Spark Streaming has supported Kafka since it’s inception, but a lot has changed since those times, both in Spark and Kafka sides, to make this integration more fault-tolerant and reliable.
https://www.bigdataspain.org/2017/talk/spark-streaming-kafka-0-10-an-integration-story
Big Data Spain 2017
16th - 17th Kinépolis Madrid
{kind=link}
{kind=link}
![About me Joan Viladrosa Riera @joanvr joanviladrosa [email protected] 2 #EUstr5](https://files.speakerdeck.com/presentations/e7a53a96b58b4b34ad677bcac60443ab/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
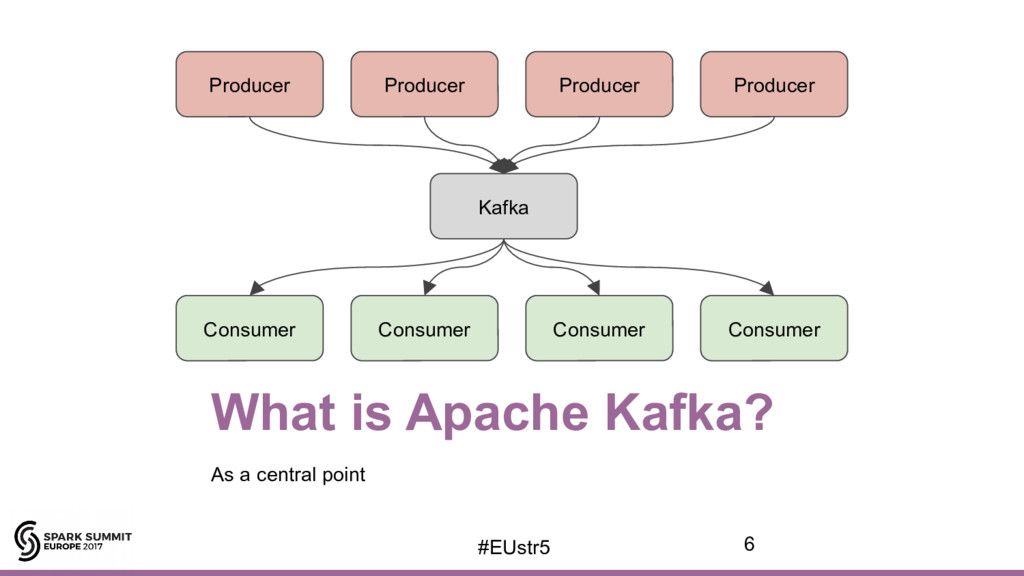{kind=link}
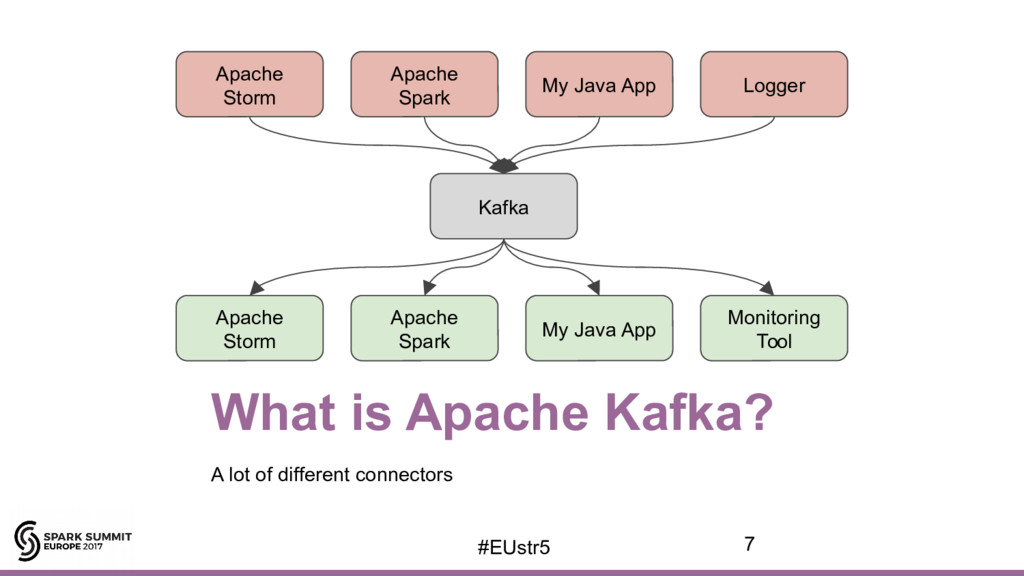{kind=link}
{kind=link}
