taken with text using relative proportional emphasis A dimension is a latent variable constructed from counts Methodological claims: models of position have a relative proportional emphasis interpretation, usually via logits, wrapped around an embedded low rank approximation SFB Workshop, October 2012
taken with text using relative proportional emphasis A dimension is a latent variable constructed from counts Methodological claims: models of position have a relative proportional emphasis interpretation, usually via logits, wrapped around an embedded low rank approximation There’s only one way to do it SFB Workshop, October 2012
theory: show how existing models are the way to do it, approximations of the way to do it, or special cases of the way to do it SFB Workshop, October 2012
theory: show how existing models are the way to do it, approximations of the way to do it, or special cases of the way to do it Practical consequences: new models, new estimation procedures, new uncertainty measures SFB Workshop, October 2012
it’s tractable Assume word parameters and ˛ are well estimated Re-parameterise as Multinomial Use 2nd derivative of the profile Likelihood to compute each „’s standard error No more deeply coupled ¸s to worry about. . . (This is what Austin does) SFB Workshop, October 2012
word parameters known partial bootstrap (Lebart, 2007), word parameters known (identical?) parametric bootstrap (Slapin and Proksch, 2007) multinomial bootstrap (Lowe and Benoit 2010, 2011) block bootstrap (Lowe and Benoit 2010, 2011) Reviewed in Lowe and Benoit (forthcoming) SFB Workshop, October 2012
word parameters known partial bootstrap (Lebart, 2007), word parameters known (identical?) parametric bootstrap (Slapin and Proksch, 2007) multinomial bootstrap (Lowe and Benoit 2010, 2011) block bootstrap (Lowe and Benoit 2010, 2011) Reviewed in Lowe and Benoit (forthcoming) Path not taken: multinomial re-parameterisation is symmetrical, so we can construct a nice Gibbs sampler this way SFB Workshop, October 2012
—ij = – = – + –R i = – + –C i = – + –R i + –C j (independence) = – + –R i + –C j + –RC ij (saturated) Problem: all the action in a word frequency matrix is in the interaction terms SFB Workshop, October 2012
approximation in a statistical model log —ij = – + –R i + –C j + ui ff vj Fun fact: Discretize a bivariate Normal distribution with correlation coefficient and fit an RC model. Then ff = =(1 ` 2) SFB Workshop, October 2012
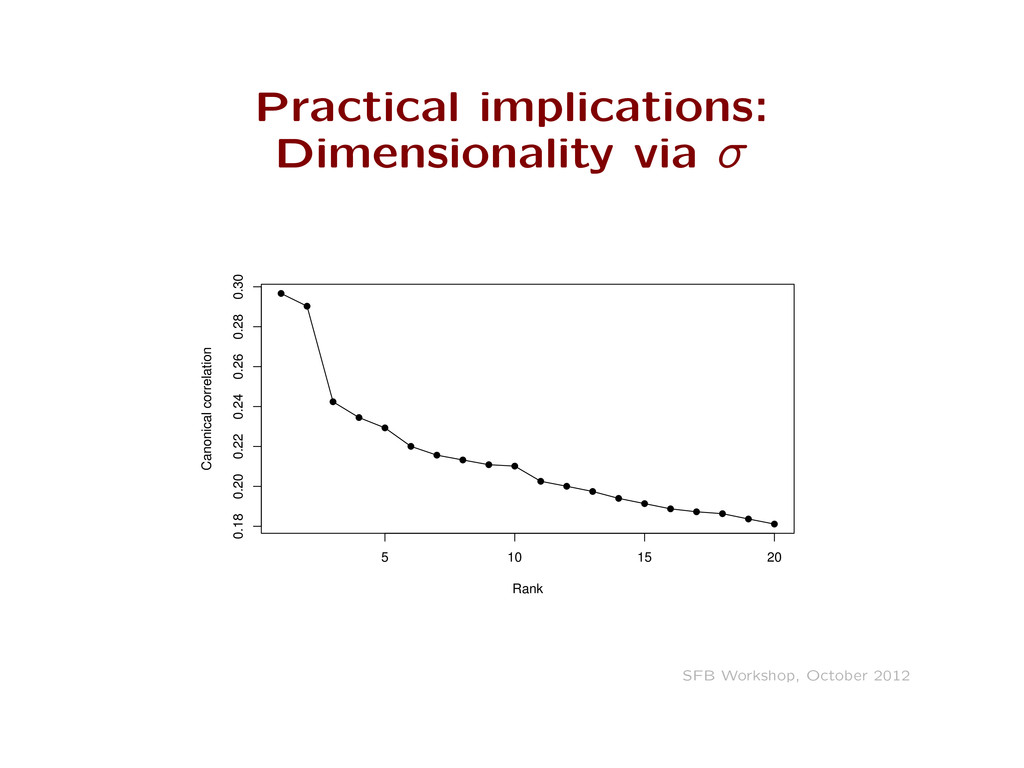
ui = X vj = 0 X u2 i = X v2 j = 1 X –R i = X –C j = 0 For rank m>1 reconstructions us and vs need to be orthogonal (for comparison with CA, weight these averages by the row and column marginals) Stop reading the footers and pay attention
log —ij = –R i + (–C j + –) + ui (ff vj) = ¸i + j + „i ˛j and change the identification strategy ¸1 = 0 X „i = 0 X „2 i = 1 This is Wordfish (Slapin and Proksch, 2007) SFB Workshop, October 2012
by changes to ¸ Wordfish is not (Likelihood) identified Fortunately a ridge prior on ˛ is sufficient for ‘posterior’ identification (Not really a “technical issue”, as suggested in S&P 2007. . . ) SFB Workshop, October 2012
