[Video of talk](https://www.youtube.com/watch?v=XPbiwxa2UfU)
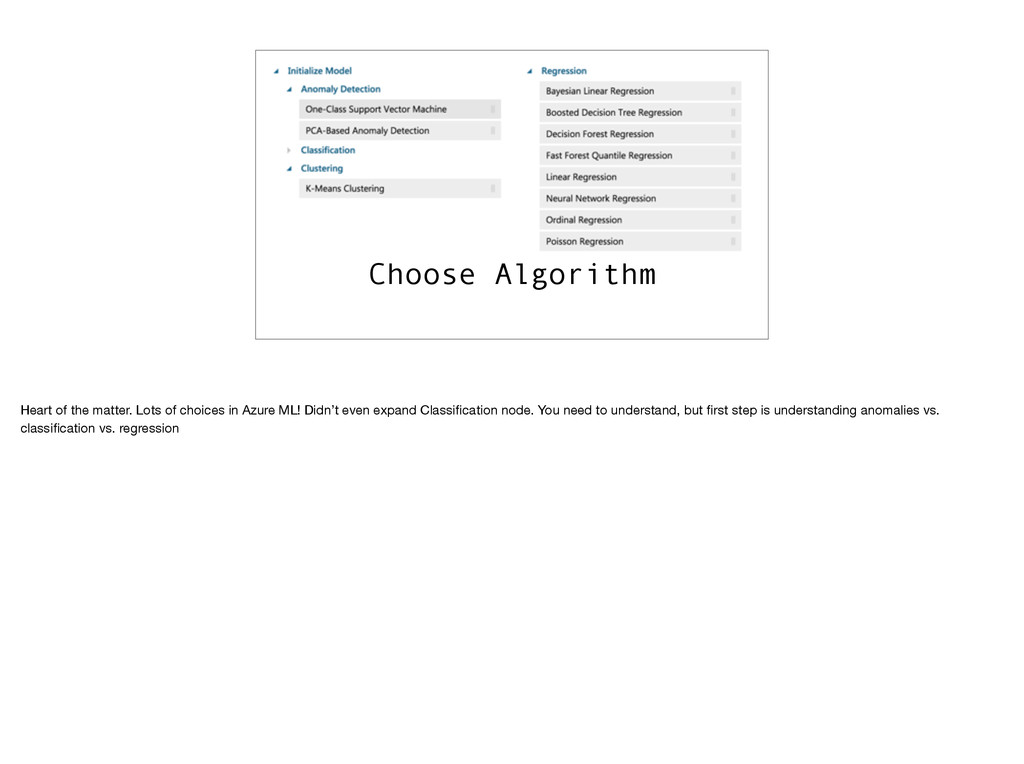
Azure Machine Learning provides an unusual mix of features designed to allow you to easily create "predictions as a service." There is integration with existing