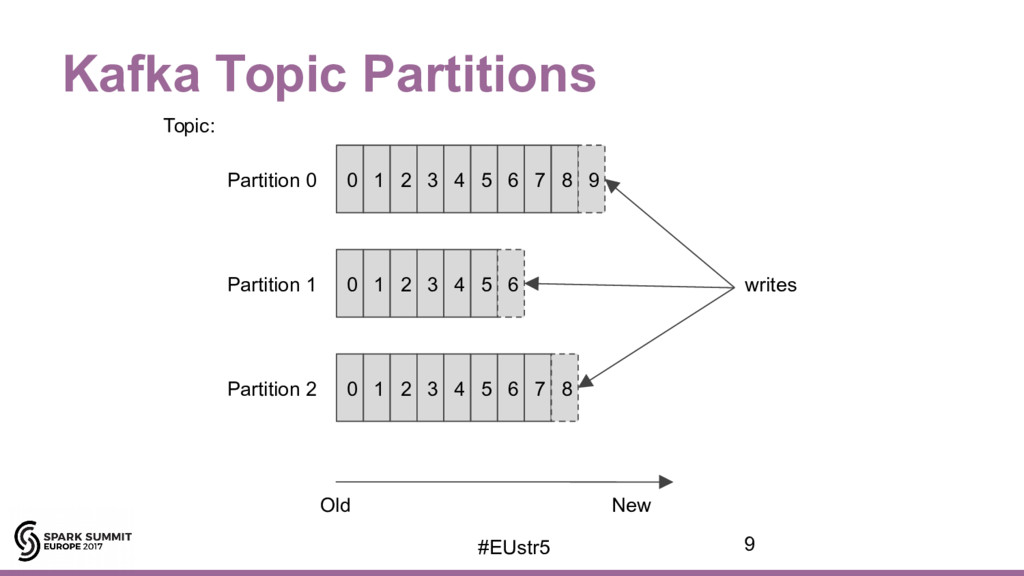{kind=link}
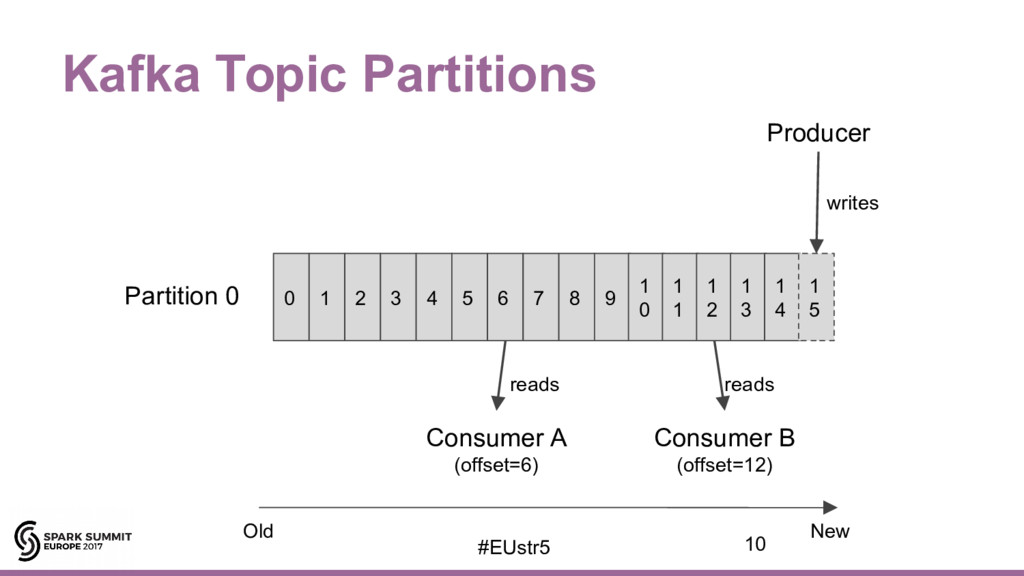{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
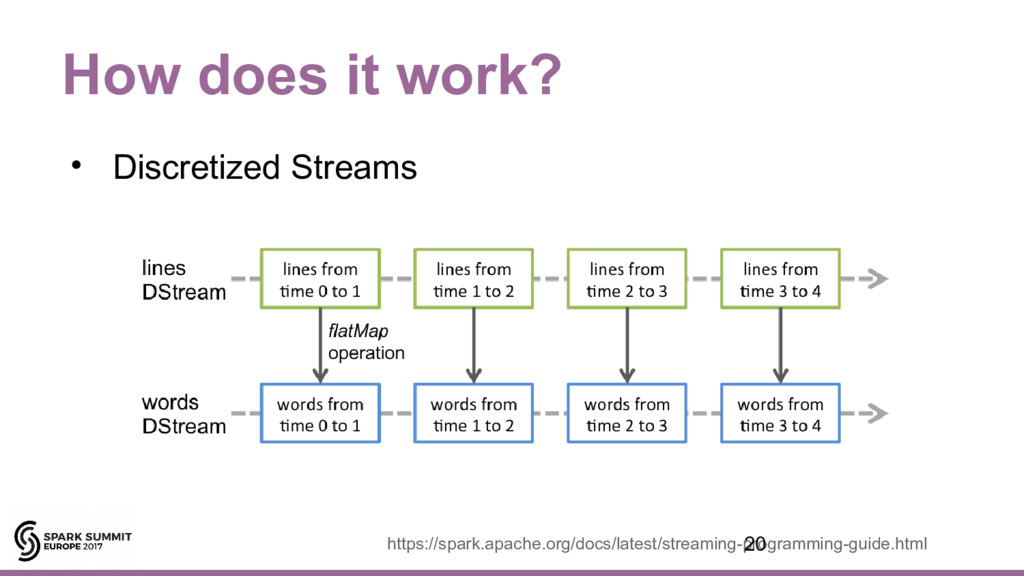{kind=link}
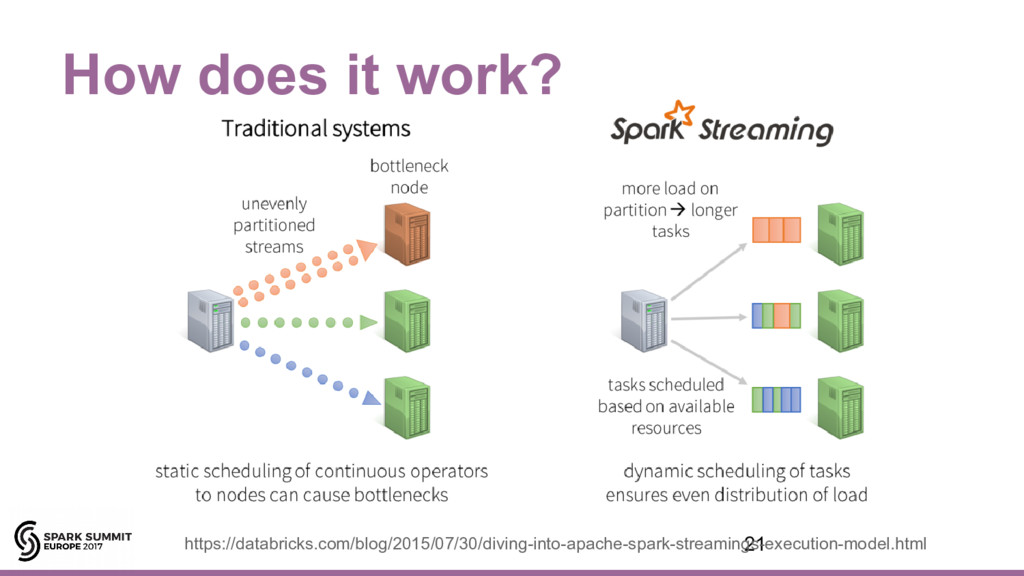{