Have you ever wanted to build your own Siri? Building a custom speech recognizer may be easier than you think. Java has many many open source tools for DIY speech recognition, including state-of-the art libraries like deeplearning4j, caffe, and CMUSphinx. In this session, we will demonstrate a few of these tools in action and show you how to use them to build a robust and accurate voice user interface for Java applications.
{kind=link}
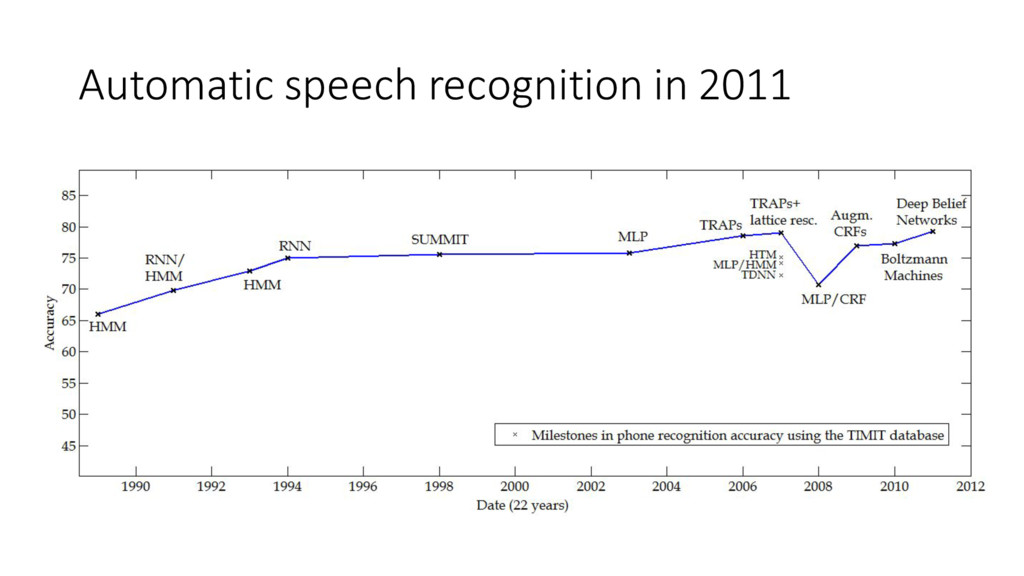{kind=link}
{kind=link}
{kind=link}
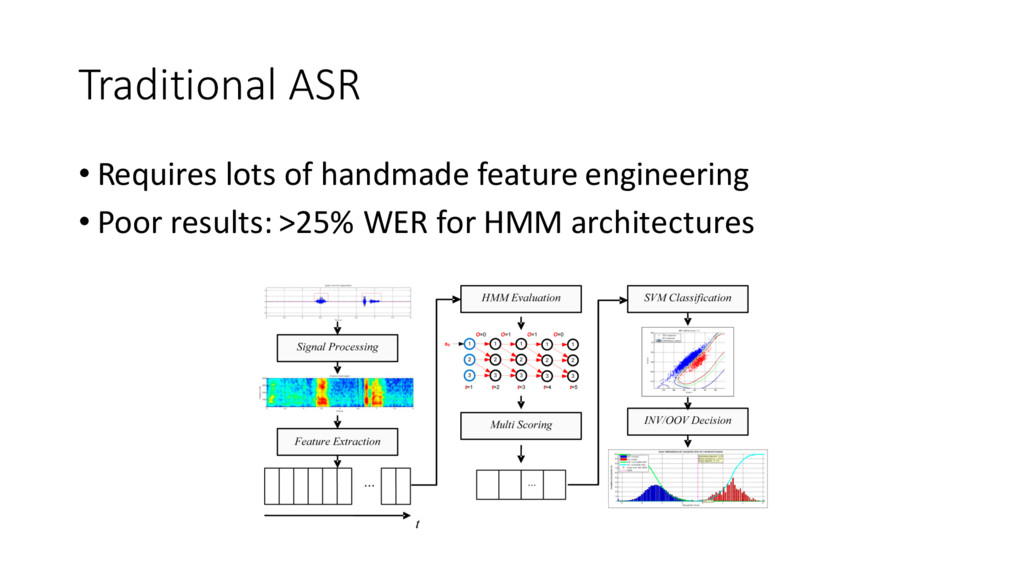{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
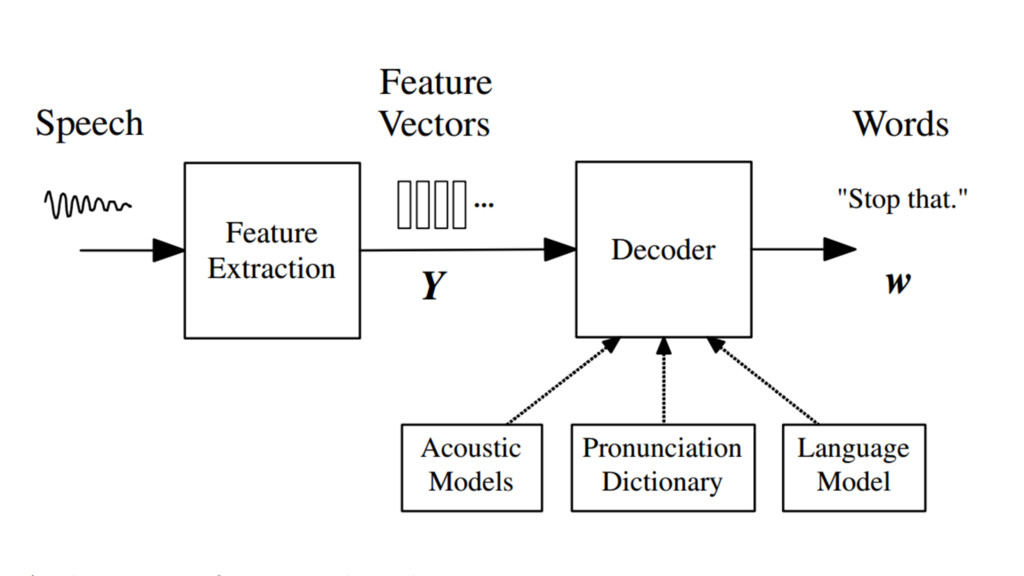{kind=link}
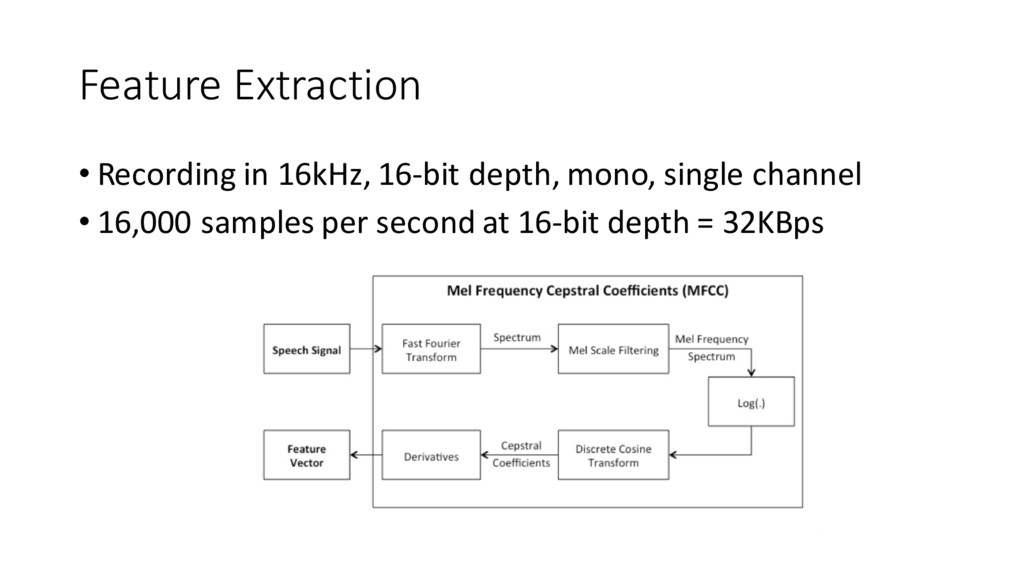{kind=link}
{kind=link}
{kind=link}
{kind=link}
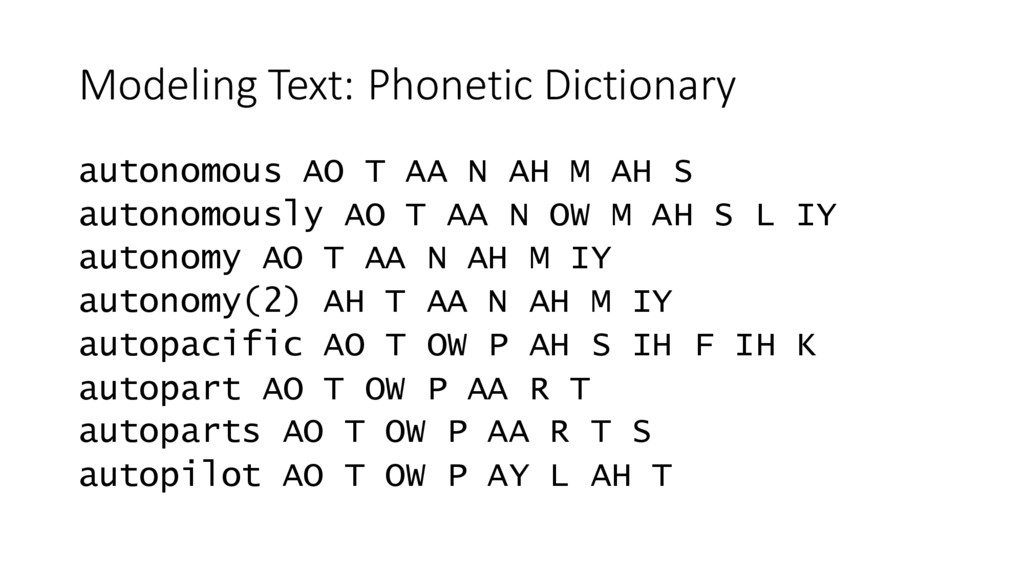{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}