Azure data services, including HDInsight, a click and drag visual editor for creating machine learning experiments, and integration with the R language and libraries. The aim is to have a product which allows beginners to get started in machine learning while still delivering the features experts require. Does it deliver? We will build an experiment to predict cancer diagnoses based on observed characteristics of diagnostic imaging. We will also compare what we have built with other systems which attempt to solve the same class of problems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Sets • Training Set • [Cross] Validation Set •](https://files.speakerdeck.com/presentations/888433047fb44a17b9feacc902eeb146/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
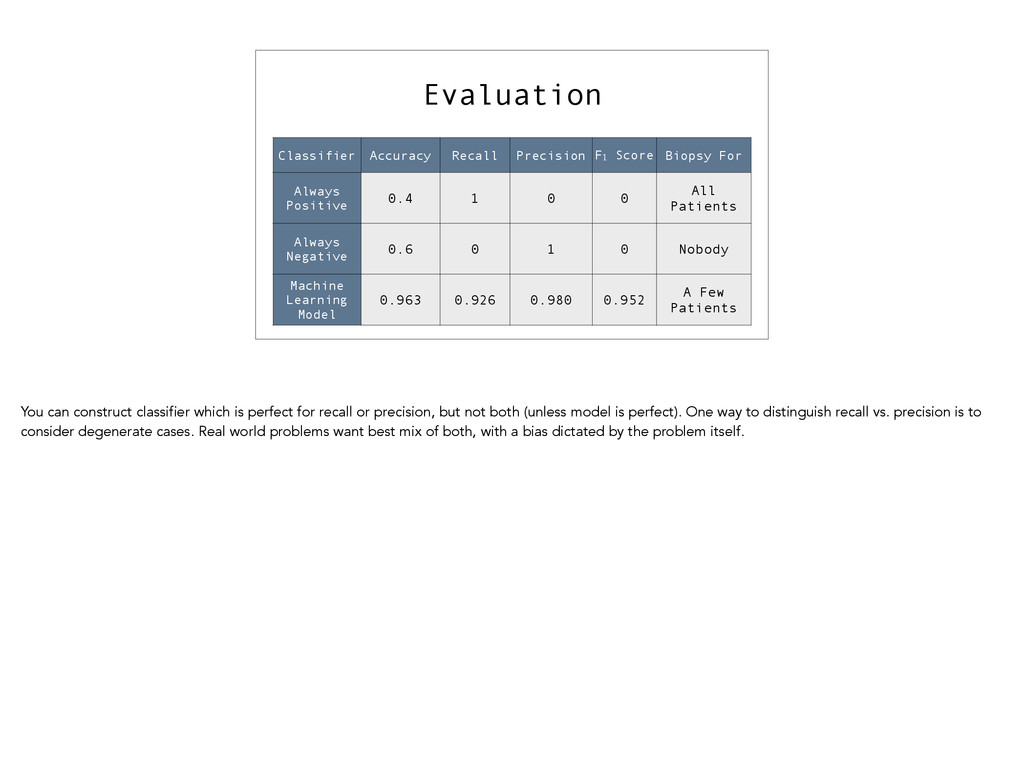{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
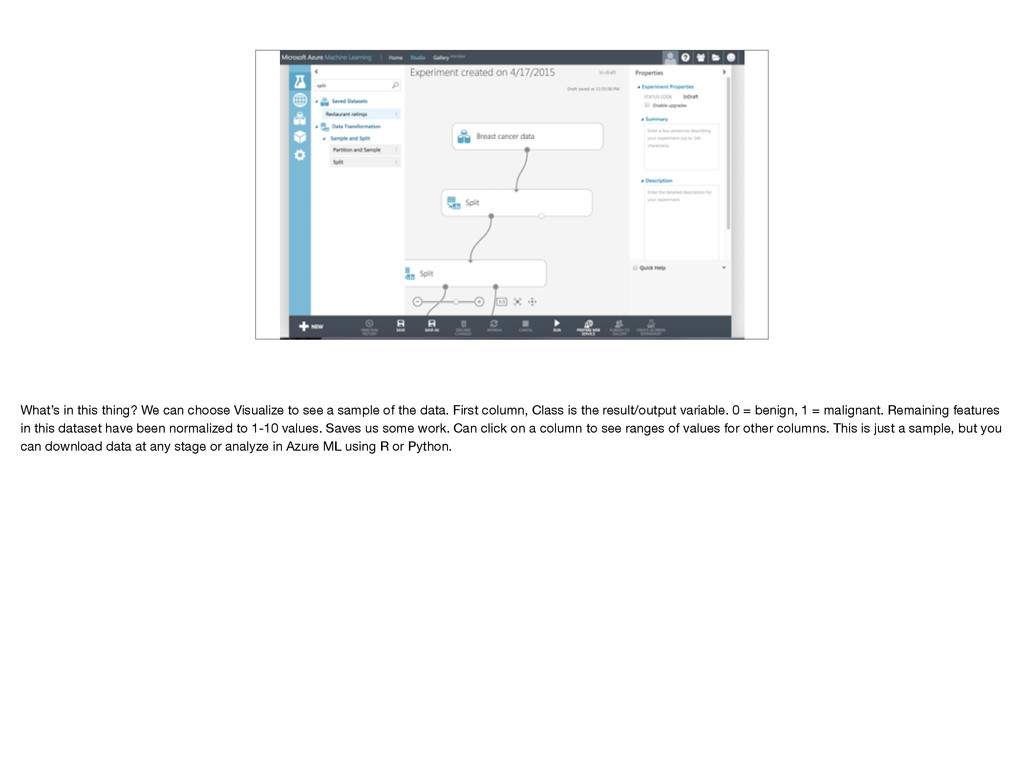{kind=link}
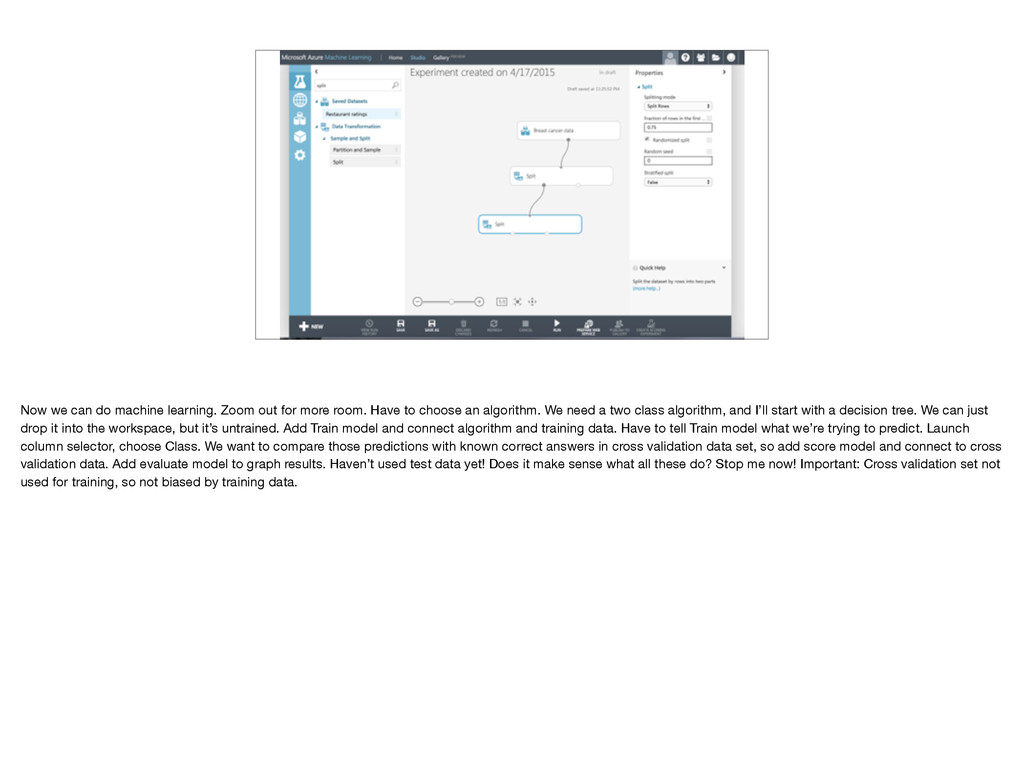{kind=link}
{kind=link}
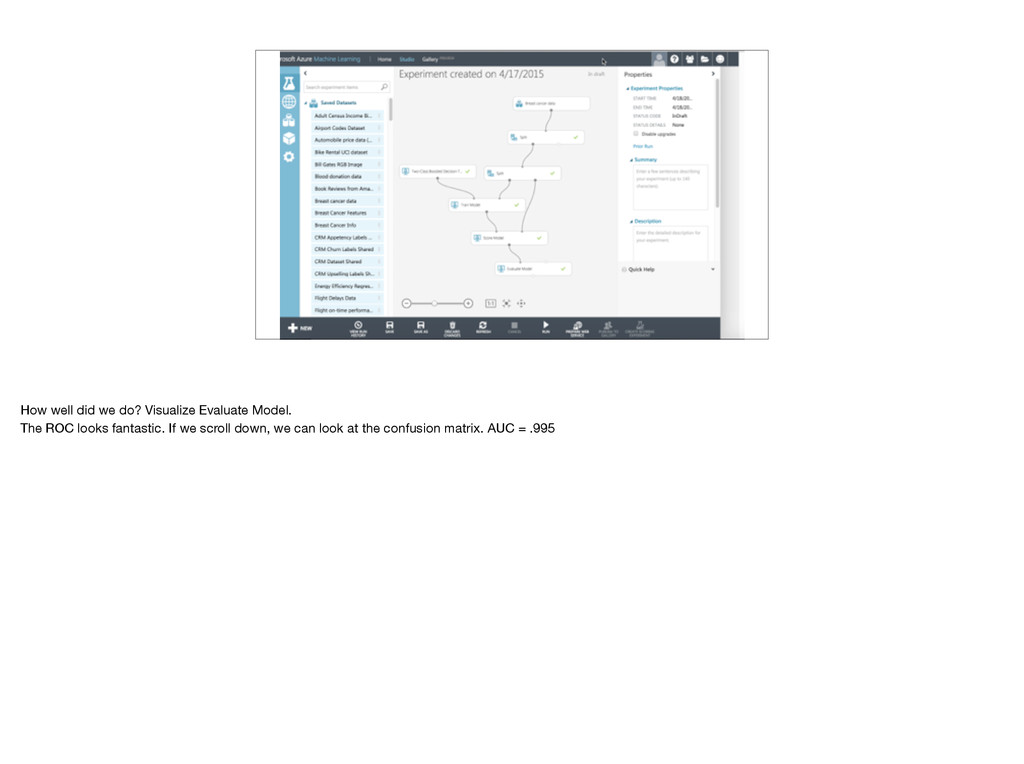{kind=link}