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
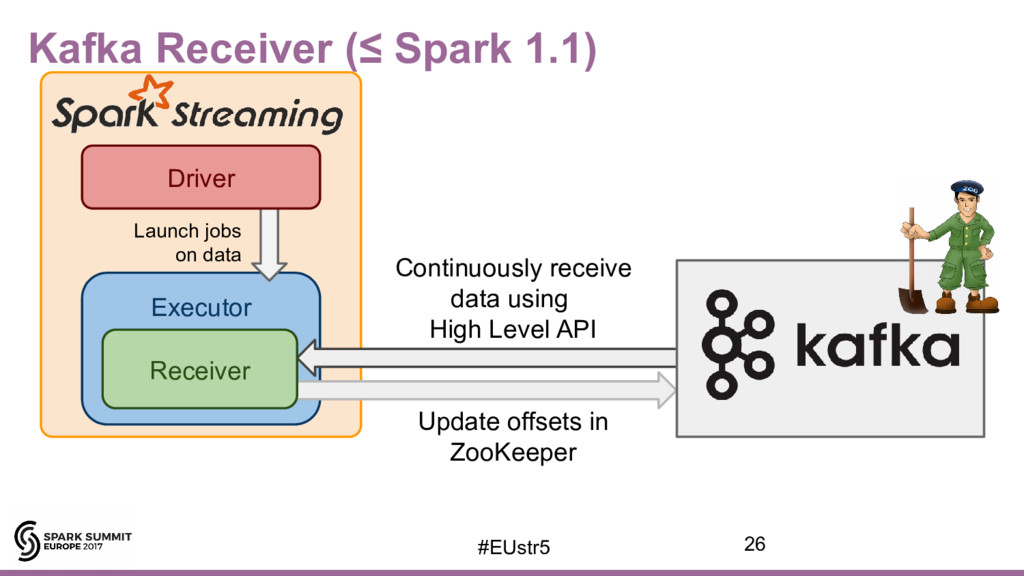{kind=link}
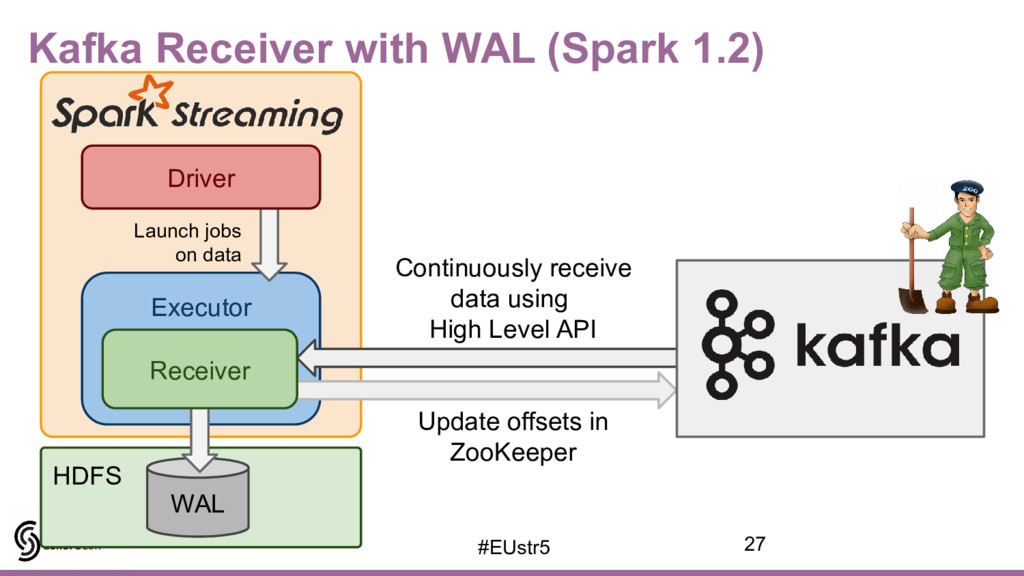{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
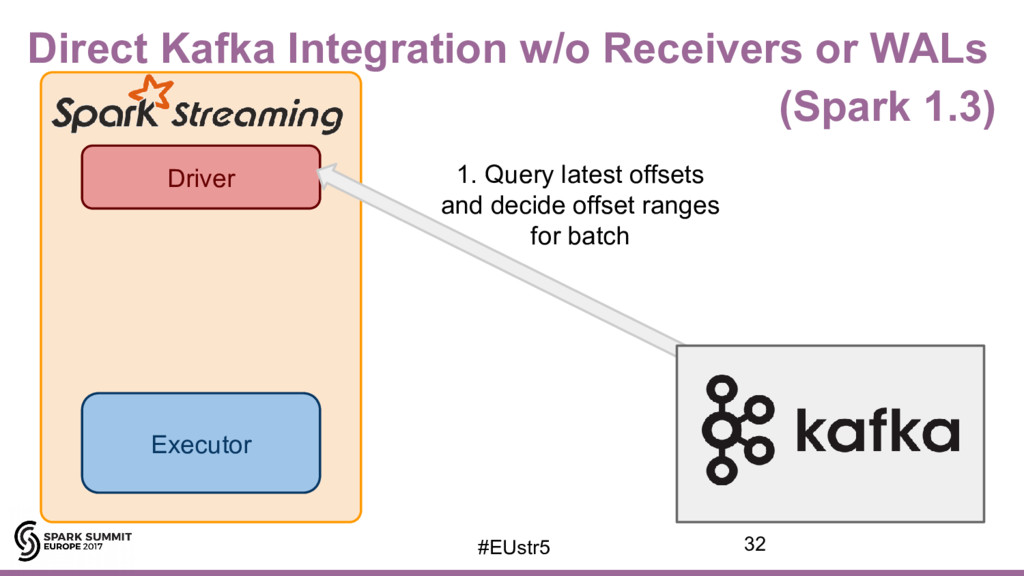{kind=link}
