Empirical Software Engineering paper on software microbenchmark result variability and reliability when executed in cloud environments, by Christoph Laaber, Joel Scheuner, and Philipp Leitner. Presented at the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE’ 19), November 11–15, 2019, San Diego, CA, USA.
{kind=link}
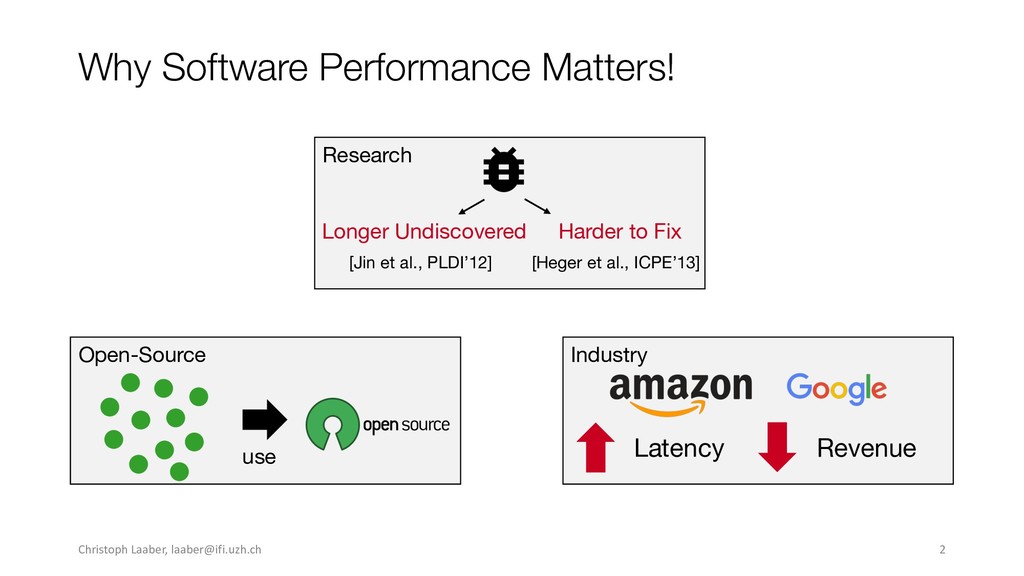{kind=link}
