Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Pythonで始める正規表現入門
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
NobuakiOshiro
PRO
September 18, 2019
Technology
700
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Pythonで始める正規表現入門
NobuakiOshiro
PRO
September 18, 2019
More Decks by NobuakiOshiro
See All by NobuakiOshiro
20260610_中東情勢_物流資源ショック_統合分析19枚_v3
doradora09
PRO
0
1
20260604_福岡女子大_講義後小レポート分析スライド_NOBDATA
doradora09
PRO
0
20
20260601_中東情勢1週間差分update
doradora09
PRO
0
33
20260602_中東情勢と物流_3か月振り返り_10枚圧縮版_最新版
doradora09
PRO
0
40
伊藤さん_発表スライド_全業種x各国_20260602
doradora09
PRO
1
34
20260528_生成AIを専属DSに_Howの次にすべきことを考える
doradora09
PRO
0
290
20260527_準悲観シナリオ_v2_価格高騰見込み
doradora09
PRO
0
59
20260527_ホルムズ制約長期化シナリオ(準悲観シナリオ)
doradora09
PRO
0
60
20260527_先週差分_今後調査予定_サマリ
doradora09
PRO
0
52
Other Decks in Technology
See All in Technology
新規ゲーム開発におけるAI駆動開発のリアル
202409e2
0
2.5k
Claude Code×Terraform IaC テンプレート駆動開発
itouhi
1
290
Terraformモジュールは、なぜ「魔境」化するのか
hayama17
1
190
Oracle AI Database@Azure:サービス概要のご紹介
oracle4engineer
PRO
6
1.9k
AI Testing Talks: Challenges of Applying AI in Software Testing: From Hype to Practical Use
exactpro
PRO
1
130
SIer20年! 培ったスキルがスタートアップで輝く時
shucho0103
0
370
美味しいスイスチーズを作ろう🧀🐭
taigamikami
1
240
ブロックチェーン / Blockchain
ks91
PRO
0
110