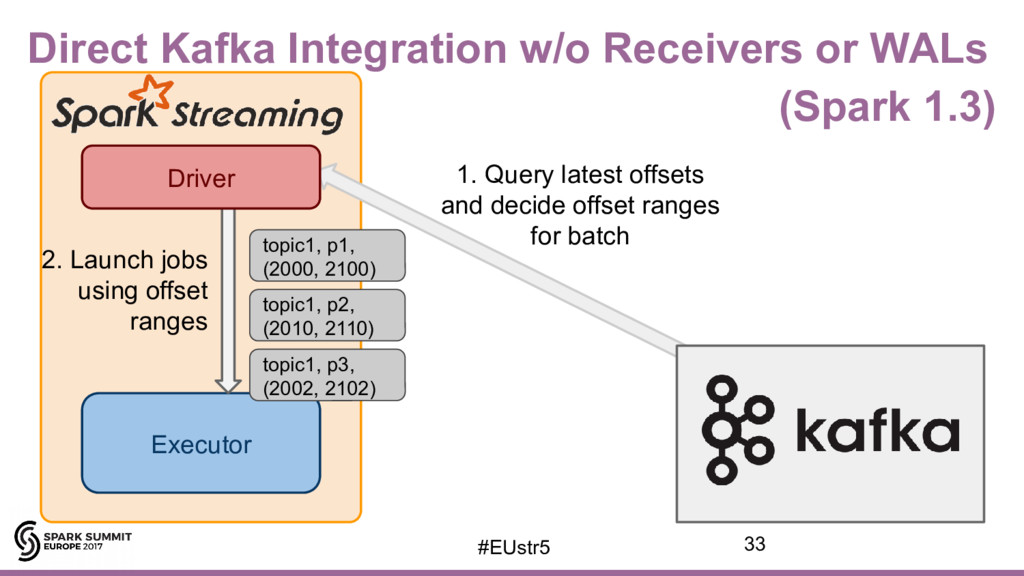{kind=link}
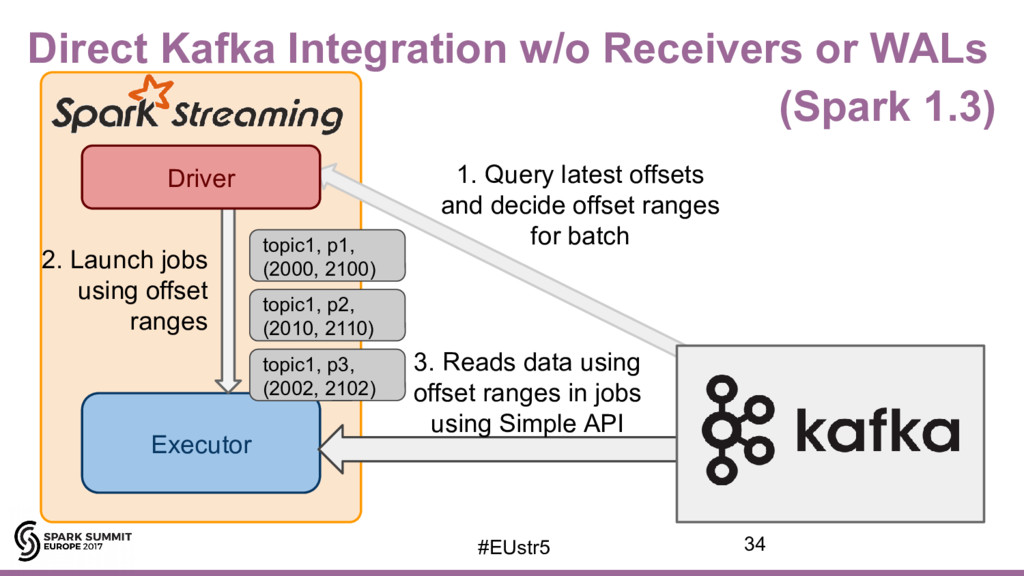{kind=link}
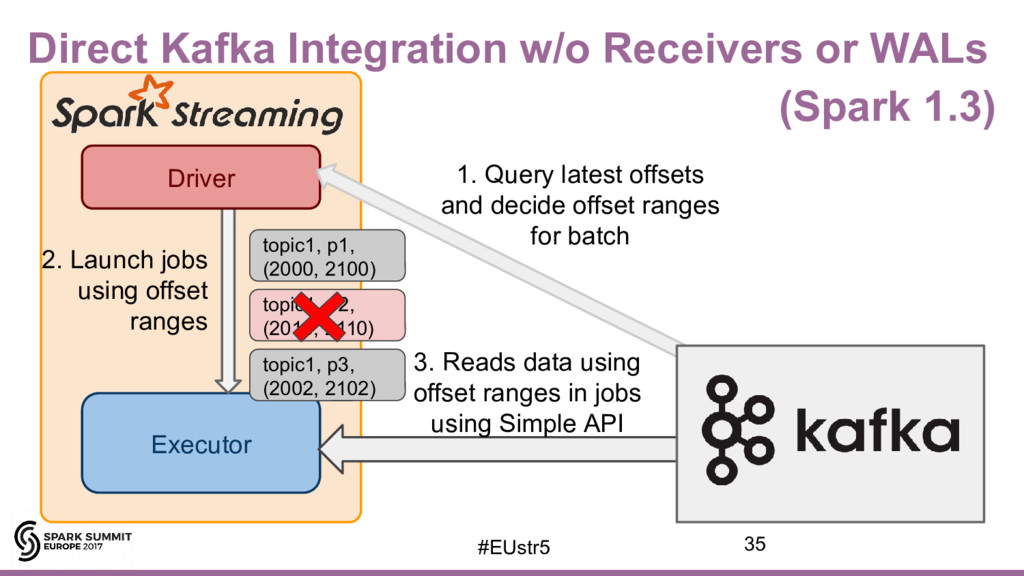{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
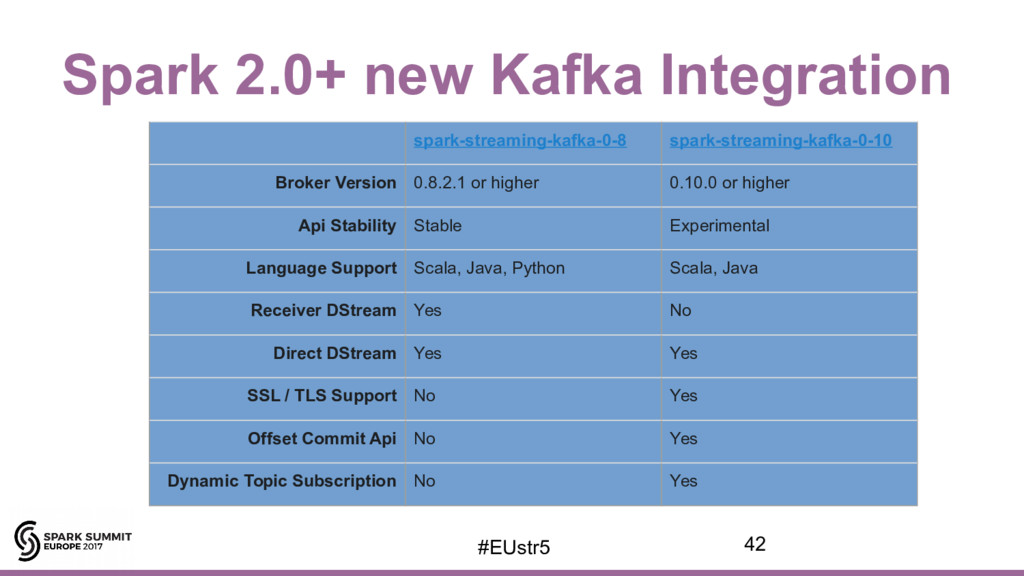