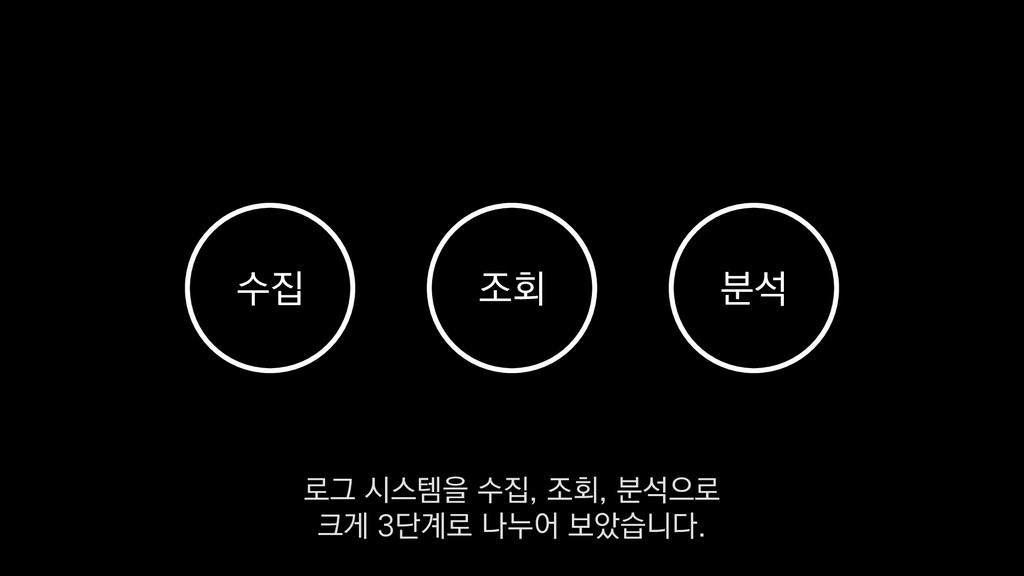
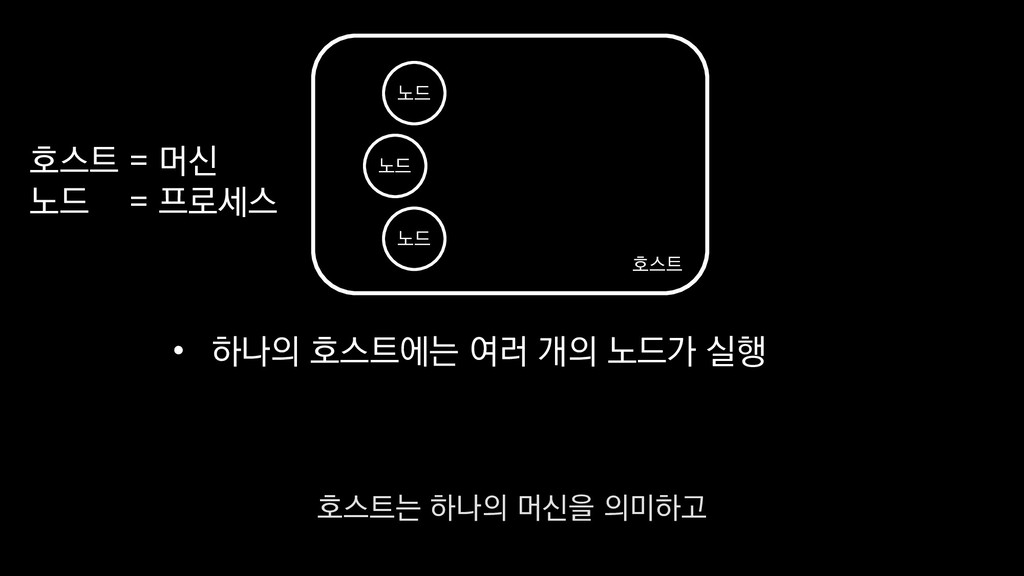
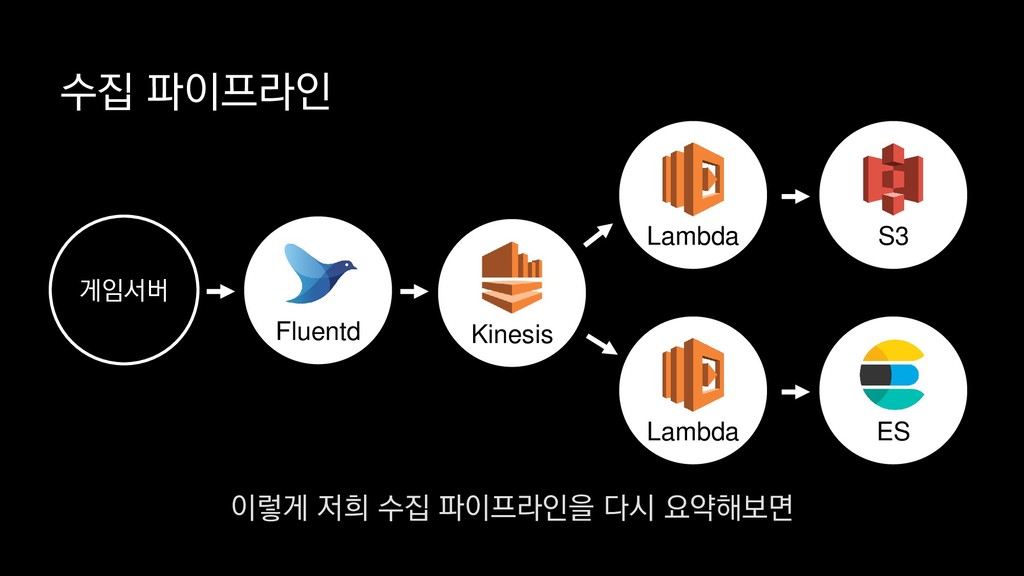
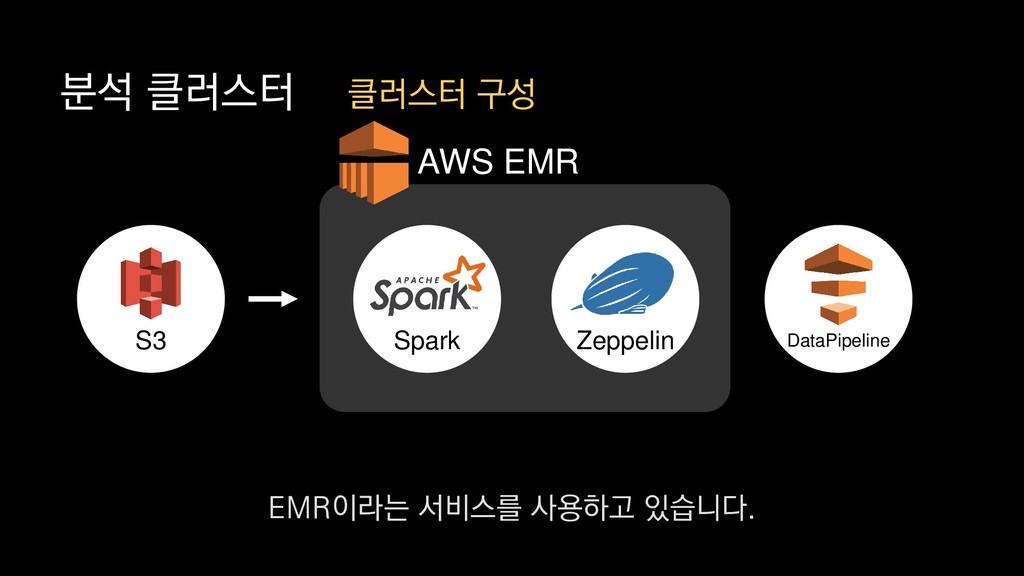
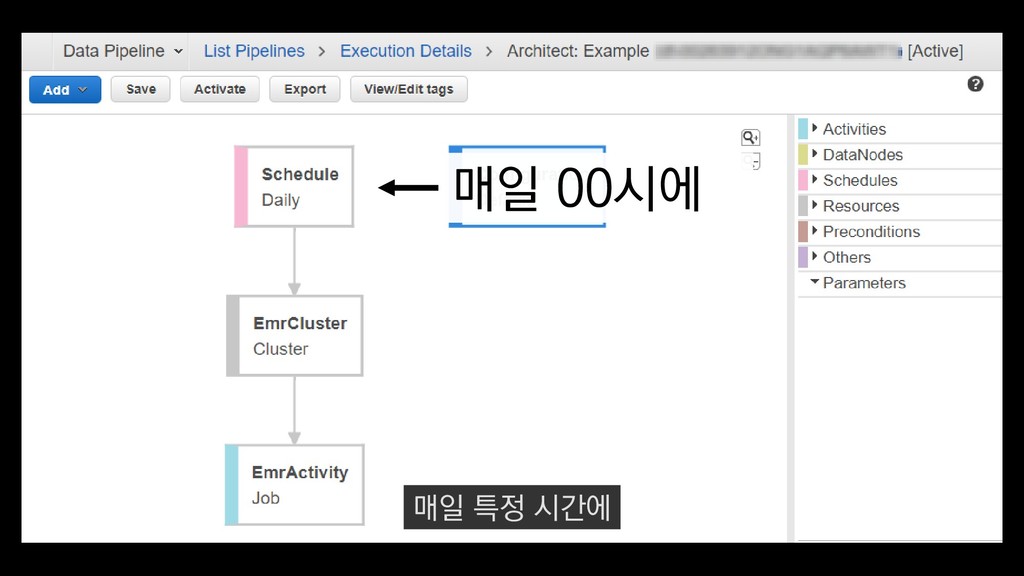
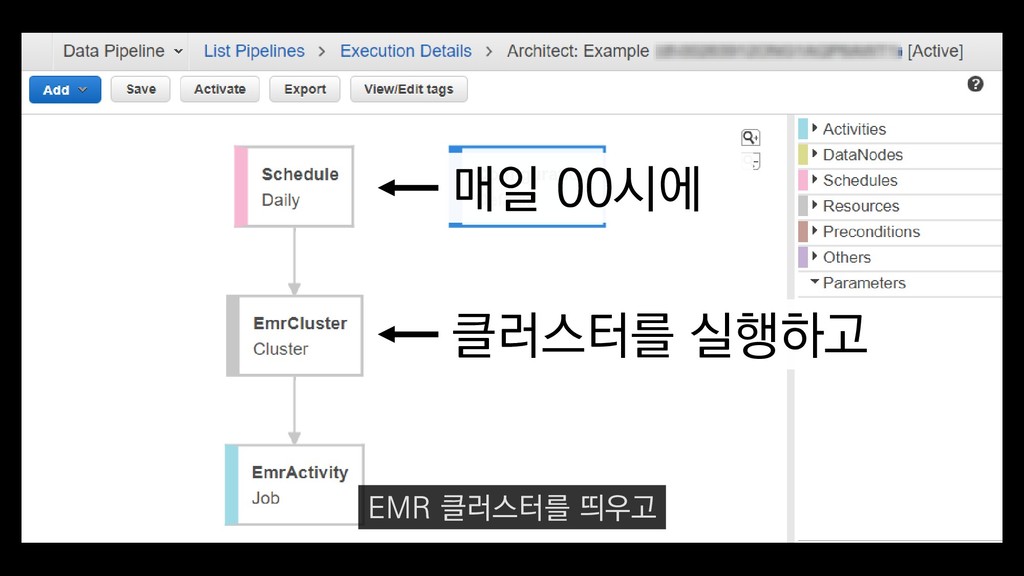
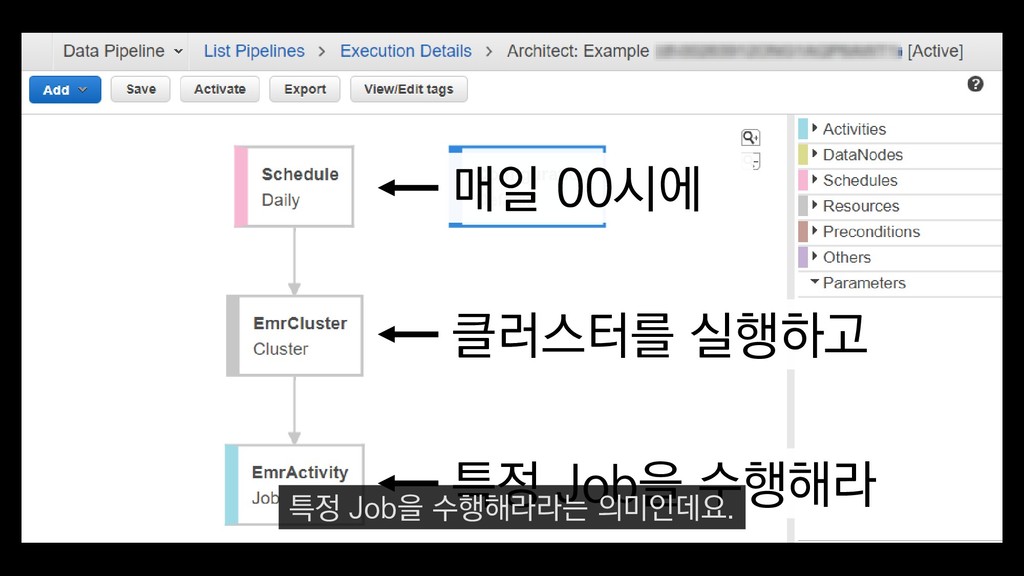
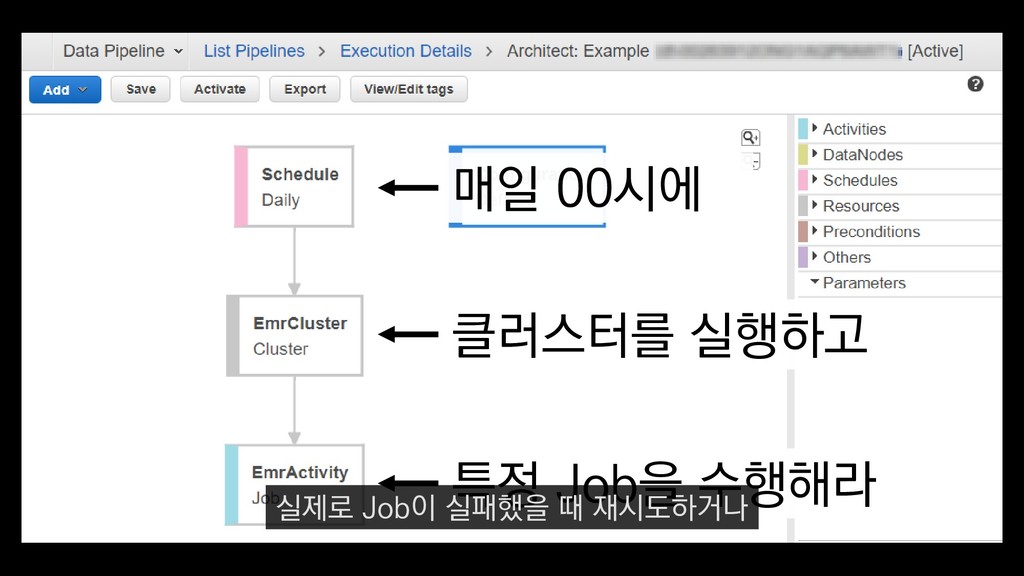
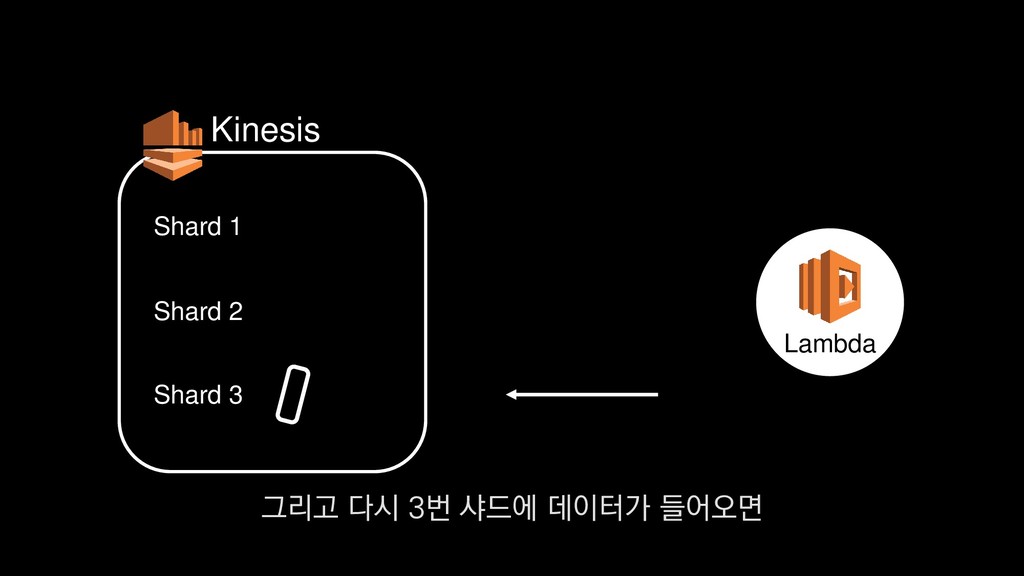
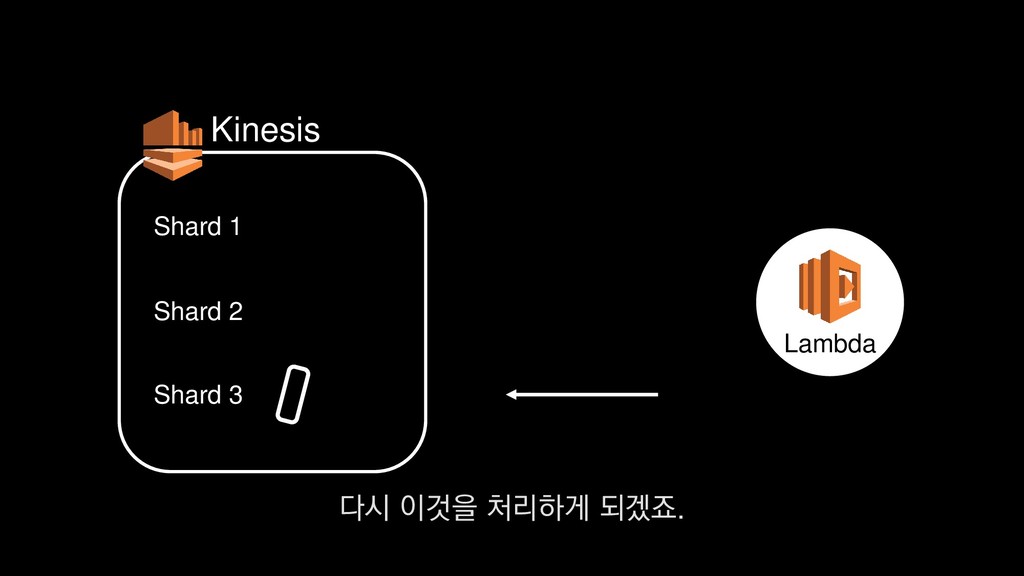
이탈구간 분석, 레벨별 활성 유저수 • 적정 인구수 산정 • (광영님 분석사례 추가) • 초반 가이드 개선 • 등등 ... 낯선 게임인데 익숙해야 하고, 알려줄 게 많은데 재미있어야 한다고요? - <야생의 땅: 듀랑고> 초반 플레이 변천사 강임성 님 / 4월 26일 오전 11시 이 초반가이드 개선에 대한 발표도 NDC 마지막날인 26일에 있으니
이탈구간 분석, 레벨별 활성 유저수 • 적정 인구수 산정 • (광영님 분석사례 추가) • 초반 가이드 개선 • 등등 ... 낯선 게임인데 익숙해야 하고, 알려줄 게 많은데 재미있어야 한다고요? - <야생의 땅: 듀랑고> 초반 플레이 변천사 강임성 님 / 4월 26일 오전 11시 관심 있으신 분들은 참관하셔도 좋을 듯합니다.
