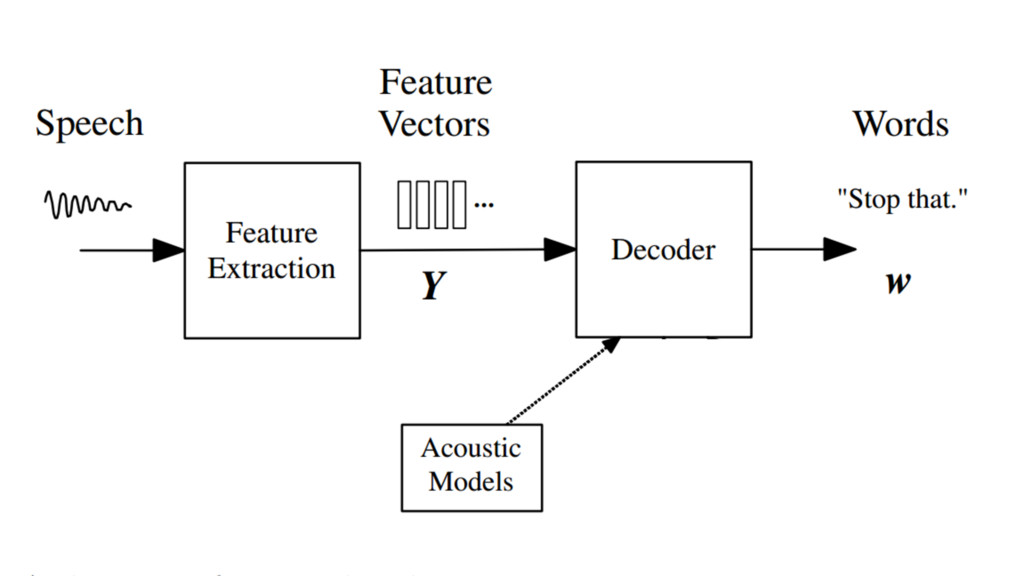
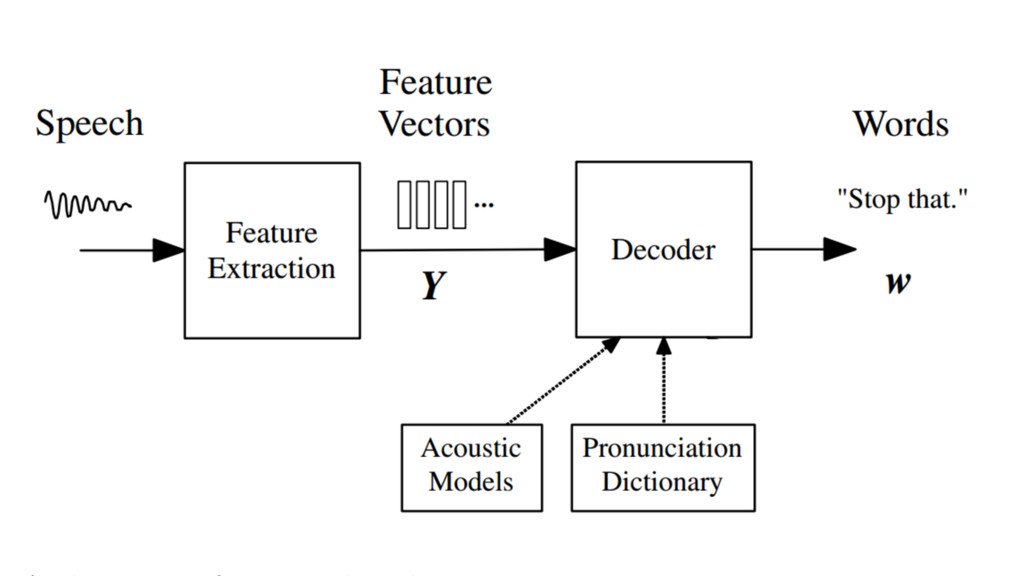
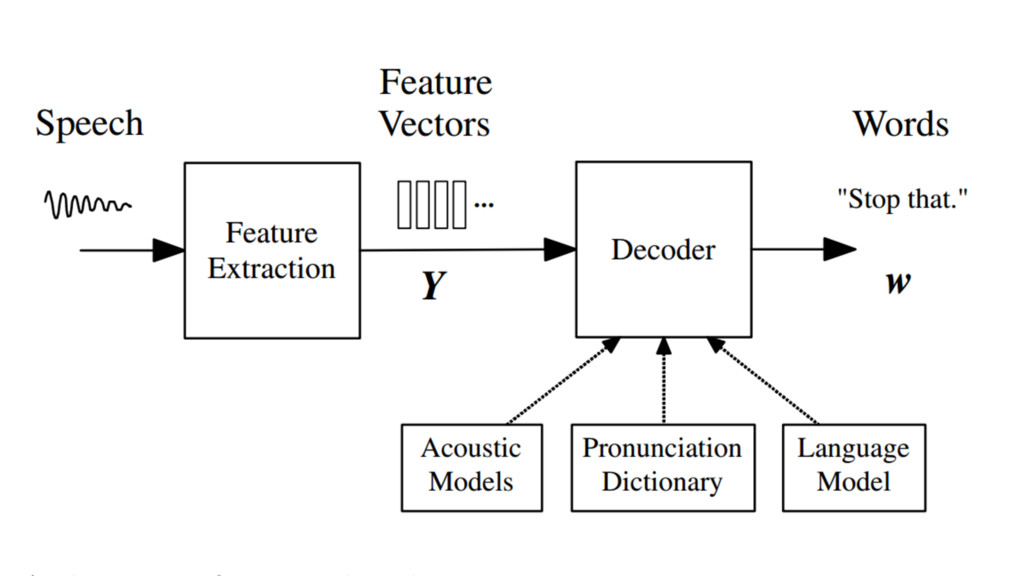
Although high quality, general-purpose dictation is just barely outside our reach, modern speech recognition is well adapted to