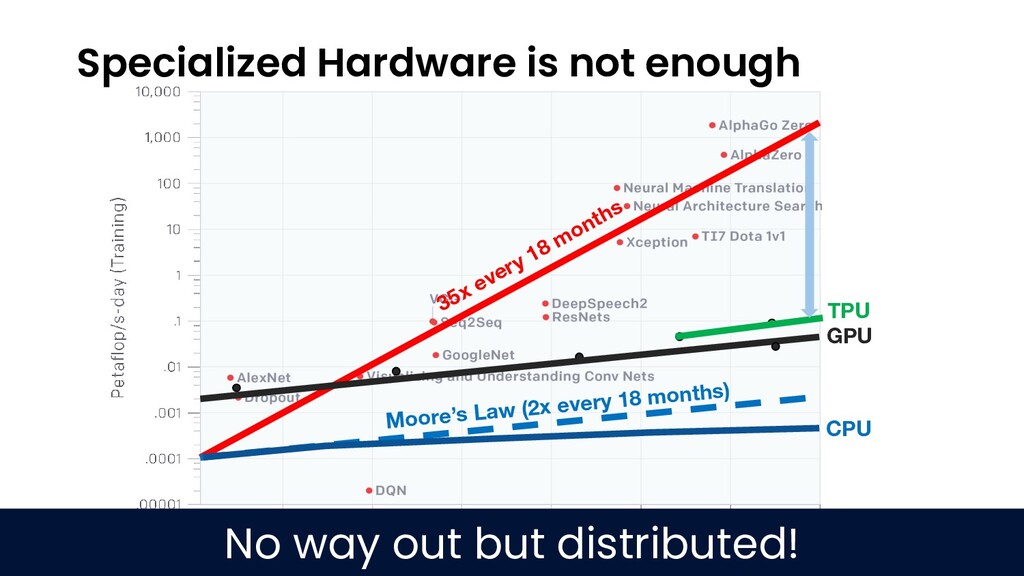
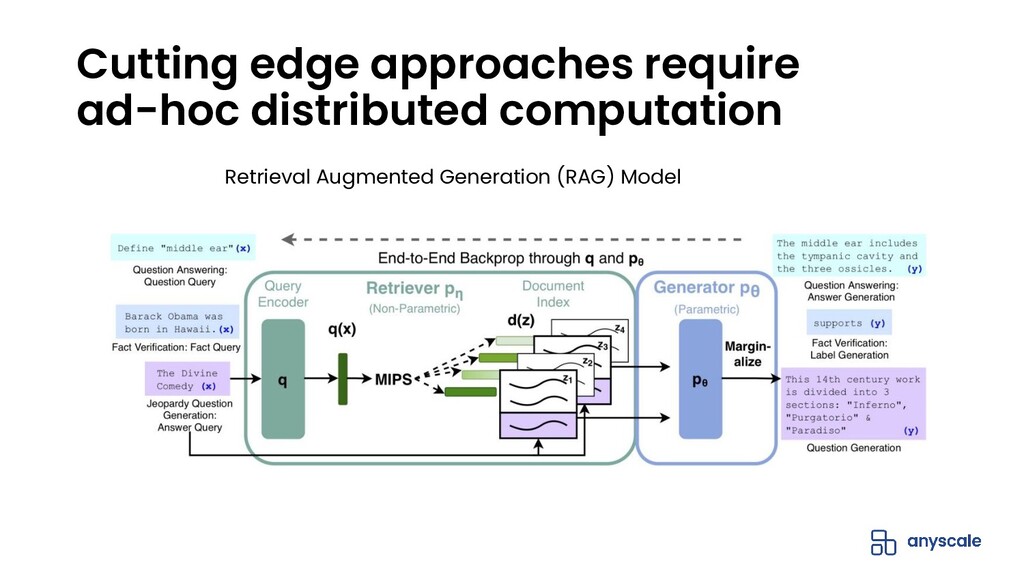
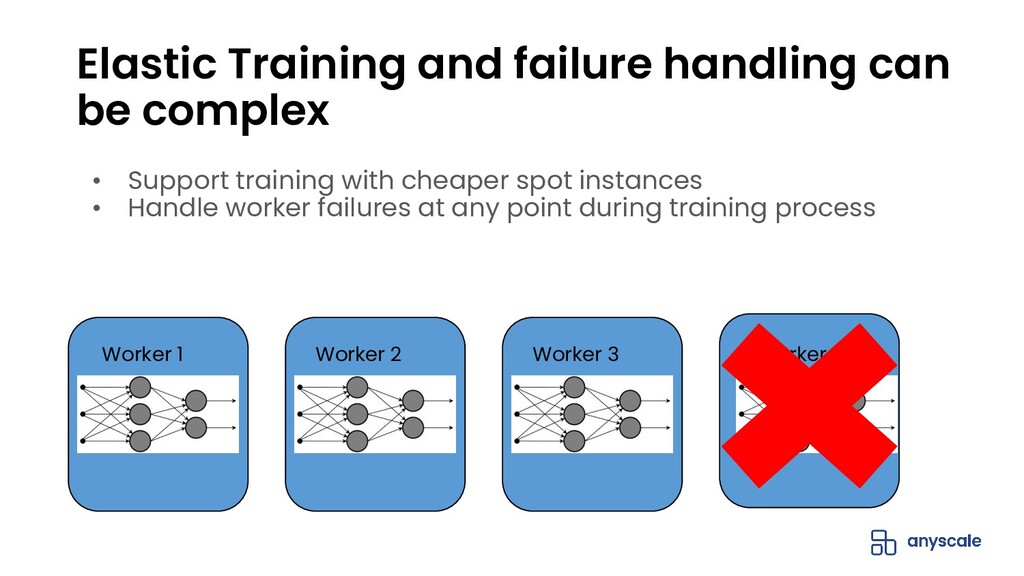
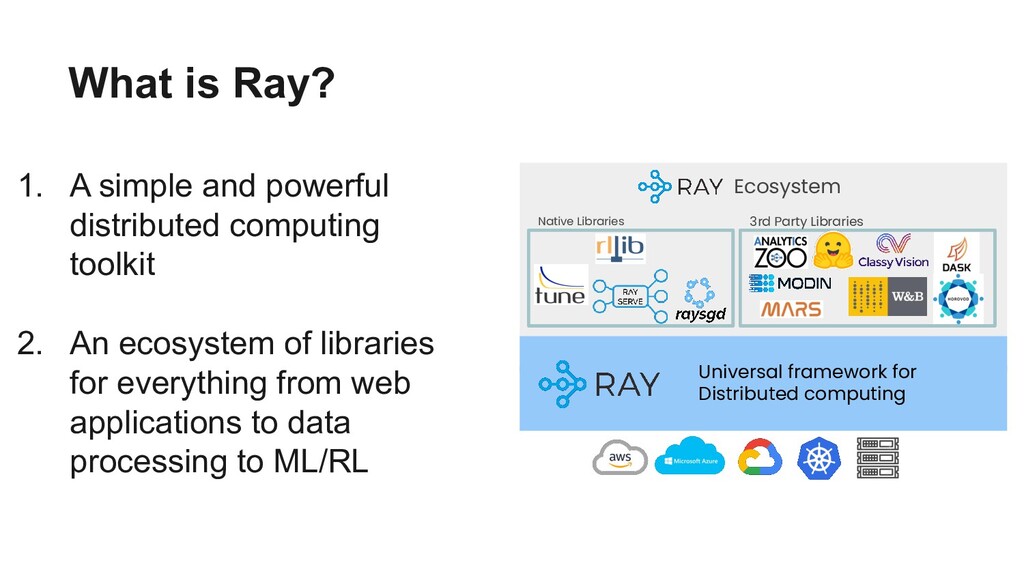
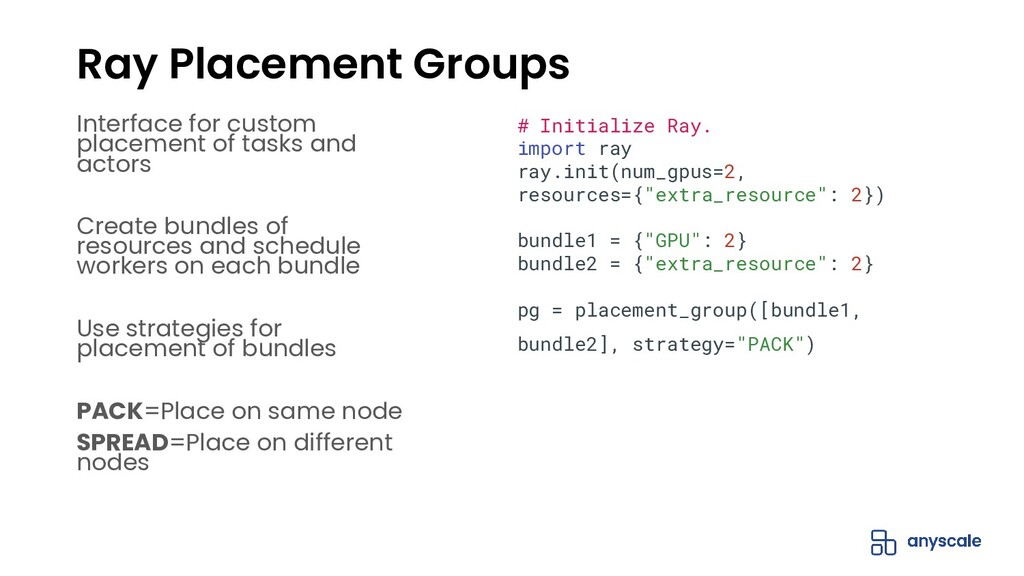
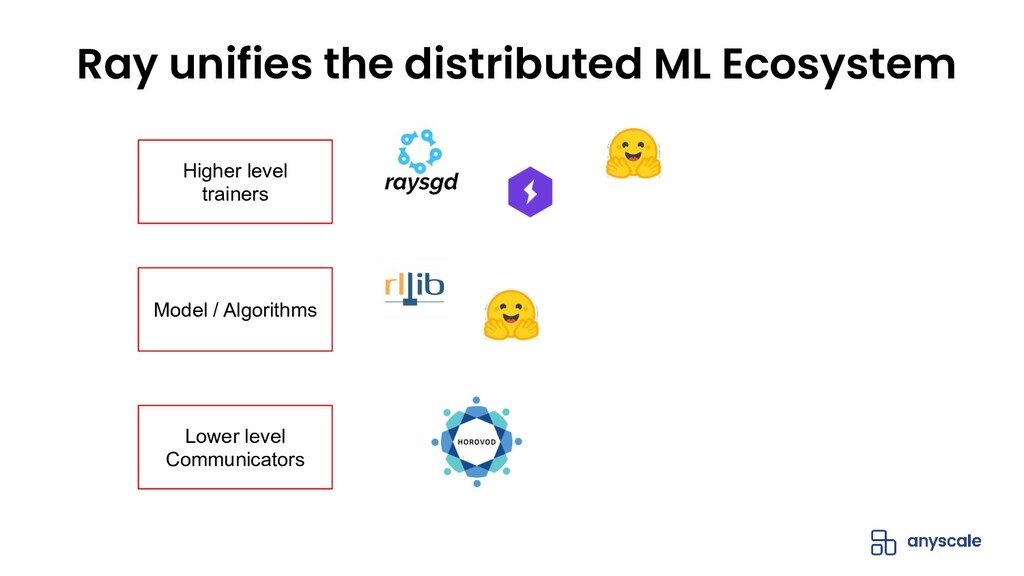
