Lecture slides for Lecture 08 of the Saint Louis University Course Quantitative Analysis: Applied Inferential Statistics. These slides cover the topics related to difference of mean testing in R.
so that we can give in to today’s lecture! WELCOME! GETTING STARTED Make sure you have the following packages: broom, car, dplyr, ggplot2, effsize, ggridges, ggstatsplot, pwr, and readr (use the packages tab in the lower righthand corner of RStudio)
Front Matter 2. Plots for Mean Difference 3. Variance Testing 4. One or Two Samples 5. Dependent Samples 6. Effect Sizes 7. Power Analyses 8. Back Matter
been? Lab 08 (from next week) and LP 09 are due before lecture 10. Lab 07 and Problem Set 04 (from today) are due before lecture 10. We do not have class next week - a short video lecture will be posted about working with factors and strings. The TBA reading didn’t get updated - Read Chapter 2 at your leisure
will need: • The lecture-08 repo cloned using GitHub Desktop • A new R project set-up on your computer named lecture-08-example • The new project will need data/, docs/, results/, and source/ subdirectories with plots/ and tests/ created within results/ • The data stl_tbl_income.csv from lecture-08/data/ should be copied into data/ • The script create_foreign.R from lecture-08/examples/ should be copied into source/ • A new notebook should be created and saved in docs/ 1. FRONT MATTER
data stored in the data/ subdirectory: > data <- read_csv(path = here::here(“data”, “data.csv”)) # output omitted The read_csv() function will return output describing the formatting of each variable imported. This formatting can be optionally forced (e.g. if you want a variable to be character). f(x) Available in readr Installed via CRAN with install.packages(“tidyverse”)
data stored in the data/ subdirectory: > data <- read_csv(path = here::here(“data”, “data.csv”)) # output omitted The read_csv() function will return output describing the formatting of each variable imported. This formatting can be optionally forced (e.g. if you want a variable to be character). f(x)
