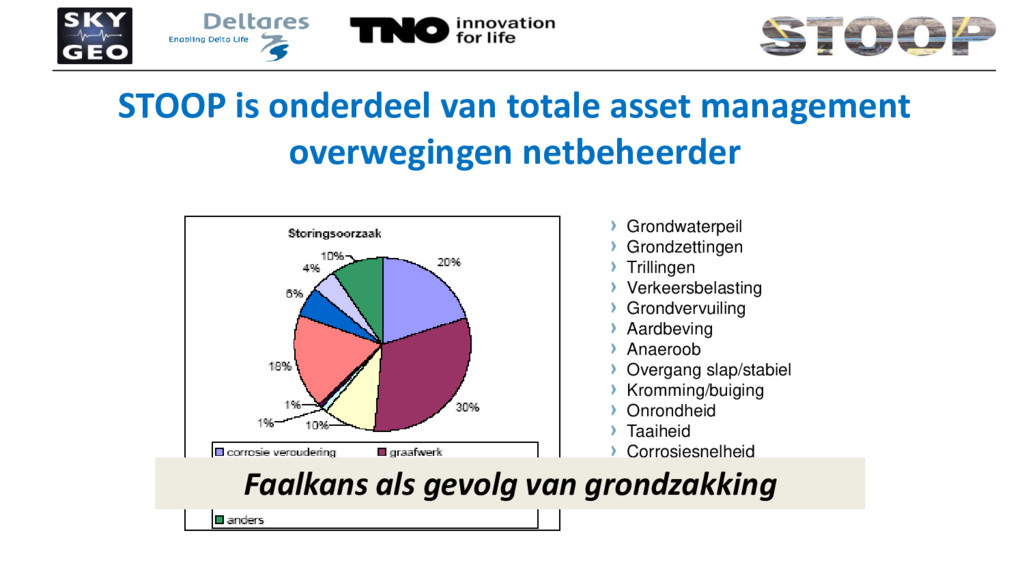
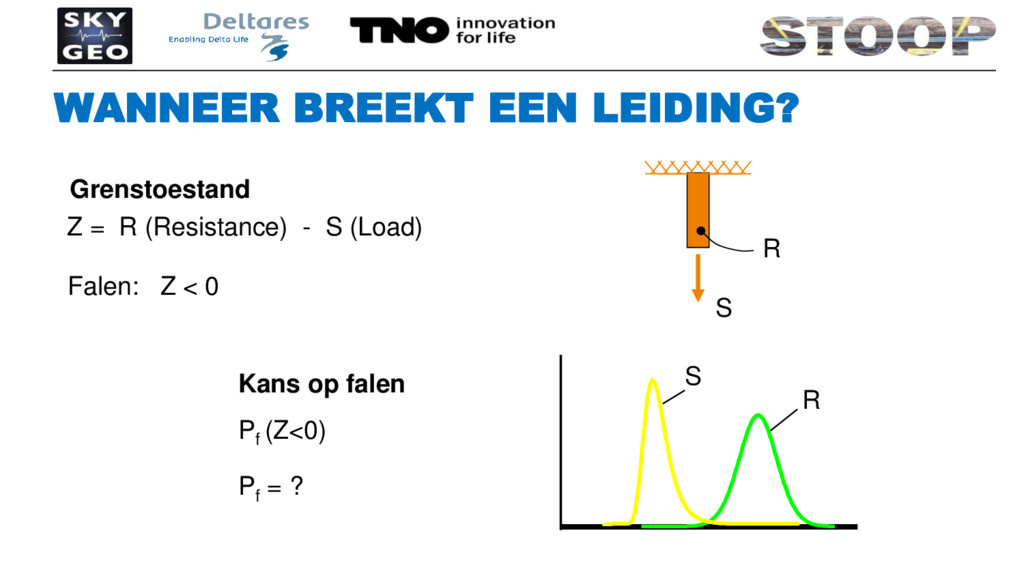
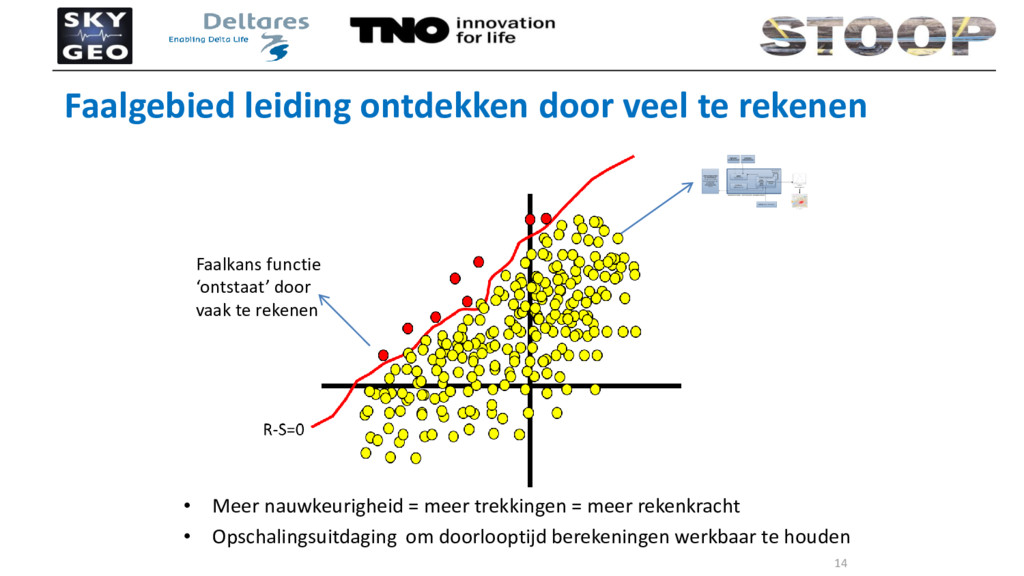
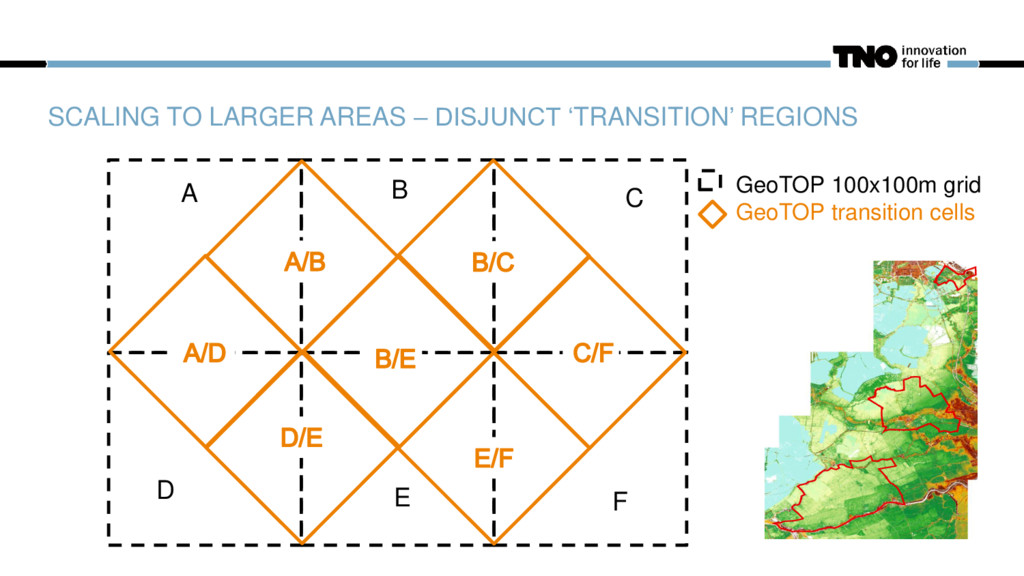
Opschalingsuitdaging om doorlooptijd berekeningen werkbaar te houden Faalgebied leiding ontdekken door veel te rekenen Faalkans functie ‘ontstaat’ door vaak te rekenen 14
Door de tijd heen: bewezen technologie, groot vertrouwen In beoogde systeem: Geheel andere inzet van de modellen Consequentie: Verscheidenheid aan platform eisen, inbreng vanuit meerdere (deel)organisaties Behouden van flexibiliteit in de te ontwikkelende workflows Beschikbare data verschilt per regio, verschillende rekenscenario’s voor meerdere doelen, doorontwikkeling systeem Geschikt voor landelijke uitrol naar de verschillende netbeheerders en waterbedrijven.