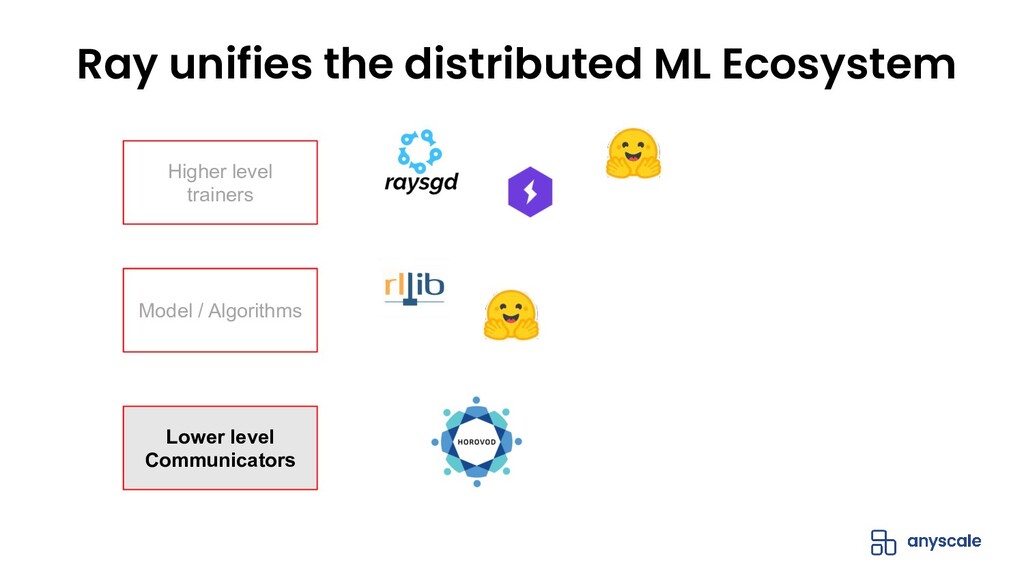
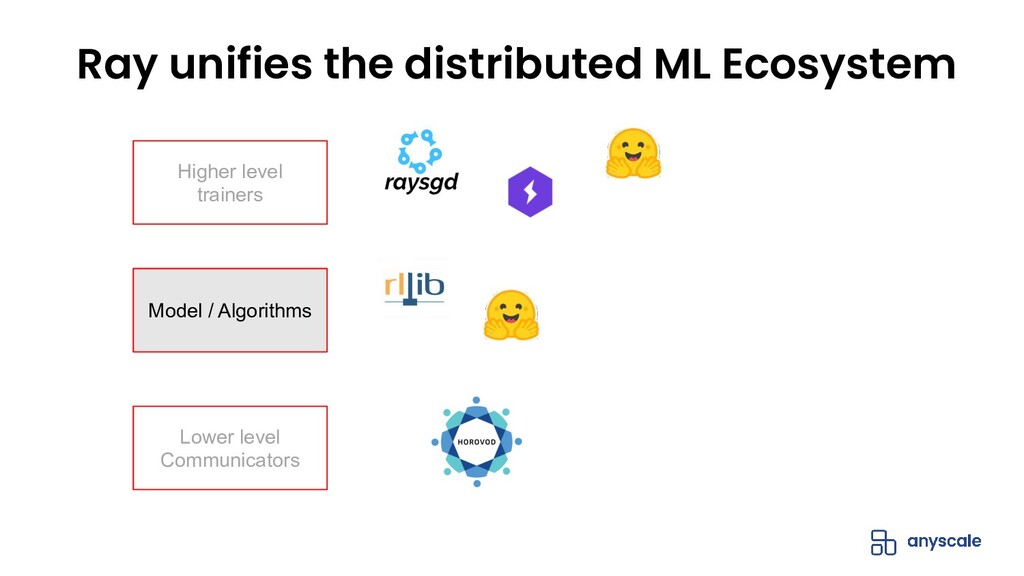
The open-source Python ML ecosystem has seen rapid growth over the recent years. As these libraries mature, there is an increased demand for distributed execution frameworks that allow