Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Generative Adversarial Text to Image Synthesis@...
Search
Dwango Media Village
July 21, 2016
Research
420
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Generative Adversarial Text to Image Synthesis@ICML2016読み会
ICML2016読み会の資料です。
Dwango Media Village
July 21, 2016
More Decks by Dwango Media Village
See All by Dwango Media Village
Siggraph Asia 2018 論文紹介(Two-stage Sketch Colorization)
dwangomediavillage
1
1.1k
[DL輪読会] Efficient Neural Audio Synthesis
dwangomediavillage
0
390
タグ情報とコメント密度を用いた画像サムネイル推薦システム
dwangomediavillage
0
1k
SIGGRAPH Asia 2017 論文とか紹介
dwangomediavillage
0
300
CVPR2017読み会
dwangomediavillage
1
180
Blending Texture Features from Multiple Reference Images for Style Transfer - SIGGRAPH ASIA 2016 Technical Brief
dwangomediavillage
1
2k
Other Decks in Research
See All in Research
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
230
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
140
事後確率分布の共分散について
koide3
0
170
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
660
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
430
羽田新ルート運用6年の検証
1manken
0
170
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.4k
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
620
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
470
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
200
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
Featured
See All Featured
We Are The Robots
honzajavorek
0
270
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
890
Designing Powerful Visuals for Engaging Learning
tmiket
1
440
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
The Curious Case for Waylosing
cassininazir
1
430
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
300
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Amusing Abliteration
ianozsvald
1
220
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Google's AI Overviews - The New Search
badams
0
1.1k
Transcript
