A.Mohamed, Jaitly, N., Senior, A., Vanhoucke, V., Nguyen, P., Sainath, T., and Kingsbury, B. (2012). Deep neural networks for acoustic modeling in speech recognition. IEEE Signal Processing Magazine, 29. Hinton, G., Osindero, S., and Teh, Y.-W. (2006). A fast learning algorithm for deep belief nets. Neural Computation, 18:1527–1554. Le, Q. V., Ranzato, M., Monga, R., Devin, M., Chen, K., Corrado, G. S., Dean, J., and Ng, A. Y. (2012). Building high-level features using large scale unsupervised learning. In ICML. 45/47
{kind=link}
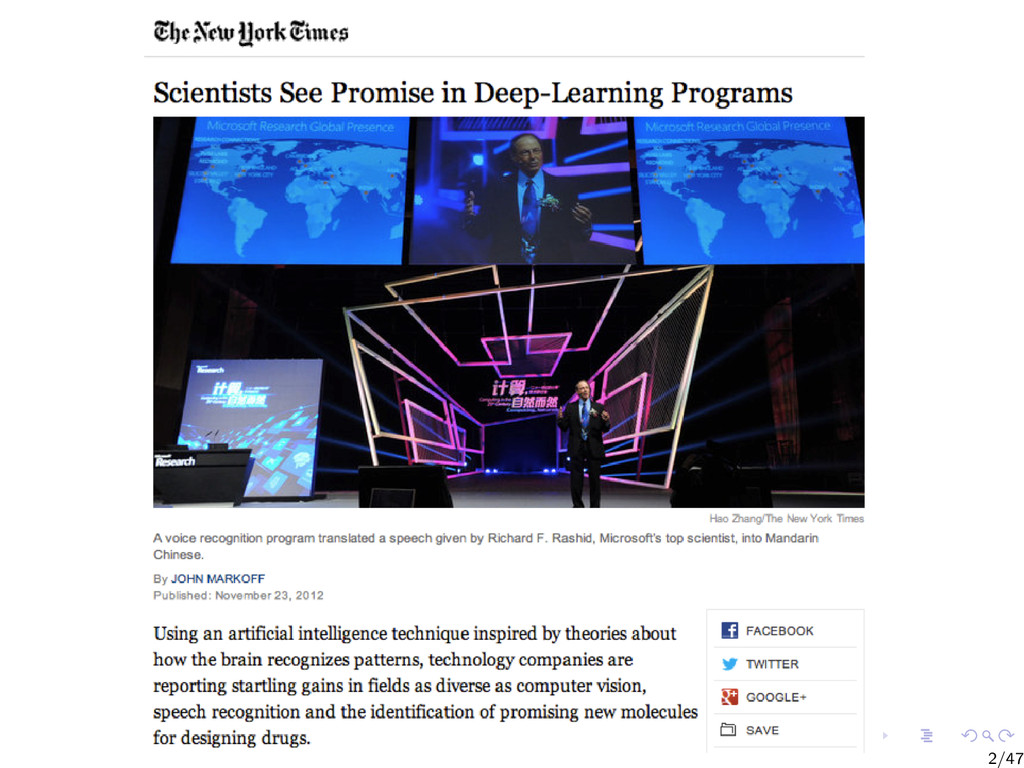{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
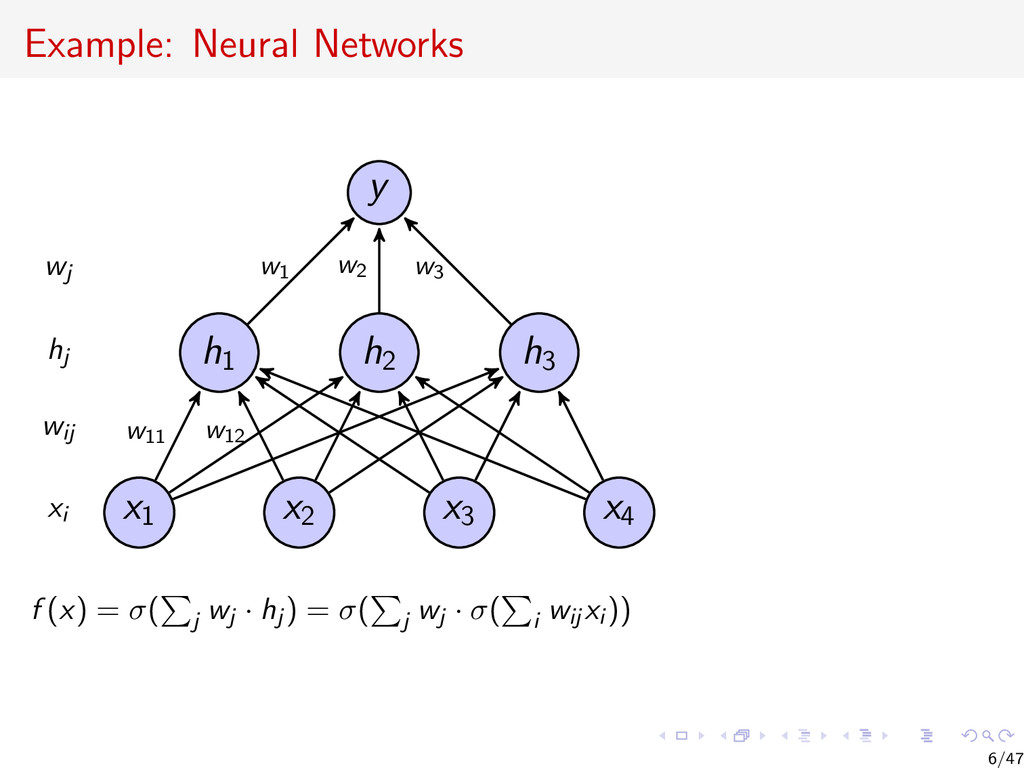{kind=link}
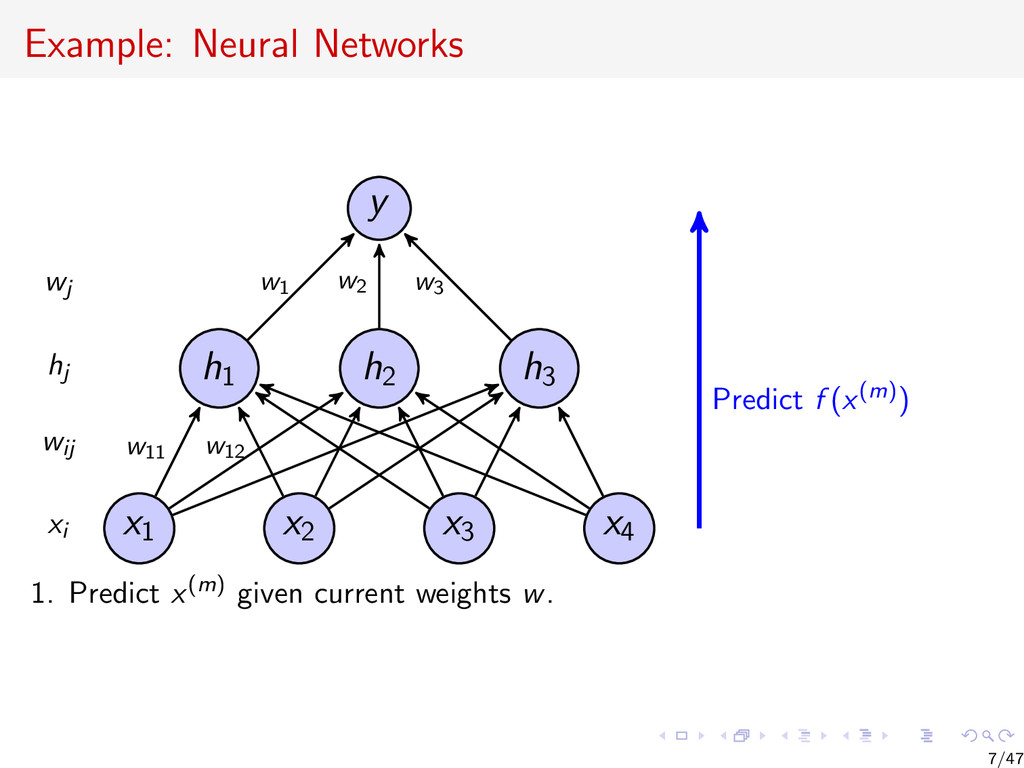{kind=link}