programmers to handle large amounts of data and coordinate computational resources. In this talk, we discuss our experiences collaborating with the open source Python ML ecosystem as maintainers of Ray, a popular distributed execution framework. We will cover how distributed computing has shaped the way machine learning is done, and go through case studies on how three popular open source ML libraries (Horovod, HuggingFace transformers, and spaCy) benefit from Ray for distributed training.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
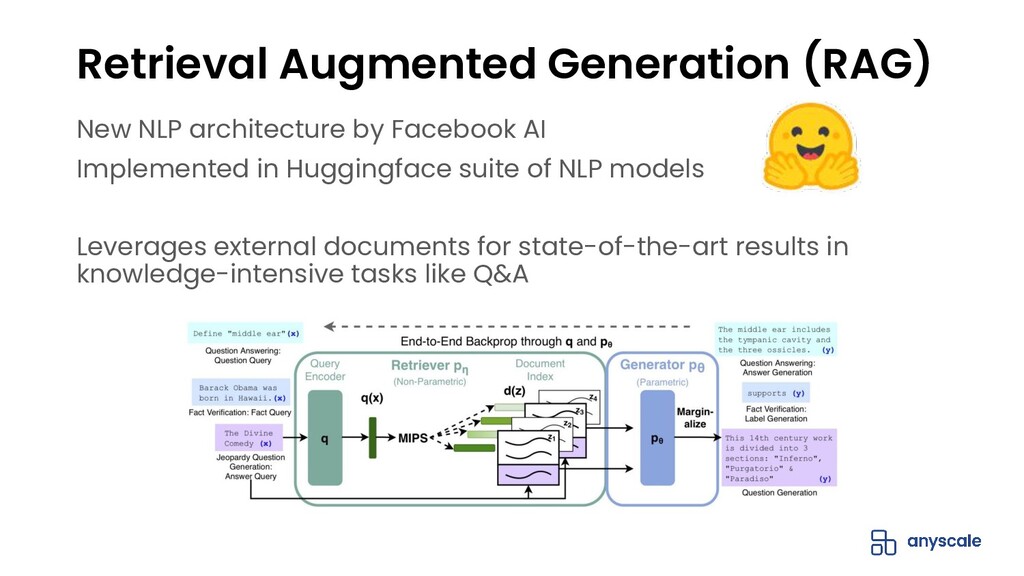{kind=link}
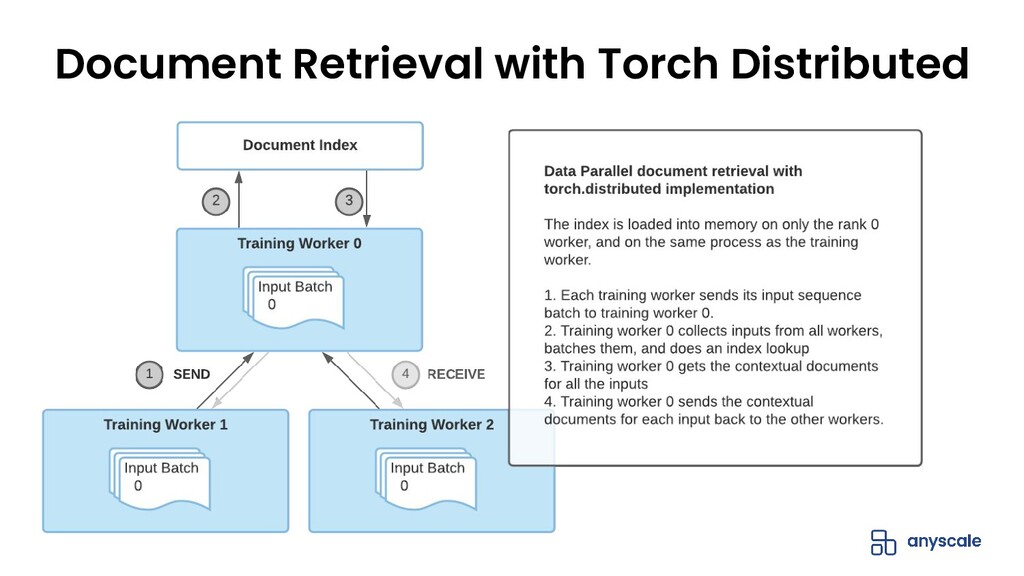{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
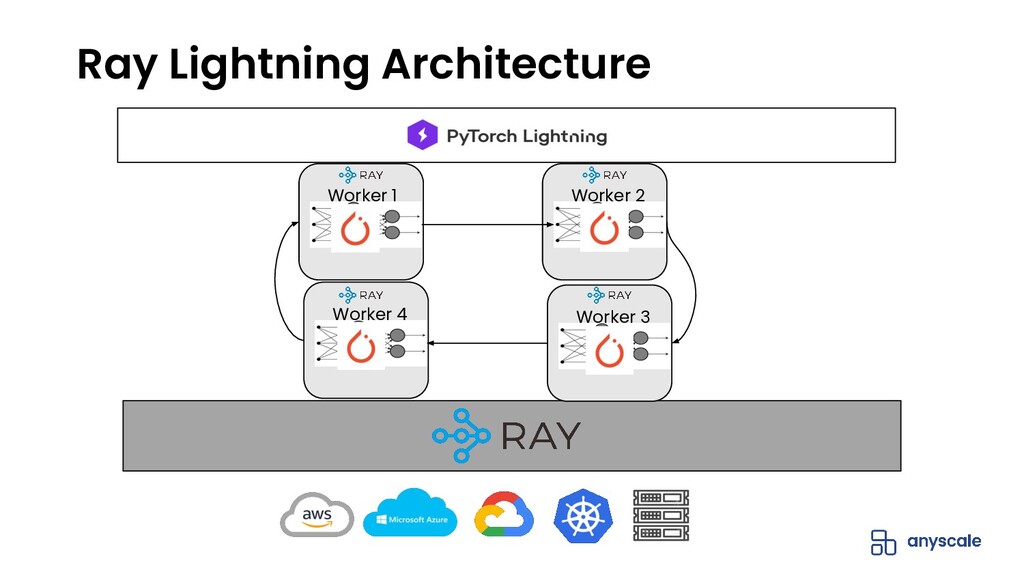{kind=link}
{kind=link}
{kind=link}
{kind=link}