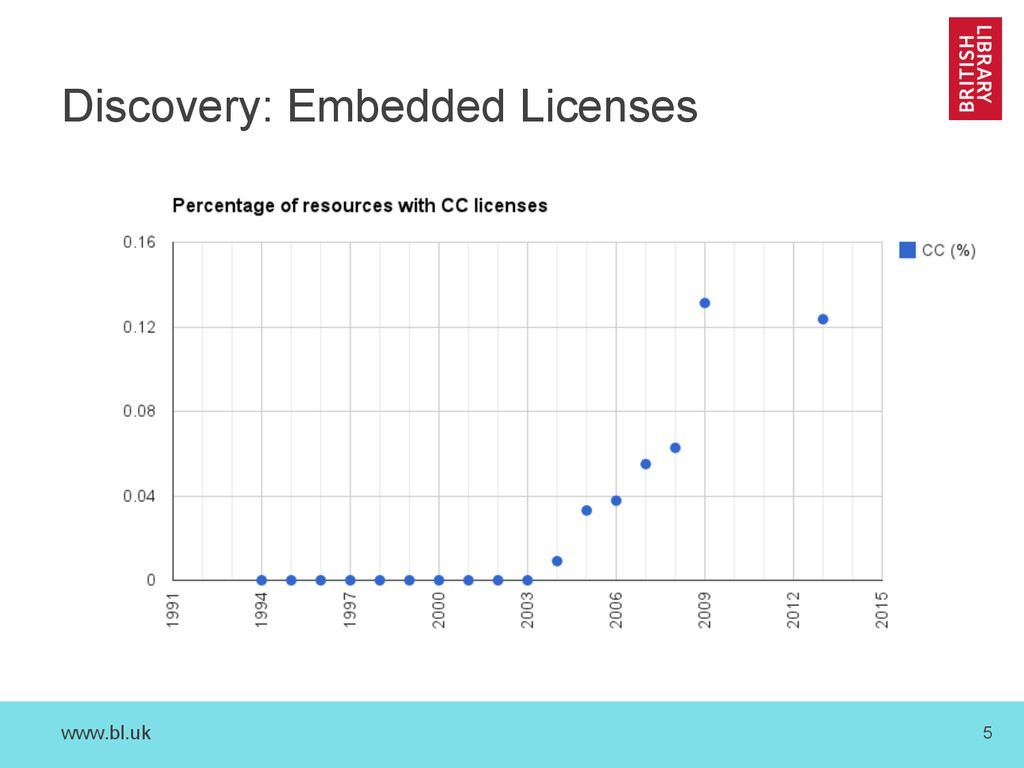{kind=link}
{kind=link}
{kind=link}
{kind=link}
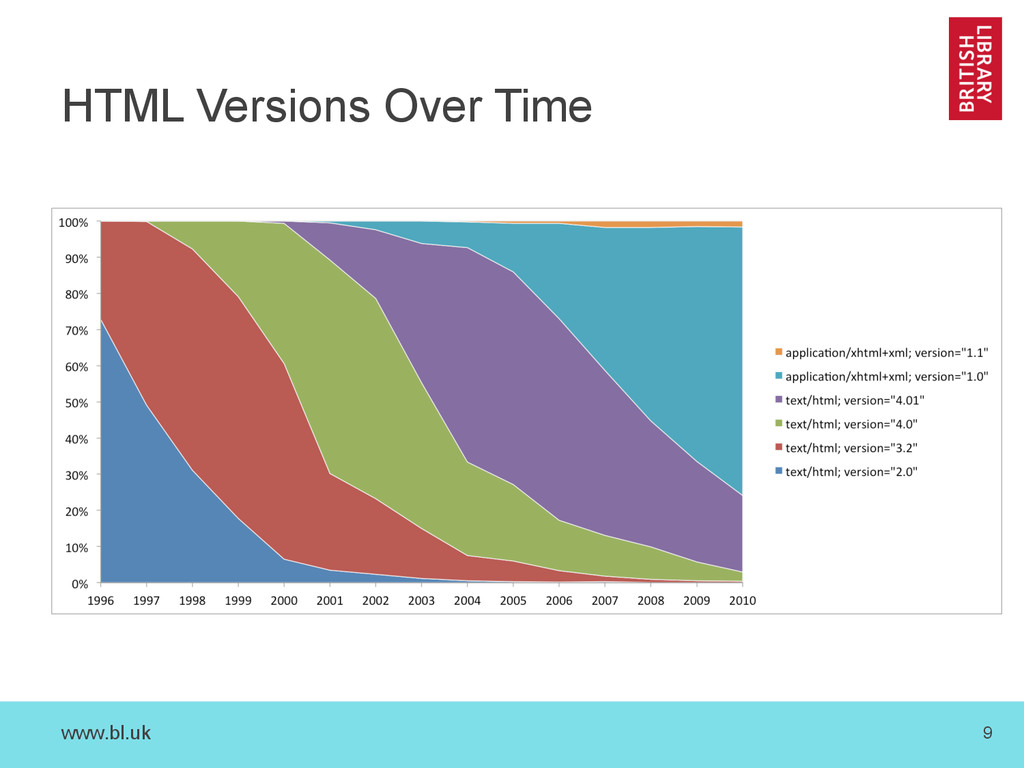{kind=link}