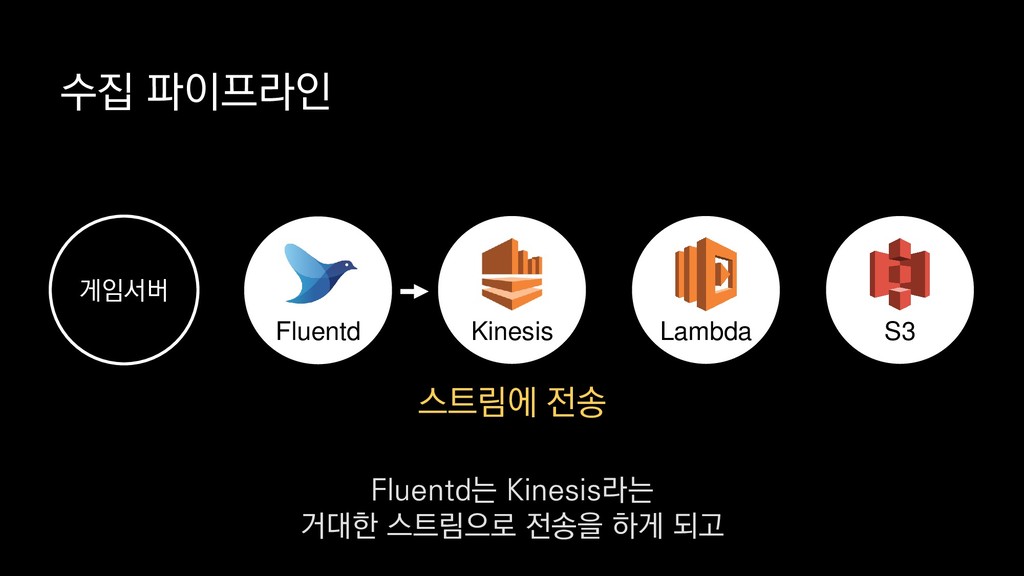
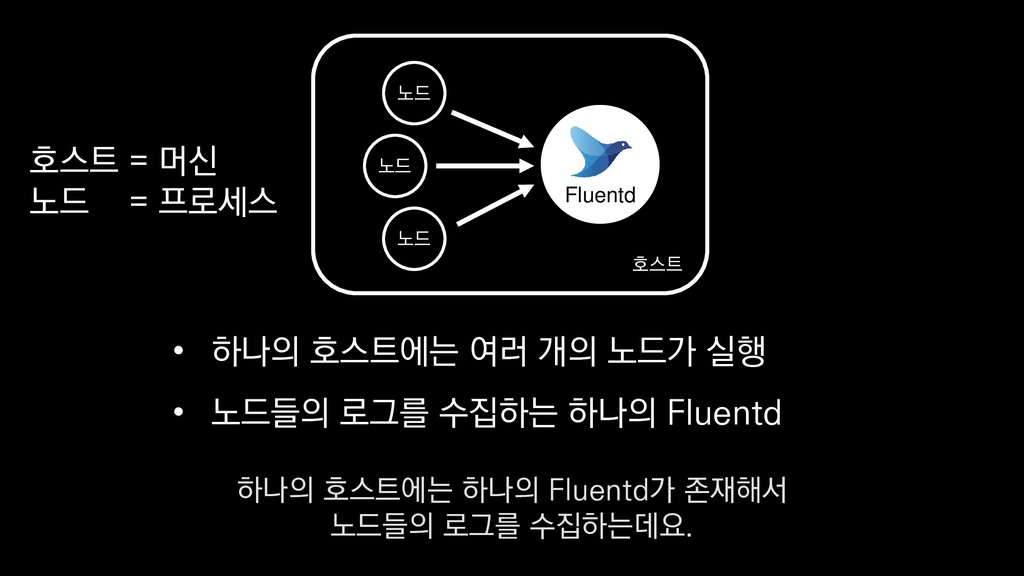
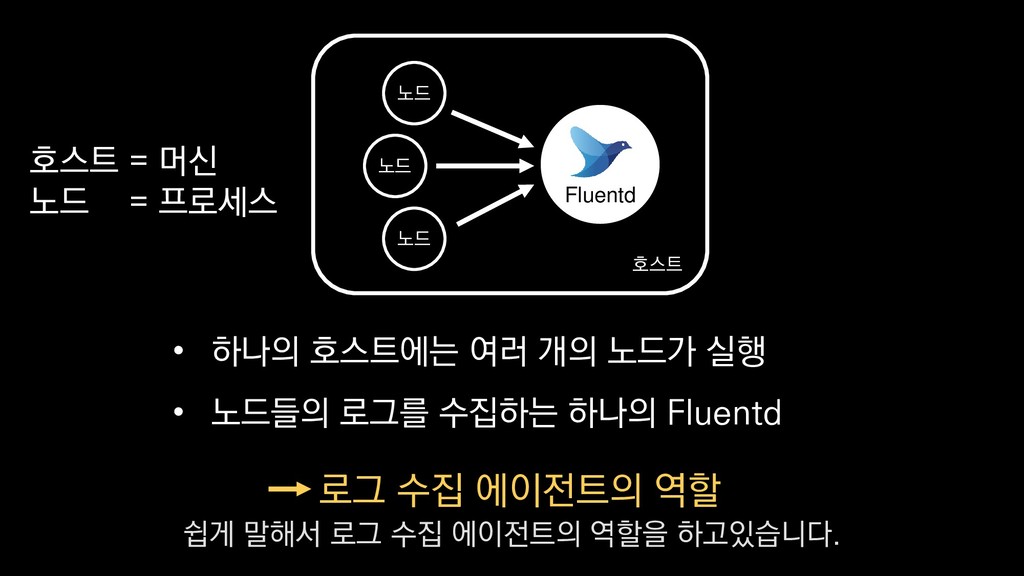
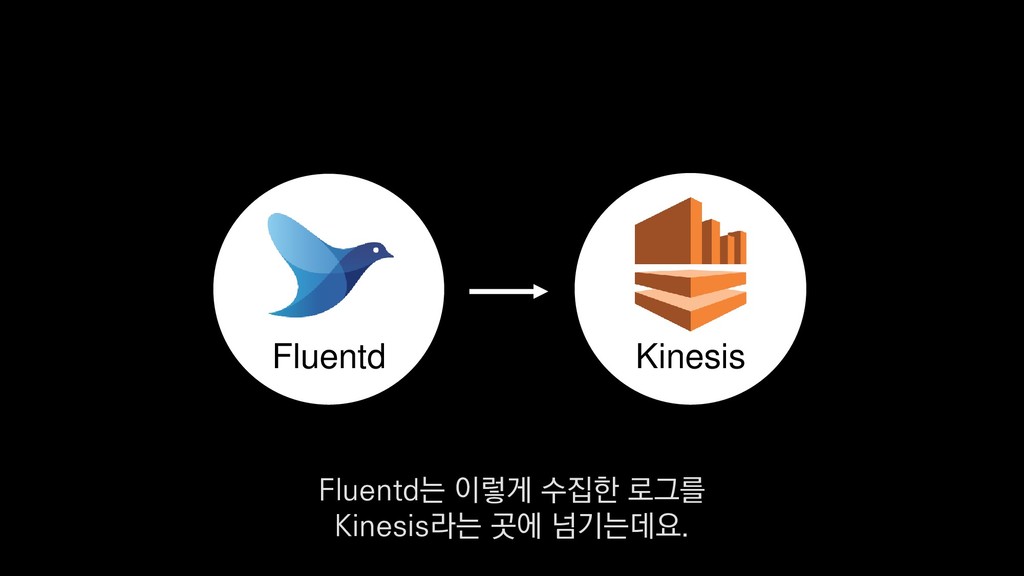
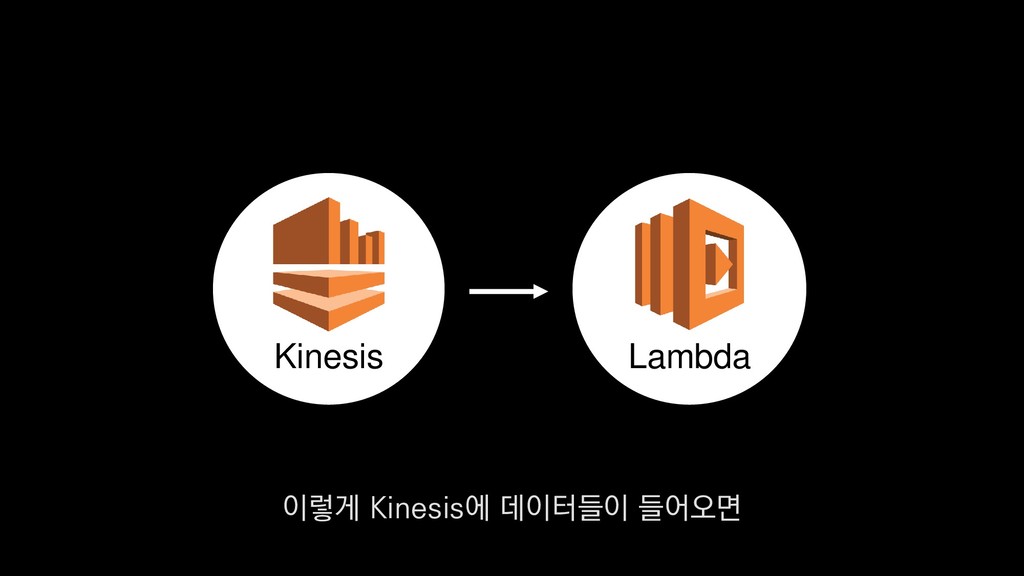
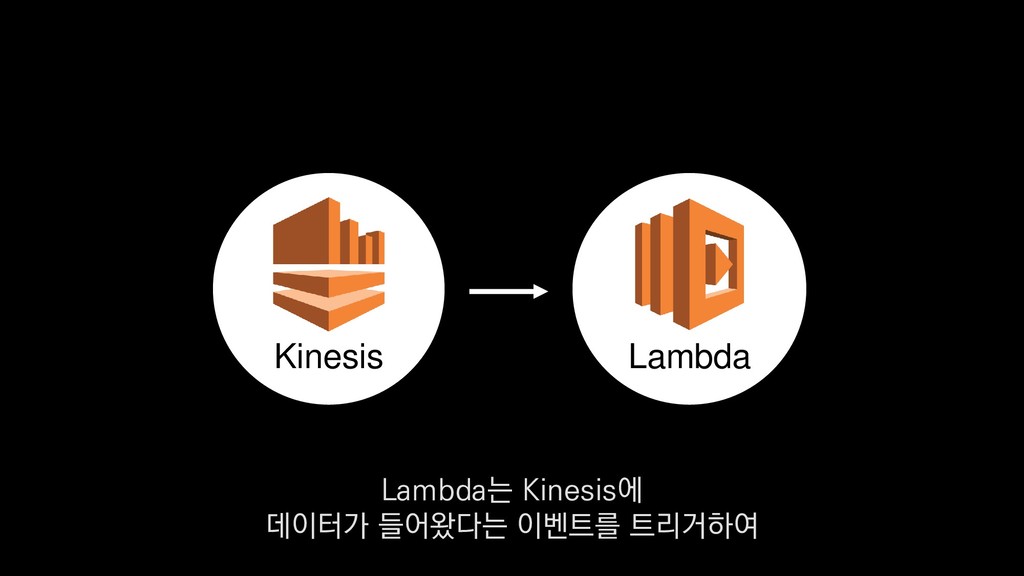
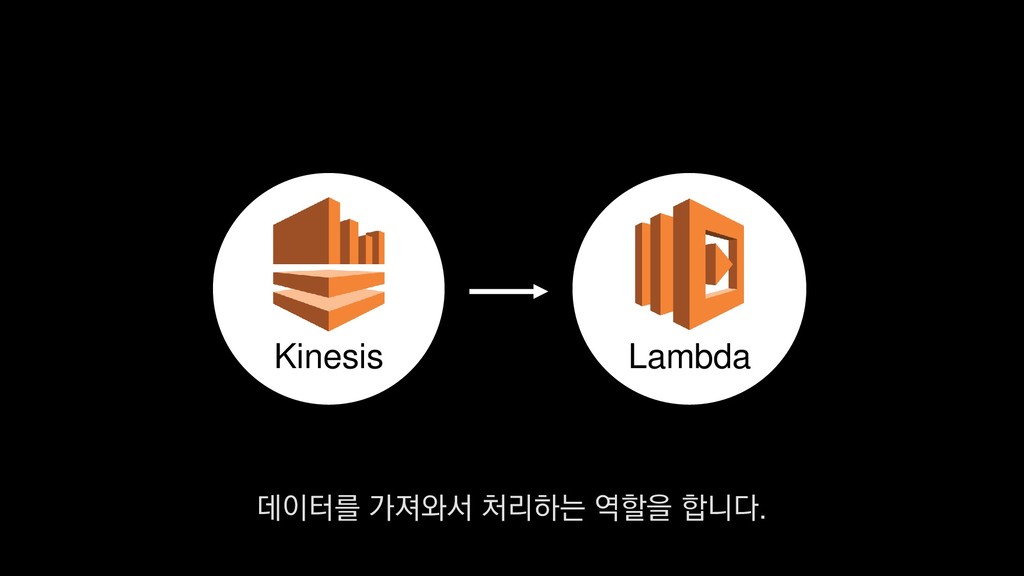
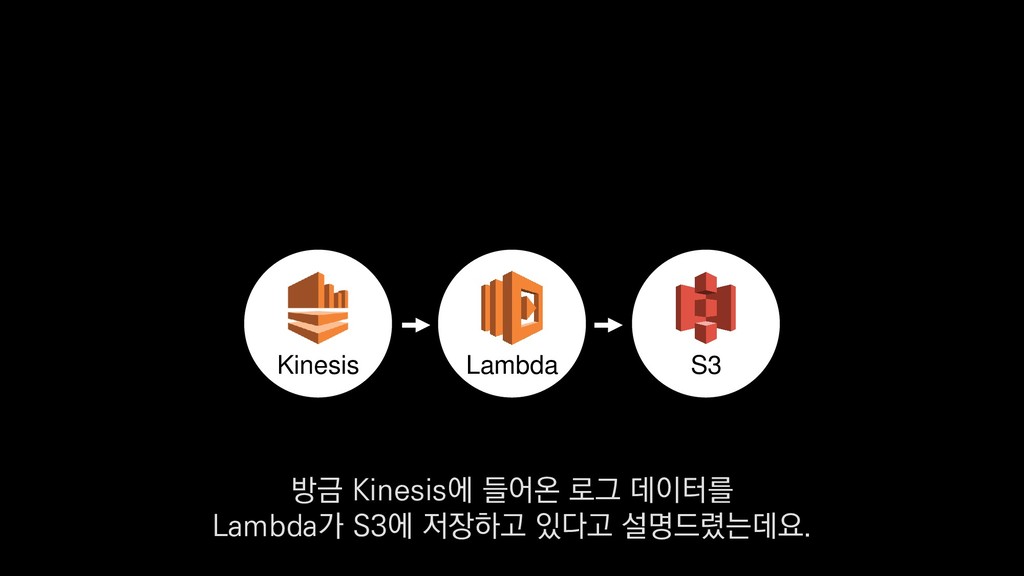
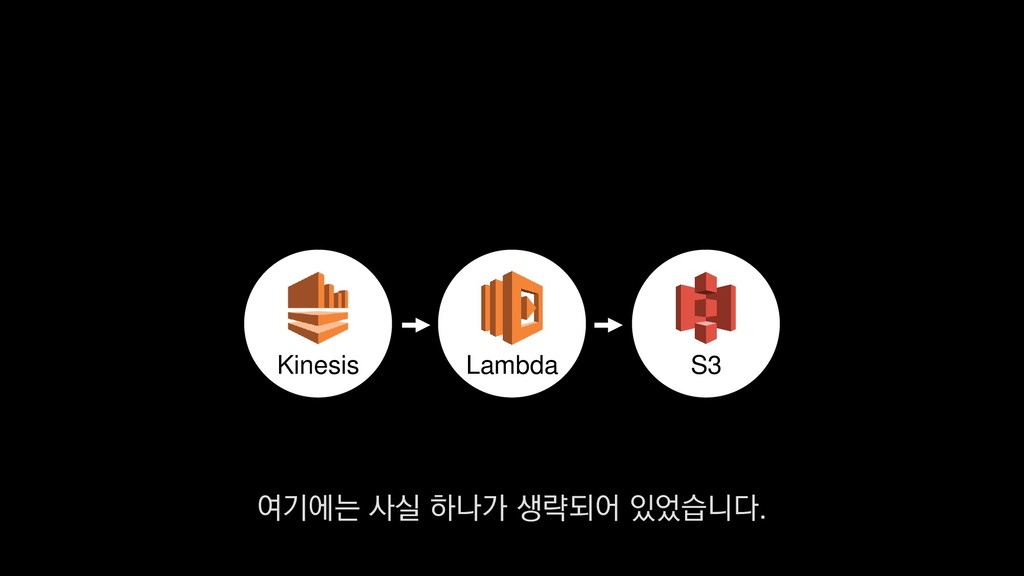
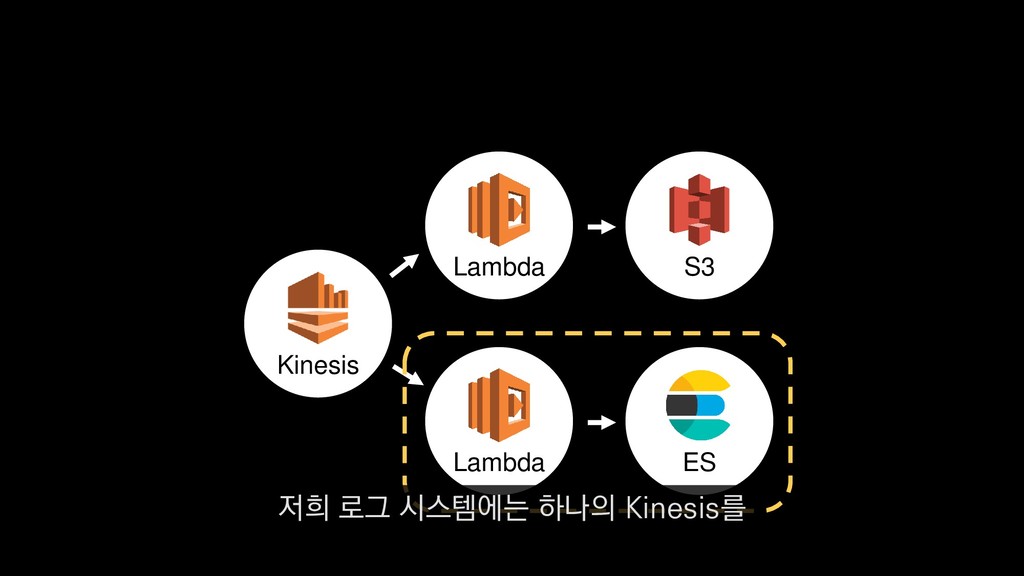
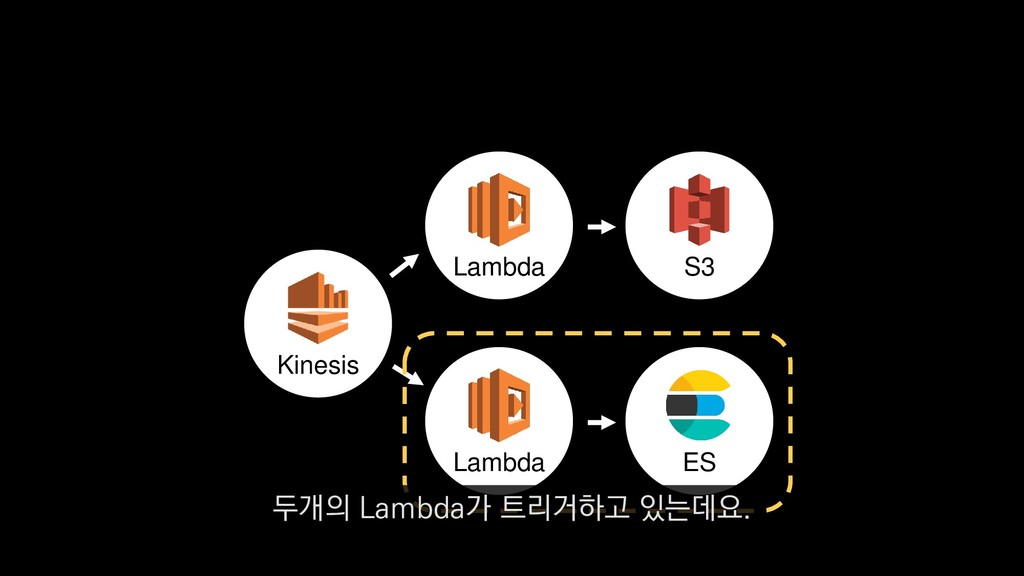
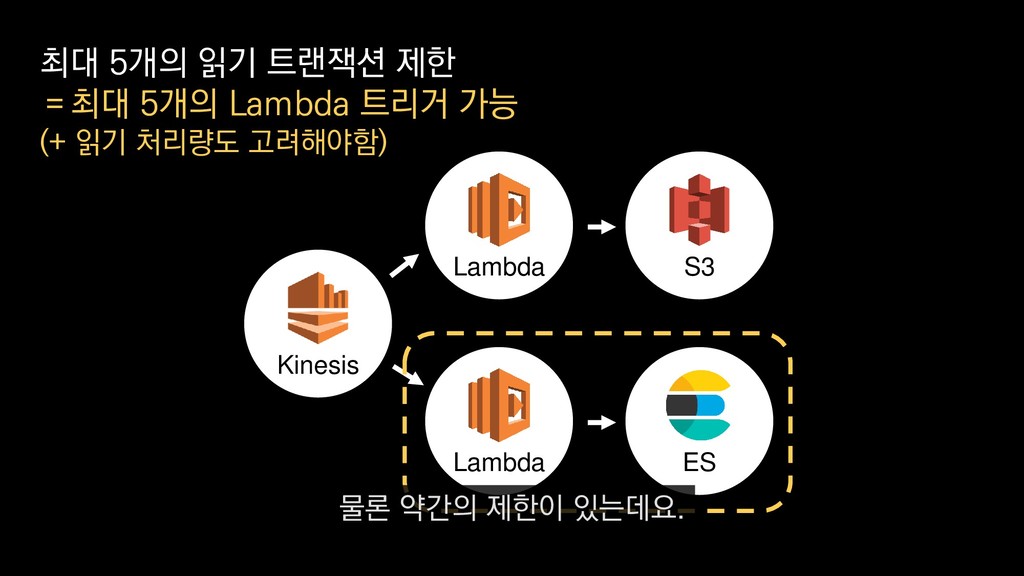
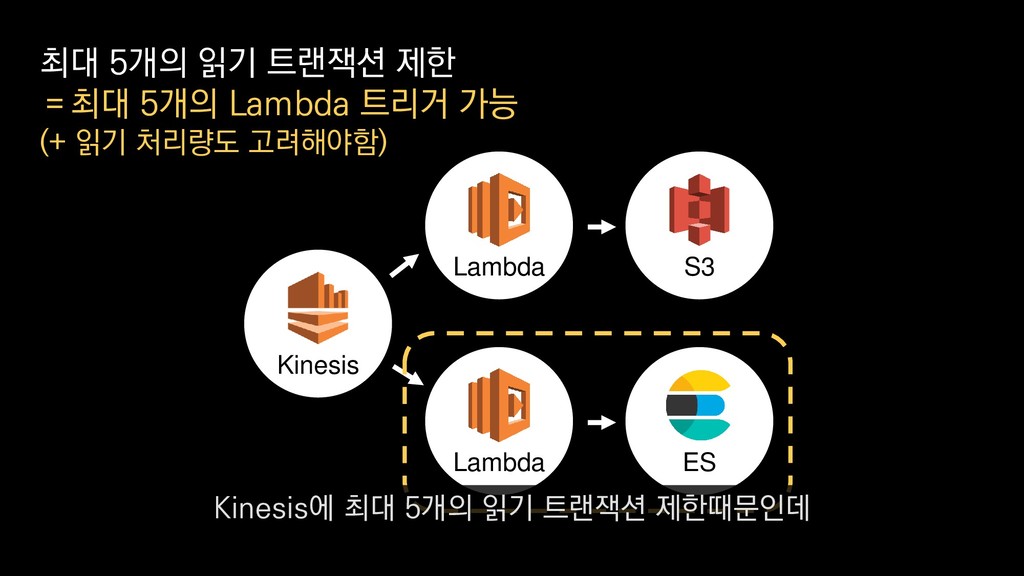
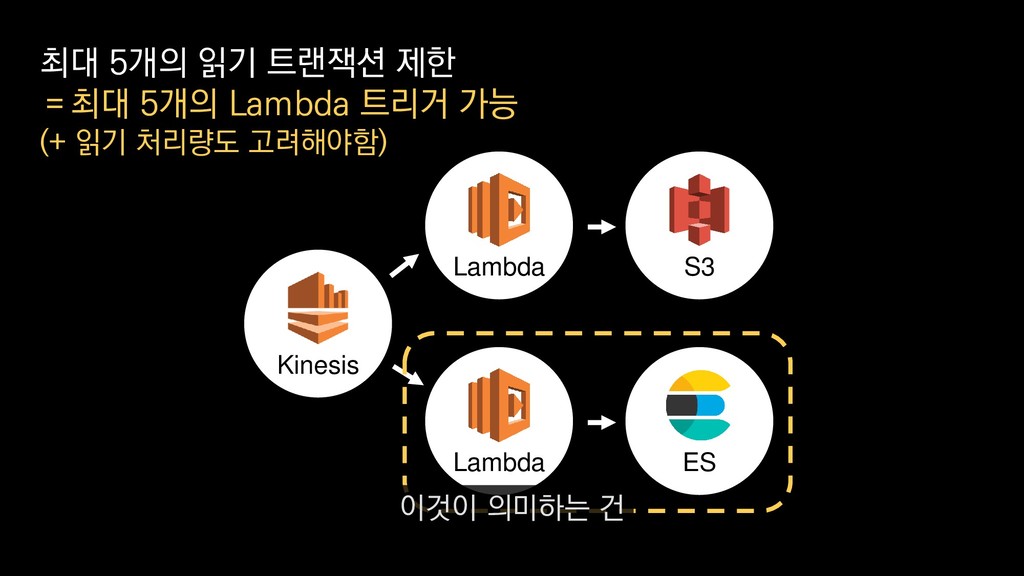
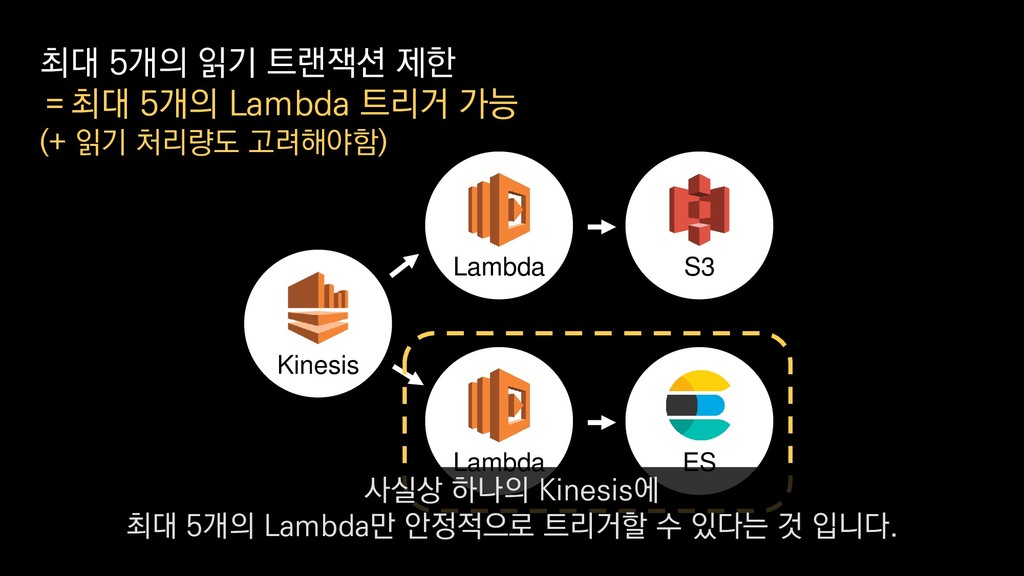
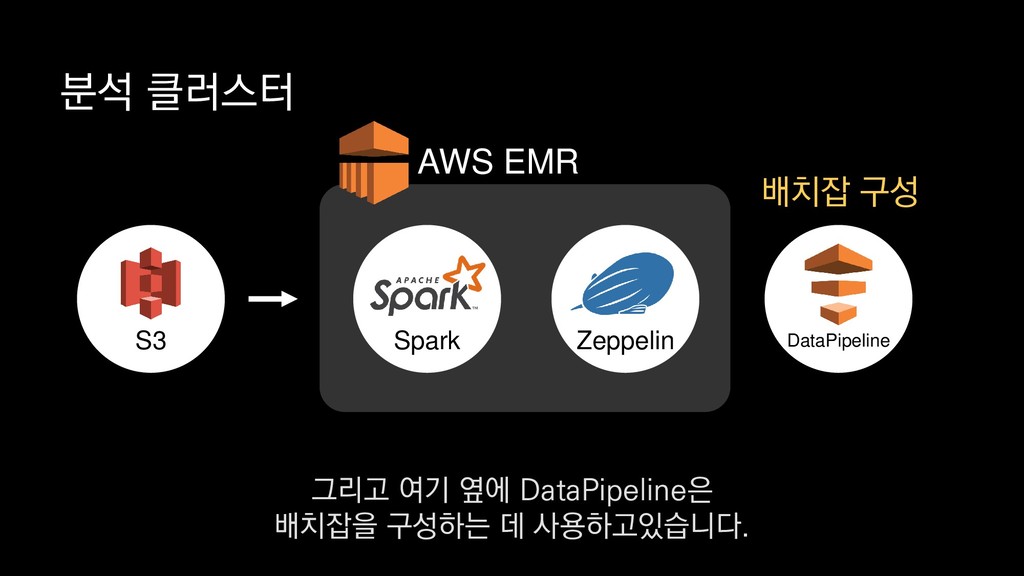
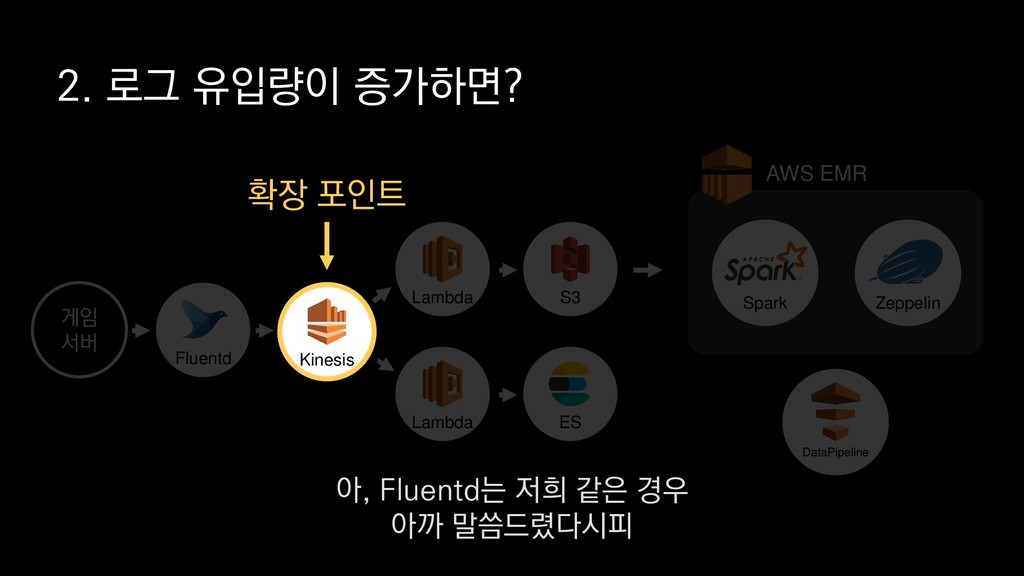
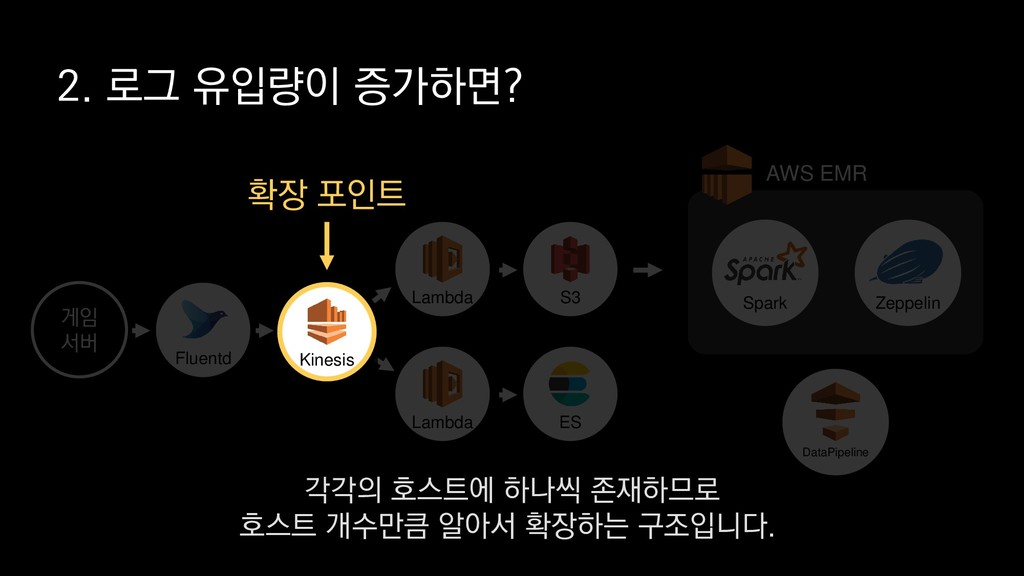