{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
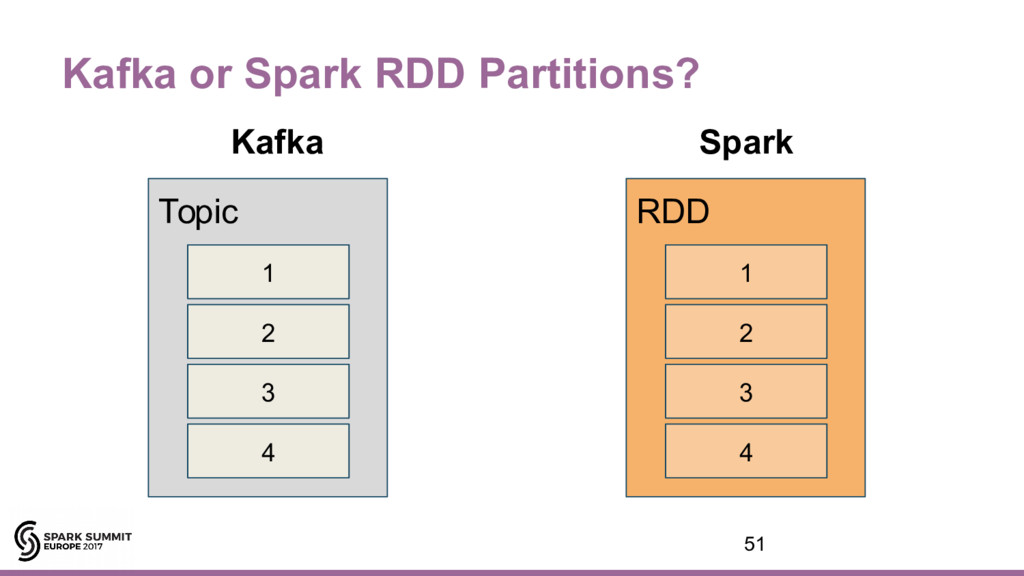{kind=link}
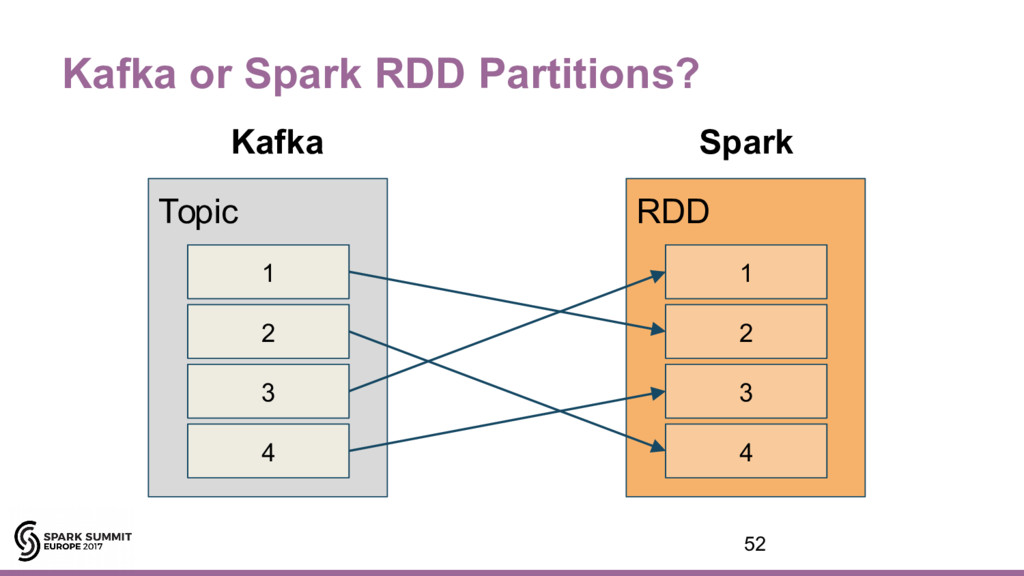{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