Genera&ve Adversarial Text to Image Synthesis Reed, S., Akata, Z.,
Yan, X., Logeswaran, L., Schiele, B., & Lee, H. (2016). ICML2016読み会 廣芝 和之 1
自己紹介 • 廣芝和之 • ドワンゴ新卒 • 大阪大学:大澤研究室 – ネコの脳の視覚野を研究 •
奈良先端大学院:塩坂研究室 – マウスの脳の海馬を研究 @hiho_karuta 2
紹介する論文 Genera&ve Adversarial Text to Image Synthesis Reed, S., Akata,
Z., Yan, X., Logeswaran, L., Schiele, B., & Lee, H. (2016). GANのアーキテクチャを応用して 文章から画像を生成するアーキテクチャを考案した 3
背景:文章から画像生成する過去手法 • 文章から、鮮明な画像を生成す ることは難しい • GANは鮮明な画像を生成できる • GANを応用して文章からより鮮 明な画像を生成する 4
Elman Mansimov et al., ICLR 2016.
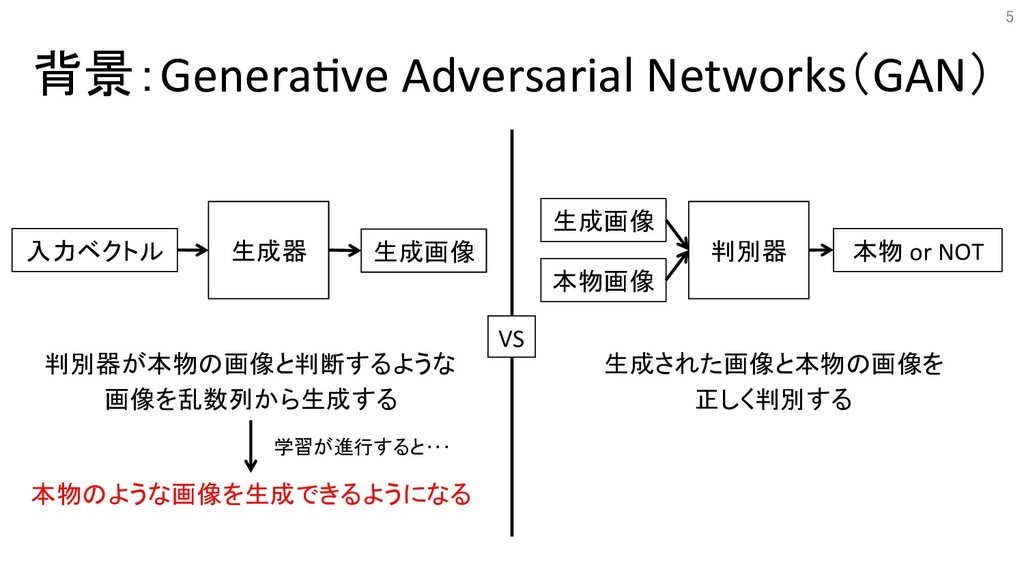
背景:Genera&ve Adversarial Networks(GAN) 判別器が本物の画像と判断するような 画像を乱数列から生成する 生成された画像と本物の画像を 正しく判別する 本物のような画像を生成できるようになる 学習が進行すると・・・ 判別器
生成画像 本物画像 本物 or NOT 5 入力ベクトル 生成器 生成画像 VS
背景:GANを用いた画像生成例 使用例(顔イラスト画像) @maTya1089, 2015 使用例(寝室) Alec Radford et al., 2015 入力する入力ベクトルを変えれば 生成される画像が変わる
6 入力ベクトル 生成器 生成画像
紹介する論文の貢献 • 文章から鮮明な画像を生成する手法を提案 • 文章以外の情報の表現を吸収する手法を提案 • 性能を向上する手法を2種類提案 • 文章以外の情報を転写する手法を提案 7
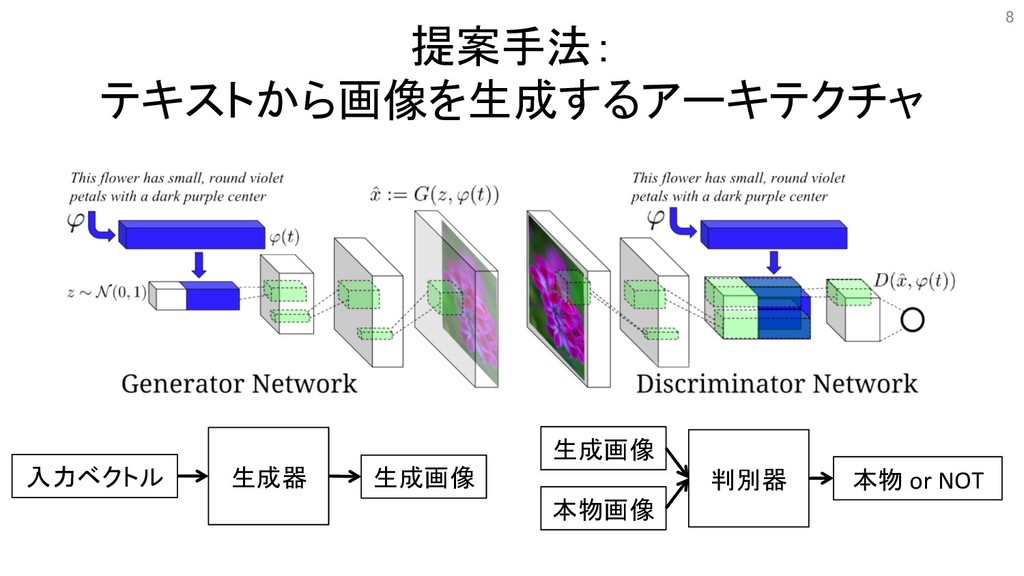
