10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.4 Safari/605.1.15 (Applebot/0.1; +http://www.apple.com/go/applebot) Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; Bytespider;
[email protected]) Mozilla/5.0 (compatible; Bytespider;
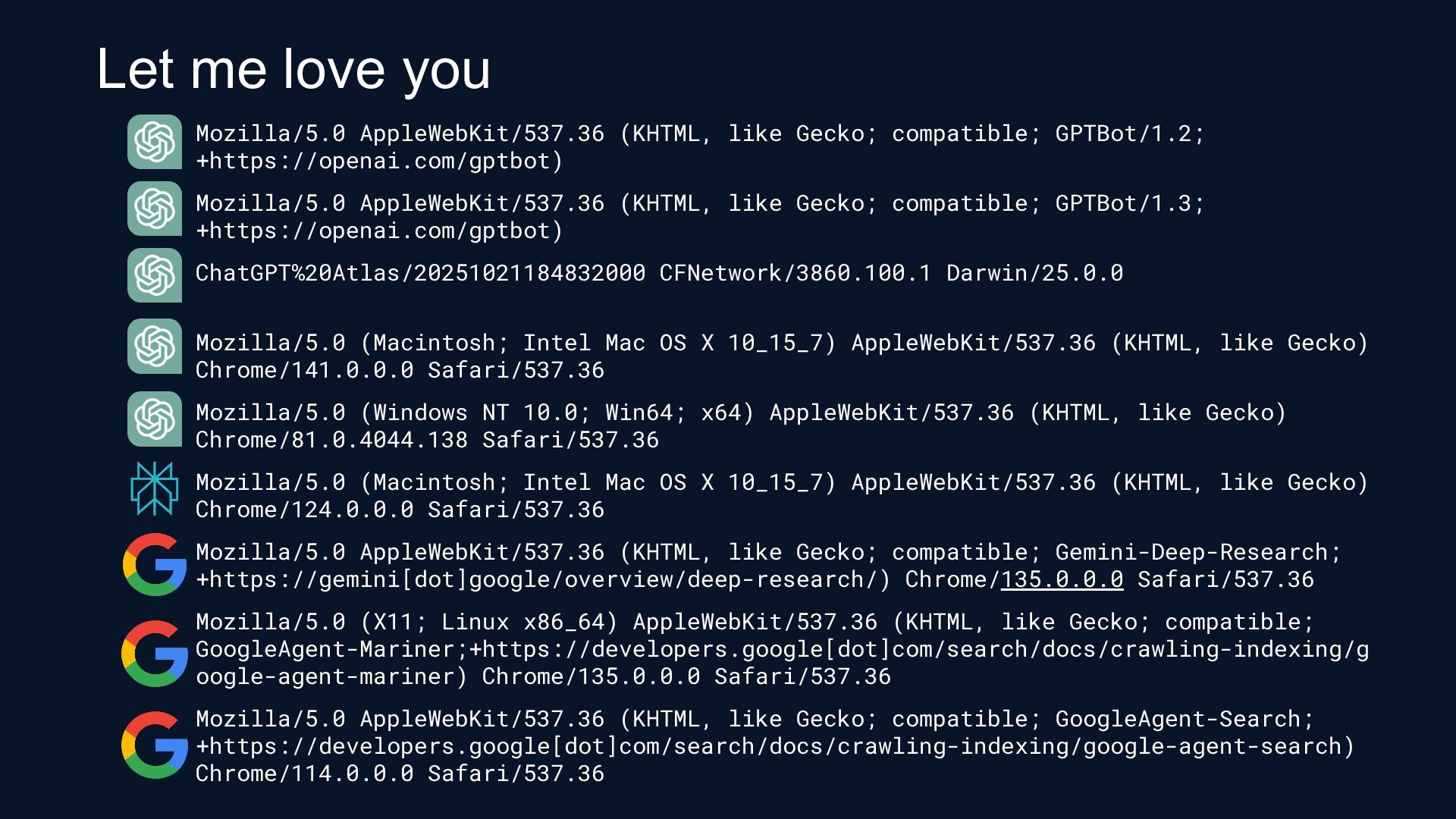
[email protected]) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.0.0 Safari/537.36 