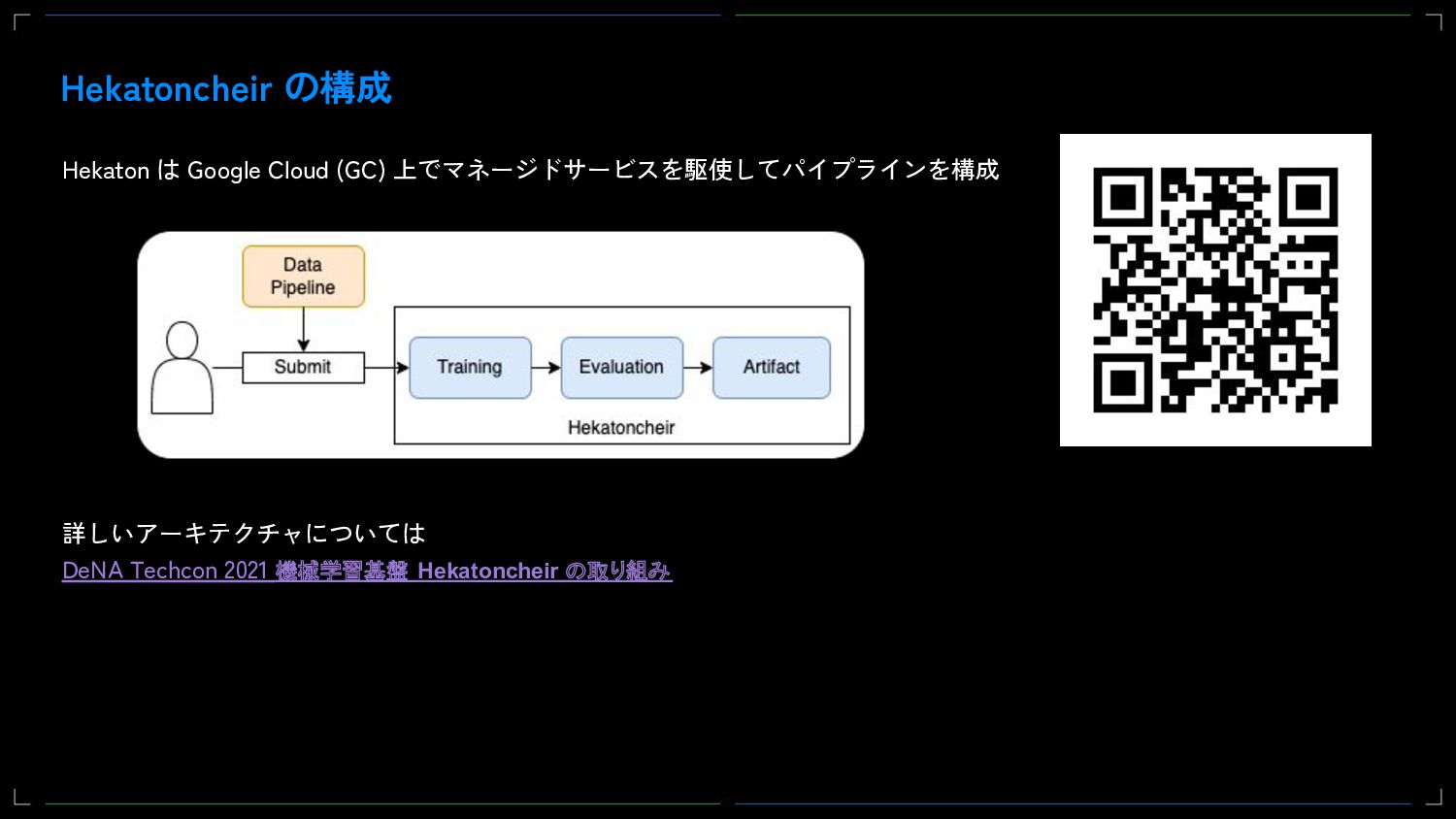
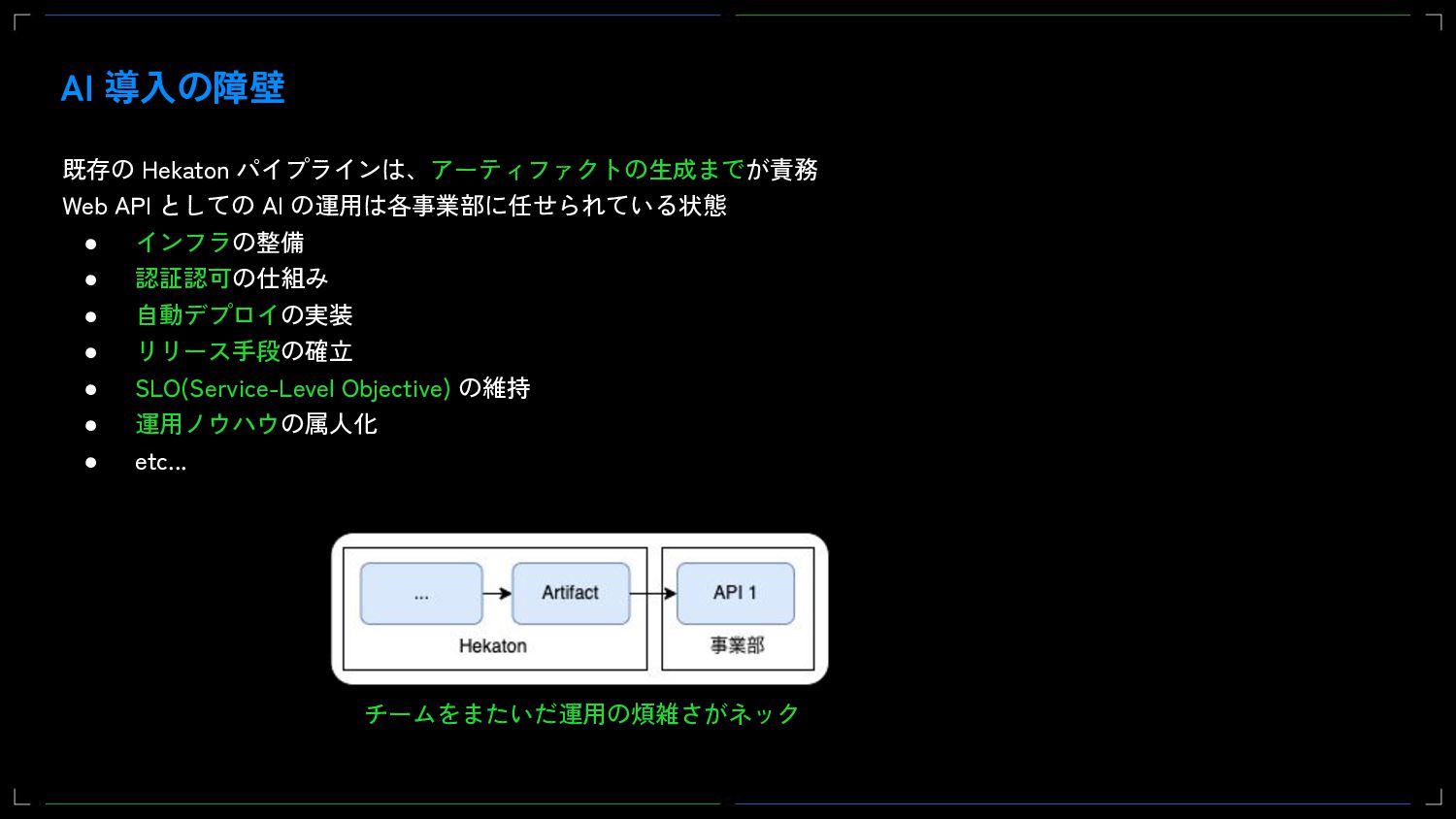
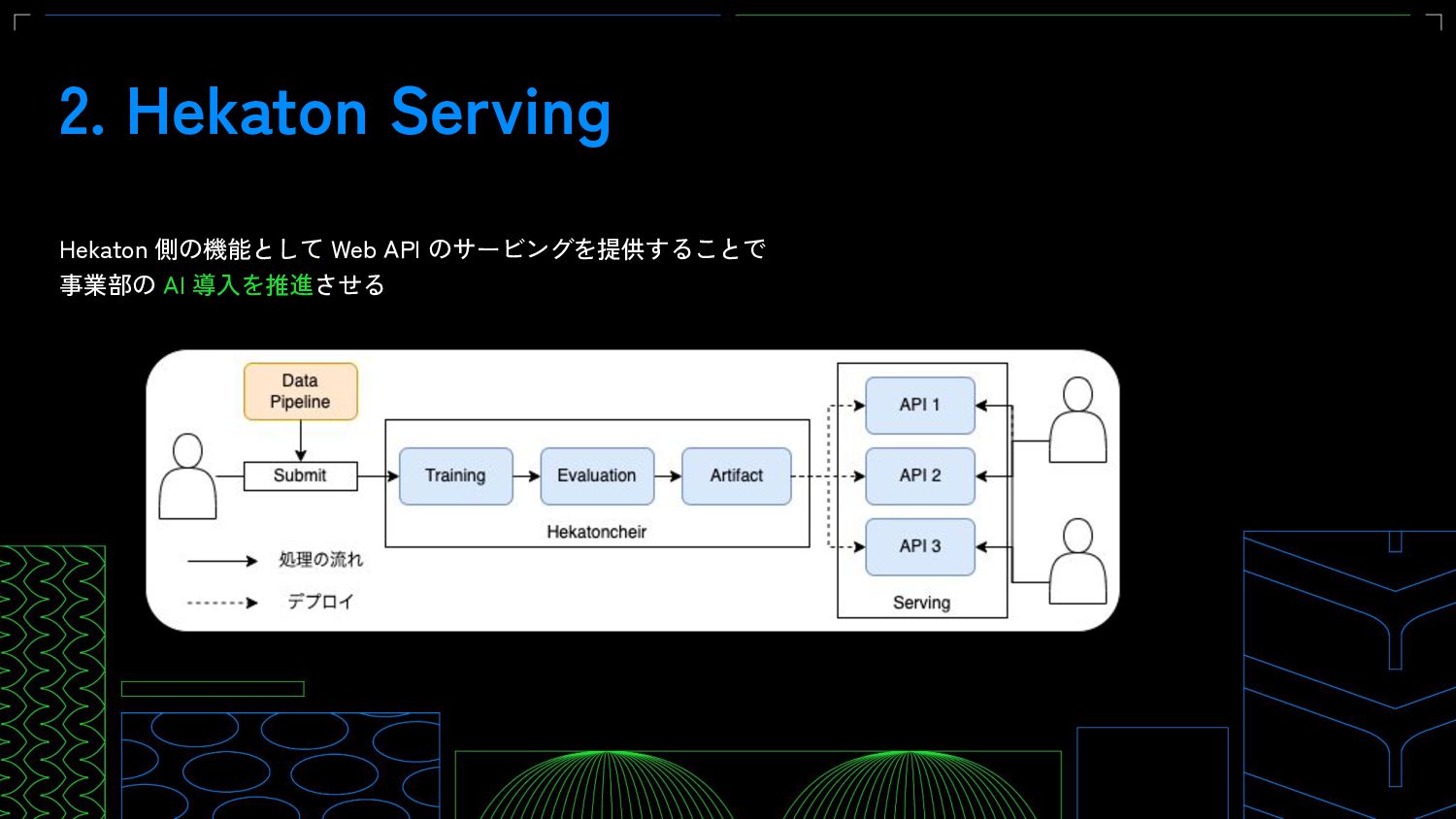
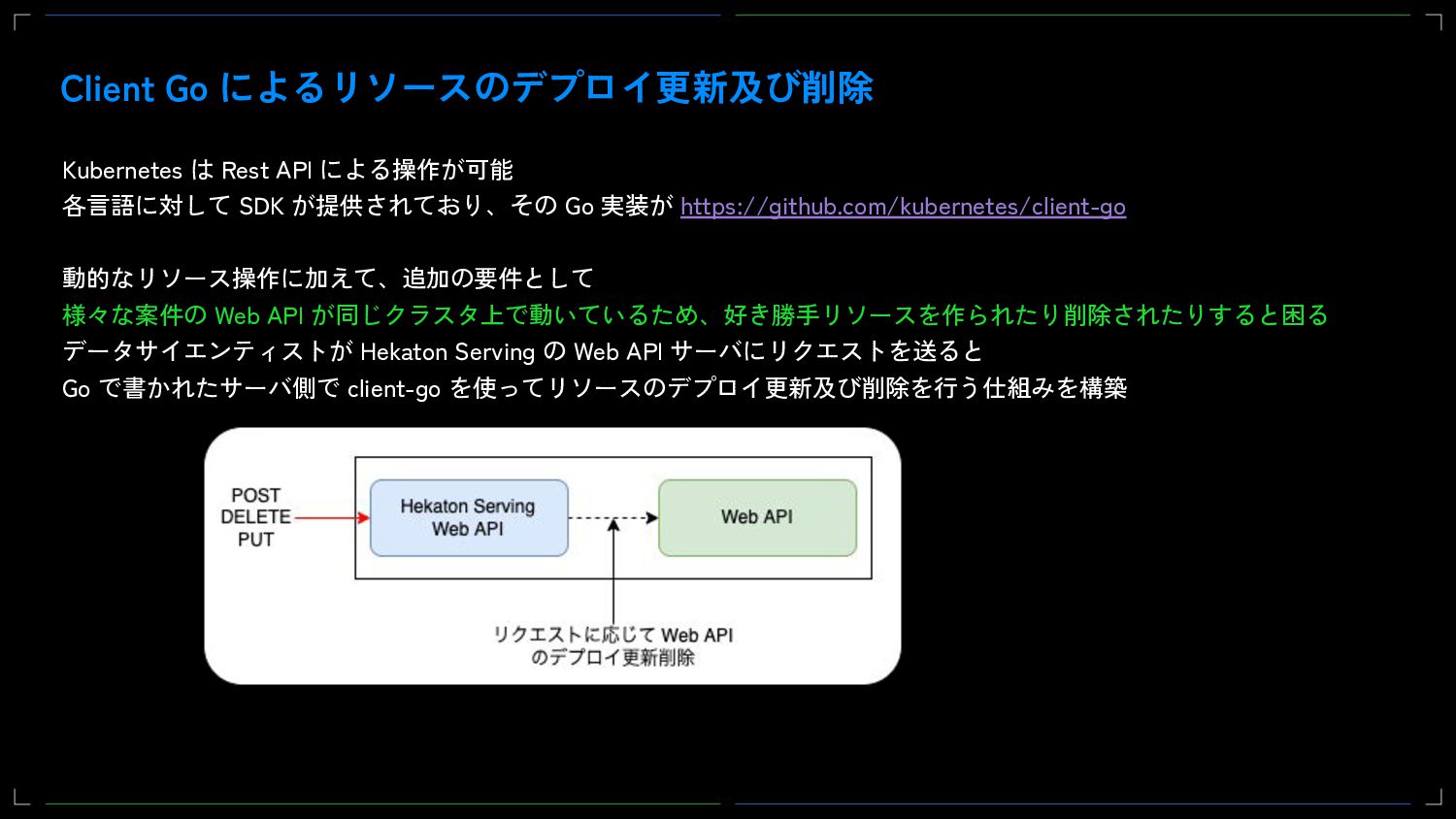
DeNAではMLOpsの活動の一環として、社内のデータサイエンティスト向けに共通の機械学習基盤であるHekatoncheirを提供することでAIの開発を促進してきました。