small-vocabulary, structured grammars like programming languages and voice user interfaces (VUIs). By providing alternative input mechanisms to traditional IDEs, we can improve accessibility for visually impaired programmers, and free developers from the paradigm of menu- and button- based navigation. In this presentation, we will demonstrate a tool that can navigate code, recognize simple commands, and help you write Java, just by listening to your voice. Written in Java and built on open source libraries, you too can integrate speech recognition in an IDE or desktop application of your choice, by using a few simple recipes. Join us to learn more!
{kind=link}
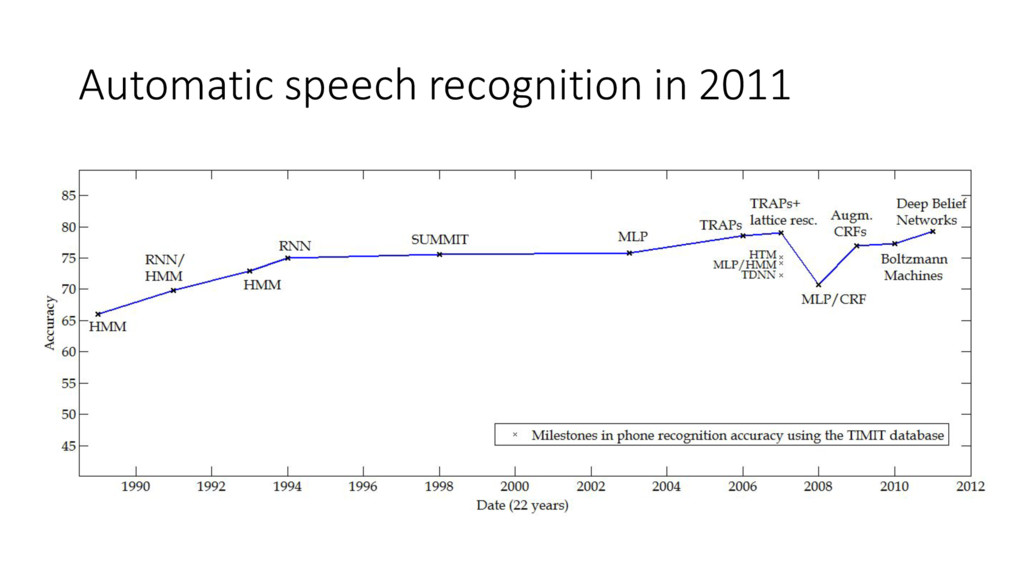{kind=link}
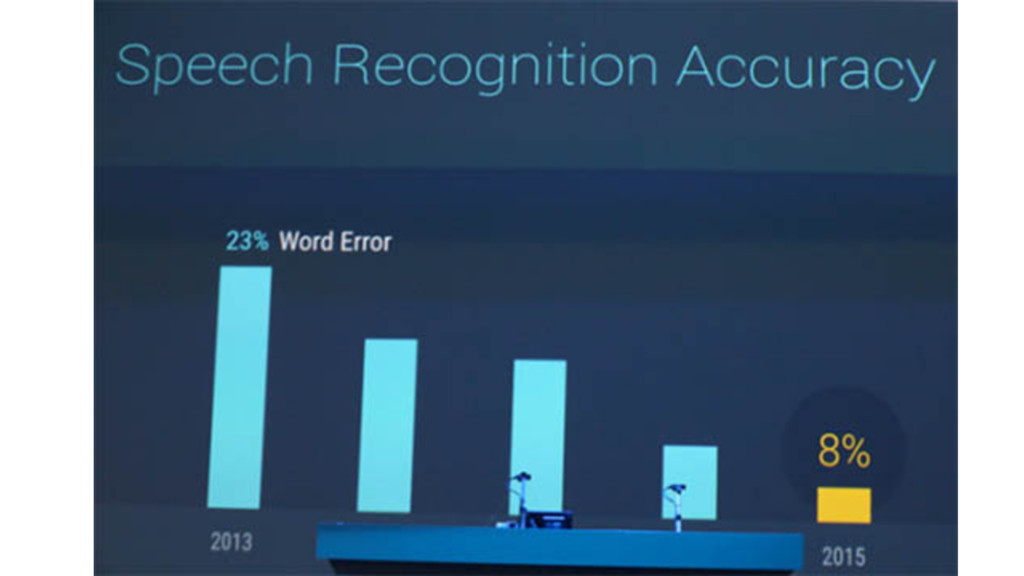{kind=link}