{kind=link}
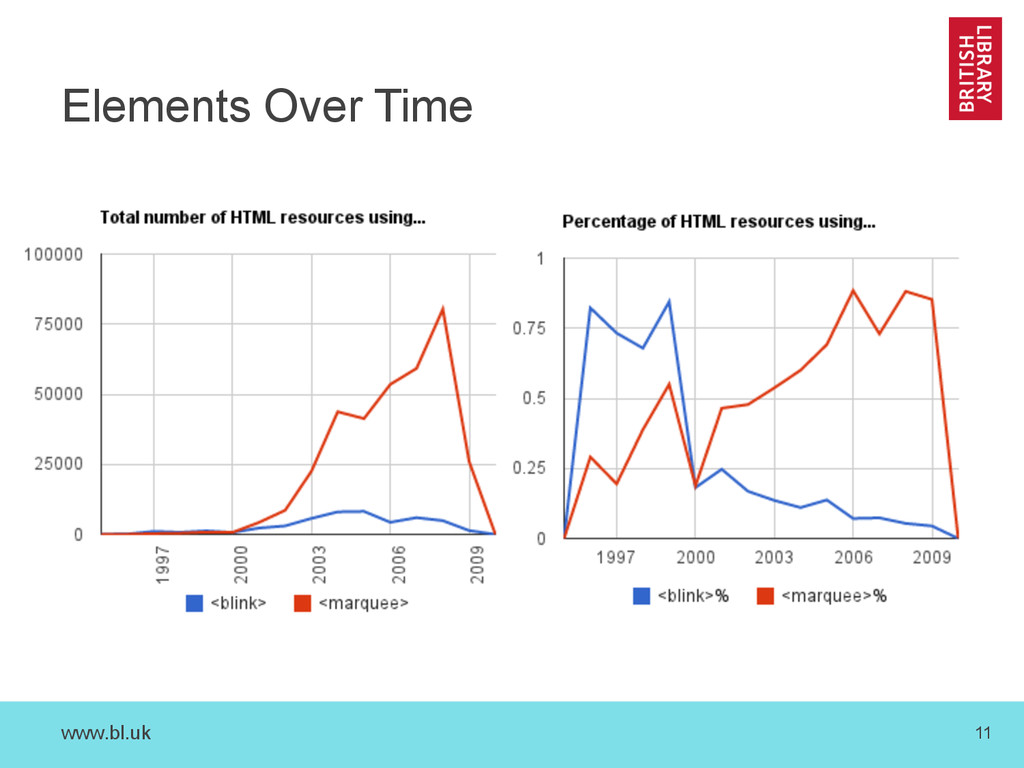{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}