当初Hekatoncheirでは学習と推論、そしてweb APIとして使うDockerイメージの生成までを責務としてきましたが、現在Web APIのサービング機能を新たに開発しています。
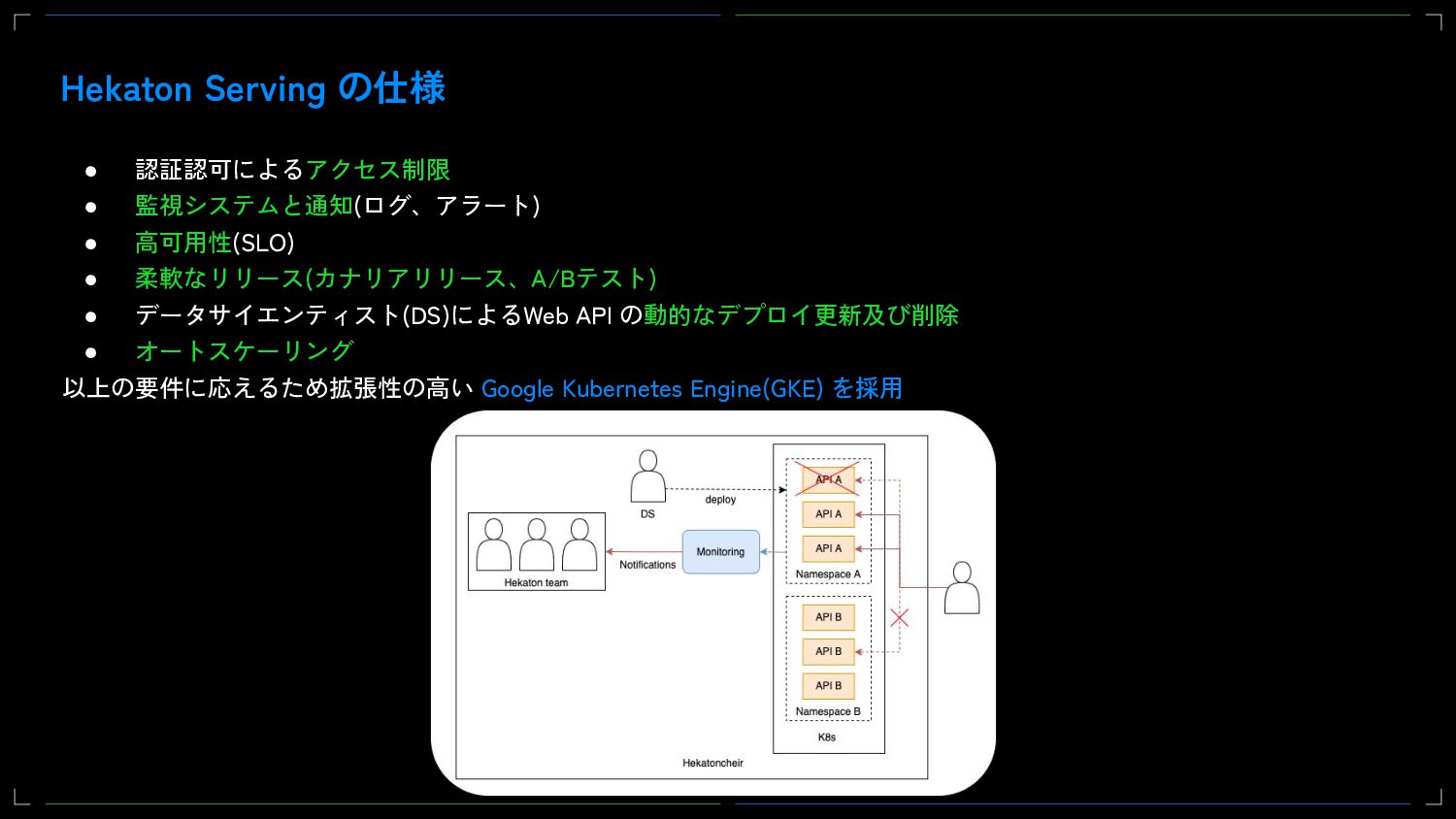
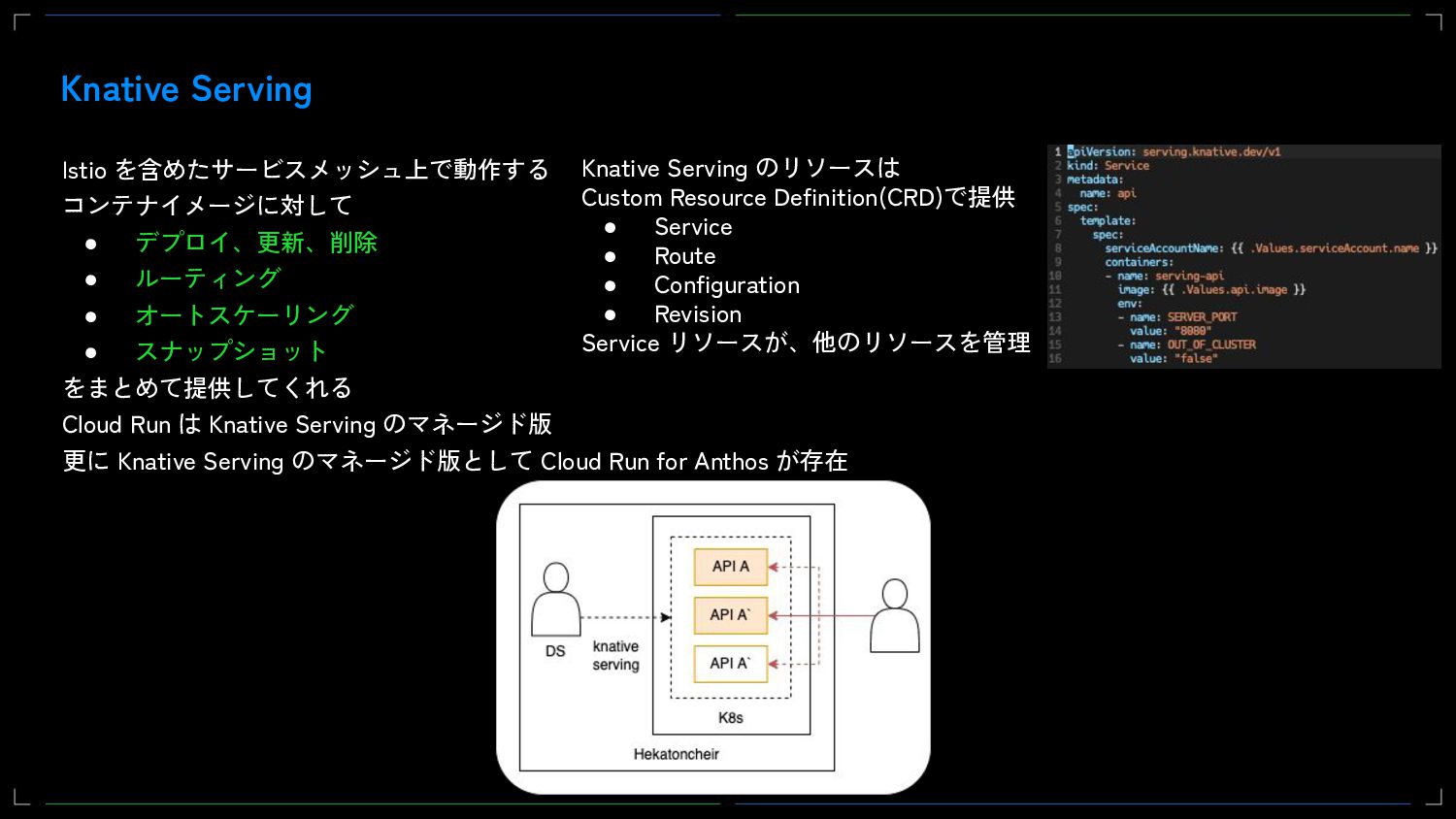
Web APIのサービング機能にはベースとしてGCPのマネージドKubernetesサービスであるGKEを採用しました。