We’ll present a use case and share the methodology we adopted to improve our mail infrastructure.
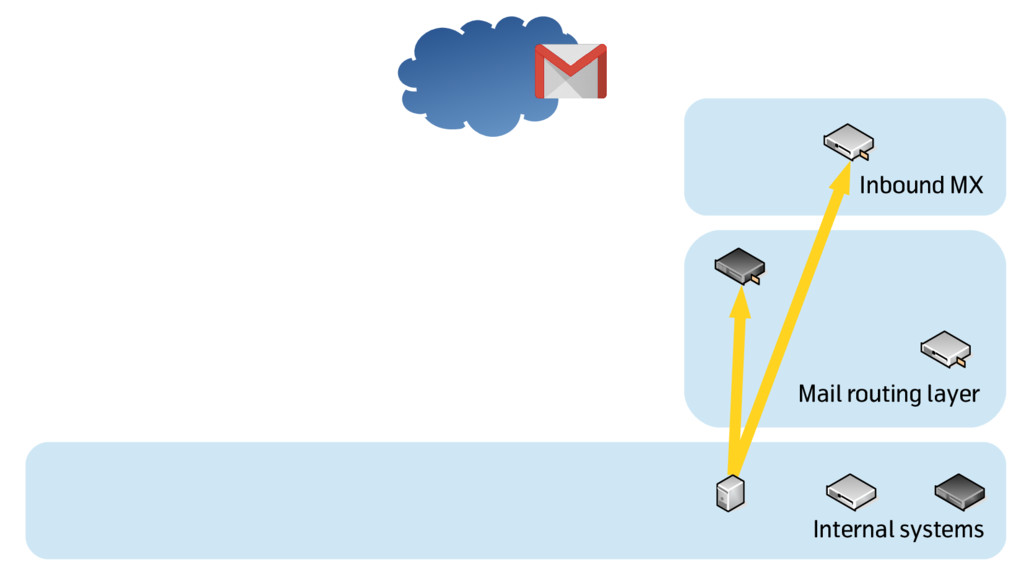
The existing infrastructure was built on good design choices. At the same time, multiple single point of failures and casual management of the service made it increasingly difficult to fix problems and improve.
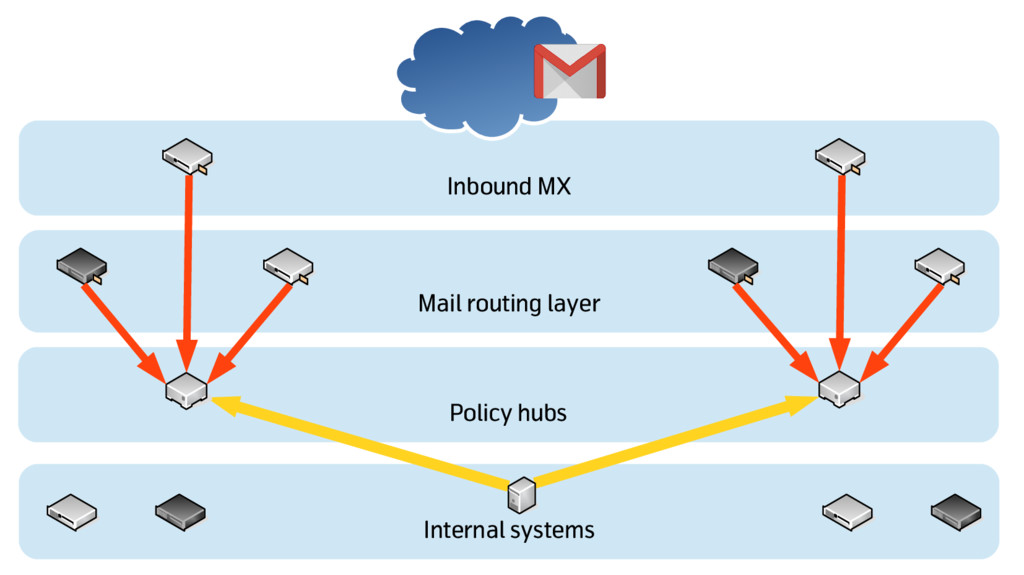
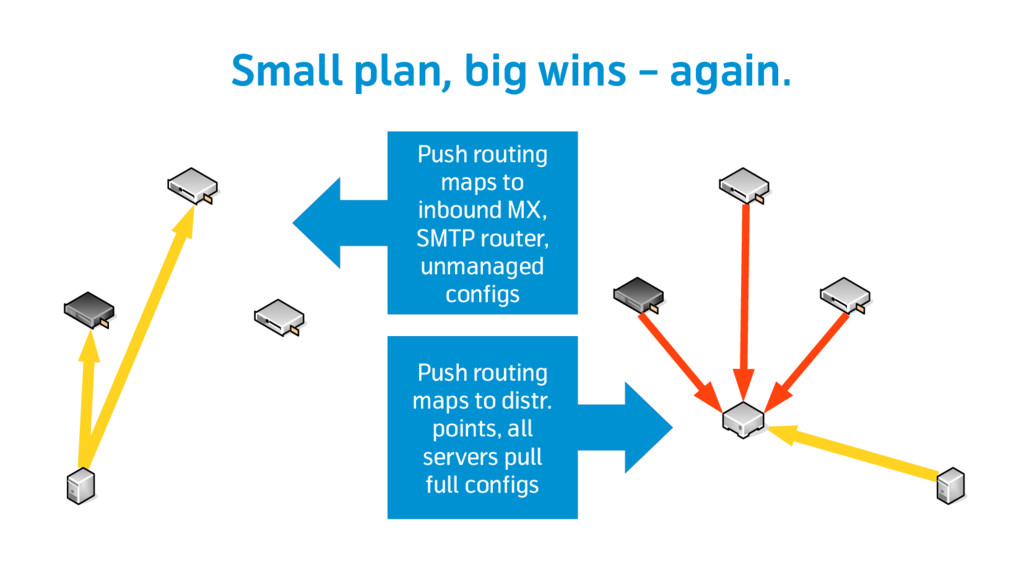
We decided to evolve the existing design to add reliability, resilience and consistency, and we needed to do that with a “rolling upgrade” approach, with the new infrastructure growing aside of the existing one and progressively replacing it. That required us to use a mix of agile and DevOps techniques, and a lot of collaboration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Marco Marongiu Email: [email protected] Twitter: @brontolinux Web: http://syslog.me/](https://files.speakerdeck.com/presentations/4c7b98adc6784bc49fd90d856d40de52/slide_31.jpg){kind=link}