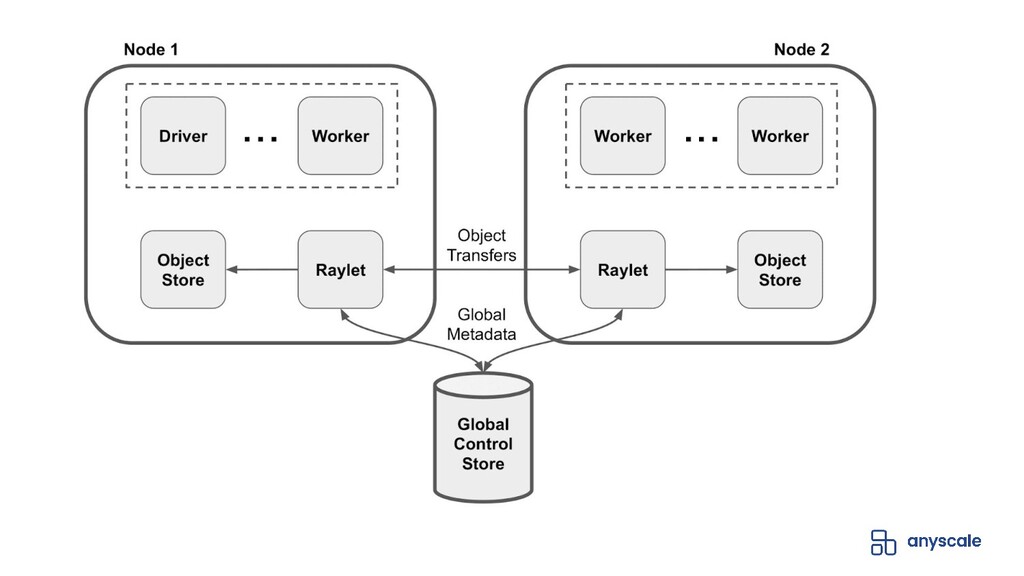
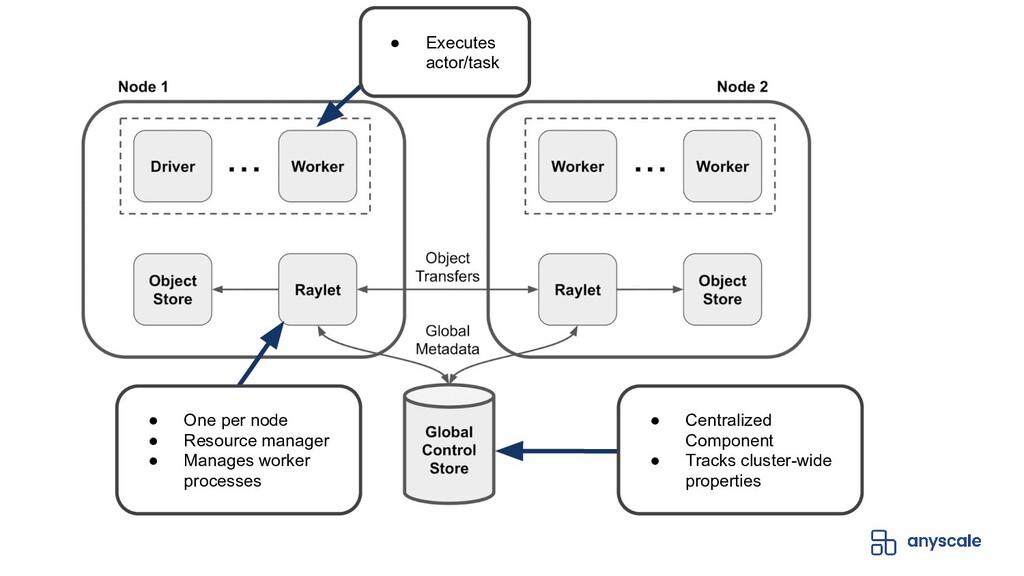
In Ray, the scheduling subsystem is responsible for deciding which process is responsible for executing a task. In this talk, we’ll take a look the different features which form Ray’s scheduling policy, in particular:
* Data locality
* Queuing
* Spillback
* Actor scheduling
