https://2014.codefest.ru/lecture/781
Я расскажу про поддержку слабо-структурированных данных в PostgreSQL, начиная от ключ-значение (hstore) к документо-ориентированному хранилищу (json). Расскажу, что случилось с проектом hstore v2 (nested hstore) и как наша работа стала основанием для нового типа jsonb. Новый тип jsonb добавляет к json наличие настоящего бинарного хранилища и высокопроизводительные индексные методы доступа.
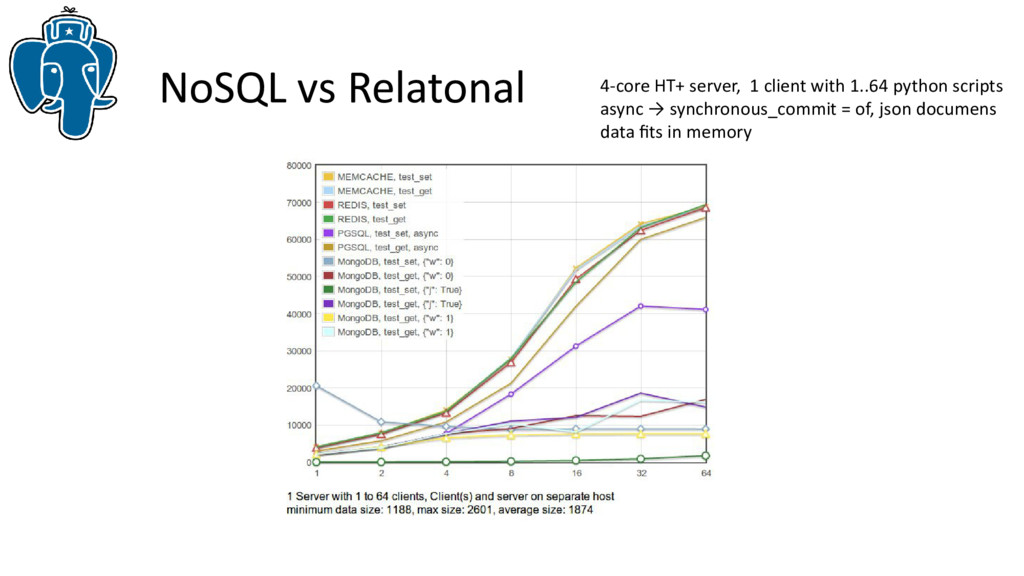
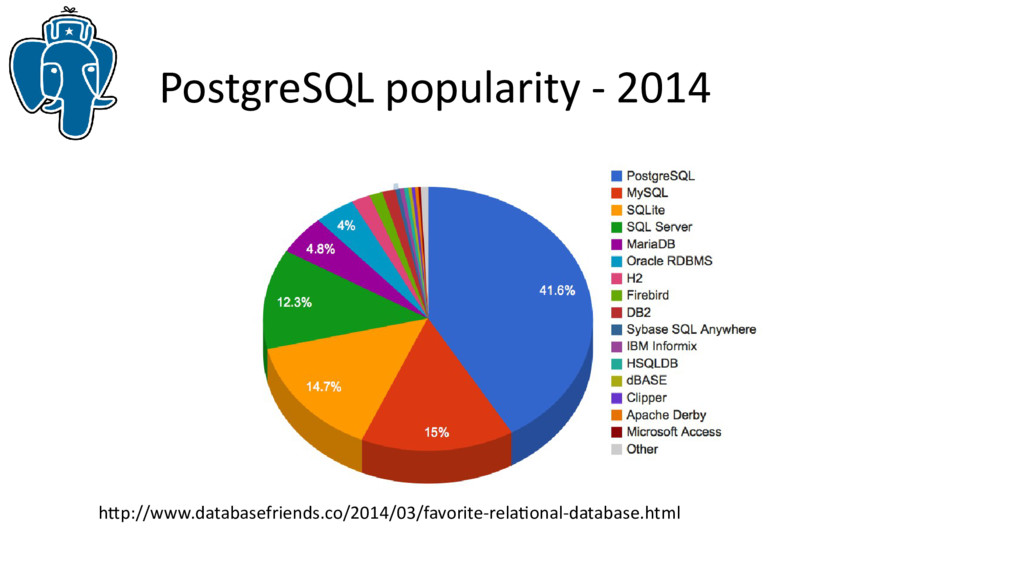
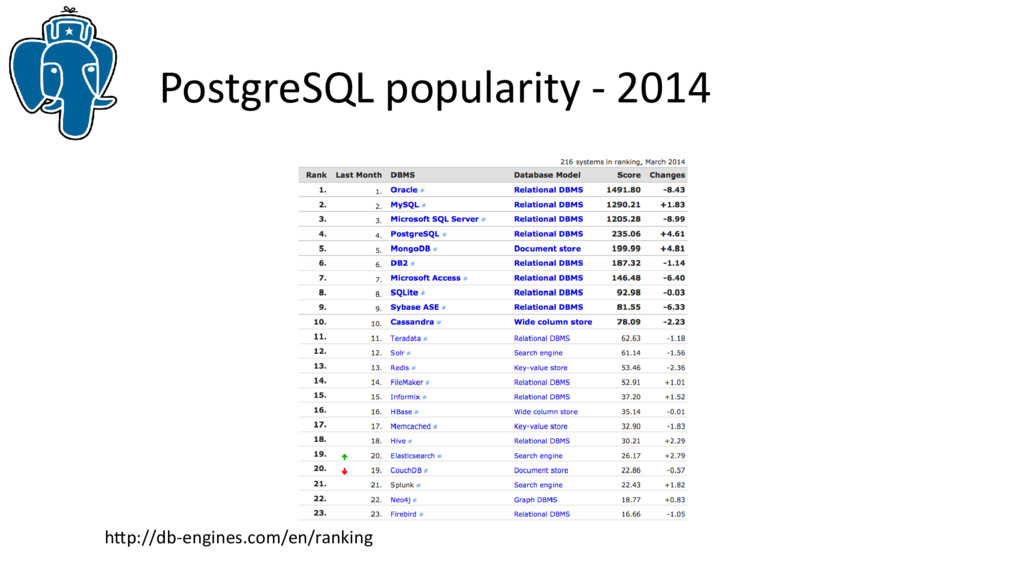
