estimation of levy processes. CIRJE-F-272, Graduate School of Economics, University of Tokyo, 2004. [2] Art B. Owen. Empirical likelihood ratio confidence intervals for a single functional. Biometrika, Vol. 75, No. 2, pp. 237–249, 1988. [3] Art Owen. Empirical likelihood ratio confidence regions. Ann. Statist., Vol. 18, No. 1, pp. 90–120, 03 1990.
and general estimating equations. Ann. Statist., Vol. 22, No. 1, pp. 300–325, 03 1994. [5] Ngai Hang Chan, Song Xi Chen, Liang Peng, and Cindy Long Yu. Empirical likelihood methods based on characteristic functions with applications to lévy processes. 2009. [6] A.B. Owen. Empirical Likelihood. Chapman & Hall/CRC Monographs on Statistics & Applied Probability. CRC Press, 2001.
B. W. Stuck. A method for simulating stable random variables. Journal of the American Statistical Association, Vol. 71, No. 354, pp. 340–344, 1976. [8] 平場誠示 (Seiji HIRABA). Lévy 過程 (Lévy Processes). https://www.ma.noda.tus.ac.jp/u/sh/pdfdvi/ Levy.pdf, 2018.
![レヴィ過程の経験尤度推定 [1] の紹介 2019 年 10 月 10 日 三原](https://files.speakerdeck.com/presentations/82838594d8d54323a9ea389aa920340d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![はじめに 特性関数のパラメータを推定する方法に経験尤度[2][3] を用い る方法がある。 経験尤度法 [4] では、分布の確率密度関数の代わりに、分布上 での期待値が 0 になるべき何らかのパラメトリックな確率変数](https://files.speakerdeck.com/presentations/82838594d8d54323a9ea389aa920340d/slide_4.jpg){kind=link}
{kind=link}
![はじめに 特性関数 ϕ(t) ≡ E[eitX] は eitX の期待値なので、これを経験尤 度による分布上の期待値 n](https://files.speakerdeck.com/presentations/82838594d8d54323a9ea389aa920340d/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
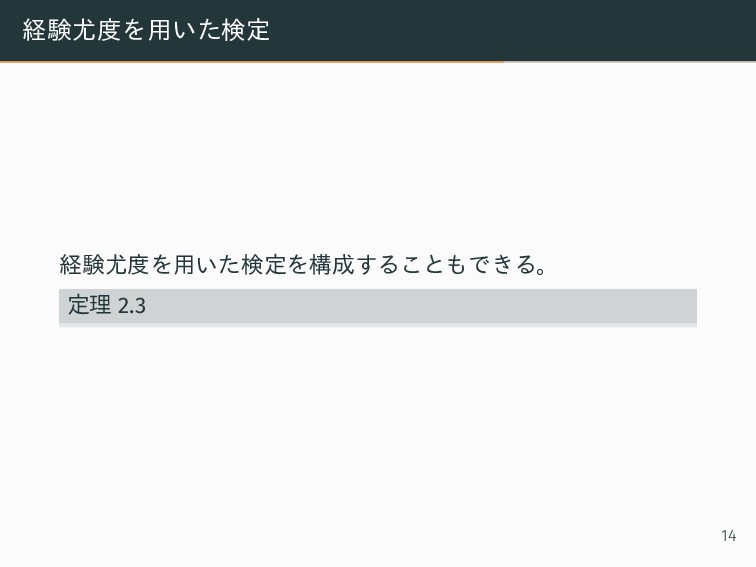{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Appendix. レヴィ過程の概要 [8] レヴィ過程とは、添え字 0 でとる値がほとんど確実に 0 であ り、独立増分性と時間的一様性と確率連続性をもち、見本関数 が右連続左極限関数であるような確率過程である。](https://files.speakerdeck.com/presentations/82838594d8d54323a9ea389aa920340d/slide_31.jpg){kind=link}
![参考文献 i [1] Kunitomo Naoto and Takashi Owada. Empirical likelihood](https://files.speakerdeck.com/presentations/82838594d8d54323a9ea389aa920340d/slide_32.jpg){kind=link}
![参考文献 ii [4] Jin Qin and Jerry Lawless. Empirical likelihood](https://files.speakerdeck.com/presentations/82838594d8d54323a9ea389aa920340d/slide_33.jpg){kind=link}
![参考文献 iii [7] J. M. Chambers, C. L. Mallows, and](https://files.speakerdeck.com/presentations/82838594d8d54323a9ea389aa920340d/slide_34.jpg){kind=link}