val) Will save the last plot created: > ggsave(here::here(“results”, “plots”, “plot.png”), dpi = 300) Use the here package to direct plots to a results/ subdirectory of your project.
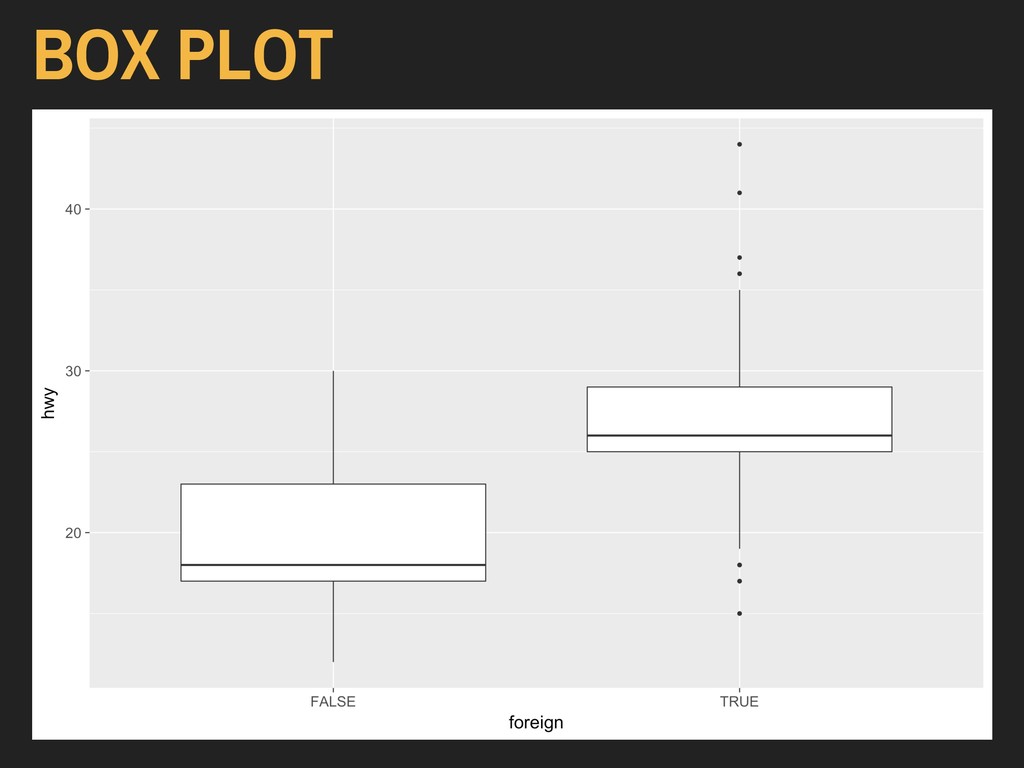
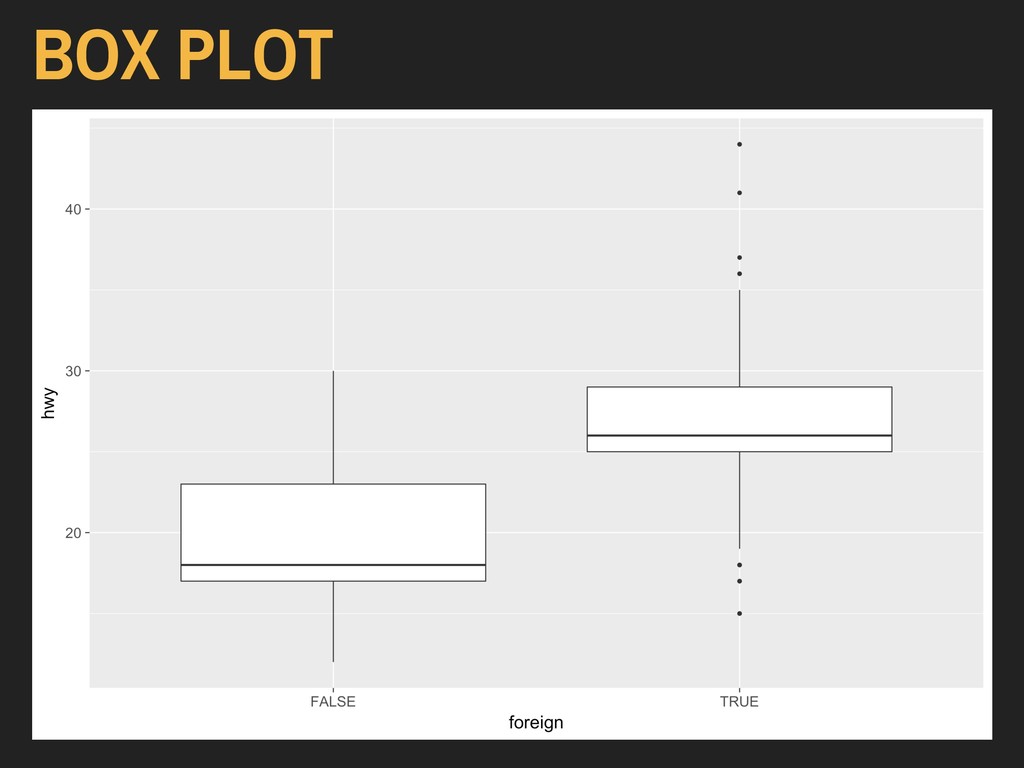
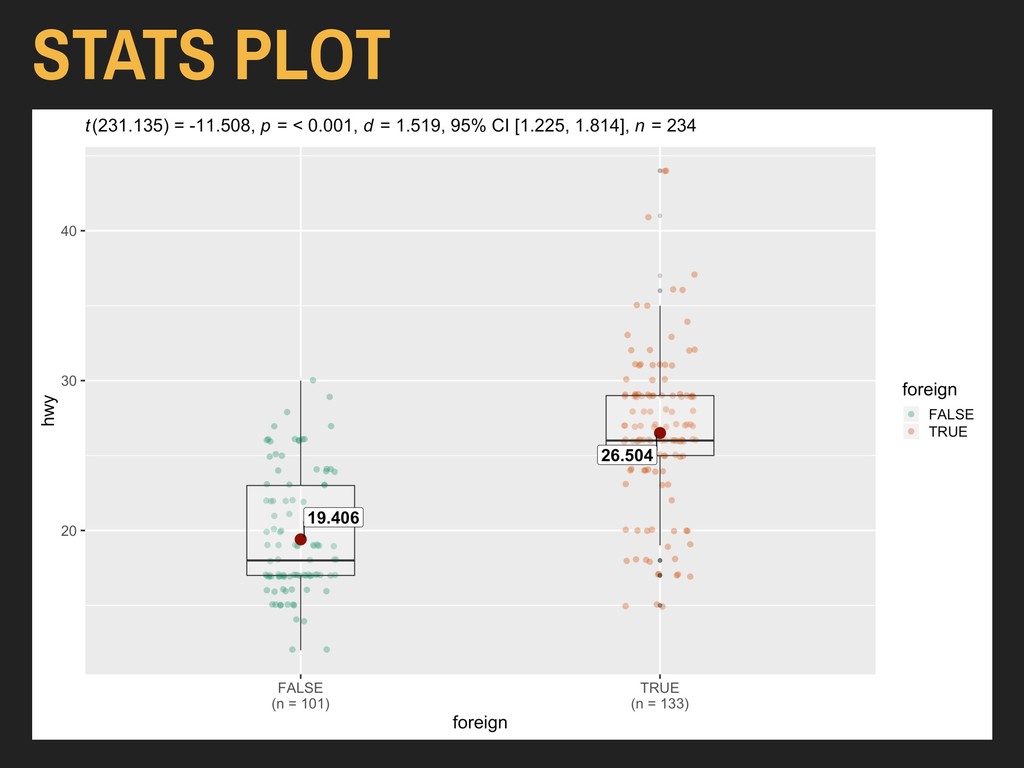
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_boxplot(mapping = aes(x = foreign, y = hwy)) The x variable should be discrete (binary, factor, or character), and the y variable should be continuous.
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_boxplot(mapping = aes(x = foreign, y = hwy)) Box plots are important parts of exploratory data analysis, but are less ideal for lay consumption.
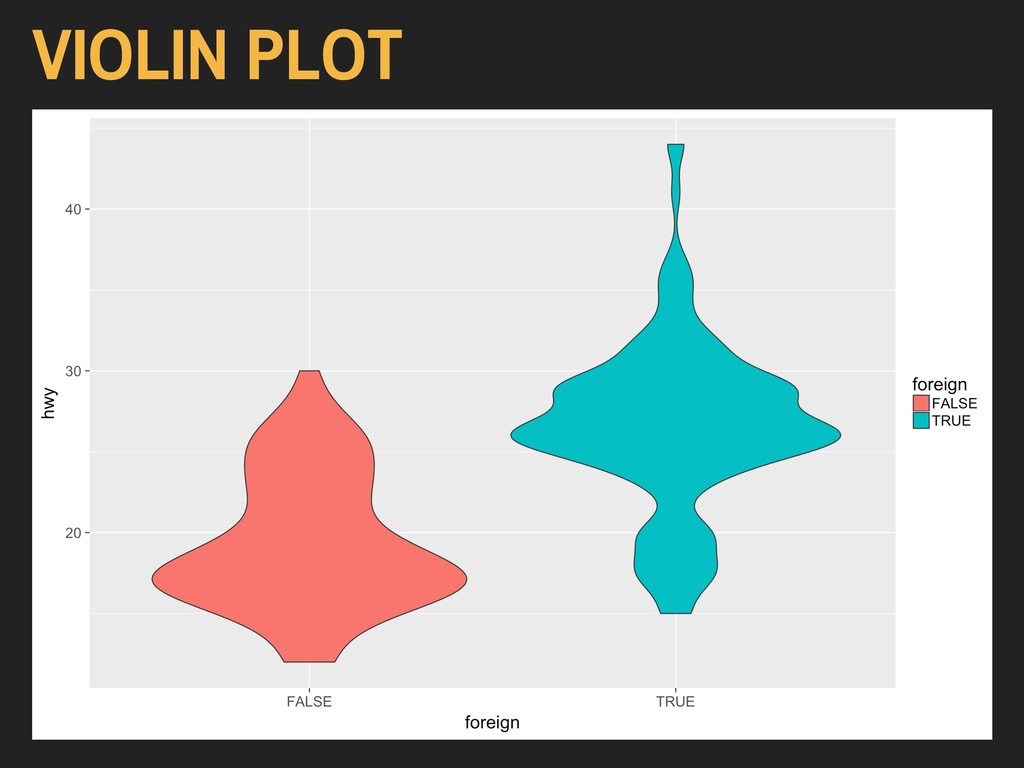
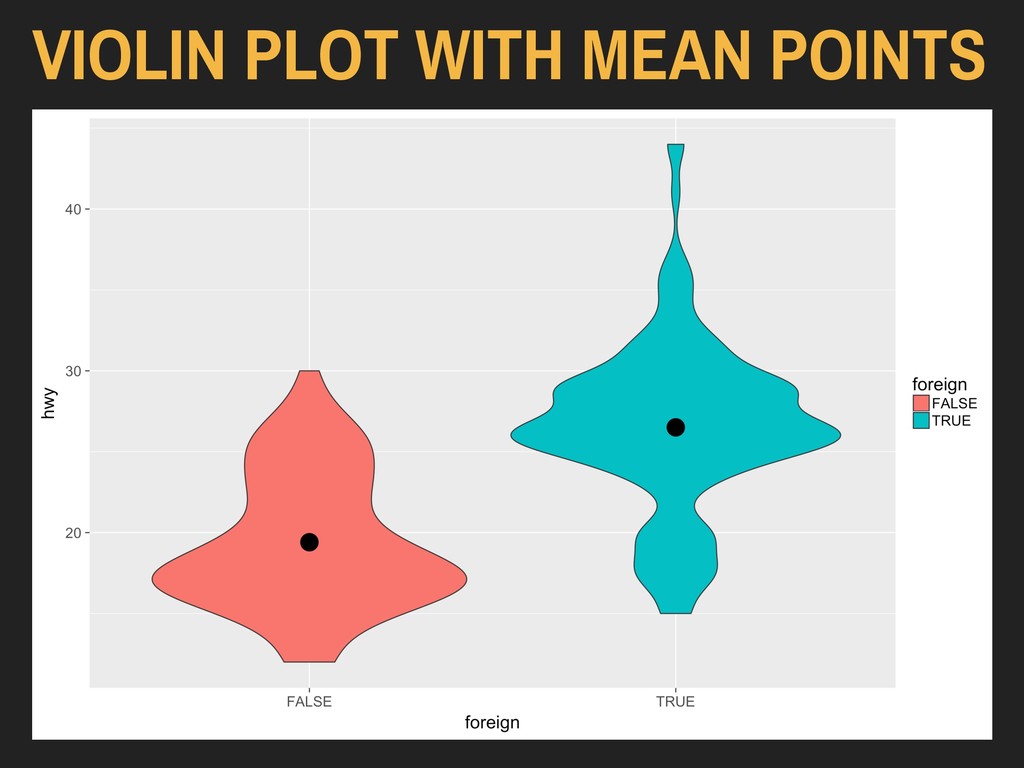
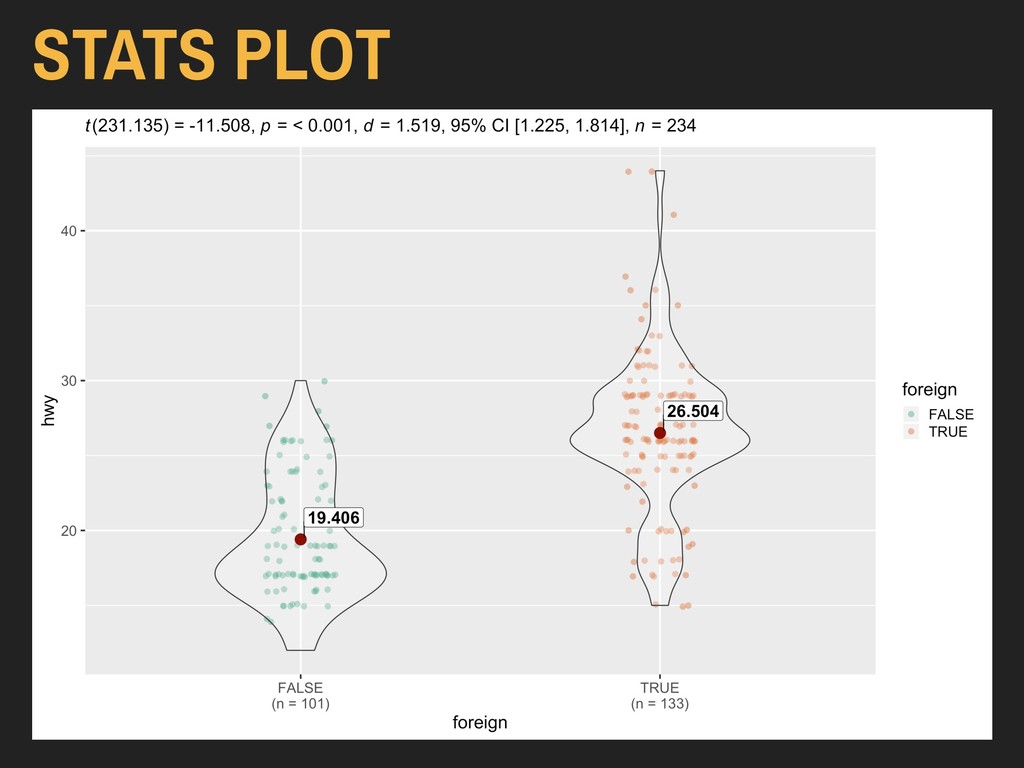
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_violin(mapping = aes(x = foreign, y = hwy)) The x variable should be discrete (binary, factor, or character), and the y variable should be continuous.