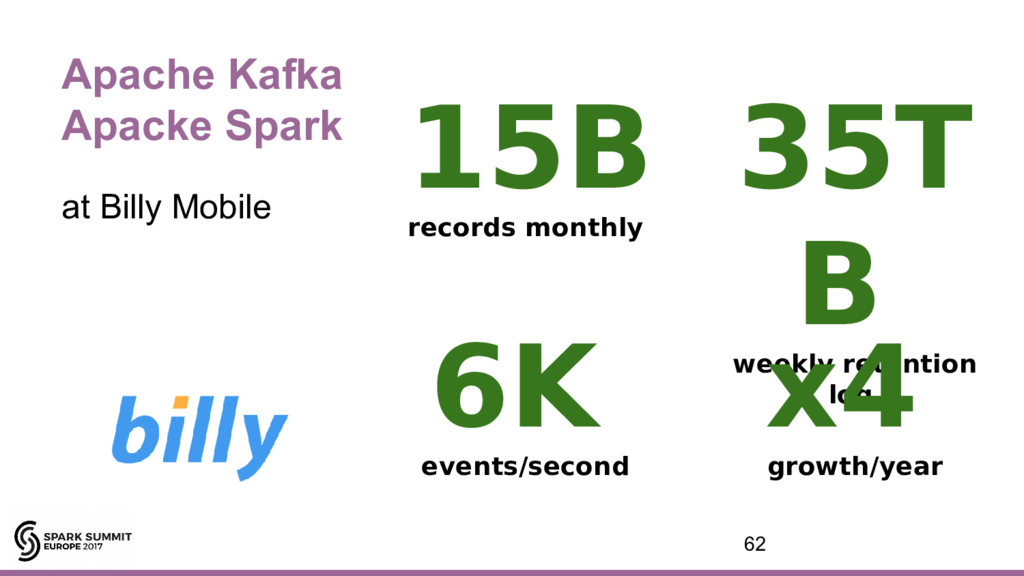{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you very much! Questions? @joanvr joanviladrosa [email protected]](https://files.speakerdeck.com/presentations/e7a53a96b58b4b34ad677bcac60443ab/slide_71.jpg){kind=link}