engine for travel ◦ Expertise in building large scale distributed systems ▪ SQL, Nosql, Big Data ▪ Database engines ▪ Fault-tolerant systems ◦ Ex-VPE Cloud Lending Solutions (Fin-tech startup), Ex-Yahoo, Ex-MS, Ex-HP
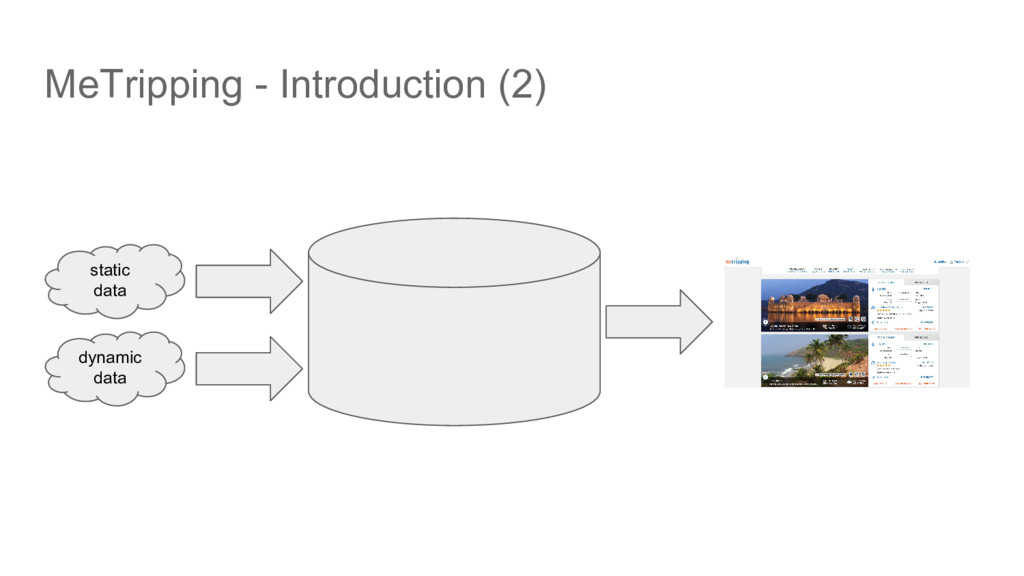
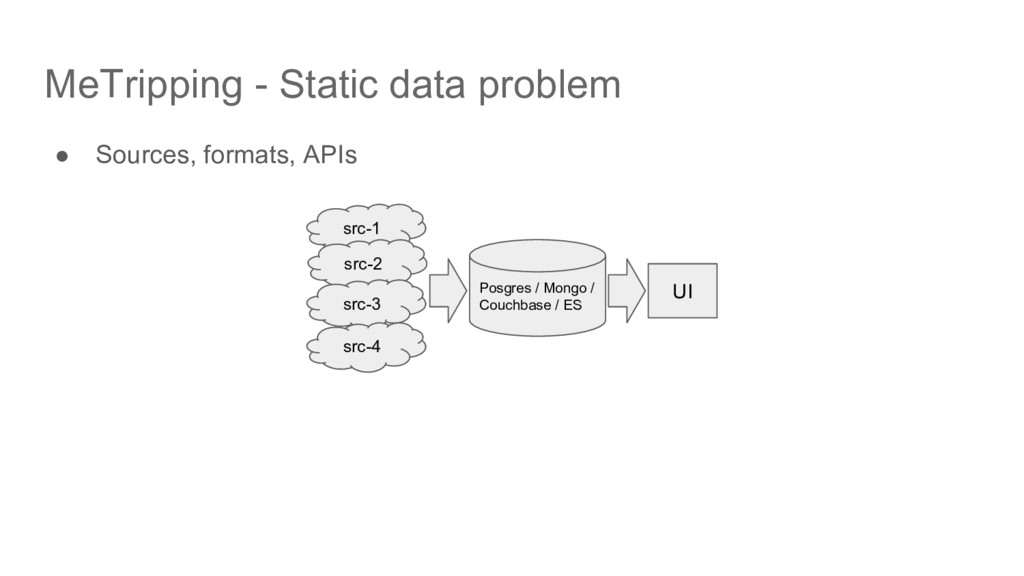
of dynamic data per rank list page • Response time ◦ Static data + dynamic data + ML scoring < 30 - 45 secs (current performance) • Static data problem ◦ Multiple data sources and formats
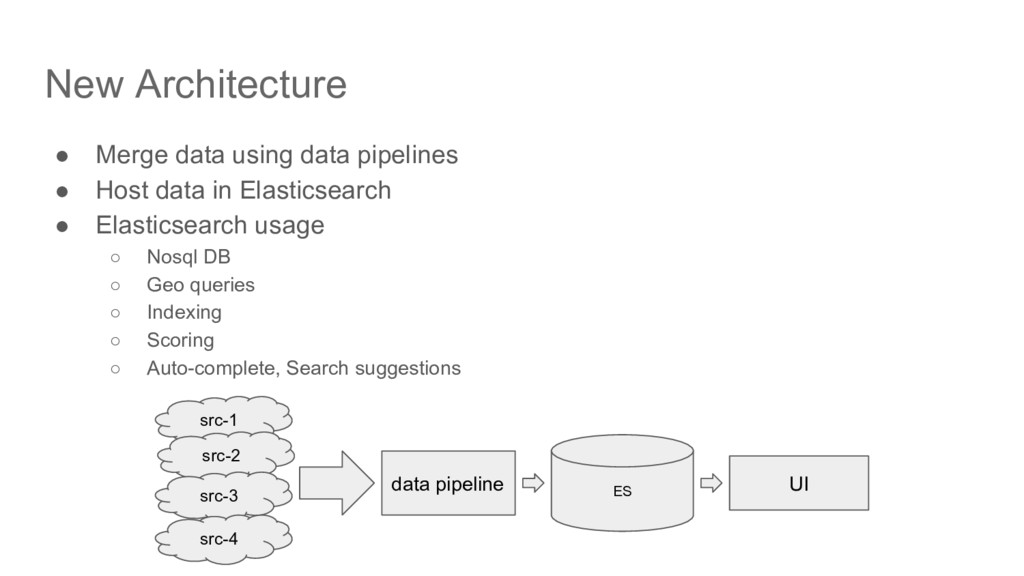
query performance ◦ 10s inserts / second vs. 1000s queries / secord • Ease of indexing ◦ No need to spend tons of efforts on query optimization • Custom scoring is extremely powerful (using painless scripting language)
Disable dynamic schema discovery in production • Index only required columns (default: true) ◦ Significantly improves insert performance • Include ‘doc_values’ where needed (default: true) • Understand ‘text’ vs. ‘keyword’ data type differences ◦ Use ‘text’ data type only where fuzzy match needed • Use manageable size shards • Use replicas (cluster) for redundancy, scalability, and performance • Use aliases for easy index switchover (eases index refreshes / upgrades) • System planning ◦ CPU: For typical use-cases (index and search) ES is extremely efficient, so low CPU needs ◦ Memory: For best performance, complete index should fit in system memory ◦ Hard disk: Use SSD. Plan spare capacity for Index upgrades.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Gaurav ([email protected])](https://files.speakerdeck.com/presentations/41b87d623e5b4b87a0d9dd4ac04d9f11/slide_14.jpg){kind=link}