{kind=link}
{kind=link}
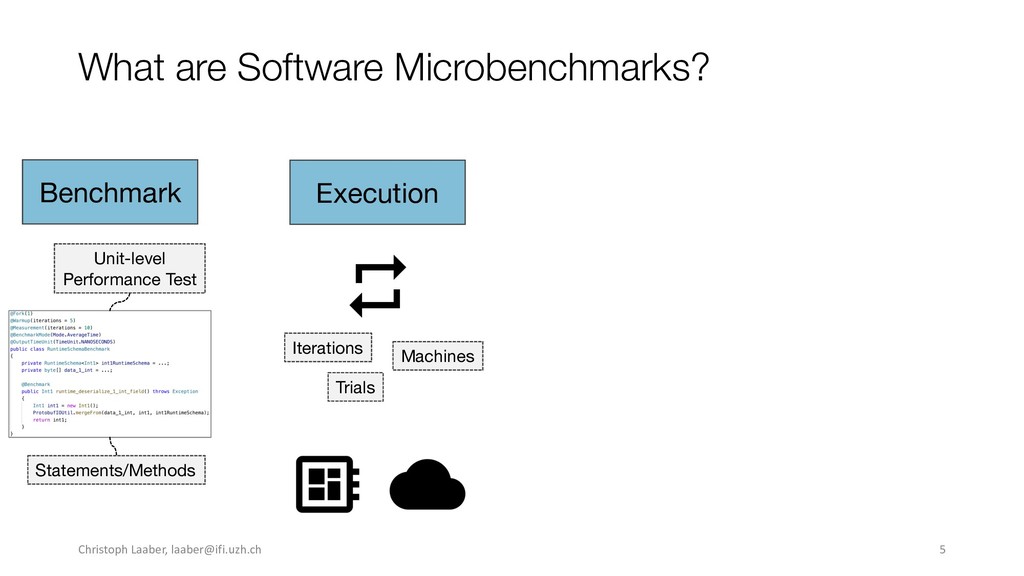{kind=link}
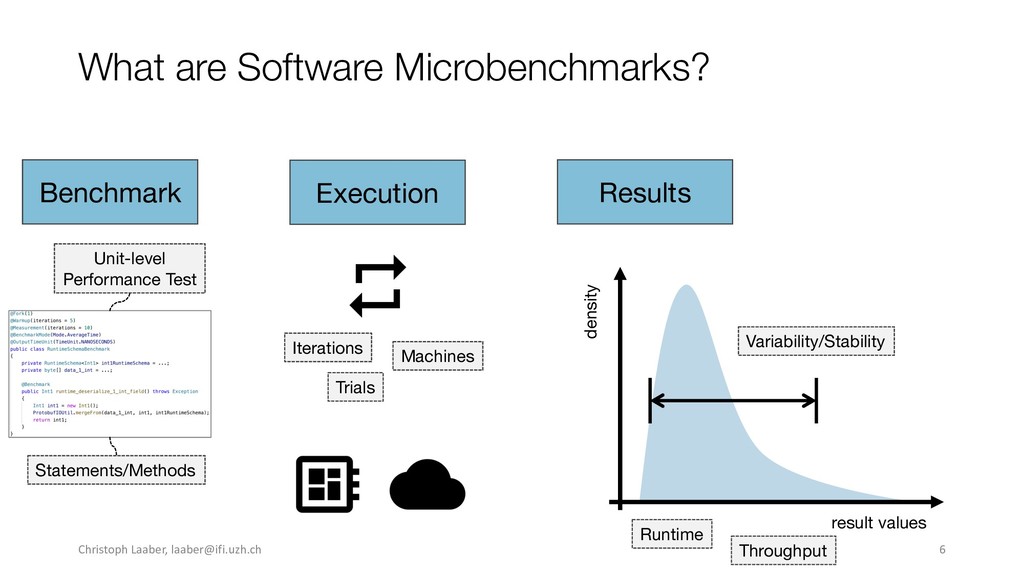{kind=link}
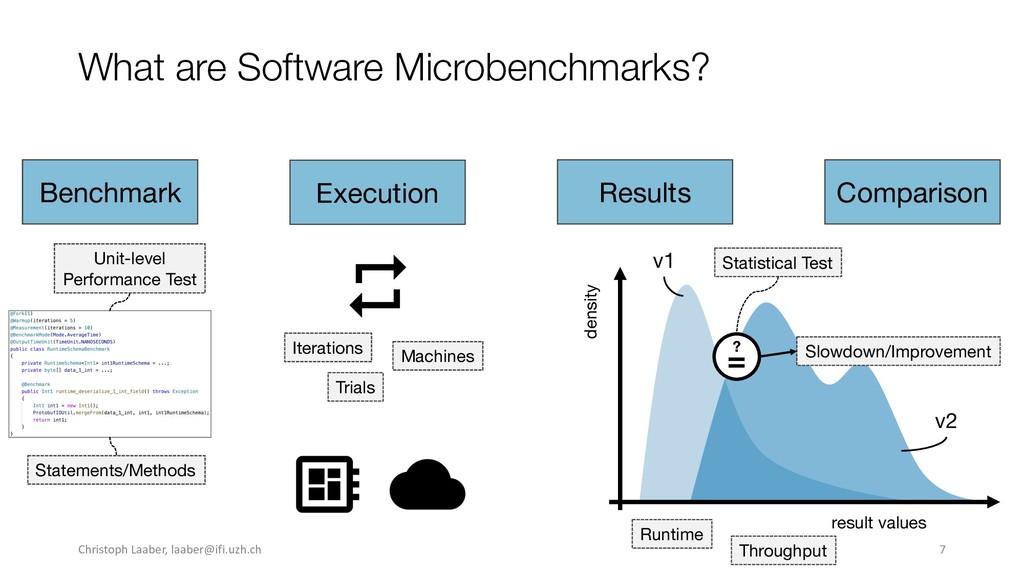{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