更にサービスメッシュとしてIstioの採用とWeb APIのサービングシステムとしてKnative Servingを使用しています。また、これらについてもGCPのマネージドサービスであるAnthosを取り入れてメンテナンスコストを下げています。
本セッションでは今回実装を進めているHekatoncheirのサービング機能について技術的に詳しく掘り下げてご紹介していきます。
DeNAではMLOpsの活動の一環として、社内のデータサイエンティスト向けに共通の機械学習基盤であるHekatoncheirを提供することでAIの開発を促進してきました。当初Hekatoncheirでは学習と推論、そしてweb APIとして使うDockerイメージの生成までを責務としてきましたが、現在Web APIのサービング機能を新たに開発しています。
Web APIのサービング機能にはベースとしてGCPのマネージドKubernetesサービスであるGKEを採用しました。更にサービスメッシュとしてIstioの採用とWeb APIのサービングシステムとしてKnative Servingを使用しています。また、これらについてもGCPのマネージドサービスであるAnthosを取り入れてメンテナンスコストを下げています。
本セッションでは今回実装を進めているHekatoncheirのサービング機能について技術的に詳しく掘り下げてご紹介していきます。
資料内でのリンク集:
p4, https://speakerdeck.com/dena_tech/techcon2021-12
p17, https://github.com/kubernetes/client-go
◆ You Tube
https://youtu.be/XpIvdyH7CuA
◆ You Tube チャンネル登録はこちら↓
https://youtube.com/c/denatech?sub_confirmation=1
◆ Twitter
https://twitter.com/DeNAxTech
◆ DeNA Engineering
