Митап на тему "Мониторинг", 16-05-2018
Николай Сивко, Okmeter.io
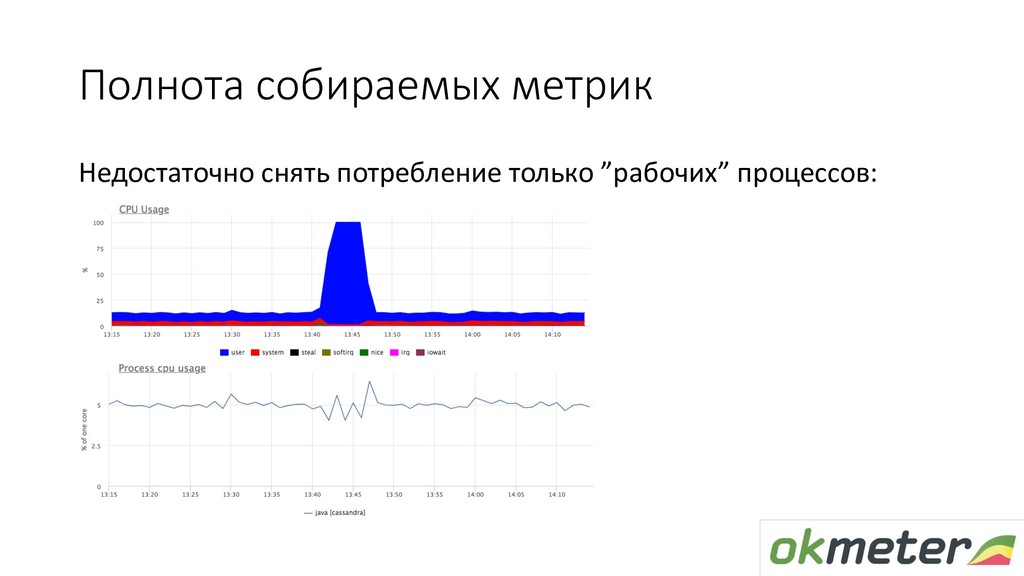
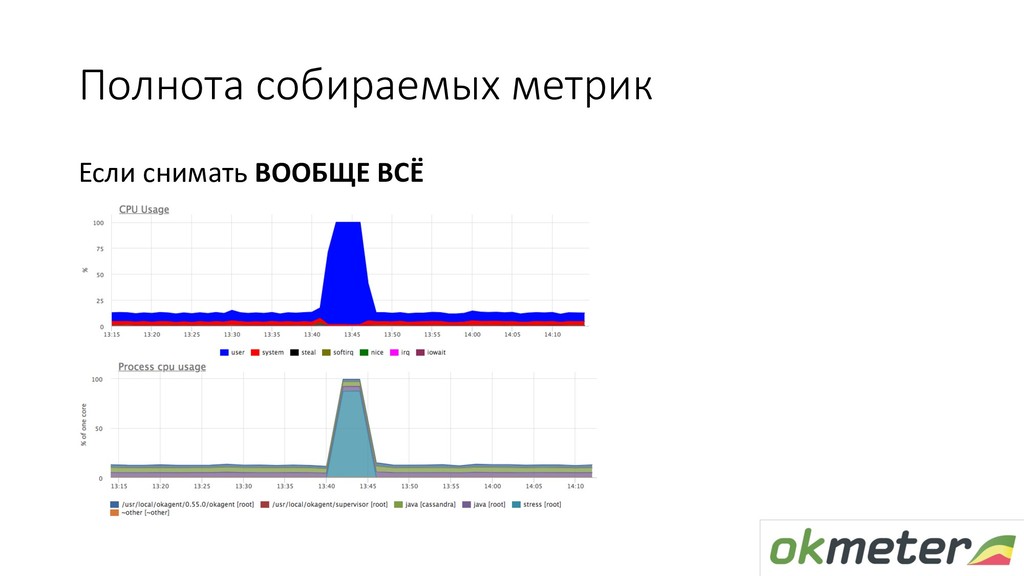
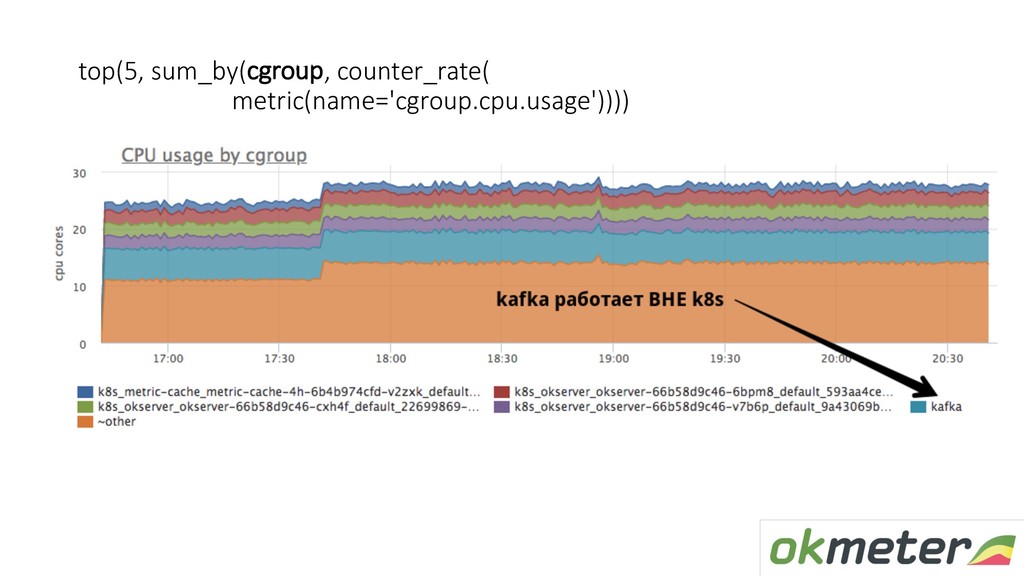
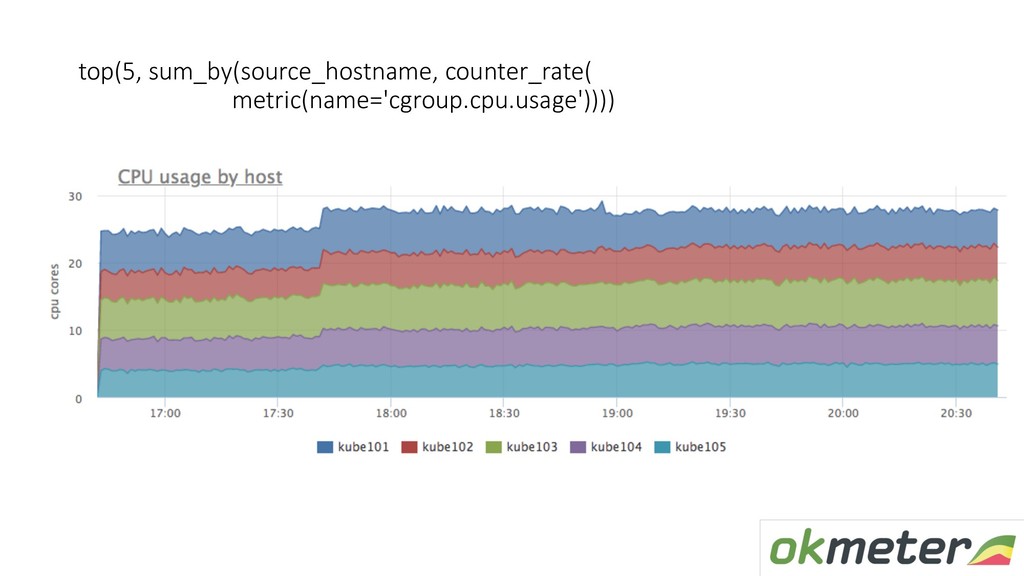
Поговорим о наполнении мониторинга — метриках. Расскажу, как обычно настраивается сбор метрик в системах мониторинга и на какие грабли можно при этом наступить. Также расскажу о нашем подходе к автоматическому сбору метрик: как это работает, какие именно метрики мы снимаем и что потом с ними делаем.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