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_violin(mapping = aes(x = foreign, y = hwy, fill = foreign)) The x variable should be discrete (binary, factor, or character), and the y variable should be continuous.
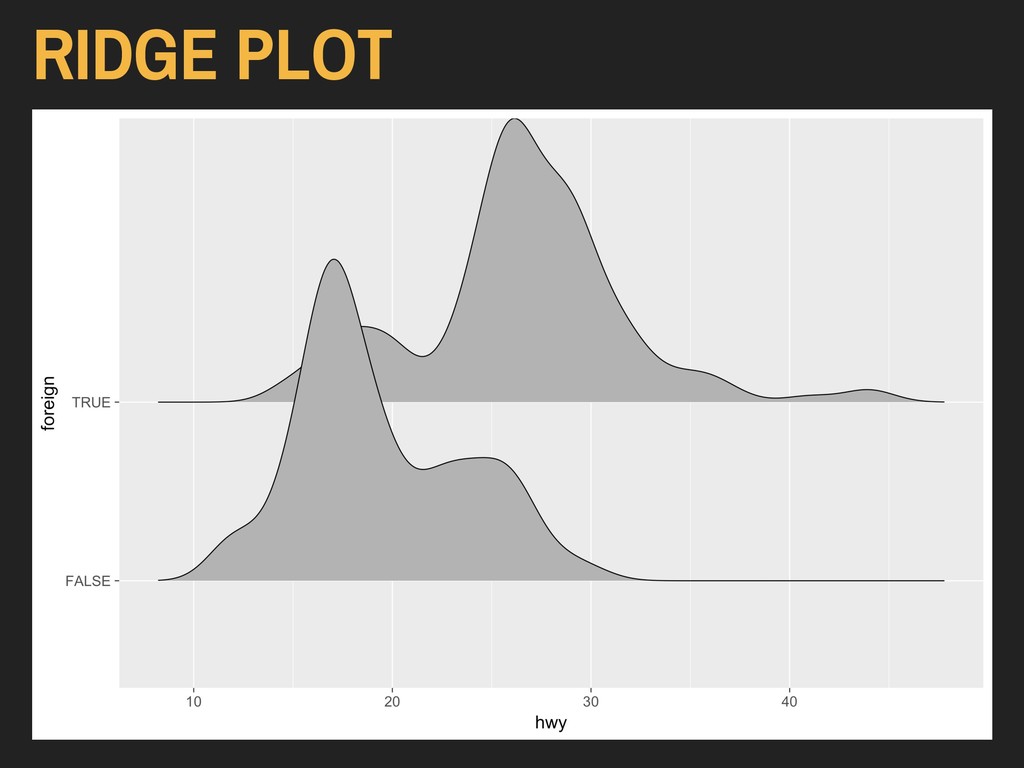
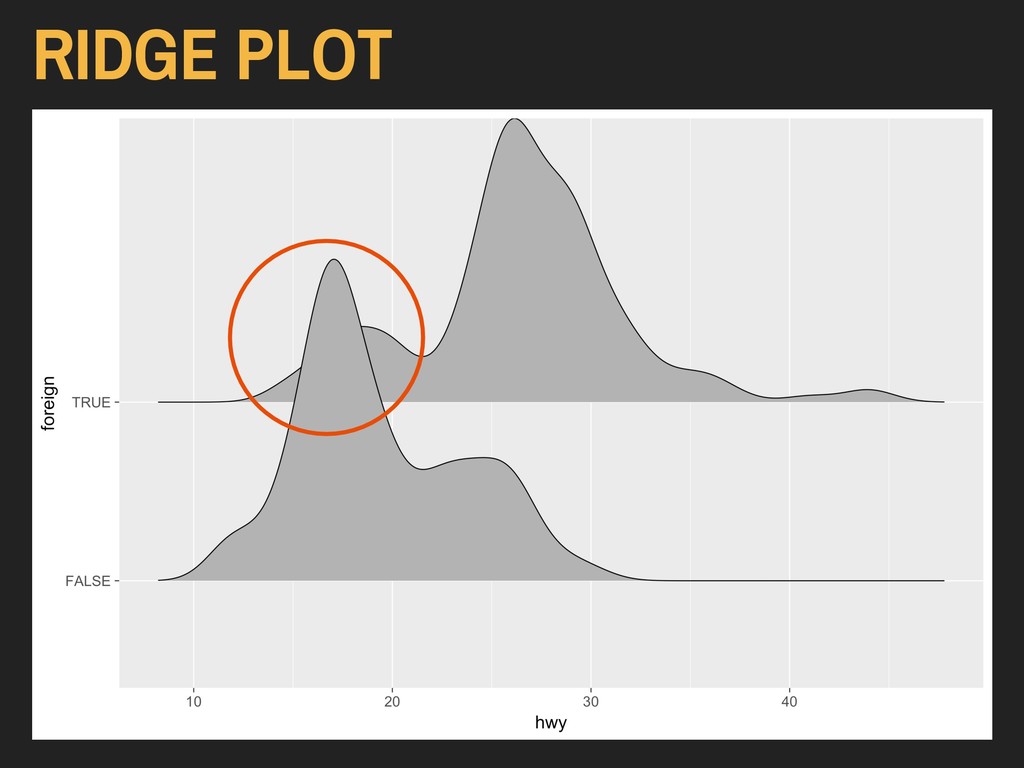
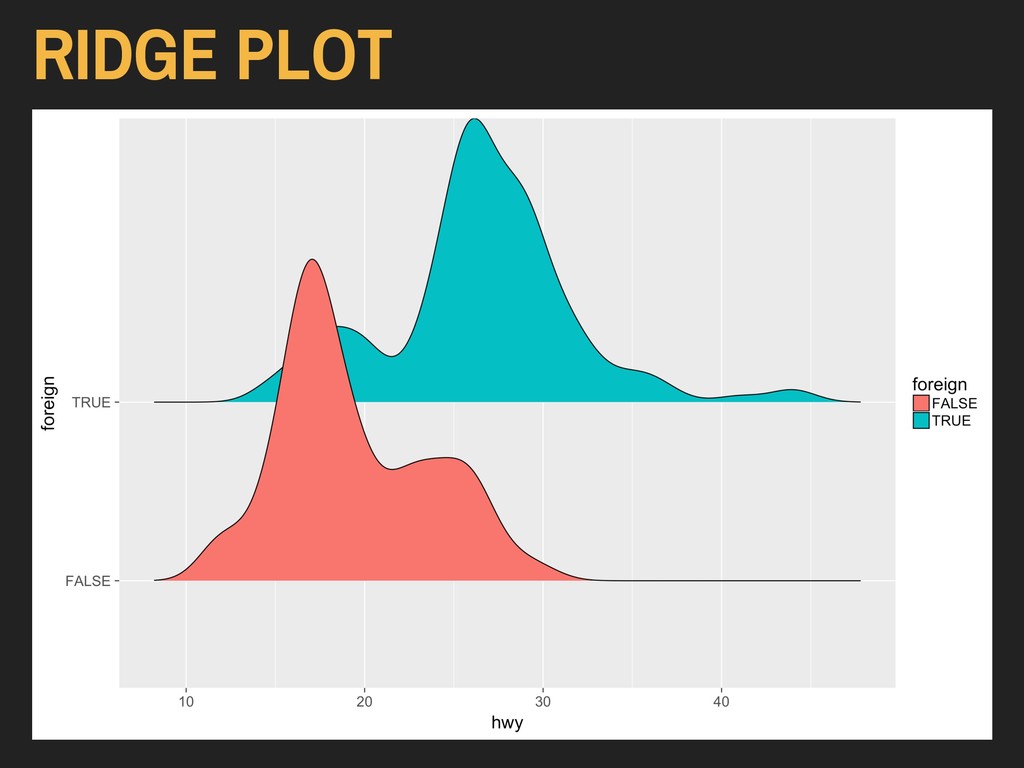
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_density_ridges(mapping = aes(x = hwy, y = foreign)) The x and y variables are reversed here because of the way the ridge plot is oriented. Available in ggridges Installed via CRAN
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_density_ridges(mapping = aes(x = hwy, y = foreign)) The x and y variables are reversed here because of the way the ridge plot is oriented.
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_density_ridges(mapping = aes(x = hwy, y = foreign)) The design of these plots will obscure some aspects of your distributions unless altered.