OCI Oracle AI Database Services新機能アップデート(2026/03-2026/05)
oracle4engineer
PRO
0
220
先取りMaven4 ~16年ぶりのメジャーアップデート、その進化とは?~
ogiwarat
0
140
noUncheckedIndexedAccess、3時間、1万円。 / noUncheckedIndexedAccess, 3 Hours, 10,000 JPY.
kaonavi
1
300
Agentic ERPをどう設計するか ー 受発注エージェントを動かす、現場の知見と設計思想ー
recerqainc
1
1.5k
Featured
See All Featured
Code Reviewing Like a Champion
maltzj
528
40k
Designing for Timeless Needs
cassininazir
1
250
We Are The Robots
honzajavorek
0
240
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
190
Ruling the World: When Life Gets Gamed
codingconduct
0
250
So, you think you're a good person
axbom
PRO
2
2.1k
Marketing to machines
jonoalderson
1
5.4k
Are puppies a ranking factor?
jonoalderson
1
3.5k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
66k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
190
Documentation Writing (for coders)
carmenintech
77
5.4k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
160
Transcript
LT Pythonで始める 正規表現⼊⾨ PyData.Fukuoka #05 2019/09/18 @doradora09
⾃⼰紹介 • NOB DATA株式会社 代表取締役 • ⼤城 信晃 (@doradora09) •
データサイエンティスト • 沖縄 -> 東京 -> 福岡(3年⽬) • ヤフー -> DATUM STUDIO -> LINE Fukuoka -> NOB DATA(株) 設⽴ • DS協会九州⽀部 発起⼈ • コミュニティ運営 • Tokyo.R, fukuoka.R, 意思決定のための データ分析勉強会, PyData.Fukuoka、等 https://nobdata.co.jp/ 2
None
