Understand product constraints and only send data that makes sense ▸ Value flexibility above all else, and will self-regulate ▸ … also be OK with limits on the # of k/v pairs per event (to prevent combinatorial explosion of Cassandra writes) AKA, USERS WILL…
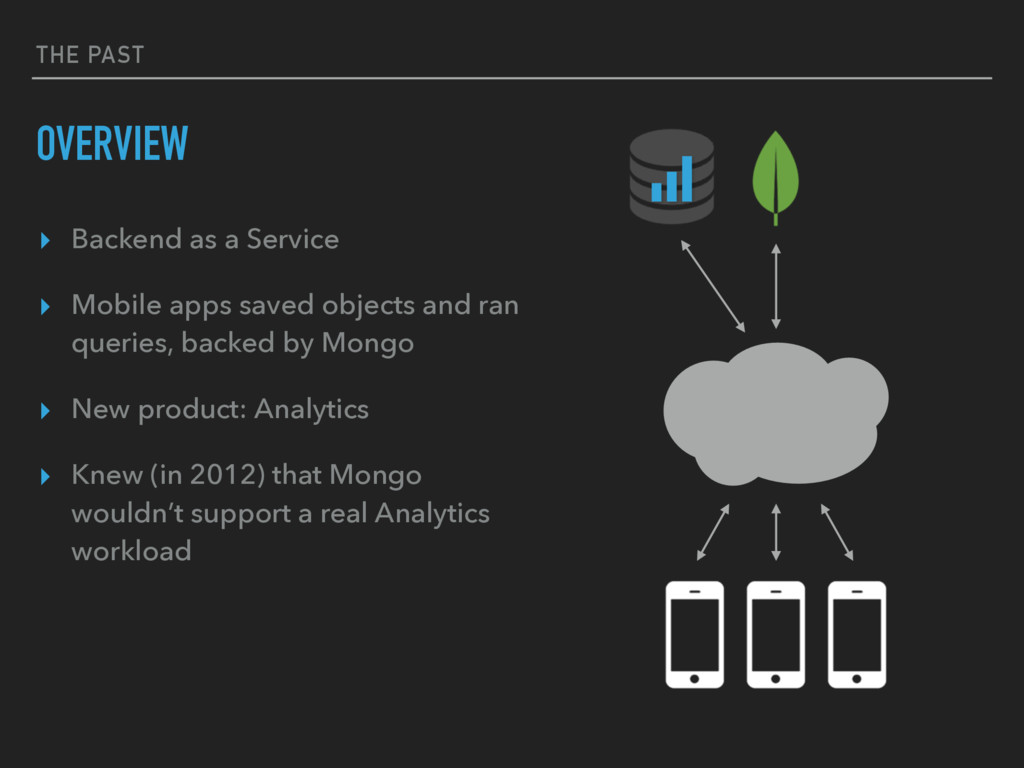
to store all dimension keys/values to generate time series row keys ▸ Started off with documents in Mongo + write-through cache "api_key": { "ApiRequest": { "platform": ["ios", "android"], "method": ["get", "post", "put"] } } MONGO "api_key:ApiRequest:ios:get:201604": { 0: 150, 1: 29, ... } CASSANDRA WHICH WORKED GREAT! UNTIL…
with granularity of 1 month ▸ Random partitioning + relying on write-time fanout to spread load ▸ Still ran into hotspots ▸ Nodes were CPU bound (compaction!) ▸ Ran Cassandra 1.1.8 (no vnodes, yet) ▸ Solution should theoretically "linear"ly scale, required exponential ▸ All things considered, Cassandra itself was fine; our requirements were not.
practices suggestions ▸ Don’t trust the user to "do what’s right," especially when assumptions abound ▸ Extreme "flexibility" benefits no one ▸ "Random" distribution of data isn’t good enough ▸ Write-time aggregation is not the future THANKS! @CYEN
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}