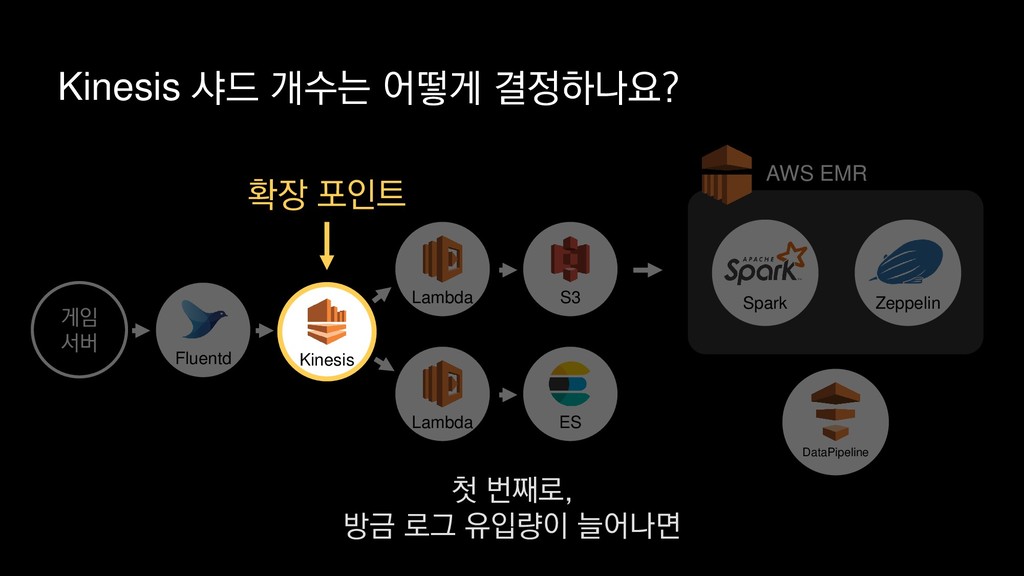
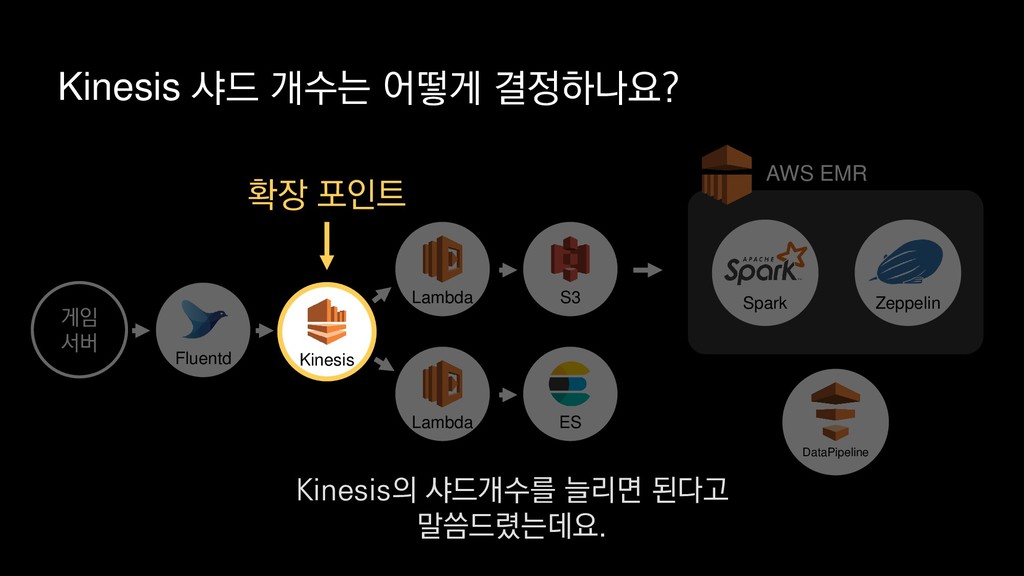
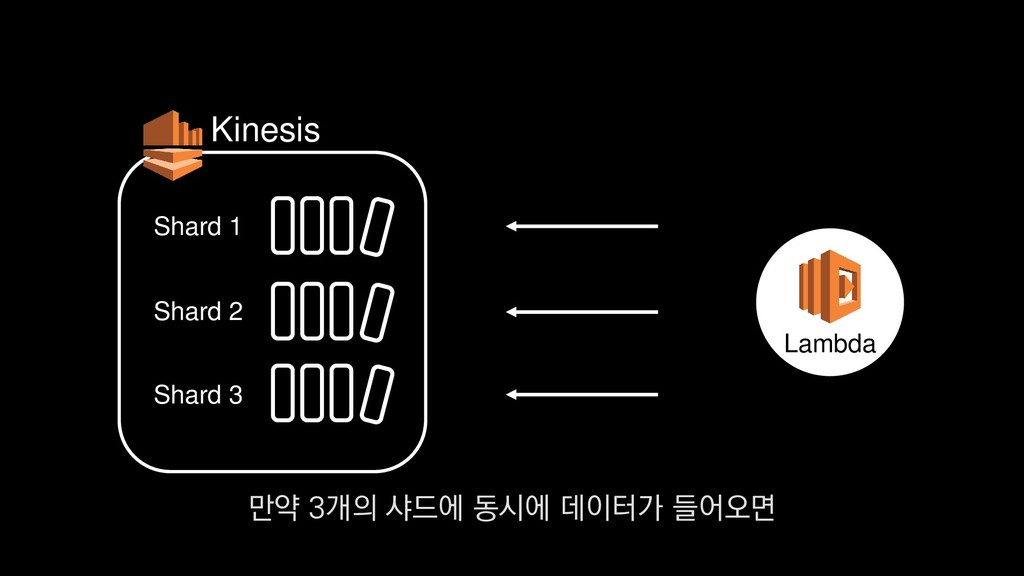
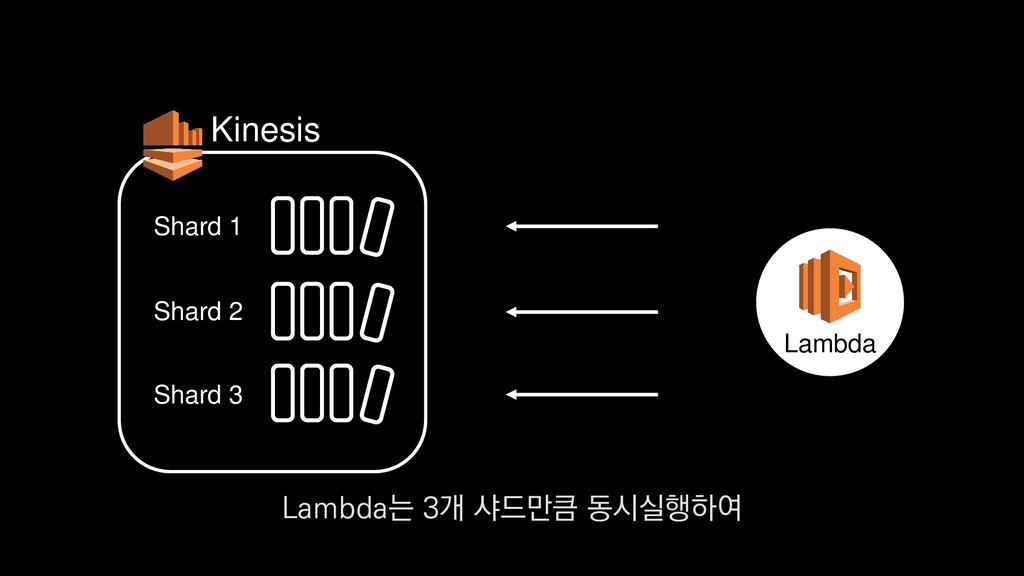
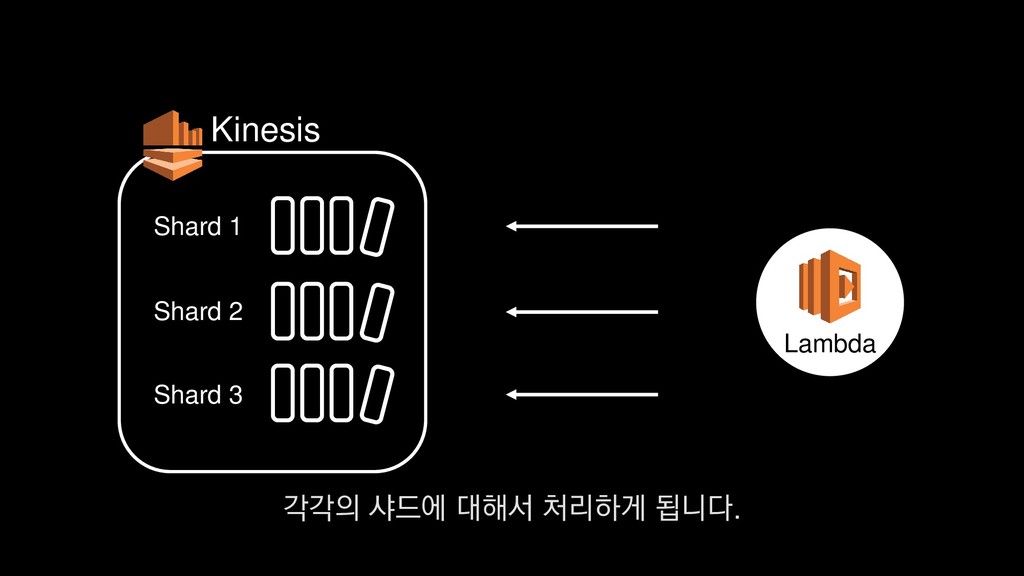
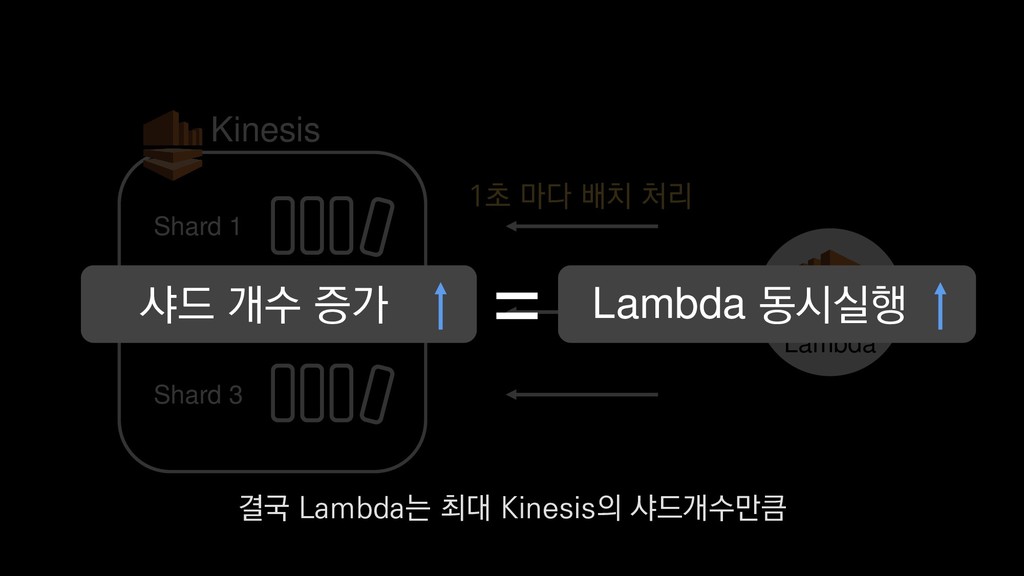
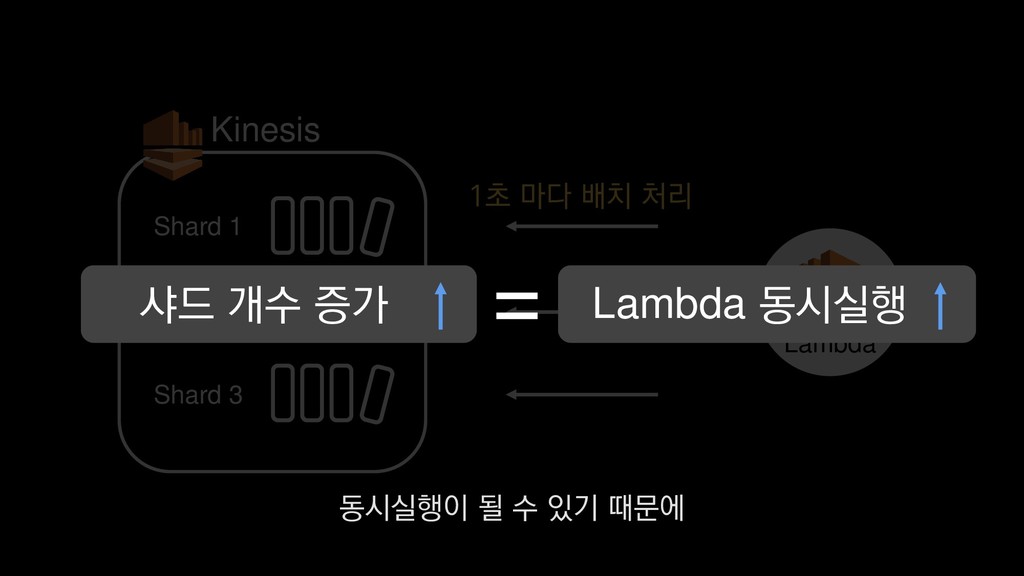
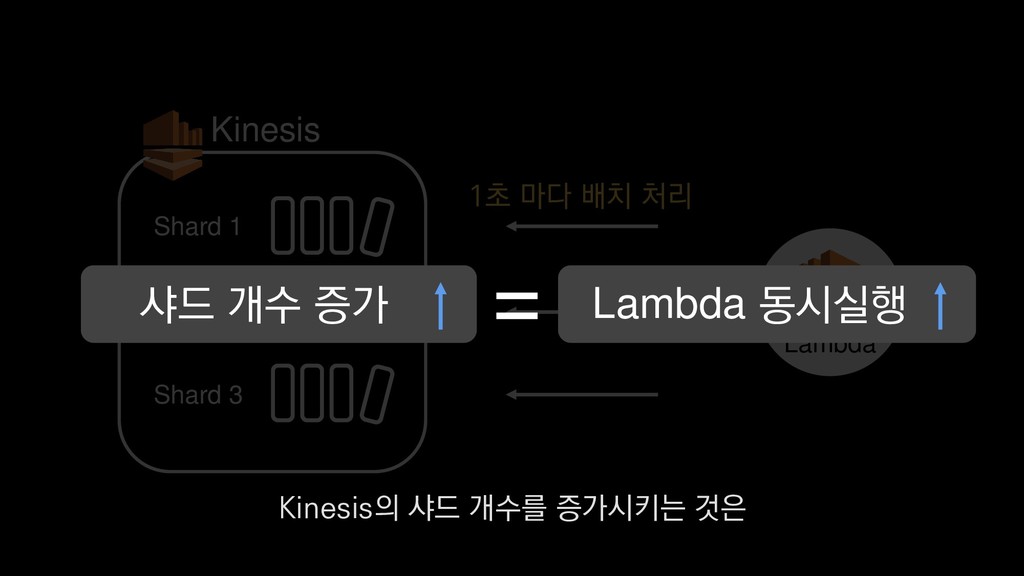
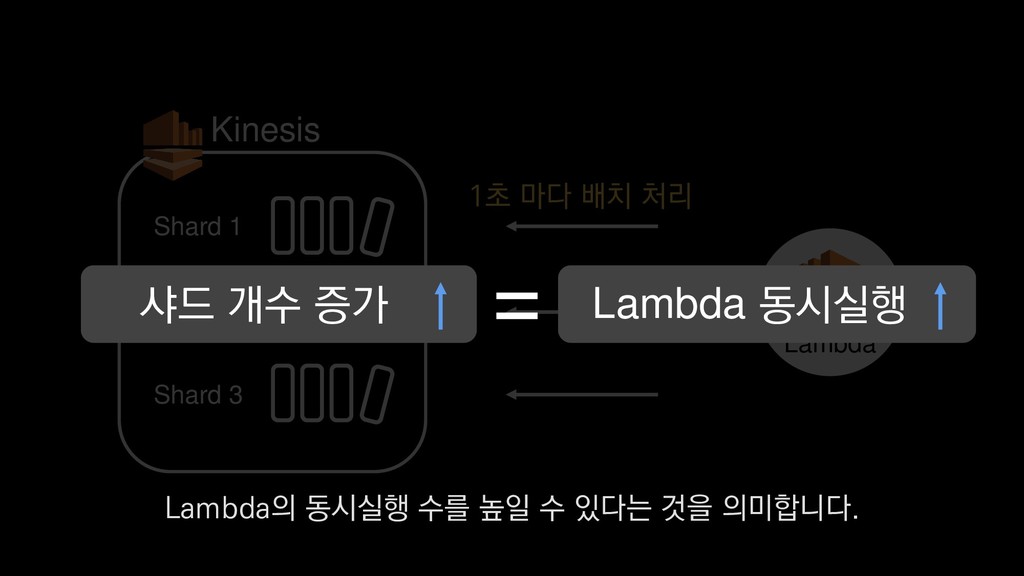
• 최대 7일동안 데이터 보존 • 데이터 유입량에 따라 무중단 확장 및 축소가능 AWS Kinesis Data Stream → 높은 가용성 → 언제든 복구가능 Kinesis → 로그 유입량에 따라 유연하게 대응가능 저희는 아직 적용하진 않았지만 오토 스케일링도 가능합니다.
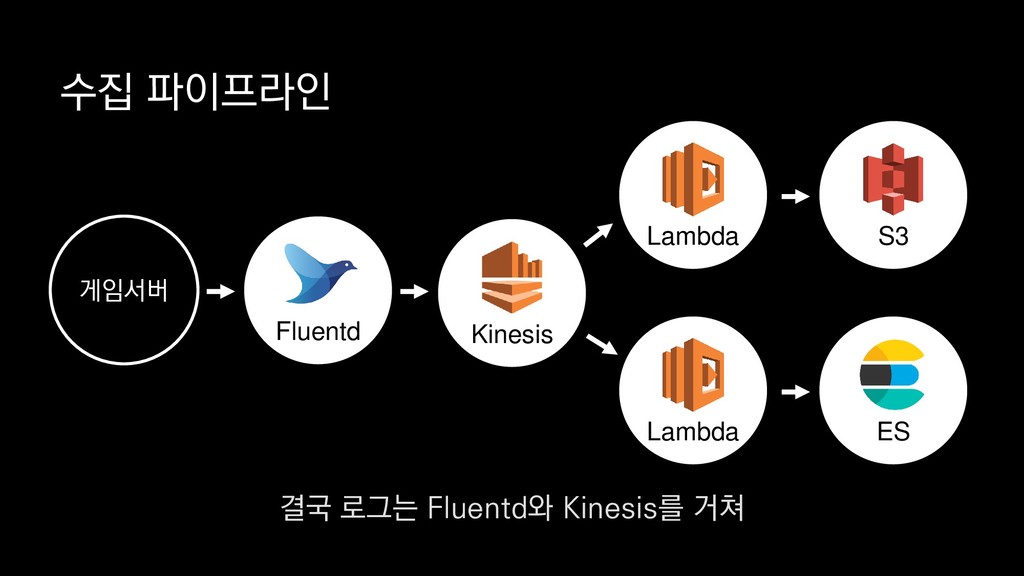
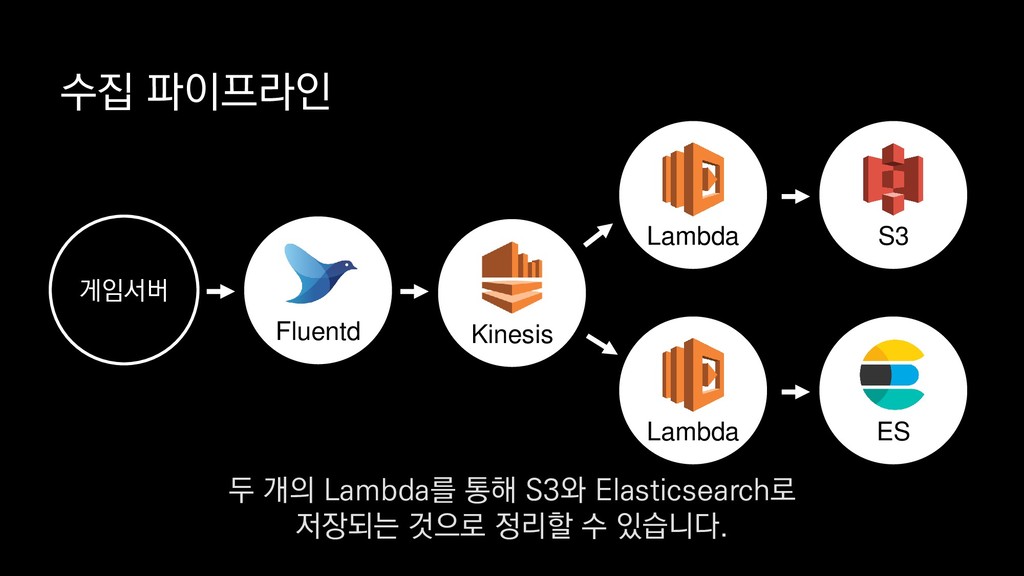
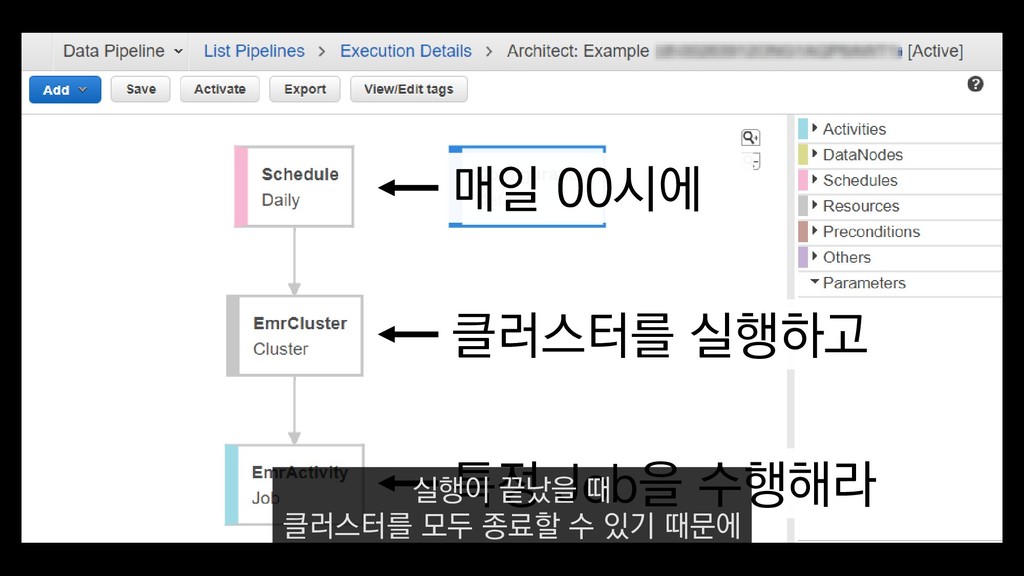
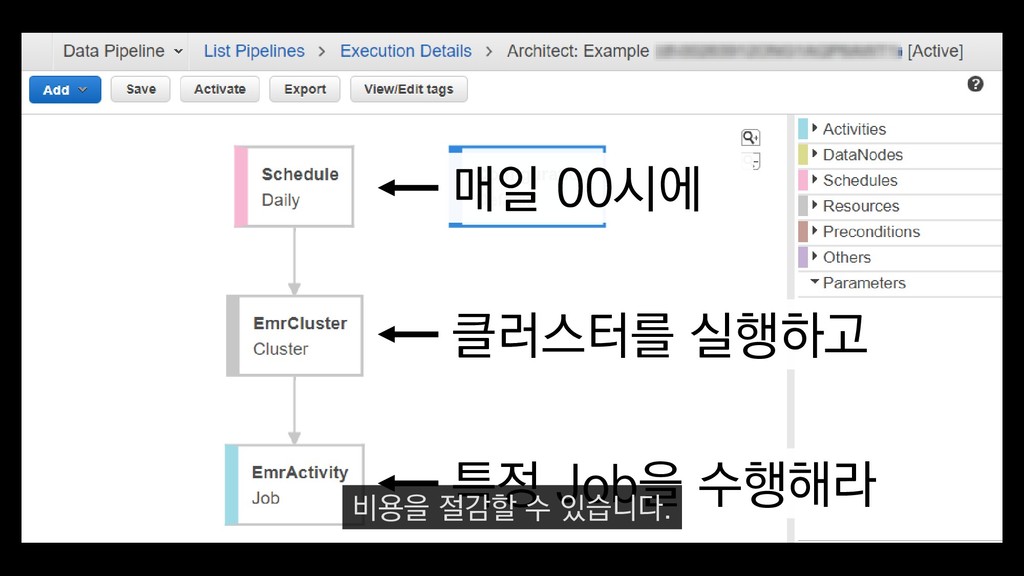