[余談1] • KDD2019の論⽂読み会があります!@LINE東京(抽選式) https://connpass.com/event/146880/
[余談2] PyConJP 2019のコミュニティ会
[余談2] PyConJP 2019のコミュニティ会
[余談2] PyConJP 2019のコミュニティ会
[余談3] https://pyconjp.connpass.com/
[RP] DS協会九州⽀部設⽴ & 第2回セミナー(9/20) 設⽴記念パーティーの模様 (ご来賓として⾼島市⻑、 記念講演としてTRE社の古賀社⻑)
[RP] DS協会九州⽀部設⽴ & 第2回セミナー(9/20) https://techplay.jp/event/749275
本題
モチベーション • たまにWebクロール & スクレイピン グのハンズオンなどをやっているが その後のデータ加⼯で皆苦戦してい る節がある • 「正規表現」という便利なものがあ
るよ、という紹介
Rバージョンの資料もあります • 資料の⼿抜き再利⽤ • 正規表現の記法を覚えれば、 RでもPythonでも他の⾔語 でもテキスト処理に⼤活躍 https://speakerdeck.com/doradora09/rdes hi-meruzheng-gui-biao-xian-ru-men
こういうケースとか • Xpathで住所データをスクレイピングしたものの、 前後に改⾏とスペースが⼤量にある、など str_replace_all(pattern = "[\n ]+", replacement =
'') => 改⾏と半⾓スペースを除去し、データを綺麗に。
正規表現とは • 正規表現(せいきひょうげん、英: regular expression)とは、 ⽂字列の集合を⼀つの⽂字列で表現する⽅法の⼀つである。正 則表現(せいそくひょうげん)とも呼ばれ、形式⾔語理論の分 野では⽐較的こちらの訳語の⽅が使われる。まれに正規式と呼 ばれることもある。(wikipediaより) •
正規表現の起源の⼀つとして、数学者のスティーヴン・クリー ネは1950年代に正規集合と呼ばれる独⾃の数学的表記法を⽤い、 これらの分野のモデルを記述した。 • (その後Unix系のツールへ広がり今に⾄る)
正規表現のメリット • テキスト処理で本領を発揮。スクレイピングにも使える • XML(HTML含む)の構造が崩れているデータにも適⽤出来る • さらに他の⾔語でも使えるので汎⽤的 • ed、 grep、expr、awk、Emacs、vi、lex、Perl、PHP、Python等
• windowsやmacで動くテキストエディタにも実装されてるものも。 ※注 • いくつか⽅⾔はあるので注意。共通して使えるものを覚えておくと吉。 • 基本正規表現、拡張正規表現、Perl⾵正規表現など
正規表現で出来ること(⼀例) プログラムのif⽂や専⽤関数を使わずに以下のようなことが可能 1. 区切り⽂字変更(タブ -> カンマ) 2. HTMLタグの除去(簡易版) 3. 都道府県の抽出(簡易版)