* Resource borrowing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@ray.remote def step(data, weights): gradients = [] for batch in](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_21.jpg){kind=link}
{kind=link}
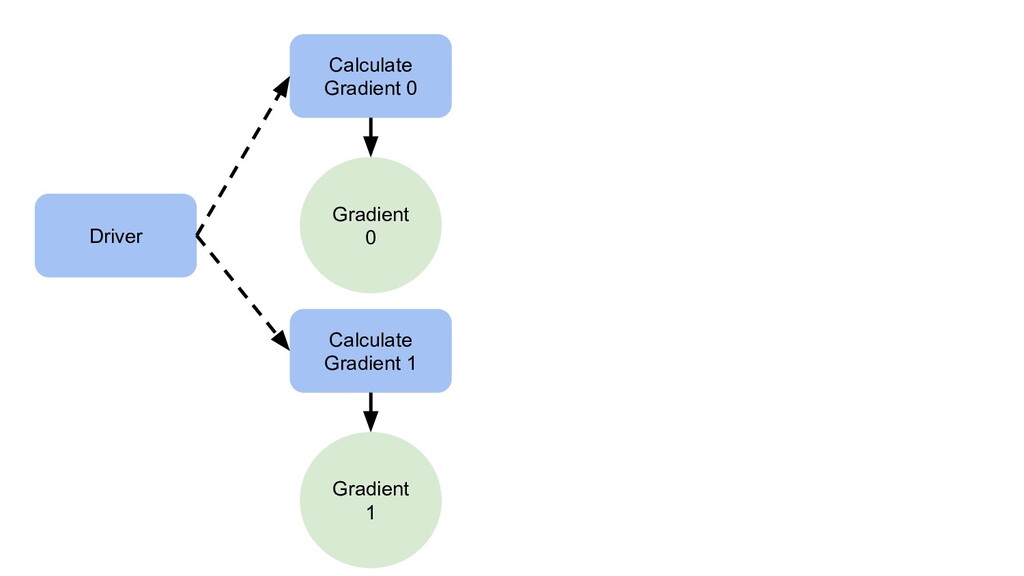{kind=link}
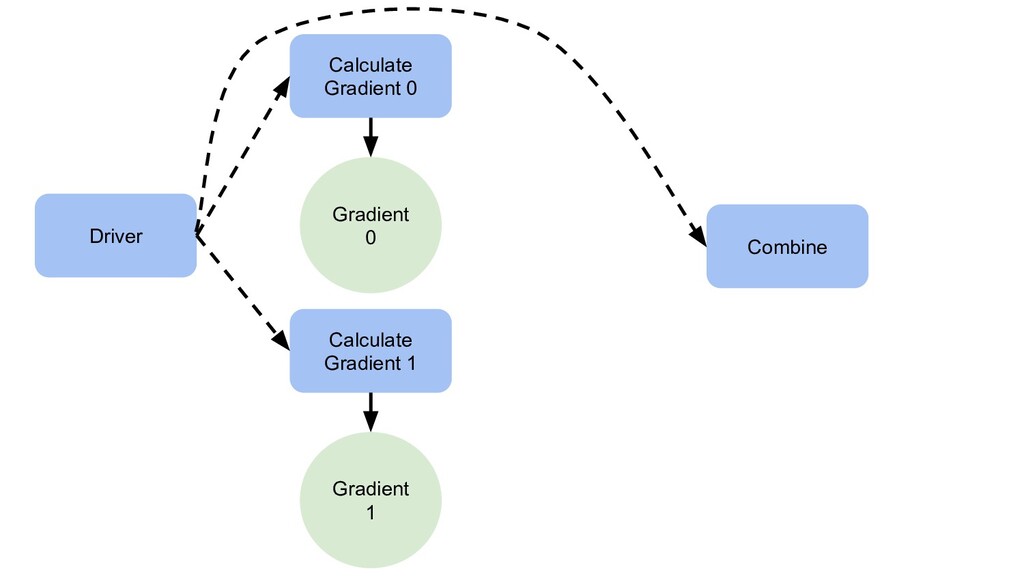{kind=link}
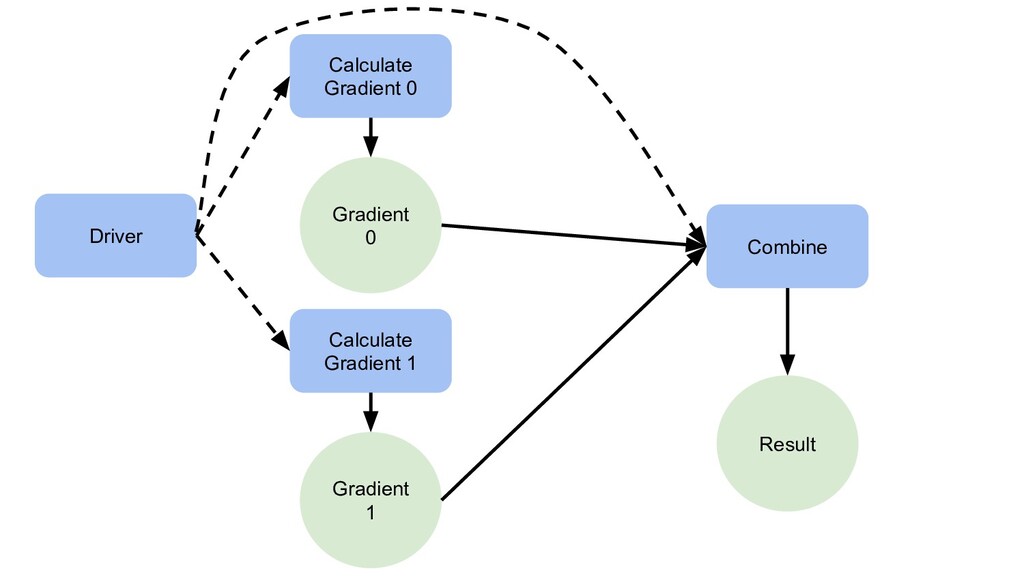{kind=link}