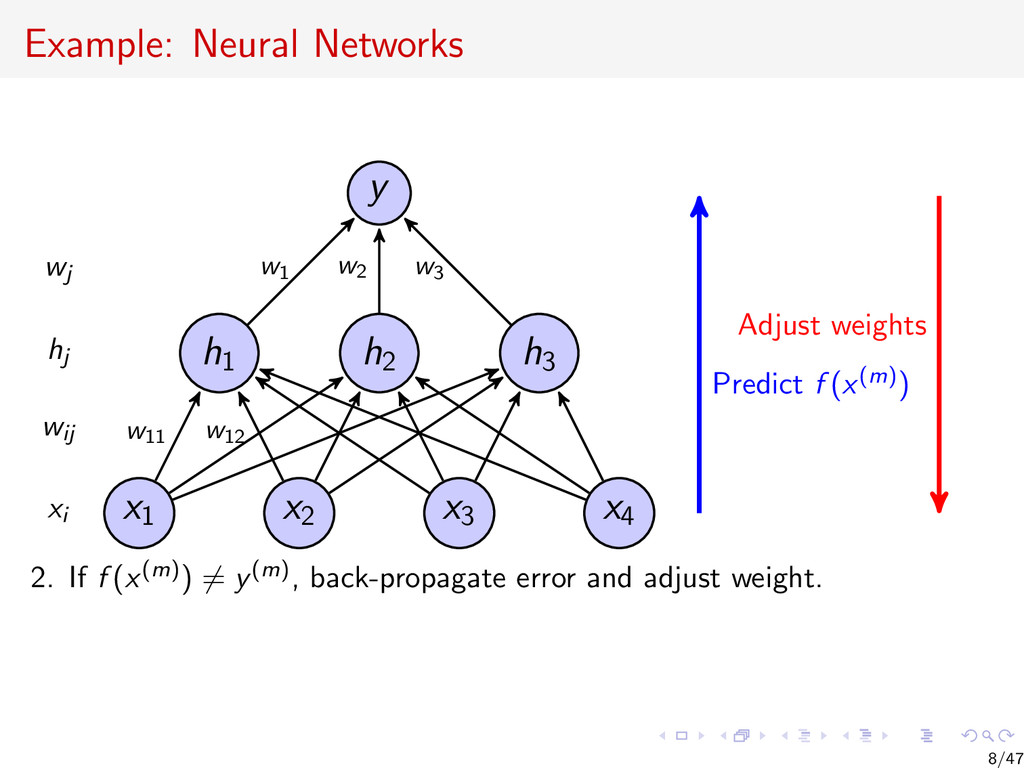{kind=link}
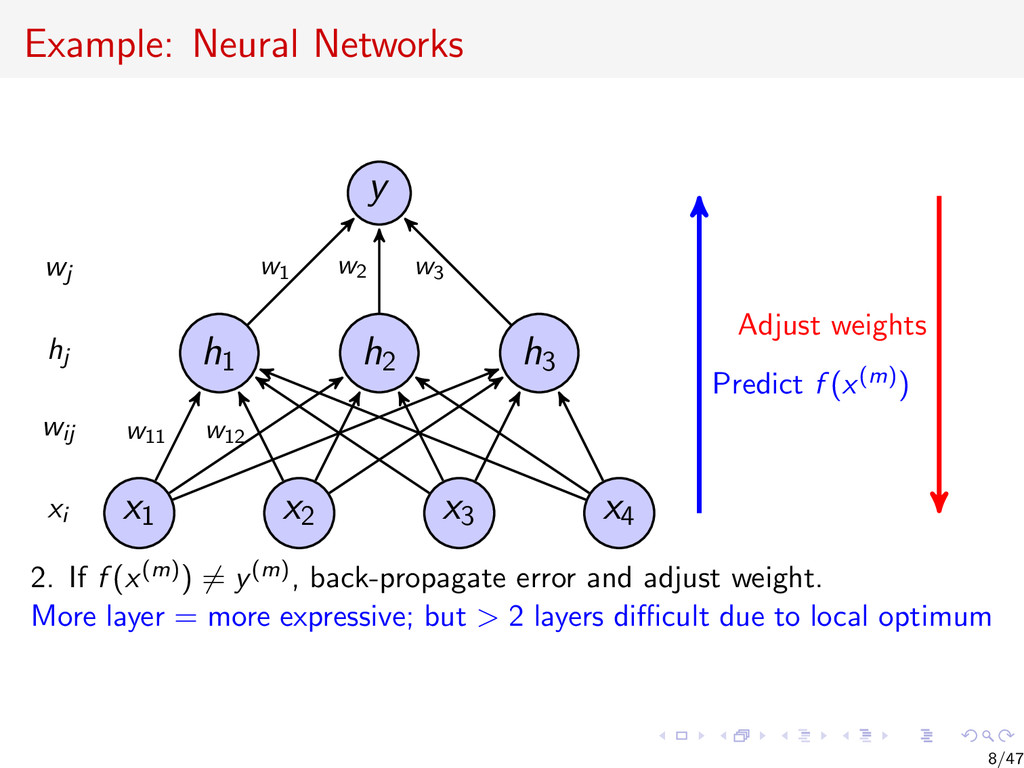{kind=link}
{kind=link}
{kind=link}
{kind=link}
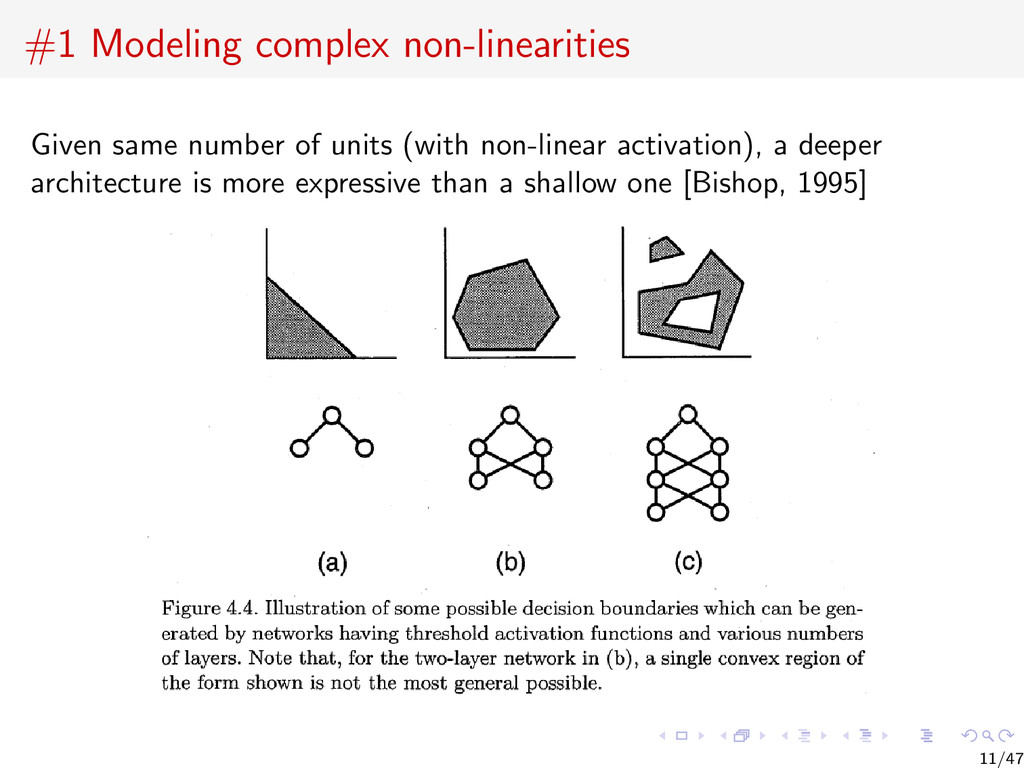{kind=link}
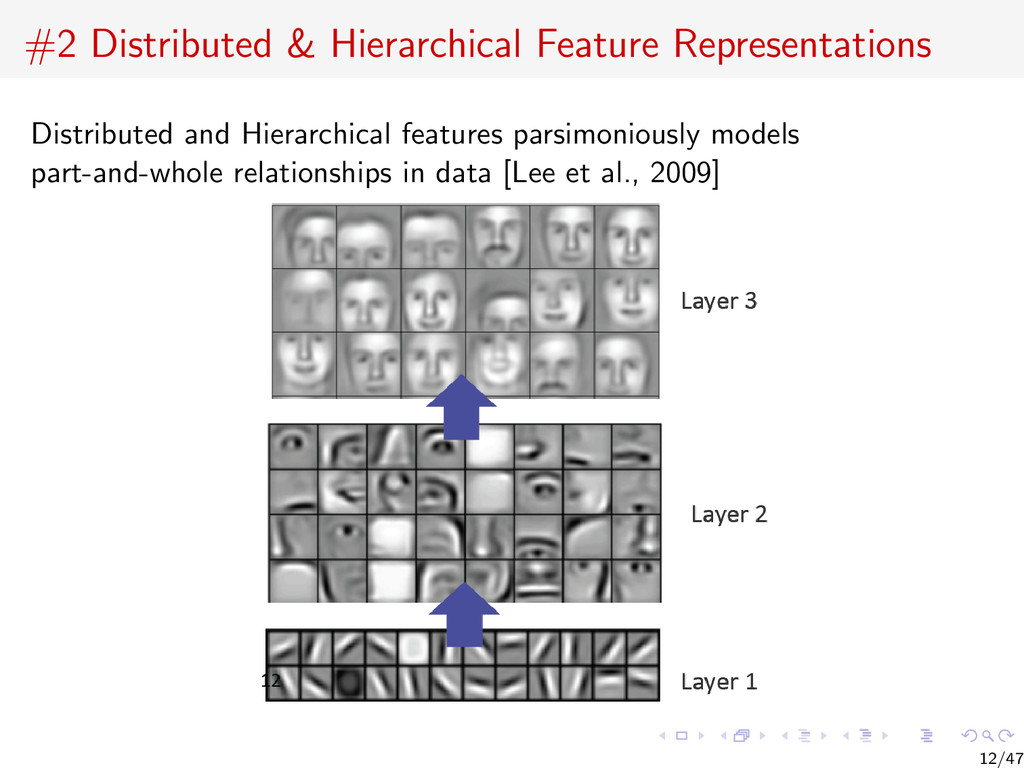{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
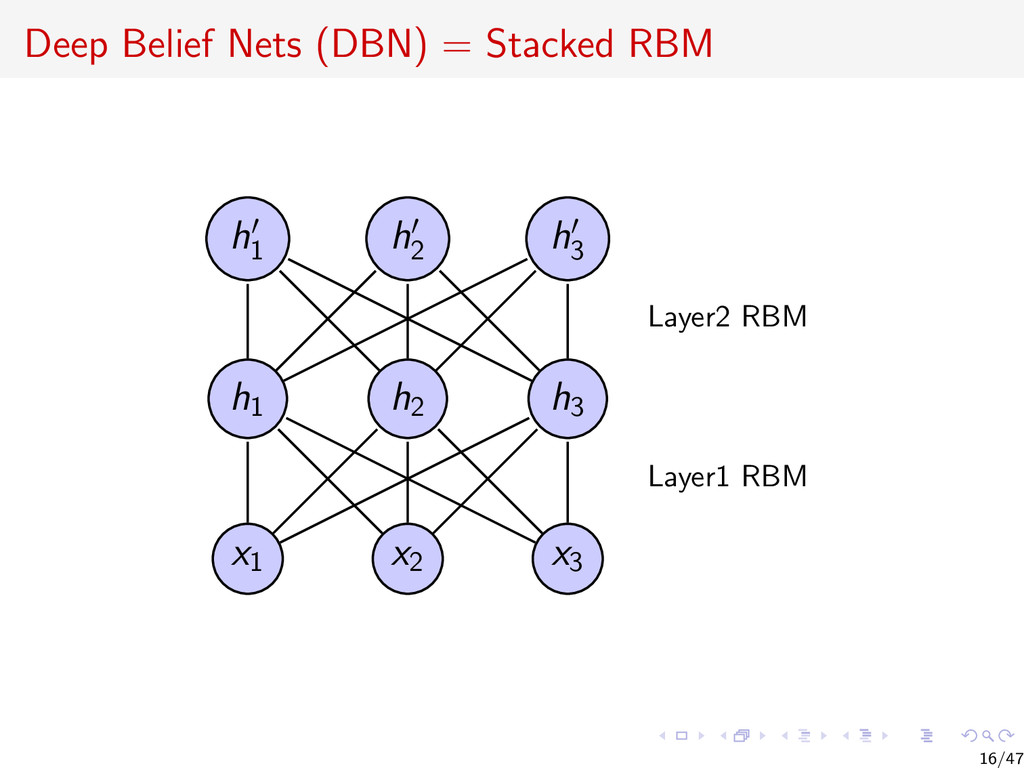{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