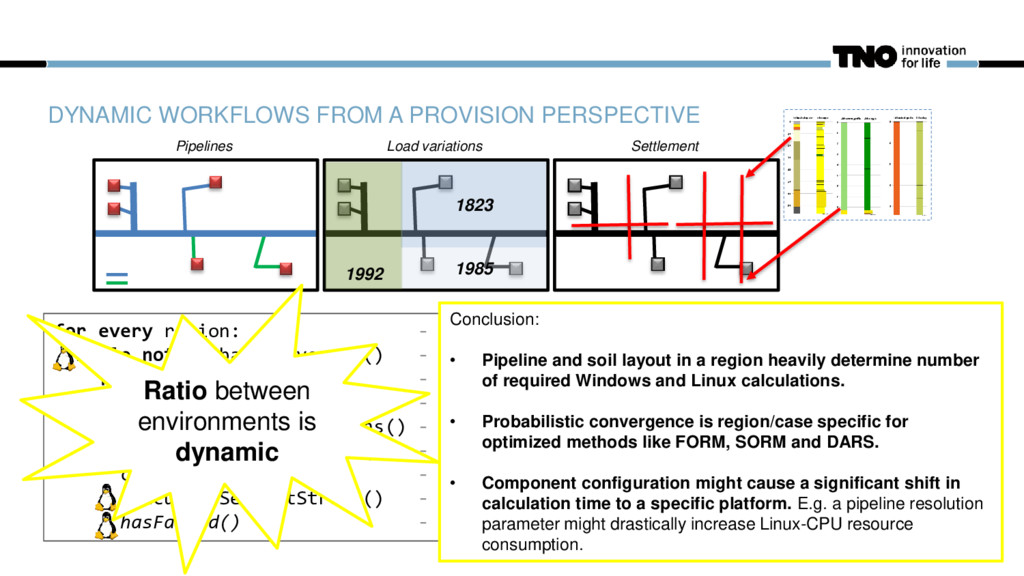
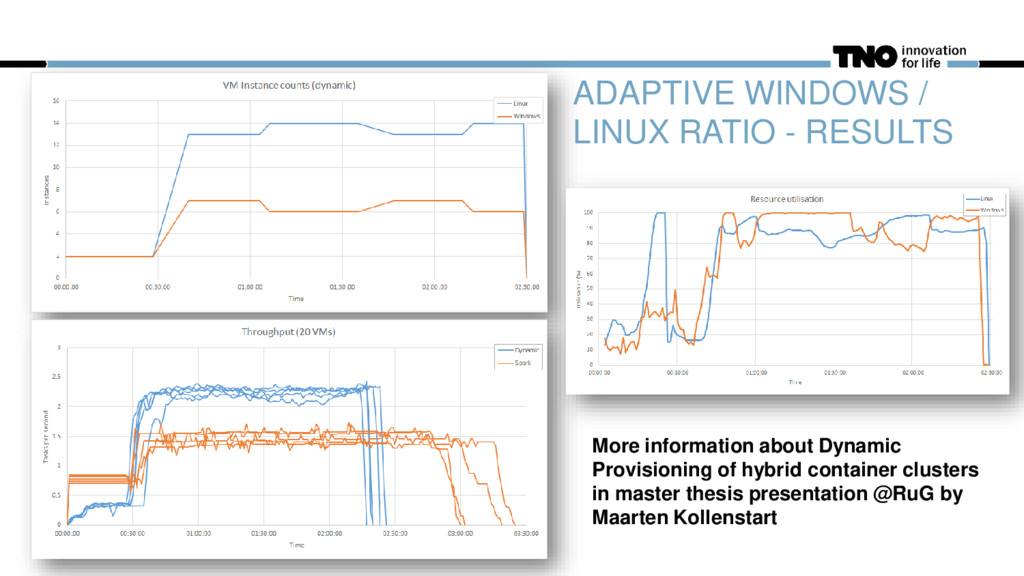
1823 1985 Settlement for every region: - selection of all regions of interest in parallel while not probab.converged() - probabilistic loop for every variation: - calculate stochastic variations in parallel constructRegionLayout() - determine local calculation scenario doSettlementCalculations() - K times doPipelineCalculations() - L times combineResults() - combine settlements and pipeline calculations calculateSegmentStress() - M times, determine pipeline stress per segment hasFailed() - update probabilistic model Ratio between environments is dynamic Conclusion: • Pipeline and soil layout in a region heavily determine number of required Windows and Linux calculations. • Probabilistic convergence is region/case specific for optimized methods like FORM, SORM and DARS. • Component configuration might cause a significant shift in calculation time to a specific platform. E.g. a pipeline resolution parameter might drastically increase Linux-CPU resource consumption.