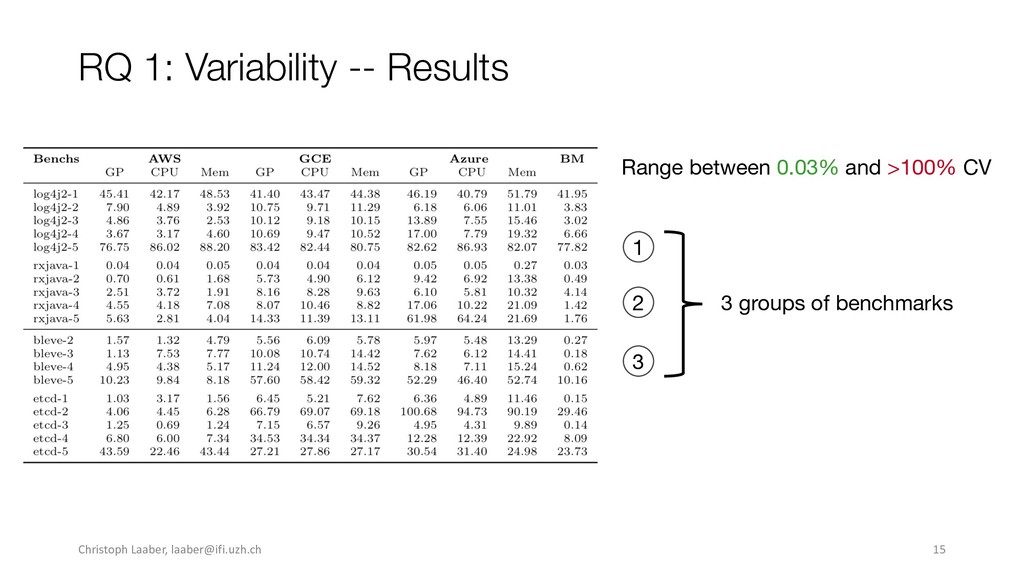{kind=link}
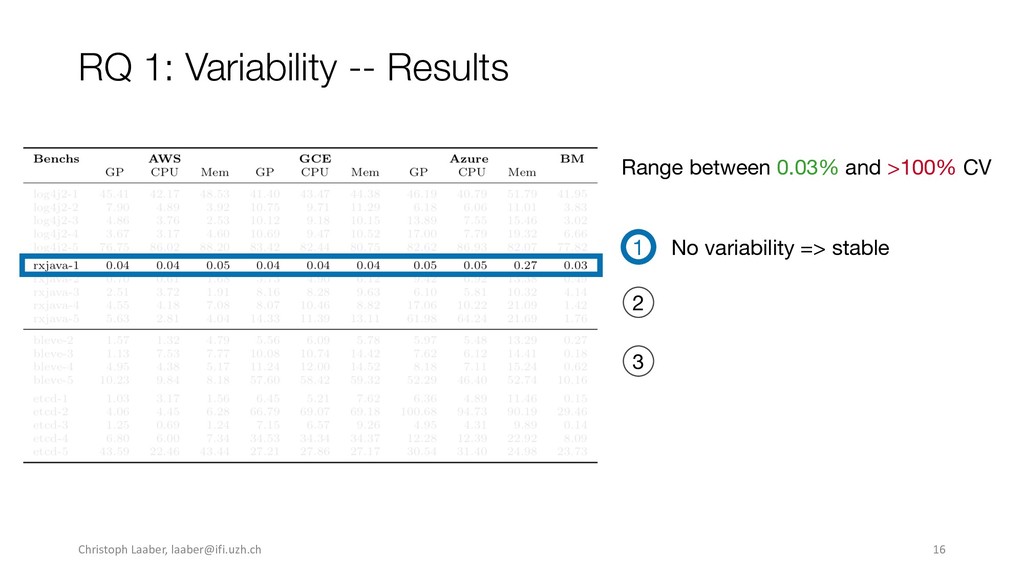{kind=link}
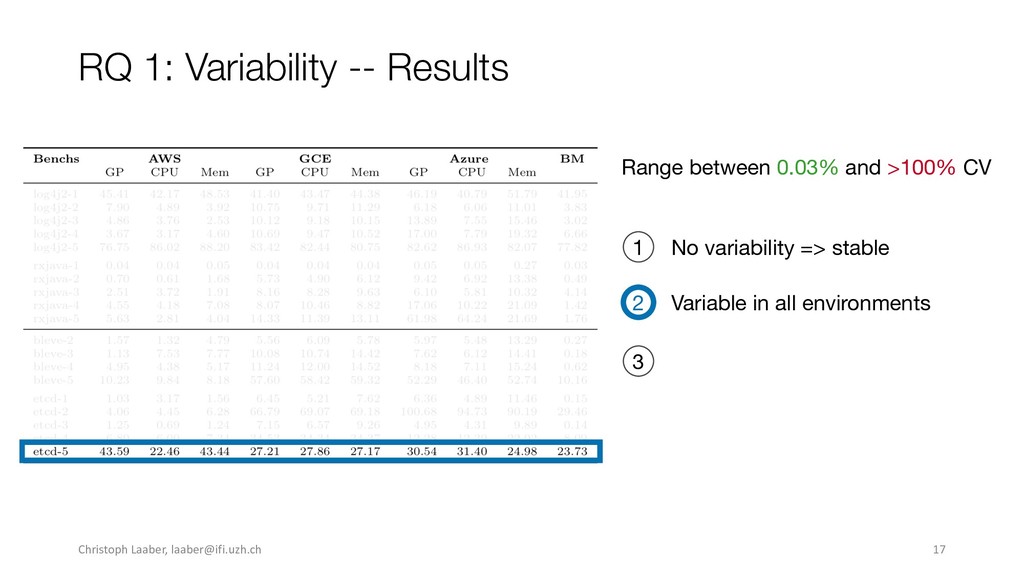{kind=link}