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/148.0.7778.96 Mobile Safari/537.36 (compatible; GoogleOther) Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; compatible; OAI-SearchBot/1.3; +https://openai.com/searchbot Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; TikTokSpider;
[email protected]) Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0;
[email protected]) meta-webindexer/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) Verity/1.1 (https://gumgum.com/verity;
[email protected]) Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0;
[email protected]) Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36; ClaudeBot/1.0;
[email protected]) Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot) Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/144.0.0.0 Safari/537.36 Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (HTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot) CCBot/2.0 (https://commoncrawl.org/faq/) meta-externalfetcher/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) DuckAssistBot/1.2; (+http://duckduckgo.com/duckassistbot.html) Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot) Google-NotebookLM
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_14.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_15.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_16.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_17.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_18.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_19.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_20.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_21.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_22.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_23.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_24.jpg){kind=link}
![216.150.168.131 emeasrvr003 [07/Mar/2018:16:11:58 -0800] 66.249.66.1 GET /twiki/bin/view/TWiki/WikiSyntax?q=ntoon HTTP/1.1 www.example.com 200](https://files.speakerdeck.com/presentations/c6f2073bfb384278b004df3f632703af/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
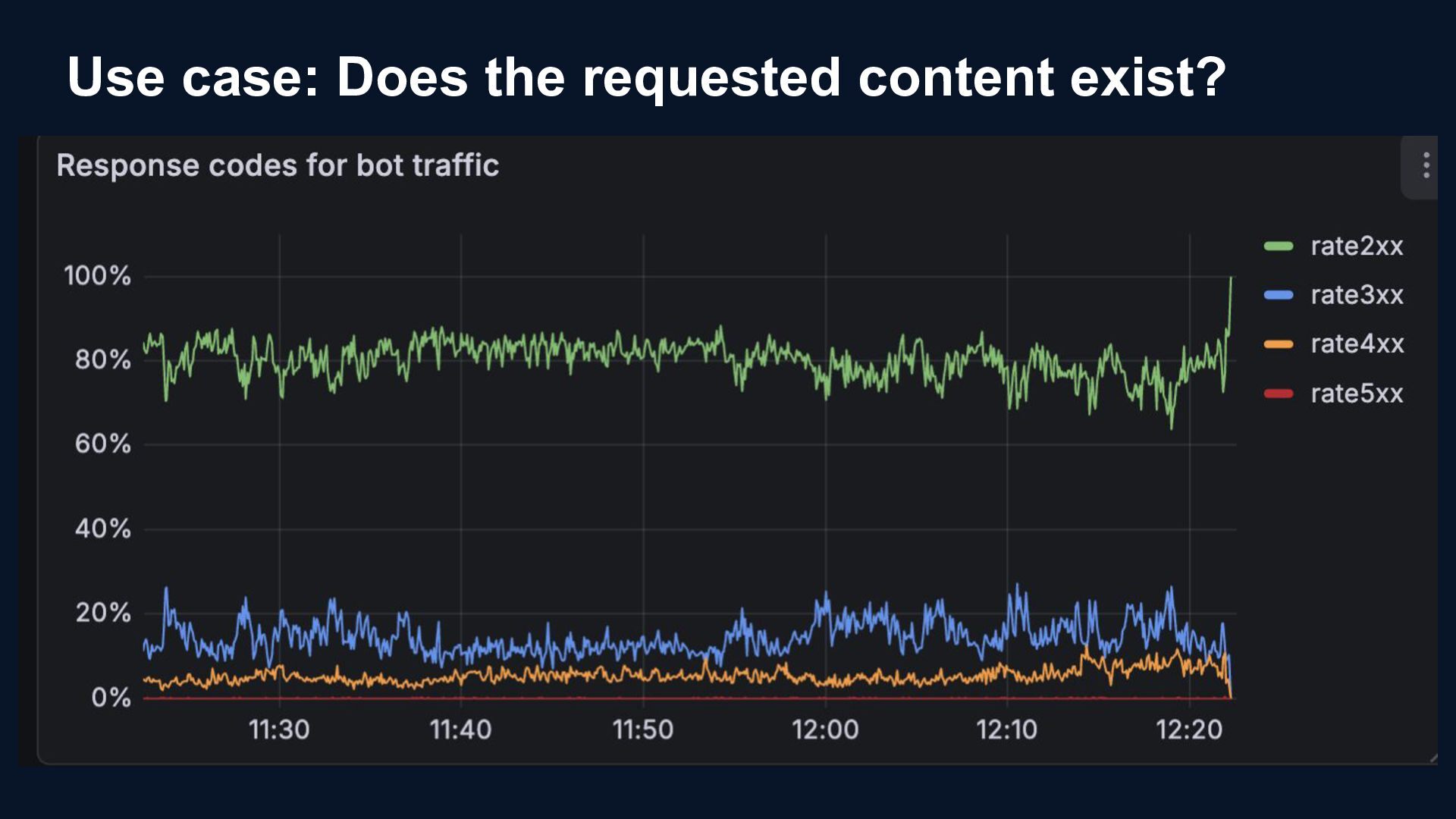{kind=link}
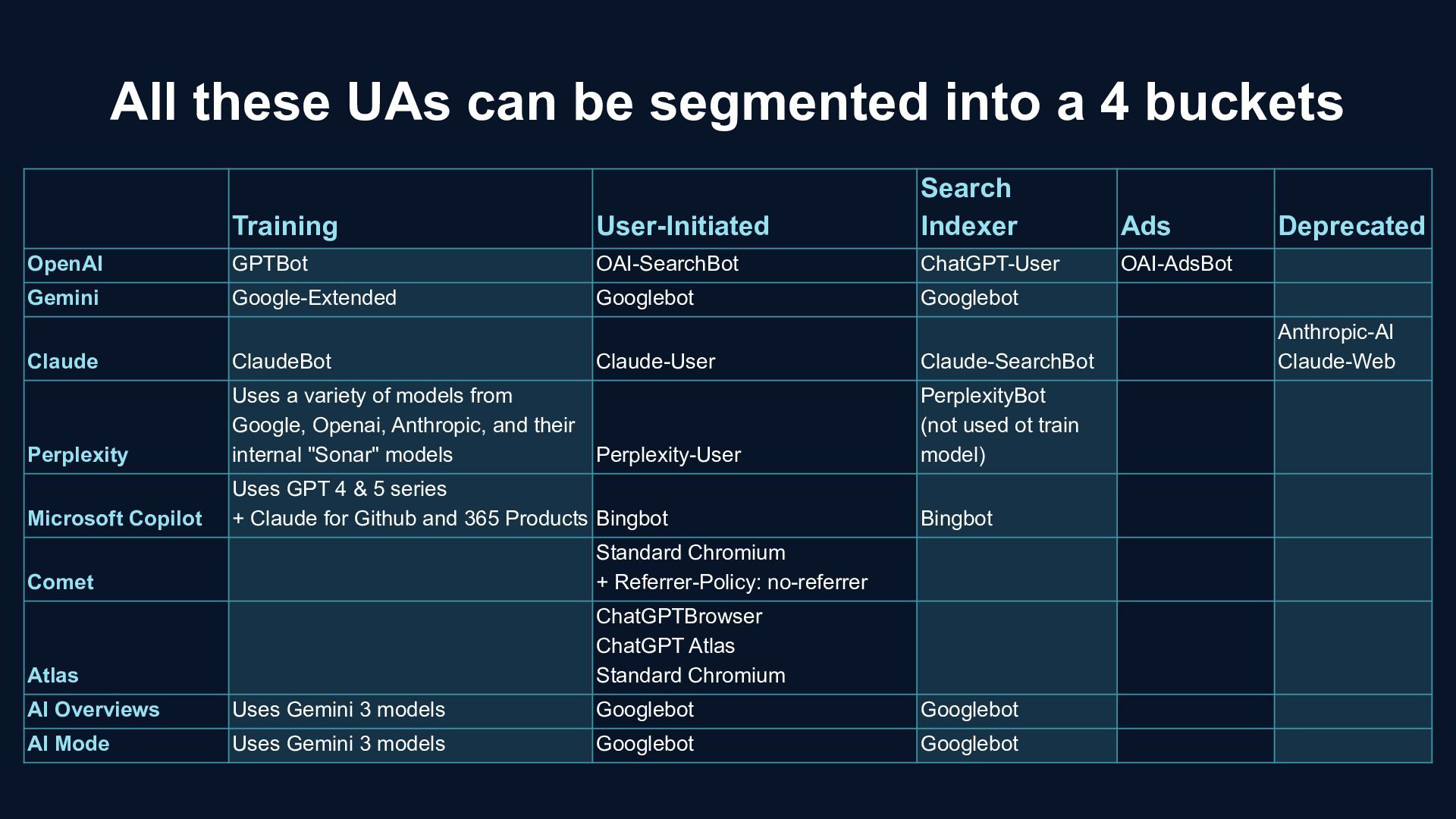{kind=link}
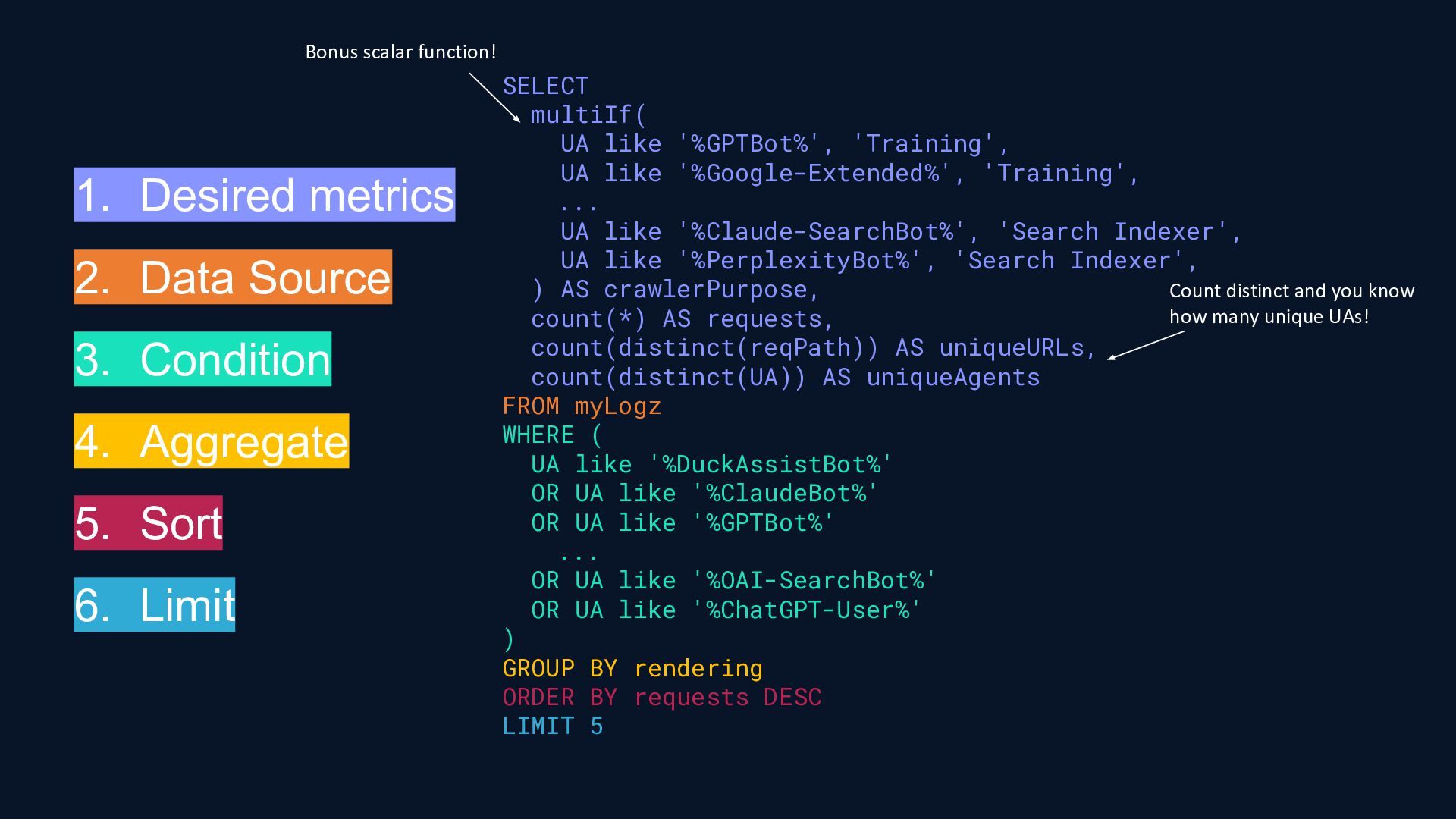{kind=link}