提案手法: テキストから画像を生成するアーキテクチャ 8 入力ベクトル 生成器 生成画像 判別器 生成画像 本物画像 本物
or NOT
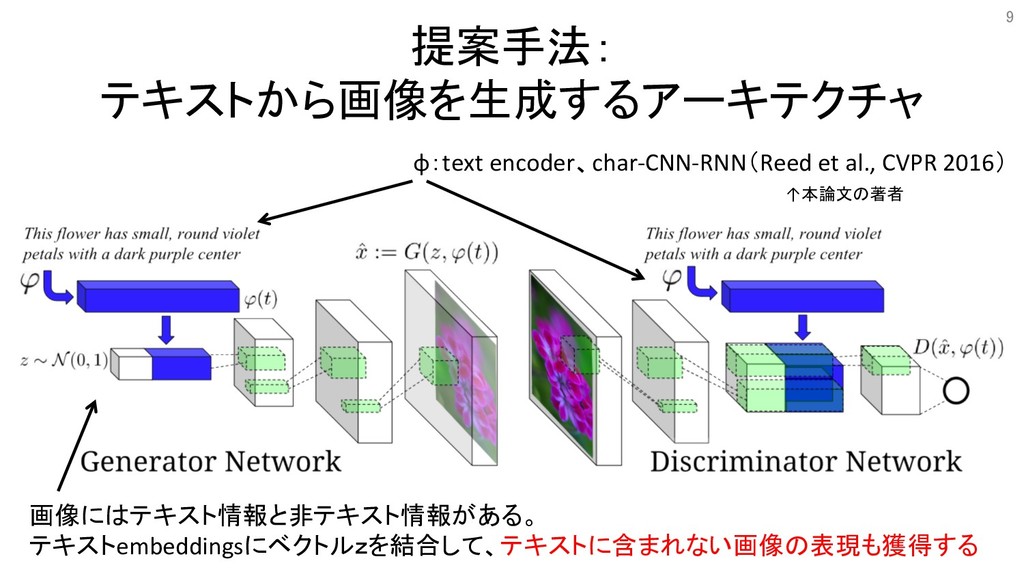
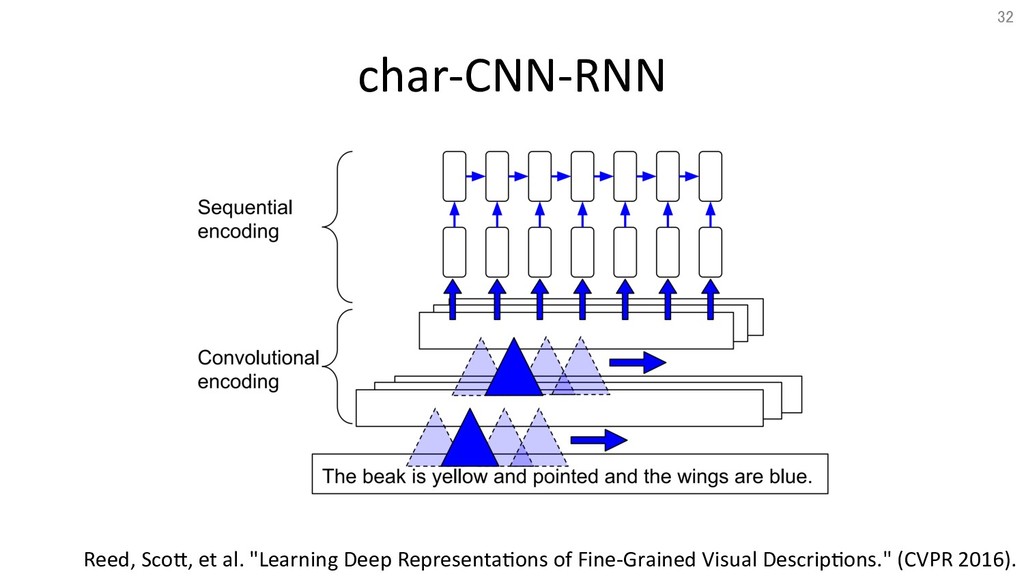
提案手法: テキストから画像を生成するアーキテクチャ φ:text encoder、char-CNN-RNN(Reed et al., CVPR 2016) ↑本論文の著者 画像にはテキスト情報と非テキスト情報がある。
テキストembeddingsにベクトルzを結合して、テキストに含まれない画像の表現も獲得する 9
課題:文章に無関係な画像が生成される? • 従来のGANの判別器 画像が本物か生成されたものか判別する – D(本物画像) → ◦ – D(生成画像) → × – 生成器は本物に近い画像を生成するように学習する
• 今回のGANに従来の判別器を用いた場合・・・ – 文章の情報を用いない – 生成器は文章内容に関係のない画像を生成するように学習する 10
提案手法:マッチング判別器 • マッチング判別器を提案 画像とテキストの組み合わせが正しいかを判別する – D(本物画像、正しい文章) → ◦ – D(生成画像、正しい文章) → × – D(本物画像、間違った文章) → ×
– 生成器は文章にマッチする画像の生成を学習する 11
課題:入力データセット数を増やしたい • (課題というよりも、試してみた?) • 既存のデータセットから 新しいデータセットを作ることはできるか 12
提案手法:補間データも学習に使用 • embeddingsの補間データの表象はデータ多様体に近い傾向 がある(Bengio et al., 2013; Reed et al.,
2014) • 訓練テキストデータembeddingsの補間データも訓練に利用 – Gの目的関数を下式に変更 Gに入力する テキストembedding (β=0.5で十分な成果) テキストembedding 13
実験手法 • テキストと画像のデータセットを用いて提案した ネットワークをトレーニング • テキストを入力して画像を生成する • 2種類の学習テクニックを組み合わせて性能を比較 – マッチング判別器
– 補間データ使用 14