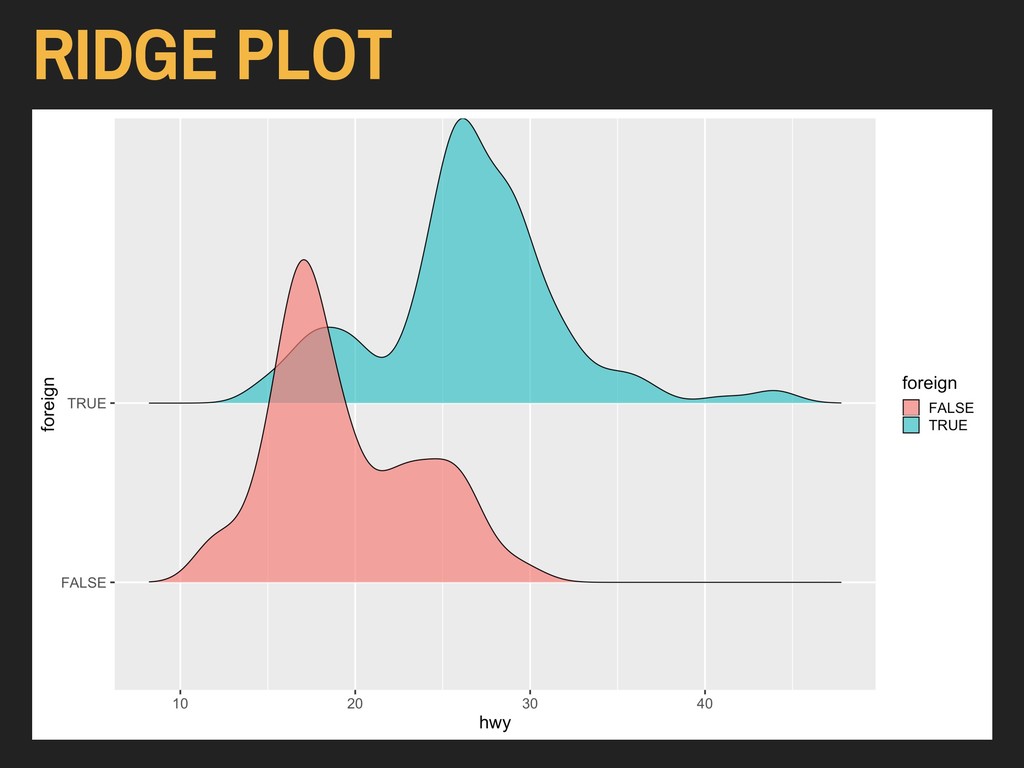
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_density_ridges(mapping = aes(x = hwy, y = foreign, fill = foreign)) The x and y variables are reversed here because of the way the ridge plot is oriented.
Using the hwy and foreign* variables from ggplot2’s mpg data: > ggplot(data = autoData) + geom_density_ridges(mapping = aes(x = hwy, y = foreign, fill = foreign), alpha = 0.65) The x and y variables are reversed here because of the way the ridge plot is oriented.
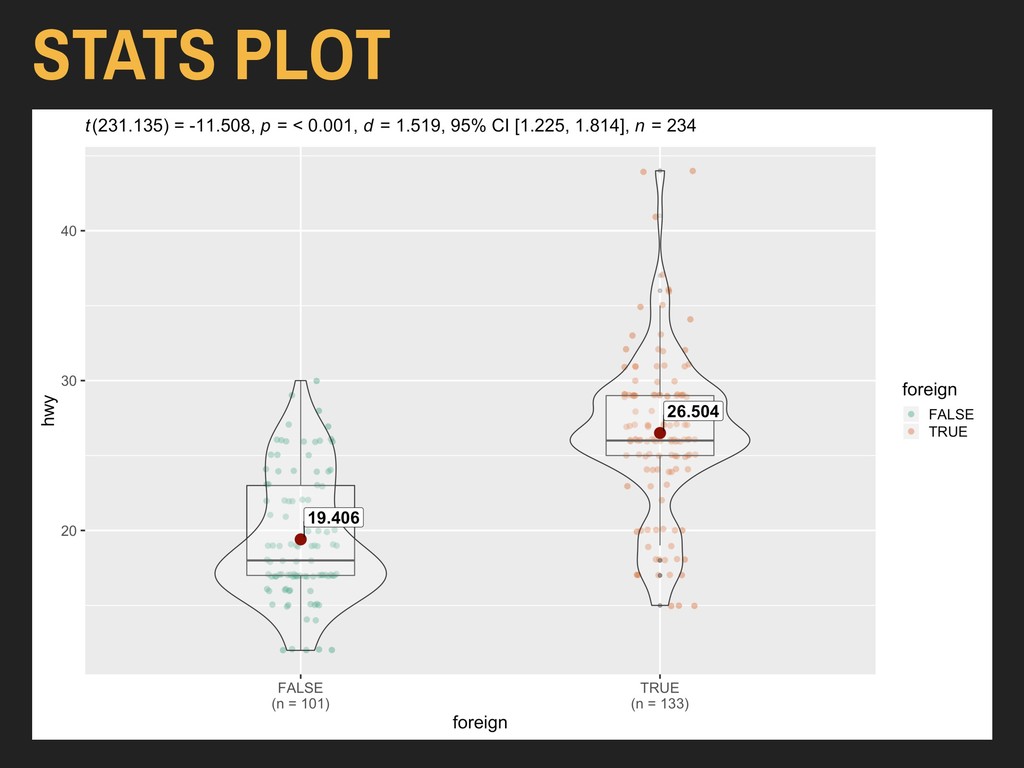
dependent (outcome) variable ▸ xVar is your independent variable ▸ effsize.type should always be “biased” to return Cohen’s D ▸ plotType should be one of “violin”, “box”, or “boxviolin” Available in ggstatsplot Installed via CRAN 2. PLOTS FOR MEAN DIFFERENCE STATS PLOT Parameters: ggbetweenstats(data = dataFrame, x = xvar, y = yvar, effsize.type = “biased”, plot.type = plotType)
dependent (outcome) variable ▸ xVar is your independent variable ▸ effsize.type should always be “biased” to return Cohen’s D ▸ plotType should be one of “violin”, “box”, or “boxviolin” 2. PLOTS FOR MEAN DIFFERENCE STATS PLOT Parameters: ggbetweenstats(data = dataFrame, x = xvar, y = yvar, effsize.type = “biased”, plot.type = plotType)
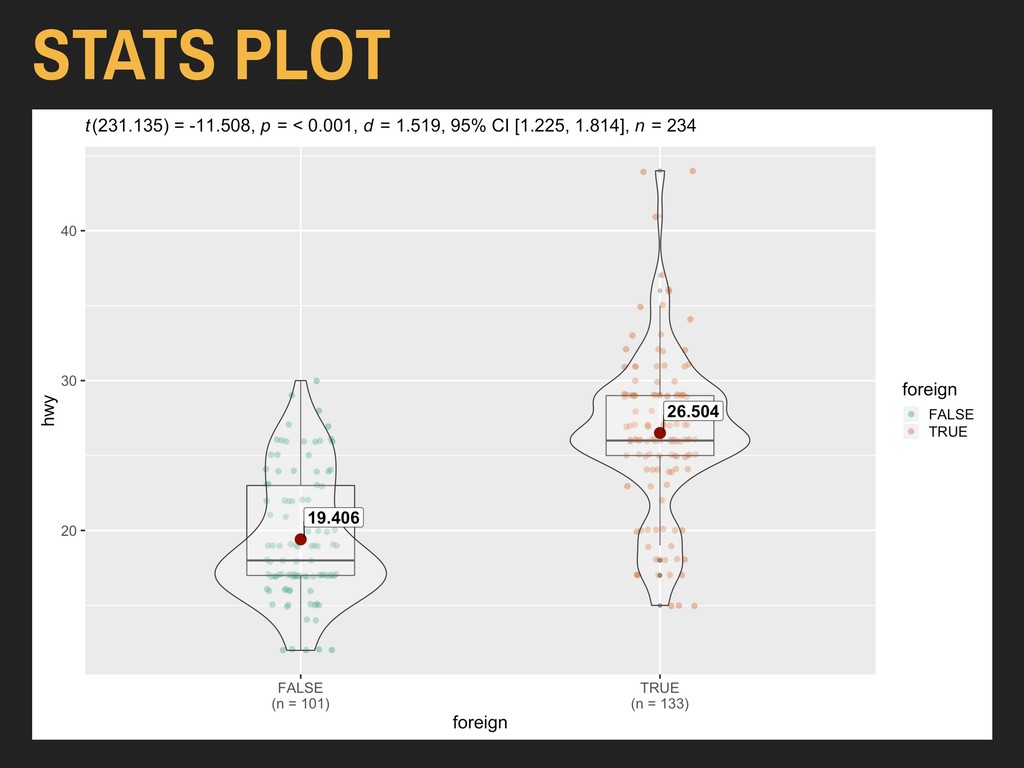
x = xvar, y = yvar, effsize.type = “biased”, plot.type = plotType) Using the hwy and foreign* variables from ggplot2’s mpg data: > ggbetweenstats(data = autoData, x = foreign, y = hwy, effsize.type = “biased”, plot.type = “boxviolin”) ggbetweenstats() will automatically test for heterskedasticity using a different test (Bartlett's test) and will report the p value as output. Based on this, it will apply Welch’s correction if needed.
x = xvar, y = yvar, effsize.type = “biased”, plot.type = plotType) Using the hwy and foreign* variables from ggplot2’s mpg data: > ggbetweenstats(data = autoData, x = foreign, y = hwy, effsize.type = “biased”, plot.type = “box”) ggbetweenstats() will automatically test for heterskedasticity using a different test (Bartlett's test) and will report the p value as output. Based on this, it will apply Welch’s correction if needed.