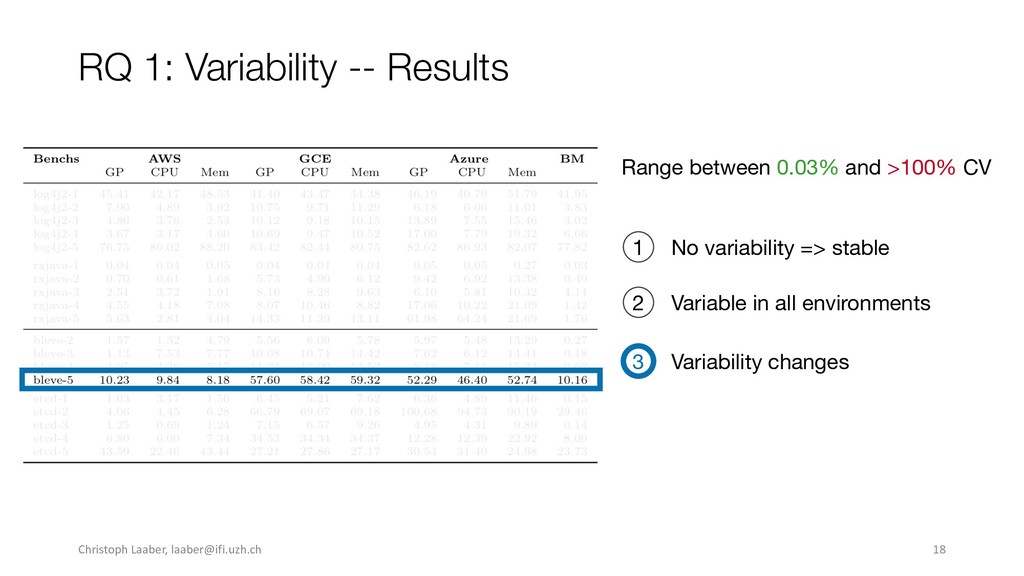{kind=link}
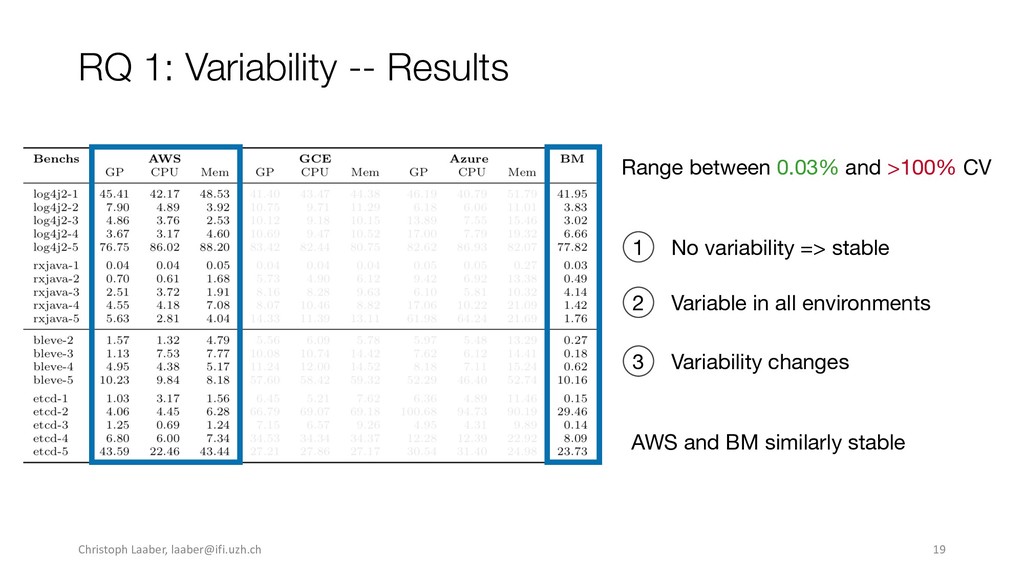{kind=link}
{kind=link}
{kind=link}
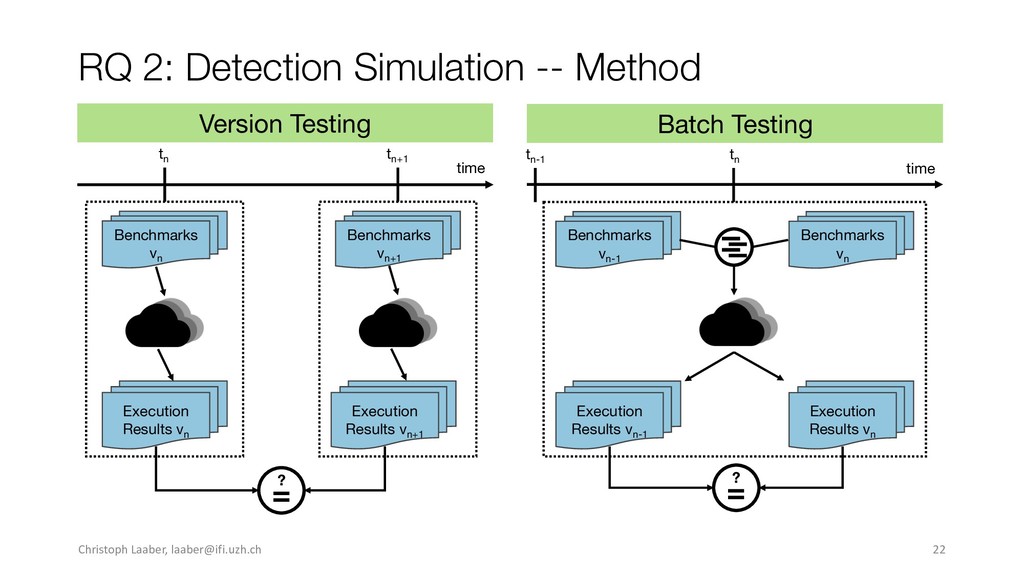{kind=link}