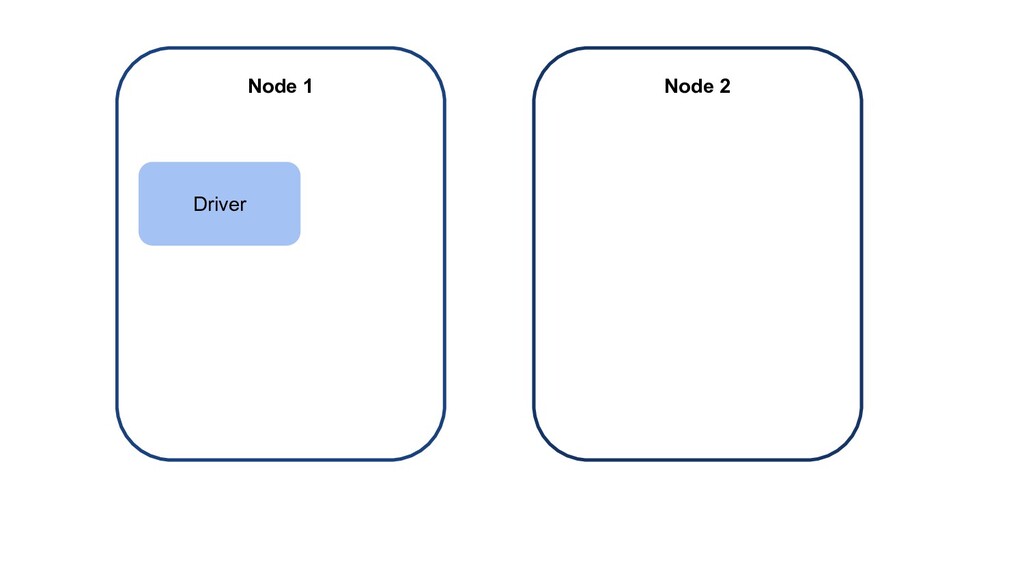{kind=link}
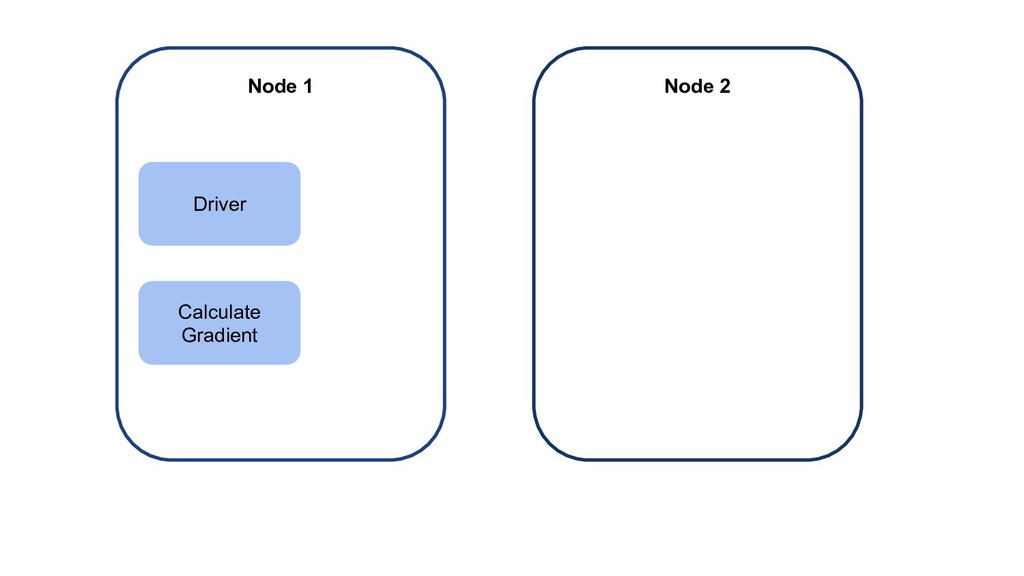{kind=link}
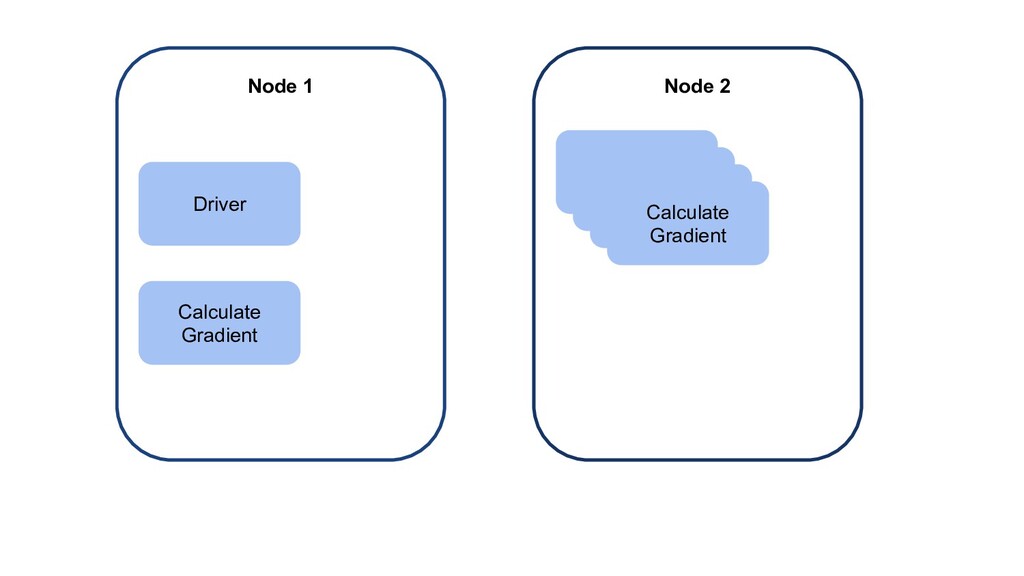{kind=link}
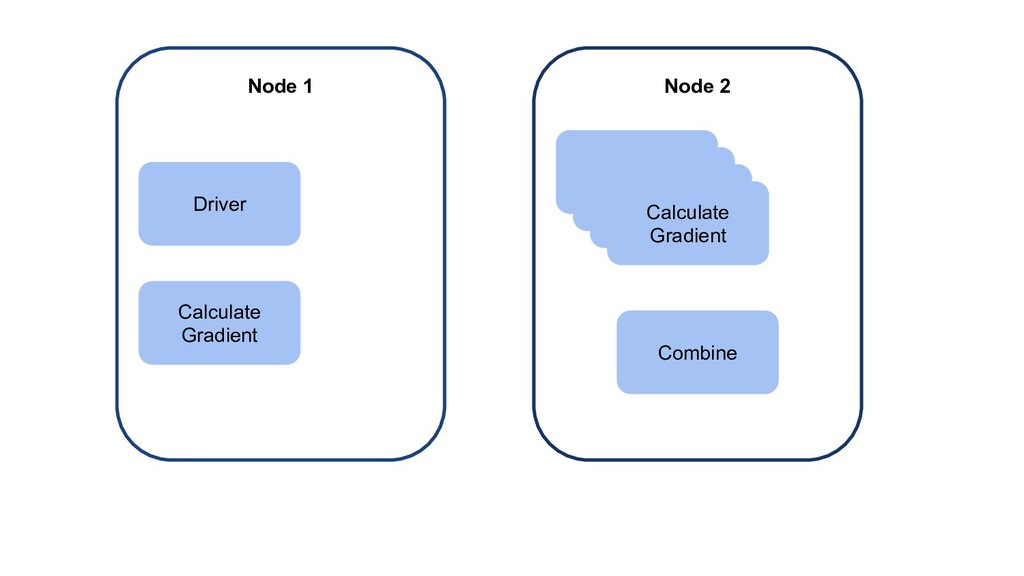{kind=link}
{kind=link}
![@ray.remote def step(data, weights): gradients = [] for batch in](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_31.jpg){kind=link}