https://engineering.dena.com/
◆ DeNA Engineer Blog
https://engineering.dena.com/blog/
◆ DeNA TechCon 2022 公式サイト
https://techcon2022.dena.dev/spring/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
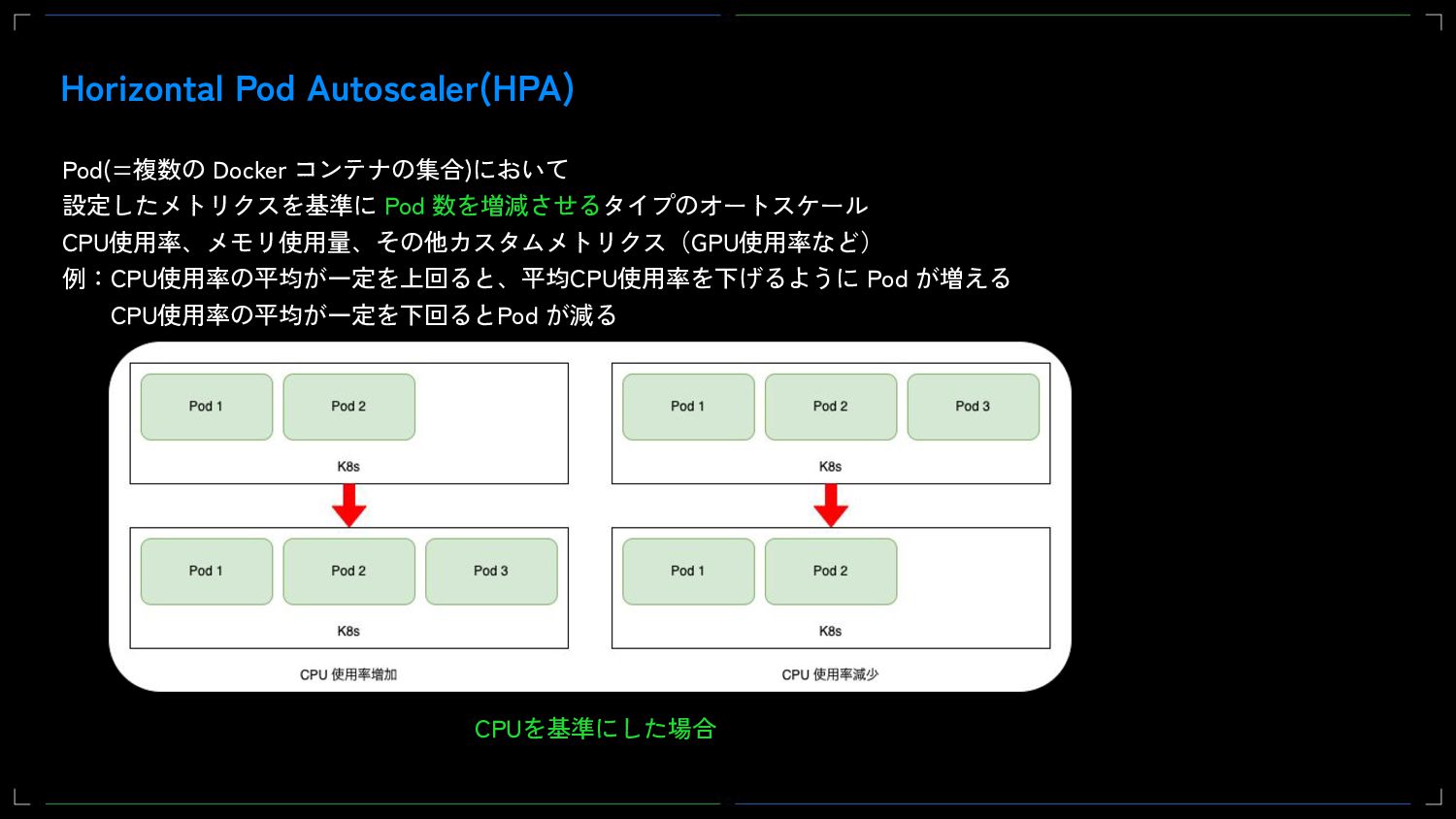{kind=link}