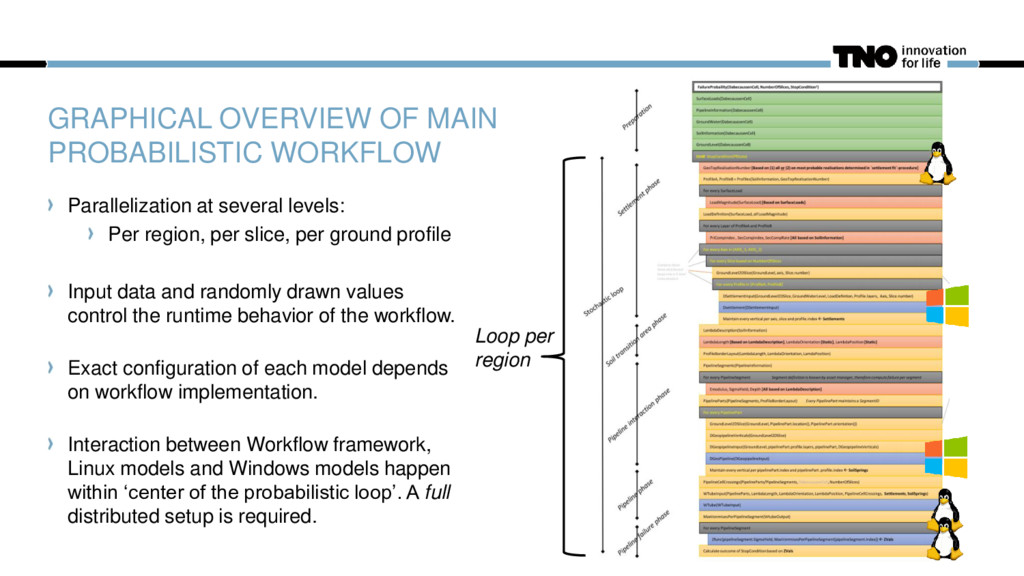
Per region, per slice, per ground profile Input data and randomly drawn values control the runtime behavior of the workflow. Exact configuration of each model depends on workflow implementation. Interaction between Workflow framework, Linux models and Windows models happen within ‘center of the probabilistic loop’. A full distributed setup is required. Loop per region
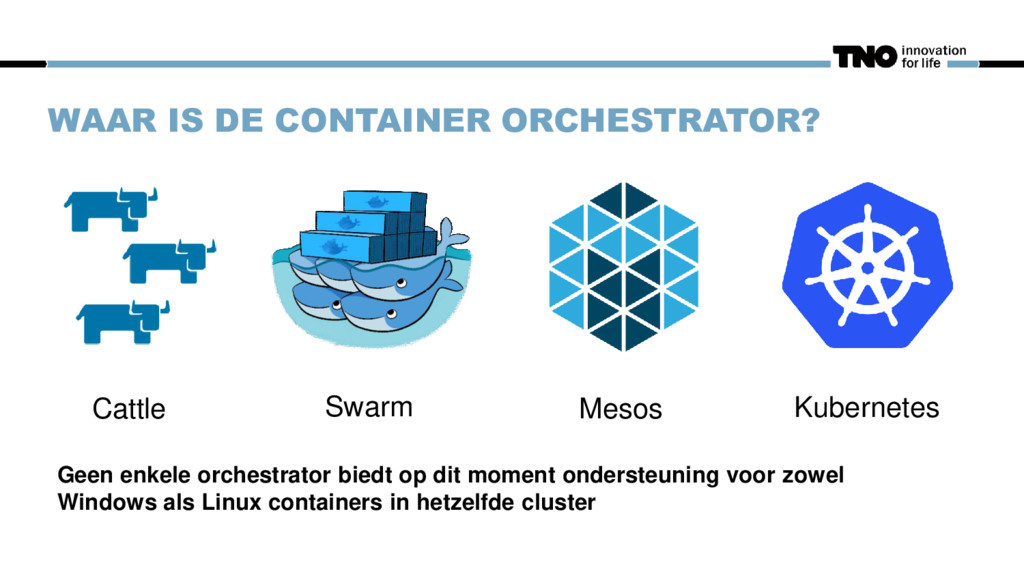