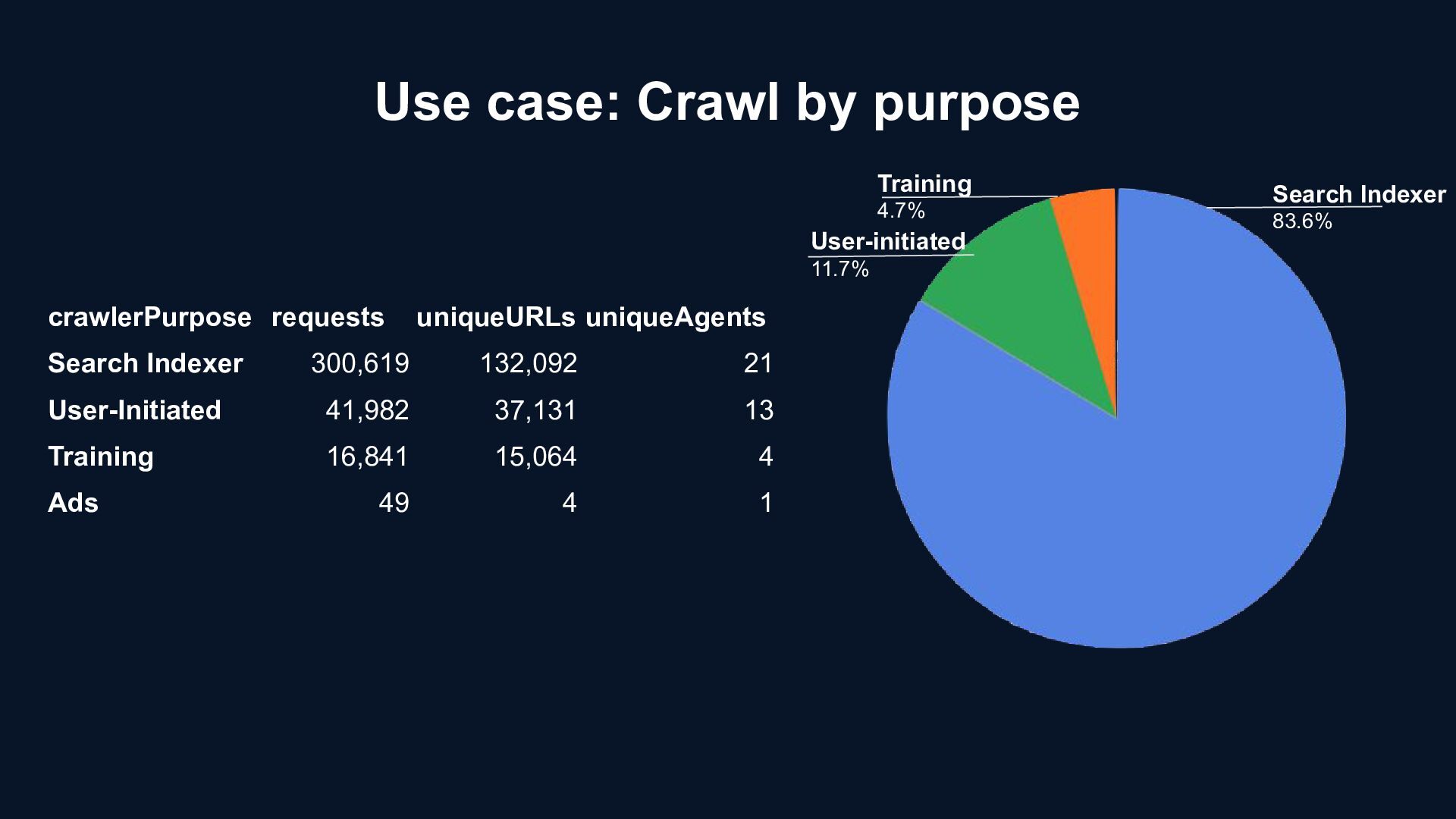{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
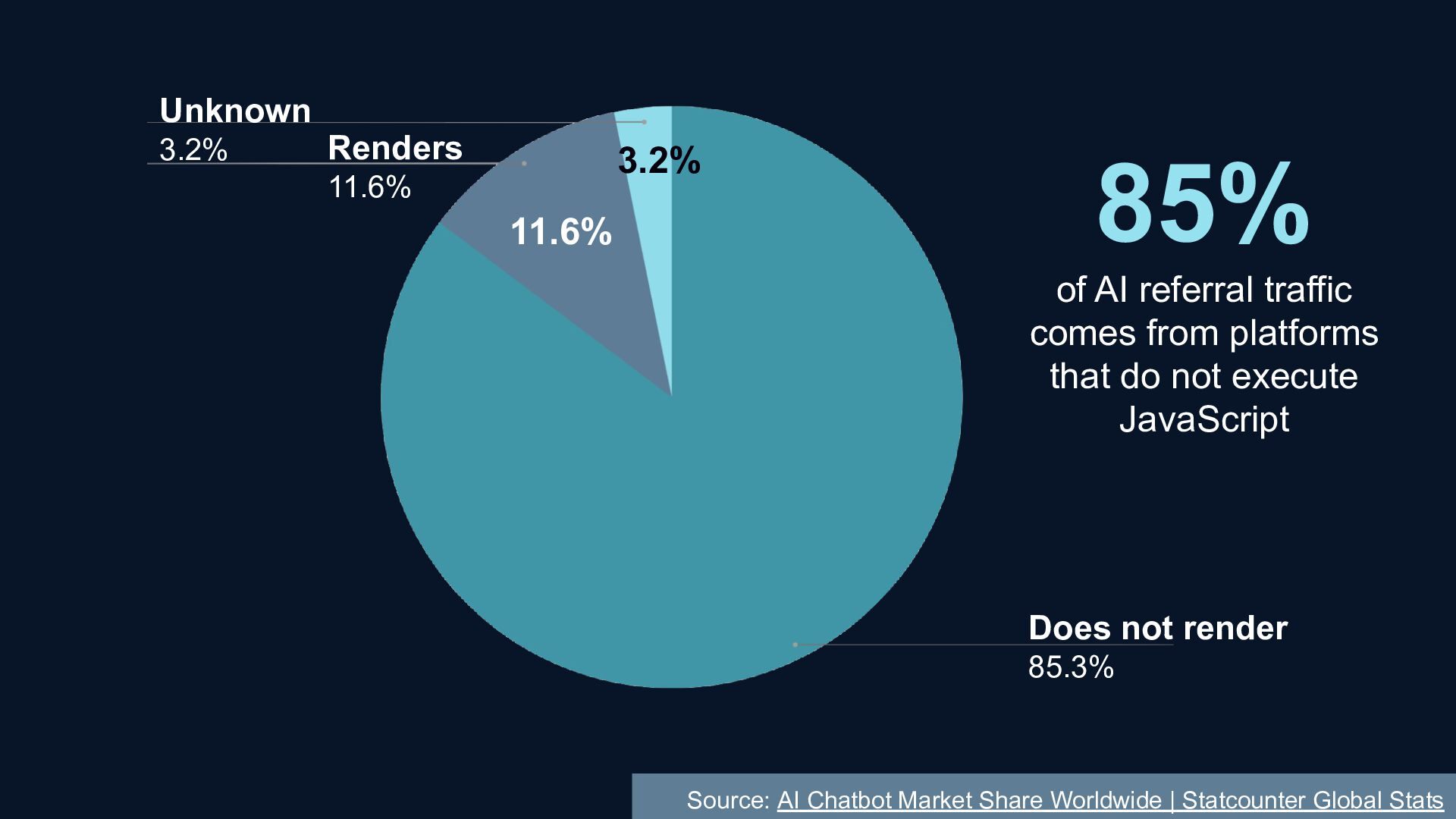{kind=link}
{kind=link}
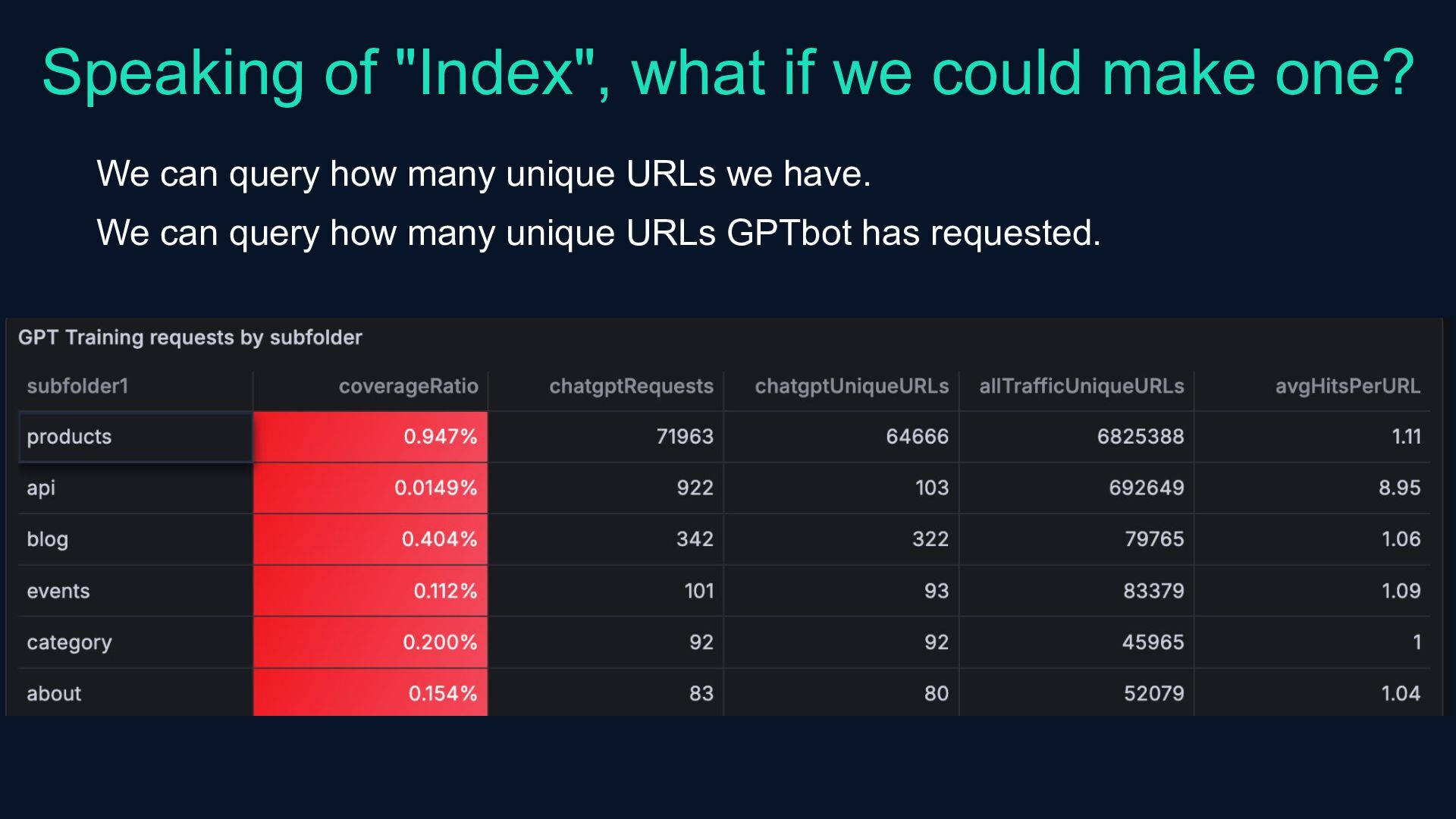{kind=link}
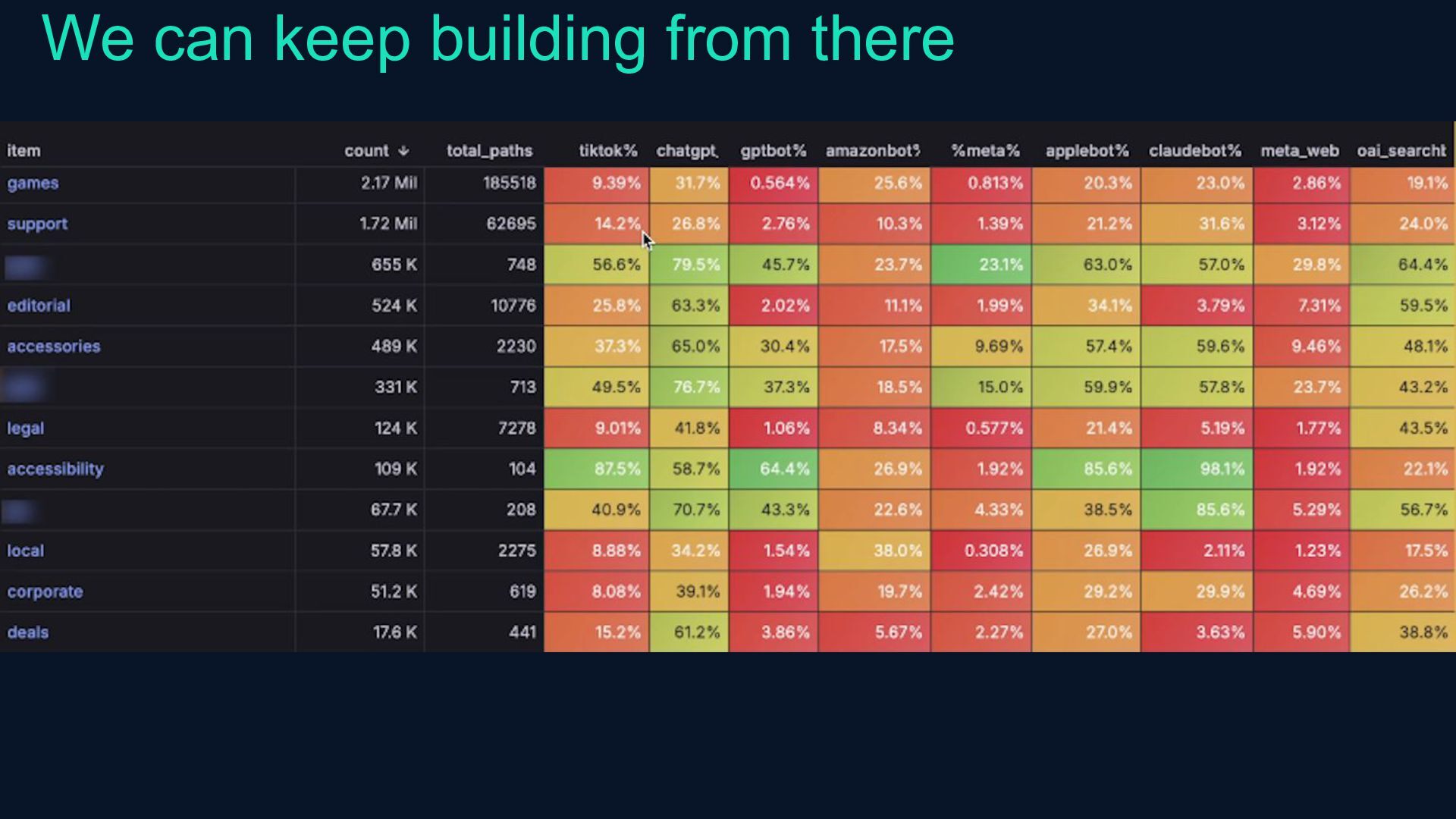{kind=link}
{kind=link}
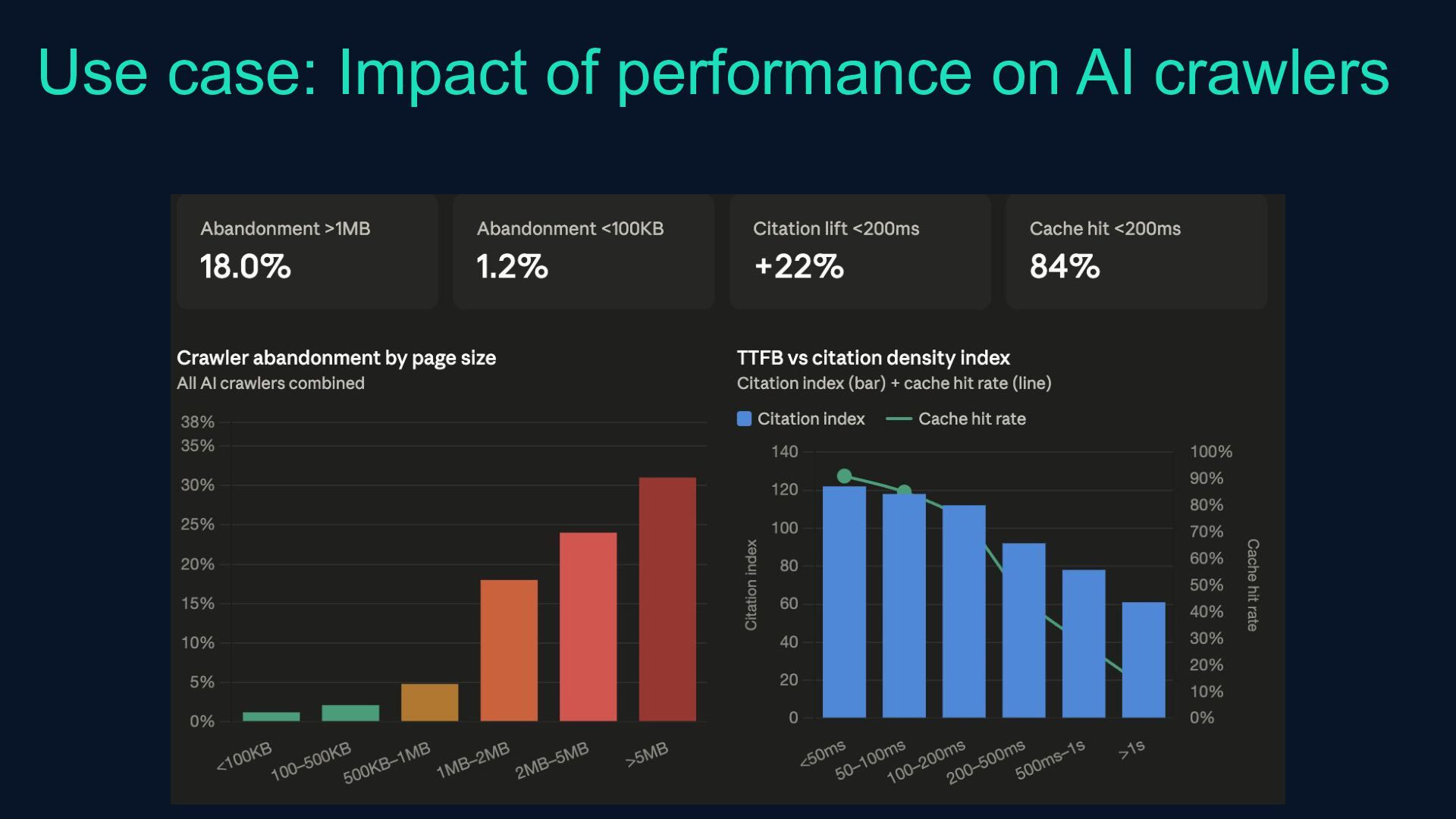{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}