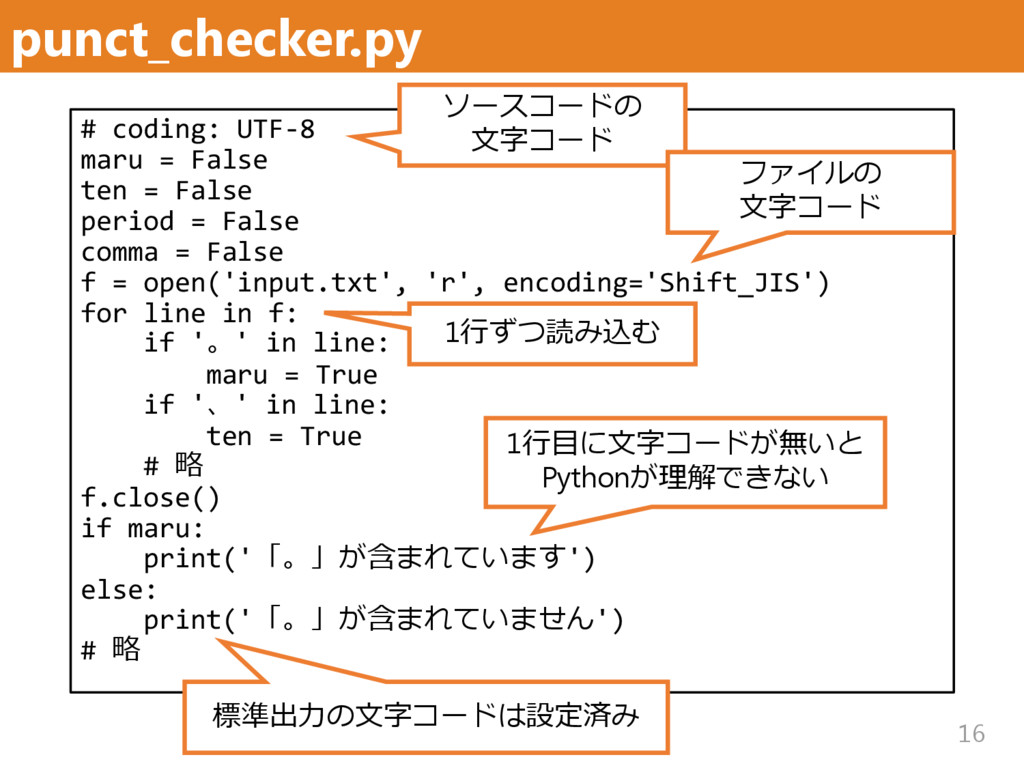
False period = False comma = False f = open('input.txt', 'r', encoding='Shift_JIS') for line in f: if '。' in line: maru = True if '、' in line: ten = True # 略 f.close() if maru: print('「。」が含まれています') else: print('「。」が含まれていません') # 略 1行ずつ読み込む ソースコードの 文字コード 1行目に文字コードが無いと Pythonが理解できない ファイルの 文字コード 標準出力の文字コードは設定済み
'r', encoding='Shift_JIS') as f: for line in f: lines.append(line) with open('output.txt', 'w', encoding='UTF-8') as f: for line in lines: line = line.replace('.', '。') line = line.replace(',', '、') print(line, file=f) ファイルに書き込み with open(...) as f: を使うと 自動でf.close() replace:置換
'r') as f: for line in f: lines.append(line.decode('Shift_JIS')) with open('output.txt', 'w') as f: for line in lines: line = line.replace(u'.', u'。') line = line.replace(u',', u'、') f.write(line.encode('UTF-8')) decodeはプログラマの 責任 ASCII以外の文字コードなんて知らん!! (codecsモジュールを使う方法もある) encodeもプログラマの 責任 非ASCII文字には u””を付ける
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![punct_normalizer.py 17 # coding: UTF-8 lines = [] with open('input.txt',](https://files.speakerdeck.com/presentations/72f2f519c7674af58bfd4070a81ee432/slide_16.jpg){kind=link}
![Python2系の思い出 18 # coding: UTF-8 lines = [] with open('input.txt',](https://files.speakerdeck.com/presentations/72f2f519c7674af58bfd4070a81ee432/slide_17.jpg){kind=link}