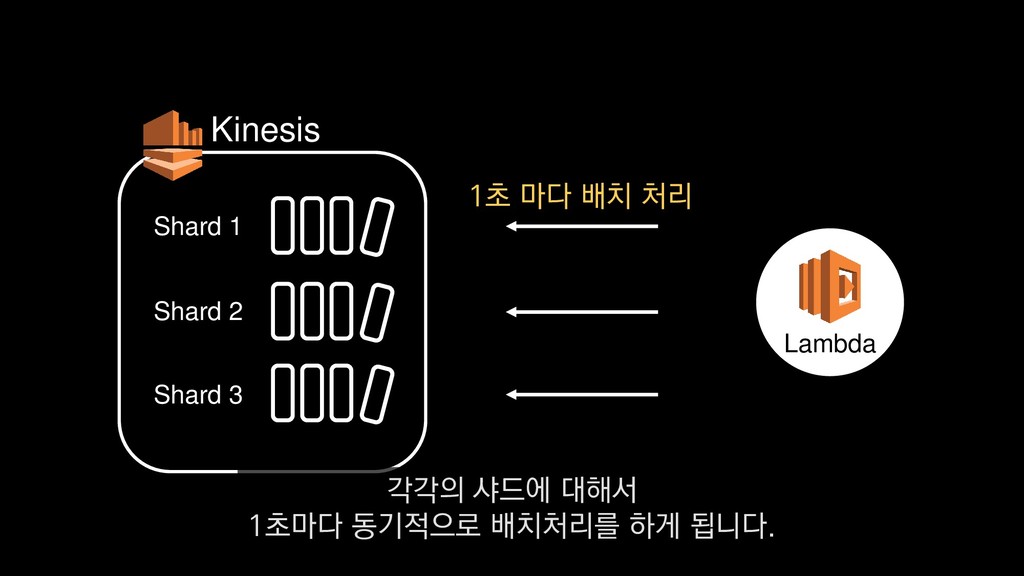
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 여기서 잠시 로그 수집 파이프라인의 비용을 살펴보면
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 만약에 초당 1000개의 로그가 지속적으로 유입되고
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 초당 2MB정도 유입된다고 가정하면
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 월 5TB정도의 로그가 발생하는데요.
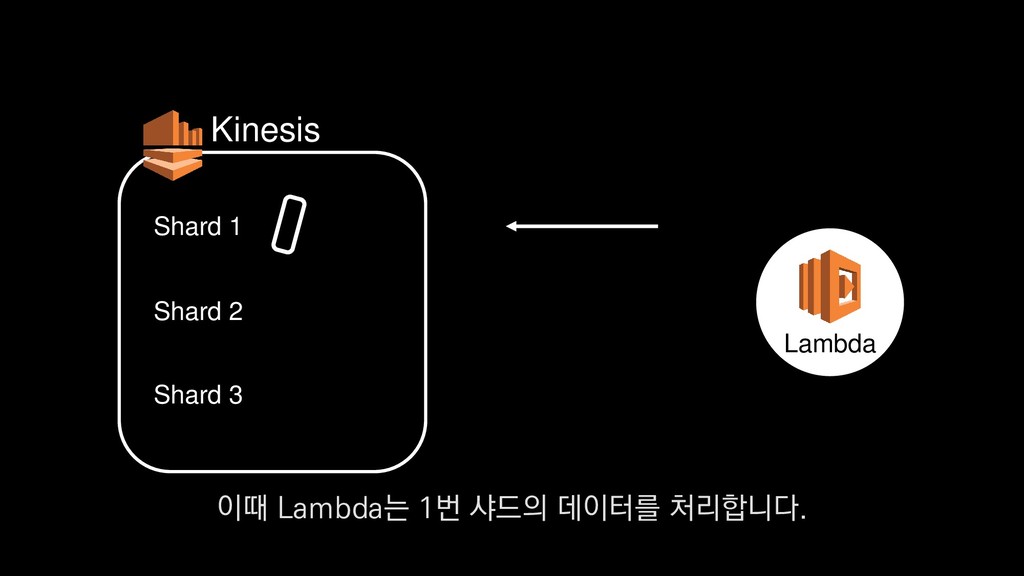
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 이 때 최소로 필요한 Kinesis 샤드 2개와
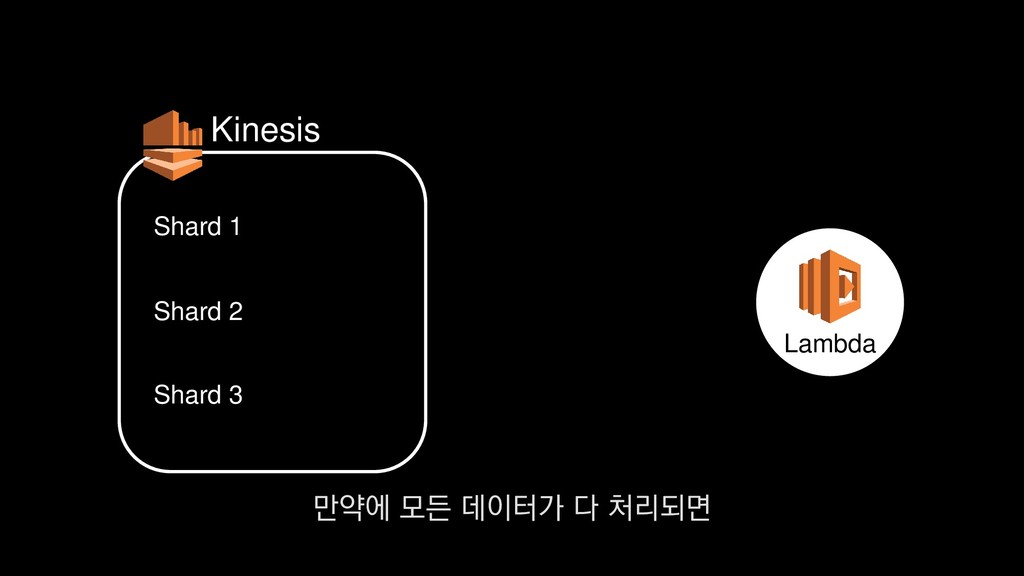
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 데이터를 기록하는 비용, Lambda에서 처리하는 비용을 모두 합쳐도
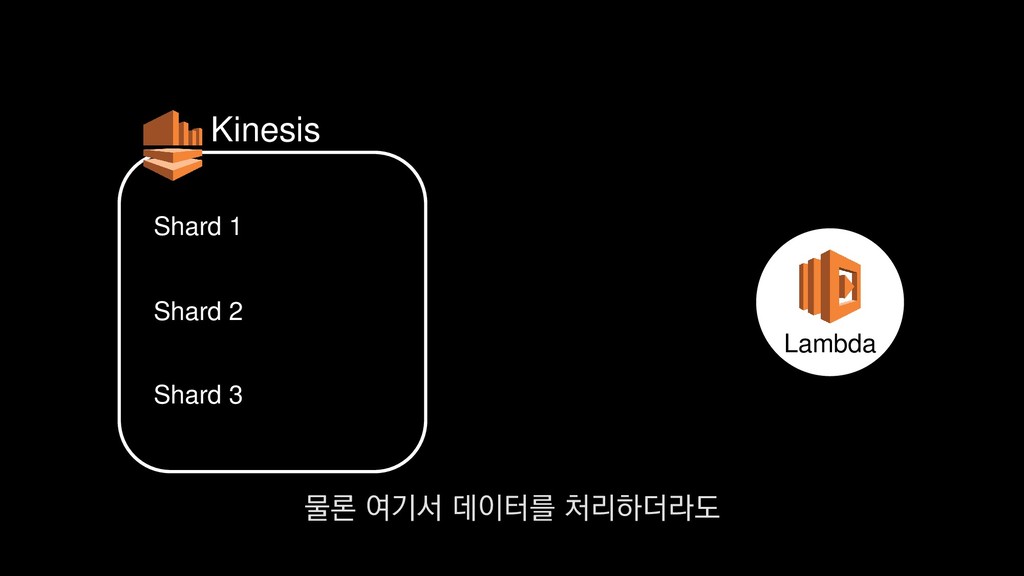
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 월 110달러 정도의 유지 비용이 발생합니다.
