Die Otto Gruppe betreibt eine zentrale Business Intelligence Plattform, die helfen soll, Kundenwünsche besser zu verstehen, schnell auf die Marktnachfrage zu reagieren und Echtzeit-Analysen zu tätigen. Dafür wird der Elastic Technologie Stack eingesetzt, wobei bis zu 5000 Dokumente pro Sekunde prozessiert werden.
Jan-Hendrik Lendholt | Elastic{ON}Tour Munich | November 10, 2015
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
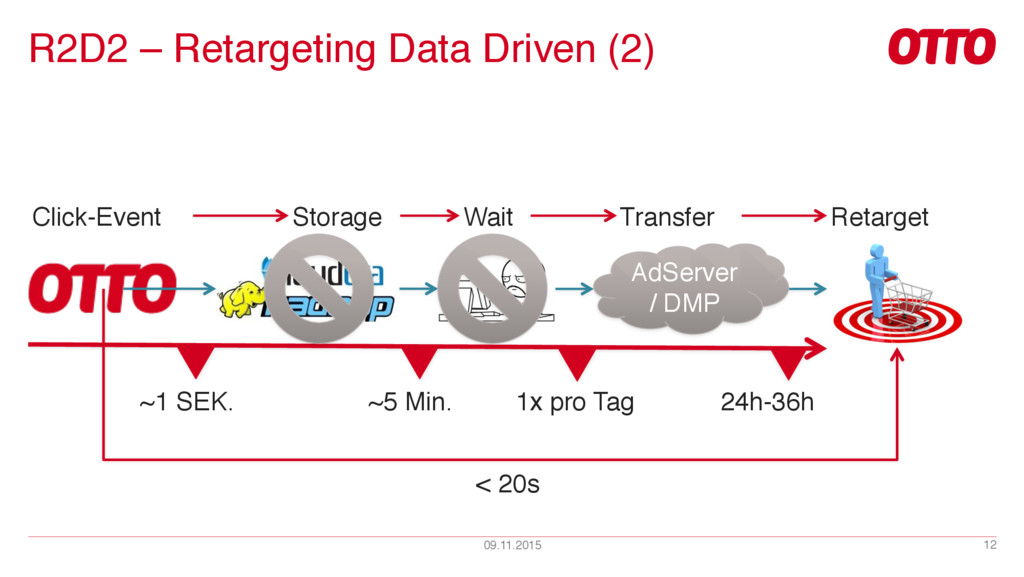{kind=link}
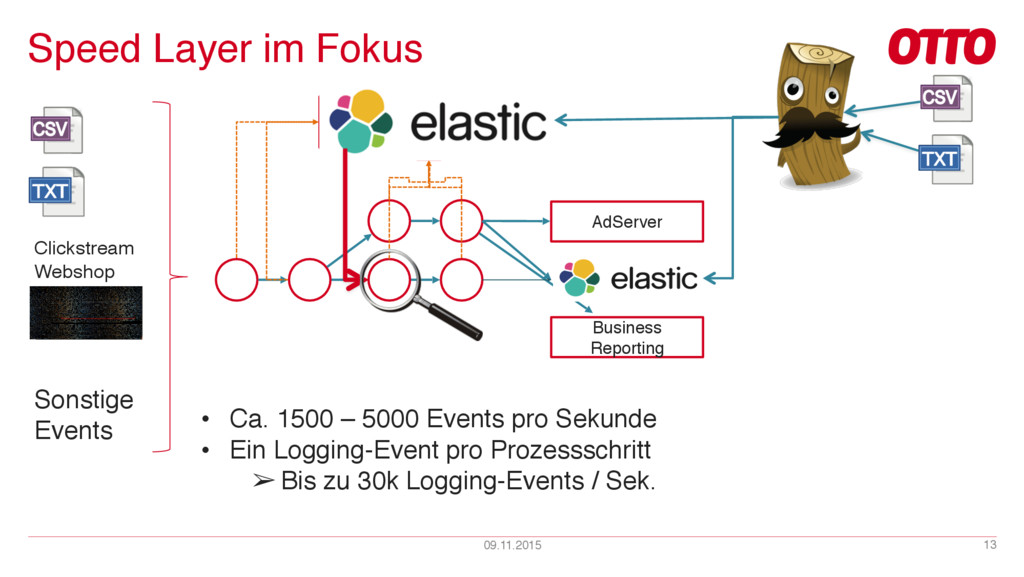{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
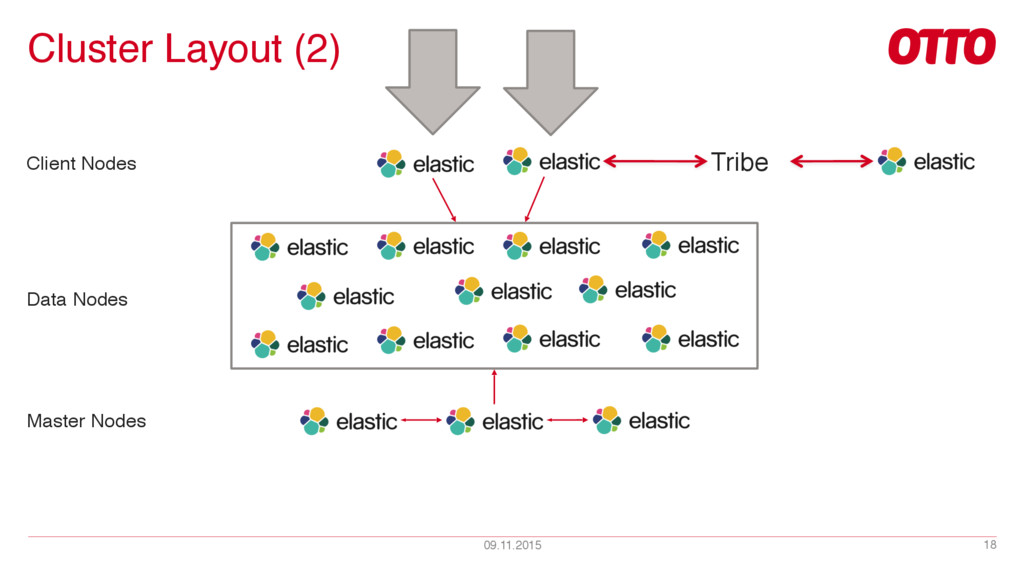{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}