In this session, we’ll explore industrial applications of reinforcement learning and compare the performance of an RL policy to traditional heuristics and optimizers. We have found that in certain use cases, RL can outperform all other approaches by more than 10%. We will cover the following topics:
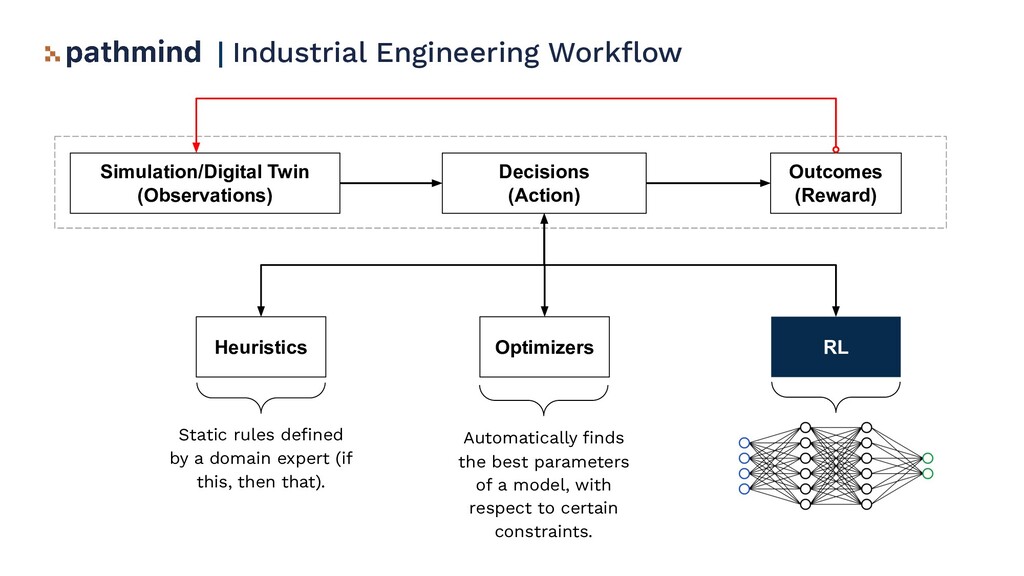
1. A comparison of reinforcement learning versus heuristics and optimizers.
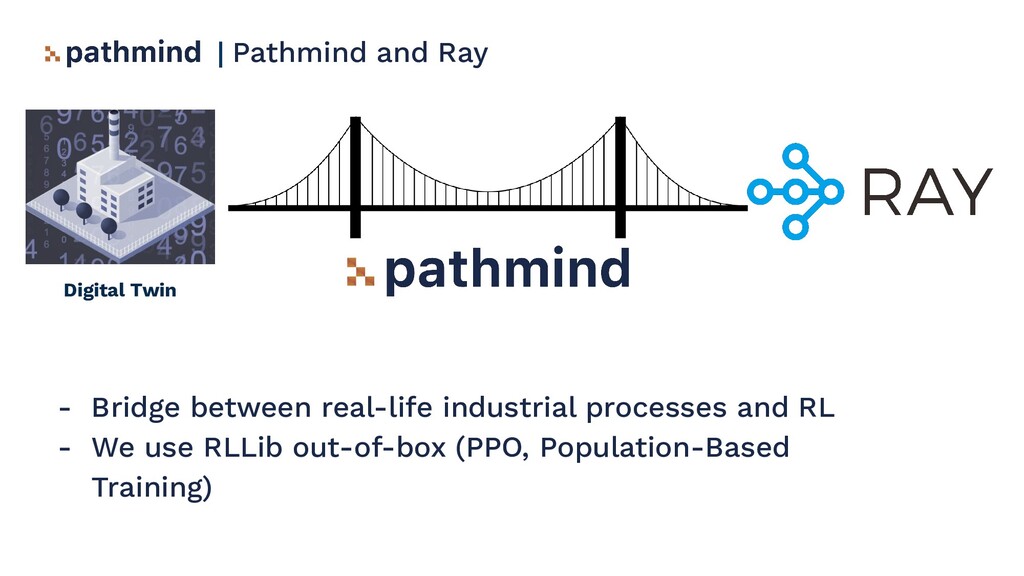
2. Bridging Ray with a simulation IDE such as AnyLogic to train a reinforcement learning policy.
3. A demo using a heating, ventilation, and air condition (HVAC) system.
At the conclusion of this session, you should be able to identify use cases suitable for RL and gain intuition on how reinforcement learning can be applied to industrial use cases.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU [email protected] [email protected]](https://files.speakerdeck.com/presentations/ccc6987727e9480e89fb34bacec2372f/slide_9.jpg){kind=link}