実験:パラメータなど • 画像:64×64×3次元 • テキストエンコーダ – char-CNN-RNN:出力は1024次元 – 全結合+Leaky ReLU、出力は128次元
• ノイズz:100次元 • normal deconvolu&onal network • stride-2 convolu&on+バッチ正規化 15
実験:画像とテキストのデータセット • CUB – 200種類のカテゴリ – 11788の鳥画像 • Oxford-102 –
102のカテゴリ – 8189の花画像 各画像に対して5つの説明テキスト (著者らが付けた?) this bird has wings that are black and has a yellow crown 013.Bobolink 16
実験:学習テクニックの効果の比較 提案手法 マッチング判別器 補間データ使用 マッチング判別器 補間データ使用 入力テキスト: an all black
bird with a dis&nct thick, rounded bill (真っ黒で太くて丸いくちばしを持つ鳥) 考察 • 上2つは色の情報は正しかったが 画像がリアルではない • 補間データを用いると テキストに合う もっともらしい画像が得られた 17
実験:テキストembeddingを補間して画像生成 • 2つのテキストから 2つのembeddingを得る • テキストembedding(右図青)の 補間を入力して画像を生成する • なめらかに画像が変化した •
つまりテキストembeddingは連続 した空間に埋め込まれている 18
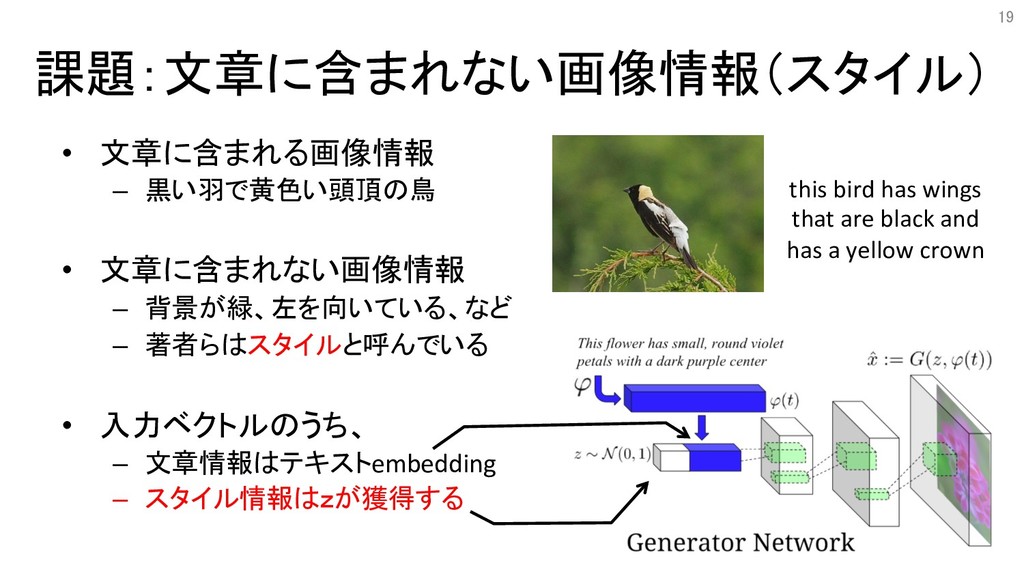
課題:文章に含まれない画像情報(スタイル) • 文章に含まれる画像情報 – 黒い羽で黄色い頭頂の鳥 • 文章に含まれない画像情報 – 背景が緑、左を向いている、など –
著者らはスタイルと呼んでいる • 入力ベクトルのうち、 – 文章情報はテキストembedding – スタイル情報はzが獲得する this bird has wings that are black and has a yellow crown 19
課題:スタイルは転写可能か この画像の スタイル (背景が青色) 「白い腹で頭は赤の鳥」 + 20 生 成 器 「白い腹で頭は赤の鳥」