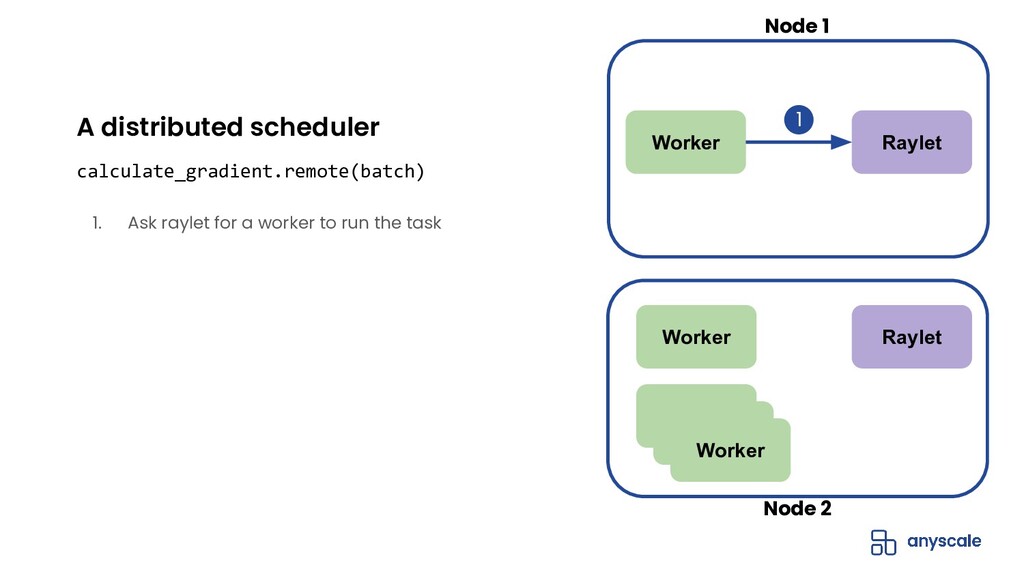{kind=link}
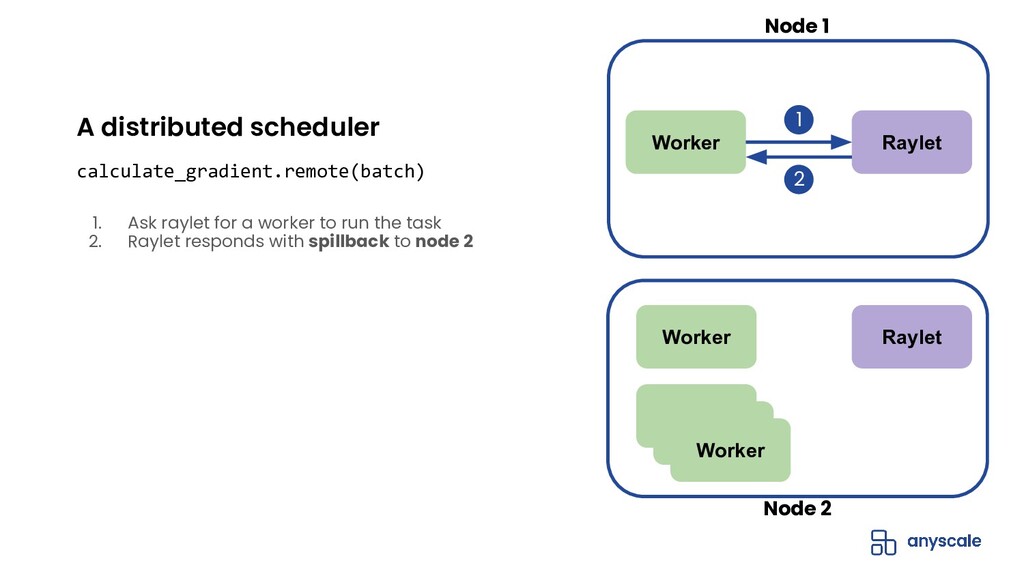{kind=link}
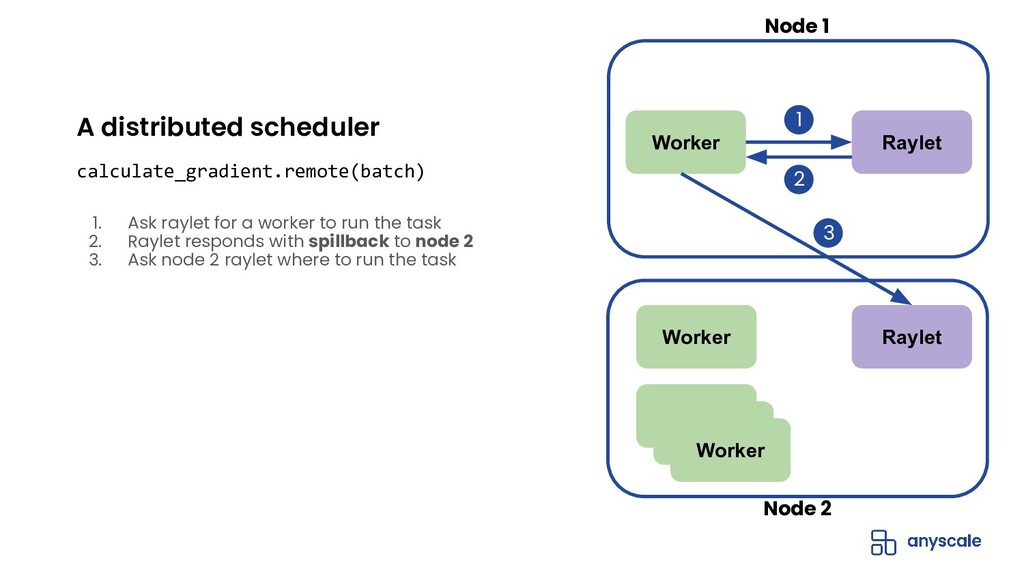{kind=link}
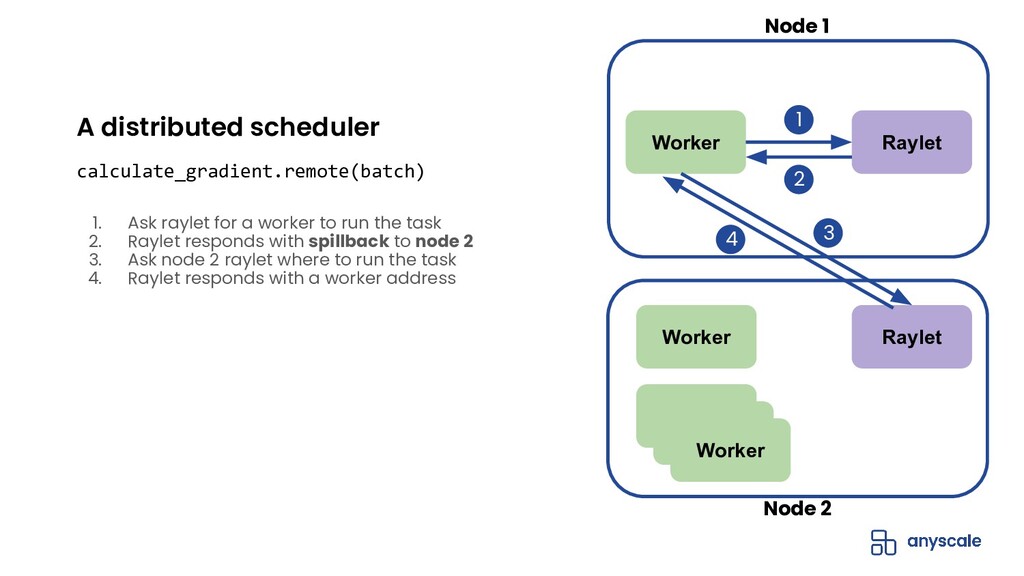{kind=link}
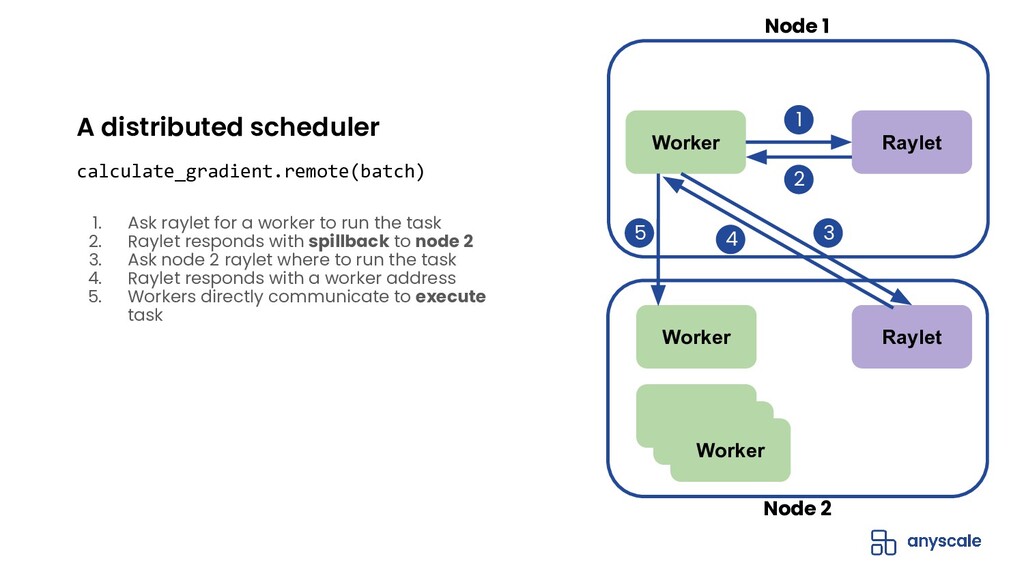{kind=link}
![@ray.remote def step(data, weights): gradients = [] for batch in](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