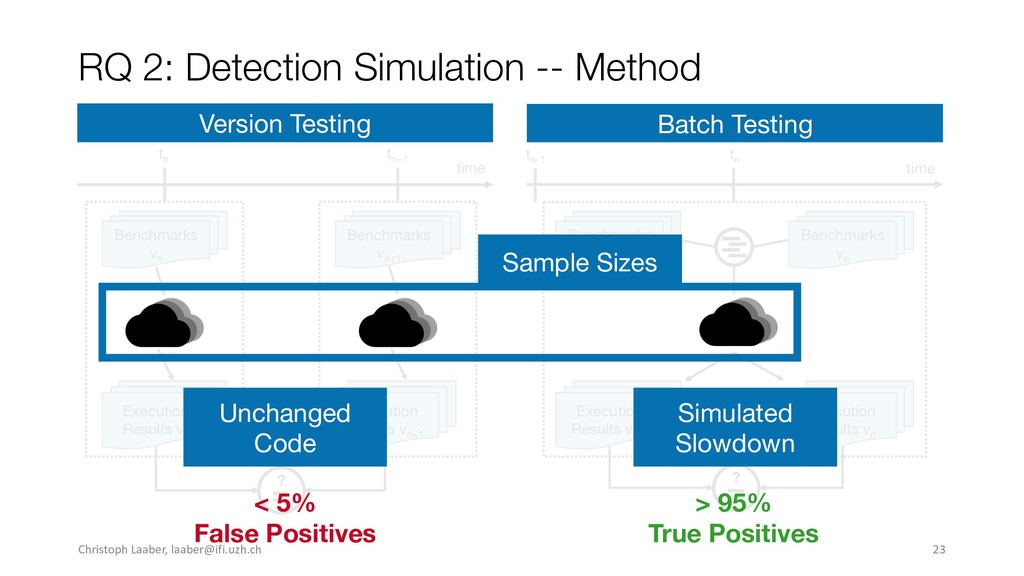{kind=link}
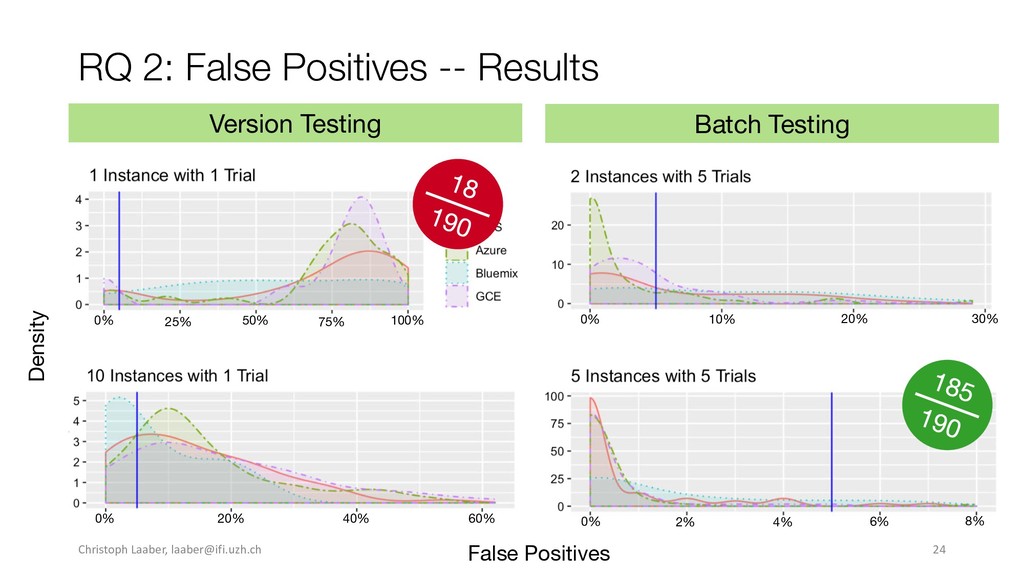{kind=link}
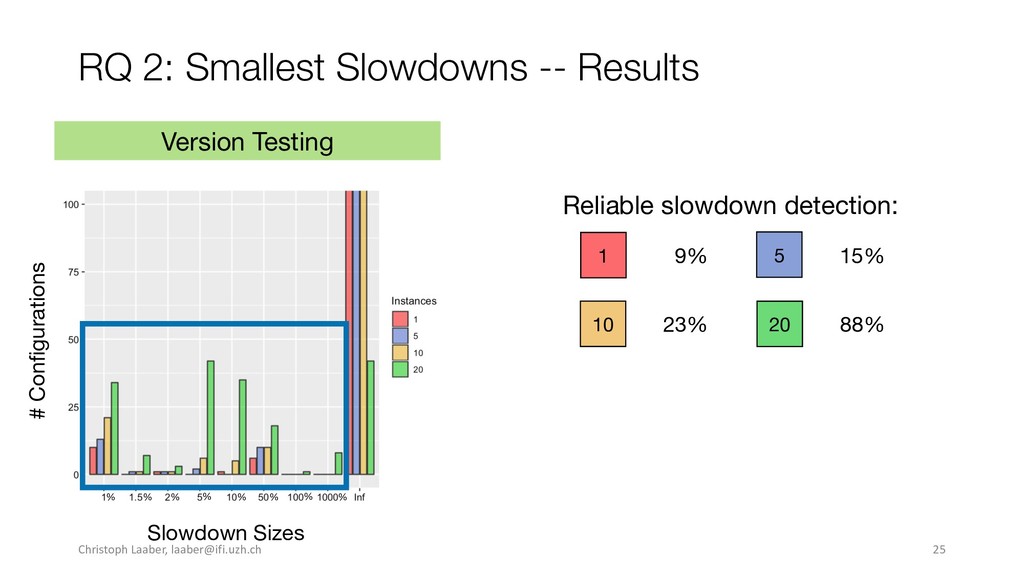{kind=link}
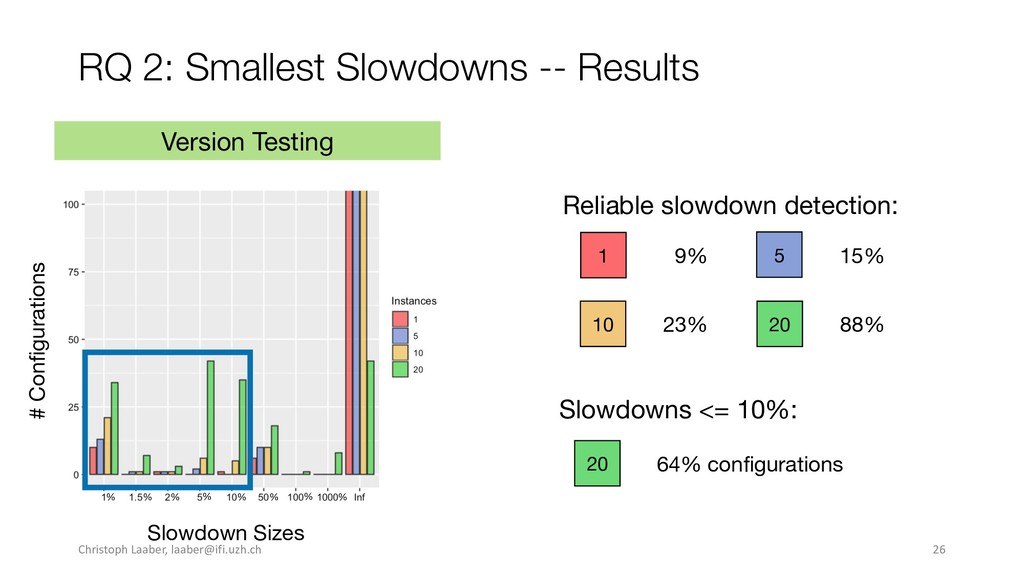{kind=link}