x = xvar, y = yvar, effsize.type = “biased”, plot.type = plotType) Using the hwy and foreign* variables from ggplot2’s mpg data: > ggbetweenstats(data = autoData, x = foreign, y = hwy, effsize.type = “biased”, plot.type = “violin”) ggbetweenstats() will automatically test for heterskedasticity using a different test (Bartlett's test) and will report the p value as output. Based on this, it will apply Welch’s correction if needed.
assessing the homogeneity of variance assumption. • H0 = The two variances are approximately equal. • H1 = The two variances are unequal. ▸ R’s implementation of the Levene’s test uses the median, rather than the mean, for this comparison. 3. VARIANCE TESTING What does the Levne’s test accomplish?
distribution of the ratio between two groups based on their variance ▸ Used to test whether two estimates of variance can be assumed to come from the same population ▸ Not symmetrical like t, and its shape varies based on the given degrees of freedom 3. VARIANCE TESTING F-DISTRUBTION RONALD FISHER
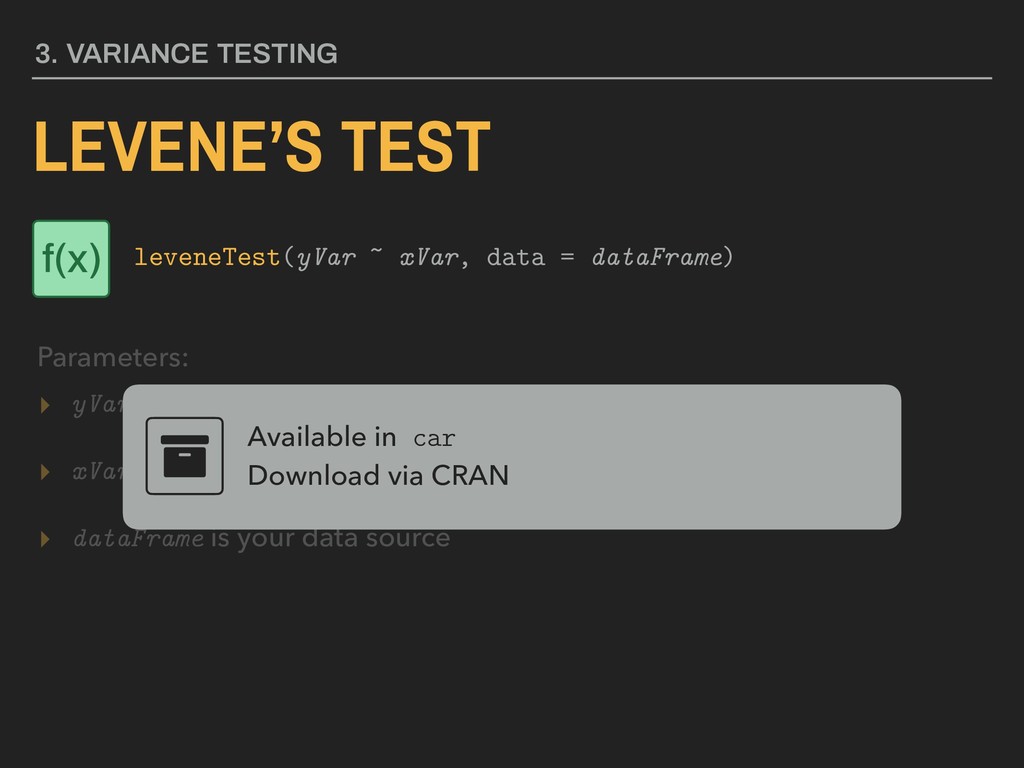
your independent variable; it should be a logical variable ▸ dataFrame is your data source Available in car Download via CRAN 3. VARIANCE TESTING LEVENE’S TEST Parameters: leveneTest(yVar ~ xVar, data = dataFrame) f(x)
your independent variable; it should be a logical variable ▸ dataFrame is your data source 3. VARIANCE TESTING LEVENE’S TEST Parameters: leveneTest(yVar ~ xVar, data = dataFrame) f(x)
dataFrame) Using the hwy and foreign* variables from ggplot2’s mpg data: > leveneTest(hwy ~ foreign, data = autoData) # see output on next slide The leveneTest() function will temporarily convert string or logical variables to factors to compute the test. f(x)
Test for Homogeneity of Variance (center = median) Df F value Pr(>F) group 1 0.5867 0.4445 232 Warning message: In leveneTest.default(y = y, group = group, ...) : group coerced to factor. 3. VARIANCE TESTING
dataFrame) f(x) The accent symbol (~) is used to separate the lefthand side (LHS) of a model’s equation from the righthand side (RHS). The lefthand side is always for the dependent variable - the main outcome we are interested in understanding. We always call this variable y. The righthand side is for our independent variables, which we always refer to as x variables.