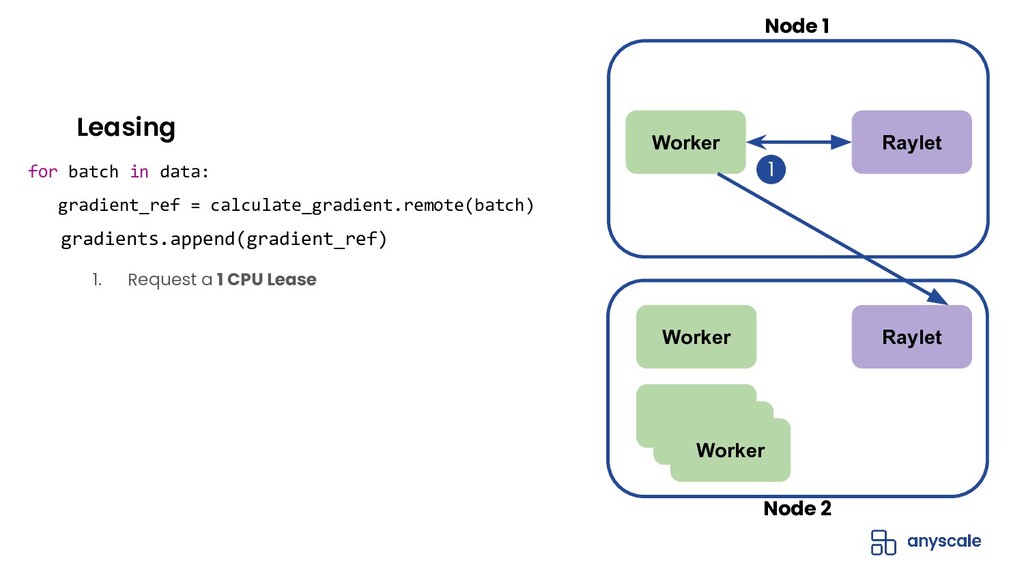{kind=link}
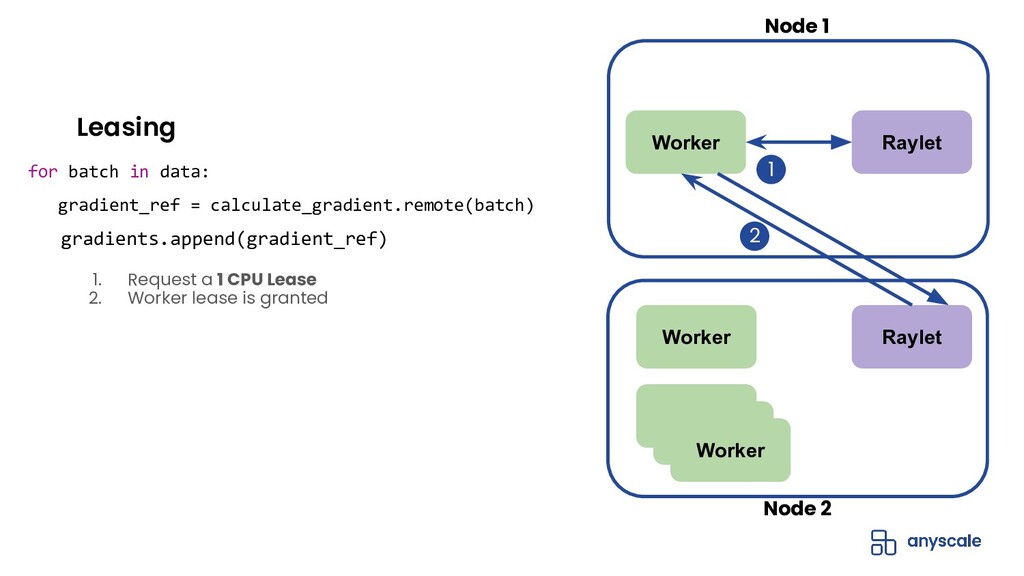{kind=link}
{kind=link}
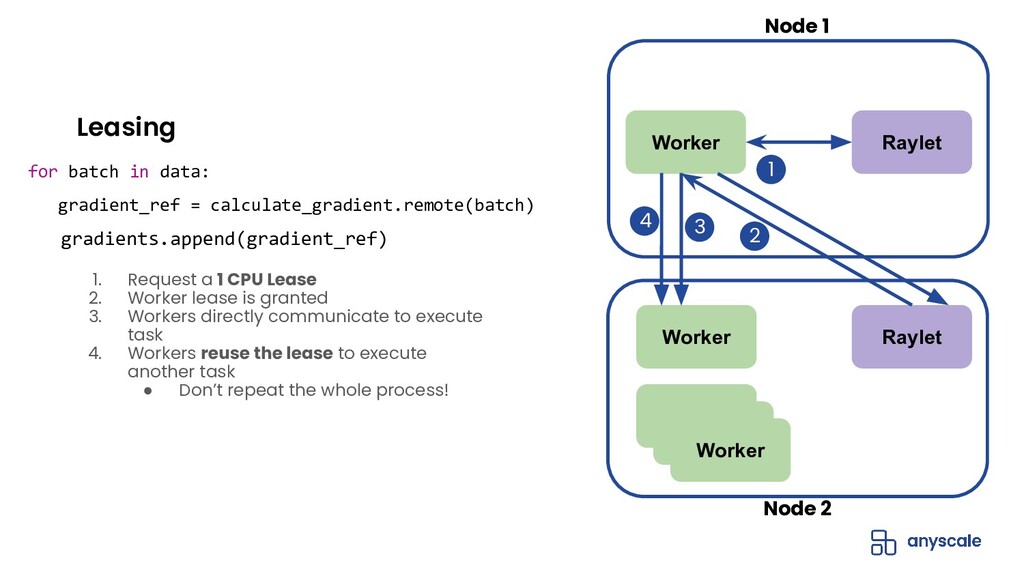{kind=link}
{kind=link}
{kind=link}
{kind=link}
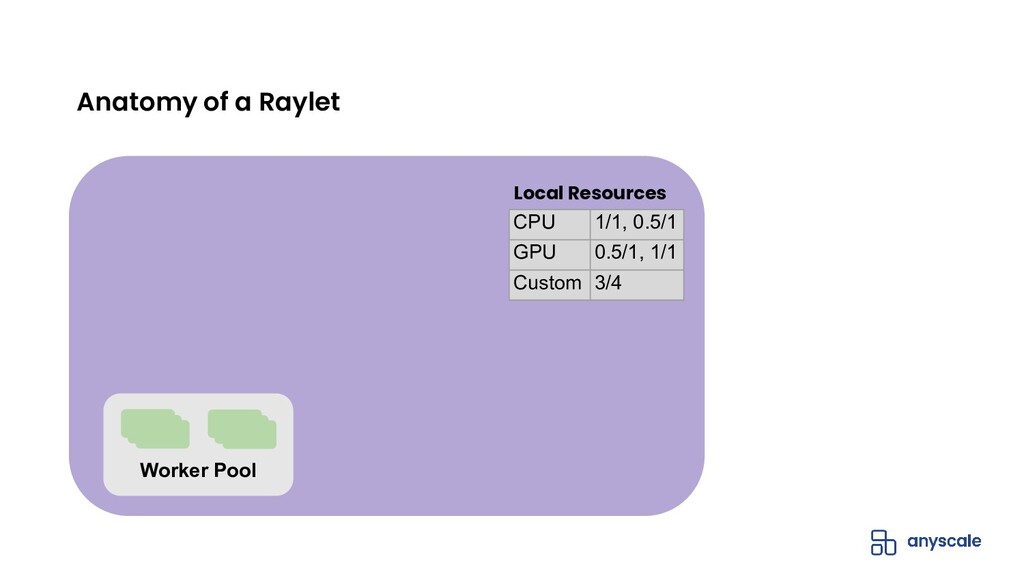{kind=link}
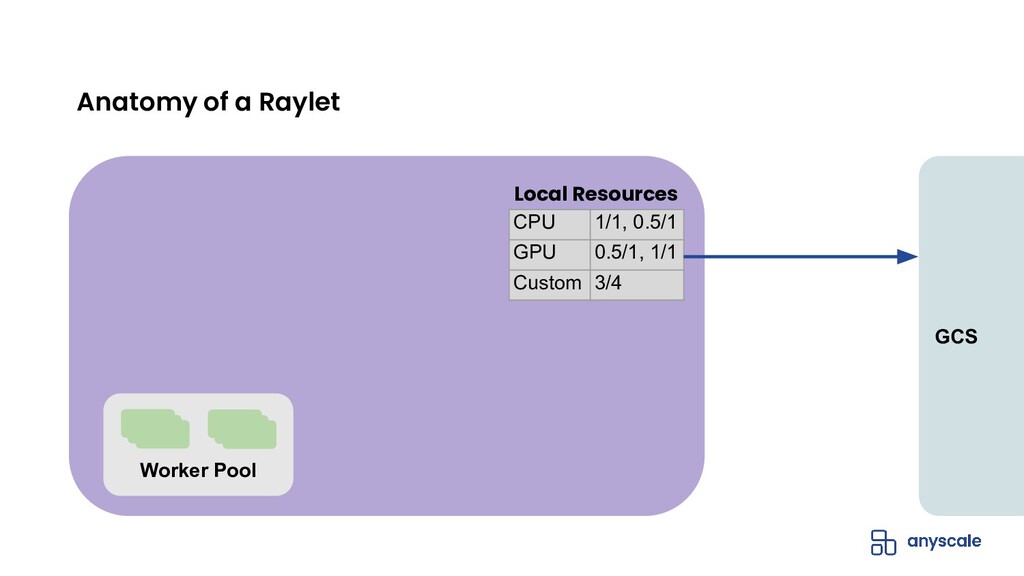{kind=link}