로그는 2KB(월 5TB 정도) • Kinesis 샤드 2개 + 데이터 PUT 비용 • Lambda (처리시간 1초) → 약 $90 → 약 $20 3. Kinesis + Lambda 월 유지비용 → 월 $110 정도로 유지 비용(저장비용 제외) 물론 이건 저장비용을 제외하고, 최소로 맞춘 스펙이니 참고만 부탁드립니다.
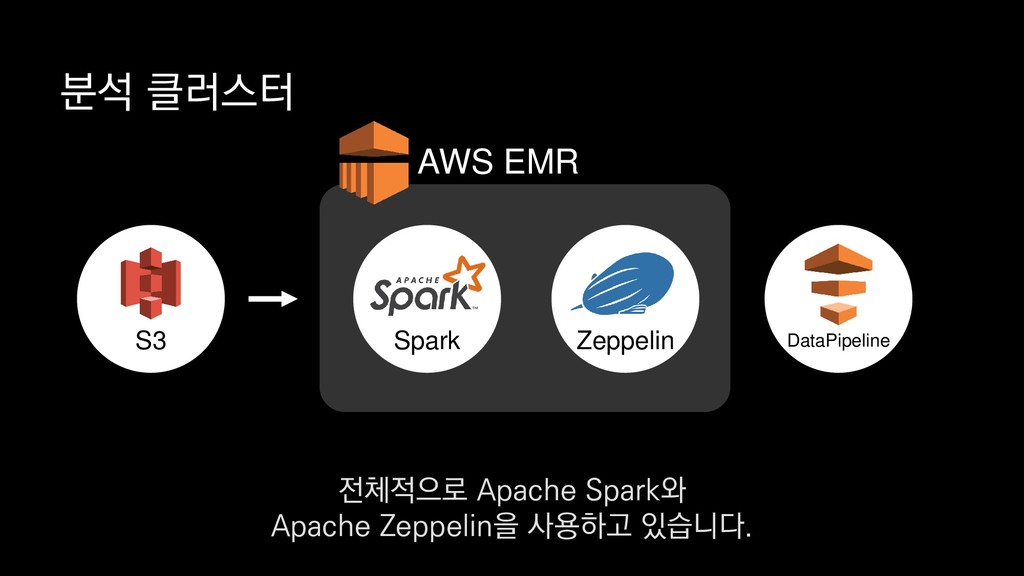
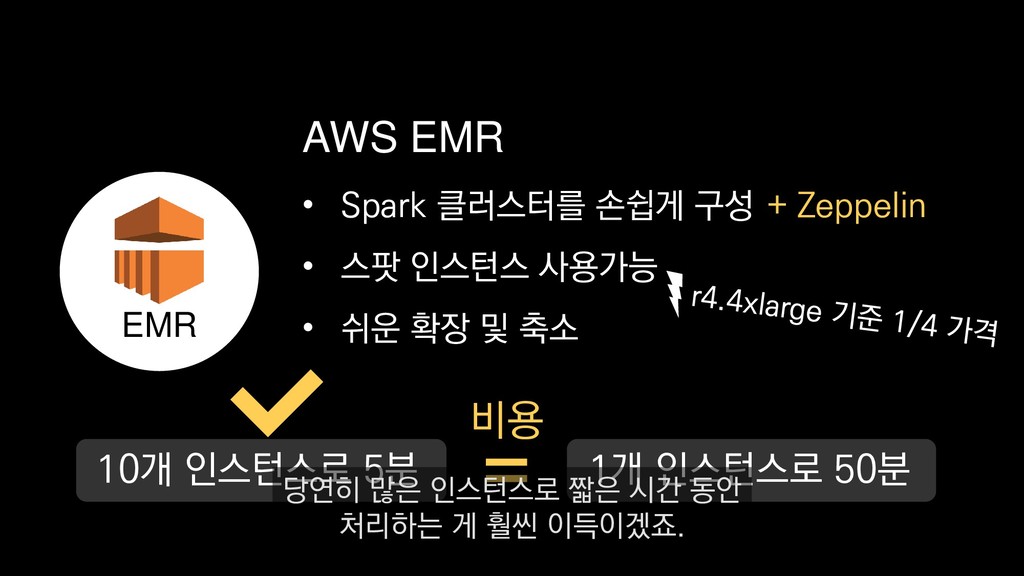
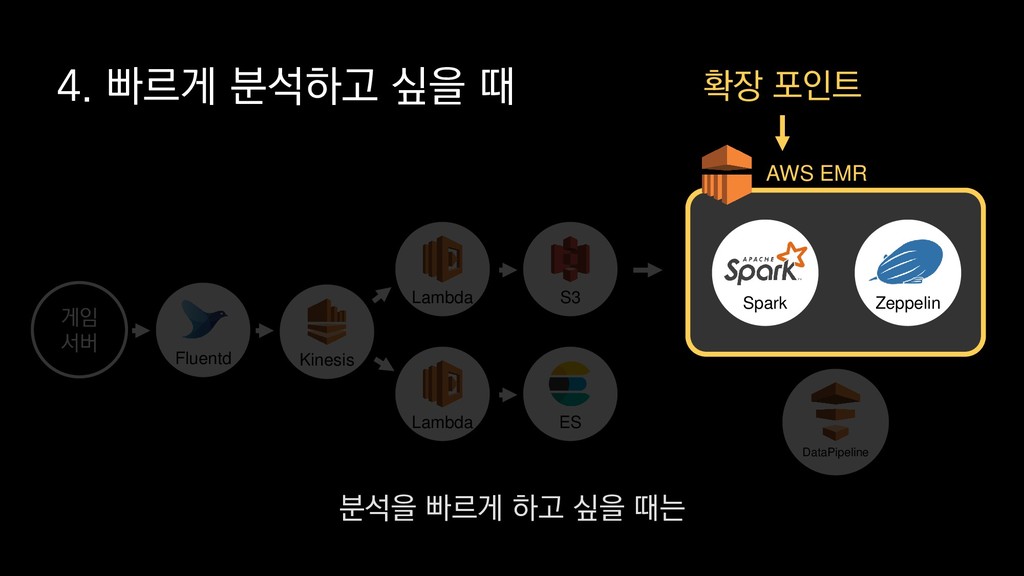
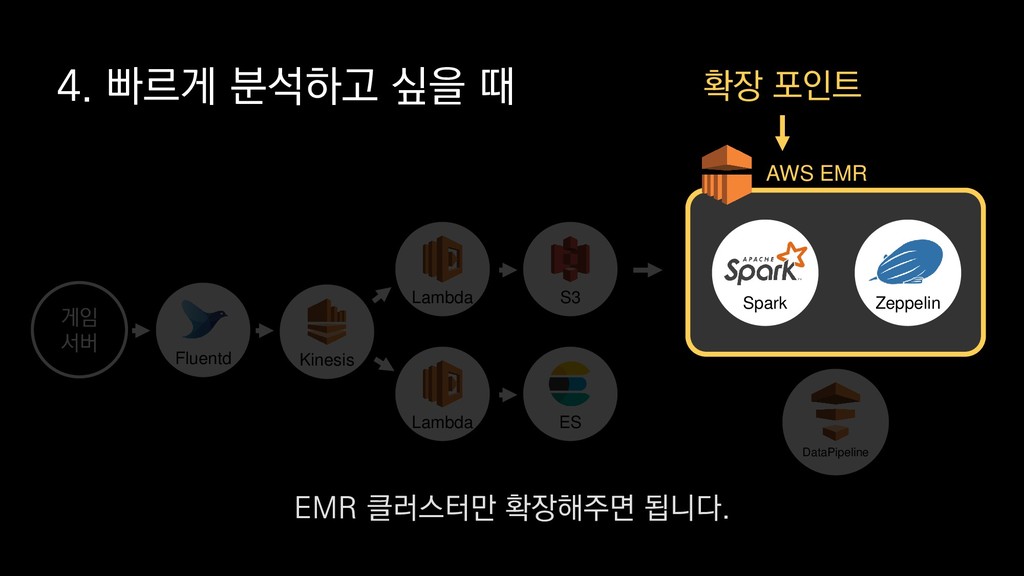
X 10 스팟 인스턴스, 도쿄 리전 기준 • 생성된 모든 섬의 개수 • 가장 많이 채집된 자원(10위까지) • 모든 섬의 날짜별 일일 활성 유저수 → 5분 = $1 미만 → 10분 = 약$1 → 15분 = 약 $ 1.3 프로비저닝 시간 제외, 2018년 4월 24일 기준 만약 대규모 분석을 위해서
X 10 스팟 인스턴스, 도쿄 리전 기준 • 생성된 모든 섬의 개수 • 가장 많이 채집된 자원(10위까지) • 모든 섬의 날짜별 일일 활성 유저수 → 5분 = $1 미만 → 10분 = 약$1 → 15분 = 약 $ 1.3 프로비저닝 시간 제외, 2018년 4월 24일 기준 도쿄 리전을 기준으로 r4.8xlarge 타입의 인스턴스를 스팟 인스턴스로 10개를 띄우고
X 10 스팟 인스턴스, 도쿄 리전 기준 • 생성된 모든 섬의 개수 • 가장 많이 채집된 자원(10위까지) • 모든 섬의 날짜별 일일 활성 유저수 → 5분 = $1 미만 → 10분 = 약$1 → 15분 = 약 $ 1.3 프로비저닝 시간 제외, 2018년 4월 24일 기준 분석이 끝나는 즉시 종료한다면
X 10 스팟 인스턴스, 도쿄 리전 기준 • 생성된 모든 섬의 개수 • 가장 많이 채집된 자원(10위까지) • 모든 섬의 날짜별 일일 활성 유저수 → 5분 = $1 미만 → 10분 = 약$1 → 15분 = 약 $ 1.3 프로비저닝 시간 제외, 2018년 4월 24일 기준 보시는 바와 같이 시간과 비용을 최대한 절감할 수 있습니다.
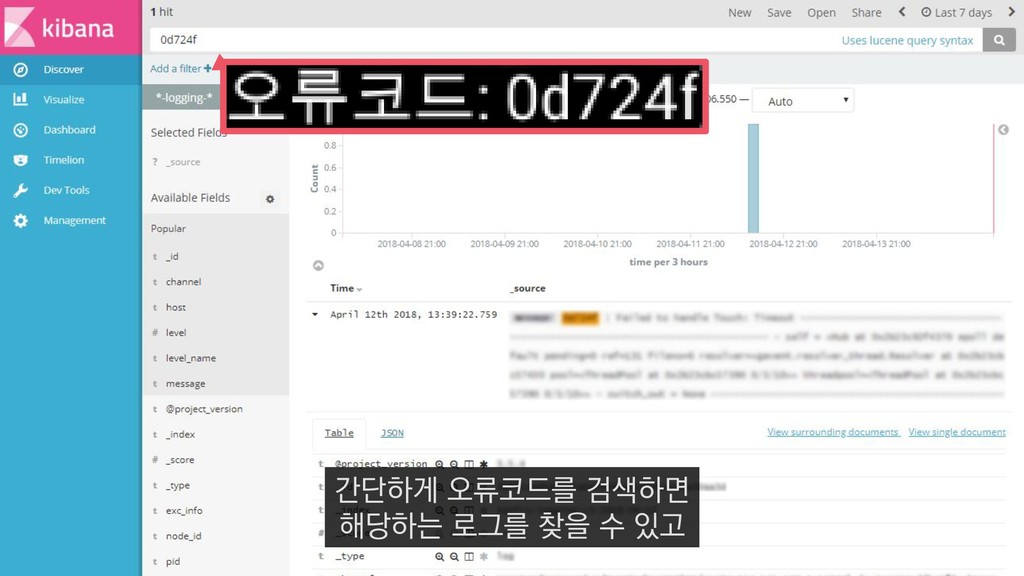
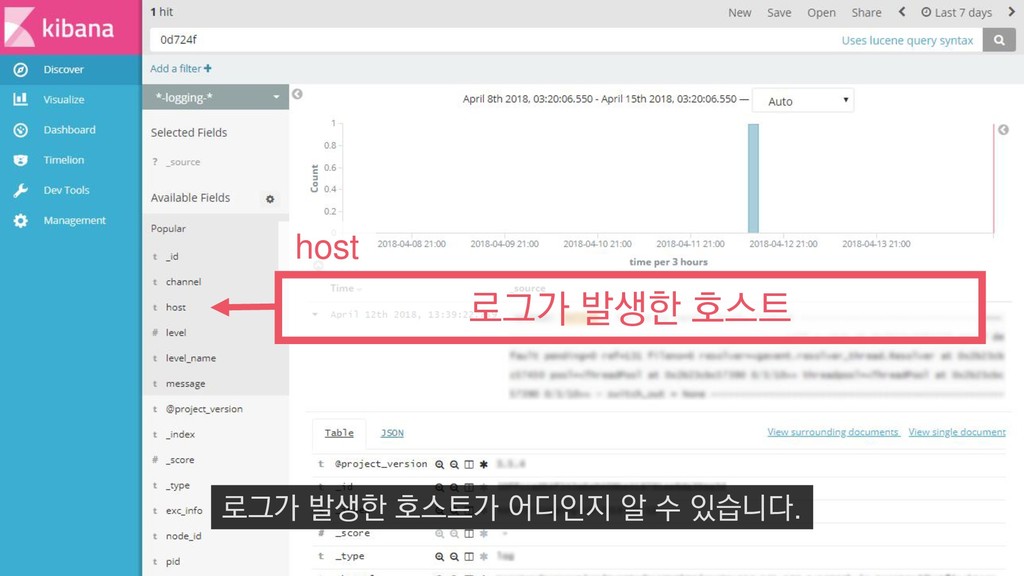
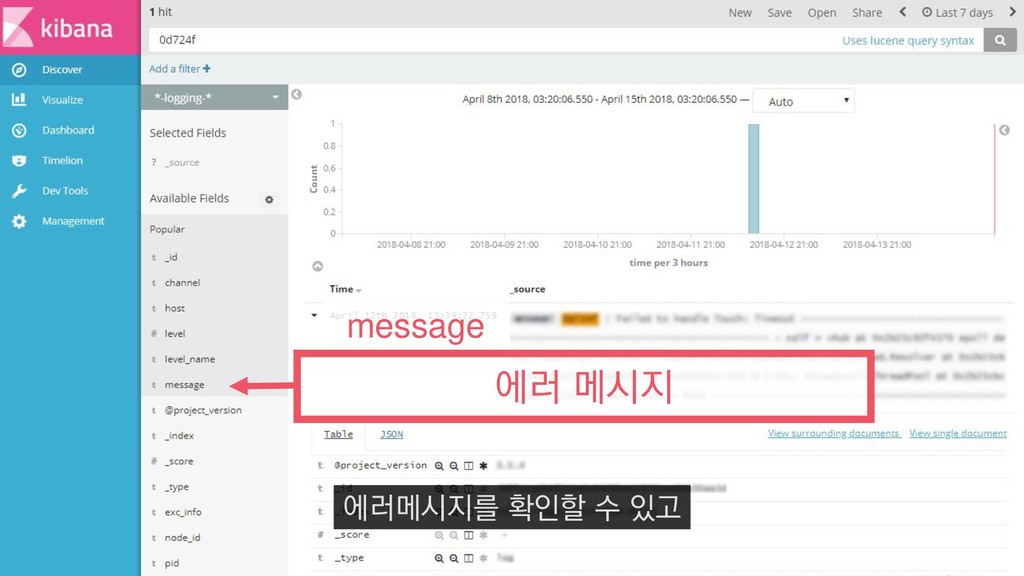
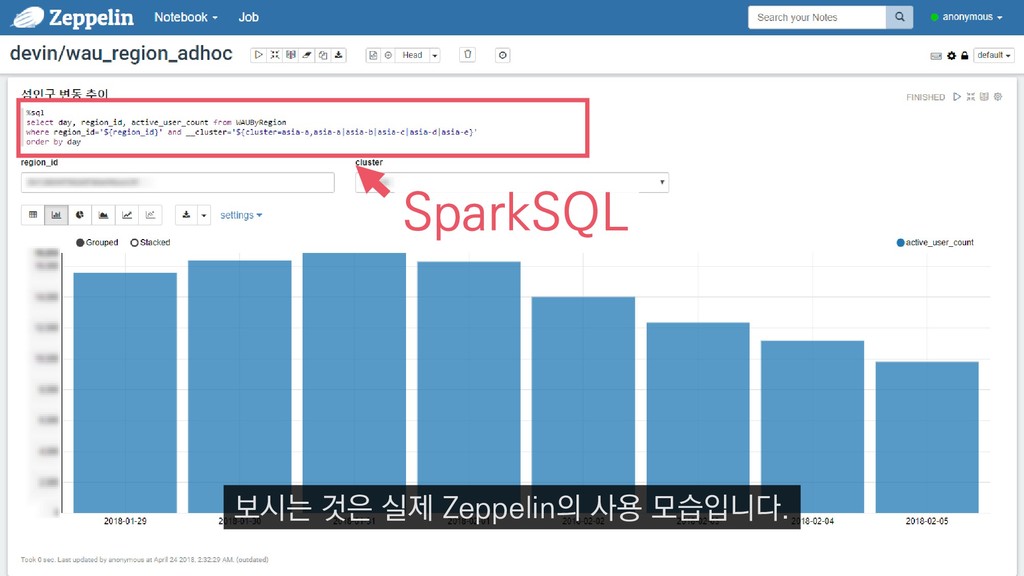