foreign* variables from ggplot2’s mpg data: > test <- leveneTest(hwy ~ foreign, data = autoData) > test <- tidy(test) The tidy() function will not return any output in the console if successful. f(x) Available in broom Installed via CRAN with install.packages(“tidyverse”)
foreign* variables from ggplot2’s mpg data: > test <- leveneTest(hwy ~ foreign, data = autoData) > test <- tidy(test) The tidy() function will not return any output in the console if successful. f(x)
test output from the previous slide: > write_csv(test, path = here::here(“results”, “tests”, “leveneTest.csv”)) The write_csv() function will not return any output in the console if successful. f(x)
for assessing whether the sample is drawn from a population by comparing their means. • H0 = The difference between the sample mean and the population’s (i.e. the “true” mean) is approximately zero. • H1 = difference between the sample mean and the population’s (i.e. the “true” mean) is substantively different from zero. 4. ONE OR TWO SAMPLES What is the one-sample t test used for?
dependent (outcome) variable ▸ mu is the hypothesized (or known) population mean Available in stats Installed with base R 4. ONE OR TWO SAMPLES ONE-SAMPLE T TEST Parameters: t.test(dataFrame$yVar, mu = val) f(x)
dependent (outcome) variable ▸ mu is the hypothesized (or known) population mean 4. ONE OR TWO SAMPLES ONE-SAMPLE T TEST Parameters: t.test(dataFrame$yVar, mu = val) f(x)
t-test data: autoData$hwy t = -2.0804, df = 233, p-value = 0.03858 alternative hypothesis: true mean is not equal to 24.25 95 percent confidence interval: 22.67324 24.20710 sample estimates: mean of x 23.44017 4. ONE OR TWO SAMPLES
used for assessing whether the mean of y for one group is approximately equal to the mean of y for another. • H0 = The difference in means is approximately zero. • H1 = The difference in means is substantively greater than zero. 4. ONE OR TWO SAMPLES What is the two-sample (independent) t test used for?
1. the dependent variable y contains continuous data 2. the distribution of y is approximately normal 3. independent variable is binary (xa and xb ) 4. homogeneity of variance between xa and xb 5. observations are independent 6. degrees of freedom (v) are defined as na +nb -2
dependent (outcome) variable ▸ xVar is your independent variable ▸ var.equal is a logical scalar; if FALSE, Welch’s corrected v is used Available in stats Installed with base R 4. ONE OR TWO SAMPLES INDEPENDENT T TEST Parameters: t.test(dataFrame$yVar ~ dataFrame$xVar, var.equal = FALSE) f(x)
dependent (outcome) variable ▸ xVar is your independent variable ▸ var.equal is a logical scalar; if FALSE, Welch’s corrected v is used 4. ONE OR TWO SAMPLES INDEPENDENT T TEST Parameters: t.test(dataFrame$yVar ~ dataFrame$xVar, var.equal = FALSE) f(x)
dataFrame$xVar, var.equal = FALSE) Using the hwy and foreign* variables from ggplot2’s mpg data: > t.test(autoData$hwy ~ autoData$foreign, var.equal = TRUE) # see output on next slide Remember that x should be a logical value. If var.equal is FALSE, Welch’s corrected degrees of freedom are used. f(x)
Two Sample t-test data: autoData$hwy by autoData$foreign t = -11.178, df = 232, p-value < 2.2e-16 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -8.348850 -5.846788 sample estimates: mean in group FALSE mean in group TRUE 19.40594 26.50376 4. ONE OR TWO SAMPLES
1. What type of formula you used, including whether pooled variance or Welch’s correction was used 2. The value of t, the value of v, and the associated p value 3. The mean for each group (xa and xb ) 4. A plain English interpretation of any difference observed between xa and xb .
each observation and multiple columns for different time points or groupings. ▸ Long data include multiple rows for each observation, one for each time point or grouping. ▸ The stl_tbl_income data are wide. 5. DEPENDENT SAMPLES What is the difference between wide and long data? Are the stl_tbl_income data wide or long?
the name of your new identification variable that takes values from the gathered columns’ names ▸ value will be the name of variable containing your numeric data ▸ ... is a list of columns to be gathered Available in tidyr Installed via CRAN with install.packages(“tidyverse”) 5. DEPENDENT SAMPLES RESHAPING DATA TO LONG Parameters: gather(dataFrame, key, value, ...) f(x)
the name of your new identification variable that takes values from the gathered columns’ names ▸ value will be the name of variable containing your numeric data ▸ ... is a list of columns to be gathered 5. DEPENDENT SAMPLES RESHAPING DATA TO LONG Parameters: gather(dataFrame, key, value, ...) f(x)
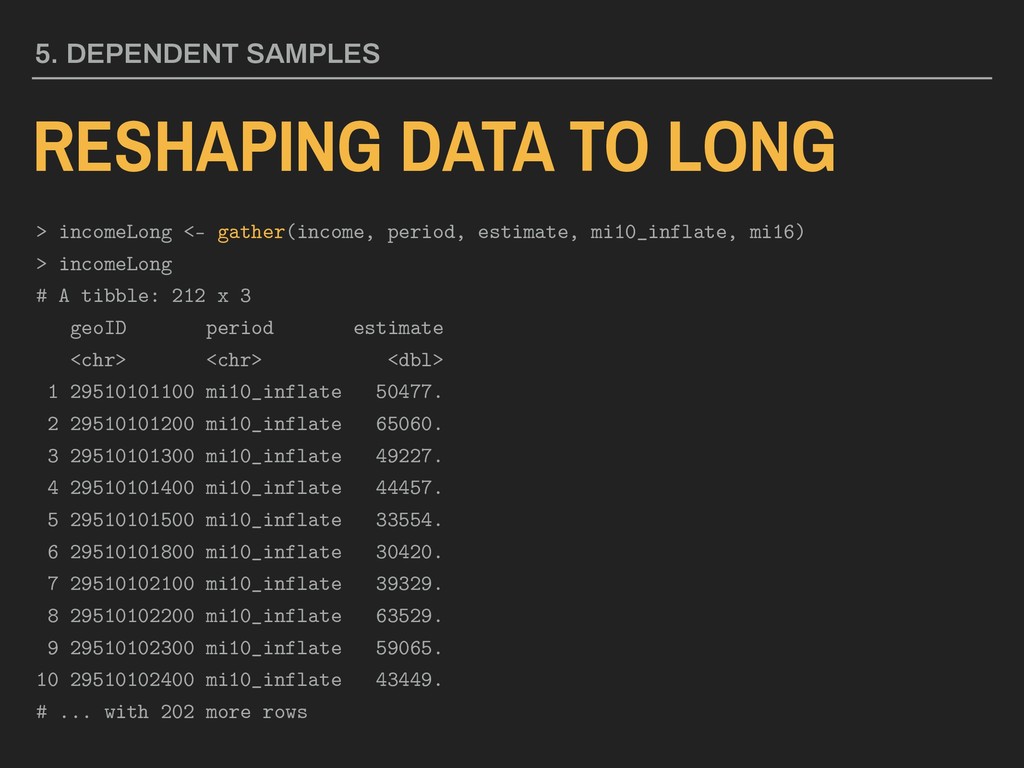
...) Using the stl_tbl_income data: > incomeLong <- gather(income, period, estimate, mi10_inflate, mi15) After you reshape, reordering observations (using dplyr::arrange()) and recoding the key (using dplyr::mutate()) are good practices. f(x)
name of the variable whose values will be used to create new variable names ▸ value is the name of variable containing your numeric data Available in tidyr Installed via CRAN with install.packages(“tidyverse”) 5. DEPENDENT SAMPLES RESHAPING DATA TO WIDE Parameters: spread(dataFrame, key, value) f(x)