4. 郵便番号の抽出(7桁) 5. URL解体(簡易版) 6. Emailアドレス形式チェック(⼀致するか否か) その他にも、⽂字列のルールに基づくマッチングや置換全般
Pythonで正規表現使うならreモジュール • (恐らく)頭⽂字からre • 正規表現(せいきひょうげん、英: regular expression) • import reで使える
• 解説 • このモジュールは Perl に⾒られる正規表現マッチング操作と同様のものを提供しま す。 • 正規表現では、特殊な形式を表すためや、特殊⽂字をその特殊な意味を発動させず 使うために、バックスラッシュ⽂字 ('\') を使います。 • 'r' を前置した⽂字列リテラル内ではバックスラッシュが特別扱いされません。従っ て "\n" が改⾏⼀⽂字からなる⽂字列であるのに対して、 r"\n" は '\' と 'n' の⼆⽂字 からなる⽂字列です。通常、 Python コード中では、パターンをこの raw ⽂字列記 法を使って表現します。 https://docs.python.org/ja/3/library/re.html
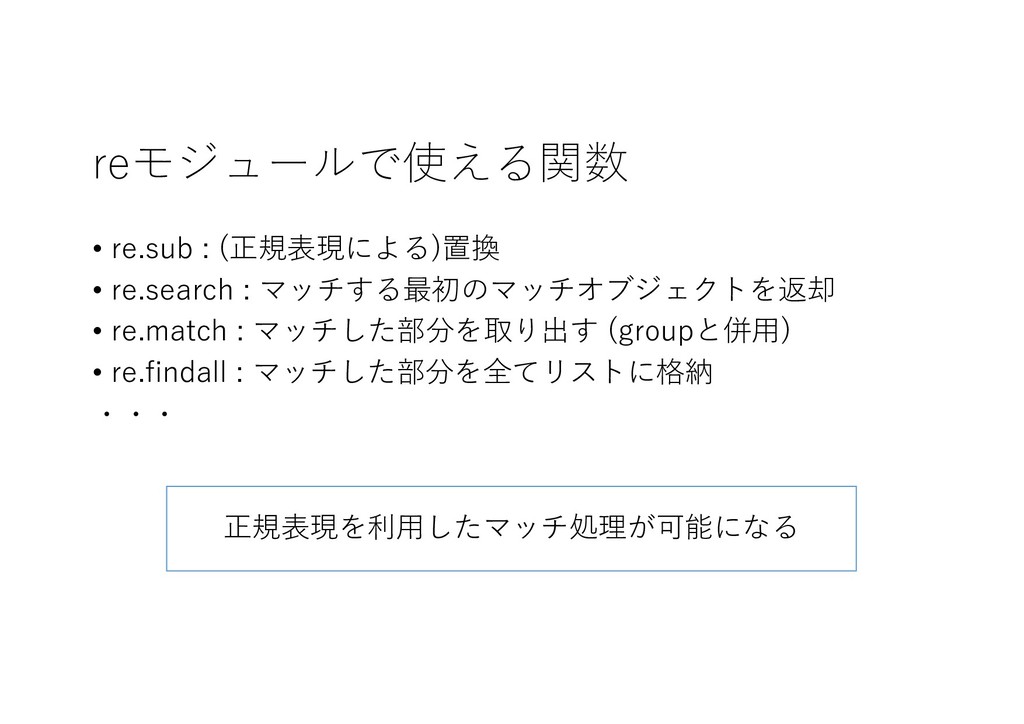
reモジュールで使える関数 • re.sub : (正規表現による)置換 • re.search : マッチする最初のマッチオブジェクトを返却 •
re.match : マッチした部分を取り出す (groupと併⽤) • re.findall : マッチした部分を全てリストに格納 ・・・ 正規表現を利⽤したマッチ処理が可能になる
ご参考 : raw⽂字表記法のありなし #通常の表記 >>> print("aaa\nbbb\nccc") aaa bbb ccc #正規表現の改⾏として扱われる
(エスケープシーケンス, 特殊⽂ 字とも) #raw⽂字の表記 >>> print(r"aaa\nbbb\nccc") aaa\nbbb\nccc #単なる⽂字列の\として扱われ る 特殊⽂字が含まれる⽂字列へのパターンマッチを⾏う 場合はraw⽂字表記の⽅がシンプルに書けるかも(後述)
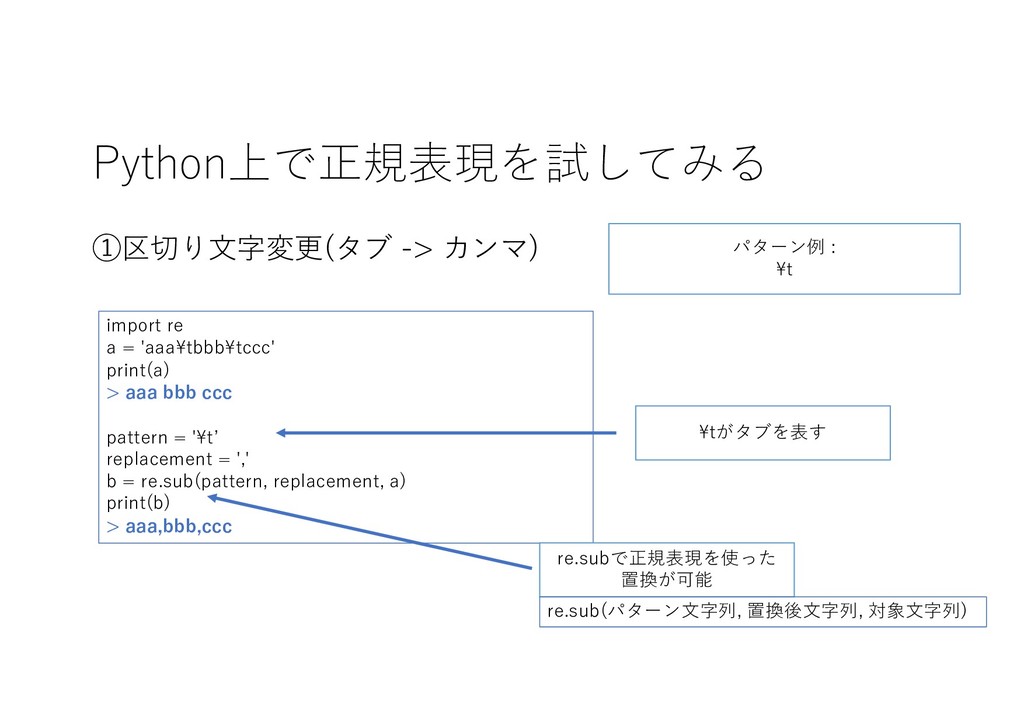
Python上で正規表現を試してみる ①区切り⽂字変更(タブ -> カンマ) \tがタブを表す パターン例 : \t import re
a = 'aaa\tbbb\tccc' print(a) > aaa bbb ccc pattern = '\tʼ replacement = ',' b = re.sub(pattern, replacement, a) print(b) > aaa,bbb,ccc re.subで正規表現を使った 置換が可能 re.sub(パターン⽂字列, 置換後⽂字列, 対象⽂字列)