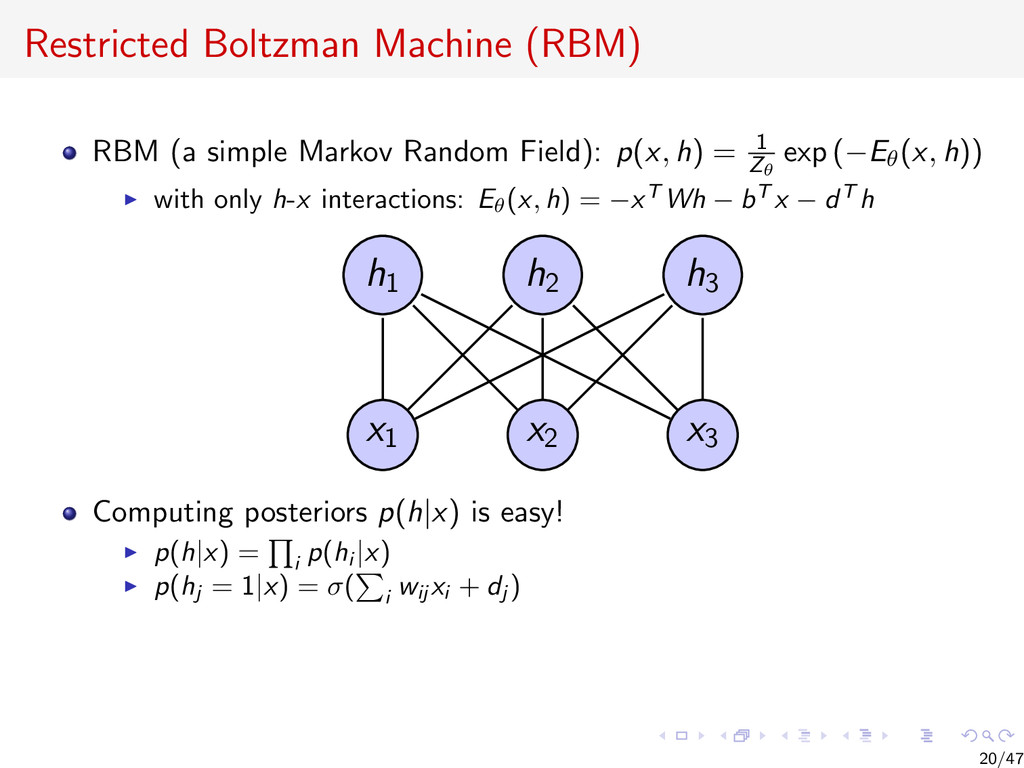{kind=link}
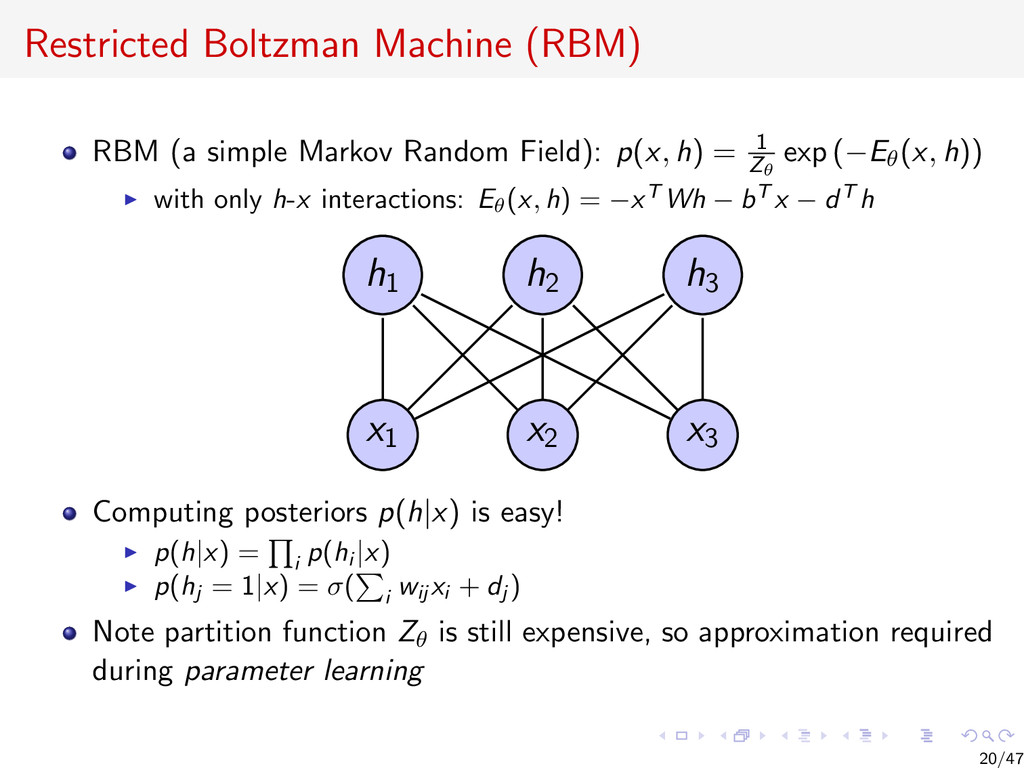{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
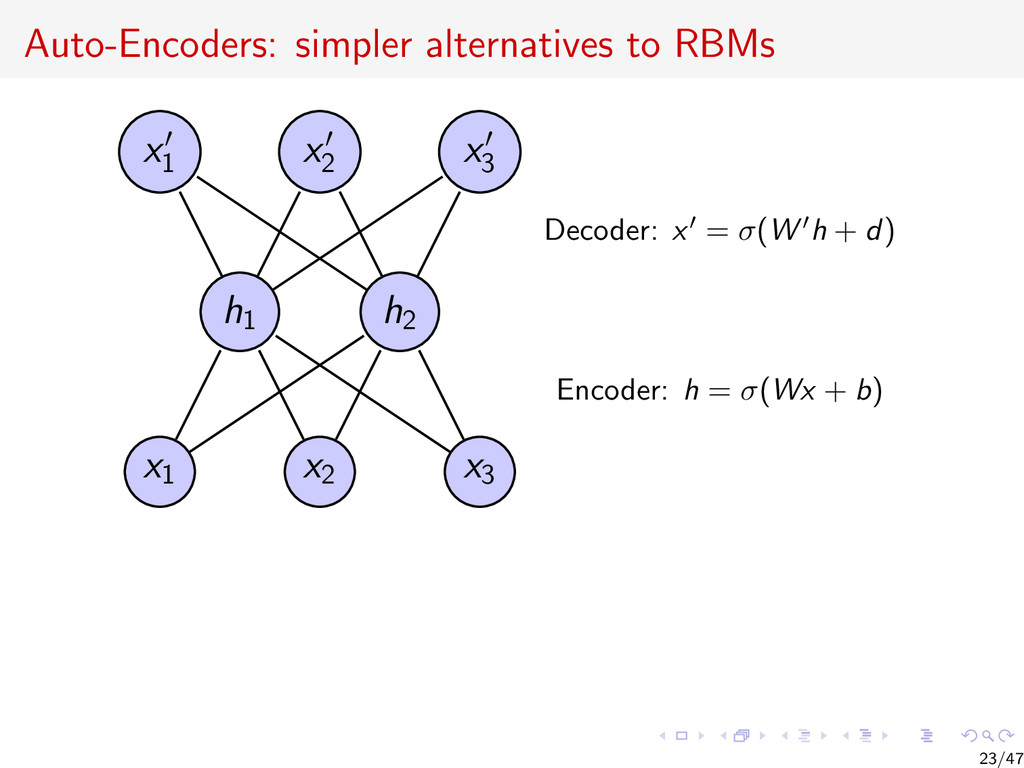{kind=link}
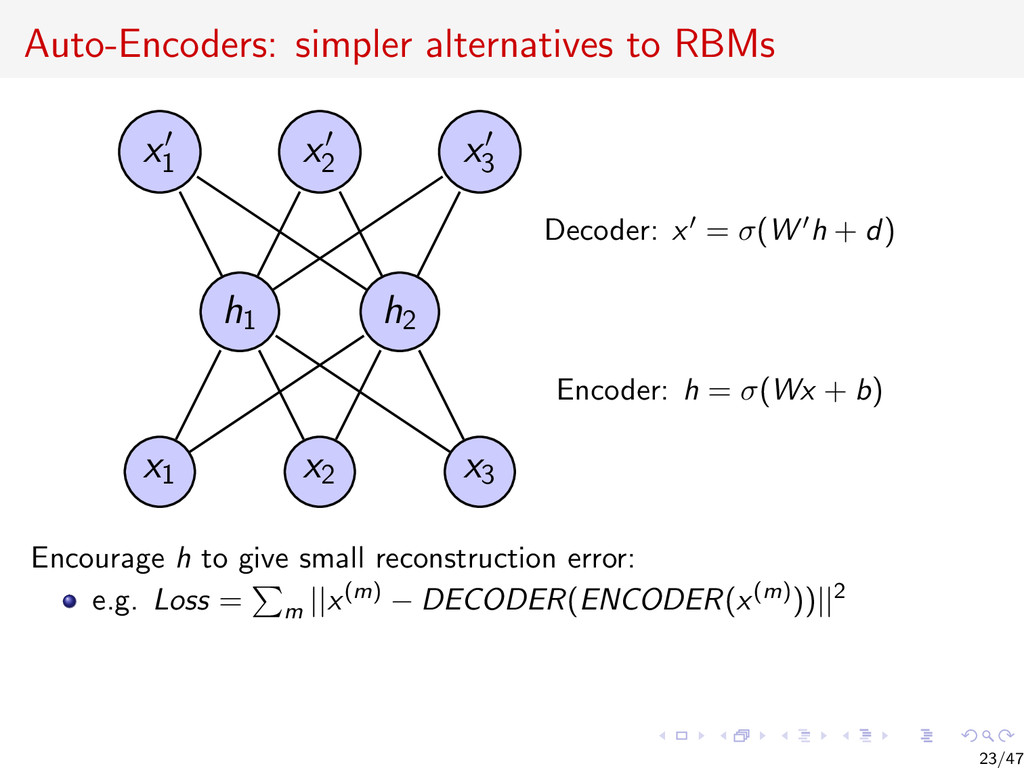{kind=link}
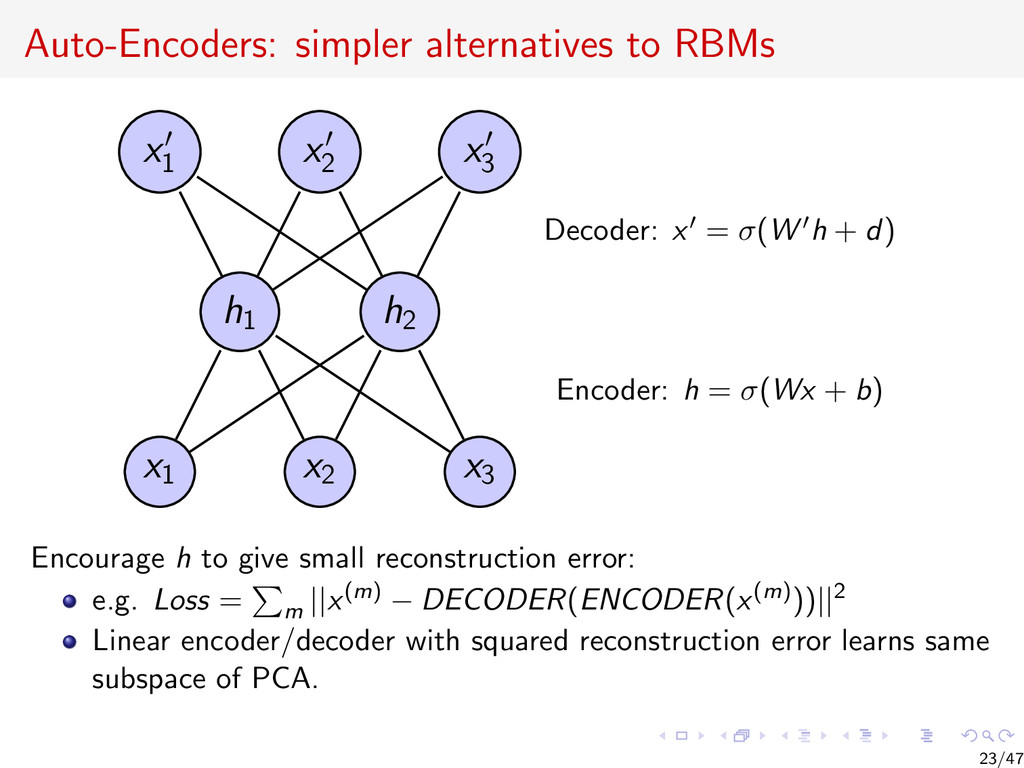{kind=link}
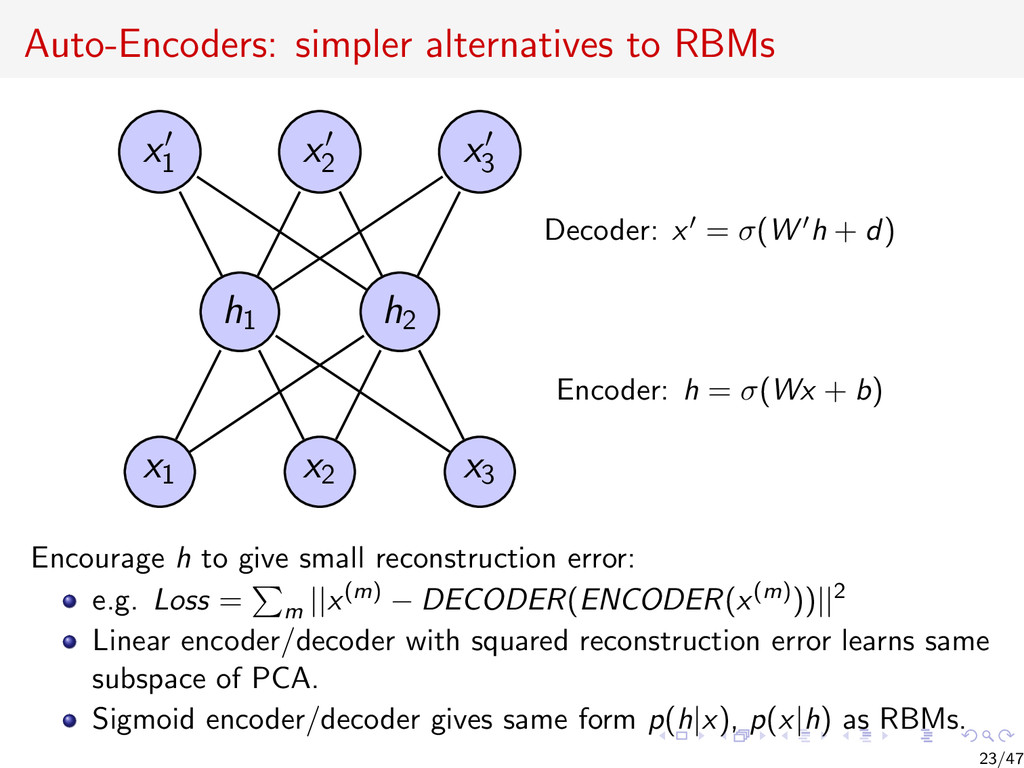{kind=link}