McCance ▪ Given names like frontend.xyz.org ▪ Unique, lovingly raised and cared for ▪ When they get ill, you nurse them back to health ▪ Given numbers like sparkworker-32 ▪ Almost identical to other cattle ▪ When they get ill, you get another one
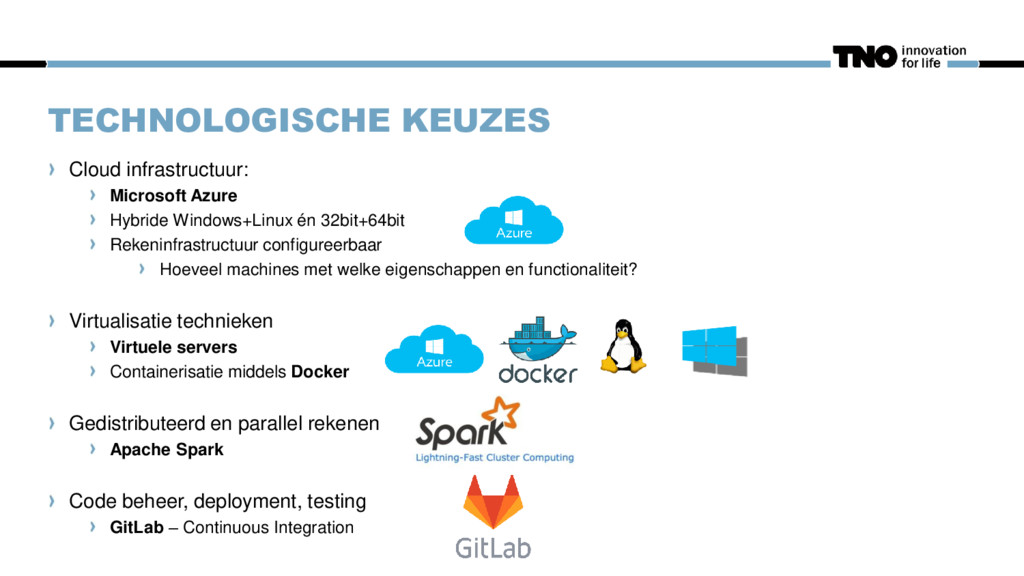
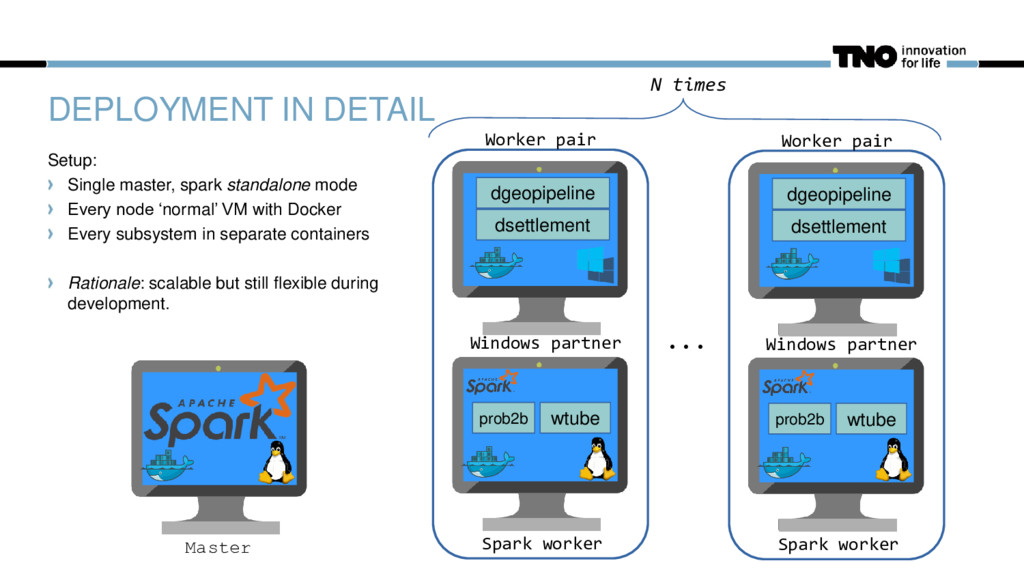
dsettlement dgeopipeline Worker pair prob2b wtube Spark worker Windows partner dsettlement dgeopipeline Worker pair ... N times Setup: Single master, spark standalone mode Every node ‘normal’ VM with Docker Every subsystem in separate containers Rationale: scalable but still flexible during development.
