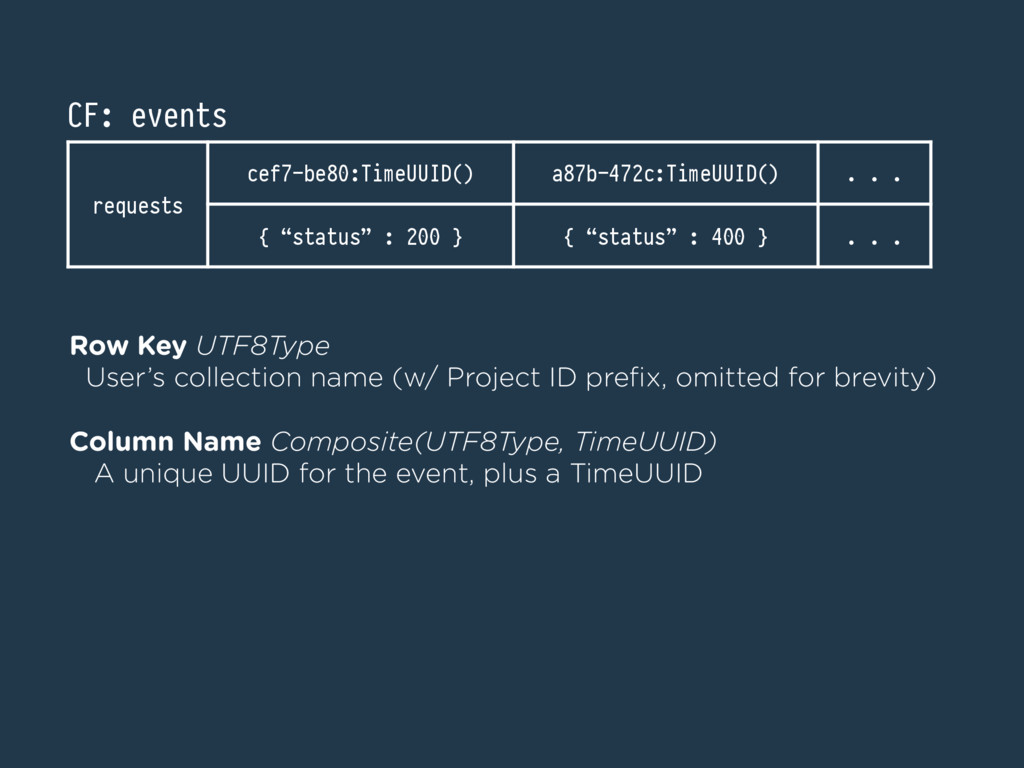
Keen IO stores events in the same format that our customers send them in—JSON. Yet, Keen uses Cassandra, a distributed database without any JSON primitives, and Keen gives customers the ability to query over arbitrary (even nested) JSON dimensions. How can this be???
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ requests-0 cef7-be80:TimeUUID() a87b-472c:TimeUUID() . .](https://files.speakerdeck.com/presentations/c9387460f5bb0131c1fa560254398127/slide_19.jpg){kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ • No more unbounded row](https://files.speakerdeck.com/presentations/c9387460f5bb0131c1fa560254398127/slide_20.jpg){kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ • No more unbounded row](https://files.speakerdeck.com/presentations/c9387460f5bb0131c1fa560254398127/slide_21.jpg){kind=link}
![• Turned ‘requests’ into ‘requests-[0…n]’ • No more unbounded row](https://files.speakerdeck.com/presentations/c9387460f5bb0131c1fa560254398127/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![requests-0 timestamp response.status url [“2014-07-21…”, “2014-07-21…”] [200, 400] [“keen.io”, “keen.io”]](https://files.speakerdeck.com/presentations/c9387460f5bb0131c1fa560254398127/slide_40.jpg){kind=link}
![requests-0 timestamp response.status url [“2014-07-21…”, “2014-07-21…”] [200, 400] [“keen.io”, “keen.io”]](https://files.speakerdeck.com/presentations/c9387460f5bb0131c1fa560254398127/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}