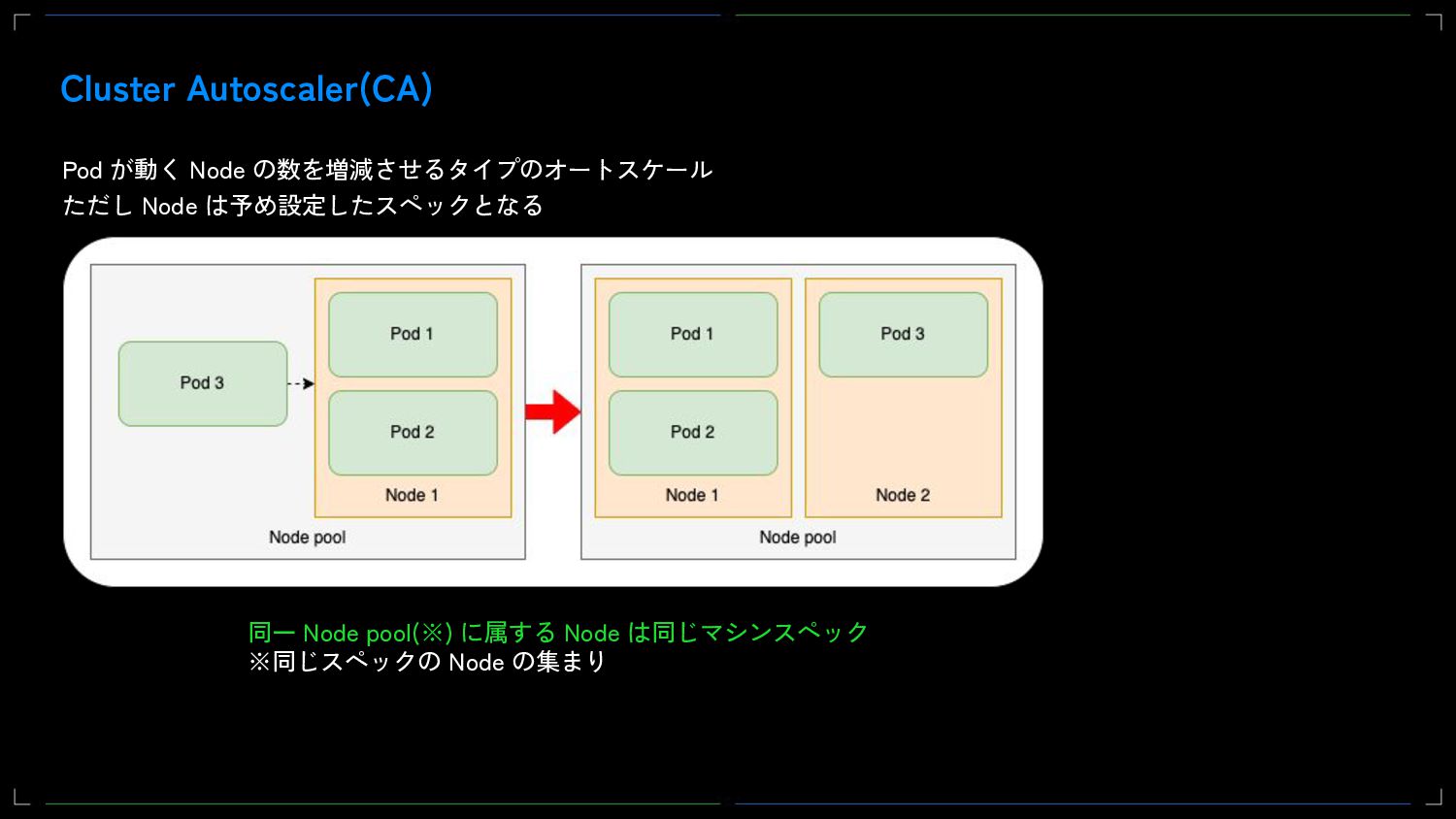{kind=link}
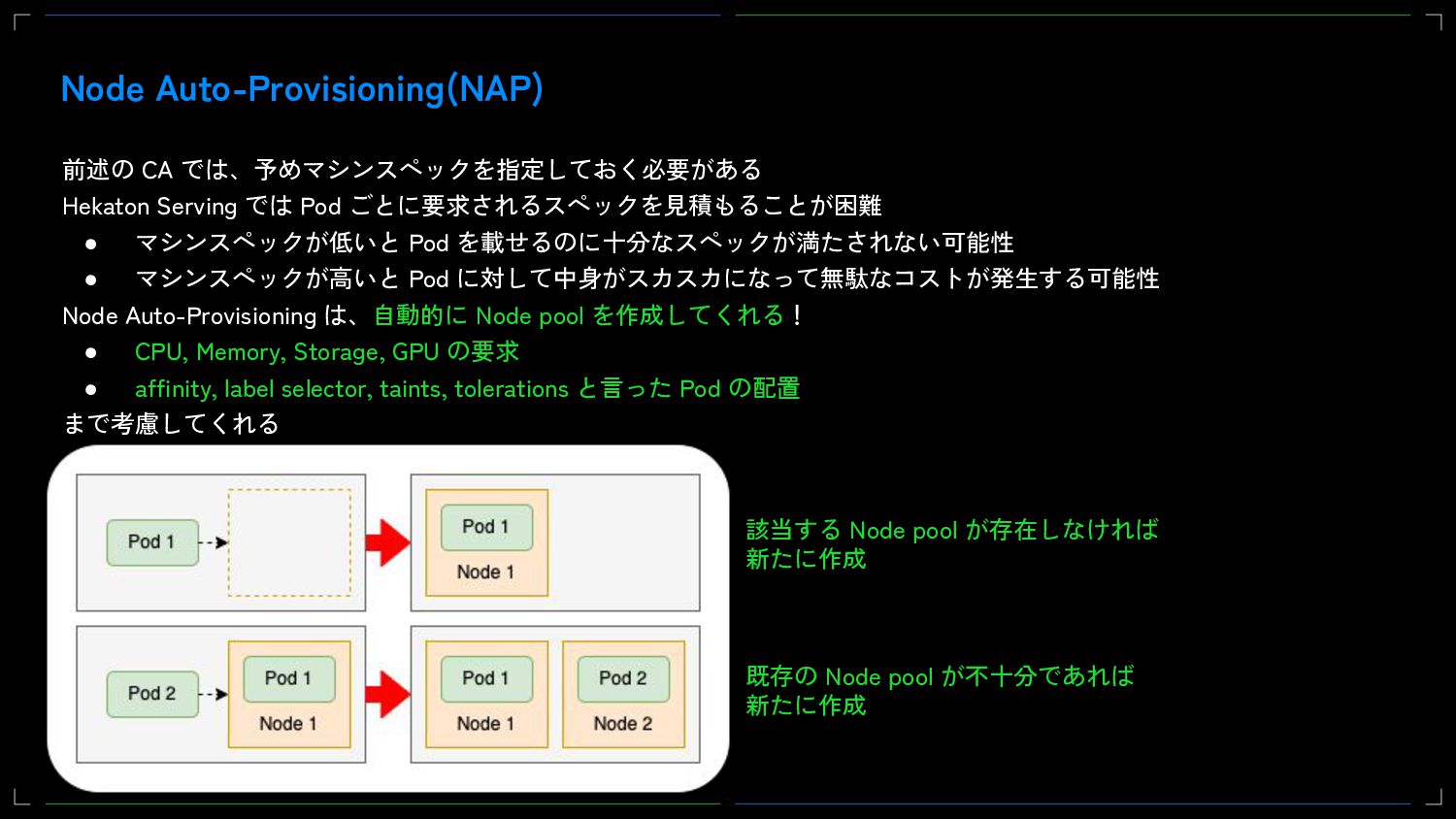{kind=link}
{kind=link}
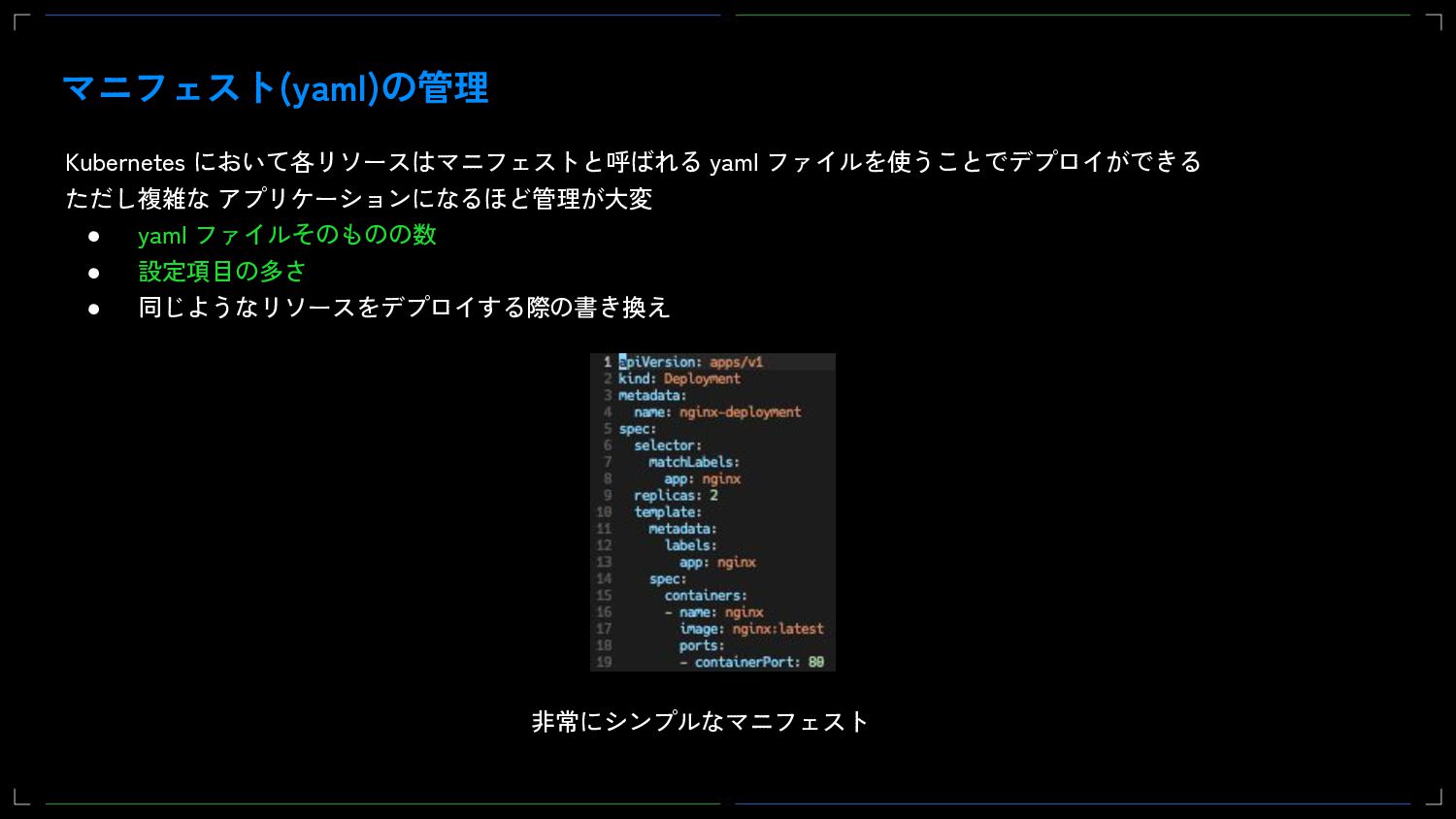{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}