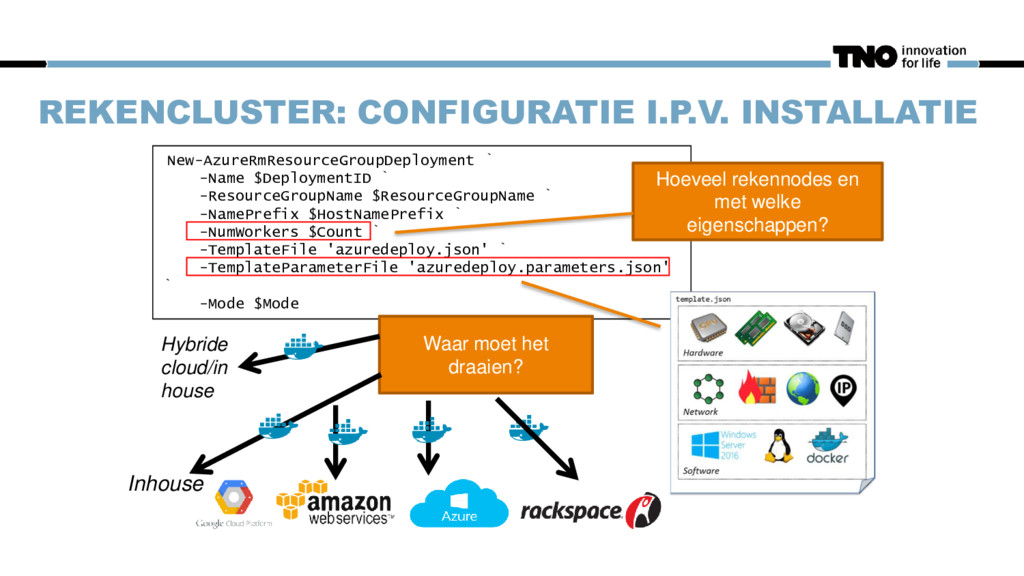
$ResourceGroupName ` -NamePrefix $HostNamePrefix ` -NumWorkers $Count ` -TemplateFile 'azuredeploy.json' ` -TemplateParameterFile 'azuredeploy.parameters.json' ` -Mode $Mode Hoeveel rekennodes en met welke eigenschappen? Waar moet het draaien? Inhouse Hybride cloud/in house
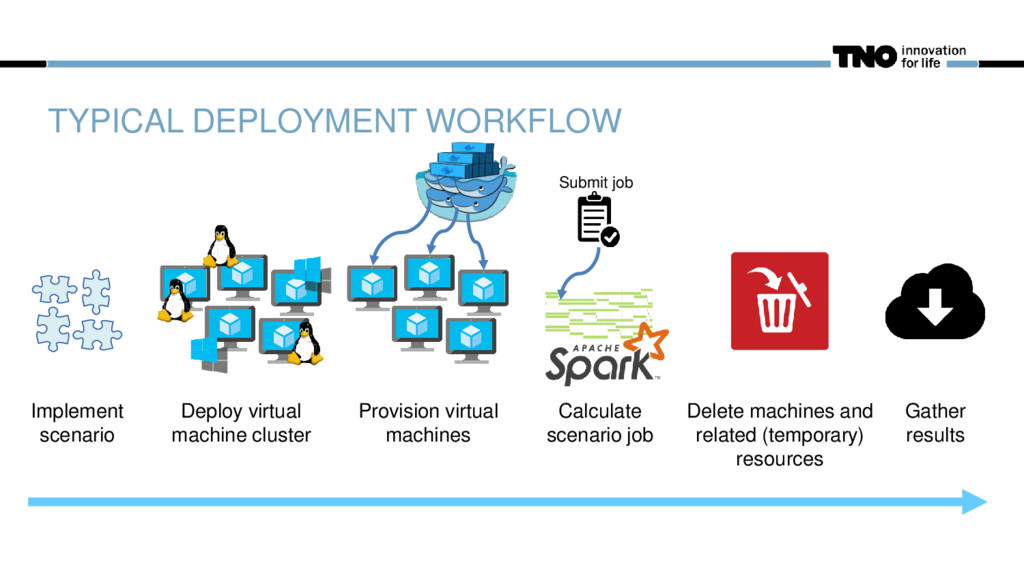
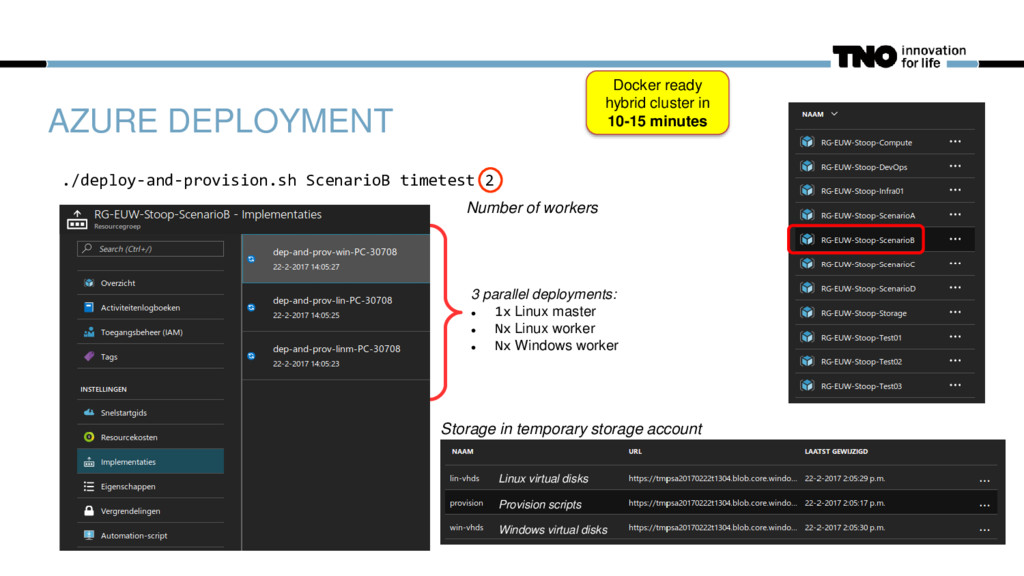