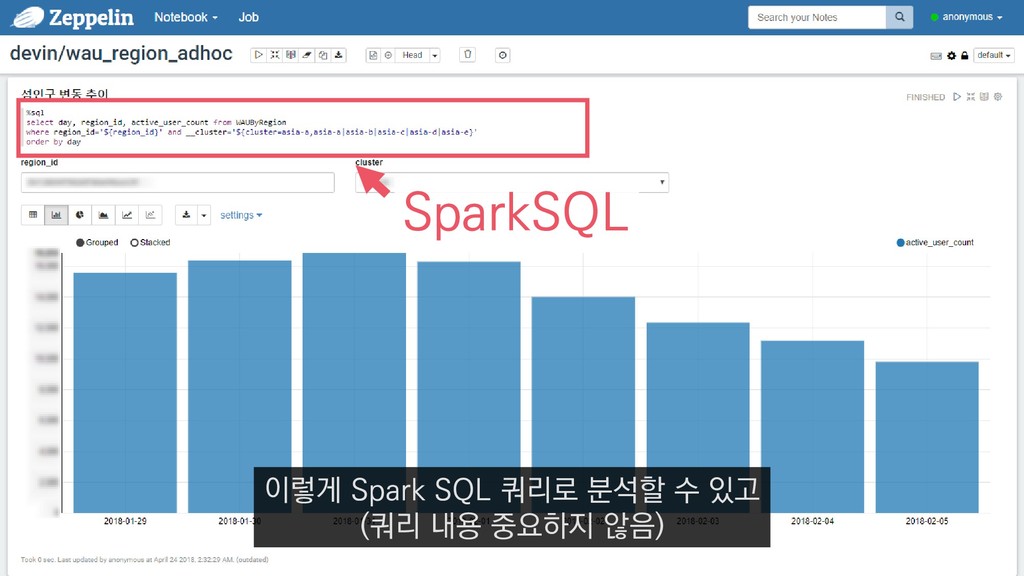
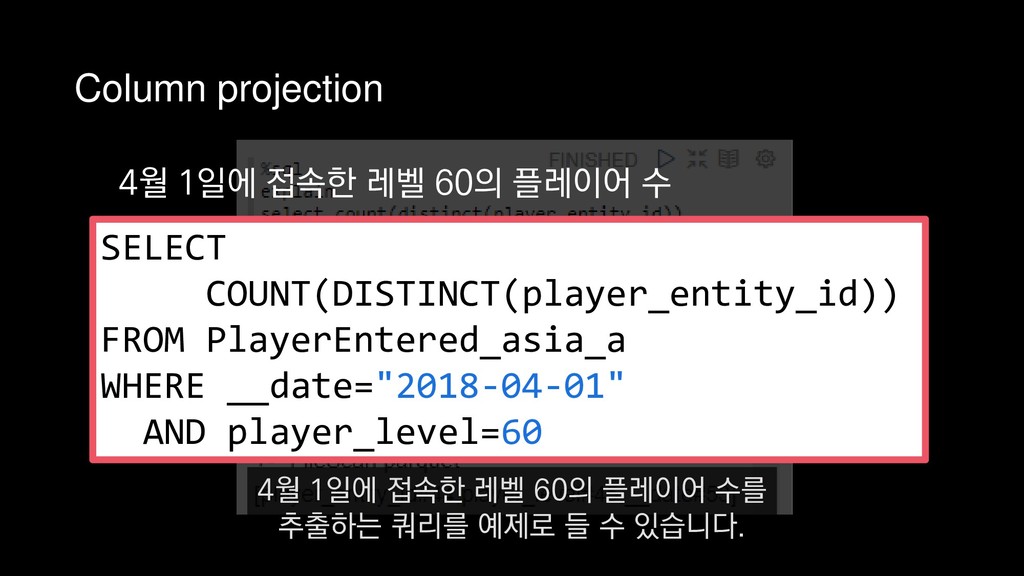
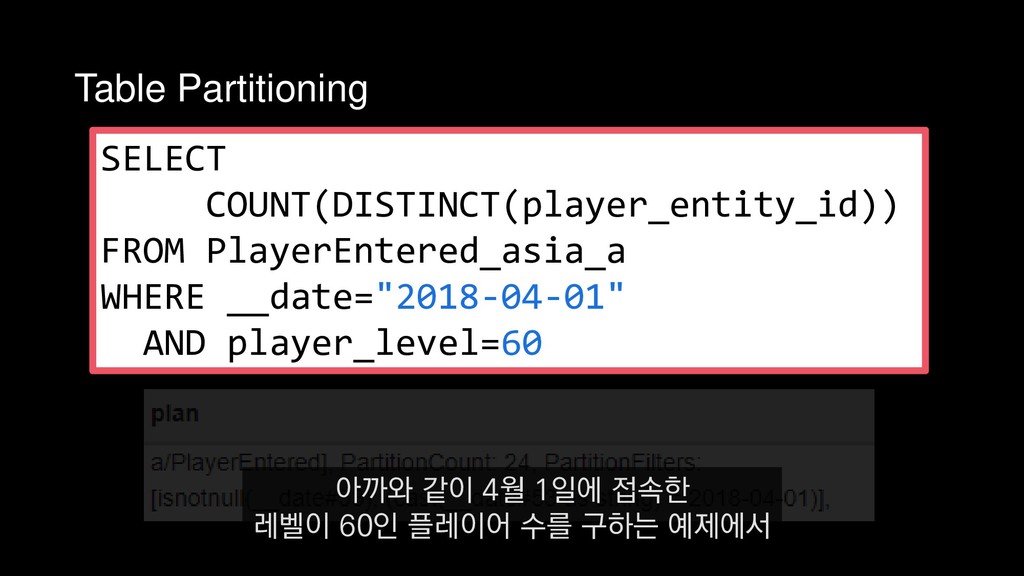
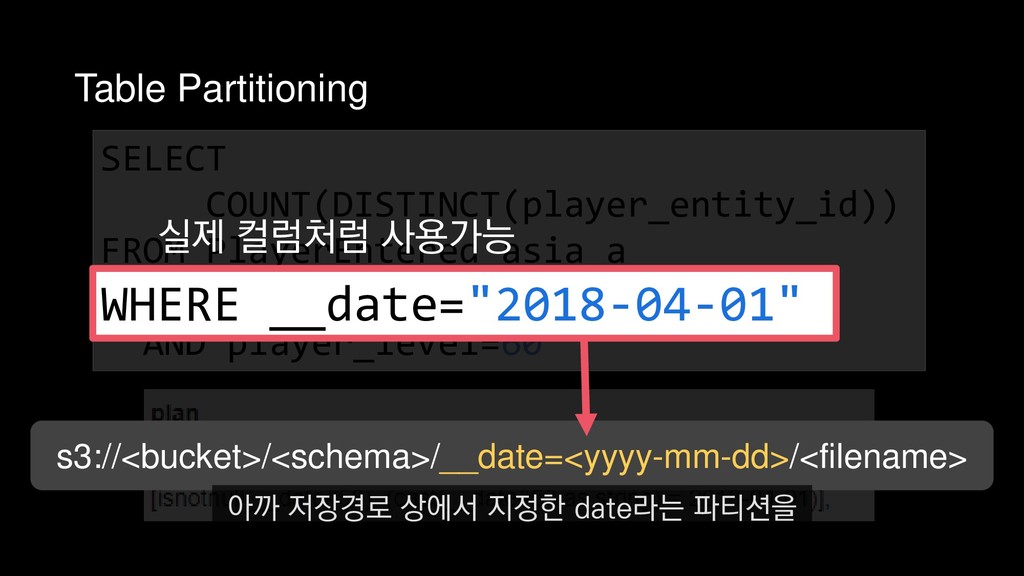
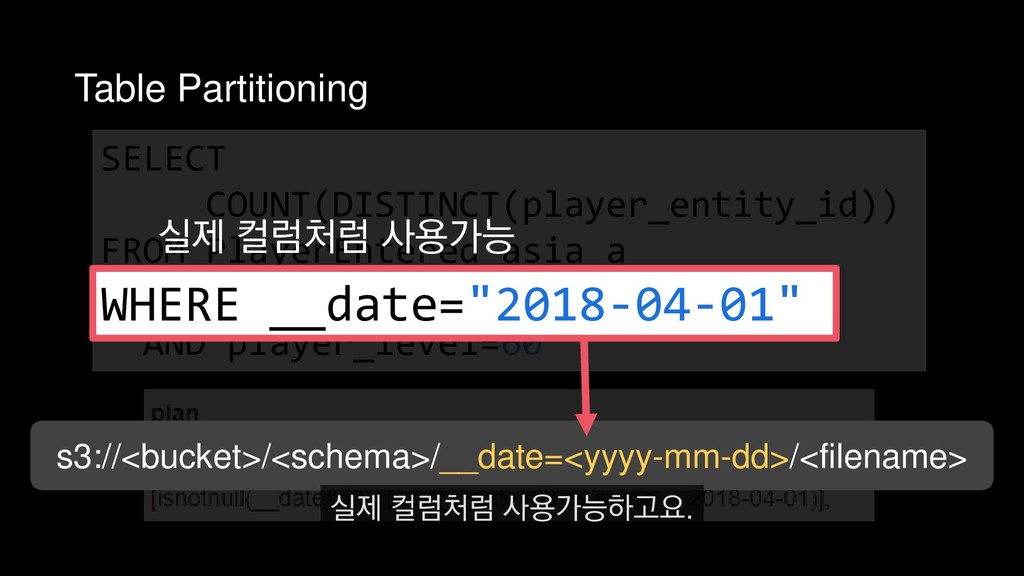
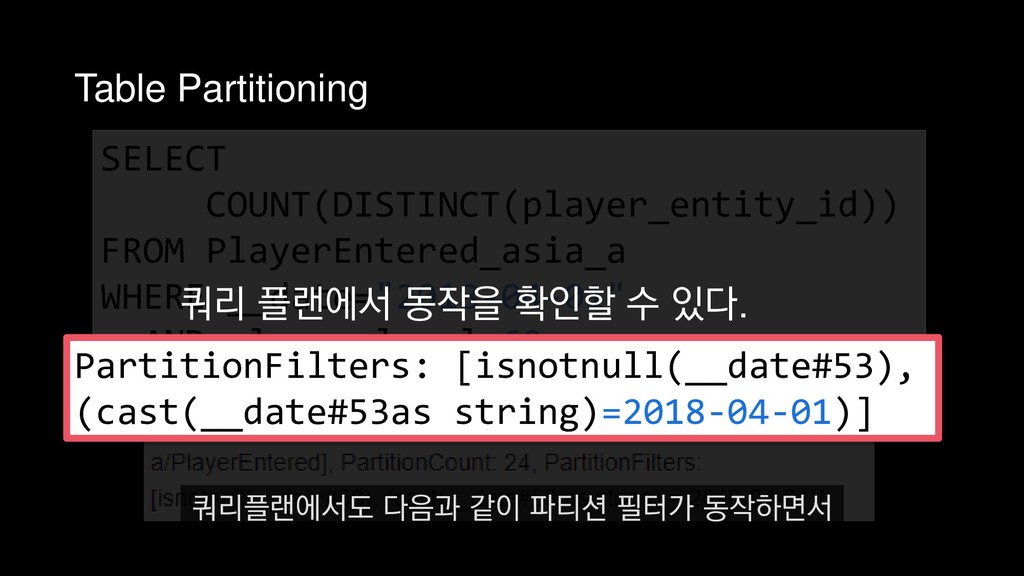
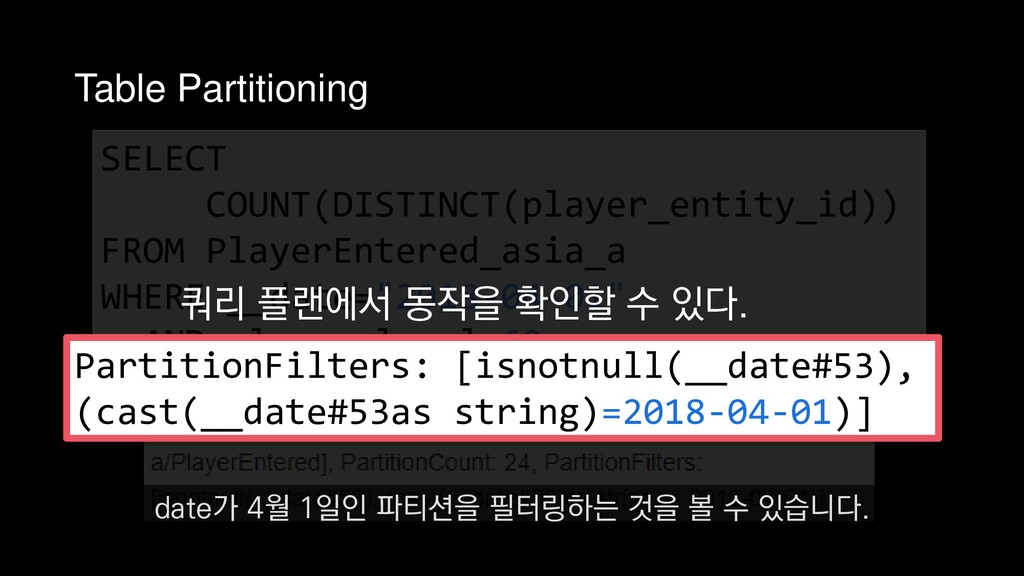
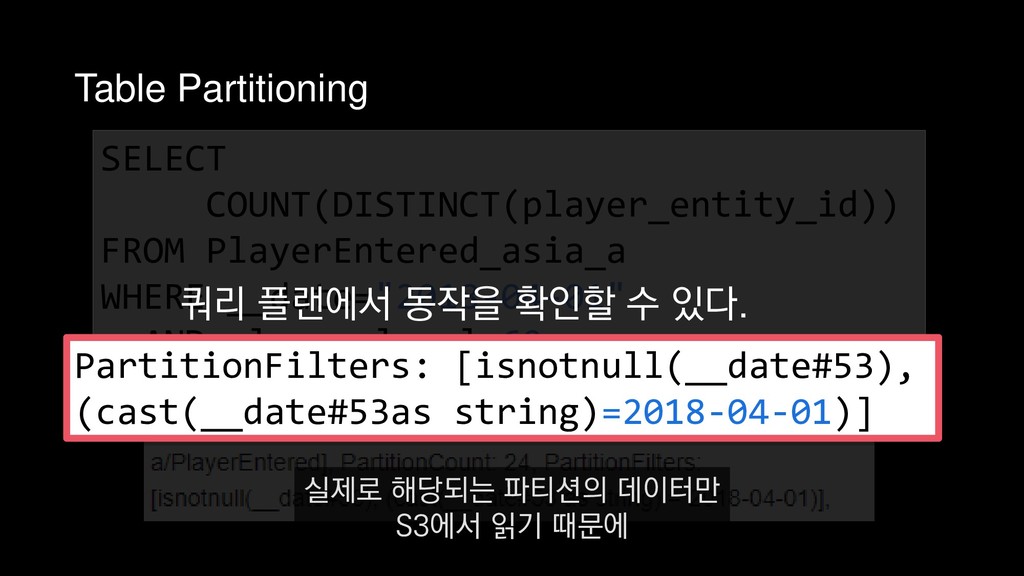
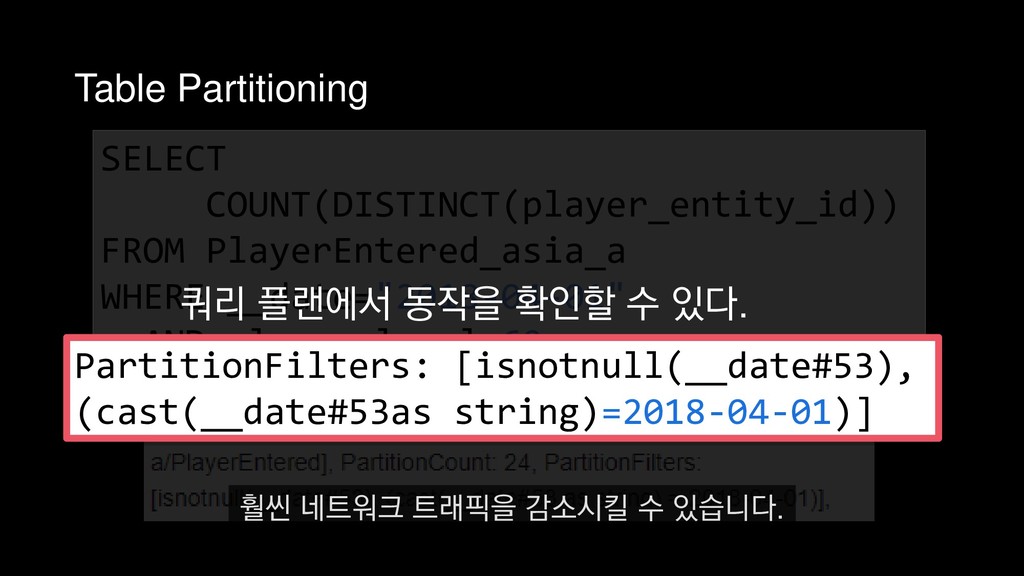
COUNT(DISTINCT(player_entity_id)) FROM PlayerEntered_asia_a WHERE __date="2018-04-01" AND player_level=60 4월 1일에 접속한 레벨 60의 플레이어 수를 추출하는 쿼리를 예제로 들 수 있습니다.
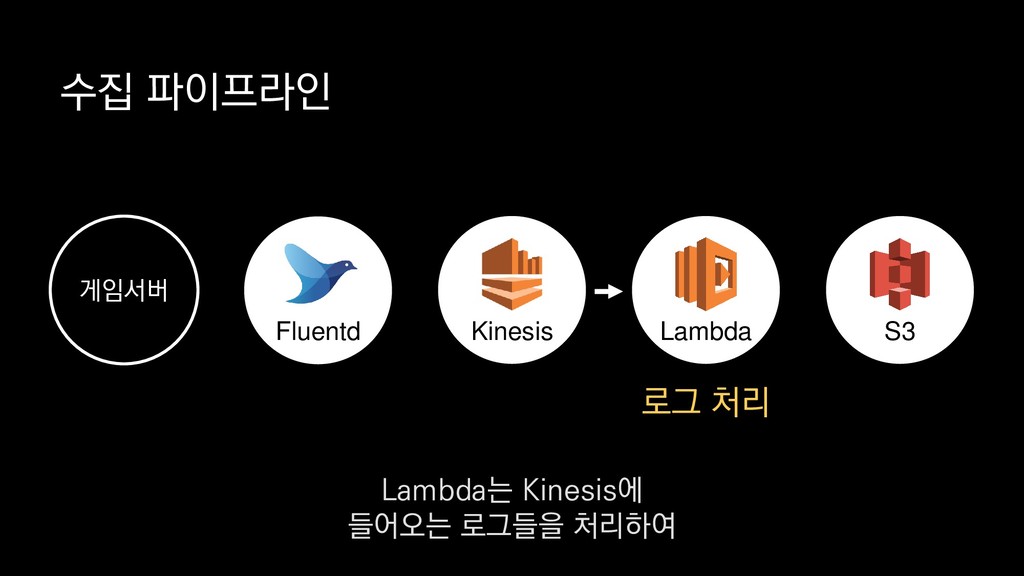
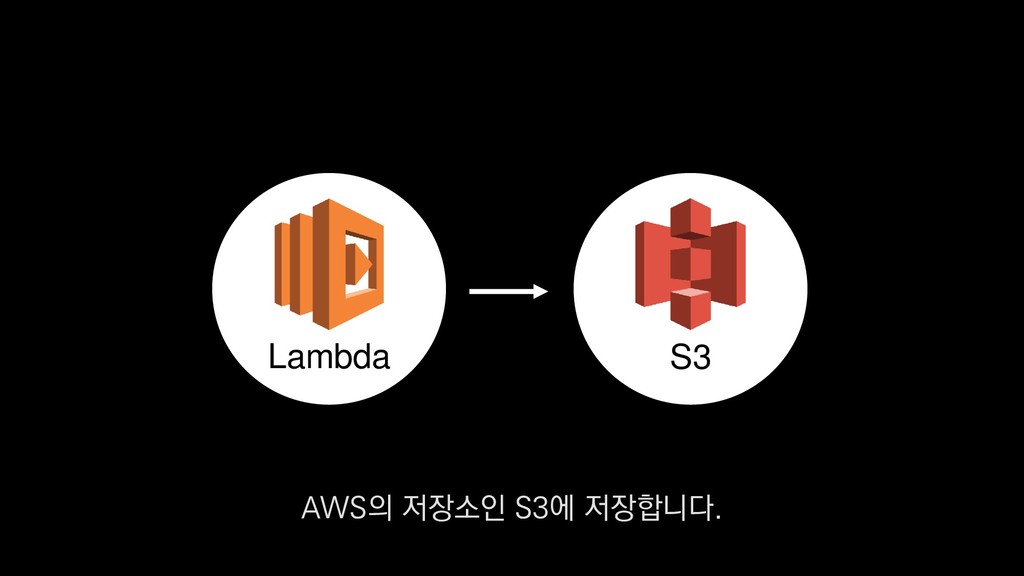
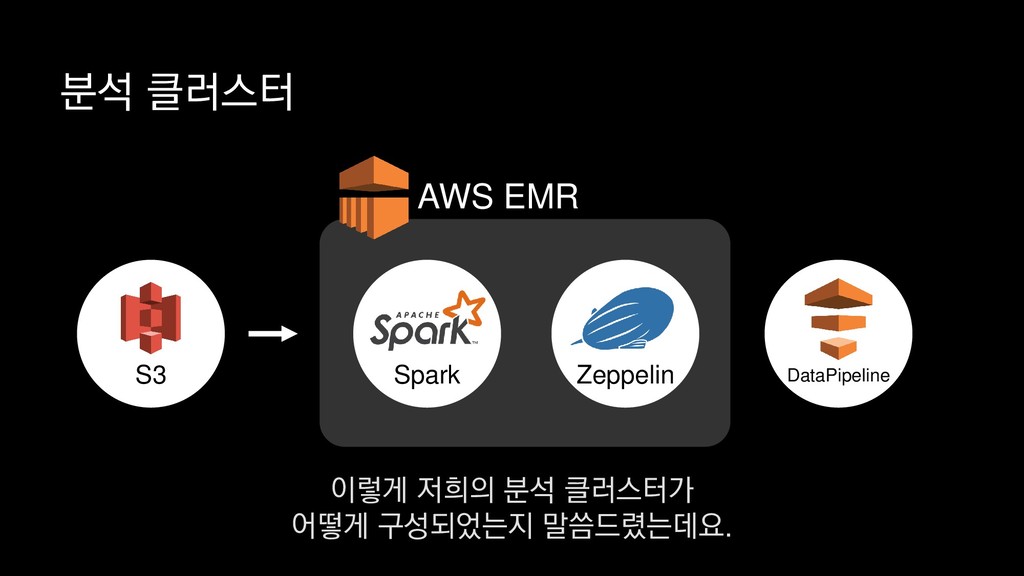
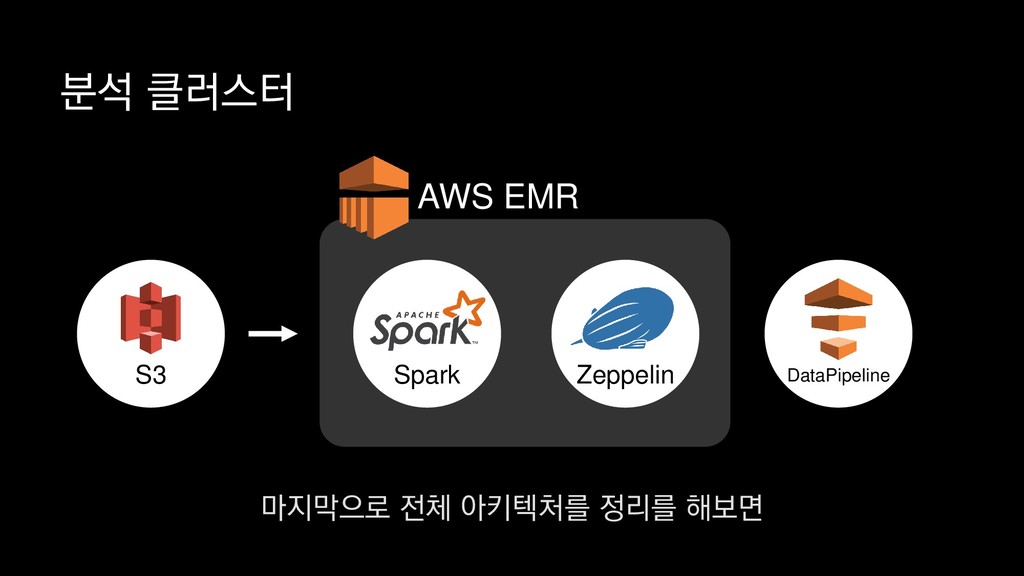
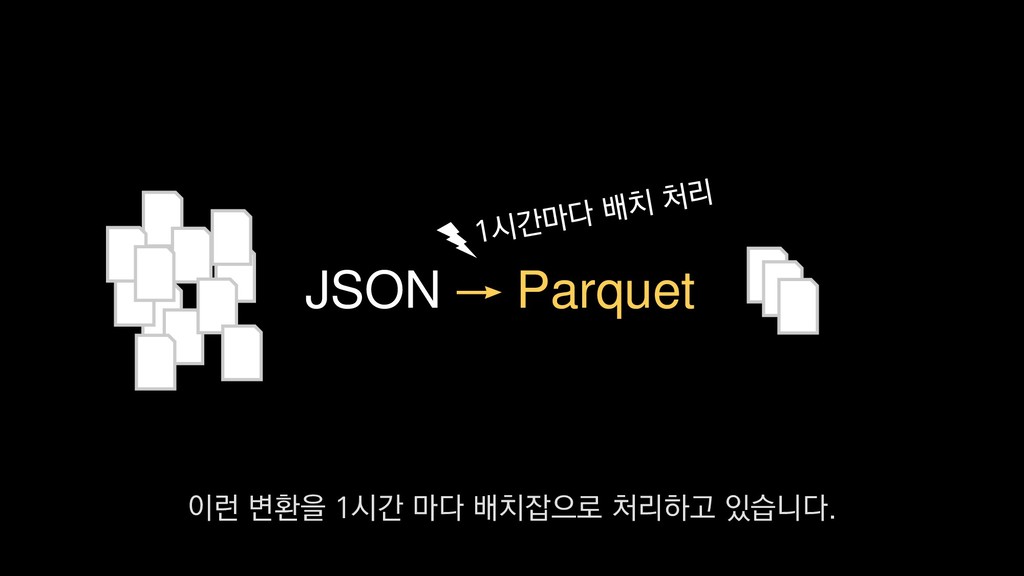
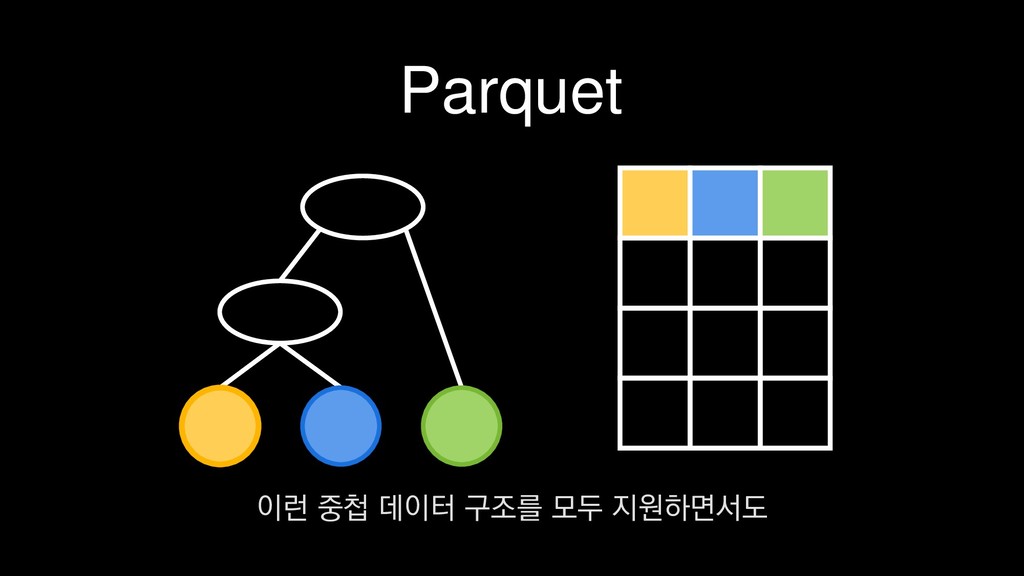
1. 스키마 별 Class 추가 또는 업데이트 2. 배포 시 Spark StructType JSON 포맷으로 추출 3. AWS S3에 저장 4. Parquet 변환 배치잡에서 매번 스키마 정보를 읽고 수행 PySpark 보시는 코드와 같이 JSON으로된 스키마 파일을 로드하여
1. 스키마 별 Class 추가 또는 업데이트 2. 배포 시 Spark StructType JSON 포맷으로 추출 3. AWS S3에 저장 4. Parquet 변환 배치잡에서 매번 스키마 정보를 읽고 수행 PySpark 물론 JSON 로그로 부터 스키마를 추론할 수 있기도 하지만
1. 스키마 별 Class 추가 또는 업데이트 2. 배포 시 Spark StructType JSON 포맷으로 추출 3. AWS S3에 저장 4. Parquet 변환 배치잡에서 매번 스키마 정보를 읽고 수행 PySpark 스키마를 따로 정의하고 관리하는 방법을 사용하고 있습니다.