(背景が青色)
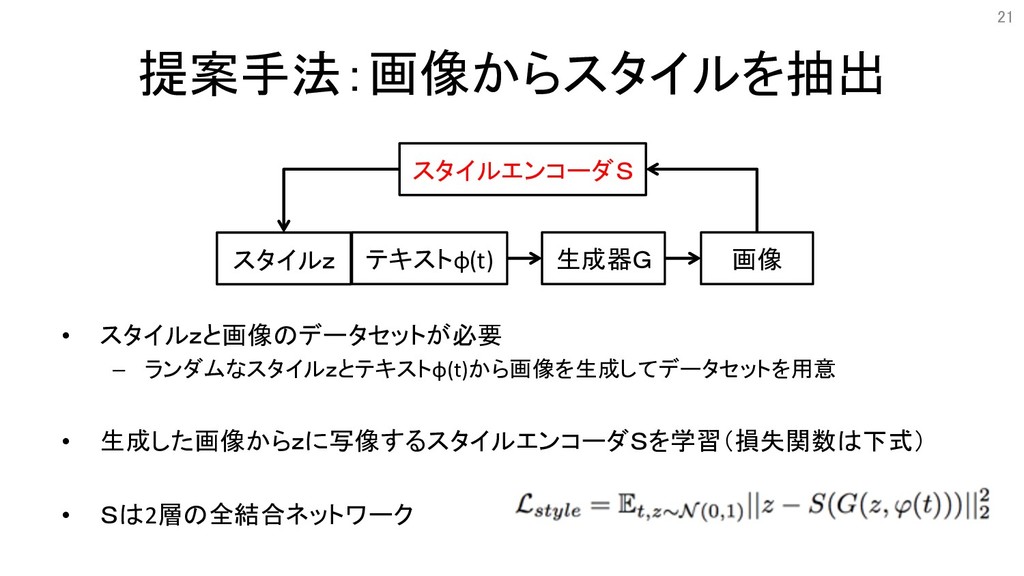
提案手法:画像からスタイルを抽出 • スタイルzと画像のデータセットが必要 – ランダムなスタイルzとテキストφ(t)から画像を生成してデータセットを用意 • 生成した画像からzに写像するスタイルエンコーダSを学習(損失関数は下式) • Sは2層の全結合ネットワーク スタイルz
テキストφ(t) 画像 生成器G スタイルエンコーダS 21
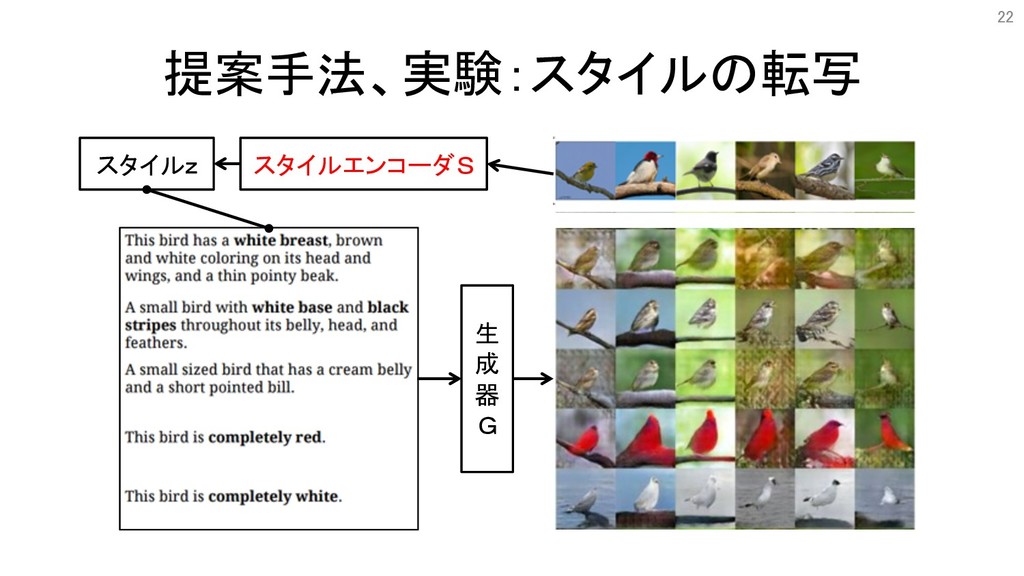
提案手法、実験:スタイルの転写 スタイルエンコーダS スタイルz 生 成 器 G 22
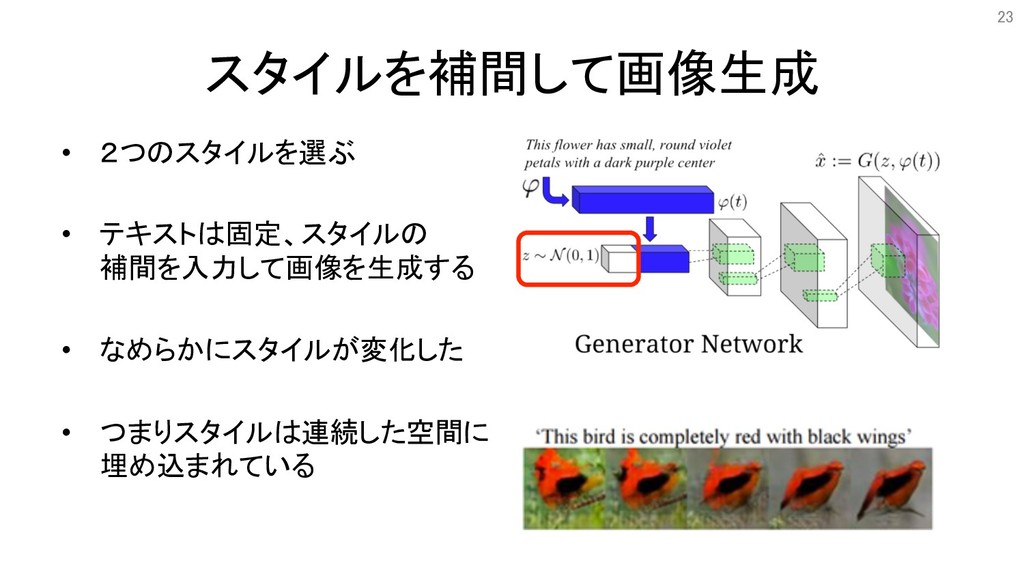
スタイルを補間して画像生成 • 2つのスタイルを選ぶ • テキストは固定、スタイルの 補間を入力して画像を生成する • なめらかにスタイルが変化した • つまりスタイルは連続した空間に
埋め込まれている 23
触ってみた • 著者らの実装がGithubにある – hTps://github.com/reedscot/icml2016 – 言語:Lua – 機械学習フレームワーク:Torch –
トレーニング済みネットワークが配布されている 24
データセットにないテキストを入力した時 • 目的 – 生成される画像が構造を持つのか確認したい • 方法、結果 – テキスト:the completely
red cat • 考察 – 猫は鳥だった? – 猫は知らない単語として、似たテキストの学習時の画像を参考に出力された? 25
実際にいない鳥を入力した時 • 目的 – 論文の入力テキストは該当する鳥がデータセットにある – 実在する鳥のパーツを組み合わせることはできるか確認したい • 方法、結果 –
テキスト:the blue bird with green wings • 考察 – パーツを組み合わせる能力は無い? 26 green wings
発表のまとめ • GANのアーキテクチャから発展させ、 文章から画像を生成するアーキテクチャを考案した – 性能を向上する手法も2種類提案 • 補間テキストembedingsも用いると性能が向上 – 文章以外の情報(スタイル)を転写する手法も提案