{kind=link}
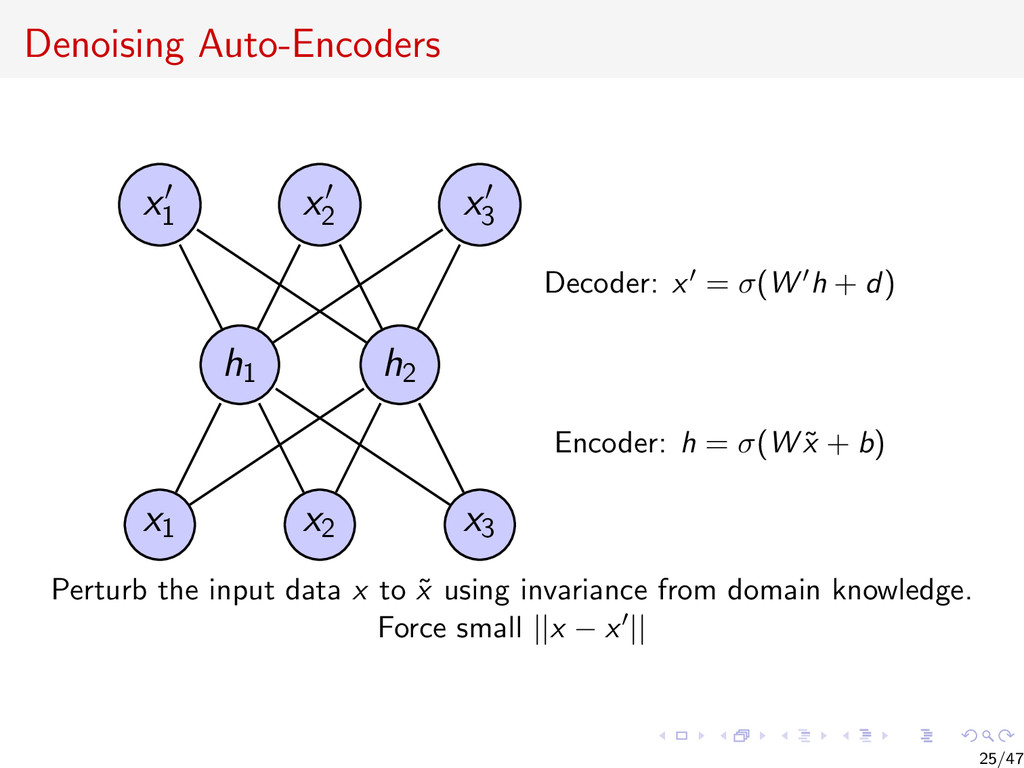{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
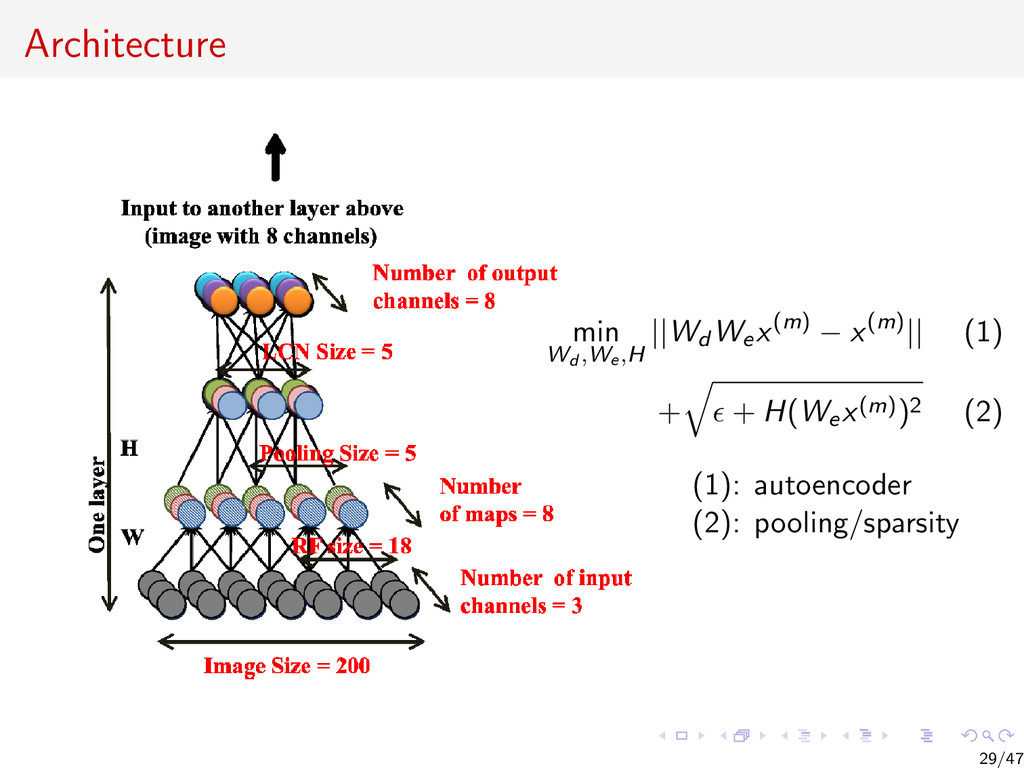{kind=link}
![Face neuron *Graphics from [Le et al., 2012] 30/47](https://files.speakerdeck.com/presentations/5a5f1e80bad5013074fc1e4bd209964e/slide_48.jpg){kind=link}