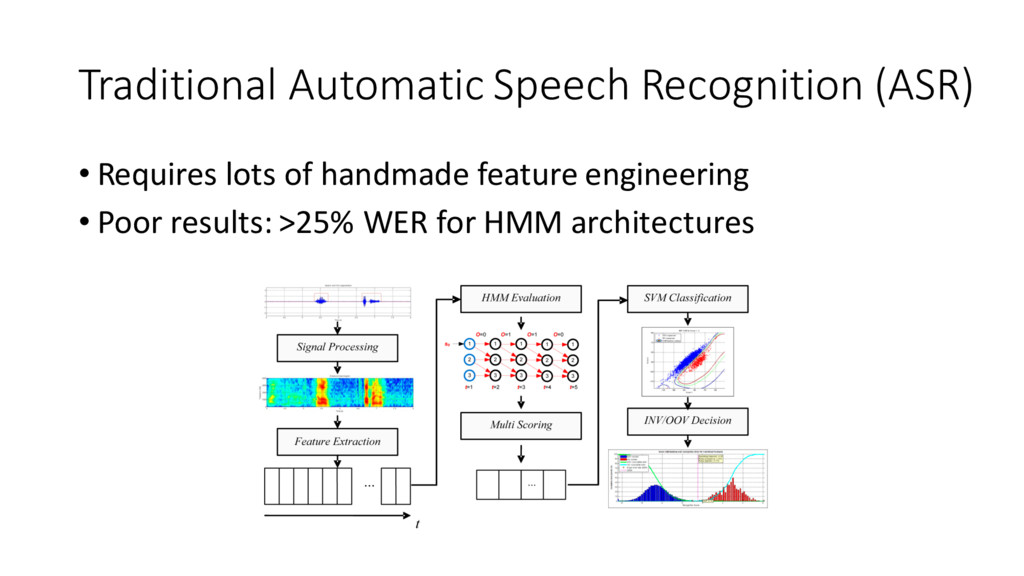{kind=link}
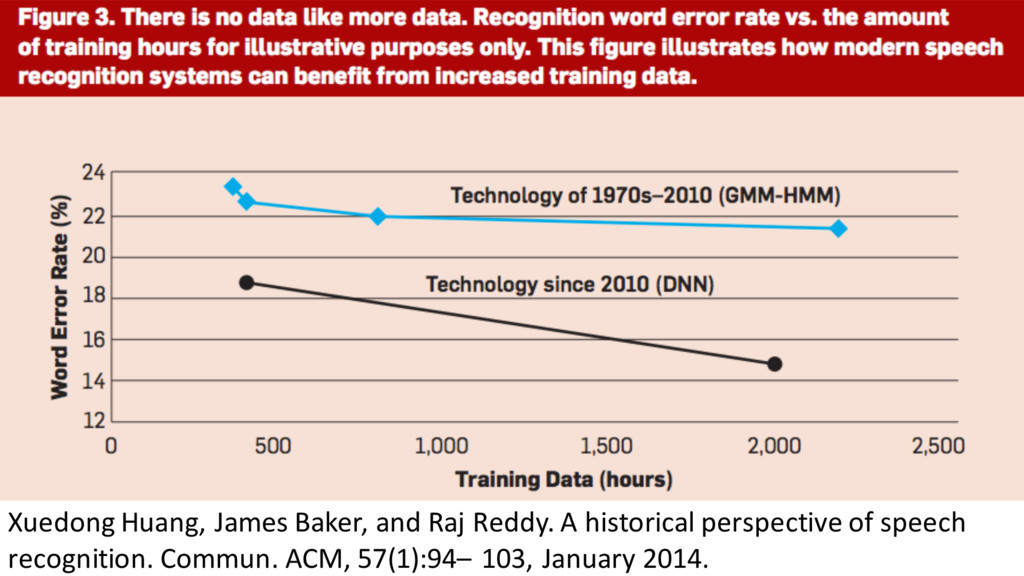{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
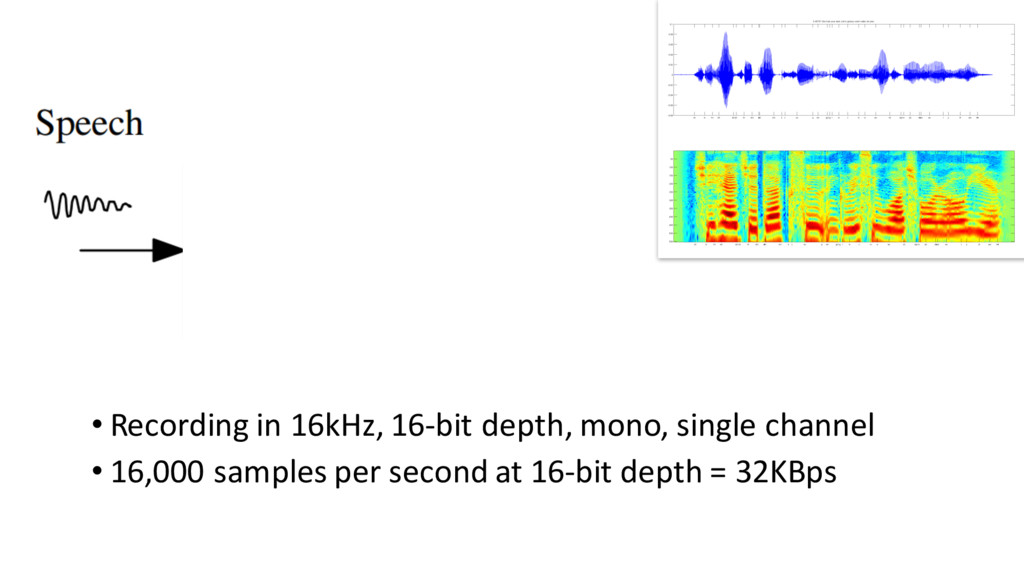{kind=link}
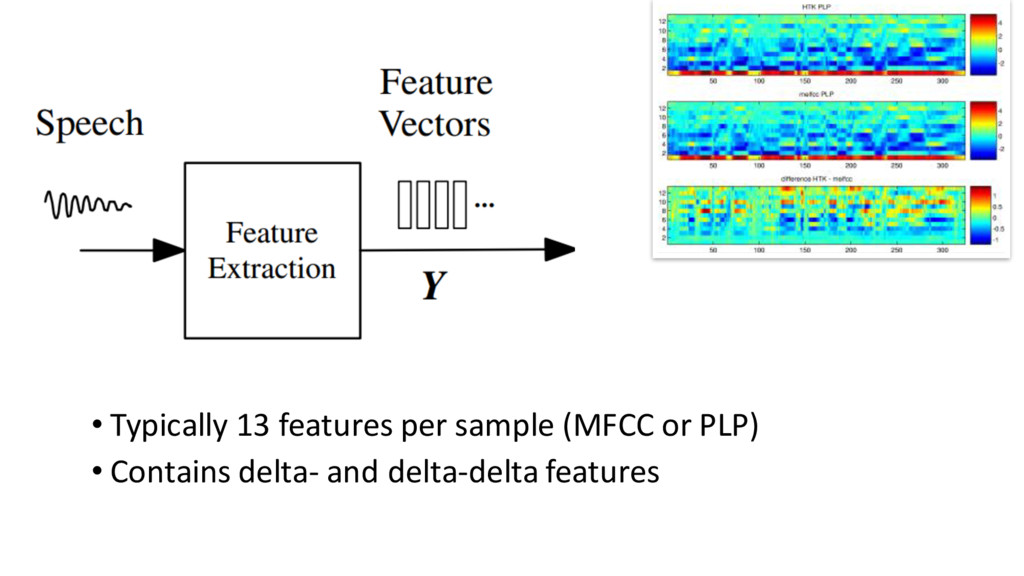{kind=link}