ご参考 : 正規表現で定義されているもの(抜粋) https://murashun.jp/blog/20190215-01.html
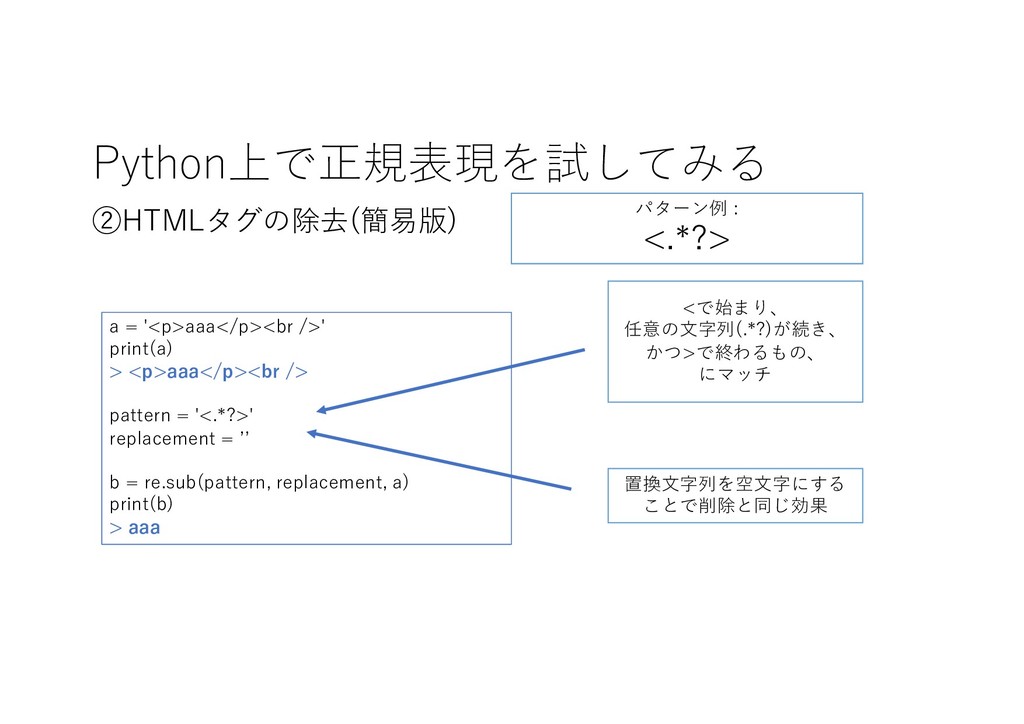
Python上で正規表現を試してみる ②HTMLタグの除去(簡易版) <で始まり、 任意の⽂字列(.*?)が続き、 かつ>で終わるもの、 にマッチ 置換⽂字列を空⽂字にする ことで削除と同じ効果 パターン例 :
<.*?> a = '<p>aaa</p><br />' print(a) > <p>aaa</p><br /> pattern = '<.*?>' replacement = ʼʼ b = re.sub(pattern, replacement, a) print(b) > aaa
ご参考 : ⽂字列系のメタ⽂字(抜粋) https://murashun.jp/blog/20190215-01.html
Python上で正規表現を試してみる ③都道府県の抽出(簡易版) スペース以外の⽂字([^ ])が、 2⽂字から3⽂字続き{2,3}?、 かつ都道府県のいずれかが続く パターンにマッチ ※[]の中の^は否定を表す。 ⾏頭を⽰す^とは別の意味な ので注意
パターン例 : ([^ ]{2,3}?[都道府県]) a = '〒810-0801 福岡県博多区中洲 3 丁⽬ 7-24' print(a) > 〒810-0801 福岡県博多区中洲 3 丁⽬ 7-24 pattern = '([^ ]{2,3}?[都道府県])' b = re.search(pattern, a) print(b[0]) > 福岡県 先頭にマッチした部分を格納する関数 re.serarch(パターン⽂字列、対象⽂字列) ※複数のマッチした部分を取りたい場合は re.findall関数を使う
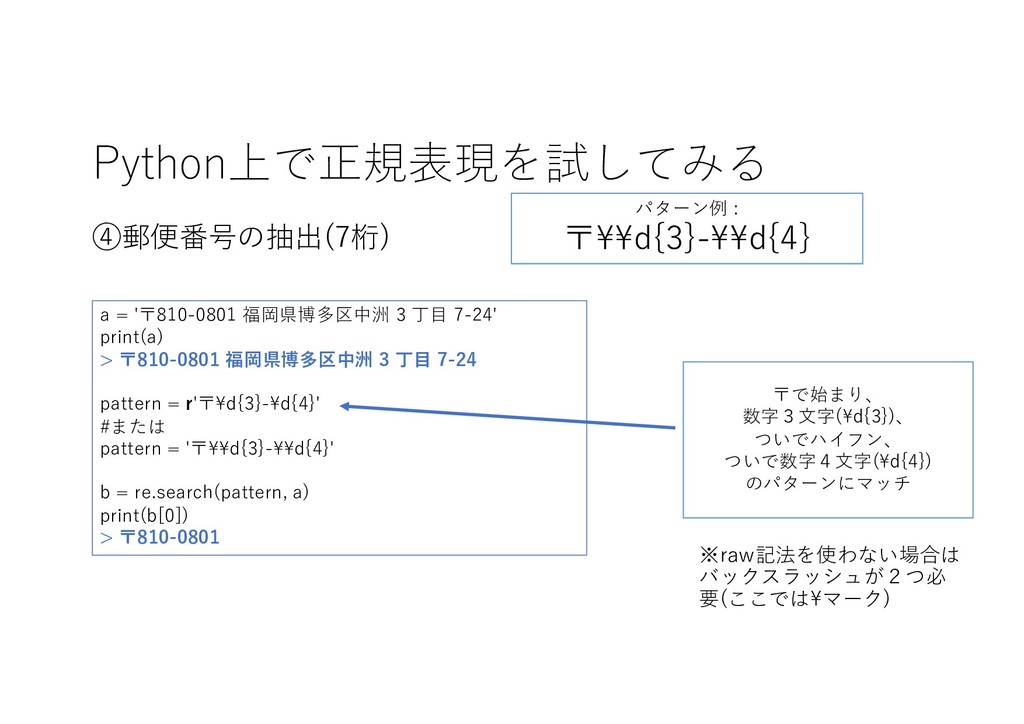
Python上で正規表現を試してみる ④郵便番号の抽出(7桁) 〒で始まり、 数字3⽂字(\d{3})、 ついでハイフン、 ついで数字4⽂字(\d{4}) のパターンにマッチ ※raw記法を使わない場合は バックスラッシュが2つ必 要(ここでは\マーク)
パターン例 : 〒\\d{3}-\\d{4} a = '〒810-0801 福岡県博多区中洲 3 丁⽬ 7-24' print(a) > 〒810-0801 福岡県博多区中洲 3 丁⽬ 7-24 pattern = r'〒\d{3}-\d{4}' #または pattern = '〒\\d{3}-\\d{4}' b = re.search(pattern, a) print(b[0]) > 〒810-0801
ご参考 : 繰り返しや否定のメタ⽂字 https://murashun.jp/blog/20190215-01.html
Python上で正規表現を試してみる ⑤URL解体(簡易版) ()でそれぞれグループ化したもの が分割されて後から取り出せる (後⽅参照) パターン例 : ^(.+?)://(.+?):?(\\d+)?(/.*)?$ a =