Не секрет, что успех MongoDB в первую очередь связан со встроенной поддержкой json, однако, парадигма NoSQL для большинства проектов не нужна или не подходит, так что PostgreSQL предоставит разработчикам дополнительные возможности для эффективной работы с популярным форматом json, оставаясь в рамках реляционной СУБД. Более того, предварительные тесты показывают производительность сравнимую, а иногда и лучше, чем MongoDB.
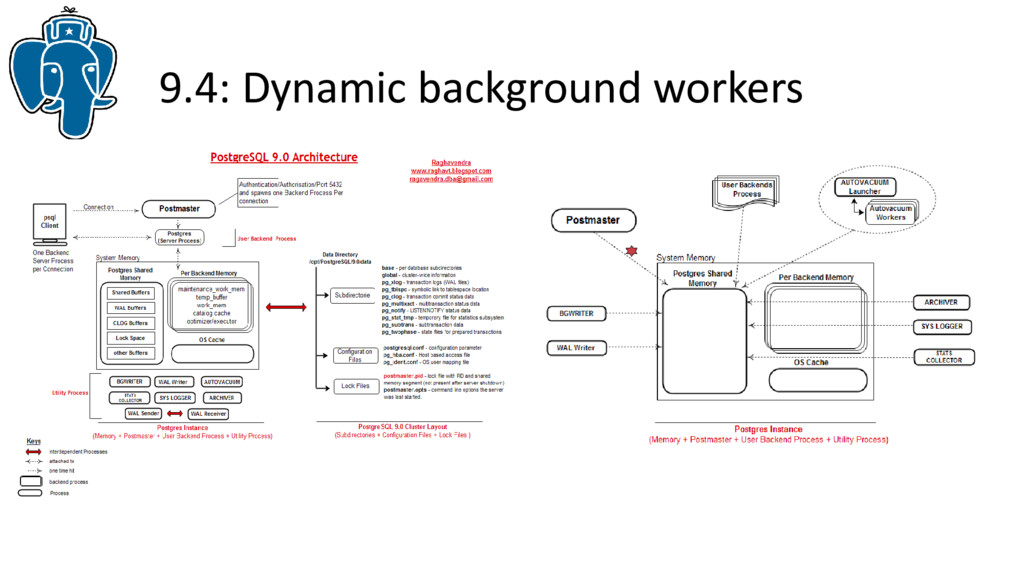
Кроме того, я расскажу про новые разработки, которые ведутся в рамках новой версии PostgreSQL 9.4.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}