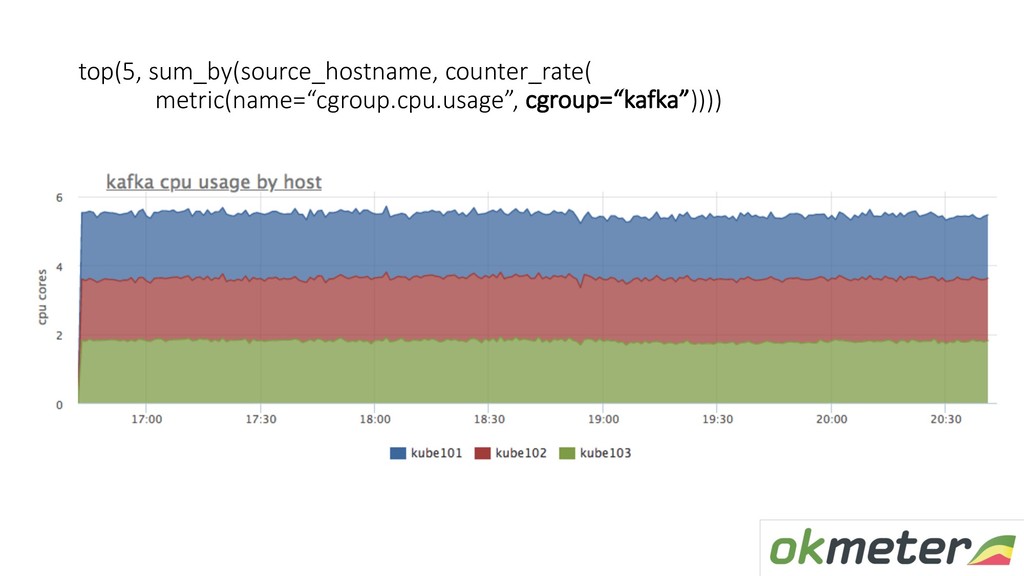{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![sum_by(source_hostname, metric(name="netstat.connections.inbound.count", listen_port="443", listen_ip=[...]))](https://files.speakerdeck.com/presentations/b6be977a34cd47f2ac4906e9b708691c/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание! Вопросы? Николай Сивко [email protected]](https://files.speakerdeck.com/presentations/b6be977a34cd47f2ac4906e9b708691c/slide_41.jpg){kind=link}