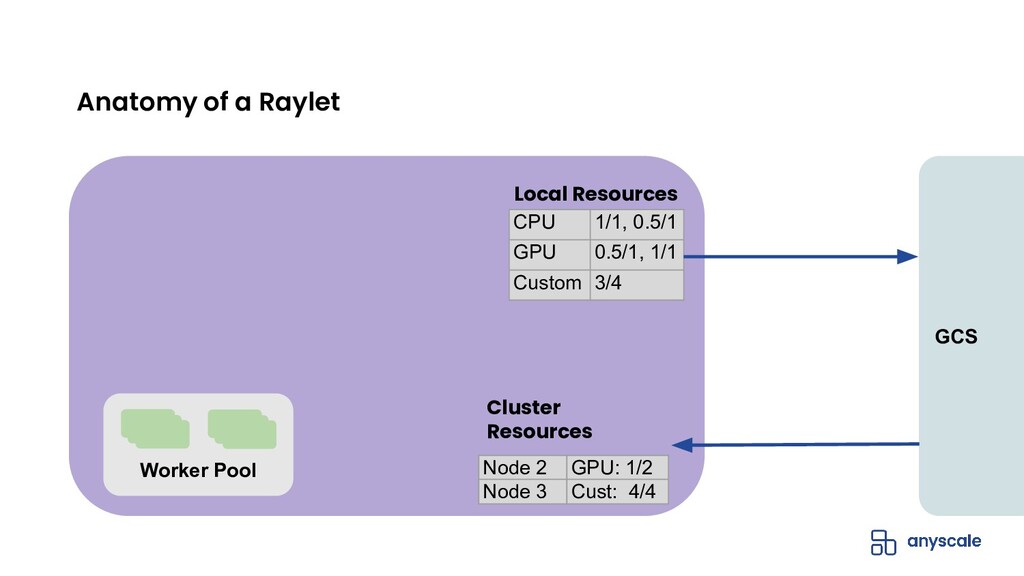{kind=link}
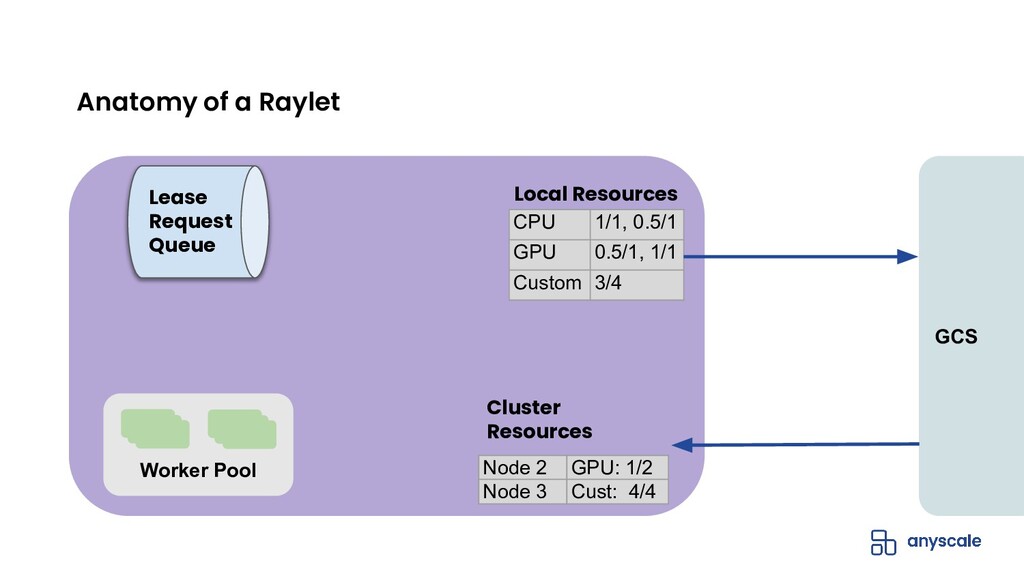{kind=link}
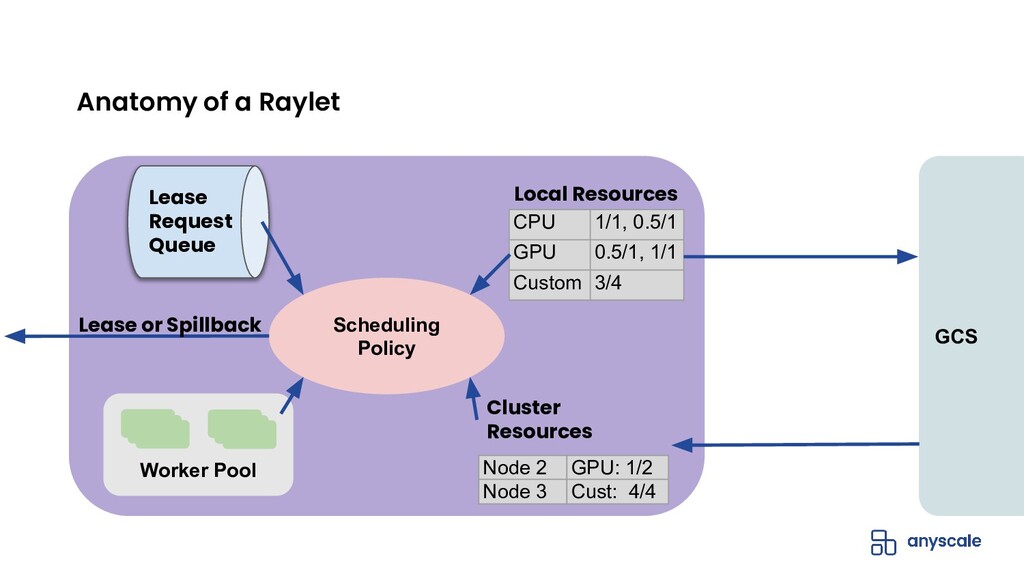{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@ray.remote def step(data, weights): gradients = [] for batch in](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_55.jpg){kind=link}
{kind=link}
![Locality Aware Leasing Core Worker Python combine.remote(*gradients) gradients[0] node 0](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_57.jpg){kind=link}
![Locality Aware Leasing Core Worker Python combine.remote(*gradients) Task Queue gradients[0]](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_58.jpg){kind=link}
![Locality Aware Leasing Core Worker Python combine.remote(*gradients) Task Queue gradients[0]](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_59.jpg){kind=link}
![Locality Aware Leasing Core Worker Python combine.remote(*gradients) Task Queue gradients[0]](https://files.speakerdeck.com/presentations/a76c7d5bd7014816827c4ca504436bd0/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}