![Face neuron *Graphics from [Le et al., 2012] 31/47](https://files.speakerdeck.com/presentations/5a5f1e80bad5013074fc1e4bd209964e/slide_49.jpg){kind=link}
![Cat neuron *Graphics from [Le et al., 2012] 32/47](https://files.speakerdeck.com/presentations/5a5f1e80bad5013074fc1e4bd209964e/slide_50.jpg){kind=link}
![More examples *Graphics from [Le et al., 2012] 33/47](https://files.speakerdeck.com/presentations/5a5f1e80bad5013074fc1e4bd209964e/slide_51.jpg){kind=link}
![More examples *Graphics from [Le et al., 2012] 34/47](https://files.speakerdeck.com/presentations/5a5f1e80bad5013074fc1e4bd209964e/slide_52.jpg){kind=link}
![More examples *Graphics from [Le et al., 2012] 35/47](https://files.speakerdeck.com/presentations/5a5f1e80bad5013074fc1e4bd209964e/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
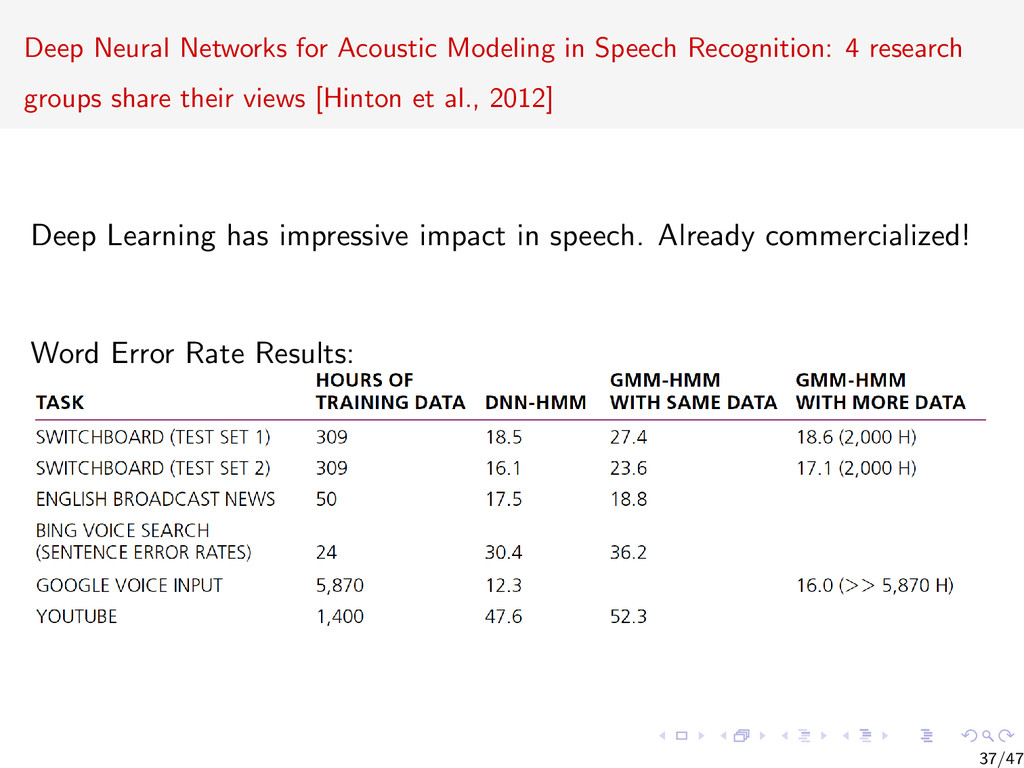{kind=link}
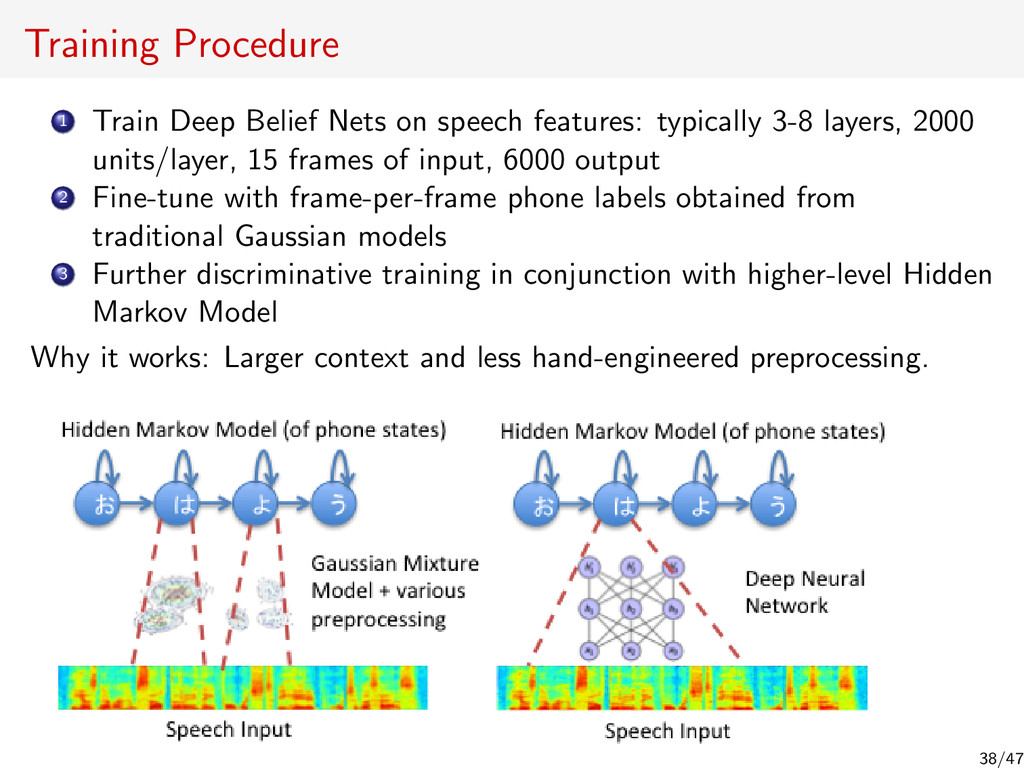{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
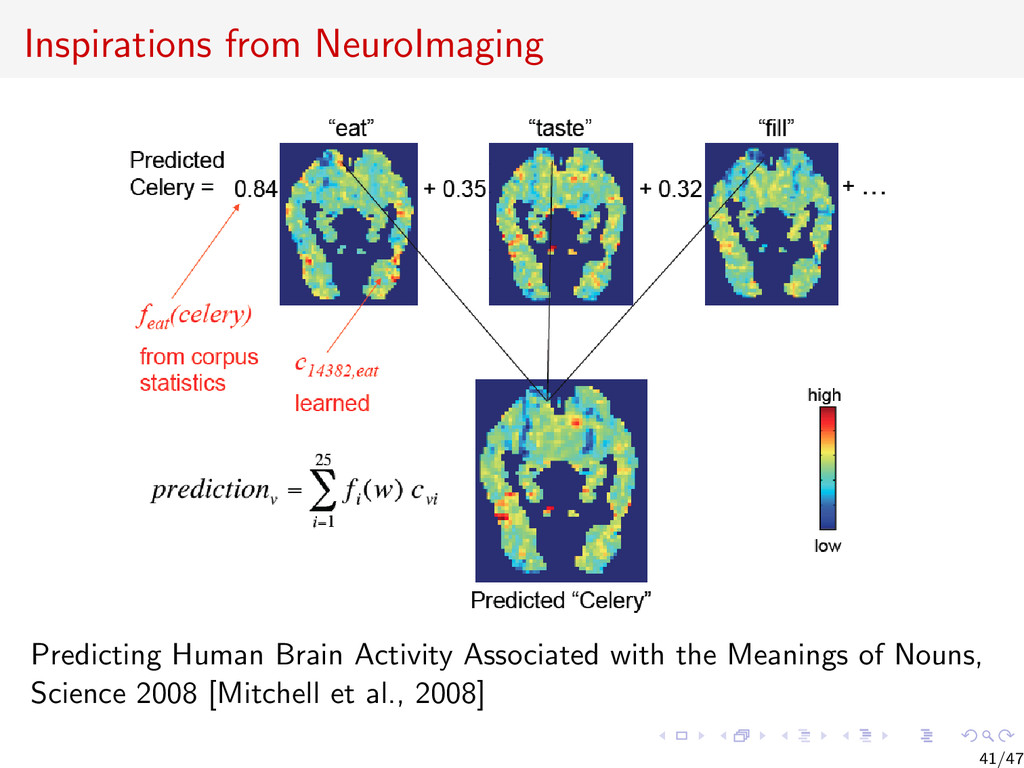{kind=link}
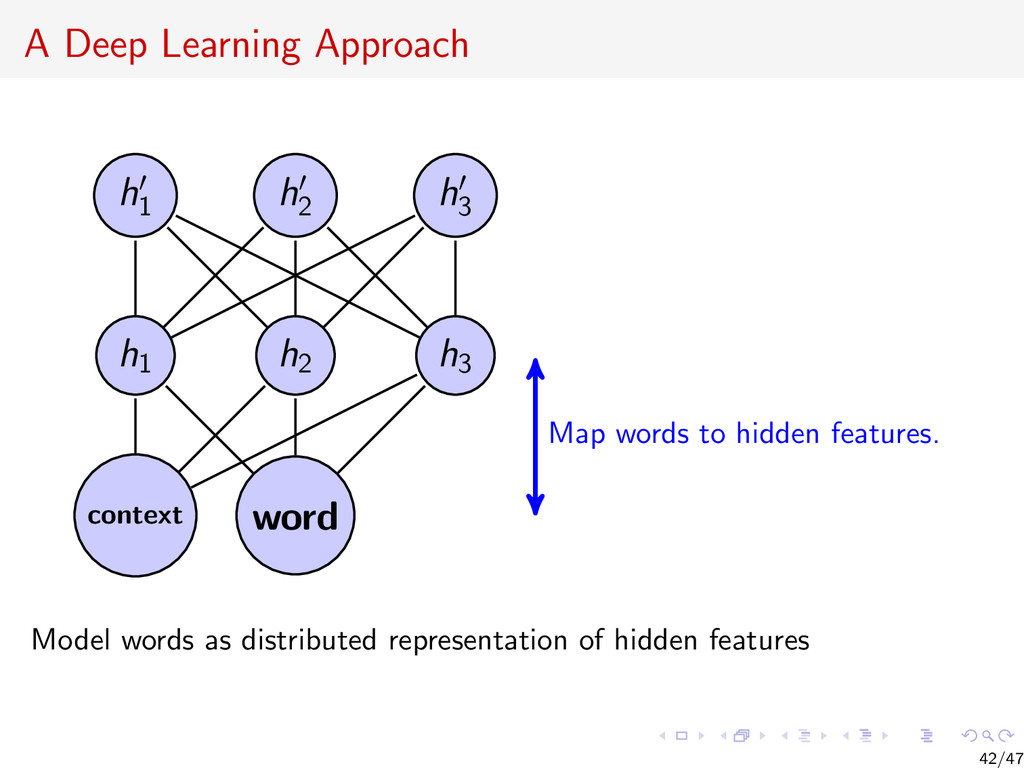{kind=link}
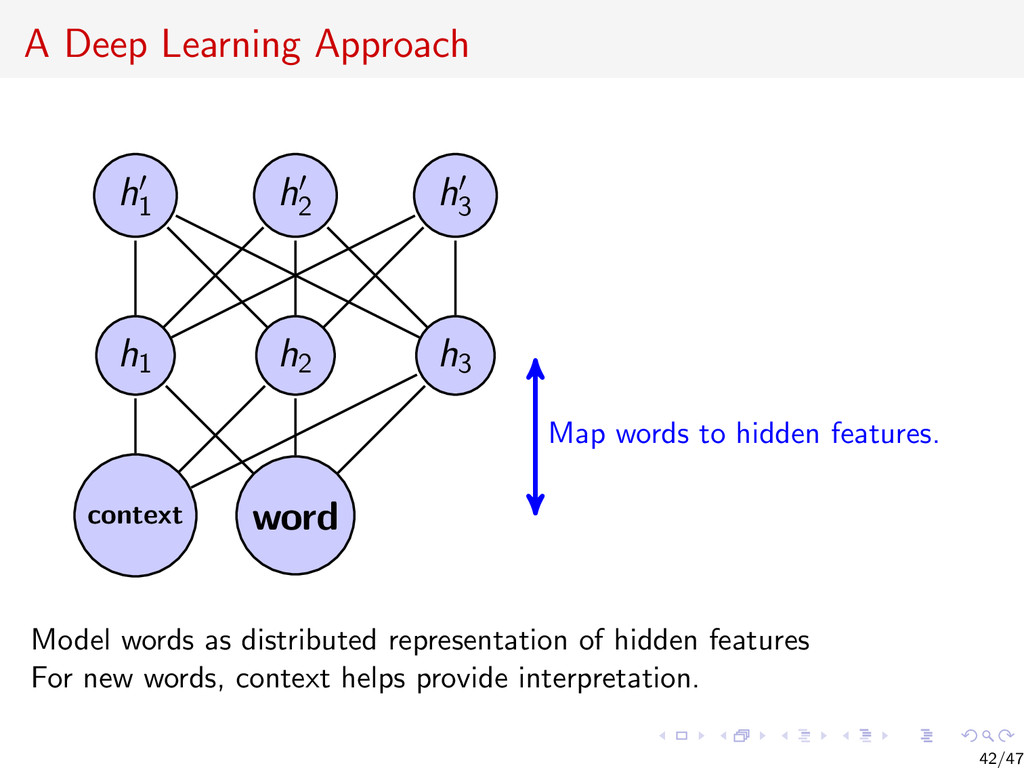{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}