이야기 김찬웅 님 / 4월 25일 오후 4시 30분 〈야생의 땅: 듀랑고〉 서버 아키텍처 Vol. 3 이흥섭 님 / 4월 25일 오후 3시 20분 〈야생의 땅: 듀랑고〉 NoSQL 위에서 MMORPG 개발하기 최호영 님 / 4월 26일 오전 11시 듀랑고의 서버에 관련된 발표로
이야기 김찬웅 님 / 4월 25일 오후 4시 30분 〈야생의 땅: 듀랑고〉 서버 아키텍처 Vol. 3 이흥섭 님 / 4월 25일 오후 3시 20분 〈야생의 땅: 듀랑고〉 NoSQL 위에서 MMORPG 개발하기 최호영 님 / 4월 26일 오전 11시 내일과 내일 모레에도 세션들이 준비되어있으니
이야기 김찬웅 님 / 4월 25일 오후 4시 30분 〈야생의 땅: 듀랑고〉 서버 아키텍처 Vol. 3 이흥섭 님 / 4월 25일 오후 3시 20분 〈야생의 땅: 듀랑고〉 NoSQL 위에서 MMORPG 개발하기 최호영 님 / 4월 26일 오전 11시 관심있는 분들은 많은 참석바랍니다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
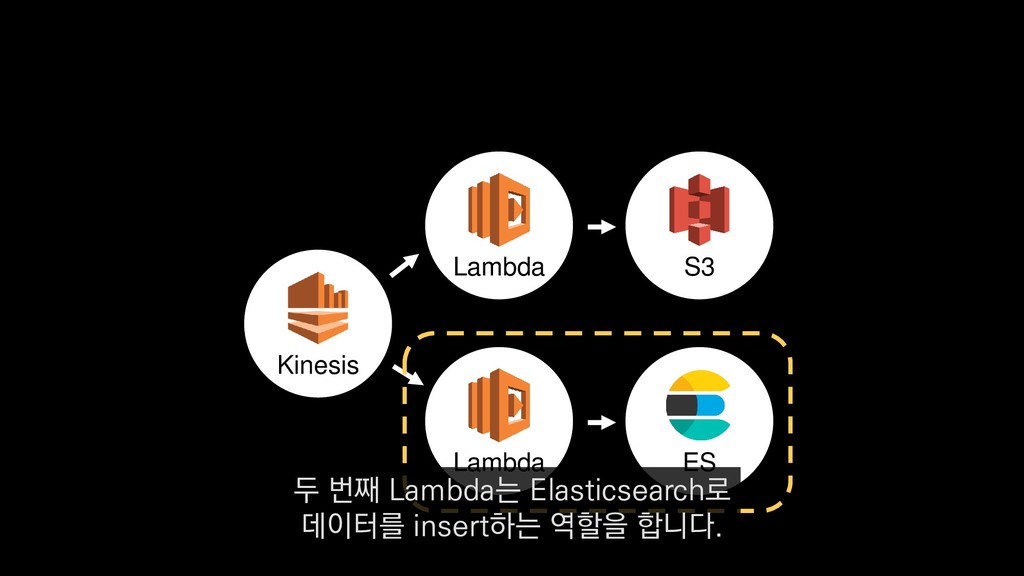{kind=link}
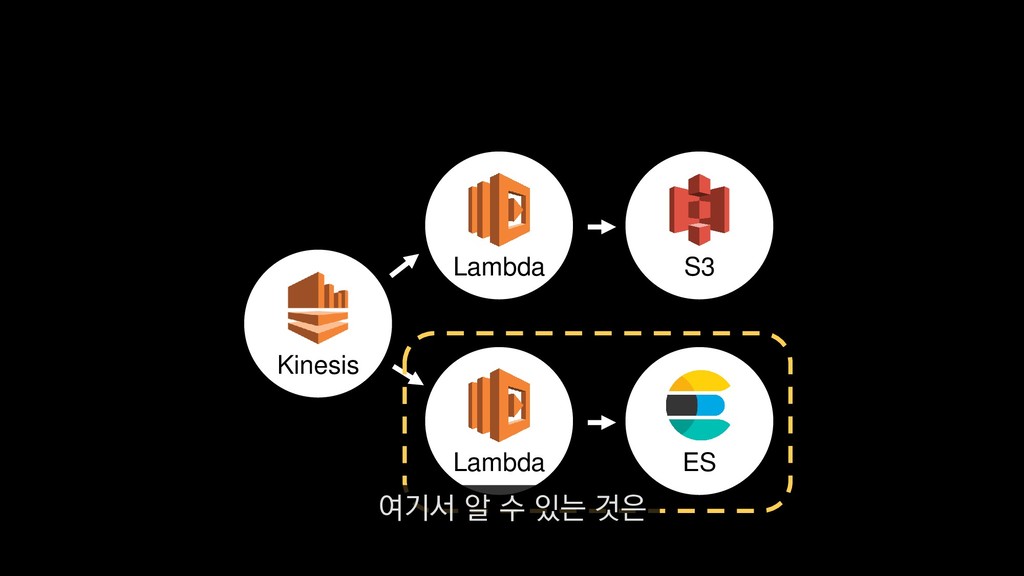{kind=link}
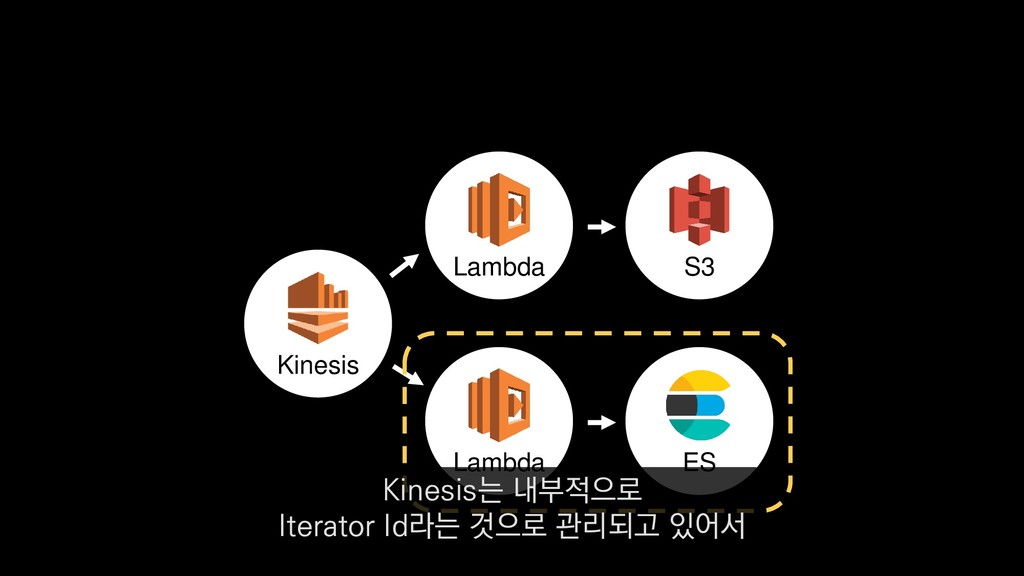{kind=link}
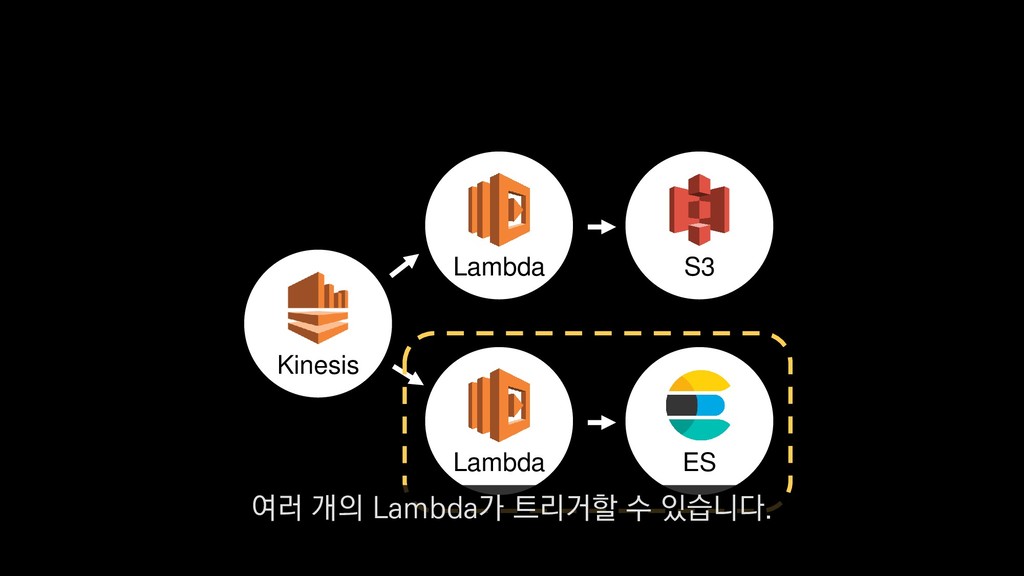{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
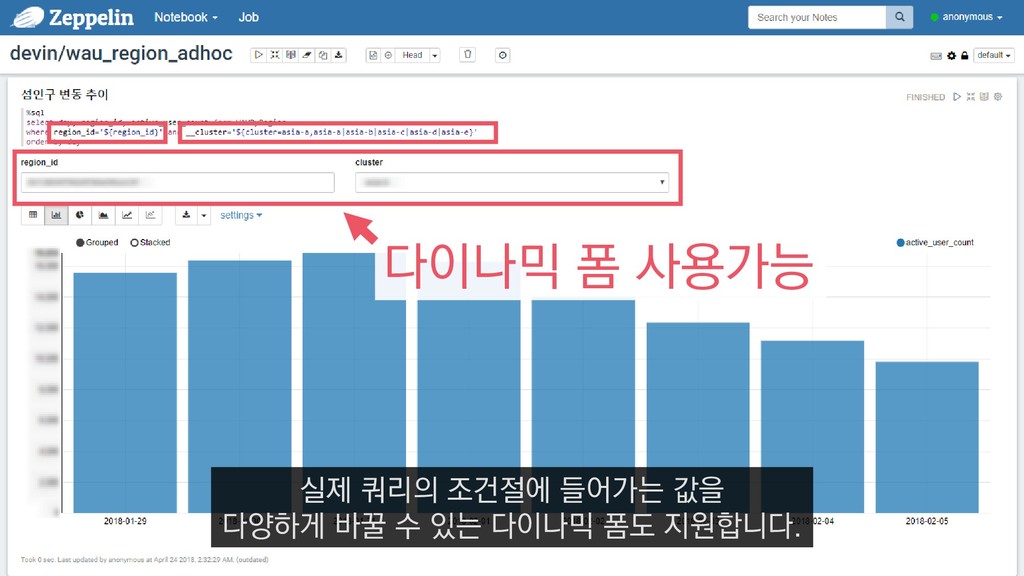{kind=link}
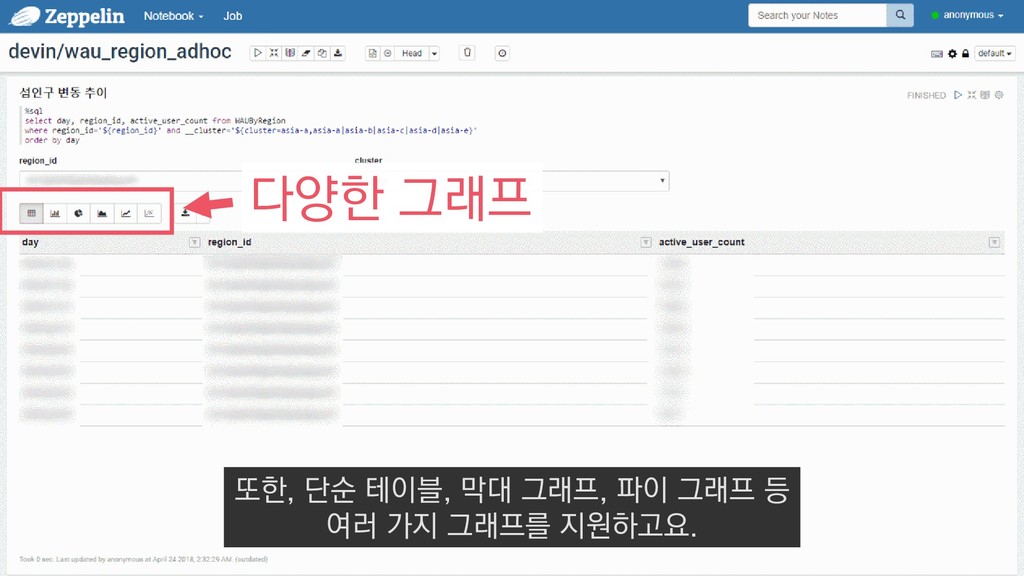{kind=link}
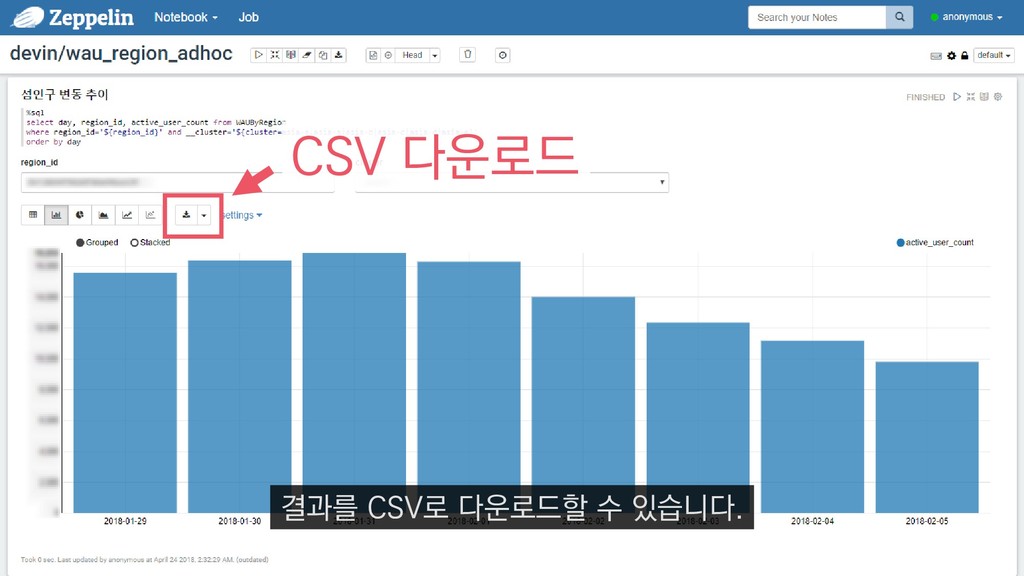{kind=link}
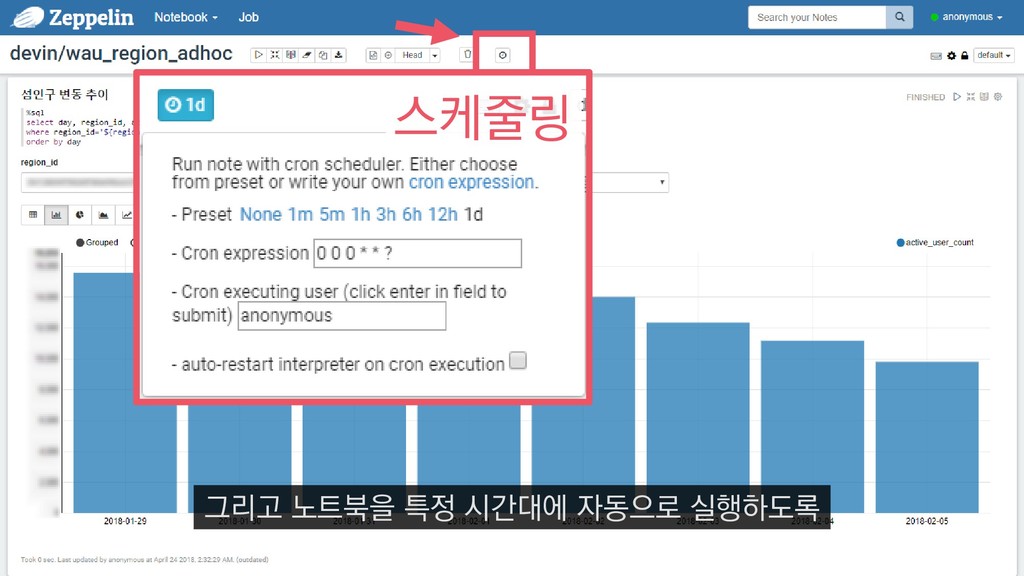{kind=link}
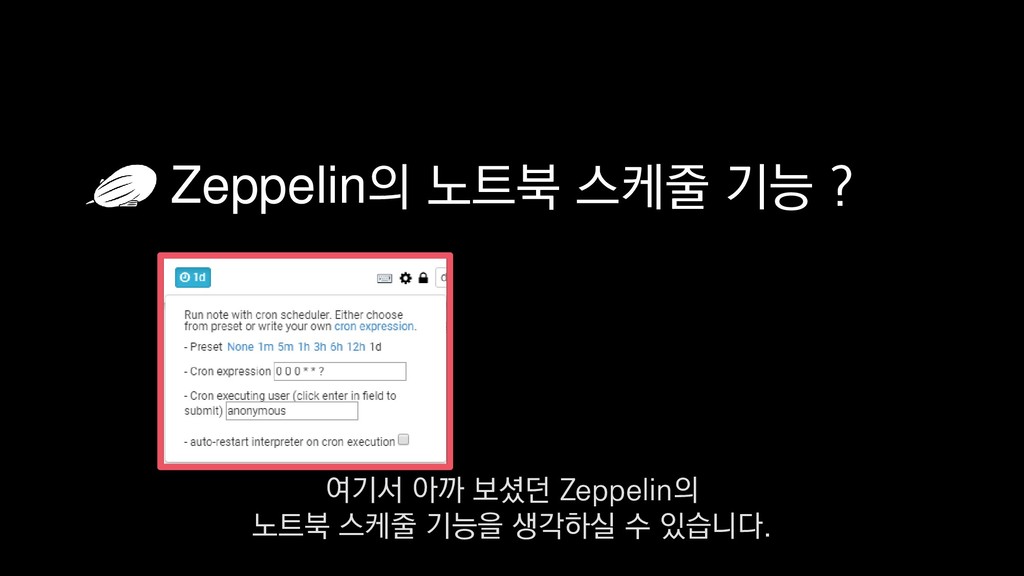
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
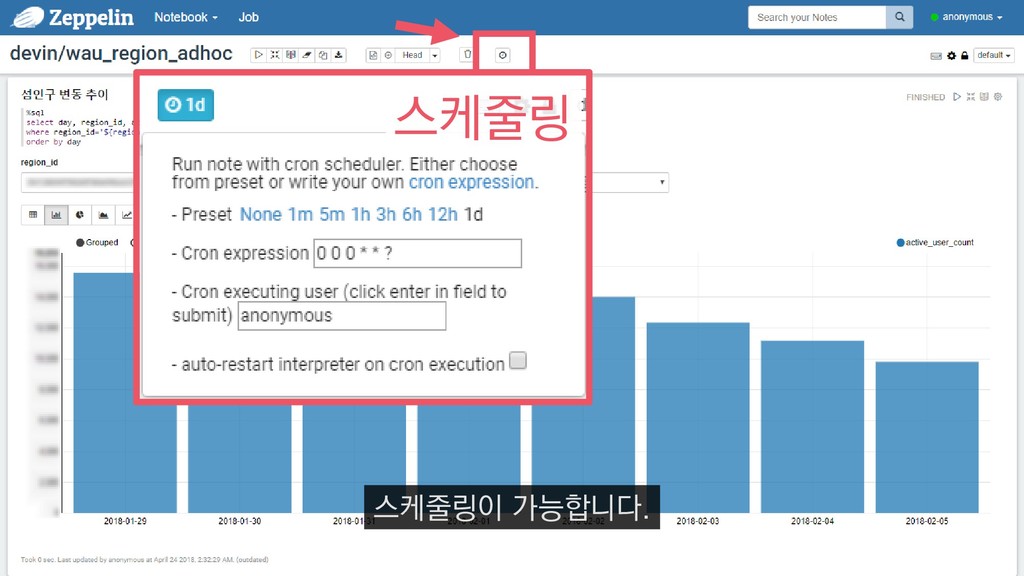
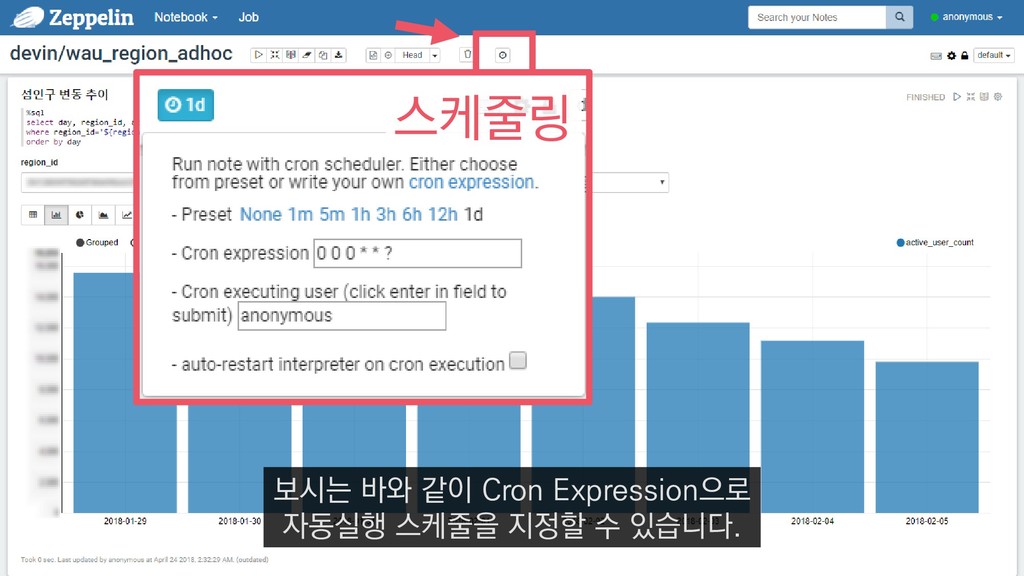
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
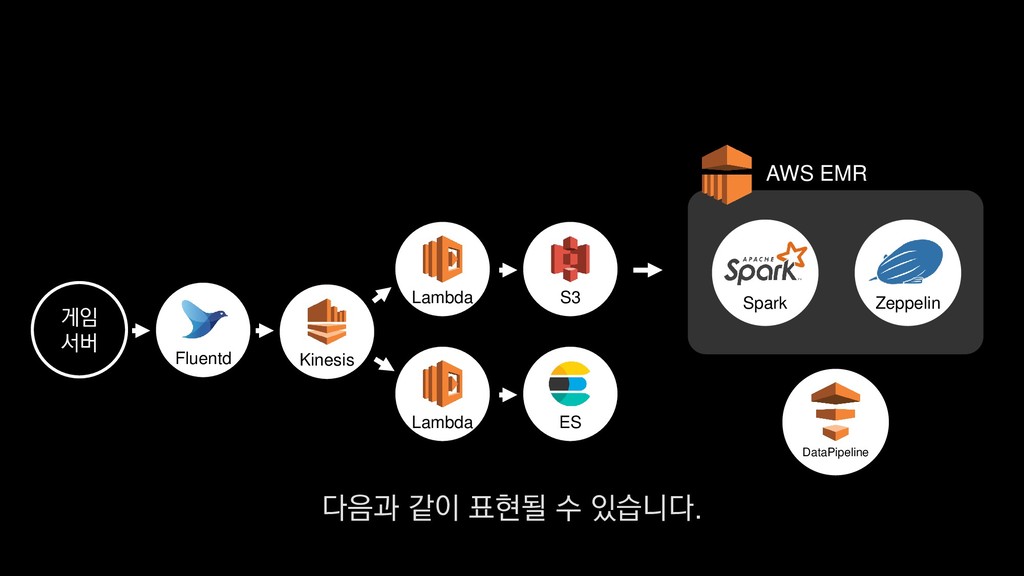{kind=link}
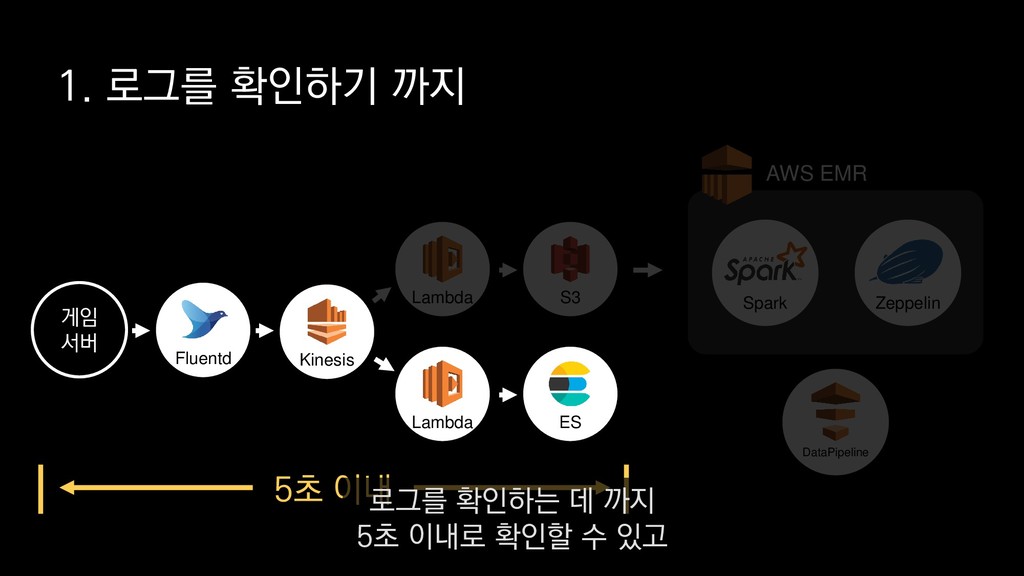{kind=link}
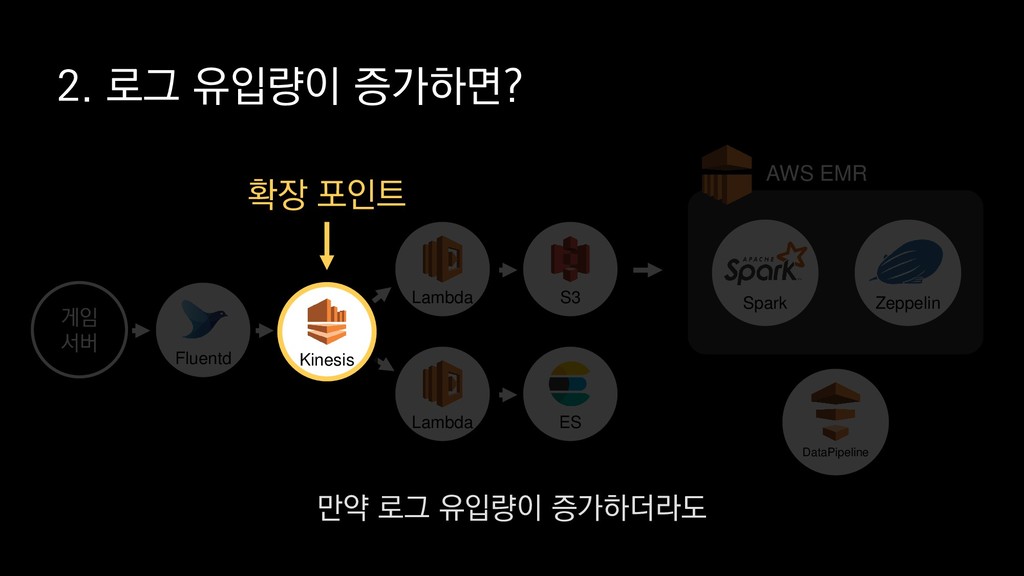{kind=link}
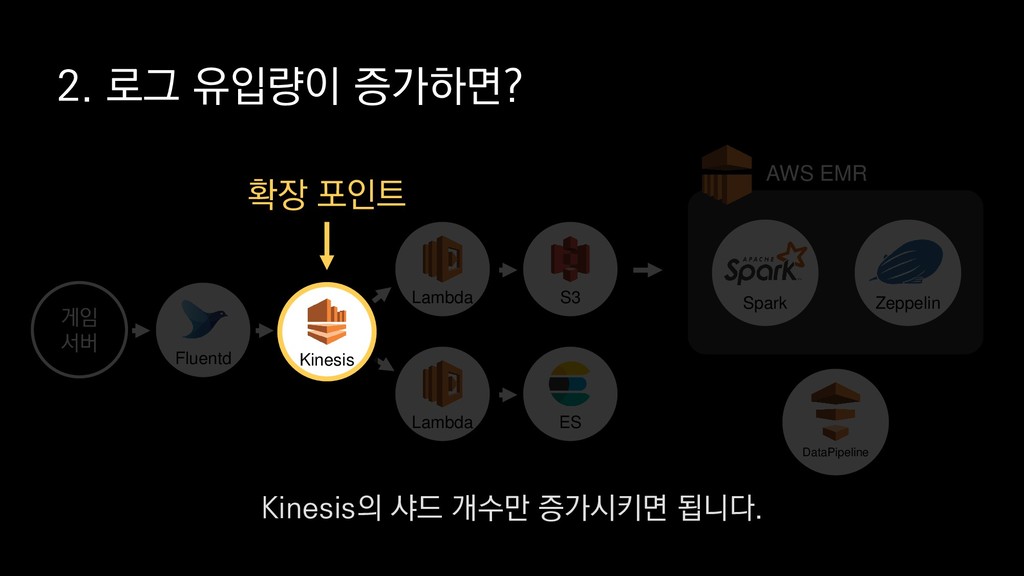{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
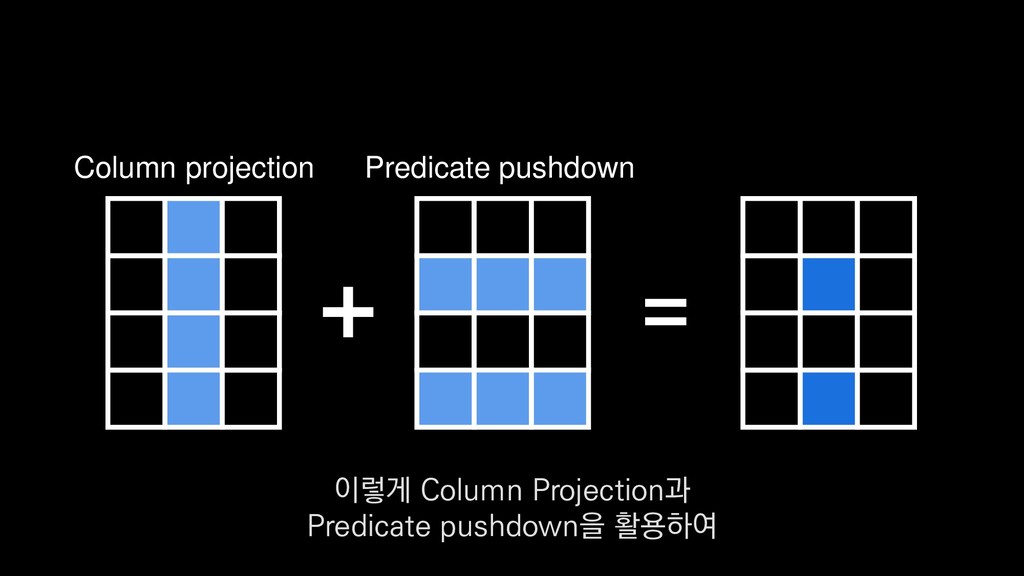
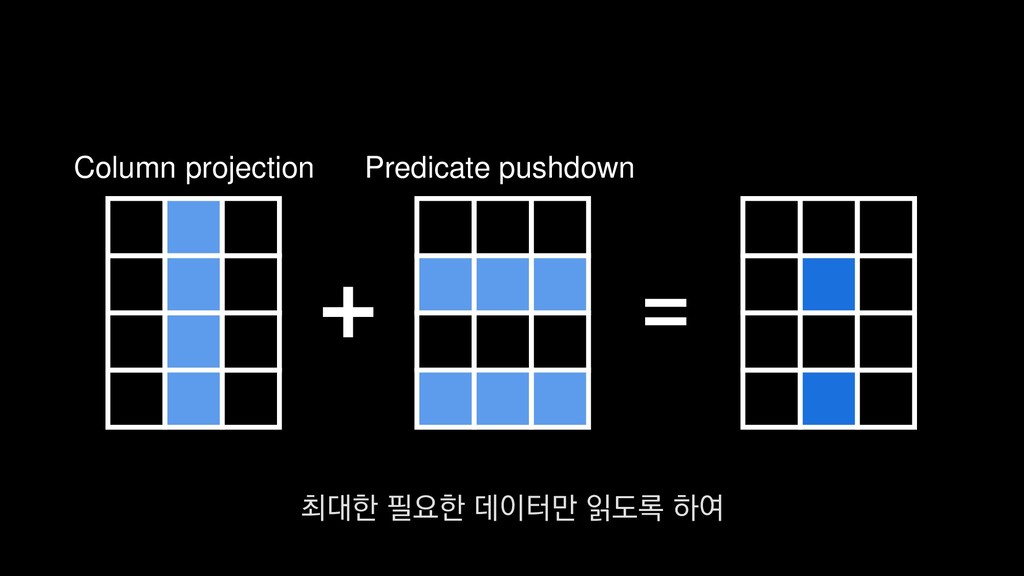