1x Linux master Nx Linux worker Nx Windows worker Number of workers Storage in temporary storage account Linux virtual disks Windows virtual disks Provision scripts Docker ready hybrid cluster in 10-15 minutes
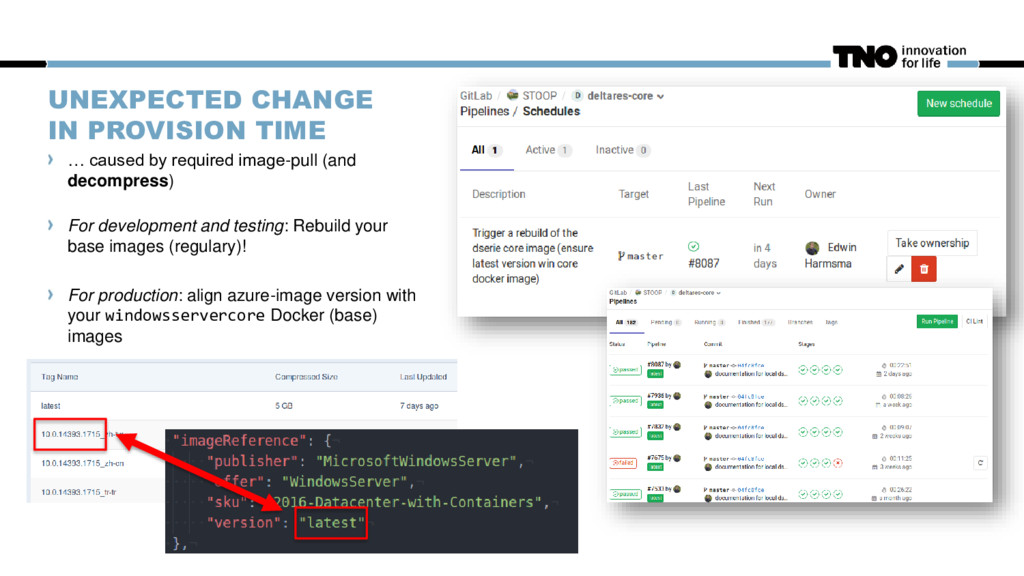
(and decompress) For development and testing: Rebuild your base images (regulary)! For production: align azure-image version with your windowsservercore Docker (base) images
‘pipe’, as distributed as a ‘normal’ Spark map-operation Workflow code is very flexible: Separation of concerns between model