'http://example.com:80/test/index.php' print(a) > http://example.com:80/test/index.php pattern = r'^(.+?)://(.+?):?(\d+)?(/.*)?$' b = re.search(pattern, a) print(b.group(0)) > http://example.com:80/test/index.php print(b.group(1)) > http print(b.group(2)) > example.com print(b.group(3)) > 80 groupを使う。 0は全体、1から順に ()でマッチ した部分が取り出せる
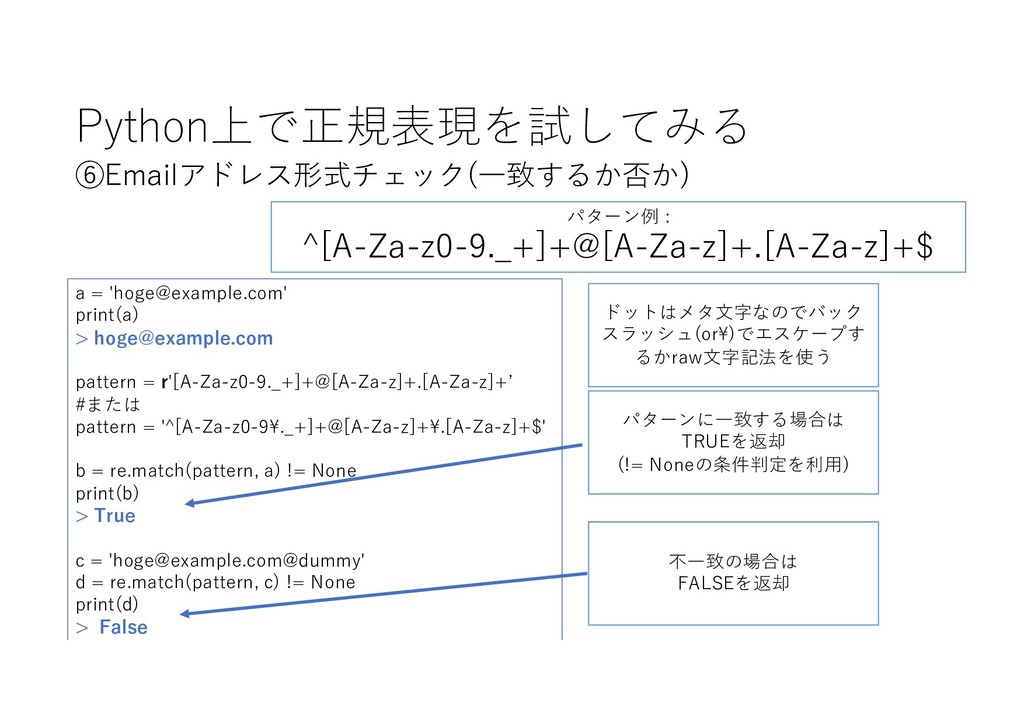
Python上で正規表現を試してみる ⑥Emailアドレス形式チェック(⼀致するか否か) パターンに⼀致する場合は TRUEを返却 (!= Noneの条件判定を利⽤) 不⼀致の場合は FALSEを返却 パターン例 :
^[A-Za-z0-9._+]+@[A-Za-z]+.[A-Za-z]+$ a = '
[email protected]
' print(a) >
[email protected]
pattern = r'[A-Za-z0-9._+]+@[A-Za-z]+.[A-Za-z]+ʼ #または pattern = '^[A-Za-z0-9\._+]+@[A-Za-z]+\.[A-Za-z]+$' b = re.match(pattern, a) != None print(b) > True c = '
[email protected]
@dummy' d = re.match(pattern, c) != None print(d) > False ドットはメタ⽂字なのでバック スラッシュ(or\)でエスケープす るかraw⽂字記法を使う
ご参考 : 連続した⽂字の省略記法(抜粋) https://murashun.jp/blog/20190215-01.html
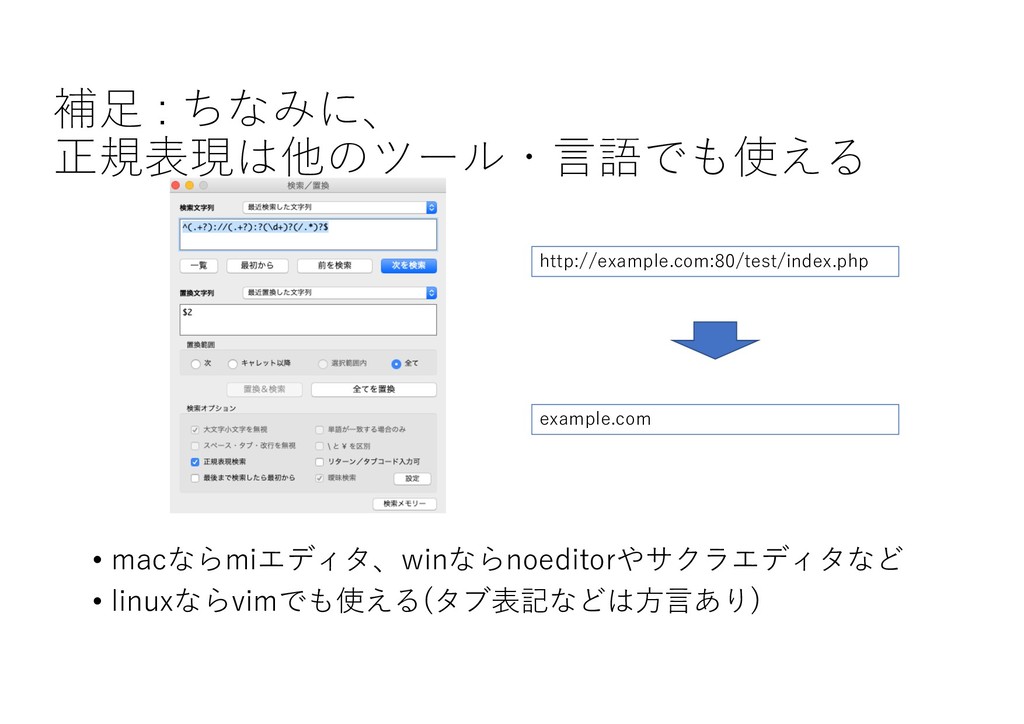
補⾜ : ちなみに、 正規表現は他のツール・⾔語でも使える • macならmiエディタ、winならnoeditorやサクラエディタなど • linuxならvimでも使える(タブ表記などは⽅⾔あり) http://example.com:80/test/index.php example.com
まとめ • テキスト処理を⾏うなら正規表現が便利 • Pythonで使うならreモジュール • 他のエディタや⾔語でも使えるので拡張正規表現あたりは覚え ておくと役に⽴つかも
Enjoy !
{kind=link}
{kind=link}