standard deviation of ˛ Wordfish to RC RC to Wordfish u ` „ „ ` u v ` (˛ ` m)=s ˛ ` vff + m ff ` s r ` ¸ + „m a ` – + –R ` „m –R ` r ` — r ¸ ` a ` a1 –C ` –C ` — –C ` –C + a1 – ` — r + — –C SFB Workshop, October 2012
theory (Goodman, Haberman, Gilula, Becker) for free from the RC model literature, e.g. diagnostics, including for extra dimensions model extensions, e.g. parameterised „, K-way tables two more estimation algorithms SFB Workshop, October 2012
directly from counts Construct word probabilities P from C (divide by total). P margins are r and c so expected probabilities under independence are rcT SFB Workshop, October 2012
directly from counts Construct word probabilities P from C (divide by total). P margins are r and c so expected probabilities under independence are rcT Decompose the residuals from independence P ` rcT p rcT = U˚V T ı u ff vT (thin SVD) SFB Workshop, October 2012
ı ri cj (1 + ui ff vj) This is also a type of unfolding model for count data (ter Braak, 1981) Positions u and v closely approximate „ and ˛ when ff is small Not surprising. . . Log both sides and compare to RC model SFB Workshop, October 2012
reciprocal averaging: ui ` X j Cijvj=C+j vj ` X i Cijui=Ci+ which converges on the first singular vectors (Hill, 1979 Prop.1) SFB Workshop, October 2012
reciprocal averaging: ui ` X j Cijvj=C+j vj ` X i Cijui=Ci+ which converges on the first singular vectors (Hill, 1979 Prop.1) Fortunately there are newer, better ways, e.g. implicitly-restarted Lanczos bidiagonalizations (Baglama and Reichel, 2005) SFB Workshop, October 2012
know scores u for ‘reference’ documents treat document with unknown scores as out-of-sample (‘virgin documents’) then we can compute word ‘scores’ v in one step, and new documents scores in one more step. SFB Workshop, October 2012
know scores u for ‘reference’ documents treat document with unknown scores as out-of-sample (‘virgin documents’) then we can compute word ‘scores’ v in one step, and new documents scores in one more step. This is Wordscores (Laver et al. 2003; Lowe, 2008) SFB Workshop, October 2012
as in-sample and estimating their scores Beats Wordscores on its own toy non-stochastic example! 5 reference document scores, one unknown true value `0:45 Wordscores `0:448 plus 8 iterations `0:450 Started in the right direction, then stopped. SFB Workshop, October 2012
as in-sample and estimating their scores Beats Wordscores on its own toy non-stochastic example! 5 reference document scores, one unknown true value `0:45 Wordscores `0:448 plus 8 iterations `0:450 Started in the right direction, then stopped. This will also work for Wordfish. . . SFB Workshop, October 2012
Fix positions on > 2 ‘reference’ documents Only update positions of other documents Unit normalise as before (yes, this maintains reference scores!) SFB Workshop, October 2012
reference score strategy work well? How do we build models of document position? (for CA this is known) How do we scale up to serious numbers of documents SFB Workshop, October 2012
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}