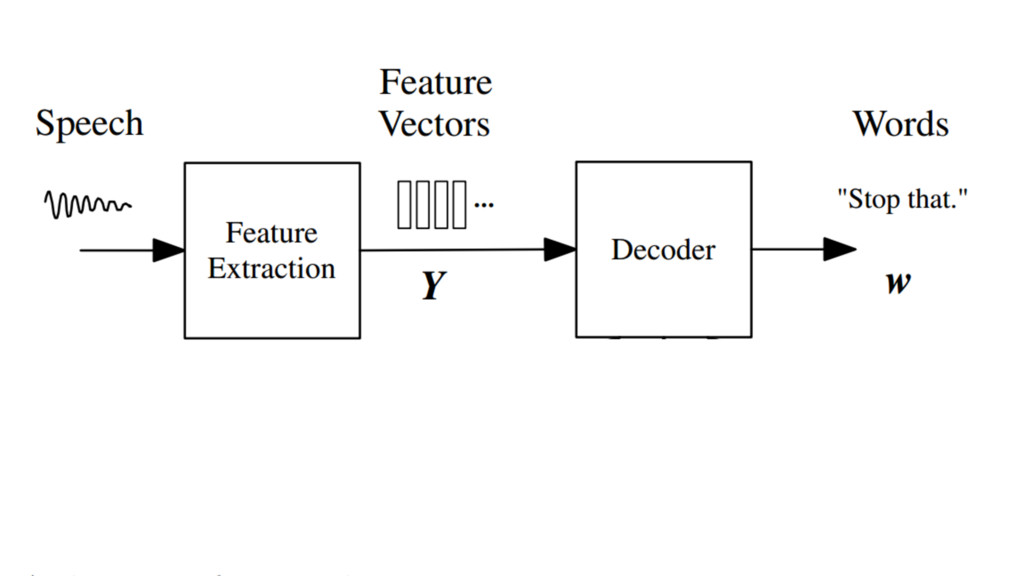{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
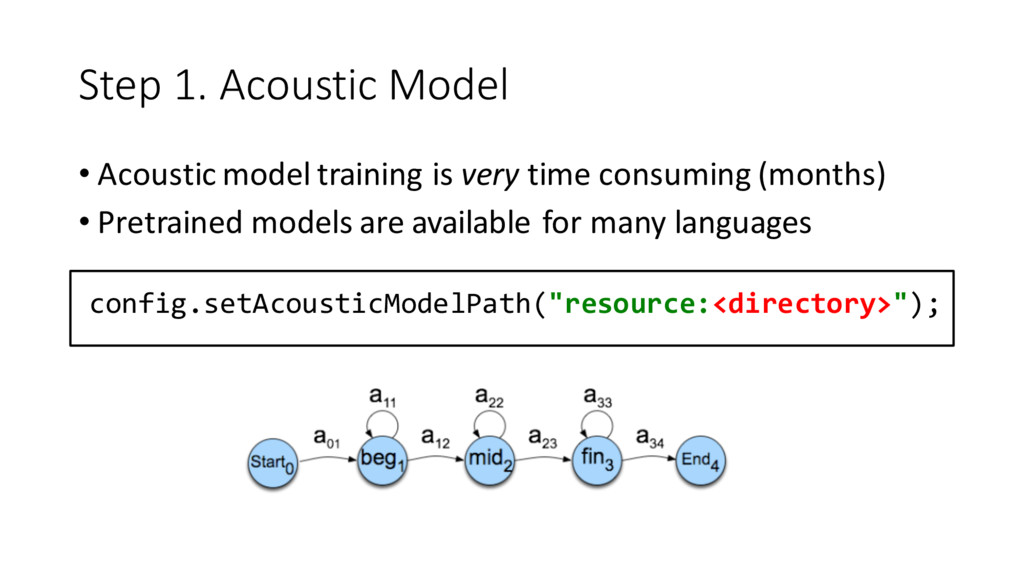{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
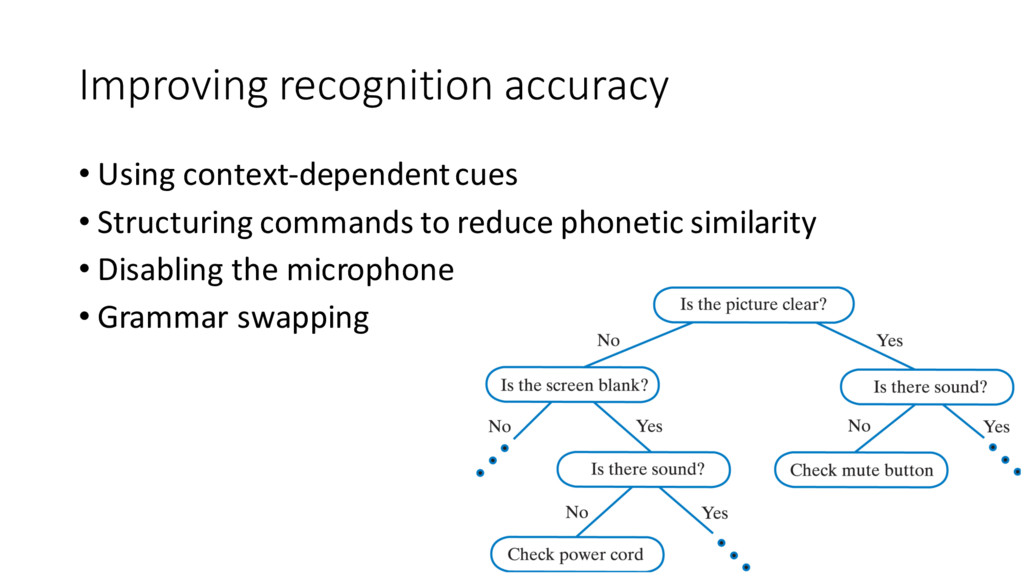{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}