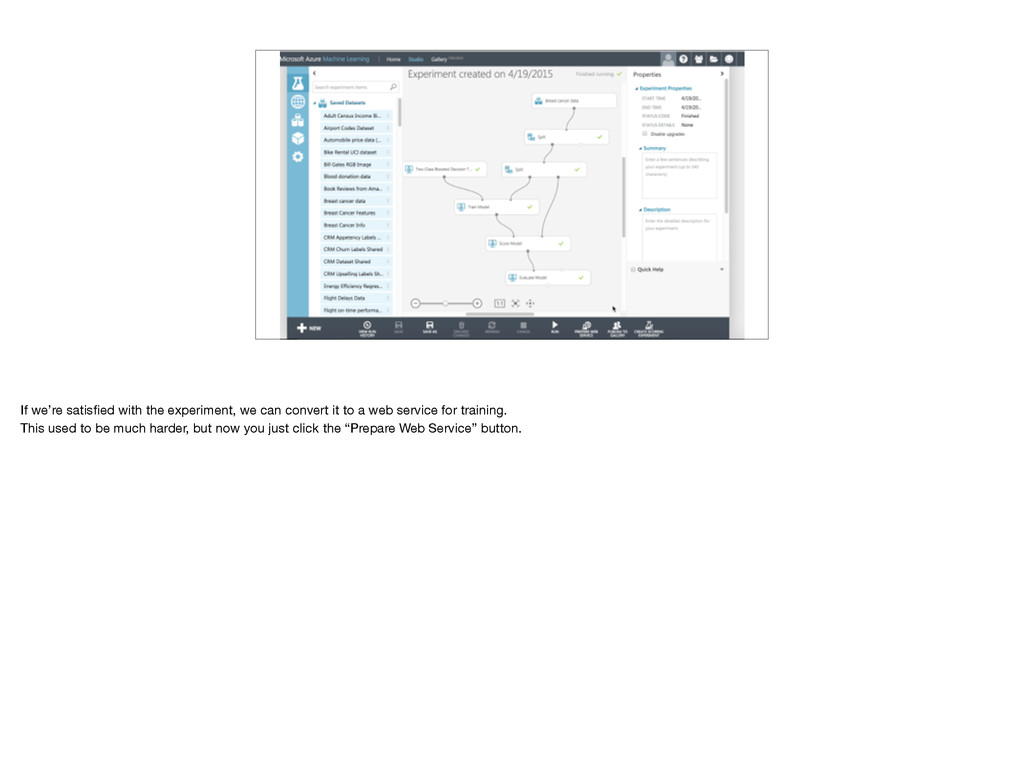{kind=link}
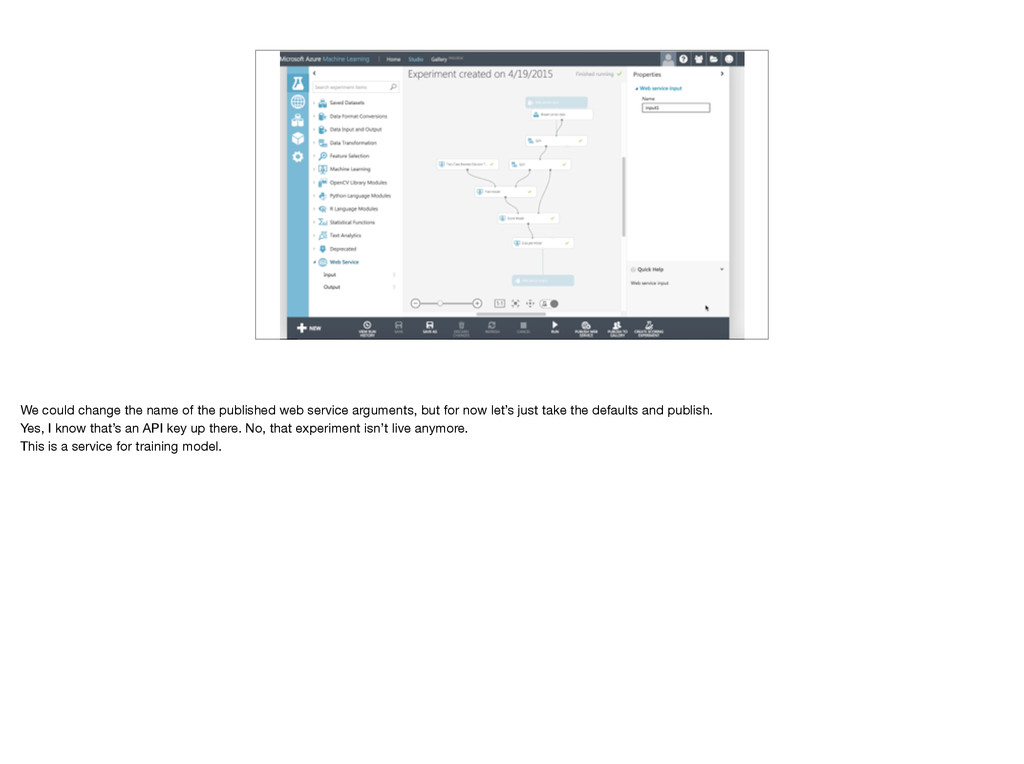{kind=link}
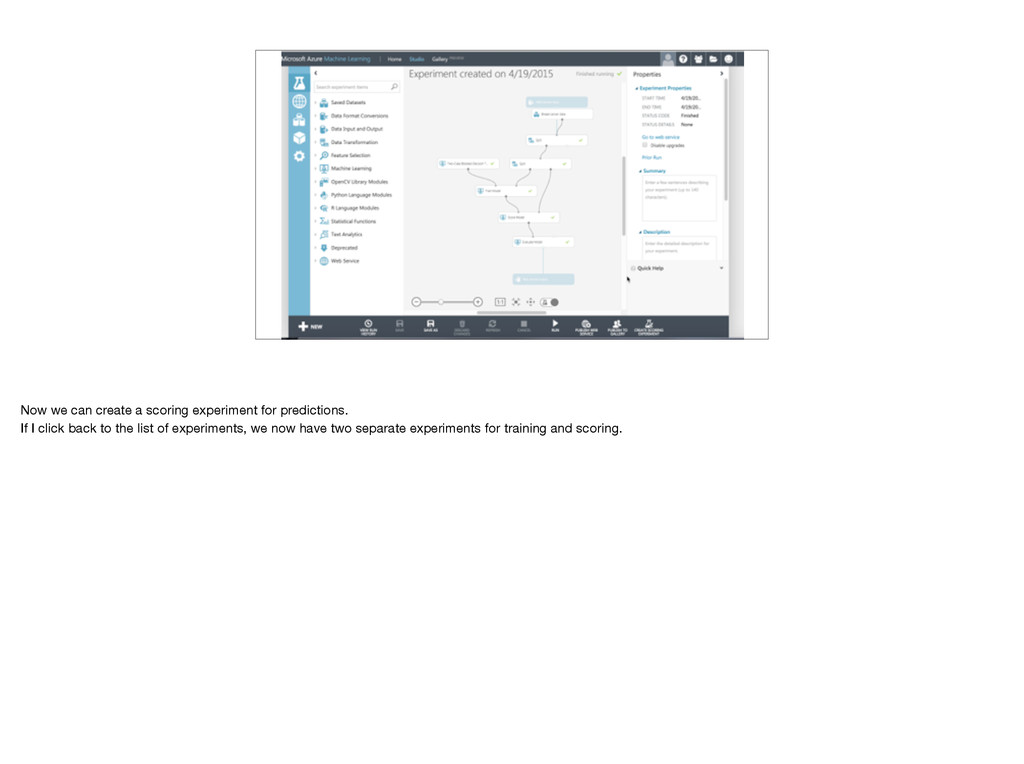{kind=link}
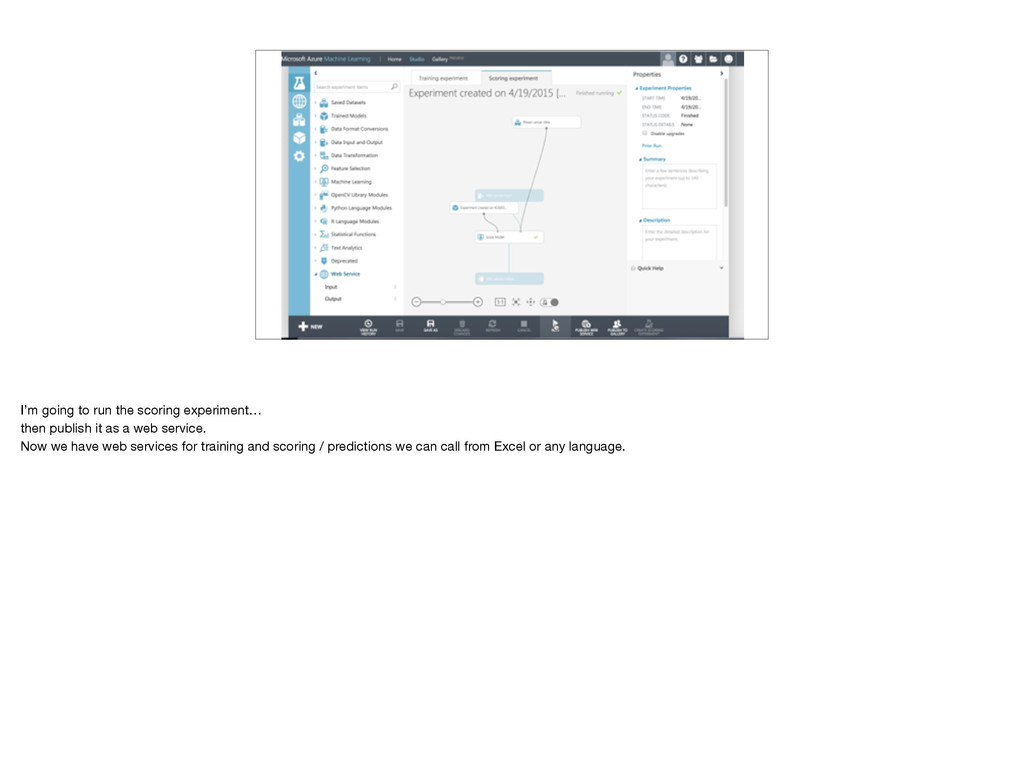{kind=link}
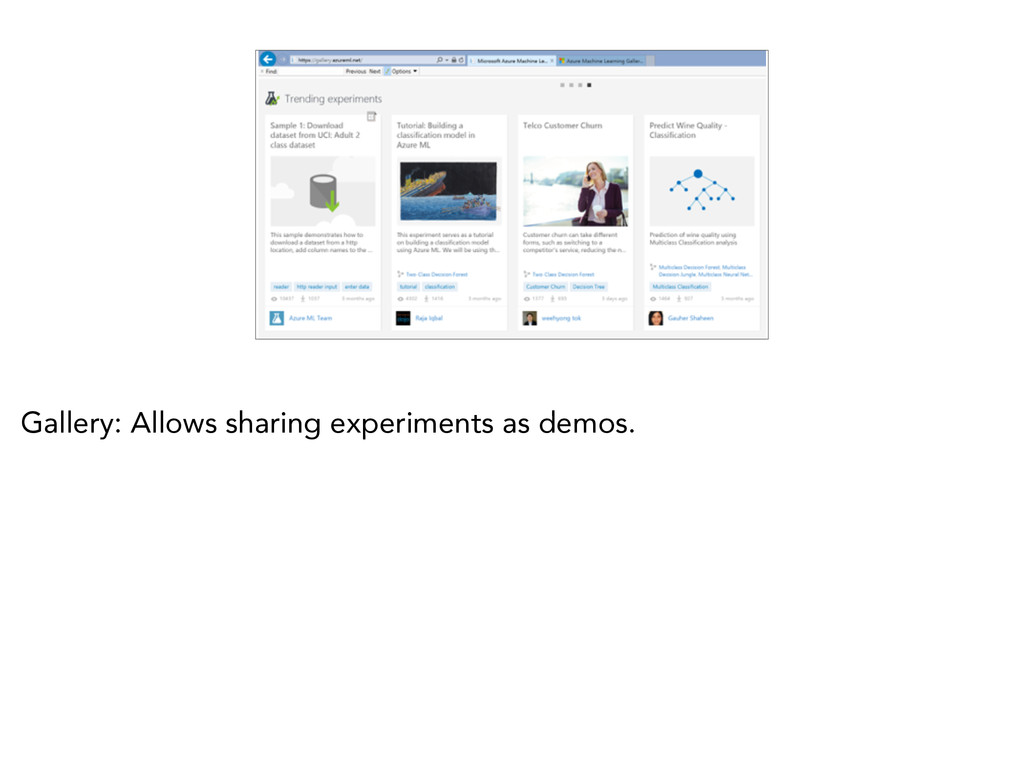{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CRAIG STUNTZ @CraigStuntz [email protected] http://blogs.teamb.com/craigstuntz http://www.meetup.com/Papers-We-Love-Columbus/ If you want to](https://files.speakerdeck.com/presentations/888433047fb44a17b9feacc902eeb146/slide_46.jpg){kind=link}