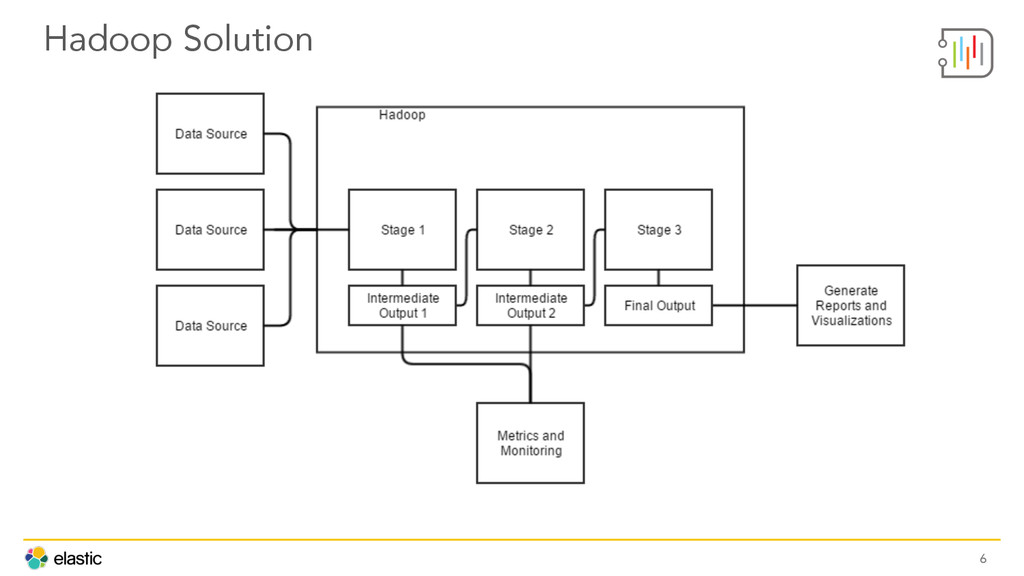
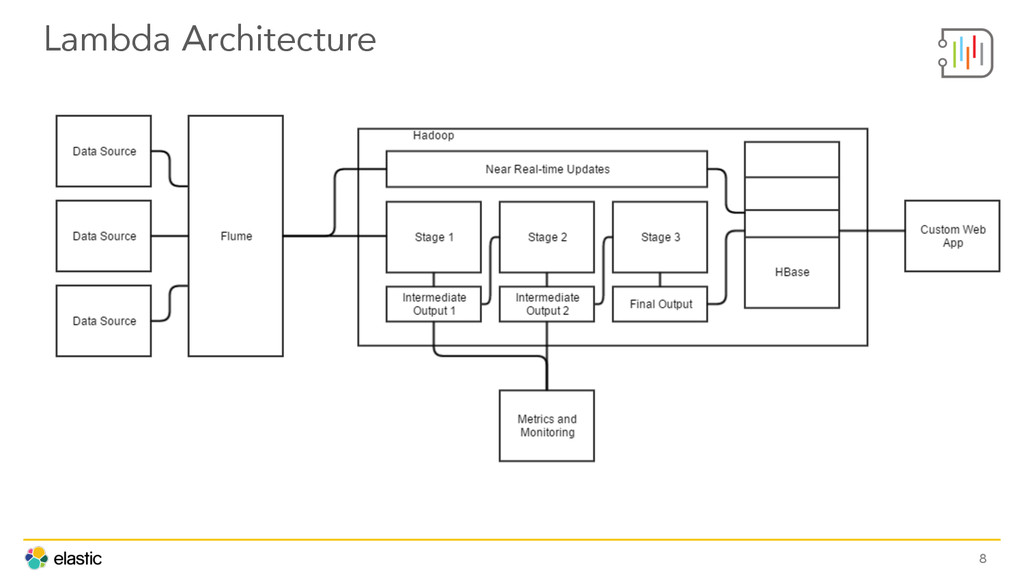
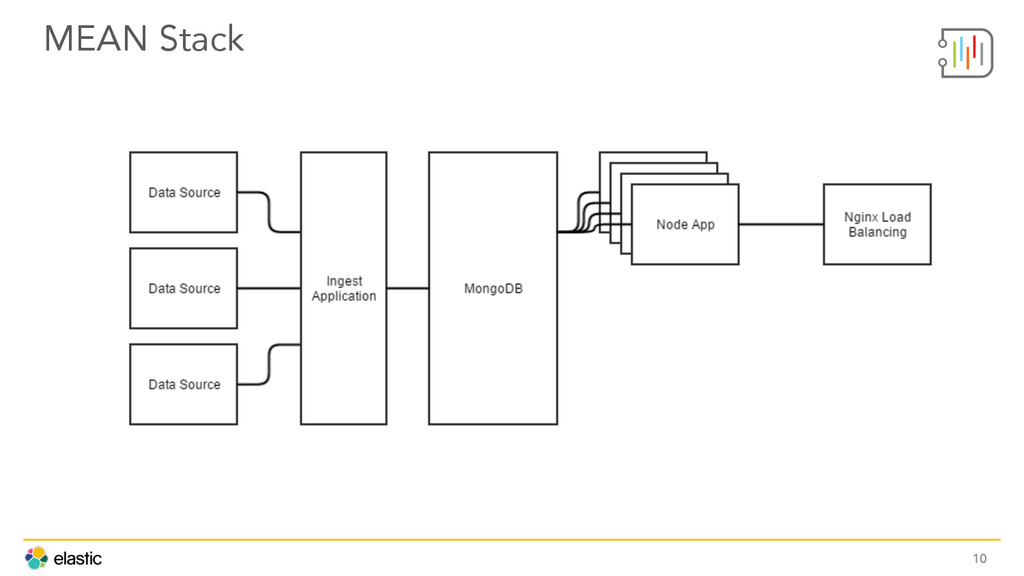
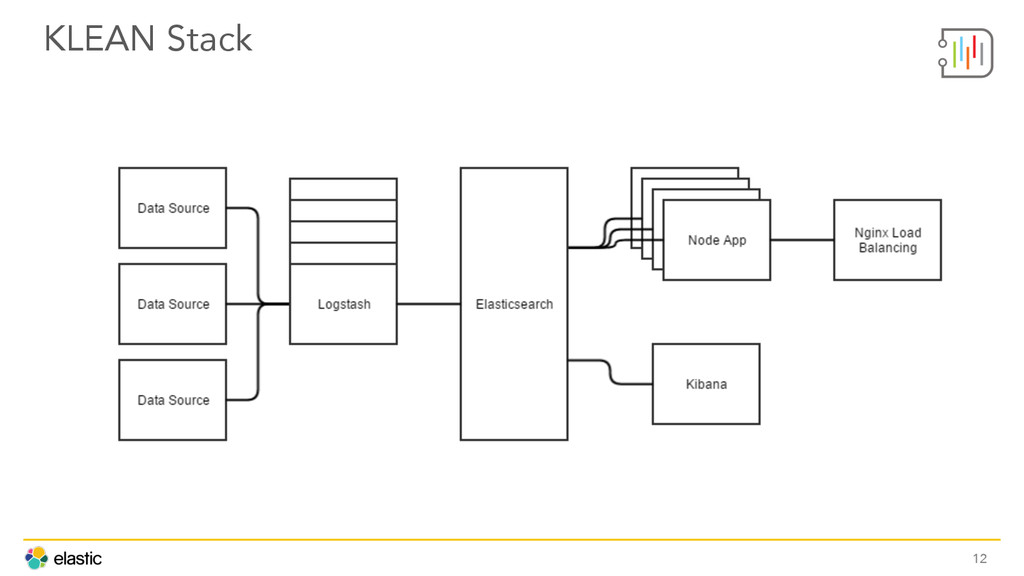
Buiding a seamless Cyber Security analytics tool starts by choosing the right stack. The team at DecisionLab shares how they've deployed Kibana, Logstash, Elasticsearch, Angular, and Node to kick Hadoop and Splunk to the curb. Other insights include architecture, automation, and deployment best practices.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}