{kind=link}
![[余談1] • KDD2019の論⽂読み会があります!@LINE東京(抽選式) https://connpass.com/event/146880/](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_3.jpg){kind=link}
![[余談2] PyConJP 2019のコミュニティ会](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_4.jpg){kind=link}
![[余談2] PyConJP 2019のコミュニティ会](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_5.jpg){kind=link}
![[余談2] PyConJP 2019のコミュニティ会](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_6.jpg){kind=link}
![[余談3] https://pyconjp.connpass.com/](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_7.jpg){kind=link}
![[RP] DS協会九州⽀部設⽴ & 第2回セミナー(9/20) 設⽴記念パーティーの模様 (ご来賓として⾼島市⻑、 記念講演としてTRE社の古賀社⻑)](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_8.jpg){kind=link}
![[RP] DS協会九州⽀部設⽴ & 第2回セミナー(9/20) https://techplay.jp/event/749275](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![こういうケースとか • Xpathで住所データをスクレイピングしたものの、 前後に改⾏とスペースが⼤量にある、など str_replace_all(pattern = "[\n ]+", replacement =](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Python上で正規表現を試してみる ③都道府県の抽出(簡易版) スペース以外の⽂字([^ ])が、 2⽂字から3⽂字続き{2,3}?、 かつ都道府県のいずれかが続く パターンにマッチ ※[]の中の^は否定を表す。 ⾏頭を⽰す^とは別の意味な ので注意](https://files.speakerdeck.com/presentations/2573e989bb7546819ecadf7433d64748/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}