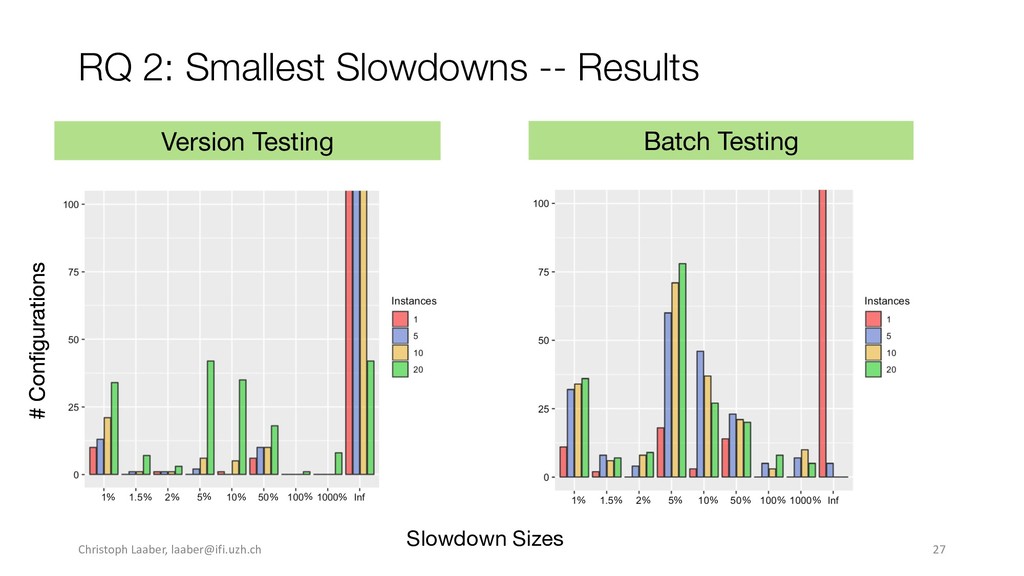{kind=link}
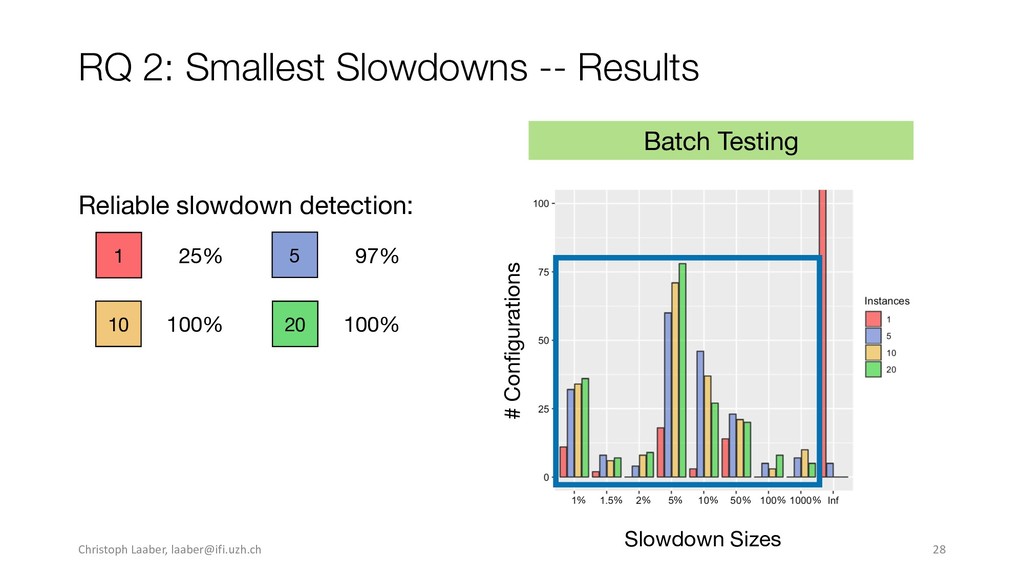{kind=link}
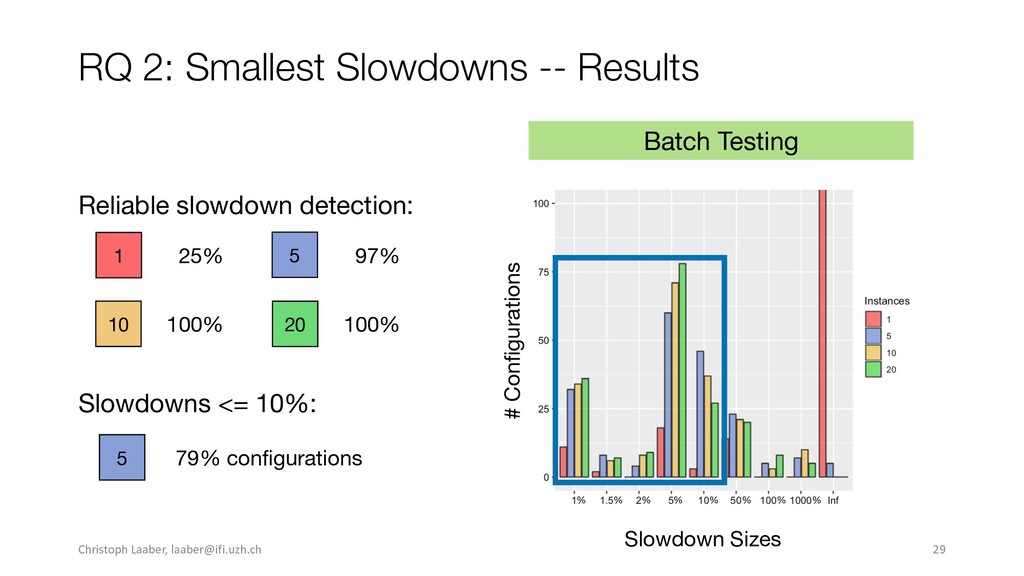{kind=link}
{kind=link}
{kind=link}
![@ChristophLaaber [email protected] Software Microbenchmarking in the Cloud. How Bad is](https://files.speakerdeck.com/presentations/bf7b73be68fe4842b145baeb7459976c/slide_31.jpg){kind=link}
{kind=link}