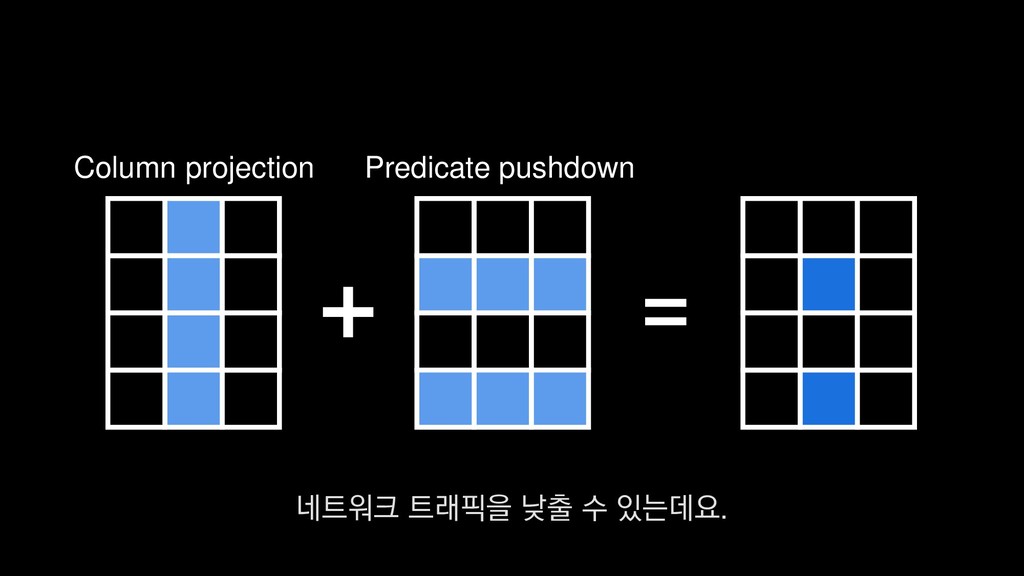
![Column projection 쿼리에 필요한 컬럼만 스캔 +- *FileScan parquet [player_entity_id#44,player_level#45,__date#53]](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_401.jpg){kind=link}
![Column projection 쿼리에 필요한 컬럼만 스캔 +- *FileScan parquet [player_entity_id#44,player_level#45,__date#53]](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_402.jpg){kind=link}
![Column projection 쿼리에 필요한 컬럼만 스캔 +- *FileScan parquet [player_entity_id#44,player_level#45,__date#53]](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_403.jpg){kind=link}
![Column projection 쿼리에 필요한 컬럼만 스캔 +- *FileScan parquet [player_entity_id#44,player_level#45,__date#53]](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_404.jpg){kind=link}
![Column projection 쿼리에 필요한 컬럼만 스캔 +- *FileScan parquet [player_entity_id#44,player_level#45,__date#53]](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_405.jpg){kind=link}
![Predicate pushdown 레벨 60인 데이터만 필터링 PushedFilteres: [IsNotNull(player_level), EqualTo(player_level,60)] 또](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_406.jpg){kind=link}
![Predicate pushdown 레벨 60인 데이터만 필터링 PushedFilteres: [IsNotNull(player_level), EqualTo(player_level,60)] 메타데이터에](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_407.jpg){kind=link}
![Predicate pushdown 레벨 60인 데이터만 필터링 PushedFilteres: [IsNotNull(player_level), EqualTo(player_level,60)] 레벨이](https://files.speakerdeck.com/presentations/e255355616684245bdcacac9baceb9c7/slide_408.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}