designer and workflow engineer Both Windows and Linux models can be used in the same distributed workflow Distributed operations
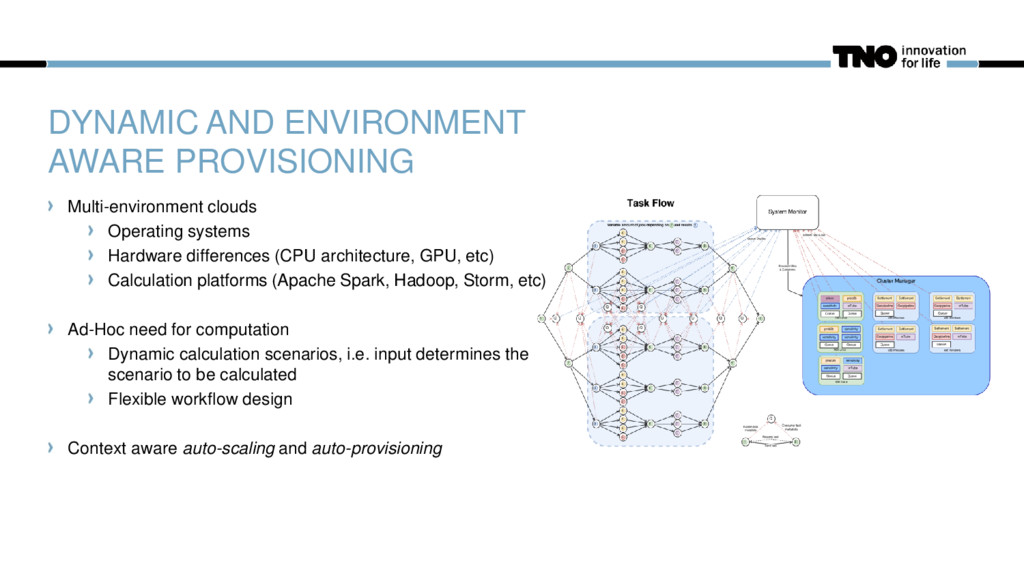
differences (CPU architecture, GPU, etc) Calculation platforms (Apache Spark, Hadoop, Storm, etc) Ad-Hoc need for computation Dynamic calculation scenarios, i.e. input determines the scenario to be calculated Flexible workflow design Context aware auto-scaling and auto-provisioning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}