• 追試を行った – パーツごとに指定すると想定した画像は生成されなかった 27
CUBでの画像生成例 28 提案手法 マッチング判別器 補間データ使用 マッチング判別器 補間データ使用
Oxfordでの画像生成例 29 提案手法 マッチング判別器 補間データ使用 マッチング判別器 補間データ使用
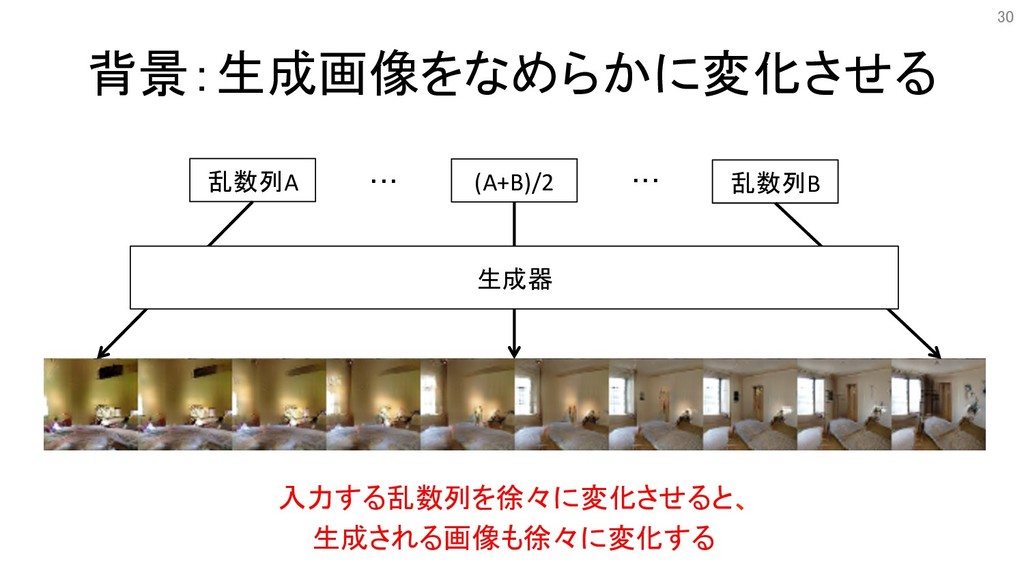
背景:生成画像をなめらかに変化させる 乱数列A 乱数列B (A+B)/2 ・・・ ・・・ 生成器 入力する乱数列を徐々に変化させると、 生成される画像も徐々に変化する 30
テキストエンコード this bird has wings that are black and has
a yellow crown 013.Bobolink N : データセットの組数 y : ラベル v : 画像 t : テキスト Δ : 損失関数 f : 分類関数 φ : 画像エンコーダ : テキストエンコーダ T(y) : yのテキスト V(y) : yの画像 Reed, ScoT, et al. "Learning Deep Representa&ons of Fine-Grained Visual Descrip&ons. " (CVPR 2016). 31
char-CNN-RNN Reed, ScoT, et al. "Learning Deep Representa&ons of Fine-Grained
Visual Descrip&ons." (CVPR 2016). 32
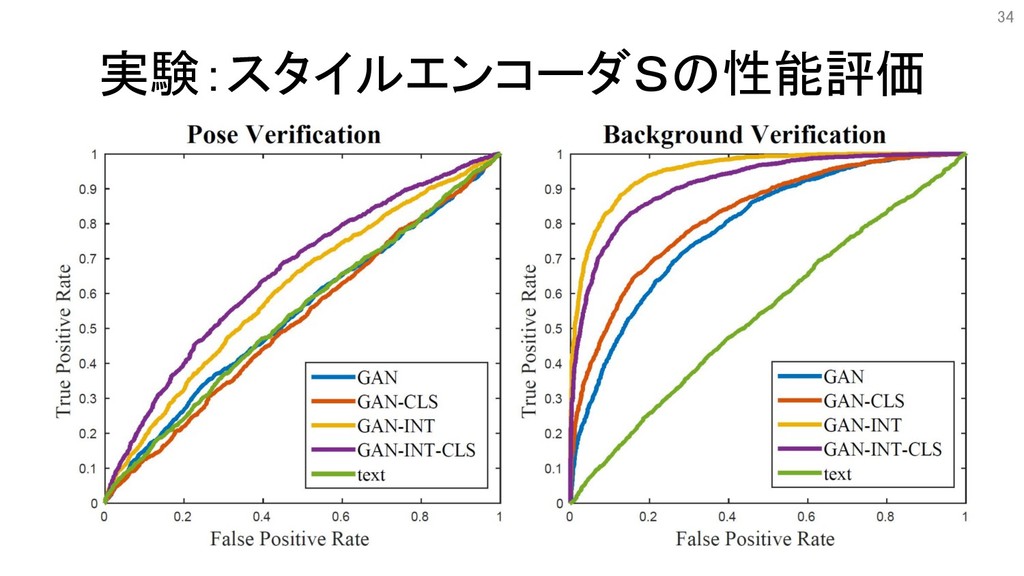
実験:スタイルエンコーダSの性能評価 • 目的:スタイルエンコーダSで抽出したスタイルが筆者らの想定したスタイル(背 景など)と相関があるか調べたい • 全画像N枚の背景画素値を求める – 画像内のピクセル値の平均RGB • 求めた背景画素値でk-meansを用いて全画像を100クラスに分類
• 全画像N枚からスタイルエンコーダを用いてスタイルzを抽出 • 各画像のスタイルのコサイン類似度を計算 • ROC曲線を描いて評価 33
実験:スタイルエンコーダSの性能評価 34
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}