name of the variable whose values will be used to create new variable names ▸ value is the name of variable containing your numeric data 5. DEPENDENT SAMPLES RESHAPING DATA TO WIDE Parameters: spread(dataFrame, key, value) f(x)
for assessing the difference means between two groups or time periods where probabilistic independence cannot be assumed. • H0 = The difference in means is approximately zero. • H1 = The difference in means is substantively greater than zero. 5. DEPENDENT SAMPLES What does the dependent t test accomplish?
dependent variable y contains continuous data 2. independent variable is binary (xg1 and xg2 ) 3. homogeneity of variance between xg1 and xg2 4. the distribution of the differences between xg1 and xg2 is approximately normally distributed 5. scores are dependent
variable for the first time period or grouping ▸ y2 is your variable for the second time period or grouping ▸ paired should always be TRUE Available in stats Installed with base R 5. DEPENDENT SAMPLES DEPENDENT T TEST Parameters: t.test(dataFrame$y1, dataFrame$y2, paired = TRUE) f(x)
variable for the first time period or grouping ▸ y2 is your variable for the second time period or grouping ▸ paired should always be TRUE 5. DEPENDENT SAMPLES DEPENDENT T TEST Parameters: t.test(dataFrame$y1, dataFrame$y2, paired = TRUE) f(x)
t-test data: income$mi10_inflate and income$mi15 t = 2.6556, df = 105, p-value = 0.009151 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 486.0955 3351.4629 sample estimates: mean of the differences 1918.779 5. DEPENDENT SAMPLES
value of t, the value of v, and the associated p value 2. The mean for each group (xg1 and xg2 ) 3. A plain English interpretation of any difference observed between xg1 and xg2 .
“real world” significance as opposed to the statistical significance - is the final a “small”, “medium”, or “large” effect? 6. EFFECT SIZES What is an effect size?
dependent (outcome) variable ▸ xVar is your independent variable ▸ pooled is a logical scalar; if FALSE, Welch’s corrected v is used ▸ paired should always be FALSE when used with an independent t test Available in effsize Installed via CRAN 6. EFFECT SIZES COHEN’S D Parameters: cohen.d(dataFrame$yVar ~ dataFrame$xVar, pooled = TRUE, paired = FALSE) f(x)
dependent (outcome) variable ▸ xVar is your independent variable ▸ pooled is a logical scalar; if FALSE, Welch’s corrected v is used ▸ paired should always be FALSE when used with an independent t test 6. EFFECT SIZES COHEN’S D Parameters: cohen.d(dataFrame$yVar ~ dataFrame$xVar, pooled = TRUE, paired = FALSE) f(x)
TRUE, paired = FALSE) Using the hwy and foreign* variables from ggplot2’s mpg data: > cohen.d(autoData$hwy ~ autoData$foreign, pooled = TRUE, paired = FALSE) # see output on next slide The cohen.d() function will temporarily convert string or logical variables to factors to compute the test. f(x)
= FALSE) Cohen's d d estimate: 1.51912 (large) 95 percent confidence interval: inf sup 1.224565 1.813675 Warning message: In cohen.d.formula(autoData$hwy ~ autoData$foreign, pooled = TRUE, : Cohercing rhs of formula to factor 6. EFFECT SIZES
variable for the first time period or grouping ▸ y2 is your variable for the second time period or grouping ▸ paired should always be TRUE 6. EFFECT SIZES COHEN’S D Parameters: cohen.d(dataFrame$y1, dataFrame$y2, paired = TRUE) f(x)
Using the stl_tbl_income data: > cohen.d(income$mi10_inflate, income$mi16, paired = TRUE) # see output on next slide f(x) The pooled parameter is not needed with paired data.
the desired value of 1-β (typically at least .8) ▸ sigLevel is the desired level (almost always .05) ▸ type is one of “one.sample”, “two.sample”, or “paired” ▸ alternative is always “two.sided” Available in pwr Installed via CRAN 7. POWER ANALYSES FINDING N Parameters: pwr.t.test(d = val, power = val, sig.level = val, type = type, alternative = “two.sided”) f(x)
the desired value of 1-β (typically at least .8) ▸ sigLevel is the desired level (almost always .05) ▸ type is one of “one.sample”, “two.sample”, or “paired” ▸ alternative is always “two.sided” 7. POWER ANALYSES FINDING N Parameters: pwr.t.test(d = val, power = val, sig.level = val, type = type, alternative = “two.sided”) f(x)
val, sig.level = val, type = type, alternative = “two.sided”) A moderate effect size (d = .5) with statistical power of .9: > pwr.t.test(d = .5, power = .9, sig.level = .05, type = “two.sample”, alternative = “two.sided”) # see output on next slide f(x)
= .05, type = "two.sample", alternative = "two.sided") Two-sample t test power calculation n = 85.03128 d = 0.5 sig.level = 0.05 power = 0.9 alternative = two.sided NOTE: n is number in *each* group 7. POWER ANALYSES
video lecture will be posted about working with factors and strings. REMINDERS 7. BACK MATTER Lab 08 (from next week) and Lecture Prep 09 (for lecture 10) are due before lecture 10. Lab 07 and Problem Set 04 (from today) are due before lecture 10.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}