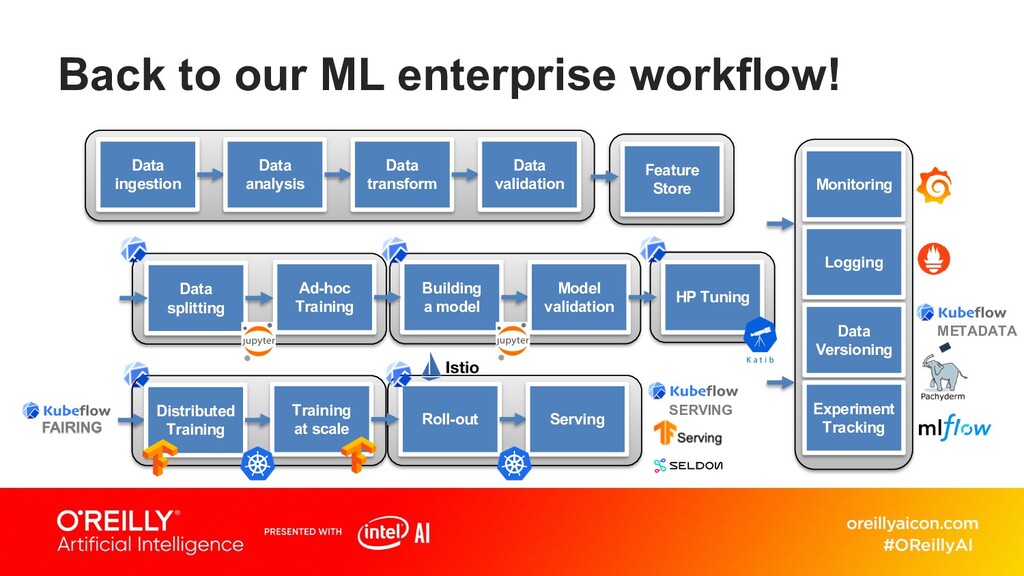
Container and cloud native technologies around Kubernetes have become the de facto standard in modern ML and AI application development. And while many data scientists and engineers tend to focus on tools, the platform that enables these tools is equally important and often overlooked.
Let’s examine some common architecture blueprints and popular technologies used to integrate AI into existing infrastructures, and learn how you can build a production-ready containerized platform for deep learning.
In particular, she explores Docker and Kubernetes, with its associated cloud native technologies, and its use and advantages in ML/AI environments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Run predictions curl http://c0198e9d-istiosystem-istio-2af2-1928351968.eu-central- 1.elb.amazonaws.com/seldon/deployment/doppelganger- model/api/v0.1/predictions -d '{"data":{"ndarray":[[0]]}}' -H "Content-Type:](https://files.speakerdeck.com/presentations/1b02e216181a4431aaf4f780063a1ce6/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}